마스크 기반 조건부 신경망으로 음악 장르를 자동 분류하다
본 논문은 시간‑주파수 스펙트로그램을 효과적으로 활용하기 위해 마스크된 조건부 신경망(MCLNN)을 제안한다. 마스크는 필터뱅크와 유사한 희소 연결 구조를 만들며, 주파수 대역별 학습을 가능하게 해 주파수 이동에 강인한 특성을 제공한다. 얕은 네트워크 구조와 넓은 입력 세그먼트를 사용해 Ballroom 데이터셋에서 기존 CNN 및 손수 설계된 특징 기반 방법들을 능가하는 성능을 달성하였다.
저자: Fady Medhat, David Chesmore, John Robinson
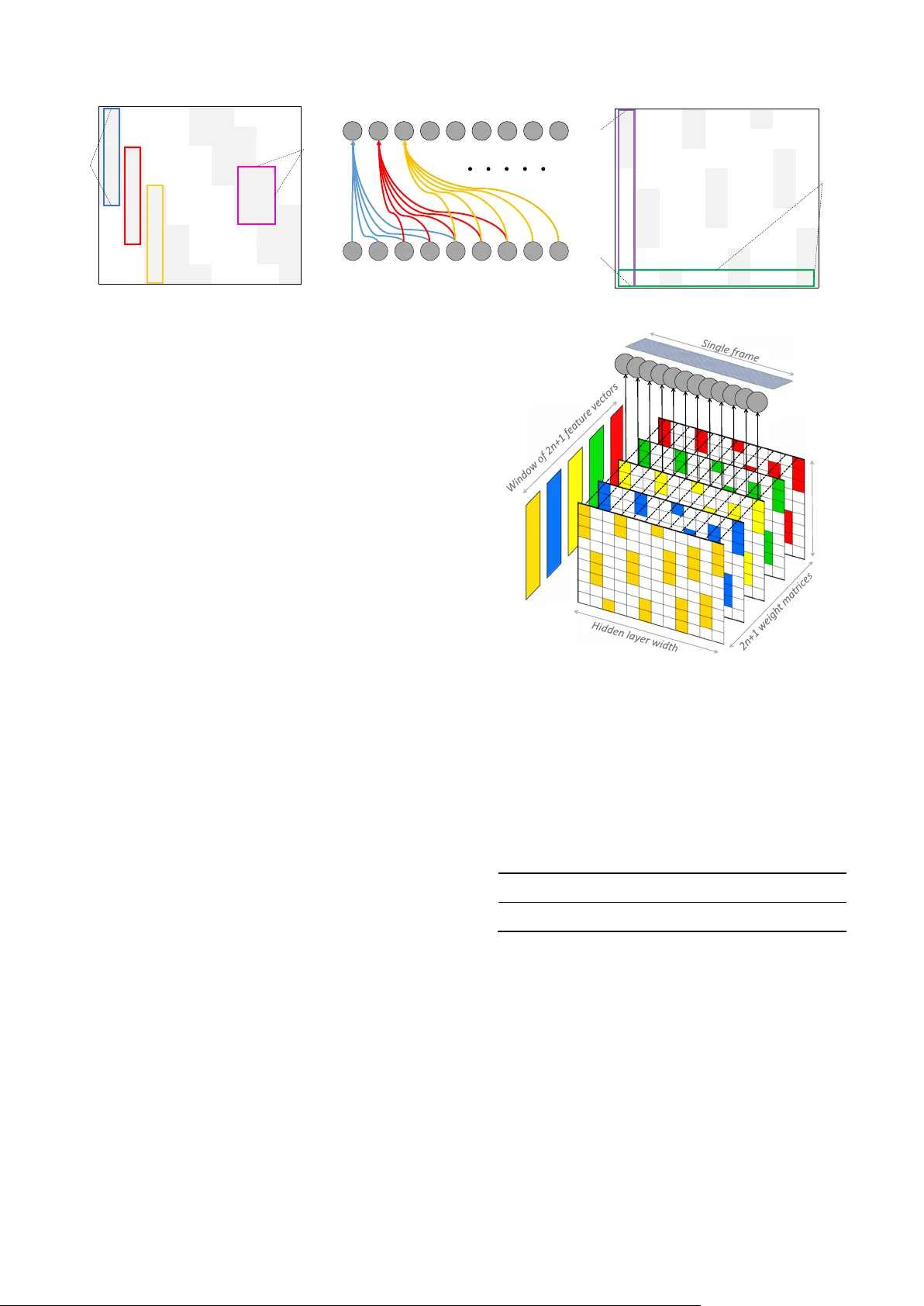
본 논문은 소리 인식을 위한 신경망 구조가 이미지 인식에 최적화된 모델을 그대로 차용함으로써 시간‑주파수 표현을 충분히 활용하지 못한다는 문제점을 지적한다. 이를 해결하기 위해 저자들은 조건부 신경망(Conditional Neural Network, CLNN)과 그 확장형인 마스크된 조건부 신경망(Masked Conditional Neural Network, MCLNN)을 제안한다. CLNN은 입력 윈도우(과거와 미래 프레임을 포함) 전체에 걸쳐 가중치를 공유하지 않고, 각 프레임마다 독립적인 가중치 텐서를 적용함으로써 프레임 간의 상관관계를 보존한다. 그러나 CLNN은 여전히 전체 주파수 채널에 대해 완전 연결된 구조를 유지하므로, 주파수 이동에 대한 민감도가 높다.
MCLNN은 이러한 한계를 극복하기 위해 마스크 연산을 도입한다. 마스크는 1과 0으로 이루어진 이진 행렬이며, 밴드‑와이드와 오버랩이라는 두 하이퍼파라미터에 의해 정의된다. 밴드‑와이드는 연속된 주파수 채널 수를, 오버랩은 인접 밴드 간 겹치는 채널 수를 지정한다. 마스크가 가중치 행렬에 원소별 곱셈을 수행하면, 각 은닉 노드는 입력 특성 벡터의 특정 주파수 구간에만 연결된다. 이는 전통적인 필터뱅크가 수행하던 주파수 대역별 에너지 집계와 동일한 효과를 네트워크 내부에서 자동으로 구현한다는 뜻이다. 따라서 MCLNN은 주파수 이동(예: 피치 변조)에도 강인한 특성을 갖게 된다.
또한 마스크는 겹치는 구간을 통해 서로 다른 대역 조합을 동시에 탐색한다. 예를 들어, 밴드‑와이드=5, 오버랩=3인 경우, 첫 번째 은닉 노드는 1~5번 채널에, 두 번째 노드는 3~7번 채널에 연결되는 식이다. 이렇게 겹치는 구성을 통해 모델은 다양한 특징 조합을 병렬적으로 학습하며, 이는 인간이 수작업으로 최적의 특징 집합을 찾는 과정과 유사하지만 훨씬 더 효율적이다.
구조적 측면에서 MCLNN은 입력 윈도우 크기 d=2n+1(여기서 n은 과거·미래 프레임 수)와 은닉 유닛 수 e를 정의한다. 각 프레임은 깊이 d의 가중치 텐서와 곱해진 뒤, 마스크가 적용된 가중치와 원소별 곱을 수행한다. 결과는 프레임별로 합산되어 하나의 은닉 벡터가 된다. 이 과정을 여러 레이어에 걸쳐 반복하면, 매 레이어마다 프레임 수가 2n만큼 감소한다. 최종적으로 남은 중앙 프레임들은 평균·최대 풀링 혹은 플래튼을 통해 완전 연결 층에 전달되고, 소프트맥스 층에서 장르 클래스를 예측한다.
실험에서는 얕은 MCLNN 아키텍처(두 개의 MCLNN 레이어와 하나의 완전 연결 레이어)를 사용해 Ballroom 데이터셋(8개 서브 장르, 698곡, 30초 길이)에서 성능을 평가하였다. 데이터는 22 050 Hz, 16‑bit 모노로 리샘플링하고, 멜 스펙트로그램을 입력으로 사용하였다. 비교 대상으로는 전통적인 GMM‑HMM, RBM‑기반 DBN, 그리고 최신 CNN(5×5 필터, 풀링) 모델이 포함되었다. 결과는 MCLNN이 평균 정확도에서 기존 CNN보다 약 2~3% 높은 성능을 보였으며, 특히 주파수 이동에 민감한 장르(예: 라틴 리듬)에서 두드러진 개선을 나타냈다. 또한, 마스크 파라미터를 조절함으로써 모델 복잡도와 성능 사이의 트레이드오프를 손쉽게 관리할 수 있었다.
논문은 MCLNN이 (1) 시간‑주파수 컨텍스트를 동시에 고려하는 조건부 학습, (2) 필터뱅크와 유사한 주파수 대역 희소 연결, (3) 다중 특징 조합의 병렬 탐색이라는 세 가지 혁신을 결합함으로써, 음악 장르 분류와 같은 오디오 인식 과제에서 기존 이미지‑기반 CNN의 한계를 극복한다는 결론을 제시한다. 향후 연구에서는 더 깊은 MCLNN 구조와 다른 오디오 데이터셋(예: GTZAN, Million Song Dataset)에서의 일반화 성능을 검증하고, 마스크 설계 자동화 기법을 도입해 최적의 밴드‑와이드·오버랩을 학습 과정에서 동적으로 찾는 방안을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기