Articulatory and bottleneck features for speaker-independent ASR of dysarthric speech
The rapid population aging has stimulated the development of assistive devices that provide personalized medical support to the needies suffering from various etiologies. One prominent clinical application is a computer-assisted speech training syste…
Authors: Emre Y{i}lmaz, Vikramjit Mitra, Ganesh Sivaraman
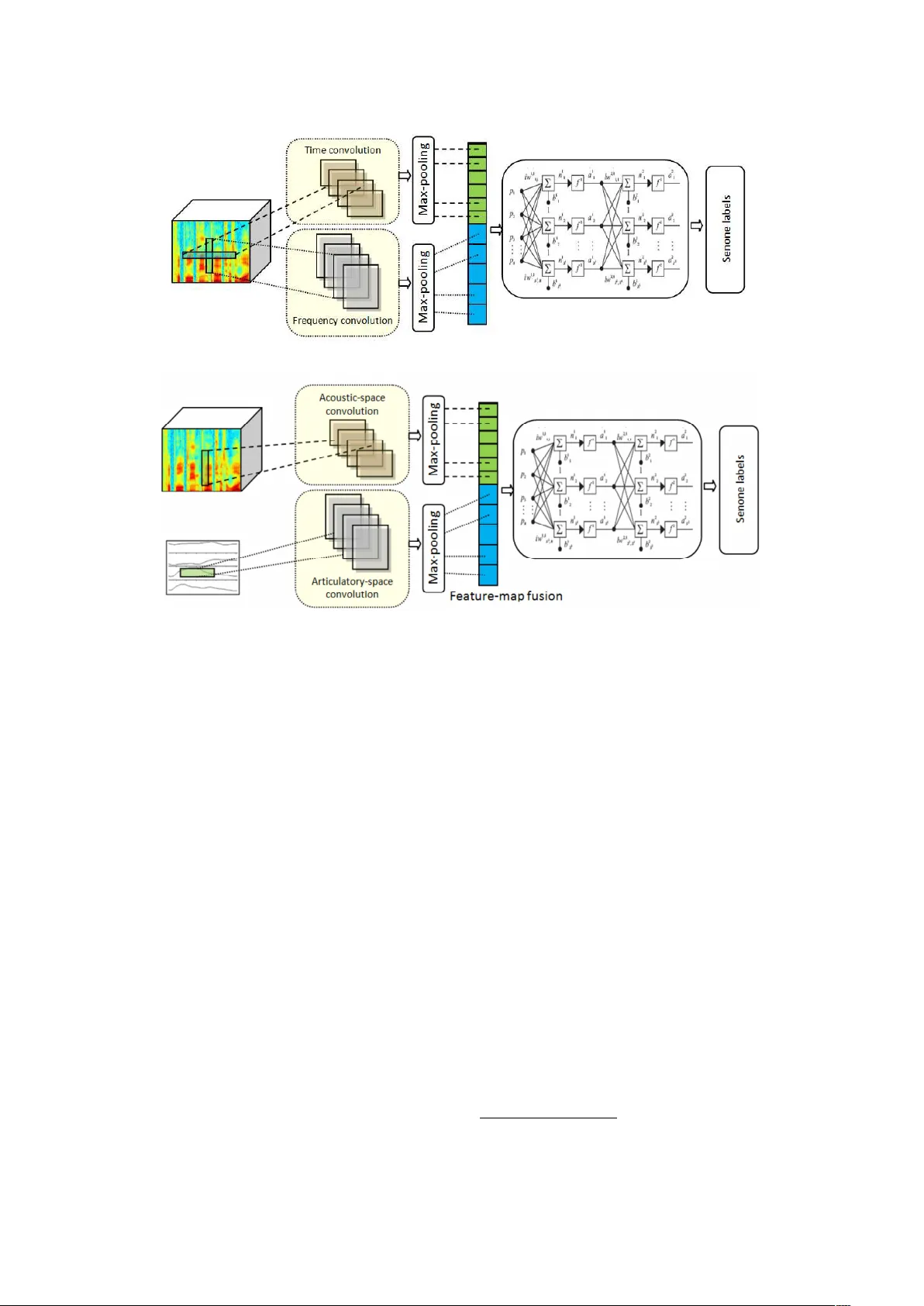
Articulatory and Bottlenec k F eatures for Sp eak er-Indep enden t ASR of Dysarthric Sp eec h Emre Yılmaz a,b, ∗ , Vikramjit Mitra c , Ganesh Siv araman d , Horacio F ranco e , a Dept. of Ele ctric al and Computer Engine ering, National University of Singap ore, Singap or e b CLS/CLST, R adb oud University, Nijme gen, Netherlands c University of Maryland, Col le ge Park, MD, USA d Pindr op, A tlanta, USA e ST AR L ab or atory, SRI International, Menlo Park, CA, USA Abstract The rapid p opulation aging has stim ulated the developmen t of assistive devices that provide personalized medical supp ort to the needies suffering from v arious etiologies. One prominen t clinical application is a computer-assisted sp eech training system which enables p ersonalized sp eec h therapy to patients impaired b y comm unicative disorders in the patient’s home en vironment. Suc h a system relies on the robust auto- matic sp eech recognition (ASR) technology to be able to pro vide accurate articulation feedback. With the long-term aim of developing off-the-shelf ASR systems that can be incorp orated in clinical context with- out prior speaker information, w e compare the ASR p erformance of sp eaker-independent b ottlenec k and articulatory features on dysarthric sp eec h used in conjunction with dedicated neural netw ork-based acoustic mo dels that ha ve been sho wn to b e robust against sp ectrotemporal deviations. W e rep ort ASR p erformance of these systems on t wo dysarthric speech datasets of differen t c haracteristics to quan tify the ac hiev ed perfor- mance gains. Despite the remaining p erformance gap b etw een the dysarthric and normal sp eec h, significan t impro vemen ts hav e b een rep orted on b oth datasets using sp eaker-independent ASR architectures. Keywor ds: pathological sp eec h, automatic sp eec h recognition, articulatory features, time-frequency con volutional neural netw orks, dysarthria 1. In tro duction Among the problems that are likely to b e as- so ciated with an increasingly ageing population w orldwide is a growing incidence of neurological disorders such as Parkinson’s disease (PD), cere- bral v ascular acciden t (CV A or stroke) and trau- matic brain injury (TBI). Possible consequences of suc h diseases are motor sp eech disorders including dysarthria caused by neuromuscular control prob- I The second author is curren tly working with Apple Inc. This research is funded b y the NW O Pro ject 314-99-101 (CHASING) and NWO Pro ject 314-99-119 (F risian Audio Mining En terprise). ∗ Corresponding author, tel. +65-9242-5322 Email addr esses: emre@nus.edu.sg (Emre Yılmaz), vmitra@umd.edu (Vikramjit Mitra), ganesa90@gmail.com (Ganesh Siv araman), horacio.franco@sri.com (Horacio F ranco) lems [1] which often lead to decreased sp eech intel- ligibilit y and comm unication impairmen t [2]. As a result, the life quality of dysarthric patients is neg- ativ ely affected [3] and they run the risk of losing con tact with friends and relativ es and even tually b ecoming isolated from the so ciety . Researc h has sho wn that in tensive therapy can b e effectiv e in (speech) motor rehabilitation [4, 5, 6, 7], but v arious factors conspire to make in tensive ther- ap y exp ensiv e and difficult to obtain. Recent dev el- opmen ts show that therapy can b e pro vided with- out resorting to frequent face-to-face sessions with therapists by employing computer-assisted sp eec h training systems [8]. According to the outcomes of the efficacy tests presented in [9], the user satisfac- tion app ears to b e quite high. Ho wev er, most of these systems are not yet capable of automatically assessing the articulation accuracy at the lev el of in- dividual speech sounds, whic h are known to ha v e an Pr eprint submitte d to Computer, Sp e ech & L anguage May 22, 2019 impact on sp eec h in telligibility [10, 11, 12, 13, 14]. In this w ork, we describ e our efforts to develop an ASR framew ork that is robust to v ariations in pathological sp eec h without relying on sp eak er information and can b e incorp orated in v arious clinical applications including p ersonalized sp eech therap y to ols. In particular, m ultiple sp eak er- indep enden t ASR arc hitectures are presented that are designated to perform robust ASR in the presence of sp ectrotemp oral deviations in speech. T raining robust acoustic mo dels to capture the within- and betw een-sp eak er v ariation in dysarthric sp eec h is generally not feasible due to the limited size and structure of existing pathological sp eec h databases. The num be r of recordings in dysarthric sp eec h databases is muc h smaller compared to that in normal sp eec h databases. Despite long-lasting efforts to build sp eak er- and text-indep endent ASR systems for people with dysarthria, the perfor- mance of state-of-the-art systems is still consider- ably low er on this type of sp eech than on normal sp eec h [15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25]. In previous work [26], w e describ ed a solution to train a b etter deep neural net work (DNN)-hidden Mark ov mo del (HMM) system for the Dutch lan- guage, a language that has fewer sp eak ers and re- sources compared to English. In particular, we in vestigated combining non-dysarthric sp eec h data from different v arieties of the Dutch language to train more reliable acoustic models for a DNN- HMM ASR system. This work w as conducted in the framework of the CHASING pro ject 1 , in whic h a serious game employing ASR is b eing de- v elop ed to pro vide additional speech therap y to dysarthric patients [27]. Moreo ver, w e created a 6-hour Dutch dysarthric sp eec h database that had b een collected in a previous pro ject (EST) [28] for training purp oses and inv estigate the impact of m ulti-stage DNN training (henceforth referred to as mo del adaptation) for pathological sp eech [29]. One wa y of addressing the c hallenges in tro duced due to dysarthria is to include additional several articulatory features (AF) whic h contain informa- tion ab out the shap e and dynamics of the v o cal tract given that such information has b een shown to b e directly related with the spectro-temp oral deviations in pathological speech ([30] and refer- ences therein). Using AFs together with acous- tic features has b een in vestigated and shown to 1 http://hstrik.ruhosting.nl/c hasing/ b e b eneficial in the ASR of normal sp eech, e.g. [31, 32, 33, 34, 35, 36]. A subset of these ap- proac hes learn a mapping betw een acoustic and ar- ticulatory spaces for the sp eech inv ersion, and use the learned articulatory information in an ASR sys- tem for impro v ed represen tation of sp eec h in a high- dimensional feature space. Rudzicz [37] tried us- ing discrete AF together with conv en tional acous- tic features for phone classification experiments on dysarthric sp eec h. More recen tly , [38] has prop osed the use of con volutional neural net works (CNN) for learning sp eak er indep enden t articulatory mo dels for map- ping acoustic features to the corresp onding artic- ulatory space. Later, a nov el acoustic mo del is designed to integrate the AF together with the acoustic features [39]. Motiv ated by the success of these system s, w e ha ve inv estigated the joint use of articulatory and acoustic features for the sp eak er-indep enden t ASR of pathological sp eech and rep orted promising initial results [40]. Sp ecif- ically , the use of v o cal tract constriction v ariables (TVs) and mel filterbank features as input to fused- feature-map CNN (fCNN) acoustic mo dels [39] has b een compared with other deep and (frequency and time-frequency) conv olutional neural net work ar- c hitectures [41]. In this pap er, w e firstly explore the use of gam- matone by comparing the ASR p erformance to the con ven tional mel filterbank features in the con- text of dysarthric sp eech recognition. The gam- matone filters can capture fine-resolution c hanges in the sp ectra and are closer to the auditory filter- banks formulated through p erceptual studies com- pared to the mel filters. In this sense, the mel fil- ters can b e considered as an appro ximation of the gammatone filters. Moreo v er, we extend our previ- ous work [40] b y concatenating articulatory features with gammatone filterbank acoustic features using sp eec h inv ersion systems trained on b oth synthetic and real speech. It is vital to note that the type of articulatory features used in this work is nov el, as prior w ork fo cuses on discrete articulatory fea- tures, whereas the articulatory features in this w ork are con tinuous and represent vocal tract kinemat- ics. The rationale b ehind using these articulatory represen tations is to capture the sp eech production space which helps to account for an y v ariabilit y ob- serv ed in the acoustic space, hence making the fea- ture com bination robust. T o the b est of authors’ kno wledge, this is the first w ork to explore articula- tory features, which are estimated using sp eec h in- 2 v ersion models trained on synthetic and real sp eech, in v arious capacities for dysarthric speech recog- nition. Similar articulatory representations hav e b een used successfully before to accoun t for acous- tic v ariations such as coarticulation and non-native sp eec h [39] and noise and c hannel v ariations [38]. Another effectiv e w a y of represen ting speech is ac hieved by using b ottlenec k features extracted from a bottleneck la y er which can b e considered a fixed dimensional non-linear transformation which giv es a stable representation of the sub-word unit subspace given acoustics. Suc h representations ha ve b een found to be useful in low-resourced lan- guage scenarios in which it is not viable to accu- rately represent the complete phoneme space due to data scarcit y . The target lo w-resourced language b enefits from additional speech data from other high-resourced languages p ossibly sharing similar acoustic units [42]. In case of dysarthric speech, using b ottlenec k features has b een shown to miti- gate the effect of the increased v ariations observed as a result of po or articulation skills thanks to their disorder inv ariant characteristics [43, 23]. In this w ork, we extend this analysis to (1) the nov el time- frequency conv olutional neural netw ork (TFCNN) framew ork aiming to obtain impro ved b ottlenec k represen tation of dysarthric sp eec h and (2) inv es- tigate the impact of applying the mo del adapta- tion technique describ ed in Section 4.3 at differen t stages aiming to disco ver the systems providing b ot- tlenec k features with increased robustness against the v ariations in pathological sp eec h. A list of the contributions of this submission is giv en b elo w for clarity: 1. A comparison of the use of gammatone and mel filterbank features is given in the context of dysarthric sp eec h recognition. 2. W e inv estigate the use of con tinuous articu- latory features representing v ocal tract kine- matics by concatenating them with acoustic features where the sp eech inv ersion system is trained using syn thetic and real sp eec h. 3. The ASR p erformance of the bottleneck fea- tures extracted using the designated conv olu- tional NN models is explored b y jointly learn- ing the b ottleneck la yers and feature map fu- sion. 4. F or the scenario with training dysarthric sp eec h data, the impact of mo del adaptation is explored on b oth acoustic mo dels and bot- tlenec k extraction schemes. This pap er is organized as follows. Section 2 summarizes some previous literature on the ASR of dysarthric speech. Section 3 details the sp eech corp ora used in this w ork b y providing some in- formation ab out the sp eak ers for each dysarthric sp eec h database. Prop osed speaker-independent ASR schemes are describ ed in Section 4. The ex- p erimen tal setup is describ ed in Section 5, and the recognition results are presen ted in Section 6. A general discussion is given in Section 7 before con- cluding the pap er in Section 8. 2. Related w ork There ha ve b een numerous efforts to build ASR systems op erating on pathological sp eec h. Lee et al. [24] has rep orted the ASR p erformance on Can tonese aphasic speech and disordered voice. A DNN-HMM system pro vided significan t impro ve- men ts on disordered v oice and minor impro vemen ts on aphasic sp eec h compared to a GMM-HMM sys- tem. T ak ashima et al. [23] prop osed a feature extraction scheme using con volutional bottleneck net works for dysarthric sp eec h recognition. They tested the prop osed approach on a small test set consisting of 3 rep etitions of 216 words b y a sin- gle male sp eak er with an articulation disorder and rep orted some gains ov er a system using MFCC features. In a recent w ork, Kim et al. [45] in- v estigated con volutional long short-term memory (LSTM) net works dysarhtric sp eec h from 9 speak- ers. They rep orted improv ed ASR accuracies com- pared to CNN- and LSTM-based acoustic mo dels. Shahamiri and Salim [22] prop osed an artificial neural net w ork-based system trained on digit utter- ances from nine non-dysarthric and 13 dysarthric individuals affected by Cerebral Palsy (CP). Chris- tensen et al. [21] trained their mo dels solely on 18 hours of sp eech of 15 dysarthric sp eak ers due to CP lea ving one sp eaker out as test set. Rudzicz [17] compared the p erformance of a sp eak er-dep enden t and a sp eak er-adaptiv e GMM-HMM systems on the Nemours database [46]. Later, Rudzicz [37] tried using AF together with conv en tional acous- tic features for phone classification experiments on dysarh tric sp eec h. Mengistu and Rudzicz [19] com- bined dysarthric data of eigh t dysarthric sp eakers with that of seven normal sp eakers, leaving one out as test set and obtained an av erage increase b y 13.0% in comparison to models trained on non- dysarthric sp eec h only . In another w ork [47], they 3 T able 1: Summary of the sp eec h resources used in the ASR exp erimen ts (h:hours, m:minutes) Sp eec h database T yp e T rain T est CGN Dutc h Normal 255h - CGN Flemish Normal 186h 30m - EST Dutc h [28] Dysarthric 4h 47m - CHASING01 Dutc h [29] Dysarthric - 55m COP AS Flemish [44] Dysarthric - 1h 30m COP AS Flemish [44] Normal (Control) - 1h compared the recognition p erformance of n¨ aiv e hu- man listener and ASR systems. In one of the earliest work on Dutch pathological sp eec h b y Sanders et al. [15], a pilot study was pre- sen ted on ASR of Dutc h dysarthric sp eech data ob- tained from tw o sp eak ers with a birth defect and a cerebro v ascular accident. Both sp eak ers w ere clas- sified as mild dysarthric b y a sp eech pathologist. Seong et al. [20] prop osed a weigh ted finite state transducer (WSFT)-based ASR correction tech- nique applied to an ASR system trained. Similar w ork had b een prop osed by Caballero-Morales and Co x [18] previously . In the scop e of the CHASING Pro ject, we ha ve b een developing a serious game emplo ying ASR to pro vide additional sp eech therap y to dysarthric pa- tien ts [14, 27]. Earlier researc h in this pro ject is rep orted in [26] and [29] in whic h we fo cus on in- v estigating the a v ailable resources by using sp eec h data from different v arieties of the Dutch language and inv estigate model adaptation to tune an acous- tic mo del using a small amoun t of dysarthric speech for training purp oses resp ectively . In general, it is difficult to compare results be- t ween these publications due to the differences in t yp es of sp eec h materials, types of dysarthria, re- p orted sev erity , and datasets used for training and testing. Additionally , dysarthric speech is highly v ariable in nature, not only due to its v arious eti- ologies and degrees of severit y , but also b ecause of p ossible individually deviating sp eech characteris- tics. This ma y negatively influence the capability of speaker-independent systems to generalize ov er m ultiple dysarthric sp eak ers. 3. Speech corp ora selection W e use Dutc h and Flemish dysarthric speech cor- p ora for inv estigating the effectiveness of different ASR systems. The details of the sp eech data used in this work are presented in T able 1. There are t wo dysarthric speech corp ora av ailable in Dutc h, namely EST [28] and CHASING01 [29], which are used for training and testing purp oses resp ectiv ely . F or Flemish, we only ha ve the COP AS corpus [44] whic h has enough speech data for testing only . Giv en the limited av ailability of dysarthric sp eec h data, w e also use already existing databases of nor- mal Dutc h and Flemish sp eec h to train acoustic mo dels. In the following paragraphs, we detail the normal and dysarthric sp eech corp ora used in this w ork. There hav e b een m ultiple Dutc h-Flemish speech data collection efforts [48, 49] which facilitate the in tegration of b oth Dutch and Flemish data in the present researc h. F or training purp oses, w e used the Corpus Gespr oken Ne derlands (CGN) cor- pus [48], which contains representativ e collections of con temp orary standard Dutch as sp ok en by adults in the Netherlands and Flanders. The CGN comp onen ts with read sp eec h, sp on taneous con- v ersations, interviews and discussions are used for acoustic mo del training. The duration of the nor- mal Flemish (VL) and northern Dutc h (NL) sp eec h data used for training is 186.5 and 255 hours, re- sp ectiv ely . The EST Dutch dysarthric sp eec h database con- tains dysarthric sp eec h from ten patien ts with P arkinson’s Disease (PD), four patients who hav e had a Cerebral V ascular Accident (CV A), one pa- tien t who suffered T raumatic Brain Injury (TBI) and one patien t having dysarthria due to a birth defect. Based on the meta-information, the age of the sp eakers is in the range of 34 to 75 years with a median of 66.5 years. The level of dysarthria v aries from mild to mo derate. The dysarthric sp eech collection for this database w as achiev ed in several exp erimen tal contexts. The sp eec h tasks presented to the patien ts in these con- texts consist of numerous word and sentence lists with v arying linguistic complexit y . The database includes 12 Seman tically Unpredictable Sentences 4 (SUSs) with 6- and 13-word declarative sen tences, 12 6-word in terrogative sen tences, 13 Plomp and Mimp en sentences, 5 short texts, 30 sentences with /t/, /p/ and /k/ in initial p osition and unstressed syllable, 15 sentences with /a/, /e/ and /o/ in un- stressed syllables, production of 3 individual v ow- els /a/, /e/ and /o/, 15 bisyllabic words with /t/, /p/ and /k/ in initial position and unstressed sylla- ble and 25 words with alternating vo w el-consonant comp osition (CVC, CVCV CC, etc.). The EST database contains 6 hours and 16 min- utes of dysarthric sp eec h material from 16 sp eak- ers [28]. The sp eech segments with pronunciation error marks indicating what is said by the speaker either (1) obviously differs from the reference tran- scription or (2) is unintelligible, w ere excluded from the training set to ensure a high degree of transcrip- tion quality . Additionally , the segments including a single word and pseudow ord w ere also excluded, since the sen tence reading tasks are more relev an t in this scenario. The total duration of the dysarthric sp eec h data ev en tually selected for training is 4 hours and 47 min utes. F or testing purposes , w e firstly use the sen tence reading tasks of the CHASING01 Dutch dysarthric sp eec h database. This database con tains sp eec h of 5 patien ts who participated in sp eec h training exp erimen ts and w ere tested at 6 different times during the treatment. F or eac h set of audio files, the following material was collected: 12 SUSs, 30 /p/, /t/, /k/ sentences in whic h the first syllable of the last word is unstressed and starts with /p/, /t/ or /k/, 15 v ow el sentences with the vo w els /a/,/e/ and /o/ in stressed syllables, appeltaarttekst ( ap- ple c ake r e cip e ) in 5 parts. Utterances that deviated from the reference text due to pronunciation errors (e.g. restarts, repeats, hesitations, etc.) w ere re- mo ved. After this subselection, the utterances from 3 male patients remained and were included in the test set. These speakers are 67, 62 and 59 y ears old, t wo of them ha ving PD and the third having had a CV A. This database contains 721 utterances (in total 6231 words) sp oken by 3 dysarthric speakers with a total duration of 55 min utes. All sentence reading tasks with annotations from the Flemish COP AS pathological sp eech corpus, namely 2 isolated sen tence reading tasks, 11 text passages with reading level difficulty of A VI 7 and 8 and T ext Marlo es, are also included as a second test set. The COP AS corpus contains recordings from 122 Flemish normal sp eakers and 197 Flemish sp eak ers with sp eech disorders such as dysarthria, cleft, v oice disorders, laryngectom y and glossec- tom y . The dysarthric sp eec h comp onen t con tains recordings from 75 Flemish patients affected b y P arkinson’s disease, traumatic brain injury , cere- bro v ascular acciden t and multiple sclerosis who ex- hibit dysarthria at different lev els of severit y . Con- taining more speakers with more diverse etiolo- gies, p erforming ASR on this corpus is found to more challenging compared to the CHASING01 dysarthric speech database (c.f. the ASR results in [26, 29, 40]). 212 different sentence tasks from the COP AS database are included in the exp eri- men ts which are uttered b y 103 dysarthric and 82 normal sp eakers. The sentence tasks uttered in the Flemish corpus b y normal sp eak ers (Sen tNor) and sp eak ers with disorders (SentDys) consists of 1918 (15,149) and 1034 (8287) sen tences (w ords) with a total duration of 1.5 and 1 hour, resp ectiv ely . 4. Speaker-independent ASR Sc hemes for dysarthric sp eec h 4.1. A c oustic mo dels In the scop e of this work, w e ha ve trained sev- eral NN-based acoustic mo dels to inv estigate their p erformance on dysarthric sp eec h using different sp eak er-indep enden t features. Standard DNN and CNN mo dels trained on mel- and gammatone fil- terbanks are compared with no vel NN architec- tures such as time-frequency con volutional nets (TF CNN) and a fused-feature-map conv olutional neural netw ork (fCNN) which are detailed in the follo wing paragraphs. Time-frequency con volutional nets (TF CNN) are a suitable candidate for the acoustic mo deling of dysarthric sp eec h. As depicted in Figure 1a, TF CNN is a mo dified con v olution netw ork in whic h tw o parallel lay ers of conv olution filters op- erate on the input feature space: one across time (time-con volution) and the other across frequency (frequency-con volution). The feature maps from these tw o conv olution lay ers are fused and then fed to a fully connected deep neural net work. P er- forming con v olution both on time and frequency axes, they exhibit increased robustness against the spectrotemp oral deviations due to background noise [41]. The acoustic and articulatory (concatenated) fea- tures are fed to a fCNN which is illustrated in Fig- ure 1b. This arc hitecture uses tw o t ypes of con v olu- tional lay ers. The first conv olutional lay er op erates 5 Acoustic features (a) A time-frequency conv olutional neural netw ork (TFCNN) [41] Acoustic features Articulatory features (b) A fused-feature-map conv olutional neural netw ork (fCNN) [39] Figure 1: Designated conv olutional neural netw ork architectures with increased robustness against sp ectrotemporal deviations on the acoustic features, whic h are the filterbank energy features, and performs conv olution across frequency . The other conv olutional lay er op erates on AFs, which are the TV tra jectories, and p er- forms conv olution across time. The output of the max-p ooling lay ers are fed to a single NN after p er- forming feature-map fusion. AFs are used only in conjunction with the fCNN mo dels, as the other NN arc hitectures are found to pro vide w orse recognition p erformance using the concatenated features [39]. 4.2. Extr acting articulatory fe atur es The task of estimating the articulatory tra jecto- ries (in this case, the v o cal tract constriction v ari- ables (TVs)) from the sp eec h signal is commonly kno wn as speech-to-articulatory in v ersion or simply sp eec h-in version. TVs [50, 51] are contin uous time functions that sp ecify the shap e of the v o cal tract in terms of constriction degree and lo cation of the constrictors. During speech-in v ersion, the acoustic features extracted from the sp eec h signal are used to predict the articulatory tra jectories, where the in verse mapping is learned by using a parallel cor- pus con taining acoustic and articulatory pairs. The task of sp eec h-in version is a well-kno wn, ill-p osed in verse transform problem, which suffers from b oth the non-linearit y and non-unique nature of the in- v erse transform [52, 53]. The articulatory dataset used to train the sp eech- in version systems consists of synthetic sp eec h with sim ultaneous tract v ariable tra jectories. W e used the Haskins Lab oratories’ T ask Dynamic mo del (T AD A) [54] along with HLsyn [55] to generate a syn thetic English isolated w ord speech corpus along with TVs. The English words and their pronuncia- tion w ere selected from the CMU dictionary 2 . Al- together 534 322 audio samples w ere generated (ap- pro ximately 450 h of speech), out of whic h 88% of the data was used as the training set, 2% was used as the cross-v alidation set, and the remaining 10% w as used as the test set. W e further added four- teen different noise types (suc h as babble, factory noise, traffic noise, high w ay noise, cro wd noise, etc.) to eac h of the syn thetic acoustic wa v eforms with a signal-to-noise ratio (SNR) b et ween 10 and 80 dB. Multi-condition training of the sp eec h-in version 2 http://www.speech.cs.cm u.edu/cgi-bin/cm udict 6 Bottleneck e xtractor Bottleneck featur es Trainin g data Adaptation data Bottleneck featur es Bottleneck featur es (a) (b) (c) Bottleneck featur es Acoustic model Bottleneck e xtractor Figure 2: Differen t b ottlenec k extractor and acoustic model training strategies - (a) T raining b oth the b ottleneck extractor and acoustic model using dysarthric sp eech, (b) T raining the bottleneck extractor using normal sp eec h, the acoustic model using dysarthric sp eec h and optionally adapting the b ottleneck extractor using dysarthric sp eech and (c) T raining b oth the bottleneck extractor and acoustic mo del using normal sp eec h and optionally adapting both using dysarthric sp eec h. system has b een sho wn to considerably improv e the TV estimation accuracy under noisy scenar- ios, while providing comparable estimation accu- racy to a system trained only using clean data [39]. W e combined this noise-added data with the clean data, and the resulting com bined dataset is used for training a CNN-based sp eec h in version system. F or further details, w e refer the reader to [38]. In this work, we use speech subband amplitude mo dulation features suc h as normalized mo dulation co efficien ts (NMCs) [56]. NMCs are noise-robust acoustic features obtained from tracking the ampli- tude mo dulations (AM) of filtered subband sp eech signals in the time domain. The features are Z- normalized b efore b eing used to train the CNN mo dels. F urther, the input features are contextu- alized b y splicing m ultiple frames. Given the lin- guistic similarit y betw een English and Dutc h, we assume that the speech inv ersion model trained on English speech would giv e a reasonably ac- curate acoustic-to-articulatory mapping in Dutch. F or a detailed comparison of the articulatory set- ting in Dutc h and English, please see Section 21 of [57]. Siv araman et al. quantifies the perfor- mance of sp eec h inv ersion under matc hed accen t, mismatc hed accent, and mismatched language sce- nario for these t wo languages in [58]. Apart from the TVs derived from the sp eech in- v ersion system trained on the synthetic dataset, w e also exp erimen ted with TVs estimated from a sp eec h inv ersion system trained on real sp eec h and articulatory data. The real sp eec h in version sys- tem w as trained on the Wisconsin X-ray microb eam dataset (XRMB) [59]. The pellet tra jectories in the m ulti-sp eak er XRMB dataset was conv erted to six TVs using the metho d outlined in [60]. The six TVs were - lip ap erture, lip protrusion, tongue b ody constriction lo cation, and tongue b o dy constriction degree, tongue tip constriction location, and tongue tip constriction degree. The XRMB data contained 46 sp eakers, out of which 36 were used for training and 5 eac h for cross v alidation and testing. 4.3. Bottlene ck fe atur es and mo del adaptation Differen t b ottleneck extractor and acoustic mo del training strategies in v estigated in this w ork hav e b een visualized in Figure 2. During these exp eri- men ts, the DNN, CNN and TFCNN architectures describ ed in Section 4.1 are used for bottleneck extraction and acoustic mo deling to compare the p erformance using the filterbank and articulatory features. Bottleneck extractor and acoustic mo del training has b een p erformed by: (1) training a NN with a b ottleneck lay er, (2) extracting the b ottle- nec k features at the output of the b ottleneck lay er b y passing the input sp eech features to the trained NN and (3) training a second NN using the b ot- tlenec k features as the input. The NN obtained in the third stage is used as the acoustic mo del for the recognition task. After obtaining the acoustic mo dels and b ottle- nec k systems, w e optionally apply mo del adapta- tion as describ ed in [29] in explore the p erformance gains that can b e obtained when using different b ot- tlenec k feature strategies. The idea b ehind such adaptation is similar to [61, 62]. In these studies, 7 considerable improv emen ts hav e b een rep orted on b oth low- and high-resourced languages on accoun t of the hidden lay ers first trained on multiple lan- guages and then adapted to the target language. Mo del adaptation is ac hieved b y initializing the hid- den lay ers using the NN mo del obtained in the first stage and retraining the mo del by p erforming ex- tra forw ard-backw ard passes only using the av ail- able dysarthric training data with a considerably smaller learning rate compared to the one used in the first stage. The aim of this step is to tune the mo dels on dysarthric sp eec h as this is the type of sp eec h to b e recognized. In previous work [29], we hav e inv estigated mul- tiple NN h yp erparameters that may influence the accuracy of the final mo del, suc h as the n umber of retrained la yers and the learning rate. More- o ver, v arious types of sp eec h data hav e b een used to explore their impact on the mo deling accuracy of the adapted mo dels including accented, elderly and dysarthric sp eec h. The b est ASR p erformance has b een obtained using only dysarthric sp eec h in the adaptation stage. Therefore, we only use the training dysarthric speech whic h is only av ailable for Dutch language in the mo del adaptation phase. 5. Experimental setup 5.1. Implementation details W e use CNNs for training sp eec h inv ersion mo d- els, where con textualized (spliced) acoustic features in the form of NMCs are used as input, and the TV tra jectories w ere used as the targets. The net work parameters and the splicing windo w w ere optimized b y using a held-out developmen t set. The conv olu- tion lay er of the CNN had 200 filters, where max- p ooling was p erformed ov er three samples. The CNN has three fully connected hidden lay ers with 2048 neurons in each lay er. The hidden lay ers hav e sigmoid activ ation functions, whereas the output la yer has linear activ ation. The CNN is trained with sto chastic gradien t descent with early stop- ping based on the cross-v alidation error. The CNN h yp erparameters are optimized by using a held-out dev elopment set. Pearson’s pro duct-momen t cor- relation coefficient b etw een the actual or ground truth and the av erage of all estimated articula- tory tra jectories are used to quan tify the estima- tion quality . The splicing window is also optimized and a splicing size of 71 frames (355 ms of sp eec h information) has b een found to b e a go od choice. F or ASR experiments, a con ven tional con text de- p enden t GMM-HMM system with 40k Gaussians w as trained on the 39-dimensional MFCC features including the deltas and delta-deltas. W e also trained a GMM-HMM system on the LD A-MLL T features, follow ed b y training mo dels with speaker adaptiv e training using FMLLR features. This sys- tem was used to obtain the state alignments re- quired for NN training. Each training set given in T able 1 has b een aligned using a GMM-HMM sys- tem trained on the same set to maximize the align- men t accuracy . The input features to the ac ous- tic mo dels are formed by using a con text windo w of 17 frames (8 frames on either side of the cur- ren t frame). A trigram language mo del trained on the target transcriptions of the sen tence tasks w as used during recognition of the sen tence tasks. This choice is motiv ated b y the final goal of build- ing speaker- and task-independent ASR systems, as using finite state grammars would hinder the scal- abilit y of these systems to ASR tasks with larger v o cabulary . The acoustic mo dels were trained by using cross- en tropy on the alignments from the GMM-HMM system. The 40-dimensional log-mel filterbank (FB) features with the deltas and delta-deltas are used as acoustic features whic h are extracted us- ing the Kaldi [63] to olkit. The NN mo dels are implemen ted in Theano. The NNs trained on dysarthric Dutc h training data has 4 hidden lay- ers with 1024 no des p er hidden lay er and an out- put la y er with 5182 con text-dependent (CD) states. The NNs trained on normal Dutch and Flemish data has 6 hidden lay ers, with 2048 no des p er hid- den la yer and an output lay er with 5792 and 5925 CD states. These hyperparameters are chosen in the earlier stage of our previous work [40] based on the p erformance of the baseline system. The net- w orks were trained by using an initial four iterations with a constant learning rate of 0.008, follow ed b y learning-rate halving based on cross v alidation error decrease. T raining stopp ed when no further signif- ican t reduction in cross-v alidation error was noted or when cross-v alidation error started to increase. Bac k-propagation was performed using sto c hastic gradien t descen t with a mini-batch of 256 training examples. The 60-dimensional b ottlenec k features are extracted the third lay er for all neural net w ork arc hitectures. All ASR systems use the Kaldi de- co der. The mo del adaptation uses the parameters learned in the first training stage to initialize the 8 neural net and the adaptation data is used for train- ing with an initial learning rate of 0.001. Using a smaller initial learning rate pro vided consistently impro ved results in [40] for adapting different n um- b er of hidden lay ers. The learning rate is gradually reduced according to the regime described in the previous paragraph. The minimum and maximum n umber of ep o c hs for the adaptation is 3 and 10 resp ectiv ely . The same early stopping criterion is adopted during the mo del adaptation as the stan- dard training. F or CNN acoustic mo dels, the acoustic space is learned using a 200 conv olutional filters of size 8 w ere used in the conv olutional lay er, and the max- p ooling size was set to 3 without ov erlap. The TF CNN mo del uses 75 filters to p erform time con- v olution, and 200 filters to p erform frequency con- v olution. A max-p o oling ov er three and five sam- ples are used for frequency and time con volution, resp ectiv ely . The feature maps after b oth the con- v olution operations w ere concatenated and then fed to a fully connected neural net. The fCNN system uses a time-frequency con volution la yer to learn the acoustic space with tw o separate con volution filters op erating on the input acoustic features. These t wo con volution lay ers are iden tical to the ones used in the TF CNN model. The articulatory space is learned b y using a time-con volution lay er that con- tains 75 filters, follo wed by max-p o oling o v er 5 sam- ples. The real AF features are extracted using a 3 hid- den lay er feed-forw ard DNN trained to map con- textualized MF CC features to TVs as described in [64, 65]. Since the articulatory tra jectories esti- mated by the DNN w ere noisy , a Kalman smo oth- ing based lowpass filter was used to smo othen the DNN estimates. The av erage correlation b etw een estimated and actual TVs on the XRMB held out test set was 0.787 [64]. This sp eech in version sys- tem trained on XRMB dataset w as used to estimate the TVs for an y utterances. 5.2. ASR exp eriments W e in vestigate tw o different training conditions, namely with and without dysarthric training data. F or the Dutch database, the ASR system is ei- ther trained on normal or dysarthric Dutch sp eec h. T raining on com bination of these databases has yielded very similar results to the system trained only the normal Dutch data in the pilot exp eri- men ts. Therefore, we do not consider this training T able 2: W ord error rates in % obtained on the Dutch test set using different acoustic mo dels with mel (MFB) and gam- matone (GFB) filterbank features AM T rain. Data WER (%) MFB GFB DNN Dys. NL 22.9 22.0 CNN Dys. NL 21.1 18.8 TF CNN Dys. NL 20.3 18.2 DNN Nor. NL 15.0 17.1 CNN Nor. NL 14.9 15.8 TF CNN Nor. NL 14.1 15.9 setup in this pap er. W e further explore model adap- tation in this scenario using the dysarthric training data. F or Flemish test data, w e use normal Flemish and Dutc h sp eec h due to lac k of dysarthric training ma- terial in this language v ariety . In the first setting, w e only use normal Flemish sp eech to train acous- tic mo dels, while b oth normal Flemish and Dutch sp eec h is used in the second setting motiv ated by the impro vemen ts rep orted in [28]. The recognition p erformance of all ASR systems is quantified using the W ord Error Rate (WER). 6. Results In this section, we presen t the results of the ASR exp erimen ts performed using the acoustic mo dels in Section 4.1 trained on several sp eak er-indep enden t features suc h as gammatone filterbanks, articula- tory features and b ottlenec k features. Later, w e apply the mo del adaptation approach we describ ed in [29] to explore the further gains that can b e ob- tained using a small amount of training dysarthric data. The baseline systems use DNN, CNN and TF CNN mo dels trained on mel filterbank features and FCNN mo dels trained using the concatenation of mel filterbank features and synthetic AFs. The details are giv en in [40]. 6.1. Sp e aker-indep endent fe atur es 6.1.1. Gammatone filterb ank fe atur es The ASR results obtained on the Dutch test set using mel (MFB) and gammatone (GFB) filterbank features are presen ted in T able 2. The WERs pro- vided by differen t acoustic models trained on the dysarthric Dutch sp eec h are giv en in the upp er panel of this table. The b est ASR p erformance of eac h panel is mark ed in b old. Using a small amoun t 9 T able 3: W ord error rates in % obtained on the Flemish test sets using differen t acoustic models with MFB and GFB features AM T rain. Data Sen tDys Sen tNor MFB GFB MFB GFB DNN Nor. VL 36.4 28.6 6.0 4.5 CNN Nor. VL 33.5 27.2 5.3 4.1 TF CNN Nor. VL 33.8 27.0 5.3 4.2 DNN Nor. VL+NL 32.1 25.5 5.5 4.3 CNN Nor. VL+NL 30.1 24.7 4.9 4.2 TF CNN Nor. VL+NL 30.1 25.0 4.9 4.1 T able 4: W ord error rates in % obtained on the Dutch test set using different acoustic models with synthetic and real articulatory features AM F eatures T rain. Data WER (%) CNN GFB Dys. NL 18.8 TF CNN GFB Dys. NL 18.2 F CNN GFB+synAF Dys. NL 16.7 F CNN GFB+realAF Dys. NL 16.7 CNN GFB Nor. NL 15.8 TF CNN GFB Nor. NL 15.9 F CNN GFB+synAF Nor. NL 15.8 F CNN GFB+realAF Nor. NL 16.3 of in-domain training data, the GFB features pro- vide b etter ASR accuracy . The b est-p erforming AM is the TF CNN with a WER of 18.2%. The lo wer panel has the WERs provided b y different sys- tems trained on normal Dutc h speech. In this sce- nario, b oth MFB and GFB features provide lo wer WERs than the previous training setting, where the b est WER is 14.1% pro vided b y the TFCNN system trained using MFB features. T able 3 presents the results on the more chal- lenging Flemish test set. In this scenario, the sys- tems using GFB p erforms consistently b etter than the systems using MFB. Adding the Dutc h data brings further impro vemen ts in the recognition of this language v ariet y whic h is consistent with pre- vious results [40, 29]. Motiv ated b y the sup erior p erformance in this scenario, the GFB features are used as the standard sp eech features in the rest of the exp erimen ts. 6.1.2. A rticulatory fe atur es The ASR p erformance of the F CNN-based ASR systems jointly using AFs and GFB are presented in T able 4 and T able 5. As detailed in Section 4.2, the AFs are extracted using sp eech inv ersion T able 5: W ord error rates in % obtained on the Flemish test sets using different acoustic models with synthetic and real articulatory features AM F eatures T rain. Data SentDys SentNor CNN GFB Nor. VL 27.2 4.1 TF CNN GFB Nor. VL 27.0 4.2 F CNN GFB+synAF Nor. NL 27.5 4.2 F CNN GFB+realAF Nor. NL 28.0 4.2 CNN GFB Nor. VL+NL 24.7 4.2 TF CNN GFB Nor. VL+NL 25.0 4.1 F CNN GFB+synAF Nor. VL+NL 25.0 4.0 F CNN GFB+realAF Nor. VL+NL 25.0 4.3 T able 6: W ord error rates in % obtained on the Dutch test set using different acoustic mo dels with b ottlenec k features T rain. BN T rain. AM DNN CNN TFCNN Dys. NL Dys. NL 15.4 17.1 16.7 Dys. NL Nor. NL 22.8 18.7 19.1 Nor. NL Dys. NL 12.9 13.8 12.0 Nor. NL Nor. NL 21.9 17.6 19.6 systems trained on synthetic and real sp eec h. W e refer to these features as synAF and realAF re- sp ectiv ely . Compared to the GFB systems trained on the Dutc h dysarthric training data, using AFs pro vides impro v ed results with a WER of 16.7%. T raining the sp eech inv ersion system on synthetic or real sp eec h has no significant impact on the recognition p erformance. A similar observ ation has b een made on normal English sp eech in [64]. Despite the gains obtained in the systems trained on Dutc h dysarthric speech, app ending b oth synAF and realAF to GFB features of normal Dutc h and Flemish training sp eec h (cf. low er panel of T able 4 and b oth panels of T able 5) do es not improv e the recognition accuracy compared to using the GFB features only . On the Flemish test set, all ASR systems trained on the Dutch and Flemish training data provide a WER in the range of 24.7% - 25.0% as shown in the lo wer panel of T able 5. The p er- formance obtained on the control utterances sp oken b y the normal speakers follow a similar pattern with WERs in the range of 4.0% - 4.3%. 6.1.3. Bottlene ck fe atur es The ASR results obtained using the b ottlenec k features on the Dutch and Flemish test sets are giv en in T able 6 and T able 7 resp ectively . W e in- v estigate different training scenarios for the b ottle- nec k extractor and the acoustic mo del trained on 10 T able 7: W ord error rates in % obtained on the Flemish test set using different acoustic mo dels with b ottlenec k features T rain. BN T rain. AM DNN CNN TF CNN Sen tDys SentNor Sen tDys SentNor Sen tDys SentNor Nor. VL Nor. VL 29.9 5.4 30.0 4.8 30.2 4.8 Nor. VL Nor. VL+NL 28.4 5.3 27.7 4.9 27.5 4.6 Nor. VL+NL Nor. VL 29.1 5.0 29.5 5.3 29.4 5.4 Nor. VL+NL Nor. VL+NL 28.4 5.2 28.5 5.4 28.0 4.8 T able 8: W ord error rates in % obtained on the Dutch test set using adapted acoustic mo dels trained on gammatone filterbank features T rain. AM Adapt. AM DNN CNN TFCNN sF CNN rFCNN Nor. NL - 17.1 15.8 15.9 15.8 16.3 Nor. NL Dys. NL 12.6 11.3 11.2 10.6 10.3 T able 9: W ord error rates in % obtained on the Dutch test set by applying mo del adaptation at bottleneck extraction and acoustic mo deling stages T rain. BN Adapt. BN T rain. AM Adapt. AM DNN CNN TFCNN Nor. NL - Dys. NL - 12.9 13.8 12.0 Nor. NL Dys. NL Dys. NL - 11.8 13.1 13.4 Nor. NL - Nor. NL - 21.9 17.6 19.6 Nor. NL Dys. NL Nor. NL - 21.0 15.2 15.5 Nor. NL - Nor. NL Dys. NL 11.8 10.4 10.3 Nor. NL Dys. NL Nor. NL Dys. NL 11.0 10.2 10.0 the corresp onding bottleneck features using b oth normal and dysarthric Dutc h training data to ex- plore which training scheme provide the b est ASR p erformance. With a significantly large margin, the setting where TF CNN b ottlenec k extractor is trained on large amount of normal sp eec h and a TF CNN acoustic mo del is trained on the bottleneck features of the dysarthric training sp eec h yield the b est performance with a WER of 12.0%. The other training sc hemes provid e inferior results compared to the results presen ted in T able 2 and T able 4. Not ha ving dysarthric training data for the Flem- ish data, we inv estigate using differen t combina- tion with only Flemish and combined Flemish and Dutc h data. The TF CNN b ottlenec k extractor trained on the target language and the TFCNN acoustic mo del trained using the b ottlenec k fea- tures of the com bined data has a WER of 27.5% whic h is b etter than any other training scheme. All results rep orted in T able 7 are still worse than the b est result reported on the Flemish test set, i.e. WER of 24.7% in T able 3. 6.2. Mo del adaptation In the final set of exp erimen ts, w e apply model adaptation to the b ottlenec k extractors and acous- tic models using the av ailable dysarthric training Dutc h data. T able 8 demonstrates the WER pro- vided by each adapted model trained on GFB fea- tures. Similar to [29], model adaptation brings con- siderable impro vemen ts in the ASR p erformance of all acoustic mo dels. The b est result is obtained us- ing the F CNN trained using GFB+realAFs with a WER of 10.3%. Using GFB+synAFs yields sligh tly w orse results compared to the GFB+realAFs with a WER of 10.6%. When the mo del adaptation applied to systems using bottleneck features, w e in vestigate the impact of adaptation on the b ottlenec k extractors as well as the acoustic mo dels. F rom T able 9, it can b e concluded that not adapting the acoustic mo dels trained on the normal sp eec h has the worst p erfor- mance with WERs of 19.6% and 15.5% without and with b ottlenec k extractor adaptation resp ectiv ely . The last tw o ro ws of T able 9 sho w the effectiveness of the acoustic model adaptation in this setting. Bottlenec k extractor adaptation improv es the p er- formance marginally , the TFCNN system pro viding the best result rep orted on this test data with a WER of 10.0% which is the best ASR results re- p orted on this dataset. 11 7. Summary and discussion With the ultimate goal of dev eloping off-the-shelf ASR solutions in the clinical setting, w e hav e de- scrib ed v arious sp eaker-independent ASR systems relying on designated features and acoustic mo dels and inv estigated their p erformance on tw o patho- logical speech datasets. A Dutch and a Flem- ish pathological dataset with different lev els of dysarthria severit y , num ber of sp eak ers and etiolo- gies hav e been used for the in vestigation the de- scrib ed systems. The exp erimen ts on the Dutch set has giv en us the opp ortunit y to inv estigate mo del adaptation, while the exp eriments on the Flemish test set enabled a comparison b et ween the p erfor- mance with control (normal) sp eec h with similar sp ok en conten t. W e hav e describ ed multiple sys- tems relying on nov el NN arc hitectures that are sho wn to more robust against sp ectrotemp oral de- viations. F rom the results presen ted in Section 6, the sup erior p erformance of TFCNN compared to the baseline DNN and CNN mo dels is clear visible in b oth acoustic mo deling and b ottlenec k feature extraction scheme. Including articulatory informa- tion together with the acoustic information through fCNN mo dels als o helps against the deviations of the target dysarthric sp eec h. W e further compare standard acoustic features suc h as mel and gammatone filterbank with articu- lartory and bottleneck features whic h ha v e been ex- tracted using these effectiv e NN mo dels. Join tly us- ing articulatory and gammatone filterbank features in conjunction with fCNN mo dels has provided con- siderable improv emen ts (cf. in T able 4) in the low- resource scenario of using only dysarthric training sp eec h with a WER of 16.7% on the Dutch test set compared to the 18.2% of the TFCNN mo dels. Us- ing normal training sp eech, we do not observe im- pro vemen t ov er the baseline CNN acoustic mo del on both test tests. T raining the AF extractor on real or syn thetic sp eec h has not provided notice- able differences in the ASR performance on b oth test sets. Bottlenec k features extracted using TFCNN mo dels give the lo west WER results (cf. in T able 6 and 7), namely 12.0% on the Dutc h test database and 27.5% on the Flemish test set. Moreov er, using large amount of normal data for b ottlenec k extrac- tor training, extracting the b ottlenec k features of the small amoun t of dysarthric speech using this extractor and finally training an acoustic mo del us- ing only these features yields considerably b etter re- sults compared to any other combination as sho wn in T able 6. Lastly , the mo del adaptation has yielded further impro vemen ts on the Dutch test set (whic h is the only applicable scenario due to lac k of dysarthric training data in Flemish) reducing the b est re- p orted WER to 10.0% as rep orted in T able 9. The system providing the b est p erformance used the normal training sp eech for both the b ottlenec k ex- tractor and the acoustic mo del training follow ed by the mo del adaptation using the dysarthric train- ing data. Moreov er, applying mo del adaptation to fCNN acoustic mo dels also brings improv emen ts with a WER of 10.3% and 10.6% b y incorp orat- ing AFs from AF extractors trained using real and syn thetic sp eec h resp ectiv ely . The results obtained on the Flemish sen tences uttered by dysarthric and control sp eakers enable us to quantify the p erformance gap b et ween the normal and pathological sp eec h. There is still a large gap b et ween the ASR p erformance obtained on the dysarthric and con trol sp eec h with a WER of 24.7% and 4.2% (cf. in T able 5) given b y the best p erforming ASR on the Flemish test set. Despite the considerable WER reductions rep orted in this pap er, the developmen t of the generic ASR engines that are to b e used in clinical pro cedures requires further in vestigation given this p erformance gap. There are multiple extensions to this work whic h remains as future w ork. One p ossible direction is to reduce the acoustic mismatch by including dysarthria detection/classification systems at the fron t-end for b etter understanding the nature of the sp eec h pathology and utilizing an adapted acous- tic model for recognition. In addition, data-driv en (template-based) ASR approaches, which is known to preserv e the complete sp ectrotemporal prop- erties of sp eec h in its templates/exemplars, can bring complimen tary information when used to- gether with the describ ed NN architectures. Such h ybrid systems relying both on statistical and data- driv en approaches can enhance the recognition p er- formance due to reduced acoustic mismatc h. 8. Conclusion Motiv ated by the increasing demand for auto- mated systems relying on robust sp eech-to-text systems for clinical applications, we present mul- tiple sp eak er-indep enden t ASR systems that are designed to b e more robust against pathological 12 sp eec h. F or this purp ose, w e explore the perfor- mance of t wo nov el con volutional neural netw ork arc hitectures: (1) TFCNN which p erforms time and frequency con volution on the gammatone fil- terbank features and (2) fCNN whic h enables to join tly use information from acoustic and articula- tory space b y p erforming frequency and time conv o- lution in the acoustic and articulatory space respec- tiv ely . F urthermore, b ottleneck features extracted using TFCNN mo dels are compared with standard DNN and CNN mo dels. Tw o datasets with differen t attributes hav e b een used for exploring the ASR p erformance of the de- scrib ed recognition schemes. The Dutch ev aluation setup with a small amount of dysarthric training sp eec h has pro vided insight in to effectively using normal and dysarthric training sp eec h for training the b est acoustic mo dels on b ottlenec k features. Ha ving some in-domain training data, we further apply mo del adaptation to all mo dels trained on normal sp eech to inv estigate the impact of fine- tuning the neural net w orks on the ASR p erfor- mance. On the other hand, the Flemish ev aluation setup has b oth dysarthric and control sp eec h of the same sentences establishing a b enc hmark for quan- tifying the performance gap b etw een the ASR of the dysarthric and normal sp eec h. F rom the presented ASR results, the TFCNN ar- c hitecture is found to b e effective b oth for acous- tic mo deling and b ottleneck extraction consisten tly pro viding promising recognition accuracies com- pared to the baseline DNN and CNN mo dels. More- o ver, mo del adaptation has given significan t im- pro vemen ts in b oth acoustic mo deling and b ottle- nec k extraction pip elines reducing the WERs to 10% on the Dutch test set. Despite the p erformance gap reported on the Flemish test set using mo dels trained on normal sp eec h only , considerable WER reductions are rep orted on b oth test sets. This en- courages in vestigation in v arious future directions including a dysarthria sev erity classification stage at the front-end of the describ ed ASR systems and complemen ting these ASR systems with the infor- mation obtained from data-driv en pattern match- ing approac hes. References [1] J. R. Duffy , Motor sp eech disorders: substrates, dif- ferential diagnosis and management, Mosby , St. Louis, 1995. [2] R. D. Kent, Y. J. Kim, T o ward an acoustic top ology of motor sp eec h disorders, Clin Linguist Phon 17 (6) (2003) 427–445. [3] M. W alshe, N. Miller, Living with acquired dysarthria: the sp eaker’s p erspective, Disability and rehabilitation 33 (3) (2011) 195–215. [4] L. O. Ramig, S. Sapir, C. F ox, S. Coun tryman, Changes in vocal loudness following intensive voice treatment (LSVT) in individuals with Parkinsons disease: A comparison with untreated patients and normal age- matched controls, Mov ement Disorders 16 (2001) 79– 83. [5] S. K. Bhogal, R. T easell, M. Speechley , Intensit y of aphasia therap y , impact on recov ery , Stroke 34 (4) (2003) 987–993. [6] G. Kw akkel, Impact of in tensit y of practice after strok e: issues for consideration, Disability and Rehabilitation 28 ((13-14)) (2006) 823–830. [7] M. Rijn tjes, K. Haev ernic k, A. Barzel, H. v an den Buss- che, G. Ketels, C. W eiller, Rep eat therapy for chronic motor stroke: a pilot study for feasibility and efficacy , Neurorehabilitation and Neural Repair 23 (2009) 275– 280. [8] L. J. Beijer, A. C. M. Rietveld, Potentials of telehealth devices for sp eec h therapy in Parkinson’s disease, diag- nostics and rehabilitation of Parkinson’s disease, InT ec h (2011) 379–402. [9] L. J. Beijer, A. C. M. Rietveld, M. B. Ruiter, A. C. Geurts, Preparing an E-learning-based Sp eech Ther- apy (EST) efficacy study: Identifying suitable outcome measures to detect within-sub ject changes of sp eech in- telligibility in dysarthric speakers, Clinical Linguistics and Phonetics 28 (12) (2014) 927–950. [10] M. S. De Bo dt, H. M. Hernandez-Diaz, P . H. V an De Heyning, Intelligibilit y as a linear combination of dimensions in dysarthric sp eec h, Journal of Communi- cation Disorders 35 (3) (2002) 283–292. [11] Y. Y unuso v a, G. W eismer, R. D. Kent, N. M. Rusche, Breath-group intelligibilit y in dysarthria: c haracteris- tics and underlying correlates, J Speech Lang Hear Res. 48 (6) (2005) 1294–1310. [12] G. V an Nuffelen, C. Middag, M. De Bo dt, J.- P . Martens, Speech technology-based assessment of phoneme intelligibilit y in dysarthria, In ternational Journal of Language & Comm unication Disorders 44 (5) (2009) 716–730. [13] D. V. P opovici, C. Buic˘ a-Belciu, Professional c hallenges in computer-assisted sp eech therapy , Pro cedia - So cial and Behavioral Sciences 33 (2012) 518 – 522. [14] M. Ganzeb o om, M. Bakker, C. Cucc hiarini, H. Strik, Intelligibilit y of disordered sp eech: Global and detailed scores, in: Pro c. INTERSPEECH, 2016, pp. 2503–2507. [15] E. Sanders, M. B. Ruiter, L. J. Beijer, H. Strik, Auto- matic recognition of Dutch dysarthric sp eec h: a pilot study , in: Pro c. INTERSPEECH, 2002, pp. 661–664. [16] M. Hasega w a-Johnson, J. Gunderson, A. P erlman, T. Huang, HMM-based and SVM-based recognition of the sp eech of talkers with spastic dysarthria, in: Pro c. ICASSP , V ol. 3, 2006, pp. 1060–1063. [17] F. Rudzicz, Comparing speaker-dependent and speaker- adaptive acoustic mo dels for recognizing dysarthric speech, in: Pro c. of the 9th In ternational A CM SIGA C- CESS Conference on Computers and Accessibility , 2007, pp. 255–256. [18] S.-O. Caballero-Morales, S. J. Cox, Mo delling errors in automatic sp eec h recognition for dysarthric speakers, EURASIP J. Adv. Signal Pro cess (2009) 1–14. 13 [19] K. T. Mengistu, F. Rudzicz, Adapting acoustic and lex- ical mo dels to dysarthric sp eech, in: Proc. ICASSP , 2011, pp. 4924–4927. [20] W. Seong, J. Park, H. Kim, Dysarthric sp eec h recogni- tion error correction using weigh ted finite state trans- ducers based on con text-dependent pron unciation v aria- tion, in: Computers Helping P eople with Special Needs, V ol. 7383 of Lecture Notes in Computer Science, 2012, pp. 475–482. [21] H. Christensen, S. Cunningham, C. F ox, P . Green, T. Hain, A comparativ e study of adaptive, automatic recognition of disordered sp eec h., in: INTERSPEECH, 2012, pp. 1776–1779. [22] S. R. Shahamiri, S. S. B. Salim, Artificial neural net- works as speech recognisers for dysarthric speech: Iden- tifying the b est-p erforming set of MFCC parameters and studying a speaker-independent approach, Ad- v anced Engineering Informatics 28 (2014) 102–110. [23] Y. T ak ashima, T. Nak ashik a, T. T akiguc hi, Y. Ariki, F eature extraction using pre-trained conv olutive bot- tleneck nets for dysarthric speech recognition, in: Pro c. EUSIPCO, 2015, pp. 1426–1430. [24] T. Lee, Y. Liu, P .-W. Huang, J.-T. Chien, W. K. Lam, Y. T. Y eung, T. K. T. Law, K. Y. Lee, A. P .-H. Kong, S.-P . Law, Automatic sp eech recognition for acoustical analysis and assessment of Can tonese pathological v oice and sp eec h, in: Pro c. ICASSP , 2016, pp. 6475–6479. [25] N. M. Jo y , S. Umesh, B. Abraham, On improving acous- tic models for torgo dysarthric speech database, in: Proc. Interspeech, 2017, pp. 2695–2699. [26] E. Yılmaz, M. Ganzeb o om, C. Cucchiarini, H. Strik, Combining non-pathological data of different language v arieties to impro ve DNN-HMM performance on patho- logical speech, in: Pro c. INTERSPEECH, 2016, pp. 218–222. [27] M. Ganzeboom, E. Yılmaz, C. Cucchiarini, H. Strik, On the developmen t of an ASR-based multimedia game for speech therapy: Preliminary results, in: Proc. W ork- shop MM Health, 2016, pp. 3–8. [28] E. Yılmaz, M. Ganzeb oom, L. Beijer, C. Cucchiarini, H. Strik, A Dutch dysarthric sp eec h database for in- dividualized sp eech therapy research, in: Proc. LREC, 2016, pp. 792–795. [29] E. Yılmaz, M. Ganzeb o om, C. Cucchiarini, H. Strik, Multi-stage DNN training for automatic recognition of dysarthric speech, in: Pro c. INTERSPEECH, 2017, pp. 2685–2689. [30] B. W alsh, A. Smith, Basic parameters of articulatory mov emen ts and acoustics in individuals with P arkin- son’s disease, Mov Disord. 27 (7) (2012) 843–850. [31] I. Zlok arnik, Adding articulatory features to acous- tic features for automatic sp eech recognition, J. Acoust. So c. Am. 97 (5) (1995) 3246. [32] A. A. W rench, K. Richmond, Contin uous sp eec h recog- nition using articulatory data, in: Proc. of the In ter- national Conference on Sp ok en Language Pro cessing, 2000, pp. 145–148. [33] T. A. Stephenson, H. Bourlard, S. Bengio, A. C. Morris, Automatic sp eec h recognition using dynamic Bay esian netw orks with b oth acoustic and articulatory v ariables, in: Pro c. of the In ternational Conference on Sp ok en Language Pro cessing, 2000, pp. 951–954. [34] K. Marko v, J. Dang, S. Nak am ura, Integration of ar- ticulatory and sp ectrum features based on the h ybrid HMM/BN mo deling framew ork, Sp eec h Communica- tion 48 (2) (2006) 161–175. [35] V. Mitra, N. H., C. Esp y-Wilson, E. Saltzman, L. Gold- stein, Recognizing articulatory gestures from sp eech for robust sp eec h recognition, J. Acoust. So c. Am . 131 (3) (2012) 2270. [36] L. Badino, C. Canev ari, L. F adiga, G. Metta, Inte- grating articulatory data in deep neural netw ork-based acoustic mo deling, Computer Sp eec h & Language 36 (2016) 173–195. [37] F. Rudzicz, Articulatory knowledge in the recognition of dysarthric sp eec h, IEEE T ransactions on Audio, Speech, and Language Pro cessing 19 (4) (2011) 947– 960. [38] V. Mitra, G. Siv araman, C. Bartels, H. Nam, W. W ang, C. Espy-Wilson, D. V ergyri, H. F ranco, Joint model- ing of articulatory and acoustic spaces for contin uous speech recognition tasks, in: Proc. ICASSP , 2017, pp. 5205–5209. [39] V. Mitra, G. Siv araman, H. Nam, C. Espy-Wilson, E. Saltzman, M. Tiede, Hybrid conv olutional neu- ral netw orks for articulatory and acoustic information based sp eech recognition, Sp eec h Communication 89 (2017) 103–112. [40] E. Yılmaz, V. Mitra, C. Bartels, H. F ranco, Articula- tory features for ASR of pathological sp eech, in: Pro c. INTERSPEECH, 2018, pp. 2958–2962. [41] V. Mitra, H. F ranco, Time-frequency con v olutional net- works for robust sp eec h recognition, in: Pro c. ASRU, 2015, pp. 317–323. [42] N. T. V u, F. Metze, T. Sc hultz, Multilingual bottle- neck features and its application for under-resourced languages, in: Pro c. SL TU, 2012, pp. 90–93. [43] T. Nak ashik a, T. Y oshioka, T. T akiguchi, Y. Ariki, S. Duffner, C. Garcia, Conv olutive Bottleneck Net- work with Drop out for Dysarthric Sp eech Recognition, T ransactions on Machine Learning and Artificial Intel- ligence 2 (2014) 1–15. [44] C. Middag, Automatic analysis of pathological sp eec h, Ph.D. thesis, Ghent Universit y , Belgium (2012). [45] M. Kim, B. Cao, K. An, J. W ang, Dysarthric sp eech recognition using conv olutional LSTM neural netw ork, in: Pro c. INTERSPEECH, 2018, pp. 2948–2952. [46] X. Men´ endez-Pidal, J. B. Polik off, S. M. Peters, J. E. Leonzio, H. T. Bunnell, The Nemours database of dysarthric sp eech, in: Pro c. International Conference on Spoken Language Pro cessing (ICSLP), 1996, pp. 1962–1966. [47] K. T. Mengistu, F. Rudzicz, Comparing humans and automatic sp eec h recognition systems in recognizing dysarthric speech, in: Adv ances in Artificial In telli- gence, Springer Berlin Heidelb erg, Berlin, Heidelb erg, 2011, pp. 291–300. [48] N. Oostdijk, The sp oken Dutch corpus: Overview and first ev aluation, in: Pro c. LREC, 2000, pp. 886–894. [49] C. Cucchiarini, J. Driesen, H. V an hamme, E. Sanders, Recording speech of children, non-natives and elderly people for HL T applications: the JASMIN-CGN Cor- pus, in: Pro c. LREC, 2008, pp. 1445–1450. [50] V. Mitra, H. Nam, C. Y. Espy-Wilson, E. Saltzman, L. Goldstein, Articulatory information for noise ro- bust sp eec h recognition, IEEE T ransactions on Audio, Speech, and Language Pro cessing 19 (7) (2011) 1913– 1924. [51] C. P . Browman, L. Goldstein, Articulatory phonology: an ov erview., Phonetica 49 (3-4) (1992) 155–180. [52] K. Ric hmond, Estimating articulatory parameters from 14 the acoustic speech signal, Ph.D. thesis, Universit y of Edinburgh, UK (2001). [53] V. Mitra, Articulatory information for robust sp eec h recognition, Ph.D. thesis, Universit y of Maryland, Col- lege Park (2010). [54] H. Nam, L. Goldstein, T ADA: An enhanced, portable task dynamics model in MA TLAB, J. Acoust. Soc. Am. 115 (2004) 2430. [55] H. M. Hanson, K. N. Stevens, A quasiarticulatory approach to controlling acoustic source parameters in a Klatt-type formant synthesizer using HLsyn, J. Acoust. So c. Am. 112 (2002) 1158. [56] V. Mitra, G. Siv araman, H. Nam, C. Espy-Wilson, E. Saltzman, Articulatory features from deep neural netw orks and their role in sp eec h recognition, in: Pro c. ICASSP , 2014, pp. 3017–3021. [57] B. Collins, I. Mees, The Phonetics of English and Dutch, Koninklijke Brill NV, 1996. [58] G. Siv araman, C. Espy-Wilson, M. Wieling, Analysis of acoustic-to-articulatory sp eech inv ersion across differ- ent accents and languages, in: Pro c. INTERSPEECH, 2017, pp. 974–978. [59] J. R. W estbury , Sp eec h Pro duction Database User ’ S Handb ook, IEEE Personal Communications - IEEE Pers. Commun. 0 (June). [60] H. Nam, V. Mitra, M. Tiede, M. Hasegaw a-Johnson, C. Espy-W ilson, E. Saltzman, L. Goldstein, A pro ce- dure for estimating gestural scores from sp eech acous- tics, The Journal of the Acoustical So ciet y of America 132 (6) (2012) 3980–3989. [61] P . Swieto janski, A. Ghoshal, S. Renals, Unsup ervised cross-lingual kno wledge transfer in DNN-based L VCSR, in: Pro c. SL T, 2012, pp. 246–251. [62] J.-T. Huang, J. Li, D. Y u, L. Deng, Y. Gong, Cross- language kno wledge transfer using multilingual deep neural netw ork with shared hidden lay ers, in: Pro c. ICASSP , 2013, pp. 7304–7308. [63] D. Pov ey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Go el, M. Hannemann, P . Motlicek, Y. Qian, P . Sch warz, J. Silovsky , G. Stemmer, K. V esely , The Kaldi sp eec h recognition to olkit, in: Pro c. ASRU, 2011. [64] G. Siv araman, Articulatory representations to address acoustic v ariability in sp eec h, Ph.D. thesis, Universit y of Maryland College Park (2017). [65] G. Siv araman, V. Mitra, H. Nam, M. Tiede, C. Espy- Wilson, V ocal tract length normalization for sp eak er independent acoustic-to-articulatory sp eec h inv ersion, in: Pro c. INTERSPEECH, 2016, pp. 455–459. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment