Deep AutoEncoder-based Lossy Geometry Compression for Point Clouds
Point cloud is a fundamental 3D representation which is widely used in real world applications such as autonomous driving. As a newly-developed media format which is characterized by complexity and irregularity, point cloud creates a need for compres…
Authors: Wei Yan, Yiting shao, Shan Liu
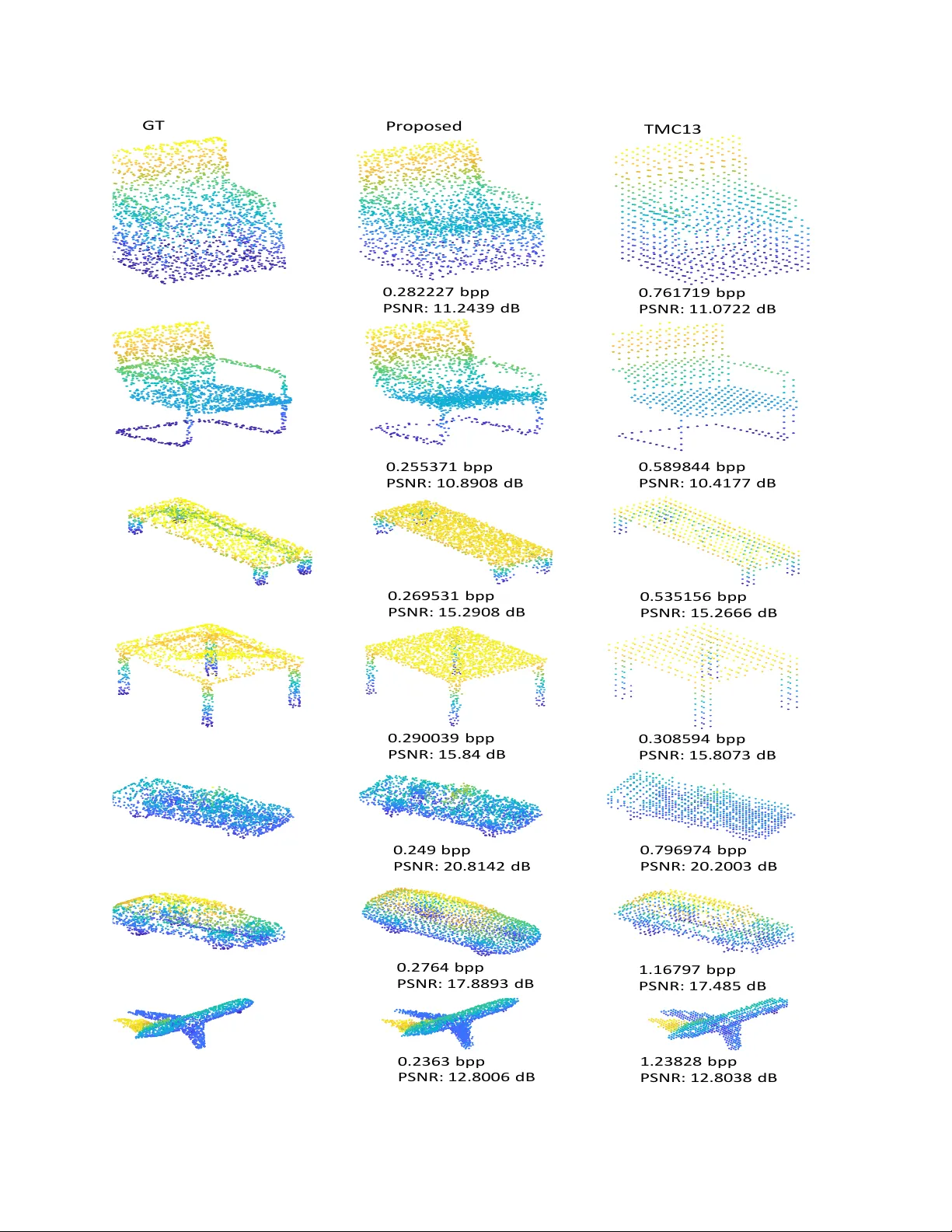
Deep A utoEncoder -based Lossy Geometry Compression f or P oint Clouds W ei Y an 1 , Y iting Shao 2 , Shan Liu 3 , Thomas H Li 4 , Zhu Li 5 , Ge Li 6 , ∗ 1 , 2 , 6 School of Electronic and Computer Engineering, Peking Uni versity Shenzhen Graduate School 3 T encent America 4 Adv anced Institute of Information T echnology , Peking Uni versity 5 School of Electronic and Computer Engineering, Peking Uni versity Shenzhen Graduate School 1 yanwe@pku.edu.cn, 6 , ∗ Corresponding Author:geli@ece.pku.edu.cn Abstract P oint cloud is a fundamental 3D r epr esentation which is widely used in real world applications such as autonomous driving. As a newly-developed media format which is char - acterized by complexity and irr egularity , point cloud cr eates a need for compr ession algorithms which ar e mor e flexi- ble than existing codecs. Recently , autoencoder s(AEs) have shown their effectiveness in many visual analysis tasks as well as image compr ession, which inspir es us to employ it in point cloud compression. In this paper , we pr opose a general autoencoder-based ar chitectur e for lossy geometry point cloud compression. T o the best of our knowledge, it is the first autoencoder-based geometry compr ession codec that dir ectly takes point clouds as input rather than voxel grids or collections of images. Compar ed with handcrafted codecs, this approac h adapts much more quickly to pr evi- ously unseen media contents and media formats, meanwhile achie ving competitive performance. Our ar chitectur e con- sists of a pointnet-based encoder , a uniform quantizer , an entr opy estimation block and a nonlinear synthesis trans- formation module. In lossy geometry compr ession of point cloud, r esults show that the pr oposed method outperforms the test model for cate gories 1 and 3 (TMC13) published by MPEG-3DG gr oup on the 125th meeting, and on avera ge a 73.15% BD-rate gain is ac hieved. 1. Introduction Thanks to recent developments in 3D sensoring tech- nology , point cloud has become a useful representation of holograms which enables free viewpoint vie wing. It has been used in man y fields such as V irtual/Augmented/Mixed reality (VR/AR/MR), smart city , robotics and automated driving[24]. Point cloud compression becomes an increas- ingly important technique in order to efficiently process and transmit this type of data. It has attracted much attention from researchers as well as the MPEG Point Cloud Com- pression (PCC) group[24]. Geometry compression and at- tribute compression are tw o fundamental problems of static point cloud compression. Geometry compression aims at compressing the point locations. Attribute compression tar - gets at reducing the redundancy among points’ attribute v al- ues, giv en the point locations. This paper focuses on the geometry compression. Point cloud is a set of unordered points that are ir- regularly distributed in Euclidean space. Because there is no uniform grid structure like 2D pictures, traditional image compression and video compression schemes can- not effecti vely work. In recent years, many researchers hav e been dedicated to de veloping methods for it. Octrees [12][18][23] are usually used to compress geometry infor- mation of point clouds, and it has been developed for intra- and inter - frame coding. In the MPEG PCC group, point cloud compression is divided into two profiles: a video coding based method named V -PCC and a geometry based method named G-PCC. All these methods are carefully de- signed by human experts who apply various heuristics to reduce the amount of information needing to be preserved and to transform the resulting code in a w ay that is amenable to lossless compression. Ho wever , when designing a point cloud codec, human e xperts usually focus on a specific type of point cloud and tend to make assumptions about their features because of the di versity of point clouds. For ex- ample, an early version of the G-PCC reference software, TMC13, was divided into two parts, one for compressing point clouds belonging to category 1, and the other for com- pressing point clouds belonging to category 3, which means that it was difficult to build a universal point cloud codec. Therefore, giv en a particular type of point cloud, designing a codec that adapts quickly to the characteristics of such a point cloud and achiev es better compression efficiency is a problem worth exploring. In recent years, 3D machine learning has made great progress in high-le vel vision tasks such as classification and 4321 n× 3 S a m p l i n g L a y er m× 3 5 l a y er s p er c ep t r o n m × k M a x p o o l i n g 1 ×k L a t e n t c o d e E n t r o p y b o t t l e n e c k l a y e r 1 ×k Q u a n t i z ed c o d e ... ... ... m× 3 C h a m f er d i s t a n c e Ra t e - d i s t o r t i o n l o s s R a t e D i s t o r t i o n I np ut O ut put E n co d e r De c o d e r Figure 1. Compression architecture. detection[6][22][30]. A natural question is whether we can employ this useful class of methods to further dev elop the point cloud codec, especially for point cloud sizes for which we do not have carefully designed. Usually , the design of a new point cloud codec can take years, but a compression framew ork based on neural networks may be able to adapt much more quickly to those niche tasks. In this work, we consider the point cloud compression as an analysis/synthesis problem with a bottleneck in the mid- dle. There are a number of research aims to teach neural networks to discover compressi ve representations. Achliop- tas et al.[1] proposed an end-to-end deep auto-encoder that directly takes point clouds as inputs. Y ang et al.[29] fur- ther proposed a graph-based encoder and a folding-based decoder . These auto-encoders are able to extract compres- siv e representations from point clouds in terms of the trans- fer classification accuracy . These works moti vate us to dev elop a no vel autoencoder -based lossy geometry point cloud codec. Our proposed architecture consists of four modules: a pointnet-based encoder , a uniform quantizer, an entropy estimation block and a nonlinear synthesis trans- formation module. T o the best of our kno wledge, it is the first autoencoder-based geometry compression codec that directly takes point clouds as input rather than vox el grids or collections of images. 2. Related works Sev eral approaches for point cloud geometry com- pression hav e been proposed in the literature. Sparse V oxel Octrees (SV Os), also called Octrees[12][18], are usually used to compress geometry information of point clouds[23][10][8][19][13]. R. Schnabel et al.[23] first used Octrees in point cloud compression. This work predicts occupancy codes by surface approximations and uses oc- tree structure to encode color information. Y . Huang et al. [10] further de veloped it for progressive point cloud coding. They reduced the entropy by bit reordering in the subdivi- sion bytes. Their method also includes attribute coding such as color coding based on frequency of occurrence and nor - mal coding using spherical quantization. There are sev eral methods that adopt inter- and intra-frame coding in point cloud geometry compression[8][7]. Kammerl et al.[13] dev eloped a prediction octree and used XOR as an inter - coding tool. Mekuria et al[19] further proposed an octree- based intra and inter coding system. In MPEG PCC[24], the depth of the octree is constrained at a certain lev el and the leaf node of the octree is regarded as a single point, a list of points or a geometric model. Triangulations, also called triangle soups, are regarded as the geometric model in PCC. Pa vez et al.[21] first explored the polygon soup representa- tion of geometry for point cloud compression. Recently , 3D machine learning has made great progress. Deep networks that directly handle points in a point set are state-of-the-art for supervised learning tasks on point clouds such as classification and segmentation. Qi et al.[6][22] first proposed a deep neural network that directly takes point clouds as input. After that, many other networks were proposed for high-level analysis problems with point clouds[15][9][17][28]. There are also a few works that focus on 3D autoencoders. Achlioptas et al.[1] proposed an end-to-end deep auto-encoder that directly takes point clouds as input. Y ang et al.[29] further proposed a graph- 4322 based encoder and a folding-based decoder . T o the best of our kno wledge, there are fe w machine-learning-based works focusing on point cloud compression, but sev eral autoencoder-based methods hav e been proposed to enhance the performance of image compression. T oderici et al.[27] proposed to use recurrent neural networks (RNNs) for im- age compression. Theis et al.[25] achiev ed multiple bit rates by learning a scaling parameter that changes the ef- fectiv e quantization coarseness. Ball ´ e et al[2][4][3]. used a similar autoencoder architecture and replaced the non- differentiable quantization function with a continuous re- laxation by adding uniform noise. 3. F ormulation of point cloud geometry com- pression W e consider a point cloud codec generally as an anal- ysis/synthesis problem with a bottleneck in the middle. The input point cloud is represented as a set of 3D points { P i | i = 1 , ..., n } , where each point P i is a vector of its ( x, y , z ) coordinate. In order to compress the input point cloud, the encoder should transform the input point cloud in Euclidean space R 3 into higher dimensional feature space H . In the feature space, we could discard some tiny com- ponents by quantization, which reduces the redundancy in the information. So we get the compressive representations as the latent code z . Then, the decoder transforms the com- pressiv e representations from the feature space H back into Euclidean space R 3 and we get the reconstructed point set { P 0 i | i = 1 , ..., n } . 4. Proposed geometry compr ession ar chitec- ture In this section, we describe the proposed compression ar- chitecture. The details of each component will be discussed in the subsections. Our proposed architecture consists of four modules: a pointnet-based encoder , a uniform quan- tizer , an entropy estimation block and a nonlinear synthe- sis transformation module. W e adopt auto-encoder[16] as our basic compression platform. The structure of the auto- encoder is shown in Figure 1. Firstly , the input point cloud is downsampled by the sampling layer S to create a point cloud with dif ferent point density . Then, the do wnsam- pled point set goes through the autoencoder-based codec. The codec consists of an encoder E that takes an unordered point set as input and produces a compressi ve representa- tion, a quantizer Q , and a decoder D that takes the quantized representation produced by Q and produces a reconstructed point cloud. Thus, our compression architecture can be for - mulated as: x 0 = D ( Q ( E ( S ( x )))) , (1) where x is the original unordered point set and x 0 is the reconstructed point cloud. 4.1. Sampling layer In G-PCC, the octree-based geometry coding uses a quantization scale to control the lossy geometry compression[24]. Let ( X i = ( x i , y i , z i )) i =1 ...N be the set of 3D positions associated with the points of the input point cloud. The G-PCC encoder computes the quantized posi- tions ( ˆ X i ) i =1 ...N as follows: ˆ X i = b ( X i − X shif t ) × s c , (2) where X shif t and s are user-defined parameters that are signaled in the bitstream. After quantization, there will be many duplicate points sharing the same quantized po- sitions. A common approach is merging those duplicate points, which reduces the number of points in the input point cloud. Inspired by G-PCC, we use a sampling layer[22] to achiev e the downsampling step. Giv en input points { x 1 , x 2 , ..., x n } , we adopt iterativ e farthest point sampling (FPS)[22] to select a subset of points { x i 1 , x i 2 , ..., x i m } , such that x i j is the farthest point (in metric distance) from the former point set { x i 1 , x i 2 , ..., x i j − 1 } with regard to the rest points. In contrast to random sampling, the point den- sity of the resulted point set is more uniform, which is better at keeping the shape characteristics of the original object. 4.2. Encoder and Decoder Generally , an autoencoder can be regarded as an anal- ysis function, y = f e ( x ; θ e ) , and a synthesis function, ˆ x = f d ( y ; φ d ) ,where x , ˆ x , and y are original point clouds, reconstructed point clouds, and compressed data, respec- tiv ely . θ e and φ d are optimized parameters in the analysis and the synthesis function. T o learn the encoded compressive representation, we consider the pointnet architecture[6][1]. There are n points in the input point set ( n × 3 matrix). Ev ery point is en- coded by sev eral 1-D conv olution layers with kernel size 1. Each conv olution layer is followed by a ReLU[20] and a batch-normalization layer[11]. In order to make a model in variant to input permutation, there is a feature-wise maxi- mum layer follo wing the last conv olutional layer to produce a k -dimensional latent code. This latent code will be quan- tized and the quantized latent code will be encoded by the entropy encoder to get the final bitstream. In our experi- ment, we use 5 1-D con volutional layers and the number of filters in each layer is 64, 128, 128, 256 and k respectiv ely . k is decided by the number of input points. See details in the experimental results. Currently , there are two kinds of decoder for point clouds: the fully-connected decoder[1] and the folding- based decoder[29]. Both decoders are able to produce re- constructed point clouds. The folding-based decoder is much smaller in parameter size than the fully-connected de- coder , but there will be more hyperparameters to choose 4323 such as the number of grid points and the interval of grid points. Thus, we choose the fully-connected decoder as our decoder , which interprets the latent code using 3 fully- connected layers to produce a n × 3 reconstructed point cloud. Each fully-connected layer is follo wed by a ReLU, and the number of nodes in each hidden layer is 256, 256 and n × 3 respecti vely . 4.3. Quantization T o reduce the amount of information necessarily needed for storage and transmission, quantization is a significant step in media compression. Howe ver , quantization func- tions like the rounding function’ s deri v ative is zero or un- defined. Theis et al.[25] replaced the deriv ati ve in the backward pass of backpropagation with the deriv ati ve of a smooth approximation r . Thus, the rounding function’ s deriv ative becomes: d dz [ z ] = d dz r ( z ) . (3) During backpropagation, the deriv ative of the rounding function will be computed by equation (3), while the round- ing function will not be replaced by the smooth approxima- tion during the forward pass[25]. This is because if we re- place the rounding function with the smooth approximation completely , the decoder may learn to in vert the smooth ap- proximation, thereby affecting the entropy bottleneck layer that learns the entropy model of the latent code. In [25], they found r ( z ) = z to work as well as more sophisticated choices. In contrast to [25], Ball ´ e et al.[3] replaced quantization by additiv e uniform noise, [ f ( x )] ≈ f ( x ) + u, (4) where u is random noise. After e xperiment, we find that the performance of these two methods is v ery similar . In our implementation, we use the second method. 4.4. Rate-distortion Loss In the lossy compression problem, one must trade off between the entropy of the discretized latent code ( r ate ) and the error caused by the compression ( distor tion ). So, our goal is to minimize the weighted sum of the rate (R) and the distortion (D) λD + R over the parameters of encoder, decoder and the rate estimation model that will be discussed later , where λ controls the tradeoff. Entropy rate estimation has been studied by many re- searchers who use neural networks to compress images[25] [2] [4]. In our architecture, the encoder E transforms the input point cloud x into a latent representation z , using a non-linear function f e ( x ; θ e ) with parameters θ e . The la- tent code z is then quantized to form ˆ z by quantizer Q . ˆ z can be losslessly compressed by entropy coding techniques such as arithmetic coding as its value is discrete. The rate of the discrete code ˆ z , R , is lower -bounded by the entropy of the discrete probability distribution of ˆ z , H [ m ˆ z ] , that is: R min = E ˆ z ∼ m [ − log 2 m ˆ z ( ˆ z )] , (5) where m ( ˆ z ) is the actual marginal distrib ution of the dis- crete latent code. Ho wever , the m ( ˆ z ) is unknown to us and we need to estimate it by building a probability model ac- cording to some prior kno wledge. Suppose we get an esti- mation of the probability model p ˆ z ( ˆ z ) . Then the actual rate is given by the Shannon cross entropy between the marginal m ( ˆ z ) and the prior p ˆ z ( ˆ z ) : R = E ˆ z ∼ m [ − log 2 p ˆ z ( ˆ z )] . (6) Therefore, if the estimated model distribution is identical to the actual marginal distribution, the rate is minimum and the estimated rate is the most accurate. Similar to [4], we use the entropy bottleneck layer 1 that models the prior p ˆ z ( ˆ z ) using a non-parametric and fully factorized density model: p ˆ z | ψ ( ˆ z | ψ ) = Y i p z i | ψ ( i ) ( ψ ( i ) ) ∗ u ( − 1 2 , 1 2 ) ( ˆ z i ) , (7) where the vector ψ ( i ) represents the parameters of each uni- variate distrib ution p z i | ψ ( i ) . Note that each non-parametric density is con volved with a standard uniform density , which enables a better match of the prior to the marginal[4]. The distortion is computed by the Chamfer distance. Suppose that there are n points in the original point cloud, represented by a n × 3 matrix. Each ro w of the matrix is composed of the 3D position ( x, y , z ) . The reconstructed point cloud is represented by a m × 3 matrix. The number of original points n may be different from m because of the lossy compression. Suppose the original point cloud is S 1 and the reconstructed point set is S 2 . Then, the reconstruc- tion error is computed by the Chamfer distance: d C H ( S 1 , S 2 ) = X x ∈ S 1 min y ∈ S 2 k x − y k 2 2 + X y ∈ S 2 min x ∈ S 1 k x − y k 2 2 . (8) Finally , our rate-distortion loss function is: L [ f e , f d , p ˆ z ] = λ E [ d C H ( S 1 , S 2)] + E [ − log 2 p ˆ z ] , (9) where f e is the non-linear function of the encoder , f d is the non-linear function of the decoder and p ˆ z is the estimated probability model. The expectation will be approximated by av erages over a training set of point clouds. 1 https://tensorflow.github.io/compression/docs/ entropy_bottleneck.html 4324 A i rp l an e ( - 79.8 % BD - rat e ) Car ( - 80.1 % BD - rat e ) Ch air ( - 71.4 % BD - rat e ) tab l e ( - 61.3 % BD - rat e ) Figure 2. Objectiv e results. 5. Experimental results 5.1. Datasets Since our data-dri ven method requires a large number of point clouds for training, we use the ShapeNet dataset[5]. Shapes from ShapeNet dataset are axis aligned and cen- tered into the unit sphere. The point-cloud-format of the ShapeNet data set is obtained by uniformly sampling points on the triangles from the mesh models in the dataset. W ith- out additional statements, we train models with point clouds from a single object class and the train/test splits is 90%- 10%. 5.2. Implementation Details The number of points in the original point cloud is 2048 and the latent code’ s dimension is 512. T o better com- pare with the reconstructed point clouds that compressed by TMC13, we downsample the original point cloud to 1024, 512, 256 and 128 points and the corresponding latent code sizes are 256, 128, 64 and 32. Because the TMC13 can not compress the normalized point cloud directly , we ex- pand normalized point clouds to be large enough so that the TMC13 can compress it properly . T o be fair , we also per - form the same operation when we compress point clouds by our model. W e add an extra normalization before feed- ing point clouds into our network, and expand reconstructed point clouds when we compute their distortion. W e implement our model based on the python2.7 plat- form with T ensorflow 1.12. W e run our model in a computer with an i7-8700 CPU and a GTX1070 GPU (with 8G mem- ory). W e use the Adam[14] method to train our network with learning rate 0.0005. W e train our model with entropy optimization within 1200 epochs and train the model with- out entropy optimization within 500 epochs. The batch size is 8 as limited by our GPU memory . 5.3. Compression results W e compare our method with the TMC13 anchor lat- est released in the MPEG 125th meeting. W e e xperiment on four types of point clouds: chair, airplane, table and car . These four types of point clouds contain a very rich point cloud shape. The chair category contains 6101 point clouds for training and 678 point clouds for testing. The airplane category contains 3640 point clouds for training 4325 GT P r o po s ed TMC1 3 0.2822 27 bpp PSN R: 11.2439 d B 0.7617 19 bpp PSN R: 11.0722 d B 0.2553 71 bpp PSN R: 10.8908 d B 0.5898 44 bpp PSN R: 10.4177 d B 0.2695 31 bpp PSN R: 15.2908 d B 0.5351 56 bpp PSN R: 15.2666 d B 0.2900 39 bpp PSN R: 15.84 d B 0.3085 94 bpp PSN R: 15.8073 d B 0.2 49 bpp PSN R: 20.8142 d B 0.7 96 97 4 bpp PSN R: 20.2003 d B 0.2764 bpp PSN R: 17.8893 d B 1.1679 7 bpp PSN R: 17.485 d B 0.2363 bpp PSN R: 12.8006 d B 1.2382 8 bpp PSN R: 12.8038 d B Figure 3. Subjectiv e results. Left: Original point clouds (GT). Color for better display . 4326 Figure 4. An ablation study of entrop y estimation module. The results are tested on point clouds of chair class. A 19.3% BD-rate gain is obtained. and 405 point clouds for testing. The table cate gory con- tains 7658 point clouds for training and 851 point clouds for testing. The car cate gory contains 6747 point clouds for training and 750 point clouds for testing. Rate-distortion performances for each types of point cloud are shown in Figure 2. T o avoid unfairly penalizing the TMC13 due to the unavoidable cost of file headers, we exclude the header size from bitstream produced by TMC13. The distortion in Figure 2 is the point-to-point geometry PSNR obtained from the pc err or MPEG tool[26]. Rate-distortion curv es are obtained by av eraging over all test point clouds. Re- sults show that our method outperforms the TMC13 in all types of point clouds at all bitrates. On av erage, a 73.15% BD-rate gain can be achie ved. In Figure 3 we show some test point clouds compressed to low bit rates. In line with objectiv e results, we find that our method produces smaller bits per point than TMC13 under the similar PSNR reconstruction quality . The recon- structed point clouds of proposed method is more dense than those compressed by TMC13. T o further analyze the entropy estimation module in our method, we implement a simple ablation study . W e consider the model without the entropy bottleneck layer as our base- line. The comparison of the RD curve between the baseline and our proposed model on point clouds of chair is pre- sented in Figure 4. Results sho w that the entropy estima- tion can effecti vely reduce the size of bitstream, yielding a 19.3% BD-rate gain. 6. Conclusion In this paper, we propose a general deep autoencoder- based architecture for lossy geometry point cloud compres- sion. Compared with handcrafted codecs, this approach not only achieves better coding efficienc y , but also can adapt much quicker to new media contents and new me- dia formats. Experimental ev aluation demonstrates that for the given benchmark, the proposed model outperforms the TMC13 on the rate-distortion performance, and on average a 73.15% BD-rate gain is achie ved. T o the best of our knowledge, it is the first autoencoder- based geometry compression codec that directly takes point clouds as input rather than voxel grids or collections of im- ages. The algorithms that we present may also be extended to work on attribute compression of point cloud or e ven point cloud sequence compression. T o encourage future work, we will make all the materials public. References [1] P . Achlioptas, O. Diamanti, I. Mitliagkas, and L. Guibas. Learning representations and generative models for 3d point clouds, 2018. [2] J. Ball, V . Laparra, and E. Simoncelli. End-to-end optimized image compression. 11 2016. [3] J. Ball, V . Laparra, and E. P . Simoncelli. End-to-end opti- mization of nonlinear transform codes for perceptual quality . In Pictur e Coding Symposium , 2016. [4] J. Ball, D. Minnen, S. Singh, S. J. Hwang, and N. John- ston. V ariational image compression with a scale hyperprior . 2018. [5] A. X. Chang, T . Funkhouser , L. Guibas, P . Hanrahan, Q. Huang, Z. Li, S. Sav arese, M. Sa vva, S. Song, H. Su, J. Xiao, L. Y i, and F . Y u. ShapeNet: An Information-Rich 3D Model Repository . T echnical Report [cs.GR], Stanford University — Princeton University — T oyota T echnological Institute at Chicago, 2015. [6] R. Q. Charles, S. Hao, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmen- tation. In IEEE Conference on Computer V ision & P attern Recognition , 2017. [7] R. L. de Queiroz and P . A. Chou. Motion-compensated com- pression of point cloud video. In 2017 IEEE International Confer ence on Image Processing (ICIP) , pages 1417–1421, Sep. 2017. [8] D. C. Garcia and R. L. de Queiroz. Context-based octree coding for point-cloud video. In 2017 IEEE International Confer ence on Image Processing (ICIP) , pages 1412–1416, Sep. 2017. [9] B. S. Hua, M. K. Tran, and S. K. Y eung. Point-wise con vo- lutional neural network. 2017. [10] Y . Huang, J. Peng, C. C. Kuo, and M. Gopi. A generic scheme for progressi ve point cloud coding. IEEE T rans- actions on V isualization & Computer Graphics , 14(2):440– 453, 2008. [11] S. Ioffe and C. Szegedy . Batch normalization: accelerating deep netw ork training by reducing internal covariate shift. In International Confer ence on International Confer ence on Machine Learning , 2015. 4327 [12] C. L. Jackins and S. L. T animoto. Oct-trees and their use in representing three-dimensional objects. Computer Graphics & Image Pr ocessing , 14(3):249–270, 1980. [13] J. Kammerl, N. Blodo w , R. B. Rusu, M. Beetz, E. Stein- bach, and S. Gedikli. Real-time compression of point cloud streams. In IEEE International Confer ence on Robotics & Automation , 2012. [14] D. P . Kingma and J. Ba. Adam: A method for stochastic optimization. In ICLR , 2015. [15] R. Klokov and V . Lempitsky . Escape from cells: Deep kd- networks for the recognition of 3d point cloud models. In 2017 IEEE International Confer ence on Computer V ision (ICCV) , 2017. [16] A. Krizhevsky and G. E. Hinton. Using very deep autoen- coders for content-based image retriev al. In ESANN , 2011. [17] Y . Li, R. Bu, M. Sun, and B. Chen. Pointcnn. 01 2018. [18] D. Meagher . Geometric modeling using octree encoding. Computer Graphics & Imag e Pr ocessing , 19(2):129–147, 1982. [19] R. Mekuria, K. Blom, and P . Cesar . Design, implementa- tion and e valuation of a point cloud codec for tele-immersi ve video. IEEE T ransactions on Circuits & Systems for V ideo T echnolo gy , PP(99):1–1, 2016. [20] V . Nair and G. E. Hinton. Rectified linear units improve re- stricted boltzmann machines. In International Confer ence on International Confer ence on Machine Learning , 2010. [21] E. Pav ez and P . A. Chou. Dynamic polygon cloud compres- sion. In IEEE International Conference on Acoustics , 2017. [22] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hi- erarchical feature learning on point sets in a metric space. In I. Guyon, U. V . Luxbur g, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett, editors, Advances in Neu- ral Information Pr ocessing Systems 30 , pages 5099–5108. Curran Associates, Inc., 2017. [23] R. Schnabel and R. Klein. Octree-based point-cloud com- pression. In Eur ographics , 2006. [24] S. Schwarz, M. Preda, V . Baroncini, M. Budaga vi, P . Ce- sar , P . Chou, R. Cohen, M. Kri vokua, S. Lasserre, Z. Li, J. Llach, K. Mammou, R. Mekuria, O. Nakagami, E. Sia- haan, A. T abatabai, A. M. T ourapis, and V . Zakharchenko. Emerging mpeg standards for point cloud compression. IEEE Journal on Emer ging and Selected T opics in Cir cuits and Systems , PP:1–1, 12 2018. [25] L. Theis, W . Shi, A. Cunningham, and F . Husz ´ ar . Lossy image compression with compressiv e autoencoders. CoRR , abs/1703.00395, 2017. [26] D. T ian, H. Ochimizu, C. Feng, R. Cohen, and A. V etro. Geometric distortion metrics for point cloud compression. pages 3460–3464, 09 2017. [27] G. T oderici, S. M. O’Malley , S. J. Hwang, D. V incent, D. Minnen, S. Baluja, M. Covell, and R. Sukthankar . V ari- able rate image compression with recurrent neural networks. Computer Science , 2015. [28] W . W ang, R. Y u, Q. Huang, and U. Neumann. Sgpn: Sim- ilarity group proposal network for 3d point cloud instance segmentation. 2017. [29] Y . Y ang, C. Feng, Y . Shen, and D. Tian. Foldingnet: Point cloud auto-encoder via deep grid deformation. In The IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , June 2018. [30] Y . Zhou and O. T uzel. V oxelnet: End-to-end learning for point cloud based 3d object detection. In The IEEE Confer- ence on Computer V ision and P attern Recognition (CVPR) , June 2018. 4328
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment