스마트 스피커 음성 인터페이스의 재생 공격 취약성 분석 및 고차 스펙트럼 기반 방어 기법
본 논문은 Amazon Echo와 Google Home 등 음성 기반 스마트 스피커가 재생(Replay) 공격에 취약함을 실험적으로 입증하고, 마이크‑스피커‑마이크(MSM) 체인에서 발생하는 고차 비선형 왜곡을 모델링한다. 고차 스펙트럼 분석(HOSA) 중 바이코히런스와 그 파라미터(QPC, Gaussianity, Linear‑ity 테스트)를 활용해 학습‑비의존적인 재생 공격 탐지 프레임워크를 제안한다. 실험 결과, 제안 기법은 원본 음성과 …
저자: Khalid Mahmood Malik, Hafiz Malik, Rol
본 논문은 급속히 보급되고 있는 음성 기반 스마트 스피커(Amazon Echo, Google Home 등)의 보안 취약성을 재생(Replay) 공격 관점에서 심층 분석하고, 이를 방어하기 위한 새로운 비학습 기반 탐지 프레임워크를 제시한다.
먼저 서론에서는 스마트 스피커 시장의 성장과 함께 음성 인터페이스가 일상 생활 및 IoT 제어에 광범위하게 활용되고 있음을 강조한다. 이러한 환경에서 자동 화자 인증(ASV) 시스템은 사용자의 신원을 확인하는 핵심 보안 요소이지만, 기존 상용 제품은 ‘Wake‑Word’ 검증만 수행하고 이후 명령에 대한 화자 식별을 생략한다는 구조적 한계를 가지고 있다. 이를 근거로 논문은 재생 공격이 가장 손쉽게 구현될 수 있는 위협임을 제시한다.
다음으로 2장에서는 Amazon Echo와 Google Home을 대상으로 한 세 차례 실험을 상세히 기술한다. 실험 1에서는 Echo에 사전 녹음된 “Alexa, Who am I?” 명령을 재생했을 때, 장치가 실제 사용자의 이름을 응답함을 확인하였다. 실험 2에서는 Google Home에 “OK Google” 웨이크워드만 검증하고 이후 명령을 화자 구분 없이 수행한다는 점을 입증하였다. 실험 3에서는 Amazon Alexa의 Drop‑In 오디오 컨퍼런싱 기능을 이용해 원격에서 Google Home에 재생 명령을 전달, 조명 제어와 같은 실제 IoT 동작을 성공적으로 수행하였다. 이러한 실험 결과는 현재 상용 스마트 스피커가 재생 공격에 대해 거의 방어 메커니즘이 없으며, 심지어 원격 공격도 가능함을 보여준다.
3장에서는 재생 공격이 음성 신호에 미치는 왜곡 메커니즘을 이론적으로 모델링한다. 마이크와 스피커를 각각 비선형 장치로 가정하고, 마이크‑스피커‑마이크(MSM) 체인을 통해 발생하는 고차 비선형성을 6차 이상의 고차 비선형 모델로 표현한다. 이때 발생하는 고조파(Harmonic), 상호조화(Inter‑Modulation, IM), 차주파수(Difference‑Frequency) 왜곡이 재생 음성의 특징이 된다.
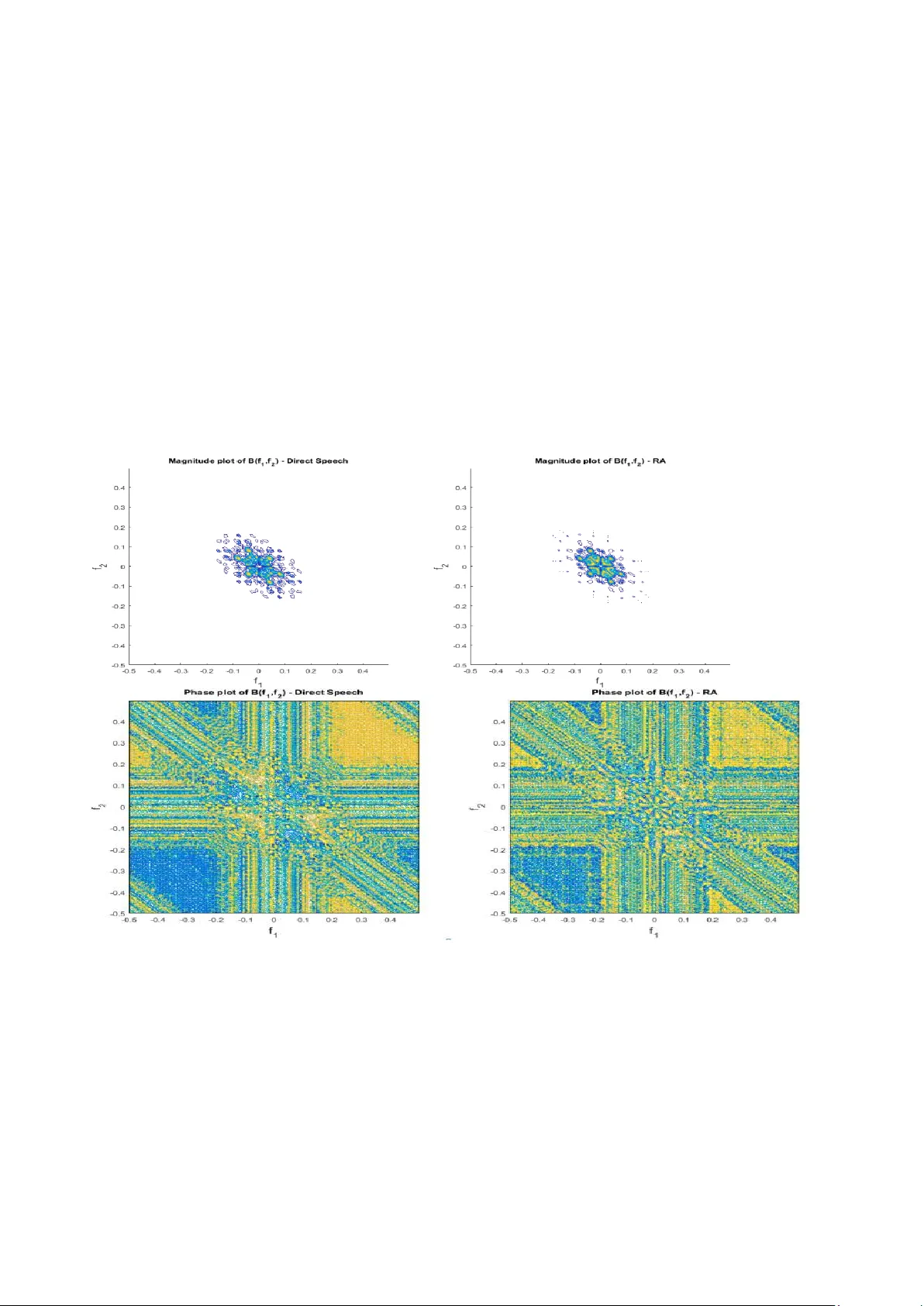
4장에서는 이러한 비선형 왜곡을 정량화하기 위해 고차 스펙트럼 분석(HOSA)을 적용한다. 핵심 특징량은 3차 누적량의 2차원 푸리에 변환인 바이코히런스이며, 이를 정규화한 bicoherence를 사용한다. 바이코히런스는 입력이 순수 톤일 경우 고조파와 IM 왜곡에 의해 특정 주파수 쌍에서 높은 크기와 0·π/2에 가까운 위상을 보인다. 논문은 QPC(Quadratic Phase Coupling) 값, Gaussianity 테스트(히니치 비대칭성 검정), Linear‑ity 테스트(선형성 검정) 세 가지 통계량을 결합해 재생 음성을 탐지한다.
5장에서는 제안된 탐지 프레임워크의 실험적 검증을 수행한다. 12개의 원본 명령어를 각각 1차·2차 재생하여 총 24개의 재생 음성을 확보하고, 1024‑point FFT와 Rao‑Gabr 윈도우를 이용해 50% 오버랩으로 바이코히런스를 추정하였다. 결과는 재생 음성에서 바이코히런스 크기가 원본 대비 현저히 증가하고, 위상 분포가 특정 주파수 대역에서 0·π/2에 집중되는 것을 확인했다. 또한 Gaussianity와 Linear‑ity 테스트 결과, 재생 음성은 비가우시안·비선형 특성을 명확히 나타내어 제안된 탐지 기준에 부합하였다.
논문의 주요 기여는 다음과 같다. (1) 현재 상용 스마트 스피커가 재생 공격에 매우 취약함을 실증적으로 입증한다. (2) 재생 공격을 고차 비선형성으로 모델링하고, 이를 기반으로 비학습 기반 탐지 기법을 제안한다. (3) 바이코히런스, QPC, Gaussianity, Linear‑ity 등 물리적 왜곡을 직접 측정함으로써 기존 머신러닝 기반 스펙트럼 특징보다 근본적인 탐지가 가능함을 보인다.
하지만 몇 가지 한계점도 존재한다. 실험이 제한된 환경(특정 스피커·마이크 모델, 실내 음향 조건)에서 수행되었으며, 다양한 하드웨어와 네트워크 환경에서의 일반화 검증이 부족하다. 또한 고차 비선형 모델이 압축 코덱, 전송 지연 등 복합 채널 효과를 충분히 포괄하는지는 추가 연구가 필요하다. 마지막으로 비학습 기반이므로 합성 음성 + 재생 등 복합 공격에 대한 내성은 아직 검증되지 않았다.
결론적으로, 본 연구는 스마트 스피커 보안에 대한 새로운 위협 모델과 탐지 방법을 제시함으로써, 향후 음성 기반 인증 시스템 설계 및 표준화에 중요한 시사점을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기