대규모 화자 검색을 위한 무작위 화자 변동성 서브스페이스
본 논문은 i‑vector와 x‑vector와 같은 화자 임베딩을 LSH 기반 해시 테이블에 매핑할 때, 완전 무작위가 아닌 화자 변동성을 반영한 무작위 서브스페이스(RSS)를 이용해 해시 비트와 테이블 수를 크게 줄이면서도 검색 정확도를 유지하는 방법을 제안한다. 실험 결과, 제안 방식은 선형 탐색 대비 100배, 기존 LSH 대비 7배 빠른 속도를 달성하였다.
저자: Suwon Shon, Younggun Lee, Taesu Kim
본 논문은 대규모 멀티미디어 데이터에서 특정 화자의 음성 구간을 빠르게 찾아내는 ‘화자 검색(speaker search)’ 문제를 다룬다. 기존 연구에서는 i‑vector와 같은 저차원 화자 임베딩을 LSH(Locality Sensitive Hashing)와 결합해 대규모 데이터베이스에서도 근사 최근접 이웃 탐색을 가능하게 했지만, 무작위 투영에 기반한 LSH는 해시 비트가 중복되는 현상과 높은 해시 테이블 수 필요성이라는 두 가지 한계가 있었다.
이를 해결하기 위해 저자들은 ‘Random Speaker‑variability Subspace (RSS)’라는 새로운 투영 방식을 제안한다. RSS는 전체 학습 데이터에서 무작위로 선택된 Nₛ명의 화자 집합을 이용해 Linear Discriminant Analysis(LDA) 변환 행렬을 계산하고, 이를 각 해시 테이블마다 독립적인 투영 행렬 Rₗ로 사용한다. LDA는 클래스(화자) 간 분산을 최대화하고 클래스 내 분산을 최소화하는 방향을 찾기 때문에, RSS를 통해 투영된 임베딩은 동일 화자 간 거리를 더 가깝게, 서로 다른 화자 간 거리를 더 멀게 만든다. 이렇게 하면 동일 화자 임베딩이 동일 혹은 인접한 해시 버킷에 배치될 확률이 높아져, 기존 LSH보다 적은 해시 비트(k)와 해시 테이블(L)만으로도 높은 재현율을 유지할 수 있다.
구현 세부 사항은 다음과 같다. (1) 화자 집합 Sₗ을 무작위로 선택해 between‑class scatter matrix와 within‑class scatter matrix를 계산하고, LDA 행렬을 구한다. (2) 해시 함수는 hᵣ(w)=sgn(wᵀr+b) 형태로 정의되며, b는 투영된 데이터의 평균값으로 설정해 해시 비트의 균형을 맞춘다. (3) Nₛ는 해시 비트 수 k보다 크게 잡아 within‑class scatter 행렬이 특이값 문제에 빠지지 않도록 한다. (4) 이러한 과정을 L번 반복해 L개의 독립적인 RSS 투영 행렬을 만든다.
실험은 VoxCeleb1과 VoxCeleb2 데이터셋을 사용해 두 가지 화자 임베딩(i‑vector와 x‑vector)을 평가했다. i‑vector는 600차원, x‑vector는 512차원으로 추출한 뒤, LDA로 150차원까지 차원 축소하였다. 검색 성능은 화자 식별(Closed‑set)에서는 정확도, 화자 검색(1‑to‑N 검증)에서는 Equal Error Rate(EER)로 측정했다.
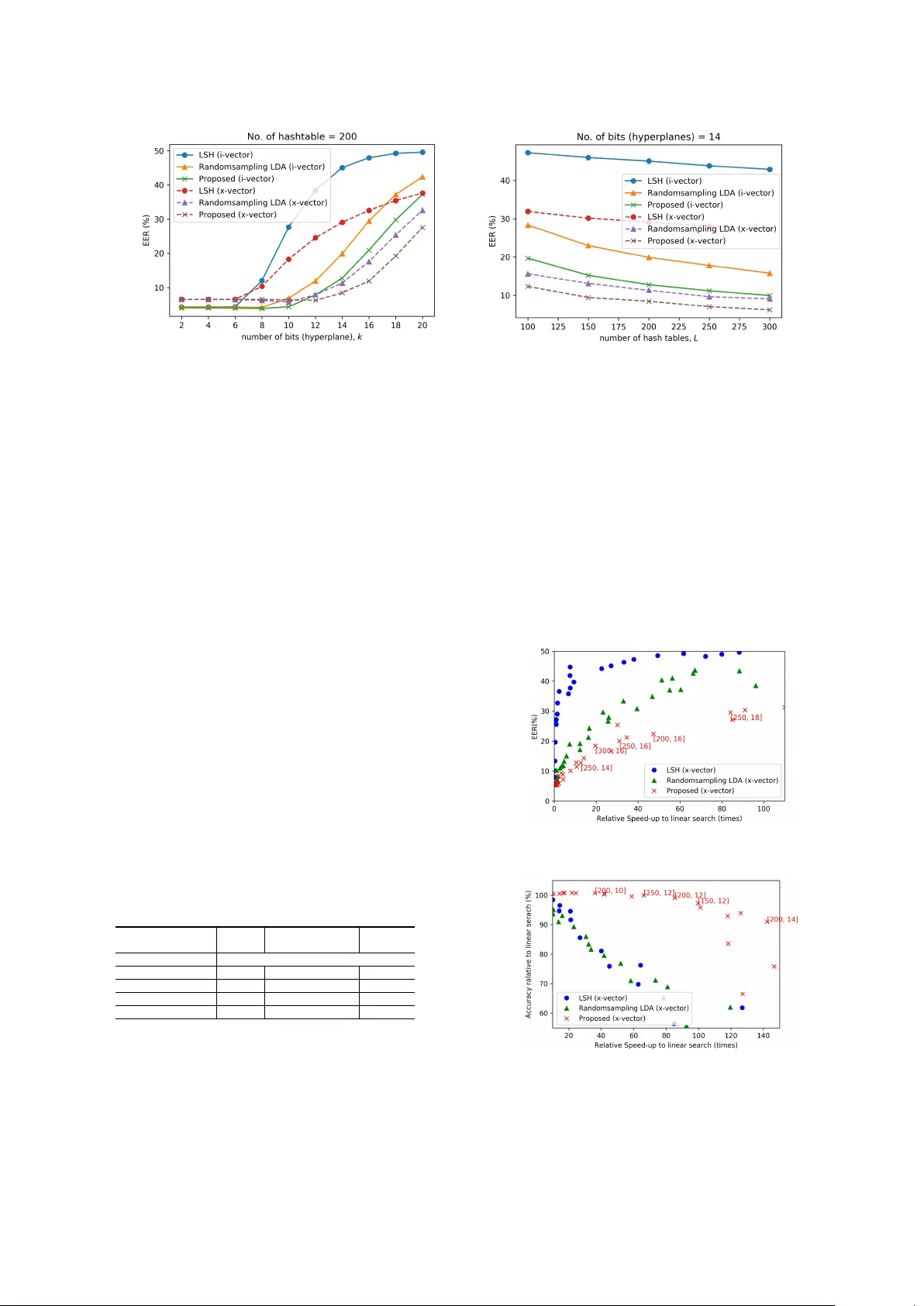
결과는 크게 세 가지 관점에서 의미가 있다. 첫째, RSS‑LSH는 동일 화자 임베딩 간 평균 해밍 거리가 비슷한 화자 간 거리보다 현저히 작아, 원본 코사인 거리와의 근사도가 높음을 보여준다. 둘째, x‑vector가 i‑vector보다 모든 해시 방식에서 더 효율적으로 버킷에 매핑되는 현상이 관찰되었다. 이는 x‑vector가 DNN 기반으로 화자 라벨을 직접 학습해 클래스 간 구분이 명확하기 때문이며, 향후 다른 DNN 기반 임베딩에도 동일한 이점이 기대된다. 셋째, 동일 정확도(≥95%)를 유지하면서 해시 테이블 수와 비트를 크게 줄여 전체 검색 속도를 7배 가속화했으며, 선형 탐색 대비 100배 이상의 속도 향상을 달성했다.
표 2와 표 3에서 확인할 수 있듯이, 기존 LSH는 300개의 해시 테이블과 10개의 하이퍼플레인으로 구성돼야 만족스러운 재현율을 얻지만, RSS‑LSH는 150개의 테이블과 12개의 하이퍼플레인만으로도 비슷하거나 더 나은 성능을 보인다. 또한, 해시 비트 수 k가 성능에 미치는 영향이 L보다 크므로, k를 중심으로 설계하고 L은 미세 조정 용도로 활용하면 된다.
논문의 결론은 RSS 기반 해시가 대규모 화자 검색에서 기존 무작위 LSH보다 효율적이며, 특히 DNN 기반 화자 임베딩과 결합했을 때 큰 이점을 제공한다는 점이다. 향후 연구 방향으로는 (1) 비선형 차원 축소 기법과 RSS를 결합해 더욱 강력한 투영을 탐색, (2) 다중 모달(음성+영상) 데이터에 적용해 화자와 얼굴을 동시에 검색하는 시스템 구축, (3) 실시간 스트리밍 환경에서의 온라인 업데이트 메커니즘 개발 등을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기