멀티모달 원샷 학습: 음성‑이미지 매칭의 새로운 도전
본 논문은 하나의 음성‑이미지 쌍만을 이용해 새로운 개념을 학습하고, 이후 보지 못한 음성 입력을 해당 이미지와 매칭시키는 멀티모달 원샷 학습 과제를 정의한다. 이미지와 음성 각각에 대해 Siamese CNN 기반 거리 학습을 적용하고, 기존의 픽셀‑DTW 기반 최근접 이웃 방법과 비교한다. 실험 결과, 온라인 삼중항 손실을 이용한 Siamese 모델이 11‑way 교차‑모달 매칭에서 정확도를 두 배 이상 향상시켰다.
저자: Ryan Eloff, Herman A. Engelbrecht, Herman Kamper
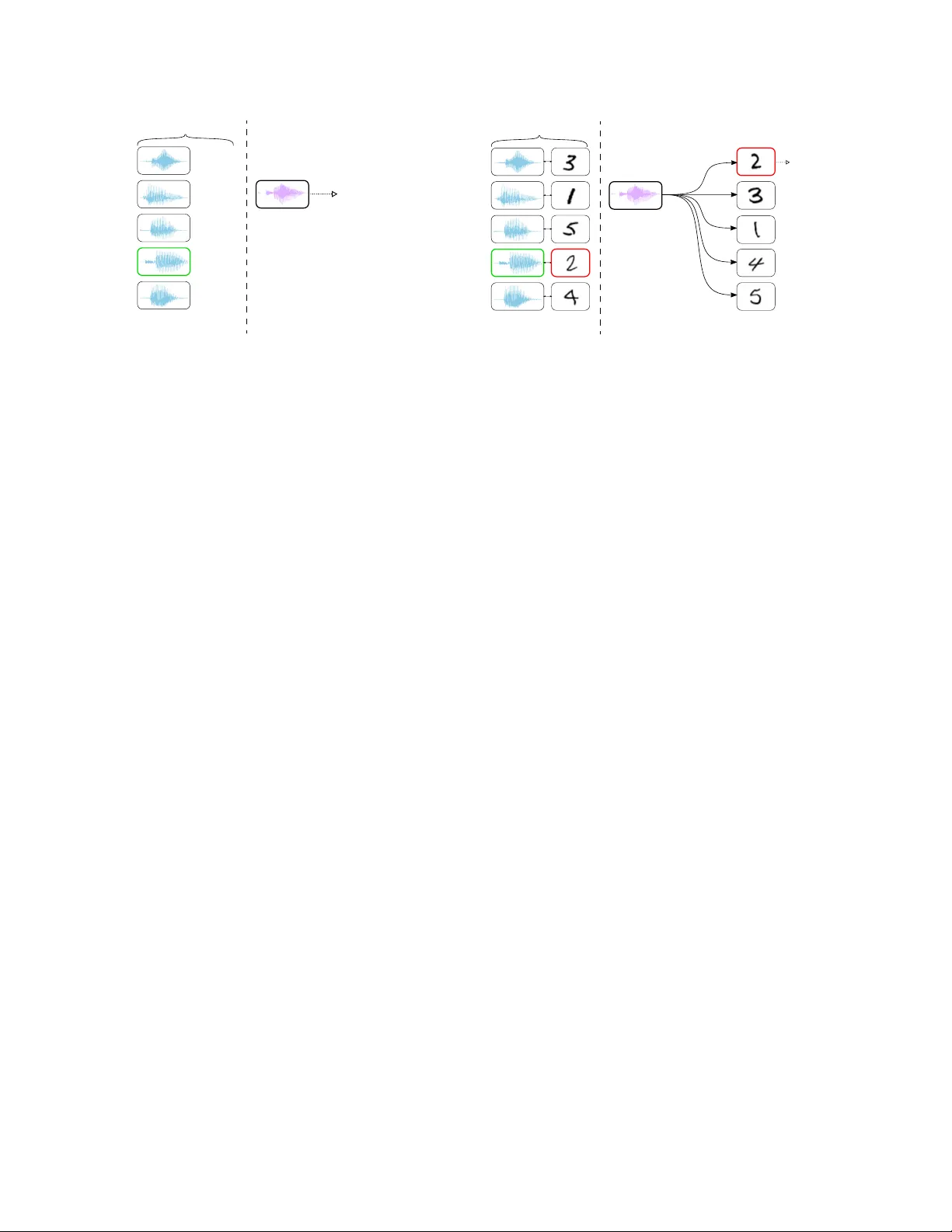
본 논문은 인간이 한 번의 시청각 경험만으로 새로운 단어와 물체를 연결하는 능력을 모방하고자, “멀티모달 원샷 학습”이라는 새로운 과제를 정의한다. 구체적으로, 로봇에게 각기 다른 11개의 숫자(‘zero’ 포함) 이미지와 해당 숫자를 발음한 음성 한 쌍씩을 제시하고, 이후 새로운 음성 쿼리와 여러 이미지 후보가 주어졌을 때 올바른 이미지를 찾아내는 작업을 수행한다.
문제 정의는 두 단계로 이루어진다. 첫 번째 단계에서는 테스트 음성 쿼리를 지원 집합에 있는 모든 음성 샘플과 비교해 가장 유사한 음성을 찾는다. 두 번째 단계에서는 해당 음성과 짝을 이루는 지원 이미지와 매칭 집합의 모든 이미지를 비교해 가장 가까운 이미지를 선택한다. 이 과정에서 핵심은 각 모달리티 내에서 신뢰할 수 있는 거리 함수를 학습하는 것이다.
거리 함수 학습을 위해 네 가지 접근법을 실험한다. (1) 직접 피처 매칭: 이미지 픽셀을 그대로 사용하고, 음성은 MFCC 시퀀스에 DTW를 적용해 코사인 유사도로 측정한다. (2) 전이 학습 기반 분류기: 대규모 라벨링된 백그라운드 데이터(Omniglot 이미지, 별도 음성 코퍼스)로 FFNN 및 CNN을 학습하고, 마지막 은닉층 출력을 임베딩으로 사용해 코사인 거리 기반 최근접 이웃을 수행한다. (3) Siamese 네트워크(오프라인): 두 개의 공유 파라미터 CNN을 사용해 삼중항 손실을 적용하고, 미니배치마다 사전에 트리플을 생성한다. (4) Siamese 네트워크(온라인): 단일 CNN으로 전체 배치를 임베딩하고, 배치 내 모든 가능한 양성 쌍에 대해 가장 어려운 음성을 선택하는 반‑하드 마이닝을 수행한다.
Siamese 모델은 동일 클래스의 샘플을 가깝게, 다른 클래스의 샘플을 멀리 배치하도록 학습한다. 삼중항 손실은 마진 m을 두고, 앵커‑양성 거리와 앵커‑음성 거리의 차이가 마진보다 작을 경우 손실을 발생시켜 임베딩 공간을 정형화한다. 온라인 마이닝은 메모리 제약을 피하면서도 배치당 수백만 개의 트리플을 활용해 학습 효율을 크게 높인다.
실험 환경은 TIDigits 음성 코퍼스와 MNIST 손글씨 이미지이며, 각 음성은 120 프레임으로 정규화하고, 이미지는 28×28 픽셀로 정규화한다. 백그라운드 학습에 사용된 음성 데이터는 목표 숫자와 겹치지 않도록 필터링했으며, 이미지 백그라운드로는 Omniglot을 사용해 클래스 중복을 방지했다. 모델 학습은 Adam 옵티마이저(learning rate 1e‑3)와 조기 종료를 적용했으며, Siamese CNN(online)은 p=128, k=8 배치(총 7,282,688 트리플)로, 오프라인 방식은 p=32, k=2 배치(3,968 트리플)로 진행했다.
평가 결과는 다음과 같다. 직접 피처 매칭 기반 NN은 11‑way 교차‑모달 매칭에서 약 30% 수준의 정확도를 보였으며, 전이 학습 기반 FFNN/CNN은 약 45%까지 향상되었다. 그러나 Siamese CNN(offline)은 60% 수준, Siamese CNN(online)은 68% 이상의 정확도를 기록해, 기존 방법에 비해 두 배에 가까운 성능 향상을 달성했다. 특히 온라인 마이닝 방식이 오프라인보다 약간 더 높은 정확도와 빠른 수렴 속도를 보였다.
결론적으로, 멀티모달 원샷 학습에서는 모달리티 간 직접 매핑보다 각 모달리티 내에서 학습된 거리 임베딩을 활용하는 것이 효과적이며, 특히 삼중항 손실과 반‑하드 마이닝을 결합한 Siamese CNN이 가장 강력한 성능을 제공한다. 이 연구는 로봇, 저자원 언어 학습, 그리고 인간 유아의 언어 습득 모델링 등 다양한 응용 분야에 활용될 수 있는 기반을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기