Telephonetic: Making Neural Language Models Robust to ASR and Semantic Noise
Speech processing systems rely on robust feature extraction to handle phonetic and semantic variations found in natural language. While techniques exist for desensitizing features to common noise patterns produced by Speech-to-Text (STT) and Text-to-…
Authors: Chris Larson, Tarek Lahlou, Diana Mingels
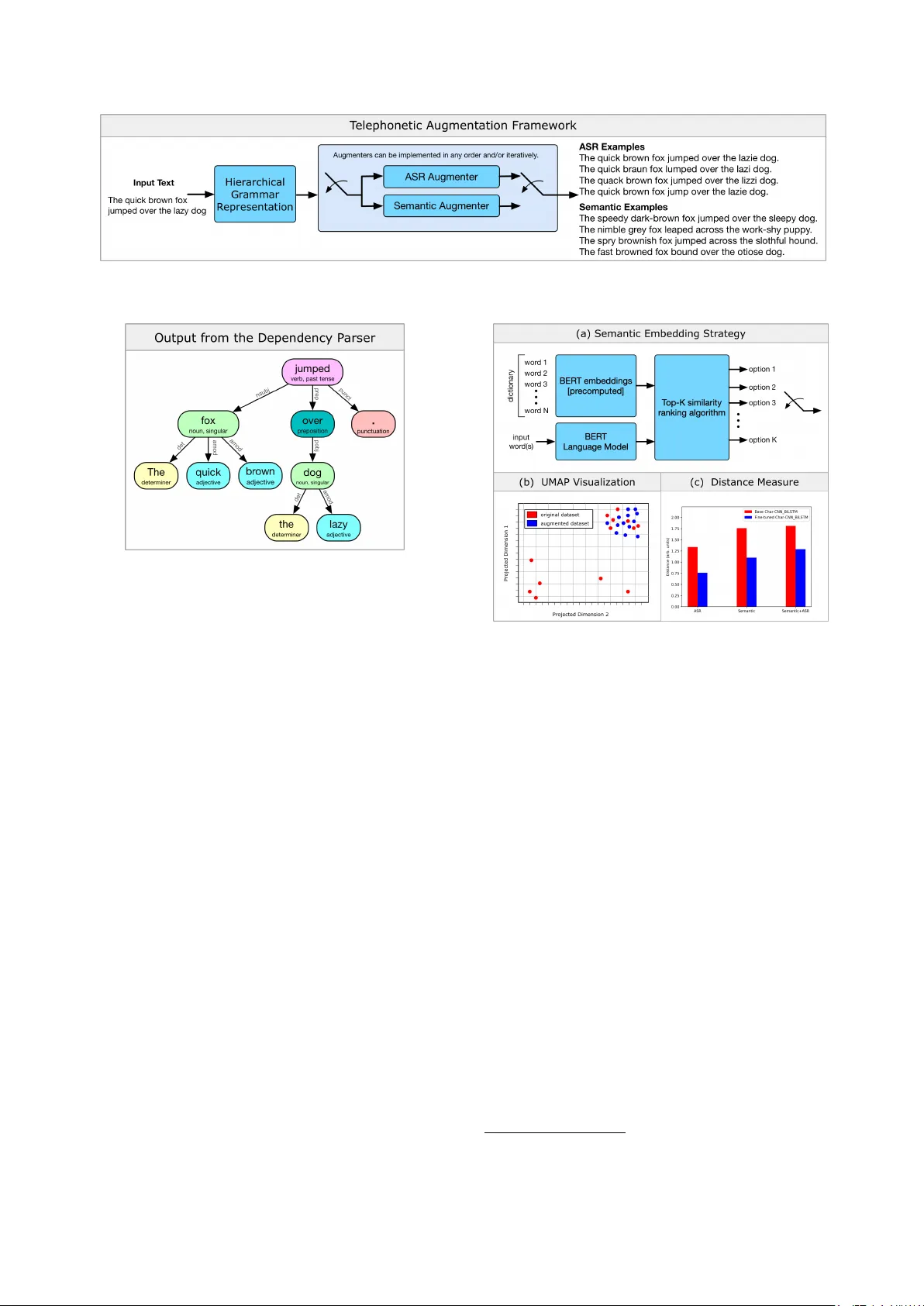
T elephonetic: Making Neural Language Models Rob ust to ASR and Semantic Noise Chris Larson T arek Lahlou Diana Mingels Zac hary K ulis Erik Mueller Capital One { christopher.larson2, tarek.lahlou, diana.mingels, zachary.kulis, erik.mueller } @capitalone.com Abstract Speech processing systems rely on robust feature e xtraction to handle phonetic and semantic v ariations found in natural language. While techniques exist for desensitizing features to common noise patterns produced by Speech-to-T ext (STT) and T ext-to-Speech (TTS) systems, the question remains how to best le verage state-of-the-art language models (which capture rich semantic features, but are trained on only written text) on inputs with ASR errors. In this paper , we present Telephonetic , a data augmentation framew ork that helps robustify language model features to ASR corrupted inputs. T o capture phonetic alterations, we employ a character-le vel language model trained using probabilistic masking. Phonetic augmentations are generated in two stages: a TTS encoder (T acotron 2, W a veGlo w) and a STT decoder (DeepSpeech). Similarly , semantic perturbations are produced by sampling from nearby words in an embedding space, which is computed using the BER T language model. W ords are selected for augmentation according to a hierarchical grammar sampling strategy . T elephonetic is ev aluated on the Penn Treebank (PTB) corpus, and demonstrates its effecti veness as a bootstrapping technique for transferring neural language models to the speech domain. Notably , our language model achie ves a test perplexity of 37.49 on PTB, which to our knowledge is state-of-the-art among models trained only on PTB. Index T erms : language modeling, neural networks, spoken lan- guage understanding, speech-to-text, text-to-speech, automatic speech recognition 1. Introduction Language modeling is the core component of both written and spoken language understanding systems. Recent work on trans- former networks [1, 2, 3] trained on massive written text cor- pora have repeatedly demonstrated step changes in performance on several tasks including text summarization, question an- swering (Q&A), intent classification, natural language infer - ence (NLI), as well as in zer o-shot settings, in which they gen- eralize to new tasks and new data without being pre trained on that data or those tasks. Le veraging these models in spoken language understanding systems, howe ver , is obfuscated by the fact that noise injected by automatic speech recognition (ASR) processing components contains structure that is otherwise not taken adv antage of. Previously , researchers hav e de veloped approaches to learn real-valued representations of spoken lan- guage that are sensiti ve to acoustic and phonetic similarities [4], and more recently semantic similarity such as Speech2V ec [5]. These approaches hav e clear drawbacks, ho wev er , in that they are stand-alone models, they are trained on one task, and they do not leverage the rich, pre trained feature layers offered by models such as BER T [2] and GPT -2 [3]. In this paper, we introduce the T elephonetic augmentation framew ork wherein data augmentations can be used to fine-tune language models on written te xt data so that the y are better equipped to handle ASR errors. The term telephonetic is in- spired by the popular game telephone wherein a message is passed sequentially and orally from person to person, aggre- gating phonetic and other errors along the way , until eventually the message has diver ged significantly from its origin. This pa- per lays the foundation for generating similar errors by pairing neural speech synthesis systems with commodity ASR systems and reflecting the resulting errors into a training dataset. In Sec- tion 2 we discuss the character lev el language model e valuated in this paper as well as the companion training strategy . In Section 3 we present the core components of the telephonetic framew ork and provide experimental results and commentary in Section 4. 2. Character -based language modeling The Language Model (LM) discussed in this paper builds upon the Char -CNN-LSTM architecture proposed in [6]. Rather than imposing causality to the learning task, as is commonplace with next-word prediction training, we instead use a masked LM training procedure inspired by De vlin et al. [2]. Letting w i de- note the i -th word in the text sequence w = [ w 0 , . . . , w T − 1 ] , of length T the masked LM training strategy is to randomly re- place a word w i with a mask token and then attempt to predict the masked word. The contribution of a single sample to the negati ve log-likelihood, − log ( ` ) , training objecti ve is specified according to − log ` ( θ LM | w ) = − log p ( w i | ˜ w i c ; θ LM ) , (1) where θ LM denotes the LM parameters and ˜ w i c denotes the character representation of w with the i -th entry or word hav- ing been replaced with the mask token. Importantly , we do not accumulate loss ov er all token in an example, only one randomly chosen token; this decorrelates the gradients at the mini-batch lev el. T o better align the Char-CNN-LSTM archi- tecture to the masked LM training procedure, we employ a bi- directional LSTM head for the prediction task since masking the label at the input layer allows us to fully recurse both LSTMs ov er the entire input sequence (including the mask tok en itself). This modified architecture, which we refer to hereon as Char- CNN-BiLSTM, is depicted in Fig. 1. The training procedure consists of randomly selecting one word from an input text se- quence, masking it with probability p m = 0 . 85 , and then per- forming mini-batch stochastic gradient descent using the ob- jectiv e in (1). W e specifically chose to focus attention on lan- guage models that operate on character-lev el tokens rather than Figure 1: The Char-CNN-BiLSTM ar chitectur e derived fr om [6]. Convolutional filters ar e used to convolve over character embeddings for eac h word in the input sequence. T wo highway transformations ar e then applied prior to the application of two bi-dir ectional LSTM layers. The model outputs a pr obability distribution o ver its wor d vocabulary . the word-piece tokens in [2] due to the resilience character level models hav e to spelling errors in the input text. 3. A ugmentation strategy The telephonetic augmentation strategy presented in this work in v olves sampling text inputs according to their grammar and then augmenting portions of those inputs by running them through noisy ASR and semantic replacement systems. The fol- lowing steps summarize this procedure for a gi ven input text: 1. Express the grammatical hierarchy of the input text using a directed graph. 2. Sample and replace nodes in the graph with semantically similar nodes. 3. Sample and replace nodes in the graph with the ASR sys- tem outputs produced using synthesized audio of the te xt within the nodes. Sev eral input-output examples as well as the above steps are illustrated in Fig. 2. The indi vidual processing modules that comprise the frame work are described in detail in the remainder of this section. 3.1. Hierarchical grammar based sampling The purpose of the sampling method is to extract portions of the input text to augment that align with the desired robustness metrics and potential use cases of the language model. T oward this goal, we le verage hierarchical representations of the inputs grammar in order to efficiently sample based on part-of-speech by traversing the graph for certain node types. For example, sampling and augmenting different grammatical elements are potentially more suitable to downstream tasks than others, e.g. verbs for intent or sentiment classification. Indeed, sampling along the graph allo ws for the selection of either indi vidual words or phrases based upon the particular tree description of the text and whether a node or a node’ s subtree are selected. One instance of such a representation can be achiev ed using a dependency parser . Broadly speaking, dependency parsers ex- pose grammatical relationships between head words and words which modify said heads thereby providing directed graphs. An example graph is portrayed in Fig. 3 for the example input text used in Fig. 2. In this paper, we utilize a dependenc y parser to strategically sample words in the input text which are well- suited to making a language model robust to input texts that draw upon large vocab ularies and contain many ASR errors, i.e., we focus on augmentations of adjectiv es and nouns. 3.2. Semantic augmentation The goal of semantic augmentation in this context is two-fold. First, it pro vides a method to sensitize pre-trained language models to domain-specific language through data augmenta- tion; this is useful in the absence of large domain-specific datasets. A second, more subtle benefit applies specifically to the ASR conte xt, in which phonetically corrupted words can be mapped back to semantically similar , in-v ocabulary words. T o generate semantically altered text samples, we leverage the BER T language model [2], which was trained on the Book- Corpus and English W ikipedia corpora, totalling 3.3B words. BER T employs a multi-embedding input layer that consists of word-piece tokens, positional tokens, and sequence tokens that are summed and then fed into the transfer layers, which con- sist of dense fully connected layers. The semantic augmenta- tion strategy is illustrated in Fig. 4(a). The core component of the semantic augmenter is a nearest-neighbor look-up table for each word in a lexicon of 80K common English words. Nearest neighbors are found by computing the covariance of the 80K lexicon in the 768-dimensional BER T embedding space, sort- ing the rows in descending order , and then packing the corre- sponding sorted words into a look-up table. At train time, the semantic augmenter replaces words simply by sampling uni- formly from its top-5 nearest neighbors. 3.3. ASR augmentation The primary goal of ASR augmentation is to produce spans of output text that coincide with common transcription errors that ASR systems would make when the input text is voiced by a number of speakers with diverse acoustic, linguistic, and pho- netic qualities. The ASR augmenter utilized in this paper is por- trayed in Fig. 5(a) and is made up of two parts: a te xt-to-speech engine and a speech-to-text engine. Referring to the figure, the depicted text-to-speech engine utilizes T acotron 2 [7] to pro- duce mel spectrogram representations of an input text that are than fed to W av eGlow [8] to produces audio outputs similar to those recorded by humans. In more detail, the T acotron 2 archi- tecture is depicted in Fig. 5(b) and maps character embeddings through a sequence-to-sequence network with attention to a se- quence of mel spectrogram frames. W av eGlo w , whose archi- tecture is depicted in Fig. 5(c), is a state-of-the-art flow-based network able to synthesize high quality audio from mel spec- trograms. As a consequence of the single-speaker identity of each architecture, e very speaker identity requires a unique pair of trained T acotron 2 and W aveGlo w models. The speech-to- text engine depicted utilizes DeepSpeech [6] to transform the generated audio back into text. 4. Experiments 4.1. ASR augmenter training The ASR augmenter used in the follo wing experiments was built by training the text-to-speech engine depicted in Fig. 5(a) for each of the speaker profiles in the CMU Arctic dataset [9]. These profiles contain fi ve male and two female v oices, four of which hav e US English accents and one of each Canadian, In- Figure 2: A high level description of the telephonetic augmentation framework. Figure 3: An example graph r epr esenting the grammati- cal dependencies in the sentence The quick brown fox jumped over the lazy dog. dian and Scottish English accents. Since each profile only con- tains approximately one hour of transcribed and aligned data, we first train both the T acotron 2 and W aveGlo w models on the LJSpeech dataset [10] which contains 13,100 short audio clips totaling approximately 24 hours of a single speaker reading pas- sages from 7 non-fiction books. Both of these models were each trained on 8 T esla V100 GPUs for sev eral days until audio sam- ples containing out of vocab ulary words qualitati vely sounded natural. Both models used the ADAM optimizer; T acotron 2 used a batch size of 128, weight decay of 1e-6, and an initial learning rate of 1e-3, whereas W av eGlow used a batch size of 32, no weight decay , and an initial learning rate of 1e-4. For each CMU speaker , a T acotron 2 and W aveGlo w model was then fine-tuned from the LJSpeech models on 4 T esla V100 GPUs for a number of additional days until comparable qual- ity in the new voice was achie ved. Both models fine tuned us- ing the ADAM optimizer with an initial learning rate of 1e-5 and weight decay of 1e-6. T acotron 2 used a batch size of 12 whereas W aveGlo w used a batch size of 8. For the fine-tuned T acotron 2 models, the sampling rate mismatch between the two datasets required the alignment mechanisms to be relearned from scratch. All models trained for the text-to-speech engines used manual learning rate annealing. While the two models for a gi ven speaker profile were not trained end-to-end, the mel spectrograms used as inputs to train- ing W av eGlo w were produced by the fully trained, correspond- ing T acotron 2 model rather than deriv ed from the original audio files. In this sense, W aveGlo w has the opportunity to learn to correct for spectral errors systematically produced by T acotron 2. Figure 5(b) illustrates the final mel spectrograms for the example sentence in Fig. 2 for the LJSpeech speaker and six Figure 4: (a) An example semantic augmentation pipeline that lever ages a deep neural languag e model to pr oduce a distance- based word similarity look-up table. (b) Embeddings fr om the fine tuned Char-CNN-BiLSTM models fr om both original ASR corrupted text inputs. Pr ojections wer e performed using the popular nonlinear manifold projection technique UMAP [11]. (c) The mean euclidean distance between pr ojected PTB data with and without ASR, semantic, and semantic+ASR err ors. of the CMU Arctic speakers. Note that the sampling rate for the LJSpeech audio is higher which manifests itself through the longer mel spectrum. For the speech-to-text engine depicted in Fig. 5(a), we uti- lized the DeepSpeech implementation and model that is open source and a v ailable from Mozilla Corporation 1 . The model architecture uses several stacked Recurrent Neural Network (RNN) decoders and the Connectionist T emporal Classification (CTC) loss function to handle alignment. 4.2. Language model training The Char-CNN-BiLSTM language model was trained on the PTB corpus, which consists of ∼ 50K sentences (90-5-5 split), compiled from v arious telephone speech, ne ws-wire, micro- phone speech, and transcribed speech data sources. The model was trained using mini-batch ( n = 512 ) stochastic gradient de- scent with Nestero v momentum, an initial learning rate of 0.25, and manual learning rate annealing. T ypically , language mod- els are trained on batches of highly correlated inputs, in which 1 A vailable at https://github.com/mozilla/DeepSpeech Figure 5: (a) An e xample ASR augmentation pipeline with a text-to-speec h engine depicted using T acotr on 2 and W aveGlow and a speech-to-te xt engine depicted using DeepSpeech. (b) The mel spectr ogram r epr esentations of the example text fr om F ig. 2 for the LJSP eech dataset (22kHz) and CMU speakers (16kHz). The arc hitectural details of (c) T acotr on 2 and (d) W aveGlow ar e also pr ovided. each input sentence is unraveled to produce T training exam- ples, where T is the number of words in the input sequence. While computationally conv enient, this sampling strategy pro- duces samples that are not independently drawn. Our train- ing procedure eliminates this dependence by randomly select- ing only one word from each text sample per epoch; this is less efficient computationally , but produces smoother gradients. T able 1 shows the perplexity v alues of the Char-CNN- BiLSTM language model on data with and without ASR and semantic perturbations. The baseline Char-CNN-BiLSTM was trained on uncorrupted PTB data, and has a test perplexity of 37.49. The perplexity of this model on ASR, semantic, and semantic+ASR corrupted data, ho we ver , is significantly higher (+55.80, +110.66, +133.58, respectiv ely), which demonstrates its inability to generalize to text containing phonetic and seman- tic noise. Through fine tuning using the T elephonetic frame- work, we observe a sharp drop in perplexity on the ASR, se- mantic, and semantic+ASR corrupted test sets relativ e to the baseline model (-43.76, -87.55, and -101.25, respectively), and only a marginal increase on the original test set (+5.02, +8.06, and +6.93, respectiv ely). While semantic perturbations appear to have a larger ef fect on language model perplexity than those from ASR, the effects of ASR perturbations are clear from Fig. 4(b), which shows a 2D projection of the embeddings produced from the base- line and fine-tuned models on original and ASR corrupted text inputs generated from the string the quick brown fox jumped over the lazy dog . The ASR augmentation clearly produces decoded text that div erges from the distribution of natural language found in the PTB dataset, as measured in the Char-CNN-BiLSTM latent space. Importantly , we observe that fine tuning on ASR corrupted data provides more robustness to those inputs than does the baseline model trained on only the original data. Figure 4(c) quantifies the variation in these projections before and after fine tuning, showing the euclidean distance between fine tuned model projections produced from baseline and corrupted inputs is lower than those prodcued by the baseline Char-CNN-BiLSTM model. The projections pro- duced by the fine tuned Char -CNN-BiLSTM models are less sensitiv e to these noise sources than the baseline. T able 1: The performance of the Char-CNN-BiLSTM model on English P enn T reebank data with and without ASR and semantic noise. F or r efer ence, the current state-of-the-art perplexity on the PTB test set is OpenAI’s GPT -2 [3] (35.76). The pre vious state-of-the-art for a non-transfer learned language model was 46.54 [12]. Fine tuned on T ested on PPL (valid / test) None Baseline 40.20 / 37.49 None ASR 110.02 / 92.85 None Semantic 178.55 / 147.71 None ASR + Semantic 206.00 / 170.73 ASR Baseline 46.14 / 42.07 ASR ASR 52.86 / 49.09 Semantic Baseline 49.61 / 45.11 Semantic Semantic 62.87 / 60.16 ASR + Semantic Baseline 47.97 / 43.98 ASR + Semantic ASR + Semantic 73.56 / 69.52 5. Conclusions The telephonetic augmentation framework, which lev erages a number of recent advances in deep learning, enables state-of- the-art language models trained on only written text datasets to transfer gracefully to handling speech domain inputs corrupted by ASR errors. Empirically , we found that fine tuning on a dataset comprising a combination of semantic and phonetic data perturbations enables character le vel language models to gener- alize to out-of-sample inputs containing ASR structured noise. It is also worth noting that these data augmentation strategies come free of labeling cost; BER T , DeepSpeech, W aveGlo w , and T acotron 2 can be leveraged either out-of-the-box or by train- ing/fine tuning on publicly av ailable datasets with no manual labeling required. In addition to the T elephonetic data aug- mentation strategy presented in this manuscript, we observe a sizeable performance improvement on the language modeling task (PPL reduced by ∼ 20 % with respect to [12]) when using character-le vel model in combination with probabilistic mask- ing and independent mini-batch sampling. This training strat- egy is inspired by the process that was used to train BER T , and to our kno wledge, the baseline perplexity of 37.49 is the lowest perplexity achie ved by a non transfer -learned model to date. 6. Acknowledgements The authors would like to thank Core y Fyock, Jeremy Doll, Kavita Hundal, Margaret Mayer , Mathias Menasi, Oluwatobi Olabiyi, and V arun Singh for their helpful insight. 7. References [1] A. V aswani, N. Shazeer, N. Parmar , J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “ Attention is all you need, ” https://arxiv .org/abs/1706.03762 , 2017. [2] J. Devlin, Ming-W eiChang, K. Lee, and K. T outanova, “Bert: Pre-training of deep bidirectional transformers for language un- derstanding, ” https://arxiv .org/pdf/1810.04805.pdf , 2018. [3] A. Radford, J. W u, R. Child, D. Luan, and D. A. I. Sutskever , “Language models are unsupervised multitask learners, ” 2019. [4] D. Serdyuk, Y . W ang, C. Fuegen, A. Kumar , B. Liu, and Y . Bengio, “T owards end-to-end spoken language understanding, ” https://arxiv .org/abs/1802.08395 , 2018. [5] Y .-A. Chung and J. Glass, “Speech2vec: A sequence-to-sequence framew ork for learning word embeddings from speech, ” 2018. [6] Y . Kim, Y . Jernite, D. Sontag, and A. M. Rush, “Character-aw are neural language models, ” https://arxiv .org/abs/1508.06615 , 2015. [7] Y . W ang, R. Skerry-Ryan, D. Stanton, Y . W u, R. J. W eiss, N. Jaitly , Z. Y ang, Y . Xiao, Z. Chen, S. Ben- gio, Q. Le, Y . Agiomyrgiannakis, R. Clark, and R. A. Saurous, “T acotron: T owards end-to-end speech synthesis, ” https://arxiv .org/abs/1703.10135 , 2017. [8] R. Prenger , R. V alle, and B. Catanzaro, “W ave glow: A flow-based generativ e network for speech synthesis, ” https://arxiv .org/abs/1811.00002 , 2018. [9] J. K ominek, A. W . Black, and V . V er , “Cmu arctic databases for speech synthesis, ” T ech. Rep., 2003. [10] K. Ito, “The lj speech dataset, ” https://keithito.com/ LJ- Speech- Dataset/, 2017. [11] L. McInnes, J. Healy , and J. Melville, “Umap: Uniform man- ifold approximation and projection for dimension reduction, ” https://arxiv .org/abs/1802.03426 , 2018. [12] C. Gong, D. He, X. T an, T . Qin, L. W ang, and T .-Y . Liu, “Frage: Frequency-agnostic word representation, ” in NeurIPS , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment