Towards Vulnerability Analysis of Voice-Driven Interfaces and Countermeasures for Replay
Fake audio detection is expected to become an important research area in the field of smart speakers such as Google Home, Amazon Echo and chatbots developed for these platforms. This paper presents replay attack vulnerability of voice-driven interfac…
Authors: Khalid Mahmood Malik, Hafiz Malik, Rol
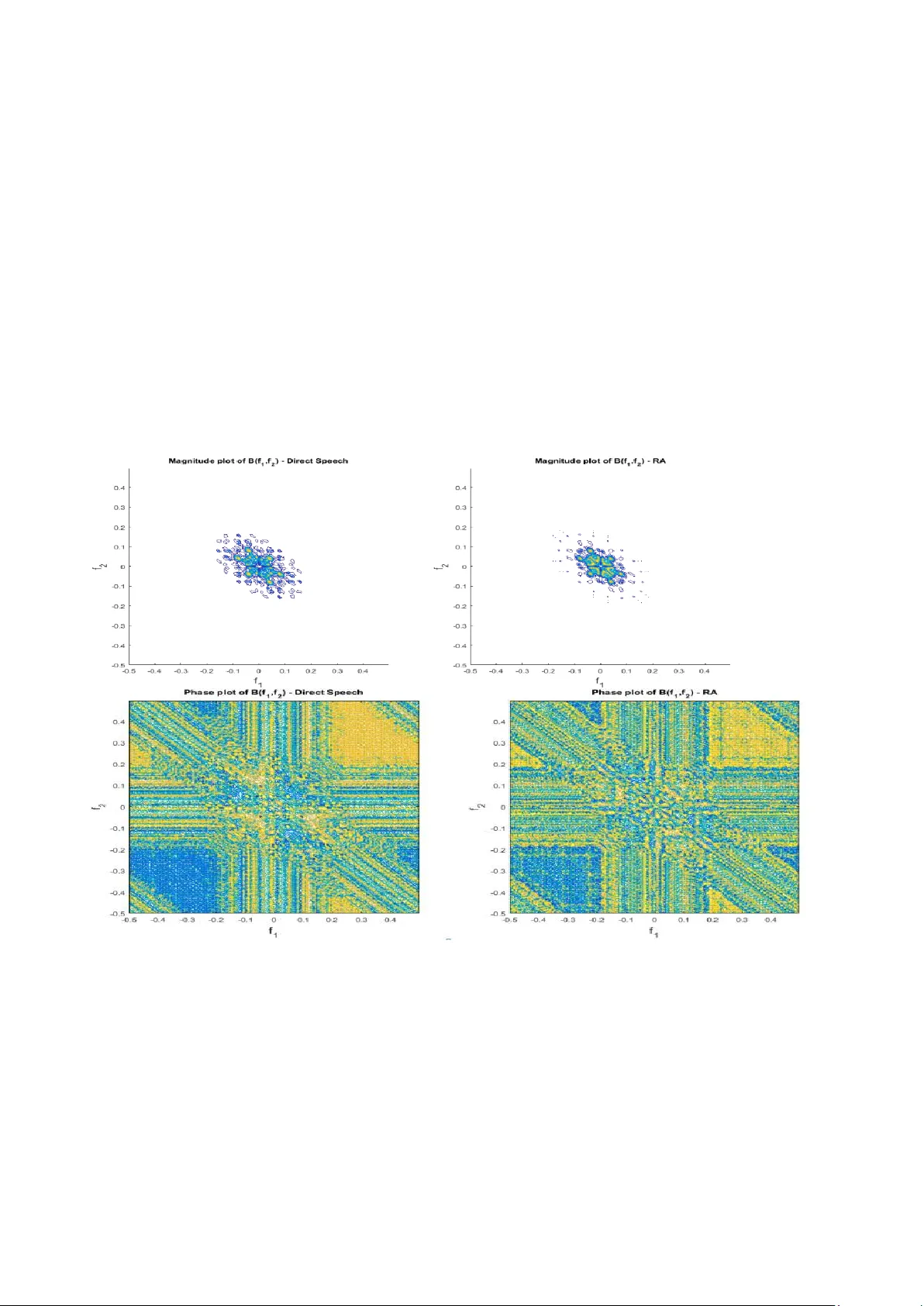
X XX -X-XXXX- XXXX -X/XX /$XX.00 ©20XX I EEE Towards Vulnerability Analysis of Voice-Driven Interfaces and Countermeasures for Replay Attacks Khalid Mahmood Malik School of Engineering and Computer Science Oakland University Rochester, MI, 48309, USA mahmood@oakland.edu Hafiz Malik College of Engineering and Computer Science, University of Michigan- Dearborn Dearborn, MI, 48128, USA hafiz@umich.edu Roland Baumann School of Engineering and Computer Science Oakland University Rochester, MI, 48309, USA rbaumann@oakland.edu Abstract — Fake audio detection is expected to become an important research area in the field of smart speakers such as Google Home, Amazo n Echo and chatbots developed for these platfor m s . This pa per presents replay attac k vulnerability of voice - driven interfaces and pr oposes a countermeasure to detect replay attack on these platforms . This paper presents a novel frame w ork to model repla y attack disto rtion, and then use a non -learning-based method for rep lay attac k detectio n on smart spea k ers. The reply attack distortio n is modeled as a hi g her-order nonlinearity in the replay attack audio. Higher -order spectral analysis (HOSA) is used to cap tu re c haracteristics distor tion s in the replay a udio. Effective n ess of the proposed countermeasure scheme is evaluated on o rigin al speech as well as corresponding repla y ed recordings. T h e r eplay attack recordings are successfully i njected into the Go ogle Home device via Amazon Alexa u sing t h e d rop-in conferenci ng feature. Keywords — Automatic Speak er Verification, Voice-Dr iven Interfaces , Vulnerability a n alysis of Google Hom e and Amazon Ech o, Audio replay attack, higher- or der spectral analysis (HOSA) I. I NTRODUCTI ON The g row ing trend of personaliza tion, inc reasing num ber of smart homes, the desire for eas y control of home IoT devices and rising consumer preferen ce for luxurious enterta inm ent system s are driving fact ors f or the tremendous grow th of smart speakers . Alon e in 2017, app roxim ately 40 millio n adults in the United States have adopted voice activated smart speakers. With a compound annual growth rate of 35%, global smart speake r market is pr ojected to rise during forecast period 2017-2024 [1]. Gartner estimated that by 2020, 75% of US househ olds are expected to have voice- driven interfaces , e.g., Alex a, Cortana, Google Ass istant, Siri, and, s o on [2] , and worldw ide spendin g on the se platf orm s and devic es i s expected to be more than $3.5 billion b y 2021 [3 ]. Currently , base d on intell igent virtual assistant use d in sm art speakers, market leaders inclu de Alexa, Cortana, Google Assistan t, and Si ri . Various home and office v oice-driv en applicati ons rely on softw are developm ent platfor ms provided by Alexa skills and Google A ction. It is estimated that cur rently chat bots are h andling a round 30 % of cust omer - service re quests, an d by 20 20 chatbots are ex pected to han dle 85 % of customer-se rvice interactions [4] . In addition , through voice, intelligent virtual assistants and sm art speakers are being used to rem otely control different Internet of things (IoT) gadgets such as cont rolling th ermostats and doorlocks . Therefor e, it becomes i m perative t o secure the voice-drive interfaces an d associat ed applic ations an d acces s control sy stem s ( speak er r e cog nition s ystem s) are vu lnera ble to replay audio (RA) attacks, impers onati on, speech synthesis and v oice convers ion. Smart speakers enables attacker to r em otely attack voice-driven interf aces and applicati ons. Among these fou r attacks , audio replay is the easiest to exploit [6], whereby the pre-recorded speech of the target speaker is played back to for autom atic speaker verificati on (ASV) task. The ASV , a key component of voice-base d authenti cation and access control system s, is a process of the auth entica ti ng u sers by doing an aly sis on the ir speech utter ances. T h e ASV has received signif icant attention in the last two decades due to its convenience , low cost, and rem ote operability with simple devices like m obile phones. The role of ASV is expected to increase furthe r due to prolif eration of voice-driv en interf aces and virtual personal assistan t-enabl ed wireless speake rs. Many technologies are used for ASV such as frequen cy eestimati on , hidden Markov models, Gaussian mixture models, vector quantizati on, decision trees, and neural netw orks [5]. The ASVspoof 2017 Challeng e [18] was focused on the ex ploiting sho rtcomin gs of existing state- of - the-art to detect replay attacks under diverse conditions . Efforts hav e been mad e to inv estigate replay att acks o n ASV system s [12 – 17]. For inst ance, Patil et al. in [ 12 ] study the spectral changes d u e to the transm ission and channel character istic o f replay device s for replay detection . Another attempt was made to capture the channel informati on embedded in the low signal to noise ratio region, a single frequency filtering feature with high spectro-temporal resoluti on was prop osed in [ 13 ]. Most of the presented w orks in ASVspoof 2 017 challenge used a combination of different features and classifie rs t o improve perform ance of replay detecti on sy stem . The combined featu re vector include constant Q cepstral coeffici ents, m el - frequency cepstral coefficients , linea r frequency cepstral coef ficients , rectangula r filter cepstral coeffici ents, perceptual linear predictive and d e ep features as front-en ds [ 14 , 15 ]. Magnitude- based features are widely used in replay attack detecti on, [ 14 , 15 ], and frequency modulation (F M ) featur es have been us ed in s peech recognition and s peaker recognit ion [ 16 , 17 ]. It has been demonstrate d that replay attack intr oduces distorti ons in th e spoofed speech [9,10]. Most existing stat e of the art methods mainly rely on machine learning based approaches . These approach es process the input speech signal for featu re extra ction that are use d to train a classif ier to learn the underlyin g disto rtion model. For example , [ 19 ] authors proposed lig ht convo lutional n eural n etwork (LCNN) classifi er to extract high-lev el features from the log power spectrum , together with a Gaussian Mixture Model (GMM). GMM, support vector machine (SVM) and i-v ector Gaussia n probabilis tic linear d is crim inant analysis were employed as back-end class ifiers [ 20 ]. H owever, little work has been done on replay attack detection using higher-order spectra l analysis (HOSA) features to captur e traces of replay attack distorti on and detecti on. Additionally , no work has been reporte d to study p oss ibility of replay attack s and their counterm easures in sm art s peak ers’ envi ronm ent. Th is main cont ributions of this paper ar e: 1. T h is paper demonstrat es that ASV feature of voice- driven interfa ces, e.g., Googl e H ome is vu lnera ble t o replay attacks an d thus all the skills and ac t ions built o n these platform , including many having critical financia l data, could b e exploited easil y even by relativ ely less tech savv y im personators . 2. According to best of our knowledge, there does n ot exist any attempt for the vuln erability analysis and exploitati on of audi o replay attack on Google hom e and Amazon Alex a. 3. We have modeled replay attack as a higher-order linearity bey ond 6 th -orde r (see Fig ure 2) . 4. A countermeasure based on HOSA framew ork is proposed to detec t reply attack . II. V ULNERABILI TY A NALYSI S OF R EPLAY A TTA CKS IN S MART S PEAK ERS This section d escribes v u lnerability analysis and exploitation of audio r eplay to understand what i s the performance of Automatic Speaker Ver if ication ( A SV) system used in the Amazo n E ch o and Google Ho m e smar t speakers We cond u cted several experiments to deter m ine the capabilities of the A SV in these devices. A. Experiment 1 – Vulnerability Analysis of Replay Attacks in Amazon Echo We have tested the ASV capa bilities of th e Amazon Echo b y placing an order for small ite ms such as candy, as n on-ow ner of the device . Amazon Ech o ASV was unable to assess who was placing the orde r. Simila rly, we found that any person could use the Am azon Echo to turn on and off IoT connected lights in the h ome. Despite the f act that all of the f unctions of the A mazon E cho are available to any user we did rep l ay a recording of the device owner asking “Alexa, Who am I?”. The Am azon Echo replied with the devic e owners name. This further proved that what limited voice recognition the device has, it is not capable of distinguishin g recorded audio from a real voic e. B. Experiment 2 – Vulnerability Analysis of Replay Attacks in Google Ho me The Google Home device does us e v oice recognition to o f fer secure purchases and access control. Howev er, our experim ent revealed that the speaker verif ication is limited to authentic ating the wake word, usually “OK Google”. Once the w ake word has been us ed t o activat e the device n o furthe r voice ve rificati on is p erf ormed on subs equent c omm ands. This mak es it possible f or anyone that has a recording of the owner using the wake word to then have full access to the device. To verify that only the initial wake word “OK Google” is checked, we took a recording of the account owner say ing the wak e word and then ad ded in a completely differen t voice requesting to purchase someth ing. At no poi nt in time did the devic e question why a diffe rent voice w as given to the devi ce. In an other test, w e took a recording o f th e male account owner saying , “OK Googl e” and then foll owed i t up with a recording of a female voice sayin g, “Who am I?” the Googl e Home device resp onded with th e male account owners name. It shows that Google Hom e performs voice verificati on only on the w ake w ord. C. Exp eriment 3 – Introduction of mu ltiple replay s us ing Drop in co nference feature of Amazon Ech o. Experim ents 1 and 2 demonstrates that the speaker verificati on capabilities of the current g enerati on of sm art speaker devices are limited. W h ile o n the surface it appears that sin ce smart sp eakers are locat ed w ithin the users home the d am age to be done is l imited t o som e m ischief b y p e ople near the device. We considered if the capa biliti es o f smart speakers could be ex ploited to un lock an I o T c onnecte d door sy stem or change the sett ings o n an IoT connected thermostat . To bette r underst and the severity of audio repl ay attacks, consider a hom e that uses a Google Hom e device to control a door lock. A ll th at woul d be r equired t o un lock the doors of that hom e w ould be a replay of the owner using the wake word. T h is coul d be a genuine copy or a sy nthesize d voice. Once the wake w ord is played and accepte d, any voic e could requ est th e doors to be u nlocke d. For this experim ent we hid an Amazon Echo device behind a TV. We then used the Drop In Audio conferencing feature of the Am azon Alexa to replay voice recordings to the Google Home Speake r. We were able to replay a recording of “OK, Google, T u rn o n Office Lamp” via the audio conferenced Amazon Alexa from another hom e. T h e Google Hom e device did turn on and off t he lights as re queste d in the replay s. One can envisage that wh ile the Drop- In feature of the Amazon E cho m ade it ve ry easy to pe rform this type of attack, it would be relatively easy to use o th er equipmen t to replay the att ack int o a person' s home. For example , one can use a Raspbery PI equipp ed with an MP3 board to re play the required sounds to get the sm art speaker t o unlock th e d oors. For the Internet conne ctivity required to perpetuate this type of attack this could be d one by kno w ing the home o w ners WiFi key o r using a Cellul ar WiFi hotspot device . III. R EPLAY A TTACK M ODELING It has bee n demonstrated that replay attac k in troduces distortions in the spoo f ed speech [9 ,10]. Mo st of existing state of the art mainly rel y on machine learning based methods. These a pproaches process the input speech signal for feature extraction that ar e used to train a classifier to learn the underl y ing distortion model. In this paper, we present a framework to model replay attack d istortion, and then use a non-learning-bas ed method for replay attac k detection o n smart speaker s. As shown in Fig u re 2, th e microphone a n d spea ker are modeled as no n-linear devices. T he Mic -Spea ker- Mic ( MS M ) processing chain o f the replay attack, t herefore, is expected to introduce no n linearity in t h e resulting rep lay a ttack signal generated using proposed Alexa drop - in attack. IV. R EP L AY A TTACK D ETECTION F RA MEWORK FOR S MART S PEAK ERS We propose to use higher -order spectral analysis (HOSA)-based features to capture traces of replay attack distortion and thu s detect the m . Details o f the pro posed approach is provided in the follo w ing subsections . A. HOS A-based detection: The microphone/speci f ic d istortions suc h as harmonic – , intermodulation (IM) – , and difference - frequency (DF) – distortions. The presence of harmonic components at the output of a nonlinear system with pure tone input is called as harmonic d istortion. System nonlinearit y can ca us e IM distortion in the output when a co m plex signal (e.g., speech) is applied at the input o f a nonlinear system. It causes the output signal to be sum s and dif ferences of the inpu t signals fundamental frequencies and t h eir har m onics, that is, , , , etc. Given a nonlinear system is excited with sum of si nusoids with same magnitudes then syste m nonlinearity can cause difference - frequency d istortion at the output, e.g., , , , etc. It has b een shown in [ 9] that m icrophone resp ons e ca n be approximated usi n g following discrete time-invariant Hammerstein serie s m odel, The microphone ( resp. speaker ) nonlinearity in troduces hi gher - order correlations at its output. T he MSM processing chain, t h erefore, can be modeled using a higher -order nonlinear system. T o capture it HOSA is used. Specifical ly , higher-order cu m ulants (resp. bicoherence ) [8] is u sed to capture higher-order corre lati ons. The bicoherence, , of a signal y [ n ] is a normalized version o f 2 - dimensional Fourier transform of the third -order cu mulants, that is, Here, deno te s third-ord er cumulant o f y [ n ] , and is defined as, Here, E{.} denotes expectati on. Sometimes, it i s more convenient to use t he nor m alized value of the b is pectru m which is also k nown as bicoherence. T his bicoherence is given by the follo w ing equation [8], It is i m portant to highlight impact of nonlinearit y o n bicoherence spectrum. Consider a pair of sinusoids with frequencies and ; the IM distortion will result in a ne w signal a t whose magnitude is correlate d to and , which will result in a high magnitude value in the bicoherence magnitude. Moreover, if the input sinusoids have p hases, and , then the phase of the no n linearit y Figure 1: A scenario of Drop-in conferencing features of Echo device to generate replay attack on Google Home’s ASV system Figure 2: Repla y attack modeling induced inter m odulation co mponents are . It is easy to see that the bicoherence has a zero p h ase a n d a bias towards / 2 m ay also occur due to harmonic auto- correlations. In general, the a v erage b icoherence magnitude would increase as the a m ount of quadratic phase-coupling (QPC ) gro w s. It ca n be co ncluded that a r eplay attack is expected to: (i) increase in the m agnitud e of bicoherence for certain harm onics, and (ii) the p h ase of bicohere n ce bia s towards 0 and/or / 2 at IM distortion frequencies. To capture traces of a replay attack, inter m odulation distortion, QPC, Gaussianit y test statis tics, a nd linearity statistics can b e used. For this pap er, QPC, Gaussianity tes t statistics, and lin earity statist ics are us ed. The m otivation behind focusing on inter m odulation disto rtion is that it is more do m inant in t h e cloned signal. To verify this claim, w e estimated the bicohere nce from bot h the speech and t h e corresponding cloned reco rdi ngs. Shown in the left panel of Fig. 3 is the b icoherence magnit u de plo t of an audio recordi n g and in the r ig ht panel is the bico h erence magnitude plot of the clo ned recording. Figure 3 : Shown in the top-left panel is the b ico herence magnitude plot for direct recording and top-right panel is the corresponding RA recoding. In the left-bottom panel is the phase bicoherence phase plot for the direct and RA recordings. It can be observed from Fi g. 3 that there is si gnificant intermodulation distortion spread in the both bicoherence magnitude and phase spec tra replay-audio reco rding s. 3.2 Gaussianity test statistics and linearity test statistics- based detection : Gaussianity and linearity statistics tests can also be used to confirm non -Gaussianity and nonlinearit y in a give n stationary time series. It is re asonable to assu m e that b ona- fide and rela y attack speech signals are stationarity sequences. Moreo v er, bone- f ide speech signal is al so modeled as a non-Ga ussian random sequence. The MSM processing cha in of replay attack is expected to introduce nonlinearity in the resulting sequence. Let x( n) is no n- Gaussian speech sequence and y(n ) is linear non -Gaussian sequence o f replay attack. How do w e kn ow that x[n] i s non-Gaussian and y[n] is non-Gaussi n a and nonlinear? To achieve this goal, Hinich’s non-skewness (also kn own as Gaussianity) and linearit y tests [ 11 ] is used. These tests rela y o n the fact that i f the 3 rd -order cumulants of a stationary process are zero, th en its bico h erence is zero , and non-zero bico h erence i m plies that pr ocess is non - Gaussian. Moreo ver, if that t he pr ocess is linear and non- Gaussian, then the bico herence is a nonzero constant. Following binar y hypothesis testing ca n be us ed for no n- Gaussianity and no n linearity detection: H1 : the bispectrum of y (n) is nonzero and not co nstant; H0 : the bispectrum of y (n) is nonzero and constant. V. E XPERI MENTAL R ESULTS For data collectio n, w e used the Dro p In A udio conferencin g feature of the Amazon Alexa to replay voice record in gs to the Google Ho me Spea k er. W e r eplay ed a reco rding of “OK, Google, Turn on Office Lamp” via the aud io- conferenced Amazon Alexa from another home. In second settings, w e tu rned on and off the lights us ing Google Ho m e remotely usin g Drop -in features of Alexa, as descr ibed in Figure 01 . A total of 12 original recor ding s were replayed twice a) once at 1 st point of replay to o btain set of t welve 1 st order replay audios; b) The 1 st order replay audios were replayed agai n at 2 nd po in t to get another set o f 2 nd ord e r replay cloned audios (See Fig.1). Next, we p erf ormed following three experi m ents. Experiment 1: The goal of this e x periment is to investigate impact o f replay attack on bichorence magnitude and phase spectra. To this end, b oth the direct spee ch a n d RA recordings are segmented into fra m es of duratio n w ith a 50% o v erlapping f actor. B icoherence i s e stimated from each audio segment using the dir ect (fft-based ) ap proach [ 8]. The bicoherence is estimated with t h e following par ameter settings: 1) 1024-point segment length, 2) 1024-point FFT length, 3 ) 50% overlap , and 4) Rao-Gabr opti m al windo w for frequency domain s m oothing. Shown in Fi g . 4 are the bispectrum magnitude an d phase plo ts estimated fro m direct speech a nd corresp ondin g RA reco rdings for thir d successful attack. It can b e observed fro m Fi g . 4 that RA causes hi gher-order nonlinearity which is e vident both in the magnitude and phase sp ectra. Si m ilar, observations are made for o th er two other attacks. Ex periment 2: The goal of this e xperiment is to investigate i m pact of repla y attac k on Gaussianit y tes t statistics and linearit y test statistics. T o this e nd, test statistics is calc ulated fro m b oth bona - fide and rep lay speech signals. T o achieve this goal, Hinch’ s Gaussianity and linearity test statistics is calculated using glstat fu nction available in the HOS A Matla b Toolbox [21], w hich can be used to estimate both Gau ss ianity test statistics and li nearity test statistics. Frame - level Gaussianity te st statistics and linearity test s tatis tics are e stimated from d irect and RA attack recordings. It i s obs erved that for all three RA recordings ever y non -silence fra m e failed Gaussianity and linearity test; whereas, all three d irect recordings only less than 35% non-silence frames failed Gaus sianity an d linearity test. T h ese findings confirm t hat RA introduce nonlinearity which can b e us ed fro m RA detection. Figure 4 : Shown in the top-left panel is the b ico herence magnitude plot for direct recording and top-right panel is the corresponding RA recoding for. In the left-bottom panel is the phase bicoherence phase plot for the direct and RA recordings. Experiment 3: T h e goal of this experiment is the investigate impact of 2 nd – order replay attack. I t is expected that of 2 nd – order w ould even introduce higher level of nonlinearity and stronger QPC. To validate this clai m , a 2 nd - order RA w as record ed for all three attacks. Parametric QPC detection is applied on three direct speech, three 1 st ord e r RA, and three 2 nd -order RA reco rding s. Sho w n in Fi g 5 are the scatter graphs of frame-level QPC freque ncy location s estimated from all nine rec ordin gs. It can b e observed from Fig. 5 that RA ca u ses shi f t of QP C peaks. This observation is consistent for all 1 st – and 2 nd – order replay attacks. Shift in QPC can be used for R A detection. C ONCLU SION This paper has demonstrate d that the automatic speaker verificati on sy stem used b y Goog le h ome and Amazon Echo gadgets is vulnerable to replay attacks and thus all the skill s and actions buil t on these platform, including many havin g critical financial data, could be exploite d easily even by relatively less tech savvy impersonators . We performed vulnerability analysis and detectio n o f r eplay attac k using a) Drop-in features of Alexa by exploiting the rep lay attac k at the Go ogle Home, b) A lexa default ser v ices as well as skill s developed using Alexa skills kit, c) Google ho m e voic e authentication. Evaluati on of pro posed fr amew ork show s that HOSA-base d features could be used to thw art replay attacks on Google Home and Amazon Alexa platf orm . More sp ecifical ly, we demonstrate d that RA caus es highe r-order nonlin earity which is evident both in the magnitu de and phase spectra . Our results confirm our hypothesis that non-linearity introduce d in RA can be u sed for its reli able det ection Figure 5: Scatter graph of frame-level QPC locations estimated from direct speech, 1 st – order RA, and 2 nd – order RA recordings. A CKNOWL EDGMENT This research is suppo rted by Nationa l Science Foundation (NSF) un der aw ards No. 18 15724 and 1816019. R EFERENCES [1] https://voicebot.ai/ 2017/04/14/gart ner-predicts- 75 - us - households- will-smart-speake rs-2020/ , Accessed on January 03, 2019 [2] Global Smart Speaker Market - Technolo gies, Market share and Industry Forecast to 2024, Occams Business Research and Consulting, Septembe r 2018, ht tps://ww w.re searchandmarkets.com /rese arch/kq9k7t/global_sm art , accessed on Jan uary 02, 2019. [3] https://www .gartner.com/en/new sroom/press-re leases/2017- 08 - 24 - gartner-say s-worldwide-spending- on -v pa-enabled-w ireless-speakers- will-top-3-billion- by -2021 , accessed on Ja nuary 02, 2019 . [4] https://www .inc.com/rebecca-hinds /by-2020-youre -more-likely - to - have-a-conver sation-with-this-than-w ith-yo ur-spouse.html, accessed on January 02, 2019. [5] Naika, R av ika. "An Overview of Automatic Sp e aker Verification Syste m." I n Intelligent Compu ting an d I nformation an d Communication, pp. 603-610. Spri nger , Singapore, 2018. [6] Nagarsheth, Parav, Elie Khoury , Kailash Patil , and Ma tt Garland. "Replay attack d e tection using dnn for channel d is crimination." In Proc. I nterspe ech, pp. 97-101. 2017. [7] Tharshini Gunendradasan, Buddhi Wickramasinghe, P hu N goc Le, Eliathamby Ambikairajah, Julien Epps “ Detection of Replay- Spoofing Attacks using Frequency M o dulation Fe atures ” In Proc. Interspee ch, pp. 636-640. 2018. [8] C.L. Nikias a nd A. P. P etropulu, “Hi gher -Orde r Spectral Analy sis: A Nonlinear Signal Processi ng Framew ork” Upper Saddle River, NJ: Prentice-Hall , 1993. [9] Malik, H. and M ill er, J., “Microphone Identification using Higher - Order Statistics,” in Proc. of 46th AES Conference on Audio Forensics, 201 2, June 14 – 16, Denve r, CO. [10] Malik, H., “Securing Spe aker Verification S ystem Against Rep lay Attack,” in Proc. of 46 th AES Conference on Audio Forensics, 2012, June 14 – 16, De nver, CO. [11] Hinich, M.J., “Testing for Gaussianity and linearity of a stationary time series,” J. T ime Serie s Analysis, Vo l. 3, pp. 169 -76, 1982. [12] H. A . Patil, M. R. Kamble, T. B. Patel, and M . Soni, "N ovel Variable Length Teager En e rgy Separation B ase d Instantaneous Fre quency Features for Re play De tection," Proc. I nterspeech, pp. 12-16, 2017. [13] K. Raju Al luri and A. K. V. Gangashetty, " SFF A nti -Spoof er: III T- H Submission for Automatic Speaker Verification Spoofing and Countermeasure s Challenge 2017," Proc. I nterspeech, pp. 107 -111, 2017. [14] V. Sethu, E. Ambika irajah, and J. Epps, "Group delay features for emotion dete ction," i n Eighth A nnual Confer ence o f the International Speech Commu nication A ssociation, 2007. [15] F. Allen, E. A mbikairajah, and J. Epps, "W arped mag nitude and phase-based features for language identification," International Conference on Acoustics, Speech and Signal Processing, vol. 1, pp. 201-204, 2006. [16] T. Thiruvaran, "A utomatic speaker r ecognition using phase base d features," Doctor of Philo sophy , Scho ol of Electrical Engi neering and Teleco mmunications, The University of New South Wales, 2009. [17] D. Dimitriadis, P . Maragos, and A. Potamia nos, "Robus t AMF M features for spee ch r ecognition," IEEE Signal Processing L etters, vol. 12, no. 9, pp. 6 21-624, 2005. [18] T. Kinnunen et al., "The ASVspoof 2017 Challenge: A ssessing t he Limits of Replay Spoofing Attack Dete ction," Proc. Interspe ech, pp.2-6, 2017. [19] G. L avrentyeva, S. Novoselov, E. Maly kh, A. Kozlov, O. Kudashev , and V. Shchemel inin, "Audio repl ay attack detection with deep learning framew orks," Pro c. Interspeech, 20 17. [20] Z. Ji et al., "Ensemble learning for countermeasure of audio replay spoofing attack in ASVspoof2017," Proc. Interspe ech, pp. 87-91, 2017. [21] A. Swami, J.M . Mendel , C.L. (Max) Nikias, “Higher -Order Spectral Analysis Tool box For Use with M ATLA B” User’s Guide v 2. 0, by United Signals & Sy stems, Inc. 1998
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment