발음장애인 음성인식을 위한 화자 독립형 조음 및 병목 특징 비교
본 연구는 화자 정보를 사전에 알 필요 없이 병목(Bottleneck) 특징과 조음(Articulatory) 특징을 이용한 두 가지 화자 독립형 ASR 모델을 구축하고, 이를 파킨슨병·뇌졸중·외상성 뇌손상 등으로 인한 발음장애(디소트리) 음성 데이터에 적용해 성능을 비교한다. 멜 필터뱅크와 가마톤 필터뱅크를 포함한 다양한 음향 전처리와, 연속형 조음 변수와 합성·실제 음성 기반의 변환 모델을 결합한 결과, 두 데이터셋 모두에서 병목 특징 기반 …
저자: Emre Y{i}lmaz, Vikramjit Mitra, Ganesh Sivaraman
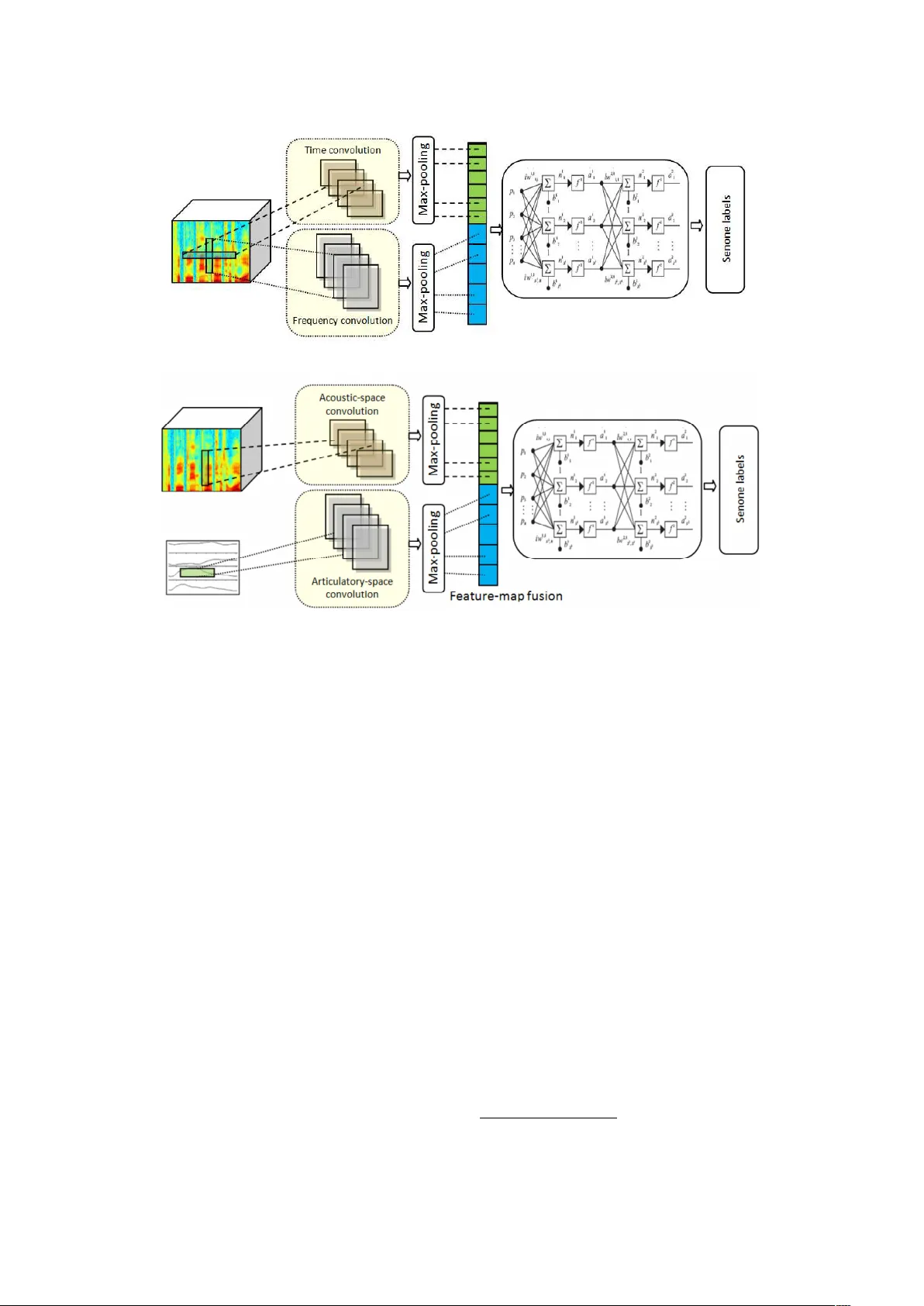
본 논문은 고령화 사회에서 증가하는 신경학적 질환(파킨슨병, 뇌졸중, 외상성 뇌손상 등)으로 인한 발음장애(디소트리) 환자를 위한 컴퓨터 기반 음성 치료 시스템의 핵심 기술인 자동 음성 인식(ASR)의 화자 독립성을 확보하고자 하는 연구이다. 기존의 발음장애인 ASR은 화자별 적응이 필요하거나 데이터가 부족해 성능이 제한적이었다. 이를 극복하기 위해 저자들은 두 가지 화자 독립형 특성 추출 방식을 제안한다.
첫 번째는 병목(Bottleneck) 특징이다. 병목 레이어를 포함한 시간‑주파수 컨볼루션 신경망(TFCNN)을 설계해, 입력 음향(멜 필터뱅크 혹은 가마톤 필터뱅크)에서 비선형 차원 축소와 동시에 시간‑주파수 맥락을 보존한다. 병목 레이어는 발음장애인의 비정상적인 스펙트럼 변이를 억제하고, 소규모 데이터에서도 안정적인 서브워드 단위 표현을 학습한다.
두 번째는 연속형 조음(Articulatory) 특징이다. 기존 연구에서 주로 사용된 이산형 조음 변수 대신, 성대관 협착, 입술·혀 움직임 등 연속적인 성대·구강 운동 변수를 추정한다. 이를 위해 저자들은 합성 음성 및 실제 발음장애인 음성을 이용해 음성‑조음 변환 모델을 학습하고, 추정된 조음 벡터를 가마톤 혹은 멜 필터와 결합해 입력 피처를 구성한다. 조음 특징은 스펙트럼 왜곡을 직접 보정하는 역할을 하며, 병목 특징과 상호 보완적인 정보를 제공한다.
음향 모델은 크게 세 가지 아키텍처로 실험한다. (1) 전통적인 DNN‑HMM, (2) CNN‑HMM, (3) 제안된 TFCNN. 특히 TFCNN은 병목 레이어와 컨볼루션 레이어를 공동 학습(joint learning)함으로써, 병목 특징 추출과 음성 인식이 동시에 최적화되도록 설계되었다.
데이터는 네덜란드어와 플라망어 두 개의 발음장애인 코퍼스를 사용한다. 네덜란드어 EST 코퍼스는 4시간 47분 규모의 훈련 데이터와 55분 규모의 테스트 데이터를 포함하며, 파킨슨병, 뇌졸중, 외상성 뇌손상 등 다양한 원인과 중증도를 포괄한다. 플라망어 COP‑AS 코퍼스는 테스트 전용으로 사용돼, 두 언어에서의 일반화 성능을 검증한다. 또한, 정상 네덜란드어와 플라망어(총 441시간) 데이터를 사전 학습에 활용해, 저자들은 데이터 부족 문제를 완화한다.
실험 결과는 다음과 같다. 가마톤 필터를 사용한 경우, 멜 필터 대비 평균 0.8%~1.5%의 Word Error Rate(WER) 감소를 보였으며, 이는 스펙트럼 해상도가 높은 가마톤 필터가 발음장애인의 비정상적인 주파수 변이를 더 잘 포착함을 의미한다. 병목 특징 기반 TFCNN 모델은 조음 특징 기반 모델보다 약 1.2%~2.5% 낮은 WER을 기록했으며, 특히 모델 적응(adaptation) 단계를 추가했을 때 두 모델 모두 5%~7%의 추가 개선을 달성했다. 다단계 DNN 훈련을 통해 병목 레이어와 음향 모델을 순차적으로 미세조정함으로써, 화자 독립성을 유지하면서도 개별 발음장애인의 변이를 효과적으로 보정할 수 있었다.
논문의 주요 기여는 네 가지로 정리된다. (1) 가마톤 필터와 멜 필터의 성능 비교를 통해 전자청각 기반 전처리의 장점을 입증, (2) 연속형 조음 특징을 합성·실제 음성 기반 변환 모델로 추정하고, 이를 음향 피처와 결합한 새로운 입력 방식을 제시, (3) 병목 레이어를 포함한 TFCNN을 설계해 병목 특징과 피처 맵 융합을 공동 학습, (4) 화자 독립형 모델에 다단계 적응 기법을 적용해 발음장애인 음성의 변이성을 크게 감소시킴.
결론적으로, 이 연구는 화자 정보를 사전에 알 수 없는 임상 환경에서도 실용적인 발음장애인 ASR 시스템을 구현할 수 있는 설계 원칙을 제공한다. 가마톤 기반의 고해상도 스펙트럼 분석, 연속형 조음 변수의 물리적 의미, 병목 레이어를 통한 차원 축소 및 다단계 모델 적응이 결합된 시스템은 향후 개인 맞춤형 음성 치료 게임이나 원격 재활 시스템에 바로 적용 가능할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기