Automatic Classification of Music Genre using Masked Conditional Neural Networks
Neural network based architectures used for sound recognition are usually adapted from other application domains such as image recognition, which may not harness the time-frequency representation of a signal. The ConditionaL Neural Networks (CLNN) an…
Authors: Fady Medhat, David Chesmore, John Robinson
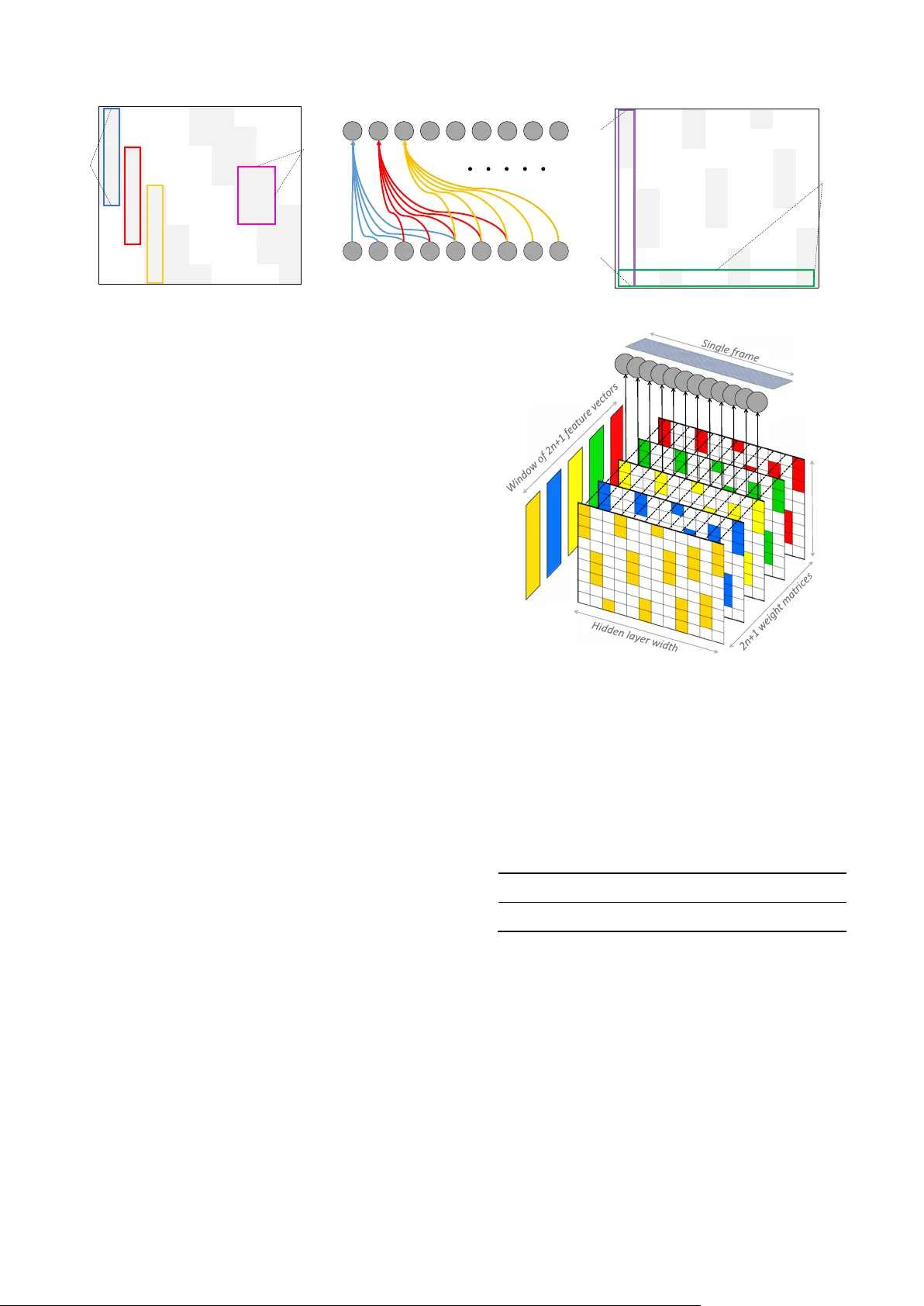
Automatic Classificatio n of Music G enre using Masked Conditional Neural Networks Fady Medhat D avid Chesm ore John Rob inson Department of Electronic Engineering Unive rsit y of Yo rk Yor k, Unite d Ki ngdo m {f ady. medhat, davi d . chesmore , john.robinson}@y ork.ac.uk Abstract — Neural ne tw or k b ase d archi tect ures used f or soun d recogniti on are us uall y ad apte d fro m other appl icat io n doma ins such a s i mage r ecog niti on, w hi c h may not ha rnes s the ti me - freq uency repr ese ntati on of a si gnal . T he Co ndit ionaL Ne ural Netw ork s (CLN N) an d its ex tensio n the M as ked Con dition aL Neural Netw ork s (MCLNN) 1 are d esigned for mult idi mens io nal tempor al sig nal re cogni tion. The CL NN is tr ain ed over a w indow of fra mes to preser ve the inte r - f ra me relation , and t he MCLNN enforces a sy ste matic sparsene ss over the n etwork’s l inks that mimics a filterbank - li ke be havi or . The masking operati on induces th e netw or k to lear n in fre quenc y bands , w hich decreases the ne tw or k susceptib ility to frequency - shifts in tim e - freq uency represent ations . Additionally, the m ask allows an e xploration of a range of feat ure co mbination s conc urre ntly analo gous to t he manua l ha nd crafting of t he optim um collection of featur e s for a recog nit ion t ask. MCLNN have achieved competi tive perfor mance on the B allroo m music d ataset compared to seve ral han d - craft ed atte mpts a nd out perf orme d mode ls b ased on s tate - of - t he - art Convol utio nal Neu ral Net wor ks. Keyword s — Restricte d Boltzmann Machine ; RBM; Condit ion al RBM; CRBM; Deep Belief Net ; DBN ; Conditional Neural Ne twork ; CLNN ; Masked C ondit ion al N eural Netw ork ; MCL NN ; Mu sic Informatio n Retrieval ; MIR I. I NTRODUCTION Statistical m ethods have been used in sound re cognition for decades . Esp ecially , th e GMM - HMM com binat ion, w h ere the GMM is used to model the sta tistical dist ribution of t he f ram es and the H MM to ca pt ur e the state transit ions in the sequen tial signal . T hese models have been used e xtensi vely for s peech [1] . Despite the success of such m odels they involve a time - consuming stage o f manual insp ec t ion of th e spa ce of featu res that can be extr acted from the raw sig nal w ith an objective of finding t he most distin ctive featu r es to intr odu ce to a r ecogni tion mode l. Deep neur al network a rchitect ures are g aining momentum in an endeav o r to elimin ate the need t o hand craf t the feat ures requi red f or c lassificati on. A r em arkable att empt for image reco gnition was in [2] using a deep Co nvolutional Neura l Netw ork (CNN) [3] . In p a rallel , effor ts were cons ider ed to apply these architectu re s for sound re cognition [4],[5],[6],[7 ]. Widel y ada pted m odels su ch as C onvol utional N eur al Networks and Deep Belief Nets (DBN) [8] were n ot initia lly desi gne d for sound, but rather they got adapted to sound reco gnition after th eir succ ess in image processing , which ma y not harne ss the nature of the sound signal in a tim e - frequenc y represen tati on such as a spectrog r am . For ex ample , the DB N does not cons ider the inter - fram e relation of a temporal sig nal , and the CNN depends on w eight - sharing, which doe s not pre serve t he spa tia l loca lity of the learned f eatur es across the frequenc y bins in a spectrogram. T he Con dit ion aL Neu ral Net work s (CL NN) [9] ta ke into cons ide ration the inter - fr ame r elation across a t empora l signal . T he Masked Co nditionaL Neur al Network s (M CLNN) [9] extend upon the CLNN str uct ure by em bedd ing a filterb ank - like beha vior within the network, which e ncourage s the ne two r k to lear n in frequ ency bands and suppo rt s sustain ing f reque ncy - shifts. Additio nally, the mask is designed to a llow a conc urrent explora tion of a range o f feature co mbinations analo gous to the exhausti ve manual search for finding t he optimum combinat ion of feat ures. I n this w ork, we explore usi ng a shallow architecture of the MCLN N with a wider segmen t compar ed to the d eep architecture used in [ 10 ] for m usic gen re clas sific ation. T he rest o f the p aper is or ganized a s f ol lo ws : In the next section, S ection II, w e will r efer to o ther relat ed mod els. Sec t io n III w ill discuss the Con ditiona L Neura l Net w ork (CL NN) an d a foll ow o n is brought i n Section IV to dis cuss the Masked Cond itional Neural Network t hat extends upon t he CLNN. Section V w i ll go through the e xpe riments with their relevant disc ussion of the findings . Finally, we wrap up this work in Sectio n VI w ith the co nclusions and future work. II. R ELA TED M ODE LS T he Rest ricted Bolt zman n Machine (RBM) [ 11 ] i s a n archite cture of tw o layers of neu r ons , a vis ible and a hidden layer, with bi - dire ctio nal connection s going across the tw o layers. An RBM is trained generati vely, aiming to model the featur e spa ce of the training d at a . Several R BMs can b e st acked on top of ea ch ot her to f orm a De ep Be lie f Net str uct ure ( DBN) [8] . Each layer of an RBM extra ct s a more ab strac t repres entation than th e lay er bef ore it, w hich is a proper ty for deep a rchit ectur es in general . T his enhanc es the featu res extrac ted and cons equently the classif ication decisi o n. Th ree RBMs w ere stacke d by Ham el et al. [7] to extract the fea tures from au d io signal s of m usic g enres th at were fu r th er cl assifi ed 1 Cod e: https: //git hub.com/f ady medhat/ MCL NN This wo rk is fun ded by the Euro pean U nion’s Seven th Fra mework Programme for r esearch , tec hnological d evelopment and demons tration under gr ant agr eeme nt no. 608 014 ( CAP AC IT IE ). using an SVM. In their work, they showed the abstract ion capture d by e ach lay er of an RBM, wh ere using the three la y e r s achieve d higher a ccuracy compa red t o using a doubl e or a single layer o f an R BM when training the model on fram e level o f a spect rogram . Despite the interestin g fin d ings, RB Ms ignore the tempor al as p ect of a signal by treatin g each fram e in isolati o n. The Con ditional Restricte d Boltzm ann Machin e (CR BM) [ 12 ] by Taylor et al . w as intr oduced t o all ow the RBM to b e adapted f or tempor al signals. The CRB M involves the inc lusion of condit ional links from the pr evious i nput states to the current hidden o ne and a uto - regres siv e lin ks t o the current input . Accordi ngly, the p redictio n of t he hid den layer’s activa tions and the reconstr ucted vector at the visible layer are condi ti oned o n the p a st n frames. Fig. 1 shows a CRB M structure . The vanilla RBM is represen ted w ith its visible and hidde n nod es with the bid ir ectio na l co nne ctio ns going a cross t he visible and hidden lay ers . The CRBM’s conditional links are rep resented by the directed co nnections from the previous vi sib le sta tes , , …, to the c urrent hidden layer using , , … , and to the curre nt visible state using , , …, . T he CRBM was ap pli ed on a multi - channel tempor al signal f o r modell ing the human motion through jo ints tracking. L ater attempt s adap ted the CRBM to the p honeme re cognition ta sk by Mohamed et al . [ 13 ] and for drum pattern ana lysis by Batt enberg et a l. in [ 14 ]. The y w ere al so extended in the Interpolating CRBM (ICRBM) [ 13 ] by including the future frames’ infl uence in add ition to the pas t ones. ICRBM o utperfor med the CRBM for the phonem e model ling in speec h recognitio n. Full y conn ected F eed - forw ard Neural Netw orks d o not s cale well with inputs of large dim ensi ons su ch as i mag es. Convo lutional Neural Networks ( CNN) [3] u se weight sha ring to tac kle this pr oblem. T he CNN ar chitecture as shown in Fig . 2 is based o n th e hypothe sis that th e featu r es detected in o ne re gio n of a 2 - dimensio nal i npu t have a high probab ility of being detect ed els ewhere in the imag e . Th erefor e, using small fi lters (weight m atrice s of sm all s izes , e. g. 5 ×5) to sc an the i mag e , a CNN does not re quire a direct conn ection betw een each pixel in the input and the hidden layer . The filters sc an th e imag e, wh er e each filt er acting as an edge det ector ext ract s diffe ren t prope rties with respect t o it s neighboring filt ers and proj ect it on a new featur e map represent ation (a new v ersion of the origin al imag e). The gene rated featu re maps ar e rescaled through a p ooling operation, wh ere a sm a ll w indow extra cts the mean or the max value across the pix els in the window to project it over a low er res olut ion fea tur e m ap. The se t wo operat ions of c onvol ution an d pooling ar e interleaved sever al times to f orm deep ar chitectural structu res, w here the f inal feat ure ma ps are fla tten ed to a single feature vec tor to be fed to a fully connected ne twork as depicted in Fig. 2 . CNN ach ieve d remarka ble res ults f or image reco gnition in [2]. T he spatia l locality of the energ y captu red at differ ent frequenc y bin s is a distinctive pro perty to th e sound category. The weight sha ring allows the CNN to be translatio n invariant, whic h does not tak e into consider ation th e nature o f the tim e - frequen cy represent ati o n . Accordi ngly, several attempts [5],[4], [6],[ 15 ] tr ied to tai lor th e CN N to fit t he nature o f the multi - dimensional temporal represen tation of a sound signal . For e xam ple, t he w ork by Abd el - Hamid et al. [5 ] r edesigned the weight shar ing to a Limited Weight Sharin g , wh ich limits the shari ng to a particul ar regi on of fr eq u encies . Othe r attem pts su ch as the work b y Pons et al. [ 15 ] combined tw o sets of f ilters in one mode l t o scan th e tem poral an d the spect ral dim ension s separat ely , wh ich achieved a hig her accu racy com p ared t o a no r mal CN N. III. C ONDITION AL N EUR AL N ET WO RKS T he Con dition aL N eural Netw ork (CLNN) [9] is a discr iminative model exte nding from the ge nerative CRBM disc ussed earlier. T he CLNN adop ts one set o f the CRBM’s con diti onal links, which connect th e previous visible states to the hidden l ayer. The CLNN also extend s the influence o f the frames to the futur e in addition to the pa st frames as in the ICRBM . T he CLNN is traine d over a wind ow of frames, where it predicts the w indow ’s mi ddle fram e condi tione d on n fra mes on both te mpo ra l dir ect ion s. The CLNN has a h idden layer of e neurons of a vector shape. The input to the CLNN is a w ind ow having d f rames. T he wi dt h of th e wi ndow follows ( 1 ) where t he w idth d is specif ied by twice the order n (to a ccount for future and past frames) in addition to the window’s middl e fram e. The order n specif ies the n um ber of fr ames in a sin gle tem poral dir ect ion . The re are dense c onnect ions betw een each frame in the windo w and hidden layer, where the acti vation of single ne uron is f ormulated in (2) where the j th hidden nod e acti vatio n , (t he ind ex t specifies the positio n of the frame in th e input seg ment d iscussed later) is give n b y the outp ut of t he tr ans fer f uncti on f . T he bias at the = 2 + 1 (1) , = + , , , (2 ) Fig . 1. The Cond itional RBM s truct ure Fig . 2. Con vol utional Ne ural Net wor k node is . T he , is the i th feature of f eature vector x of lengt h l at position u + t in a wind ow , wh ere the u ranges between [ - n , n ] and the frame at u = 0 is the window’s midd le frame at position t of a segment . , , is t he weigh t between the i th feature and the j th hidd en node o f the matrix at position u in the weig ht ten sor. The windo w of fra mes i s extracted from a larger temporal chunk that we will refer to as the segment . The segment has a mini mum widt h of a wind ow a nd ca n be la rge r as we will di scuss later . T he activation can be reformulated in a vect or form in (3) where is the activation patte rn at the hidden la yer . f is the trans fer function. is th e bias vect or. is the vector at index u + t , whe r e u is within the interv al [ - n, n ]. is the m atrix at in de x u of th e weight tensor of dimensions [feature vect or length l , the hidd en layer width e , the number of fra mes in a window d ]. A ccordin gly , for e ach f rame in th e w indow a dedicat ed matrix o f the tensor is used to process it. The output of the vector - m atrix multiplicati on is d vec to rs each of len gth e to b e summed togethe r feature - w ise before the nonlin earity applie d by the trans fer functio n. The conditional distributi o n o f the win dow’s m iddle fram e conditioned on th e n frames on both side s is capt ured b y ( | , … , , , … ) = ( … ) , wh er e is a Sigm o id or the o utput layer’s S oftmax. Fig . 3 show s two CLNN layers scanning a multi - dimensi onal tempor al sig nal . The o utput fram es at each CLNN lay er ar e decrem ented b y 2 n fram es . To ac count for thi s re d uct io n i n th e num ber of f ram es, the input to a deep CLNN arc hitect ure is a chunk of fr ames referred to as the segment. The segment si ze foll ows (4 ) wher e a segment q dep ends on th e order n ( the 2 is for t he future and past f rames ), m is the number of layer s and k is for th e extra fram es that shoul d rem ain a fter th e CLNN layers . These k fram es can be flat tened to a single v ector or pool ed ac ross ( e.g. mean or m ax pooling) a s i n a CNN , b ut fo r sound , it is a sin gle dimensio n pooling . For ex ample, at n = 4, m = 3 and k = 5, the input segm ent at th e fi rst l ayer (of the th ree lay ers at m=3 ) is of siz e (2×4 )× 3+5 = 29. T he output at the firs t layer is 29 – (2×4) = 21 fram es . T he o utput of the se co nd lay er is 21 – (2 ×4) = 13 frames and finally the outp ut of the third layer is 13 – (2×4) = 5 fram es. The rem aining 5 fram es represent th e extra f rames to be flatte ned or pooled across before transferring t hem to the fu lly connect ed layers for the fin al classificati o n. IV. M AS KED C ONDITIONAL N E URAL N ETWORK Spectro grams provide an ins ight of the energy contribut ion at each frequenc y bin as th e sound signal progresses thro ugh tim e. The energ y of a sin gle frequency bin may smear ac ross near by bins due to unc ontrolled propagat ion factors, which affect th e spectr ogra m represe ntat ion. This al terati on i s no t helpful f or recogn ition sy stems. A filte rbank is a group of filte rs used to subdivide the spectro gram re present ation into f reque ncy bands. T he part itioning p r ovides a repres entation t hat count er s the sm earing, w hich all ows the s pect rogram to be f requen cy shift - inva riant by aggrega ting the ener gy across several frequenc y bins. Additio nally, the transfor med spectro gram has fewer dimensi ons matching the number of fi lters. A filte rbank is the mai n opera ting block in sc aled spect rogram s using e.g. Bar k or Mel scale. Fo r ex ample , in the Mel - scale d filte rbank , the filters are scaled by having th eir cent er frequ encies Mel - spac ed fro m eac h oth er. The Maske d Con dition aL N eural Netw ork (MCLNN) [9] embeds a fil terbank - like behavior within the ne twork by enforci ng a sy stematic sparseness over the network’s links. The ba nd - like s parseness in duces the n e two r k to lear n in frequency b a nds a nd p er mit e ach hidden node to b e an expert in a local ize d region of t he feature vector, whic h allows focusing on di stinctive features in the node’s field of observatio n. T he m a sk is a binary pat tern as depicted in Fi g. 4 . It i s desi gned to follow a band - like struc ture using two tunab le hype r - paramet ers : t he Bandwid th and the Overlap . The Bandwidth s p ecifies the number of column - wi se 1 ’s , wh i c h refers to the number of featur es that will be considered together fro m a fea ture vector. The Over lap controls the superposition distan ce betw een tw o successi ve colum ns. For exam ple, Fig. 4 .a depi cts a ma s k having a Bandw idth=5 and an Overl ap=3 . Th e posi ti on s of the o nes activate di fferent re gion s within the feature vector . F ig. 4 .b shows the ena bl ed links w ith respect to the hidden layer node s matching the p attern enfor ced in Fig. 4 . a. Fig. 4 .c s how s an exam ple of a m asking of a Band wid th = 3 and an Overl ap = –1 , whe r e a negative Overlap refers to the non - overlapp ing distance between tw o consecutiv e columns . The linear spacing o f the 1’s p atterns is specified us ing wher e the linear index lx is s p ecified b y the length of the vector l , the bandwidth bw and the over lap ov . T he val ues of a ranges = + · (3 ) = (2 ) + , wher e n, m an d k (4 ) = + ( 1 ) ( + ( )) (5 ) Fig . 3 A t wo la y er C LNN mo de l wi t h n=1 CLNN of n = 1 CLNN of n = 1 Feature vectors with 2n fewer frames than the previous layer k central frames Result ant frame of the Mean/Max pooling or flattening operation over the central frames One or more Fully connect ed layer Output Softmax between [0, bw - 1] a nd g i s in t he range [1, ( × )/( + ( )) ] , w here e is the hidden layer w id th. I n addition t o the mask ’s role in impos ing a band - like str uctur e over the l inks , i t autom ates the expl o rati o n of a ran ge of feature combina tion concurre ntly analogous to mixing - and - matching the optimum combination of fe a tures m anually for a reco gnition task. Fig. 4 .c shows thr ee shi fted ver sion s of a filterbank - like p attern depicte d in the 1 st thre e columns com pare d to t he 2 nd batch o f three co lumns and the 3 rd one s. Each f ilter b ank - like version is aggre gating different sets o f featur e com binat ions , and all the a ggregated sets are consi dere d concurr ently. On a gran ular level , the input at the 1 st hidden nod e (mapped to the first column) in Fig. 4 .c is the first three featur es disre garding the temporal dime nsion t at this s tage . The i nput at the 4 th node is the first two feat ures and at the 7 th node’s inp ut is the first f eature only . The masking opera tion is im posed over the ne twork’s connect ion through an el ement - wise mu ltiplication between mask’s matri x and each w eight matrix in the tens o r following (4 ) where is the o riginal weight matrix at index u , is the masking pattern and is the masked version of the weight matrix t o substitute in ( 3). Fig. 5 shows a singl e step of the MCLNN scanning a windo w of frames having ord er n . The w indow size is 2n+1 . A ccordingly , t he w eight te nsor has a depth of 2n+1 , where each frame in the input windo w is processed with its corr esponding weight m atr ix at the sam e in dex . The highli ghted regions i n the mas k are th e activ e connecti ons foll owin g the location s of the 1’s. The result ant of th e depict ed M CLNN step is a singl e vecto r repres entation for the window of frames. V. E XPER I MENTS T he experim ents use a shall ow architectu re of th e MCLNN co mpared to the de ep mode l used in [ 10 ] . We ev aluate d t he MCLNN p erformance on the music genr e classificatio n using the B allroom [16] datas et. The da tas et is com posed of 698 musi c cli p of 30 sec onds each for 8 Ballroom musi c sub - genres : Cha Cha, Ji ve, Quickstep, Rumba , Samba, Tango , Viennese Waltz and Slo w Walt z . As an init ial process ing step, w e resam pled the files to a monaural 16- bit word depth wa v format at a s ampling rate o f 22050 Hz. All fil es underw ent a spect r ogr am trans formation to a 256 freq uency bin logarithm ic me l - scaled spe ctrog ram w ith an FF T win dow of 2 048 s ample an d 50% overlap. Further prepro cessing involved ext ract ing segm ent s following (4 ). We fo ll o wed a 1 0 - f old cr oss - vali dation to re por t the accu racies, w here the traini ng folds a re standar d ize d , an d the z- scor e par ameter s are applie d o n the validation and test fo ld s . We ad o pt ed a single layer MCLNN follo wed b y a pooling lay er to p ool a cross k= 55 frames in addit ion to the window’s mid d le fra me afte r the MCLNN l ayers and two f ully connected layers o f 50 and 10 neurons, respecti vely, before the final 8- wa y output sof tma x . The total segment length at an order n = 20 is 96 fram es. The mod el hyp e -r pa rameters are listed in T able I. The m odel is tr ained to m inimize cat egorical c ross - entropy between the predic tion of a seg ment and th e labels usin g ADAM [ 17 ] . Dropout [ 18 ] was used for re gulari zation. T he catego ry of = (6) TA B LE I. M C LN N H YPER - PARAMETERS FOR THE B ALLROOM La ye r Type Nodes Ma sk Bandw idth Ma sk Overl ap Order n 1 M CLN N 220 40 - 10 20 Fig . 4 Exam ples o f the Mas k patte rns. a) A ba ndwidt h of 5 w ith an o ve rl ap of 3, b) The allow ed connec tions matching the mask in a. across th e neurons of two lay er s, c) A ba ndw idth of 3 and an o ver lap o f -1 1 0 0 0 1 1 0 0 0 1 0 0 0 1 1 1 0 0 1 1 0 0 0 1 1 0 0 1 1 0 0 0 1 1 1 0 1 1 1 0 0 0 1 1 0 0 1 1 0 0 0 1 1 1 0 1 1 1 0 0 0 1 1 0 0 1 1 0 0 0 1 1 0 0 1 1 1 0 0 0 1 Overlap Bandwidth 1 0 0 1 0 0 1 0 0 1 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 0 0 0 0 0 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 0 1 0 0 1 0 0 1 Hidden layer width Feature vector length Fig . 5 A sin gle st ep of th e MC LN N Feature vector length a music file was decided using proba bility voting across the pred ictions o f the frames of a cli p. Tab le II lists the accuraci es reported on the Bal lroom datase t through sever al attem p ts in th e lite r ature in cluding the MCLNN. The h ighest accuracy in the table is report ed i n th e wor k o f Peeters [ 19 ] , whe r e he achieved 96.13% using his proposed handcr afted features with the help of the T empo an notat ion s releas ed wi th the datas et. Pee ter s re applied his method with out the t emp o annotations , and th e accura cy droppe d to 88 %. An accuracy of 93. 12% and 92.44 % w as also report ed o n the B allroom dat aset in [ 20 ] and [ 21 ], re spectively, where bot h attempts exploite d hand crafte d featu res. The eff ectiv eness of the tem po annot ati ons w as also s tu die d by Gouyon et al. [ 22 ] , w here they achieve d a b ase accu racy of 82.3% u sing the temp o dat a only . They achieve d an accu r ac y of 90.1% using the te mp o annotat ions in combina tion with their proposed handcraft ed featur es. Co nver sely , the MCLNN achieve d 92 .12 % without any handcraf ted featu r es . Additionally, t here is no spec ial tailoring to exp loit musica l percept ual proper ties or te mp o annotat ions, which allows the MCLNN to be co nsider ed fo r other multi - channel tem poral r epresen tations. In co mparison t o a neural based archi tect ure, t he work o f Po ns e t al. [ 15 ] achie ved 87.68% using a specially designed shallow Convo lutional Neural Network archit ecture o f musically m otivated filters . The ir archit ecture used a single convolut ion la yer followed b y a max polling layer before a 200 neuro n fully connected layer and the 8 - wa y S of tma x . In thei r work, the y compared the performance of three CN N architecture s based on the size of th e filter used : Blac k - box, Freque ncy filters and Tempor a l f ilte r s. The Black - b ox filt e rs are of si ze m×n , which ar e the regular CNN filter s, the Fre quency filters are of size m×1 to convolve the freq uency dimensio n and 1 ×n sized filte rs for the temporal di mension . T abl e III lists the accura cies of 10 - fold cross va lidat ion achieved in the work of Po ns et al. i n addition to the accurac y ach ieved b y th e MCLNN. T he highest accuracy achi e ved b y Pons et al. was obtain ed wh e n combining the filt er s tr ained separate ly across each of tem poral and freque ncy dimensions in the s ame model. Their combi ned architecture achieve d 86.54%, which increased to 87.68% wh e n using a pre - trained m o del. A s the tabl e show s, the MCLNN achieve d the hig hest accu racy w ith the low est stand ard deviat ion, which demonstrate s the stability o f the accura cy rep orte d by t he MCL NN a cros s the folds . Fig. 6 shows the confusio n across the Ballroo m genres using the MCL N N. Ther e i s hi gh confusio n r ate between the Rumba and the Waltz s imilarly for th e Vie nnese W alt z and the W alt z. Lykartsis et al. report ed similar confusio n trends i n [ 26 ]. The perfor mance of the MLCNN is accounted to exp loiting both d imensional r epresentat ions, either the tempor al or the frequenc y dimension. Additionally, t he masking operatio n counter the smear ing that occurs natura lly across frequenc y bins due to uncon trolled ci rcumstan ces r elat ed to th e sound propa gation. Thro ugh various Overla p an d Ban dw idth settings , we noticed that incre asing the sparsene ss through negative Overlap val ues, enhanced the accuracy. T his is acco unted t o dis ablin g the effe ct of the smear ing earl y on before the smear ing noise acro ss the frequencies propa gates into the network and affect th e classif icat io n decisi o n. MC LNN accuracy ha s surpass ed sev eral handc raft ed att empts in additi on to state - of - the art Co nvolutional Neural Ne tworks. Additionally , the MCLNN have achi e ved com pe titive results c omp ared to hand cr afted feature s w i thout using a ny mus ical perc eptua l pro pert ies expl oited by other effor ts for music ta sks. This provid es a promising ar gument to the generalization o f the MCLNN to m ultidimensional temporal signals othe r than spectro grams, which we will consi der in future work. VI. C ONCLUS IONS AND F U TUR E W OR K We have ex plored t he ConditionaL Neur al Network (CLNN ) and the M asked Condi tiona L Neural Network designed for multidimens ional t emporal signal recognit ion. The CLNN pre serve s the inter - fram e relations , and th e MCLNN extends TA B LE II. P ERFORMANCE ON B ALLROOM DATASET USING MC LN N COMPARED WITH ATTEMP TS IN THE LITERATURE Cla ssif ier and Featu res Acc . % SVM + 2 8 fea ture wi th Tem po [ 19 ] 96.13 KNN + M odu latio n Scale Sp ect rum [ 20 ] 93.12 Man hatt an Dist ance + Block - Level f eatu res [ 21 ] 92.44 MCLNN ( Shallow , n = 20 , k = 55 ) + Me l - Spec. (thi s work) 92.12 MCLNN (Deep, n =15, k =10)+ Mel - S pec . [ 10 ] 90.40 SVM + Rhyth., H ist., Sta tist., Ons et, Sy mb. [ 23 ] 90.4 0 KNN + 15 MFCC - like de scri ptors with Temp o [ 22 ] 90.1 0 KN N + Rhythm and Tim bre [ 24 ] 89.2 0 SVM + 2 8 fea tures wi thout Tem po [ 19 ] 88.0 0 CNN+ M el - Scal ed Spectrog ram [ 15 ] 87.68 SVM + Rhyth. + His t. + S tatist. fe ature s [ 25 ] 84.2 0 KNN + Tempo [ 22 ] 82.3 0 TA B LE I II. M C LN N COMPARED WITH P ONS ET A L . [ 15 ] C ONVOLUTIONAL N EURAL N ETWORK PERFORMANCE FOR THE B ALL ROOM Cla ssif ier and Featu res Acc . % ± S td . MCLNN + Mel - Scaled Sp ectro gram (this work ) 92 . 12 ± 2. 94 Tim e - Fre quency pr e - tr ained CN N 87.6 8 ± 4.44 Black - Box CNN 87.2 5 ± 3.39 Tim e - Fre quency CN N 86.5 4 ± 4.29 Time Fi lter - CNN 81.7 9 ± 4.72 Fre quency F ilter - CNN 59.5 9 ± 5.82 Fig. 6 . Ballroom confu sion usi ng MCLNN. Cha Ch a (CC) , Jive (Ji), Quickst ep (QS) , Rumba (R u) , Sa mba (Sa) , Ta ngo (Ta ) , V ienn ese Walt z (VW) and Slow Walt z ( Wa) upon the C LNN by enforcing a masking op eration over the network’s links that follow s a band - lik e represent ation mimicking a filt erbank. The masking process indu ces t he ne t wo rk t o l e arn in frequen cy ban d s and assist a n eur o n in t he hidden layer to b e an expert i n a localize d regi o n of the featu re vector . The mask als o aut o m ates th e explorat ion o f a ran ge o f featur e com b inati o n s c oncurrent ly, analogous to the manua l optimization o f m ixing and m atc hing d iff eren t feature combina tions for a recognitio n task. MCLNN outperf orm ed several sta te - of - the - art handcrafted a nd Convol utional Neural Ne t wo r ks based att empts for the music genr e recognition task using the Ballro om music genre dataset . MCLNN achieved these accura cies without applying any aug mentatio ns or depe nding on a ny musical perceptu al f eatures used by o th er attempts. Future w o rk w ill expl o re differe nt MC LNN architectures w ith optimized m asking patterns and differen t orde r n across th e MCLNN l ayers . Fut ure work w ill co nsid er applying the M CLNN to other mu lt i- channel t empo ral sig nal repres entations o the r t ha n sou nd. R EFERENCES [1] L . R. Rabi ner, "A Tutor ial on H idden Mar kov Mo dels a nd Se lec ted Applic ation s in Speech Recognit ion," Proc eedi ngs of the IEE E, vol. 77, pp. 25 7 - 286, 1 989. [2] A . Krizhev sky, I . Sutskeve r, and G. E. H inton, "I mageNet Clas sificat ion wit h De ep Co nvolut ional Neural Netw ork s," in Neural Inform ati on Processing System s, N IPS , 201 2. [3] Y . Le Cun, L. Bo ttou, Y . Beng io, an d P. H affner, "G radient - base d learni ng appli ed to d ocument r ecogniti on," Proce edi ngs of the I EEE, vol. 86, pp. 2278 - 23 24, 1998. [4] C. K ereliuk, B. L . Sturm, and J . Larse n, "Deep Le arning an d Music Adversaries, " IEEE Trans actions on Multi med ia, vol. 17 , pp. 2059 - 2071 , 2015. [5] O . Abdel - Hamid, A. - R. Mohamed, H . Jiang, L . Deng, G . Penn, an d D. Yu, "Convolu tiona l Neural Networks for Sp ee ch Recogn ition, " IE EE/AC M Trans actio ns on Au dio , Spee ch and Lan gua ge Pr oces sing , vol. 22, pp. 1533 - 15 45, Oct 2014. [6] P . Barros , C. We ber, an d S. We r mter , "Lear n ing A uditory Neural Represen tation s for Emoti on Recognit ion," in IEEE Int ernationa l Join t Conf erence on Neural Networks (I JC NN/WCCI ) , 2016. [7] P. Hamel an d D. Eck , "Learni ng Feat ures From Mus ic Audi o With Deep Beli ef Net work s," i n Int ernation al Soc iety f or Mu sic In formation Retrie val Conf erence, I S MIR , 2010 . [8] G . E. Hinto n and R. R. Sala khut di no v, "Redu cing the Di mensionali ty of Data w ith Ne ural Ne tworks," Science , vol. 3 13, pp . 504 - 7, Jul 28 2006. [9] F . Med hat, D. Ch esmore, and J. Robinson , "Masked C onditi onal Neural Netw orks for Audio Cl assifica tion, " in Inte rnational Confe rence on Art ificia l Neu ral Netw orks ( ICANN) , 2017. [10] F . Medhat, D. Chesm ore , and J. Robinso n, "Music G enre Classif ication usin g Masked Conditi onal Neural Network s," in Inte rnationa l Conferenc e on N eural Inform ation P roc ess ing (IC ONIP) , 2017. [11] S. E . Fahlman, G. E. H inton , and T. J. Se jnow ski, " Massiv ely Parallel Ar chitecture s for Al: N ETL, T histle, and Boltz mann Machine s," i n Natio nal Confer ence on Arti ficial Intel ligence , AAAI , 1983 . [12] G . W. Taylo r, G. E. Hinton, and S. Roweis, "Modeli ng Human Moti on Using Bi nary L at en t V ariab les," i n Advan ces in Neu ral Informatio n Processing Systems, NIPS , 2006, pp. 1 345 - 1352 . [13] A. - R. M ohamed and G. Hint on, "Phone Rec ognition Us ing Restri cted Boltzma nn Machin es " i n IEEE Intern ational Conf erence on Acou stics Spee ch and Sign al Pr oc essing, ICASSP , 2 010. [14] E. Batt enber g and D. Wessel, " Ana lyzin g Dru m Patt erns Us ing Cond iti onal Deep Beli ef Net work s," in Inte rnatio nal Soci ety for M usic Infor mation Ret riev al, ISM IR , 2012. [15] J. Po ns, T. Lidy , and X. Serr a, "Expe rime nting w ith Musica ll y Motivate d Conv ol utio nal N eural N etw orks," in I ntern ati onal W orkshop on Con tent - based Mu ltimedi a Indexing, CBMI , 2016 . [16] F . Go uyon, A . Klapuri , S. Dixo n, M. Al onso, G . Tz an etakis, C. Uhl e , et al. , "A n experi menta l comparison of aud io tempo induct ion algorith ms," IEEE Tra nsac tions o n Audio, Speec h an d Lan guage P roce ss ing , vol. 14, pp. 1 832 - 1844 , 2006. [17] D. King ma a nd J. B a, "A DAM: A Method For Sto chastic O ptimiza tion," in Internat ional Confe rence fo r Learning Representat ions, ICLR , 2015 . [18] N. Sri vastava , G. H inton, A . Krizhevs ky, I . Sutskeve r, and R. Sal akhu tdino v, "Dro pout: A Simple Way to Preve nt Ne ural Ne tw orks from Overfitt ing," Jour nal of M achine Lear ning Re sear ch, JM LR, vol. 15, pp. 1 929 - 1958 , 2014. [19] G . Peeters, " Spectral and Te mporal Pe riodic ity Re pres entat ions of Rhythm for the Auto matic Class ificatio n of M u sic Audio Sig nal," IEEE Tran sactions on A udio, Spe ech, and Langu age Proc essing, vol. 19, pp. 1242 - 12 52, 2011. [20] U. Marchand and G. Peeters, "The Modulati on Scale Spect rum and its Appl ication to Rhy thm - Conten t Descript ion," in Internat ional C onferen ce on Dig ital Aud io Effe cts (DA Fx) , 2 014. [21] K. Seyer lehn er, M . Sch edl, T. P ohle, and P. Knees , "Us in g Block - Level Feat ures for Gen re Cla ssif icati on, Ta g Clas sifi catio n and Mus ic Sim ilarity Estim atio n," i n Music I nform atio n Retriev al eXc hange, M IRE X , 20 10. [22] F . Gouyon, S. Dixon , E. Pam palk, and G . Widmer, " Eval uating Rhythmic Descri pt ors for Music al Genre Cla ssi ficati on," in Internatio nal AES con feren ce , 20 04. [23] T . L idy, A. Ra uber, A . Pertusa , and J. M. I nesta, "I mproving Ge nre Class ifica tion By Combi natio n Of A ud io A nd Symbo lic De scriptors Using A Transcr iption S ys tem, " in I nternat ional C onf ere nce o n Mus ic Infor mation Ret riev al , 2007 . [24] T . Pohl e, D. S chnitze r, M. Sc hedl, P. K nees, and G . Widme r, "On R hyt hm And Gene ral Mu sic S imilar ity," in Intern ati onal Soc iety for Music Infor mation Ret riev al, ISM IR , 2009. [25] T . Lidy and A. Raube r, "Evaluat ion Of Fe ature Ex tracto rs A n d Ps ycho - Aco ustic Transfo rmations F or Music G enre Cla ssifica tion," in Inte rnational Confe rence on Music Informa tion Re trieval , ISMIR , 2005. [26] A . Ly kartsis, Chih - W eiW u, and A . Lerch, " Beat Histog ram Feature s from NMF - Based Novelt y Functi ons for Music Classi ficat ion," in Inte rnational Socie ty fo r Music I nfo rmatio n Retr ieva l, ISM IR , 20 15.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment