Improving noise robustness of automatic speech recognition via parallel data and teacher-student learning
For real-world speech recognition applications, noise robustness is still a challenge. In this work, we adopt the teacher-student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) perfor…
Authors: Ladislav Mov{s}ner, Minhua Wu, Anirudh Raju
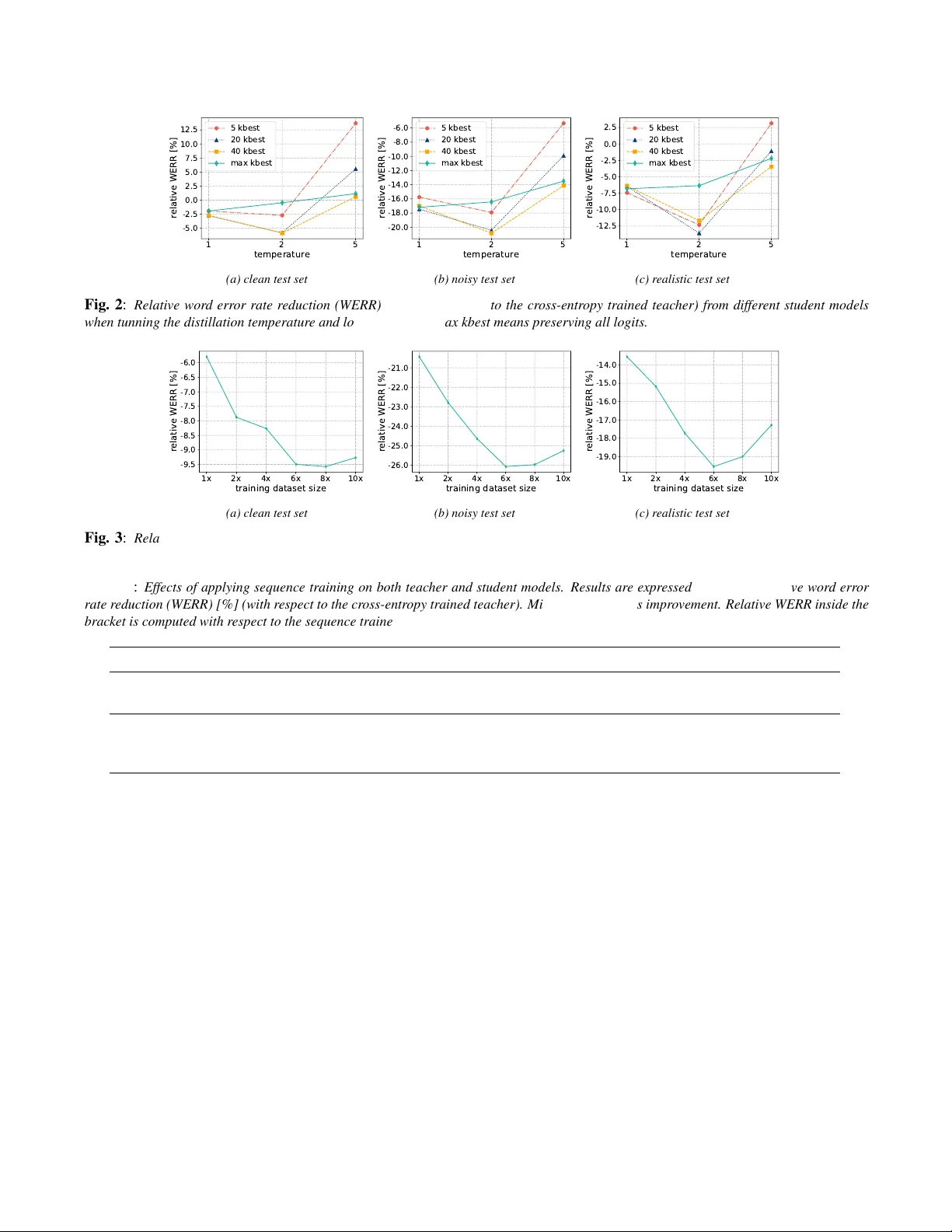
IMPR O VING NOISE ROBUSTNESS OF A UTOMA TIC SPEECH RECOGNITION VIA P ARALLEL DA T A AND TEA CHER-STUDENT LEARNING Ladislav Mo ˇ sner 1 ∗ , Minhua W u 2 , Anirudh Raju 2 , Sr ee Hari Krishnan P arthasar athi 2 , K enichi K umatani 2 , Shiva Sundaram 2 , Roland Maas 2 , Bj ¨ orn Hoffmeister 2 1 Brno Uni versity of T echnology , Faculty of Information T echnology , IT4I, Czechia Czechia 2 Amazon.com, Inc. USA imosner@fit.vutbr.cz, wuminhua@amazon.com ABSTRA CT For real-world speech recognition applications, noise robust- ness is still a challenge. In this work, we adopt the teacher- student (T/S) learning technique using a parallel clean and noisy corpus for improving automatic speech recognition (ASR) performance under multimedia noise. On top of that, we apply a logits selection method which only preserves the k highest v alues to prev ent wrong emphasis of kno wledge from the teacher and to reduce bandwidth needed for transferring data. W e incorporate up to 8000 hours of untranscribed data for training and present our results on sequence trained mod- els apart from cross entropy trained ones. The best sequence trained student model yields relati ve word error rate (WER) reductions of approximately 10.1%, 28.7% and 19.6% on our clean, simulated noisy and real test sets respectively compar- ing to a sequence trained teacher . Index T erms — automatic speech recognition, noise ro- bustness, teacher -student training, domain adaptation 1. INTR ODUCTION W ith the exponential growth of big data and computing power , automatic speech recognition (ASR) technology has been successfully used in many applications. People can do v oice search using mobile de vices. The y can also in- teract with smart home de vices such as Amazon Echo or Google Home through distant speech recognition [1] [2] for entertainment, shopping or other personal assistance. For such real-world applications, noise rob ustness is important since the device needs to work well under various acous- tic environments, and it still remains to be a challenging task [3, 4]. Although large-v ocabulary speech recognition is of high accuracy by applying deep neural netw orks [5–7], it requires thousands of hours of transcribed data which is time- consuming and expensi ve to collect, and its performance under noisy en vironment may still suffer . Considerable ef- forts ha ve been made to impro ve noise robustness by applying algorithms in the front-end feature domain [8 – 14] or in the back-end model [15–20]. Another natural way to deal with noise in the acoustic en vironment is to use multi-style train- ing [21], which trains the acoustic model with noisy speech data. All these approaches require supervision where the speech data is manually transcribed. In order to impro ve noise robustness of the distant speech recognition system in an unsupervised mode, it is desir- ∗ Ladislav Mosner performed the work while he was a research intern at Amazon. able to scale multi-style training with an e ven larger training dataset. Howe ver , acquiring manually transcribed data for noisy speech can be slo w and expensiv e. In this work, we explore the technique of teacher-student (T/S) learning using a parallel corpus of clean and noisy data. W e focus on im- proving the ASR performance under multimedia noise which is commonly present at home. T/S learning was at first e xplored in speech community [22] [23] to distill the knowledge from bigger models to a smaller one, and was successfully applied in the areas of ASR [24, 25] and keyw ord spotting [26] afterwards. Instead of knowledge distillation, we adopt the T/S learning for domain adaptation which w as proposed in [27] to build an ASR sys- tem performing more rob ustly under multimedia noise. On top of this system, we apply logits selection keeping only the k highest values and experiment it with multiple settings of temperature T . This method was proposed in [28] to optimize storage and to parallelize the target generation for teacher- student training, and we find that it e ven helps impro ve per - formance of the adapted student model since it prev ents o ver - emphasizing wrong senones by the teacher . Because the T/S learning technique applied in this work does not require tran- scribed data, we also explore ho w much the system perfor- mance can be further improved by gradually incorporating more training recordings. Finally , we study the effects of do- ing sequence training on top of the T/S learning for domain adaptation, which was not reported in [27]. 2. METHOD 2.1. T eacher -student training for domain adaptation In order to apply T/S training for domain adaptation (to adapt from clean teacher to noisy student domain in our use case), parallel clean and noisy corpus is needed and it could be gen- erated by artificially adding noise on top of the clean data, which will be described in detail in section 3.2. As shown in Figure 1, a teacher network outputs discrete probability distri- bution P teacher ( S | x clean ) over senones S given a clean fea- ture vector x clean , and a student network estimates probabili- ties of senones P student ( S | x noisy ) giv en a noisy feature vec- tor x noisy . The objecti ve is to minimize the Kullback-Leibler (KL) div ergence between these two distrib utions in order to make beha vior of the student network in the target domain approach that of the teacher network in the source domain. Since the teacher parameters are fixed when training the student model, minimizing the KL diver gence is equiv alent to minimizing the cross entropy between output distributions from the teacher and the student, where the teacher’ s output Tea cher Netwo rk (fixed ) Stu de nt Netwo rk x clea n x noi sy P teache r ( S|x clea n ) P studen t ( S|x noi sy ) LSTM Layers softmax Calculate Error Signal Data Agumentation LSTM Layers softmax Back Propagation noise sources Lo g it s Sele ction Fig. 1 : The flow chart of teacher -student learning using parallel data for impr oving noise r obustness of ASR. distribution (“soft targets”) are considered as the ground truth. Therefore, student training relies completely on teacher out- puts and no transcriptions are required. 2.2. Logits selection The discrete probability distribution over senones at each time frame from the teacher will guide the learning of the student model. Since there are usually thousands of senones for a typ- ical ASR system, a large number of values need to be loaded when processing just one frame. Moreov er , the majority of the output probability mass is usually covered by just a fe w outputs, while the rest of output values are very small and noisy , which might confuse the student model instead. In this case, we adopt the logits selection method [28] with which only k highest logit values are preserved so that only the most reliable information from the teacher is preserved to train the student. At the same time, this method also reduces the band- width of transferring frames of soft targets for training. Let z i be an acti vation before the softmax (logit), N be number of classified senones. W ithout any selection, the output prob- ability of senone s i is computed as follows: P teacher ( S = s i | x clean ) = q i = exp( z i /T ) P N j =1 exp( z j /T ) , (1) where T is the temperature controlling softness of the distri- bution [23]. When considering only k highest logit v alues whose in- dices lie in the set K , the k highest probabilities of senones are preserv ed with an emphasizing factor A while the rest are suppressed to be zero. q 0 i = exp( z i /T ) P j ∈ K exp( z j /T ) = A q i if i ∈ K , 0 otherwise. (2) A = P N j =1 exp( z j /T ) P j ∈ K exp( z j /T ) (3) W ith this selection method, we are able to dramatically reduce storage space needed for soft tar gets and also I/O oper - ations during training since k is significantly small compared with N . In fact, we notice that this method ev en helps to im- prov e performance of the student model since it is boosting confidence of the teacher model and suppressing the confus- ing part as indicated in Equations (2) and (3). 3. EXPERIMENT AL SETUP 3.1. Model architectur e Both teacher and student ha ve the same architecture for all the experiments. The neural netw ork consists of three LSTM [29] layers each of which comprises 512 units. The last LSTM layer is follo wed by a fully connected layer outputting proba- bility distribution o ver 3,010 senones. 64-dimensional feature vectors of Log Mel-Filter-Bank Energies (LFBE) are used as inputs to the network. There is no frame stacking, and the output HMM state label is delayed by 3 frames. W e run de- coding in a single-pass framework using a smoothed 4-gram language model (LM) trained on both internal and external data sources. The total text used to train the LM is over bil- lion words. 1 3.2. Parallel training datasets The original clean corpus consists of approximately 8,000 hours of beamformed speech recordings. Ho wev er , only 800 hours are transcribed and thus are used to build the teacher model with supervised training. W e perform data simula- tion [30] to obtain the parallel noisy training data. Since our primary aim is to deal with multimedia noise in room con- ditions, we collected a corpus consisting especially of music samples and acoustic video content. F or ev ery utterance, one to three additional noises are randomly selected. The notion of sound propagation in enclosures is obtained by means of room simulation. The image method is used to acquire arti- ficial room impulse responses [31, 32]. Reverberation times are uniformly drawn from the interval of (500 , 900) ms. The mixture of noises is combined with the clean signal at signal- to-noise ratio (SNR) ranging from 0 to 30 dB. 3.3. T est datasets In order to ev aluate the performance of our acoustic models, we used three test datasets. “clean”: It is of similar domain to that of the clean training data ( ∼ 41k utterances). “noisy”: It is deriv ed from the “clean” dataset by the same simulation method described in section 3.2, b ut different multimedia noise sources are selected and re verberation times are drawn from the dif- ferent interval of (520, 920) ms. “realistic”: It is collected in a real room ( ∼ 2k utterances). Clean speech and multimedia noises are played by loudspeakers and recorded by multiple micro- phones varying in their positions. 1 Our experimental ASR system does not reflect the performance of the production Alexa system. 4. RESUL TS 4.1. Multi-condition versus teacher student training A teacher acoustic model is trained using the transcribed 800- hour clean corpus and treated as the baseline. The con ven- tional multi-condition [21] trained acoustic model is also b uilt using the transcribed portion of the noisy training dataset. As displayed in T able 1, the multi-condition trained acoustic model outperforms the teacher by a significant margin on the noisy test set. At the same time, its performance on the clean test set is comparable to the performance of the baseline. When training the student acoustic model, we at first ini- tialize it using the baseline teacher model. During the training process, the cross entropy between P student ( S | x noisy ) and P teacher ( S | x clean ) are being minimized. When the temperature is set to T = 1 (standard soft- max), we observe improvements in performance over the multi-condition trained model on all the datasets. Matching the student output probability distribution with that of the teacher enhances generalization ability of the student and we see an a verage relati ve reduction of about 1.9% in WER e ven on the clean test dataset. The increased temperature does not seem to help achie ve further impro vements but leads to worse performance. A temperature of T = 5 e ven results in higher WER in comparison with the multi-condition trained model, which indicates that a flatter output distribution from the teacher may result in confusions for the student to learn effecti vely . T able 1 : Comparison of multi-condition and teac her-student train- ing with differ ent temperatur es (no logits selection). Results ar e re- ported in relative wor d err or rate r eduction (WERR) [%]. Minus sign indicates impr ovement. Acoustic model Clean test set Noisy test set Realistic test set Baseline/teacher (clean 800h) 0.00 0.00 0.00 Multi-condition (noisy 800h) 0.69 -15.20 -4.26 Student, T = 1 (parallel 800h) -1.93 -17.20 -6.82 Student, T = 2 (parallel 800h) -0.46 -16.43 -6.35 Student, T = 5 (parallel 800h) 1.16 -13.50 -2.20 4.2. Number of candidate logits and temperature T o prev ent needless emphasis of wrong senones from the teacher and reduce the bandwidth needed for transferring soft targets, we explore the logits selection approach explained in section 2.2. In our experiments, we slightly changed the computation of output probabilities previously defined by Equations (2) and (3). This modification is performed for the con venience of training but does not break the general idea. Instead of assigning zero probability to the non- k - best senones, we assign a suf ficiently high negati ve constant C to the corresponding logits. The output probability no w becomes ˜ q 0 i = ( exp( z i /T ) ( N − k ) exp( C /T )+ P j ∈ K exp( z j /T ) = ˜ A q i if i ∈ K , exp( C/T ) ( N − k ) exp( C /T )+ P j ∈ K exp( z j /T ) ≈ 0 otherwise. (4) ˜ A = P N j =1 exp( z j /T ) ( N − k ) exp( C /T ) + P j ∈ K exp( z j /T ) (5) W e explore the resulting recognition accurac y for multi- ple settings of temperature T and candidate logits selection k , which are summarized in Figure 2. 4.2.1. T emperatur e T = 1 While using a temperature of 1, no significant dif ferences in WER can be seen even for a very aggressi ve logits selection (5 senones out of 3010). Inspecting the average output distribu- tion after application of softmax, we find out that the highest probability is close to one and the rest close to zero. There- fore, a sum of probabilities of senones that do not belong to the 5-best is still small. Redistrib ution of this mass among 5-best senones then does not affect the distrib ution much. 4.2.2. T emperatur e T = 2 Interestingly , the combination of temperature 2 with logits se- lection bring accurac y improv ements. W e observ e that taking 5-best v alues into consideration is not sufficient. Howe ver , the dif ference between results obtained using 20-best and 40- best logits is minimal. 4.2.3. T emperatur e T = 5 When the output distribution gets flatter (temperature 5), the difference among highest probabilities diminishes. Then the effect of multiplication by constant is similar for all k senones and it becomes more dif ficult to estimate the correct one. The fewer candidates are taken into account, the more se vere degradation occurs. Based on the analysis, the most promising hyperparam- eters for our student models are: temperature T = 2 . 0 and k = 20 for logits selection. These values are fixed for the following e xperiments. 4.3. Size of the training dataset Building both the baseline and the multi-condition system re- quire transcribed data. Compared to those methods, the major advantage of the teacher-student training approach is that it does not require transcripts once the teacher model is trained. Therefore, we could explore how much the WER can be fur- ther reduced by incorporating ev en lar ger number of utter- ances in the training set to build the student model. The stu- dent training dataset is gradually increased up to ten times more audio compared with the original amount. The relativ e word error rate reduction (WERR) is displayed in Figure 3 as a function of training data size. Similar trends are observ ed for all the test datasets. As e xpected, the accuracy impro ves with the increasing amount of data. Howe ver , the minimum WER is achiev ed when using approximately 4800 hours ( 6 × ). It could be possible that we only ha ve about 4800 hours of unique noise resources and the model ov erfits after adding re- peated noise examples. This hypothesis, ho wev er , requires further inv estigation. Alternativ ely , the f act that the teacher itself is erroneous could also affect dependence of accuracy on training data size. 1 2 5 temperature -5.0 -2.5 0.0 2.5 5.0 7.5 10.0 12.5 relative WERR [%] 5 kbest 20 kbest 40 kbest max kbest (a) clean test set 1 2 5 temperature -20.0 -18.0 -16.0 -14.0 -12.0 -10.0 -8.0 -6.0 relative WERR [%] 5 kbest 20 kbest 40 kbest max kbest (b) noisy test set 1 2 5 temperature -12.5 -10.0 -7.5 -5.0 -2.5 0.0 2.5 relative WERR [%] 5 kbest 20 kbest 40 kbest max kbest (c) r ealistic test set Fig. 2 : Relative word err or r ate reduction (WERR) [%] (with r espect to the cross-entr opy tr ained teacher) fr om dif ferent student models when tunning the distillation temperatur e and logits selection. max kbest means preserving all lo gits. 1x 2x 4x 6x 8x 10x training dataset size -9.5 -9.0 -8.5 -8.0 -7.5 -7.0 -6.5 -6.0 relative WERR [%] (a) clean test set 1x 2x 4x 6x 8x 10x training dataset size -26.0 -25.0 -24.0 -23.0 -22.0 -21.0 relative WERR [%] (b) noisy test set 1x 2x 4x 6x 8x 10x training dataset size -19.0 -18.0 -17.0 -16.0 -15.0 -14.0 relative WERR [%] (c) r ealistic test set Fig. 3 : Relative word err or r ate reduction (WERR) [%] (with r espect to the cross-entr opy tr ained teacher) fr om dif ferent student models incorporating mor e untranscribed training data. “ 1 × ” means 1 × 800 hours of training data. F ix T = 2 , k = 20 for building all the models. T able 2 : Ef fects of applying sequence training on both teacher and student models. Results are expr essed in terms of r elative wor d err or rate r eduction (WERR) [%] (with r espect to the cr oss-entr opy trained teacher). Minus sign indicates impr ovement. Relative WERR inside the brac ket is computed with r espect to the sequence trained teac her . T = 2 , k = 20 for building all the student models. Acoustic model T raining objectiv e T raining data Clean test set Noisy test set Realistic test set T eacher xent 800h clean 0.00 0.00 0.00 Student xent 6 × 800 h parallel -9.50 -26.08 -19.57 T eacher xent, sMBR 800h clean, 800h clean -5.79 (0.00) -0.98 (0.00) -3.68 (0.00) Student xent 6 × 800 h parallel -11.89 (-6.48) -26.80 (-26.08) -21.63 (-18.63) Student xent, sMBR 6 × 800 h parallel, 800h noisy -15.29 (-10.08) -29.36 (-28.67) -22.54 (-19.58) 4.4. Sequence training Sequence training has been shown to be ef fective in improv- ing ASR performance in general [33]. W ong and Gales also in vestigated the usefulness of the combination of sequence and teacher -student training [34]. In our experiment, we at first fine-tune the original cross-entropy trained teacher using state-lev el minimum Bayes risk (sMBR) criterion [35]. As displayed in T able 2, the ne w teacher outperforms the origi- nal one on all our test datasets. W e then train a ne w student network on top of the ne w sequence-trained teacher using the parallel corpus. W e used size 6 × of the parallel datasets to train the student as it was sho wn to be the best option in the previous experiment. The new cross-entropy trained student network is able to make use of the improv ed teacher , since its performance is better than that of the student taught by the weaker teacher . Finally , the new student is further optimized by means of sMBR training using only the transcribed portion of noisy data ( 1 × ). 5. CONCLUSION In this paper , we explore the teacher -student learning ap- proach using parallel clean and noisy corpus to impro ve speech recognition performance under multimedia noise. W e gradually optimize this system by applying logits selection and incorporating larger amount of untranscribed training data. W ith a temperature of T = 2 and logits selection of k = 20 highest v alues, we obtain the best student model using a parallel clean and noisy corpus which is about 6 times more of the original clean training data. By applying standard sequence training on both the teacher and student model, the final student brings relative WER reductions of about 10.1%, 28.7% and 19.6% on the clean, simulated noisy and real test sets, respectiv ely . In the future, a larger corpus of noise sources will be col- lected to prev ent the multimedia samples from being repeated. W e will attempt to scale up architecture and training datasets. Soft targets selection based on teacher’ s certainty could be explored as well. 6. REFERENCES [1] Kenichi Kumatani, John McDonough, and Bhiksha Raj, “Microphone array processing for distant speech recognition: From close-talking mi- crophones to far-field sensors, ” IEEE Signal Pr ocessing Magazine , vol. 29, no. 6, pp. 127–140, 2012. [2] Minhua W u, K enichi K umatani, Shiv a Sundaram, Nikko Str ¨ om, and Bj ¨ orn Hoffmeister , “Frequency domain multi-channel acoustic model- ing for distant speech recognition, ” in 2019 IEEE International Con- fer ence on Acoustics, Speech and Signal Processing (ICASSP) . 2019, IEEE. [3] Jinyu Li, Li Deng, Y ifan Gong, and Reinhold Haeb-Umbach, “ An overvie w of noise-robust automatic speech recognition, ” IEEE/ACM T ransactions on Audio, Speech, and Language Pr ocessing , vol. 22, no. 4, pp. 745–777, 2014. [4] Brian King, I-Fan Chen, Y onatan V aizman, Y uzong Liu, Roland Maas, Sree Hari Krishnan Parthasarathi, and Bj ¨ orn Hoffmeister , “Robust speech recognition via anchor word representations, ” INTERSPEECH- 2017 , pp. 2471–2475, 2017. [5] T ara N Sainath, Brian Kingsbury , Bhuvana Ramabhadran, Petr Fousek, Petr Novak, and Abdel-rahman Mohamed, “Making deep belief net- works effecti ve for large vocabulary continuous speech recognition, ” in Automatic Speech Recognition and Understanding (ASR U), 2011 IEEE W orkshop on . IEEE, 2011, pp. 30–35. [6] George E Dahl, Dong Y u, Li Deng, and Alex Acero, “Context- dependent pre-trained deep neural networks for large-v ocabulary speech recognition, ” IEEE Tr ansactions on audio, speech, and lan- guage pr ocessing , vol. 20, no. 1, pp. 30–42, 2012. [7] Geoffrey Hinton, Li Deng, Dong Y u, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly , Andrew Senior , V incent V anhoucke, Patrick Nguyen, T ara N Sainath, et al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups, ” IEEE Signal pr ocessing magazine , vol. 29, no. 6, pp. 82–97, 2012. [8] Steven Boll, “Suppression of acoustic noise in speech using spectral subtraction, ” IEEE T ransactions on acoustics, speech, and signal pro- cessing , vol. 27, no. 2, pp. 113–120, 1979. [9] Bishnu S Atal, “Effecti veness of linear prediction characteristics of the speech wav e for automatic speaker identification and verification, ” the Journal of the Acoustical Society of America , vol. 55, no. 6, pp. 1304– 1312, 1974. [10] Alejandro Acero, “ Acoustical and environmental robustness in auto- matic speech recognition, ” in Proc. of ICASSP , 1990. [11] Hynek Hermansky and Nelson Morgan, “Rasta processing of speech, ” IEEE transactions on speech and audio processing , vol. 2, no. 4, pp. 578–589, 1994. [12] Hynek Hermansky , “Perceptual linear predicti ve (PLP) analysis of speech, ” the J ournal of the Acoustical Society of America , v ol. 87, no. 4, pp. 1738–1752, 1990. [13] Duncan Macho, Laurent Mauuary , Bernhard No ´ e, Y an Ming Cheng, Douglas Ealey , Denis Jouvet, Holly K elleher , Da vid Pearce, and Fa- bien Saadoun, “Evaluation of a noise-robust dsr front-end on aurora databases, ” in INTERSPEECH , 2002. [14] Xiaodong Cui, Markus Iseli, Qifeng Zhu, and Abeer Alwan, “Eval- uation of noise robust features on the Aurora databases, ” in Seventh International Confer ence on Spoken Language Pr ocessing , 2002. [15] Mark JF Gales and Stev e J Y oung, “Robust continuous speech recogni- tion using parallel model combination, ” IEEE T ransactions on Speech and Audio Pr ocessing , vol. 4, no. 5, pp. 352–359, 1996. [16] Pedro J Moreno, “Speech recognition in noisy environments, ” 1996. [17] Christopher J Leggetter and Philip C W oodland, “Maximum likelihood linear regression for speaker adaptation of continuous density hidden markov models, ” Computer speech & languag e , vol. 9, no. 2, pp. 171– 185, 1995. [18] Jian W u and Qiang Huo, “Supervised adaptation of MCE-trained CDHMMs using minimum classification error linear regression, ” in Acoustics, Speech, and Signal Processing (ICASSP), 2002 IEEE Inter - national Confer ence on . IEEE, 2002, vol. 1, pp. I–605. [19] Xiaodong He and Wu Chou, “Minimum classification error lin- ear regression for acoustic model adaptation of continuous density HMMs, ” in Acoustics, Speech, and Signal Processing, 2003. Pr o- ceedings.(ICASSP’03). 2003 IEEE International Confer ence on . IEEE, 2003, vol. 1, pp. I–I. [20] Kai Y u, Mark Gales, and Philip C W oodland, “Unsupervised adaptation with discriminativ e mapping transforms, ” IEEE T ransactions on A udio, Speech, and Languag e Pr ocessing , vol. 17, no. 4, pp. 714–723, 2009. [21] R Lippmann, Edward Martin, and D Paul, “Multi-style training for ro- bust isolated-word speech recognition, ” in Acoustics, Speech, and Sig- nal Pr ocessing, IEEE International Conference on ICASSP’87. IEEE, 1987, vol. 12, pp. 705–708. [22] Jinyu Li, Rui Zhao, Jui-T ing Huang, and Y ifan Gong, “Learning small-size dnn with output-distribution-based criteria, ” in F ifteenth an- nual confer ence of the international speec h communication associa- tion , 2014. [23] Geoffrey Hinton, Oriol V inyals, and Jeff Dean, “Distilling the knowl- edge in a neural network, ” arXiv pr eprint arXiv:1503.02531 , 2015. [24] Y evgen Chebotar and Austin W aters, “Distilling knowledge from en- sembles of neural networks for speech recognition., ” in Interspeech , 2016, pp. 3439–3443. [25] Liang Lu, Michelle Guo, and Ste ve Renals, “Knowledge distillation for small-footprint highway networks, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Confer ence on . IEEE, 2017, pp. 4820–4824. [26] George T ucker , Minhua W u, Ming Sun, Sankaran Panchapagesan, Gengshen Fu, and Shi v V italadevuni, “Model compression applied to small-footprint keyword spotting., ” in INTERSPEECH , 2016, pp. 1878–1882. [27] Jinyu Li, Michael L. Seltzer , Xi W ang, Rui Zhao, and Y ifan Gong, “Large-scale domain adaptation via teacher-student learning, ” in IN- TERSPEECH , 2017. [28] Sree Hari Krishnan P arthasarathi and Nikko Str ¨ om, “Lessons from building acoustic models with a million hours of speech, ” in 2019 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) . 2019, IEEE. [29] Has ¸im Sak, Andre w Senior , and Franc ¸ oise Beaufays, “Long short-term memory recurrent neural network architectures for large scale acoustic modeling, ” in F ifteenth annual conference of the international speech communication association , 2014. [30] Anirudh Raju, Sankaran Panchapagesan, Xing Liu, Arindam Mandal, and Nikko Str ¨ om, “Data augmentation for robust keyword spotting under playback interference, ” Aug. 2018, arXiv:1808.00563 e-prints. [31] Jont B. Allen and David A. Berkley , “Image method for ef ficiently simulating smallroom acoustics, ” The J ournal of the Acoustical Society of America , vol. 65, no. 4, pp. 943–950, 1979. [32] Robin Scheibler, Eric Bezzam, and Ivan Dokmani ´ c, “Pyroomacous- tics: A python package for audio room simulations and array process- ing algorithms, ” in 2018 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) . 2018, IEEE. [33] Karel V esel ´ y, Arnab Ghoshal, Luk ´ a ˇ s Burget, and Daniel Pove y , “Sequence-discriminativ e training of deep neural networks, ” in Pro- ceedings of Interspeech 2013 . 2013, number 8, pp. 2345–2349, Inter- national Speech Communication Association. [34] Jeremy H.M. W ong and Mark J.F . Gales, “Sequence student-teacher training of deep neural networks, ” in INTERSPEECH 2016 , pp. 2761– 2765. [35] Matthew Gibson and Thomas Hain, “Hypothesis spaces for minimum bayes risk training in large vocabulary speech recognition, ” in Ninth International Confer ence on Spoken Language Pr ocessing , 2006.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment