Multimodal One-Shot Learning of Speech and Images
Imagine a robot is shown new concepts visually together with spoken tags, e.g. "milk", "eggs", "butter". After seeing one paired audio-visual example per class, it is shown a new set of unseen instances of these objects, and asked to pick the "milk".…
Authors: Ryan Eloff, Herman A. Engelbrecht, Herman Kamper
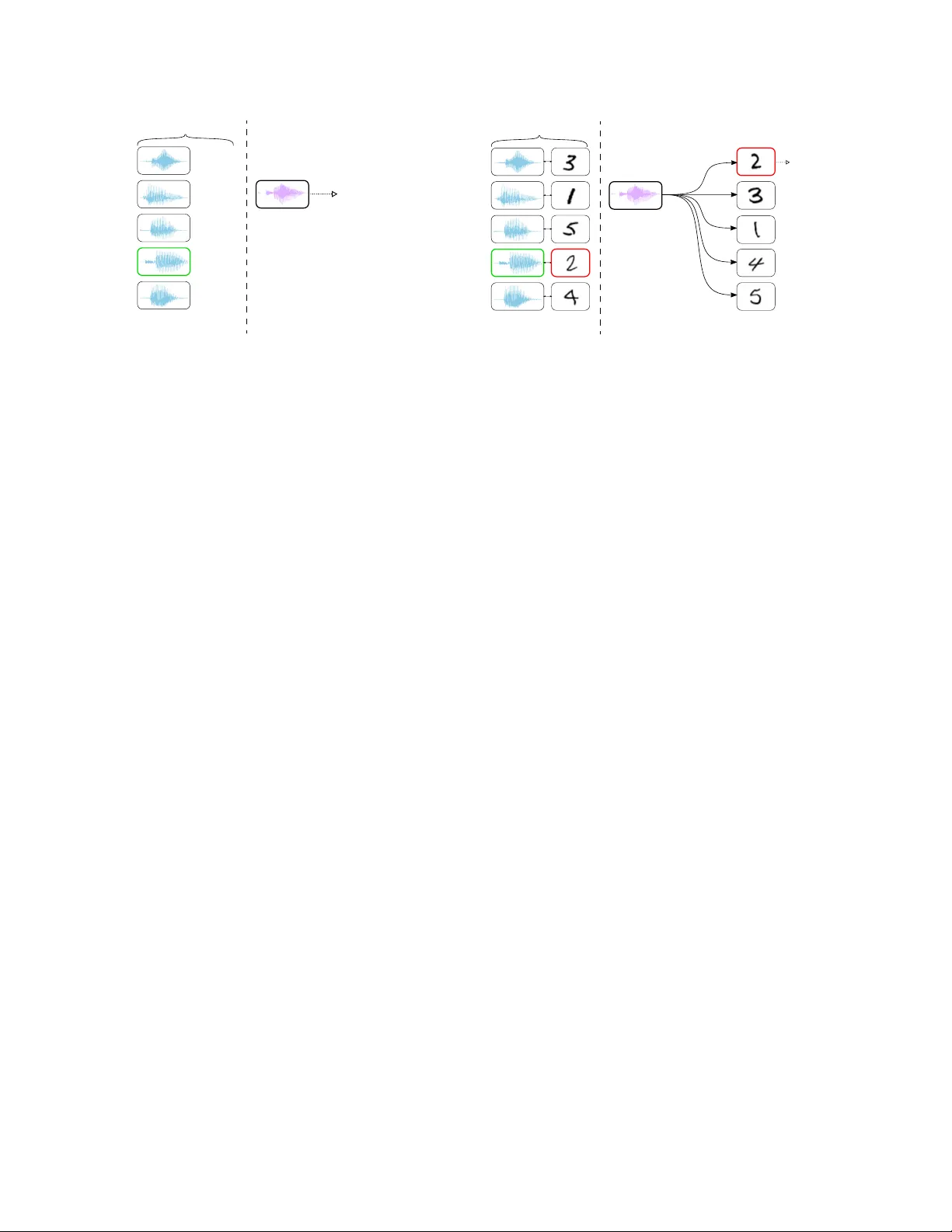
MUL TIMOD AL ONE-SHO T LEARNING OF SPEECH AND IMA GES Ryan Eloff Herman A. Engelbr echt Herman Kamper E&E Engineering, Stellenbosch Uni versity , South Africa rpeloff@sun.ac.za, hebrecht@sun.ac.za, kamperh@sun.ac.za ABSTRA CT Imagine a robot is sho wn new concepts visually together with spoken tags, e.g. “milk”, “e ggs”, “butter”. After seeing one paired audio- visual example per class, it is sho wn a ne w set of unseen instances of these objects, and asked to pick the “milk”. W ithout receiving any hard labels, could it learn to match the new continuous speech input to the correct visual instance? Although unimodal one-shot learning has been studied, where one labelled example in a single modality is gi ven per class, this e xample motiv ates multimodal one- shot learning . Our main contribution is to formally define this task, and to propose sev eral baseline and advanced models. W e use a dataset of paired spoken and visual digits to specifically in vestigate recent advances in Siamese con volutional neural networks. Our best Siamese model achieves twice the accuracy of a nearest neighbour model using pixel-distance ov er images and dynamic time warping ov er speech in 11-way cross-modal matching. Index T erms — Multimodal modelling, one-shot learning, cross- modal matching, low-resource speech processing, w ord acquisition. 1. INTR ODUCTION Humans possess the remarkable ability to learn ne w words and object categories from only one or a few examples [1]. For example, a child hearing the word “le go” for the first time in the context of recei ving a ne w toy , can quickly learn to associate the spoken w ord “lego” to the new (visual) concept le go . Current state-of-the-art speech and vision processing algorithms require thousands of labelled examples to complete a similar task. This has lead to research in one-shot learning [2 – 4], where the task is acquisition of nov el concepts from only one or a few labelled e xamples. One-shot learning studies hav e focused on problems where novel concepts in a single modality are observed along with class labels. This is dif ferent from the example above: the child directly associates the spoken word “lego” to the visual signal of lego without any class labels, and can generalise this single example to other visual or spoken instances of le go . This motiv ates multimodal one-shot learning , a ne w task we formalise in this paper . Consider an agent such as a household robot that is shown a single visual example of milk , e ggs , butter and a mug , nov el objects each paired with a spoken description. During subsequent use, a speech query is giv en and the agent needs to identify which visual object the query refers to. This setting is rele vant in modelling infant language acquisition, where models can be used to test particular cogniti ve hypotheses [5]; lo w- resource speech processing, where ne w concepts could be taught in an arbitrary language [6]; and robotics, where nov el concepts must be acquired online from co-occurring multimodal sensory inputs [7 – 11]. Here we specifically consider multimodal one-shot learning on a dataset of isolated spoken digits paired with images. A model is shown a set of speech-image pairs, one for each of the 11 digit classes. W e refer to this set, which is acquired before the model is applied, as the support set . During testing, the model is shown a new instance of a spoken digit and a new set of test images, called the matching set . It then needs to predict which test image in the matching set corresponds to the spoken input query . W e tackle this problem by extending existing unimodal one-shot models to the multimodal case. T o do cross-modal test-time matching, we propose a framew ork relying on unimodal comparisons through the support set. Giv en an input speech query , we find the closest speech segment in the support set. W e then take its paired support image, and find its closest image in the matching set. This image is predicted as the match. Metrics for speech-speech and image-image comparisons need to be defined, and this is where we tak e adv antage of the lar ge body of w ork in unimodal one-shot learning to in vestigate se veral options. One approach is to use labelled background training data not containing any of the classes under consideration. Using such speech and image background data, we specifically in vestigate Siamese neural networks [12, 13] as a way to explicitly train unimodal distance metrics. W e also incorporate recently proposed advances [4, 14–19] for such networks. W e compare novel Siamese con volutional neural network (CNN) architectures to traditional direct feature matching models. W e show that a single CNN with a triplet loss [14, 15] and online semi-hard mining [18] is more efficient and results in higher accuracies than the offline v ariant which uses shared weight networks, both approaches outperforming the direct feature matching baseline. Our main contri- bution is the formal definition of multimodal one-shot learning. W e also develop a one-shot cross-modal matching dataset that may be used to benchmark other approaches. As an intermediate ev aluation in our work, we also consider unimodal one-shot speech classifica- tion. Apart from [20], our paper is to our knowledge the only work that considers one-shot unimodal learning of spoken language. W e present sev eral new models and baselines not considered in [20]. 1 2. RELA TED WORK Most one-shot learning studies have been primarily interested in image classification. Apart from Siamese models [4], which we focus on here, other metric learning based approaches have been proposed [21 – 23] which build on adv ances in attention and memory mechanisms for neural networks. Along with the more recent meta- learning approaches [24 – 26], these have each produced improv ements in one-shot image classification. Howev er , only small improvements hav e been made ov er Siamese networks: Finn et al. [25] achie ved state-of-the-art results with only 1.4% increase in accuracy over Siamese networks for a 5-way one-shot learning task. A limited number of studies ha ve considered other domains, such as robotics [7, 27], video [28], and gesture recognition [9, 29]. Lake 1 Full code recipe available at: https://github.com/rpeloff/ multimodal- one- shot- learning . (a) - “four” - “two” - “five” - “one” - “three” S → C S ( ˆ x ) Suppor t set S C S ( ˆ x a ) Query ˆ x a ( “two” ) ˆ y = “two” i. One-shot speech learning ii. One-shot speech classification (b) S → D S ( ˆ x a , ˆ x v ) ( “three” ) ( “one” ) ( “five” ) ( “two” ) ( “four” ) Suppor t set S Query ˆ x a ( “two” ) D S ( ˆ x a , ˆ x v ) Matching set M v Match i. One-shot multimodal learning ii. One-shot cross-modal matching Fig. 1 . (a) Unimodal one-shot speech learning and classification and (b) multimodal one-shot learning and matching of speech and images. et al. [20] inv estigated one-shot speech learning using a generative hierarchical hidden Markov model to recognise novel words from learned primitiv es. This Bayesian model is based on prior work [30] in vision and has displayed strong results, although on visual tasks the Siamese model seems superior [4]. Our work is also related to learn- ing multimodal representations from paired images and unlabelled speech [31–35]. W e extend this research to the one-shot domain. 3. MUL TIMOD AL ONE-SHO T LEARNING The goal of unimodal one-shot learning is to b uild a model that can acquire new concepts after observing only a single labelled e xample from each class. This model must then successfully generalise to new instances of those concepts in tasks such as classification or regression. Formally , a model is shown a support set S , containing one labelled example for each of L classes. From this set, it must learn a classifier C S for unseen queries ˆ x . This is illustrated in Figure 1(a) for fi ve-way one-shot speech classification. In this case the support set S contains spoken utterances along with hard te xtual labels. The model uses this information to classify the spoken test query “two” as the concept label two . Note that the test-time query does not occur in the support set itself—it is an unseen instance of a class occurring in the support set. W e now modify this scheme to fit multimodal one-shot learn- ing. Instead of a labelled unimodal support set, we are now given features in multiple modalities with the only supervisory signal be- ing that these features co-occur . In our case we consider speech and images as the two modalities, although this may be applied to any source of paired multi-sensory information. Formally , in an L -way one-shot problem we are given a multimodal support set S = { ( x ( i ) a , x ( i ) v ) } L i =1 , where each spoken caption x ( i ) a ∈ A (audio space) is paired with an image x ( i ) v ∈ V (vision space). During test- time, the modal is presented with a test query in one modality , and asked to determine the matching item in a test (or matching) set in the other modality . This is related to cross-modal retriev al tasks [35 – 37] used to ev aluate multimodal networks. Formally , we match query ˆ x a in one modality (speech) to a matching set M v = { ( ˆ x v ) } N i =1 in the other modality (images) according to some metric D S ( ˆ x a , ˆ x v ) learned from the support set S . Neither the query ˆ x a or the items in the match set M v occur exactly in the support set S . W e refer to this task as one-shot cross-modal matching. It is illustrated in Figure 1(b), where the spoken query “tw o” is most similar to the image of a two in the matching set according to the model trained on the support set. One-shot learning can be generalised to K -shot learning, where, in the unimodal case, a model is shown a support set containing L nov el classes and K examples per class. In multimodal L -way K - shot learning, the support set S = { ( x ( i ) a , x ( i ) v ) } L × K i =1 consists of K speech-image example pairs for each of the L classes. This would occur , for instance, when a user teaches a robot speech-image corre- spondences by presenting it with multiple paired examples per class. 4. MUL TIMOD AL ONE-SHO T MODELLING W e now turn to the general frame work we use to perform multimodal one-shot learning. Assume we have a method or model that can measure similarity within a modality . One-shot cross-modal matching is then accomplished by first comparing a query to all the items in the support set in the query modality (e.g. speech). The most similar (speech-image) support-set pair is retriev ed. Finally , the retriev ed support-set instance is used to determine the closest item in the matching set, based on comparisons in the matching-set modality (e.g. images). This approach thus defines a metric D S as a mapping A → V which can match speech to images by unimodal comparisons through the multimodal support set S . As a concrete example, in Figure 1(b) the speech query in (b)-ii is compared to all the support set speech segments in (b)-i, and the closest speech item determined. The corresponding support-set image of this item is then tak en and compared to all the images in the matching set M v in (b)-ii. The closest image is predicted as the match. Sev eral different methods or models can be used to determine within-modality similarity: we compare directly using the raw image pixels and extracted speech features ( § 4.1) to feature embeddings learned by neural network functions ( § 4.2 and § 4.3). 4.1. Direct featur e matching Our first approach consists of directly using image pixels and acoustic speech features. W e specifically use cosine similarity between image pixels and dynamic time warping (DTW) [38] to measure similar- ity between speech segments. This is essentially our direct nearest neighbour baseline, as used in unimodal one-shot studies [4, 20, 21]. 4.2. Neural network classifiers Another method, also used in unimodal one-shot learning, is to train a supervised model on a large background dataset. This background dataset should not contain instances of the target one-shot classes. The idea is that features learned by such a model would still be useful for determining similarity on classes which it has not seen [21]. I.e., it follo ws the transfer learning principle: first train a classifier on a large labelled dataset, and then apply the learned representations to new tasks which are related b ut hav e too few training instances [39]. Here we specifically train both a feedforward (FFNN) and a con- volutional neural netw ork (CNN) classifier . W e train such networks separately for both the spoken and visual modalities. W e then take representations from the final hidden layer (before the softmax out- put) and apply these as the learned feature embeddings for nearest neighbour matching using cosine similarity . 4.3. Siamese neural networks Networks can also be trained on background data to directly measure similarity between inputs instead of predicting a class label. Siamese neural networks ha ve been used for this task [12, 13]. T wo identical neural network functions with shared parameters (hence “Siamese”) are trained to map input features to a target embedding space where the “semantic” relationship between input pairs may be captured based on proximity: inputs of the same type should ideally be mapped to similar embeddings, while inputs that are unrelated should be f ar apart. Early approaches [4, 12, 13] took in pairs of training examples and either maximised or minimised a distance based on whether the inputs were of same or different types. Recent studies [14 – 18] hav e argued that the relative rather than absolute distance between embeddings are meaningful, and we also follow this approach here. Concretely , let x a and x p be inputs of the same class, while x a and x n are of different classes. The intuition is that we want to push the so-called anchor example x a and positiv e example x p together such that the distance between them is smaller (by some specified mar- gin) than the distance between the anchor x a and negati ve e xample x n . Models using this approach are sometimes referred to as triplet models, since there are three tied networks for inputs ( x a , x p , x n ) . W e apply this approach where we learn embedding function f ( · ) as the final fully-connected layer of a CNN. W e train models with a hinge loss for triplet pairs [14–16, 18], defined as: l ( x a , x p , x n ) = max { 0 , m + D ( x a , x p ) − D ( x a , x n ) } (1) where D ( x 1 , x 2 ) = || f ( x 1 ) − f ( x 2 ) || 2 2 is the squared Euclidean dis- tance and m is the margin between the pairs ( x a , x p ) and ( x a , x n ) . One problem with this approach is that the number of triplet pairs grows cubically with the dataset, and it may become infeasible to fit all possible triplets in memory . W e follo w the online semi-har d mining scheme [18], where all possible anchor-positi ve pairs in a mini-batch are used. For each positi ve pair , the most dif ficult negati ve example x n satisfying D ( x a , x p ) < D ( x a , x n ) is then used, except if there is no such negati ve example in which case the one with the largest distance is used. According to [18], although it might seem natural to simply choose the hardest negati ve example in the mini-batch, this constraint is required for stability . W e also incorporate another recent advance, specifically to im- prov e ef ficience: we simplify the three shared-parameter networks with a single neural network that embeds a mini-batch of e xamples and then samples triplet pairs online from these embeddings. This is done with an ef ficient implementation of pairwise distances, similar to [40]. W e build this single network model with semi-hard triplet mining, and refer to it as Siamese CNN (online) . W e also compare to using three shared-parameter networks with the same CNN architec- ture, where we generate triplets offline at each training step from the current mini-batch. W e refer to this model as Siamese CNN (offline) in our experiments. Similar to our neural network classifier base- lines abov e, these models are trained on triplets from a large disjoint labelled dataset which do not contain the target one-shot classes. 5. EXPERIMENTS 5.1. Experimental setup W e perform multimodal one-shot learning on a simple benchmark dataset: learning from examples of spoken digits paired with hand- written digit images. For speech we use the TIDigits corpus which contains spoken digit sequences from 326 different speakers [41], and for images we use the MNIST handwritten digits dataset which contains 28 × 28 grayscale images [42]. W e use utterances from men, women, and children, and split digit sequences into isolated digits using forced alignments. Speech is parametrised as Mel-frequency cepstral coef fi cients with first and second order deri vativ es. W e centre zero-pad or crop speech segments to 120 frames. Image pixels are normalised to the range [0 , 1] . Each isolated spoken digit is then paired with an image of the same type. Unlike pre vious work which used the same dataset combination for learning multimodal repre- sentations [33, 35], we treat utterances labelled “oh” and “zero” as separate classes, resulting in 11 class labels. Neural network models are trained on large labelled background datasets to obtain feature representations which may be applied to the one-shot problem on classes not occurring in the background data. W e use the speech corpus of [43] and the Omniglot handwritten character dataset [44] as background data for the within-modality speech and vision models, respecti vely . Utterances in the audio corpus are split into isolated words using forced alignments, and features are extracted using the same process as for TIDigits. W e ensure that none of the tar get digit classes occur in this audio data. Images in the Omniglot dataset are do wnsampled to 28 × 28 and pixel values are normalised and in verted in order to match MNIST . Again, none of the Omniglot classes ov erlap with digit classes. Models are implemented in T ensorFlow and trained using the Adam optimiser with a learning rate of 10 − 3 which is step decayed by 0.96 at each new epoch. A batch size of 200 is used for the neural network classifiers ( § 4.2). For the Siamese models ( § 4.3) we follo w an alternate approach where mini-batches are formed using the batch all strategy proposed in [19]. Specifically , we randomly sample p classes and k examples per class to produce balanced batches of pk examples each. This results in pk ( pk − k )( k − 1) valid triplet combinations, maximising the number of triplets within a mini-batch. Our Siamese CNN (online) v ariant is capable of large pk combinations due to the efficient single netw ork implementation and online triplet sampling scheme. W e choose p = 128 and k = 8 (total of 7 282 688 triplets per mini-batch). For Siamese CNN (offline) , trained in the standard way where three networks are explicitly tied [15, 17, 18], we use p = 32 and k = 2 , giving 3 968 triplets per mini-batch which is the largest batch we could fit on a single NV idia T itan Xp GPU. Models are trained for a maximum of 100 epochs using early stopping based on one-shot validation error on the background data. W e also tune all models using unimodal one-shot learning on the validation sets of the background data. This gave the follo wing architecture for speech CNNs: 39 × 9 con volution with 128 filters; ReLU; 1 × 3 max pooling; 1 × 10 con volution with 128 filters; ReLU; 1 × 28 max pooling ov er remaining units; 2048-unit fully-connected; ReLU. V ision CNNs have the architecture: 3 × 3 con volution with 32 filters; ReLU; 2 × 2 max pooling; 3 × 3 con volution with 64 filters; ReLU; 2 × 2 max pooling; 3 × 3 con volution with 128 filters; ReLU; 2048-unit fully-connected; ReLU; 1024-unit fully-connected. The speech and vision FFNNs have the same structure: 3 fully-connected layers with 512 units each. For the classifier networks ( § 4.2), the speech networks ha ve an additional 5534-unit softmax output layer (the number of word types in the background data), while vision networks ha ve a 964-unit softmax (background image classes). T able 1 . 11-way one-shot and fi ve-shot speech classification results on isolated spoken digits. Model T rain 11-way Accuracy time one-shot fiv e-shot DTW – 67.99% ± 0.29 91.30% ± 0.20 FFNN Classifier 13.1m 71.39% ± 0.81 89.49% ± 0.45 CNN Classifier 60.6m 82.07% ± 0.92 93.58% ± 0.98 Siamese CNN (offline) 70.5m 89.40% ± 0.54 95.12% ± 0.37 Siamese CNN (online) 15.0m 92.85% ± 0.38 97.65% ± 0.22 W e ev aluate our models on the one-shot tasks according to the accuracy averaged over 400 test episodes. Each episode randomly samples a support set of isolated spoken digits paired with images for each of the L = 11 classes (the digits “oh” to “nine” and “zero”). For testing, a matching set is sampled, containing 10 digit images not in the support set. Finally , a random query is sampled, also not in the support set. The query then needs to be matched to the correct item in the matching set. The matching set only contains 10 items since there are 10 unique handwritten digit classes. W ithin an episode, 10 different query instances are also sampled while keeping the support and matching sets fixed. Results are a veraged over 10 models trained with different seeds and we report av erage accuracies with 95% confidence intervals. 5.2. One-shot speech classification W e first consider unimodal one-shot speech classification, which has so far only been considered in [20]. T able 1 shows one-shot and fiv e-shot (see end of § 3) speech classification results. A verage train- ing time is also shown; all models trained within a few seconds of the av erage. Siamese models outperform the direct feature matching baseline using DTW , as well as the neural network classifiers. The Siamese CNN (online) model achiev es best overall performance, out- performing the Siamese CNN (offline) v ariant, while training almost fiv e times faster . The single network with online semi-hard mining is thus more efficient and accurate than the three shared-network approach. None of these Siamese models were considered in [20]. 5.3. One-shot cross-modal matching of speech to images W e now turn to multimodal one-shot learning. T able 2 sho ws results for one- and five-shot cross-modal matching of speech to images. Here the Siamese models are again stronger overall compared to direct feature matching or transferring features from neural network classifiers. The Siamese CNN (online) model achiev es our best results, with double the accuracy of direct feature matching using pixel- distance over images and DTW over speech. The Siamese CNN (offline) model follo ws closely , but is again slo wer to train. While the Siamese models achie ve promising results compared to the baselines here, our best one-shot multimodal accuracy is lower than the accuracy in unimodal one-shot speech classification (T able 1). Our best unimodal one-shot vision model achie ves an accuracy of 74% (comparing fa vourably to the best result of 72% reported in [21]). The multimodal one-shot results here are therefore w orse than both the indi vidual unimodal matching results. This is due to compounding errors in our retriev al framew ork ( § 4): errors in comparisons with the support set af fects comparisons in the subsequent matching step. This suggests in vestigating an end-to-end architecture which can directly compare test queries in one modality to the matching set items in the other modality , without doing explicit comparisons to the support set. T able 2 . 11-way one- and five-shot cross-modal matching of spoken and visual digits. Model 11-way Accuracy one-shot fiv e-shot DTW + Pixels 34.92% ± 0.42 44.46% ± 0.69 FFNN Classifier 36.49% ± 0.41 44.29% ± 0.56 CNN Classifier 56.47% ± 0.76 63.97% ± 0.91 Siamese CNN (offline) 67.41% ± 0.56 70.92% ± 0.36 Siamese CNN (online) 70.12% ± 0.68 73.53% ± 0.52 T able 3 . Speaker inv ariance tests for 11-way one-shot cross-modal speech-image digit matching. All support set items are from the same speaker as the query , except for the item actually matching the query . Model 11-way Accuracy one-shot DTW + Pixels 28.00% ± 1.86 FFNN Classifier 34.95% ± 2.28 CNN Classifier 53.71% ± 2.20 Siamese CNN (offline) 66.70% ± 0.92 Siamese CNN (online) 69.73% ± 1.04 5.4. In variance to speakers In all the experiments above we chose spoken queries such that the speaker uttering the query does not appear in the support set. This is representativ e of an extreme case where one user teaches an agent and another then uses the system. An even more e xtreme case could occur: the matching item in the support set could be the only item not coming from the query speaker . This is problematic since the same word uttered by dif ferent speakers might be acoustically more different than dif ferent words uttered by the same speaker . W e test this worst-case setting: we sample a support set where all spoken digits are from the same speaker as the query , except for the one instance matching the query w ord which is produced by a dif ferent speaker . Cross-modal matching results for this case are shown in T able 3. All of the models experience a drop in accuracy compared to the results in T able 2 (first column). This decrease is smallest for the Siamese models, with the DTW + Pixels approach dropping most. This indicates that the neural models learn features from the background data which are more independent of speaker and can generalise to other speakers, whereas DTW ov er speech is af fected more by speaker mismatch. 6. CONCLUSION W e introduced and formalised multimodal one-shot learning, specif- ically for learning from spok en and visual representations of digits. Observing just one paired example from each class, a model is asked to pick the correct digit image for an unseen spoken query . W e pro- posed and ev aluated sev eral baseline and more advanced models. Although our Siamese conv olutional approach outperforms a raw- feature nearest neighbour model, the performance in the cross-modal case is still worse than in unimodal one-shot learning. W e argued that this is due to a compounding of errors in our frame work, which relies on successi ve unimodal comparisons. In future work, we will therefore explore a method that can directly match one modality to another , particularly looking into recent meta-learning approaches. W e thank NVIDIA for sponsoring a Titan Xp GPU for this w ork. 7. REFERENCES [1] J. Halberda, “Is this a dax which I see before me? Use of the logical argument disjuncti ve syllogism supports word-learning in children and adults, ” Cogn. Psychol. , vol. 53, no. 4, pp. 310–344, 2006. [2] L. Fei-Fei, R. Fergus, and P . Perona, “One-shot learning of object categories, ” IEEE T rans. P AMI , vol. 28, no. 4, pp. 594– 611, 2006. [3] B. M. Lake, R. Salakhutdino v , J. Gross, and J. B. T enenbaum, “One shot learning of simple visual concepts, ” in Pr oc. CogSci , 2011. [4] G. Koch, R. Zemel, and R. Salakhutdinov , “Siamese neural networks for one-shot image recognition, ” in Pr oc. ICML , 2015. [5] O. R ¨ as ¨ anen and H. Rasilo, “ A joint model of word segmentation and meaning acquisition through cross-situational learning, ” Psychol. Re v . , vol. 122, no. 4, pp. 792–829, 2015. [6] L. Besacier , E. Barnard, A. Karpov , and T . Schultz, “ Automatic speech recognition for under -resourced languages: A survey , ” Speech Commun. , v ol. 56, pp. 85–100, 2014. [7] M. R. W alter , Y . Friedman, M. Anton, and S. T eller , “One-shot visual appearance learning for mobile manipulation, ” IJRR , vol. 31, no. 4, pp. 554–567, 2012. [8] T . T aniguchi et al., “Symbol emergence in robotics: A survey , ” Adv . Robot. , vol. 30, no. 11–12, pp. 706–728, 2016. [9] W . Thomason and R. A. Knepper, “Recognizing unfamiliar gestures for human-robot interaction through zero-shot learning, ” in Pr oc. ISER , 2016. [10] V . Renkens and H. V an hamme, “W eakly supervised learning of hidden Markov models for spoken language acquisition, ” IEEE/A CM T rans. ASLP , vol. 25, no. 2, pp. 285–295, 2017. [11] V . Renkens and H. V an hamme, “Capsule networks for low resource spoken language understanding, ” in Pr oc. Interspeech , 2018. [12] J. Bromley et al., “Signature verification using a “Siamese” time delay neural network, ” in Pr oc. NIPS , 1994. [13] S. Chopra, R. Hadsell, and Y . LeCun, “Learning a similarity metric discriminatively , with application to face verification, ” in Pr oc. CVPR , 2005. [14] G. Chechik, V . Sharma, U. Shalit, and S. Bengio, “Large scale online learning of image similarity through ranking, ” JMLR , vol. 11, no. 11, pp. 1109–1135, 2010. [15] J. W ang et al., “Learning fine-grained image similarity with deep ranking, ” in Proc. CVPR , 2014. [16] K. M. Hermann and P . Blunsom, “Multilingual distributed representations without word alignment, ” in Pr oc. ICLR , 2014. [17] E. Hoffer and N. Ailon, “Deep metric learning using triplet network, ” in Pr oc. SIMBAD , 2015. [18] F . Schrof f, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering, ” in Pr oc. CVPR , 2015. [19] A. Hermans, L. Beyer , and B. Leibe, “In defense of the triplet loss for person re-identification, ” arXiv pr eprint arXiv:1703.07737 , 2017. [20] B. M. Lake, C.-Y . Lee, J. R. Glass, and J. B. T enenbaum, “One- shot learning of generati ve speech concepts, ” in Pr oc. CogSci , 2014. [21] O. V inyals et al., “Matching networks for one shot learning, ” in Pr oc. NIPS , 2016. [22] P . Shyam, S. Gupta, and A. Dukkipati, “ Attentiv e recurrent comparators, ” in Proc. ICML , 2017. [23] J. Snell, K. Swersky , and R. Zemel, “Prototypical networks for few-shot learning, ” in Pr oc. NIPS , 2017. [24] A. Santoro et al., “Meta-learning with memory-augmented neural networks, ” in Pr oc. ICML , 2016. [25] C. Finn, P . Abbeel, and S. Levine, “Model-agnostic meta- learning for fast adaptation of deep networks, ” in Pr oc. ICML , 2017. [26] N. Mishra, M. Rohaninejad, X. Chen, and P . Abbeel, “ A simple neural attentiv e meta-learner , ” in Pr oc. ICLR , 2018. [27] C. Finn et al., “One-shot visual imitation learning via meta- learning, ” in Proc. Robot Learn. , 2017. [28] T . Stafylakis and G. Tzimiropoulos, “Zero-shot keyw ord spot- ting for visual speech recognition in-the-wild, ” in Pr oc. ECCV , 2018. [29] D. W u, F . Zhu, and L. Shao, “One shot learning gesture recog- nition from rgbd images, ” in Pr oc. CVPR , 2012. [30] B. M. Lake, R. Salakhutdinov , and J. B. T enenbaum, “One-shot learning by in verting a compositional causal process, ” in Pr oc. NIPS , 2013. [31] J. Ngiam et al., “Multimodal deep learning, ” in Pr oc. ICML , 2011. [32] D. Harwath, A. T orralba, and J. R. Glass, “Unsupervised learn- ing of spoken language with visual context, ” in Pr oc. NIPS , 2016. [33] K. Leidal, D. Harwath, and J. R. Glass, “Learning modality- in variant representations for speech and images, ” in Pr oc. ASR U , 2017. [34] H. Kamper , G. Shakhnarovich, and K. Liv escu, “Semantic speech retrieval with a visually grounded model of untran- scribed speech, ” IEEE/A CM T rans. ASLP , vol. 27, no. 1, pp. 89–98, 2019. [35] K. Kashyap, “Learning digits via joint audio-visual representa- tions, ” M.S. thesis, MIT , 2017. [36] L. W ang, Y . Li, J. Huang, and S. Lazebnik, “Learning two- branch neural networks for image-te xt matching tasks, ” IEEE T rans. P AMI , vol. 41, no. 2, pp. 394–407, 2018. [37] A. Eisenschtat and L. W olf, “Linking image and te xt with 2-way nets, ” in Proc. CVPR , 2017. [38] H. Sakoe and S. Chiba, “Dynamic programming algorithm optimization for spoken word recognition, ” IEEE T rans. ASSP , vol. 26, no. 1, pp. 43–49, 1978. [39] J. Donahue et al., “Decaf: A deep conv olutional activ ation feature for generic visual recognition, ” in Proc. ICML , 2014. [40] H. O. Song, Y . Xiang, S. Jegelka, and S. Sav arese, “Deep metric learning via lifted structured feature embedding, ” in Pr oc. CVPR , 2016. [41] R. G. Leonard and G. Doddington, “TIDIGITS LDC93S10, ” Philadelphia: Linguistic Data Consortium, 1993. [42] Y . LeCun, L. Bottou, Y . Bengio, and P . Haffner , “Gradient- based learning applied to document recognition, ” Proc. IEEE , vol. 86, no. 11, pp. 2278–2324, 1998. [43] D. Harwath and J. R. Glass, “Deep multimodal semantic em- beddings for speech and images, ” in Proc. ASR U , 2015. [44] B. M. Lake, R. Salakhutdino v , and J. B. T enenbaum, “Human- lev el concept learning through probabilistic program induction, ” Science , vol. 350, no. 6266, pp. 1332–1338, 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment