음성 인식 오류에 강인한 언어 모델을 위한 텔레포니틱 데이터 증강
텔레포니틱은 문자‑레벨 언어 모델에 ASR·TTS 파이프라인을 이용한 음성‑텍스트 변환과 BERT 기반 의미 교체를 결합한 데이터 증강 기법이다. 계층적 문법 그래프에서 선택된 토큰을 음성 합성·인식 혹은 의미 유사어로 교체해 학습 데이터를 다양화하고, 이를 PTB에 fine‑tuning 하면 원본 모델 대비 ASR·의미 잡음에 대한 퍼플렉시티가 크게 감소한다.
저자: Chris Larson, Tarek Lahlou, Diana Mingels
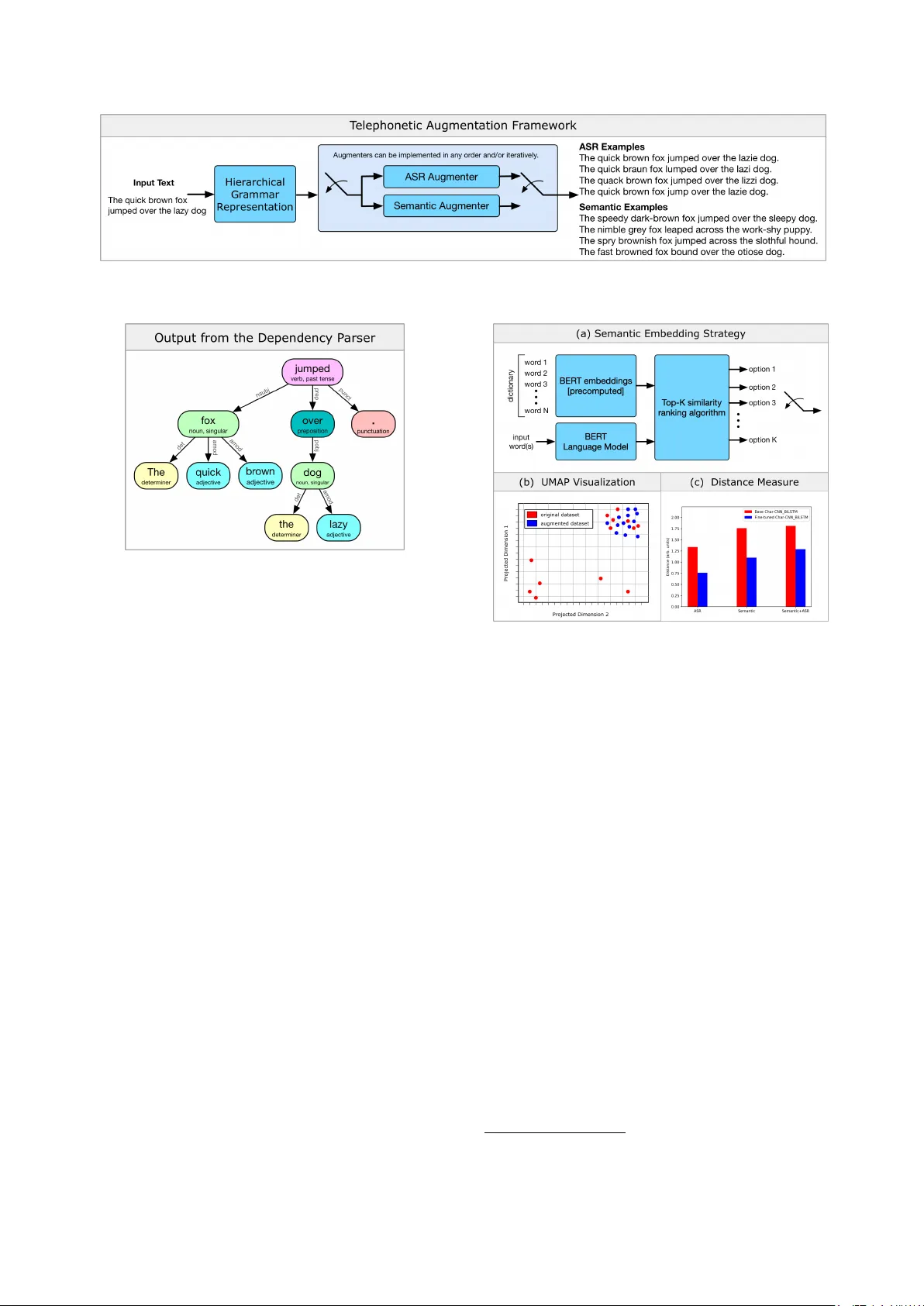
본 논문은 음성 인식(ASR)과 텍스트‑투‑스피치(TTS) 시스템이 만든 구조적 잡음에 강인한 언어 모델을 만들기 위한 데이터 증강 프레임워크 “텔레포니틱”을 제안한다. 기존 연구들은 음성 신호 자체를 처리하거나 별도 음성‑언어 임베딩을 학습했지만, 텔레포니틱은 사전 학습된 텍스트‑기반 언어 모델을 그대로 활용하면서, 입력 텍스트에 인위적인 음성·의미 잡음을 삽입해 모델을 재학습한다.
1. **문자‑레벨 언어 모델 설계**
- Char‑CNN‑BiLSTM 구조를 기반으로, 각 단어를 문자 임베딩으로 변환 후 1‑D 컨볼루션, 하이웨이즈 변환, 양방향 LSTM 두 층을 통과시켜 단어 수준 확률 분포를 출력한다.
- 기존 next‑word 예측 대신 BERT에서 영감을 얻은 마스크드 LM 방식을 채택한다. 학습 시 무작위 단어를 마스크(p_m = 0.85)하고, 마스크된 위치 하나만 손실에 포함시켜 미니배치 간 그래디언트 상관성을 낮춘다.
- 양방향 LSTM 헤드 덕분에 마스크 토큰 자체를 포함한 전체 문맥을 활용해 복원하도록 설계돼, 문자‑레벨 특성(철자 오류, 부분 단어 손실 등)에 대한 복원 능력이 강화된다.
2. **잡음 생성 파이프라인**
- **음성 잡음(ASR)**: 텍스트를 Tacotron 2 로 멜 스펙트로그램으로 변환하고, WaveGlow 로 실제 음성 파형을 합성한다. 이후 DeepSpeech ASR 엔진으로 다시 텍스트화한다. 화자 다양성을 확보하기 위해 CMU Arctic 데이터셋의 7개 화자(5 명 남성, 2 명 여성) 각각에 대해 TTS 모델을 LJSpeech 사전 학습 모델에서 파인‑튜닝한다.
- **의미 잡음(Semantic)**: 사전 학습된 BERT 임베딩(768‑dim)에서 80 K 일반 영어 단어의 코베리언스 행렬을 계산하고, 각 단어에 대해 상위 5개 최근접 이웃을 저장한다. 증강 시 선택된 토큰을 이 이웃 중 무작위로 교체한다. 이는 동의어 교체를 넘어, 의미적으로 유사하지만 철자·발음이 다른 형태를 생성한다.
3. **계층적 문법 기반 샘플링**
- 입력 문장을 의존 구문 분석기로 그래프화하고, 파트‑오브‑스피치별(명사, 형용사 등)로 노드를 샘플링한다. 논문에서는 특히 명사·형용사에 초점을 맞추어, ASR 오류가 빈번히 발생하는 고빈도 어휘를 목표로 잡음 삽입을 수행한다.
- 샘플링 전략은 (i) 의미 교체, (ii) 음성 교체, (iii) 두 가지를 동시에 적용하는 세 가지 변형을 만든다.
4. **실험 설정 및 결과**
- 데이터: Penn Treebank(PTB) 90‑5‑5 분할(≈50 K 문장).
- Baseline: Char‑CNN‑BiLSTM를 원본 PTB만으로 학습, 테스트 PPL = 37.49.
- 잡음 적용 시 PPL 급증: ASR → 92.85, Semantic → 147.71, ASR+Semantic → 170.73.
- 텔레포니틱으로 fine‑tuning 후: ASR → 42.07(−43.76), Semantic → 45.11(−87.55), ASR+Semantic → 43.98(−101.25). 원본 테스트에서도 약간의 상승(+5~9)만 발생, 전반적인 성능 저하 없이 잡음에 대한 강건성을 크게 향상시켰다.
- 추가 분석: UMAP을 이용한 2‑D 임베딩 시, fine‑tuned 모델은 원본과 잡음 입력 사이의 평균 유클리드 거리가 감소해, 내부 표현이 잡음에 덜 민감함을 시각적으로 확인했다.
5. **의의 및 한계**
- 라벨링 비용이 전혀 들지 않는다. BERT, DeepSpeech, Tacotron 2, WaveGlow 등 공개 모델만으로 전 과정을 자동화할 수 있다.
- 문자‑레벨 모델 특성상 스펠링 오류와 같은 음성 잡음에 자연스럽게 대응한다.
- 의미 교체는 단순 동의어 교체를 넘어, ASR가 만든 비표준 형태를 의미적으로 보정하는 역할을 한다.
- 현재 실험은 PTB와 제한된 화자(7명)만 사용했으며, 대규모 실세계 음성 데이터(다양한 방언, 잡음 환경)에서의 일반화는 추가 검증이 필요하다. 또한, 현재는 명사·형용사 중심 샘플링이지만, 태스크에 따라 동사·부사 등 다른 품사에 대한 맞춤형 샘플링이 필요할 수 있다.
결론적으로, 텔레포니틱은 기존 텍스트‑기반 언어 모델을 음성 도메인에 손쉽게 전이시키는 효율적인 데이터 증강 전략이며, 문자‑레벨 모델과 마스크드 학습, 계층적 문법 샘플링을 결합함으로써 ASR·의미 잡음에 대한 강건성을 크게 개선한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기