멀티미디어 잡음에 강한 자동음성인식을 위한 병렬 데이터와 교사학생 학습
본 연구는 깨끗한 음성과 잡음이 섞인 음성의 병렬 코퍼스를 활용해 교사‑학생(Teacher‑Student) 학습을 적용하고, 로그잇 선택(logits selection) 기법으로 상위 k 개의 출력만 전달함으로써 데이터 전송량을 감소시키면서도 잡음에 강인한 ASR 모델을 구축한다. 800 시간의 전사된 청정 데이터로 교사를 학습시키고, 최대 8000 시간의 비전사 데이터(청정‑잡음 병렬)로 학생을 훈련한다. 온도 파라미터 T = 2와 k = 2…
저자: Ladislav Mov{s}ner, Minhua Wu, Anirudh Raju
본 논문은 실생활에서 스마트 스피커나 모바일 디바이스가 다양한 배경 잡음 속에서도 정확히 음성을 인식하도록 하는 문제를 다룬다. 기존의 잡음 강인성 향상 방법은 전처리 기반의 특징 강화, 다중 스타일 학습, 혹은 대규모 전사 데이터 확보에 의존했지만, 전사 데이터는 비용이 많이 들고 잡음 환경마다 새로운 라벨링이 필요했다. 이를 극복하고자 저자들은 교사‑학생(Teacher‑Student, T/S) 학습을 도메인 적응 방식으로 활용한다. 구체적으로, 청정 음성 800 시간을 전사해 교사 모델을 학습하고, 동일 청정 음성에 멀티미디어 잡음(음악, 영상 사운드 등)과 방 반향을 시뮬레이션해 만든 병렬 데이터(청정‑잡음 쌍)를 이용해 학생 모델을 훈련한다. 학생은 잡음이 섞인 입력에 대해 교사의 소프트 타깃(확률 분포)을 모방하도록 KL‑다이버전스를 최소화한다. 이때 교사의 파라미터는 고정되며, 학생은 전적으로 교사의 출력에 의해 지도된다.
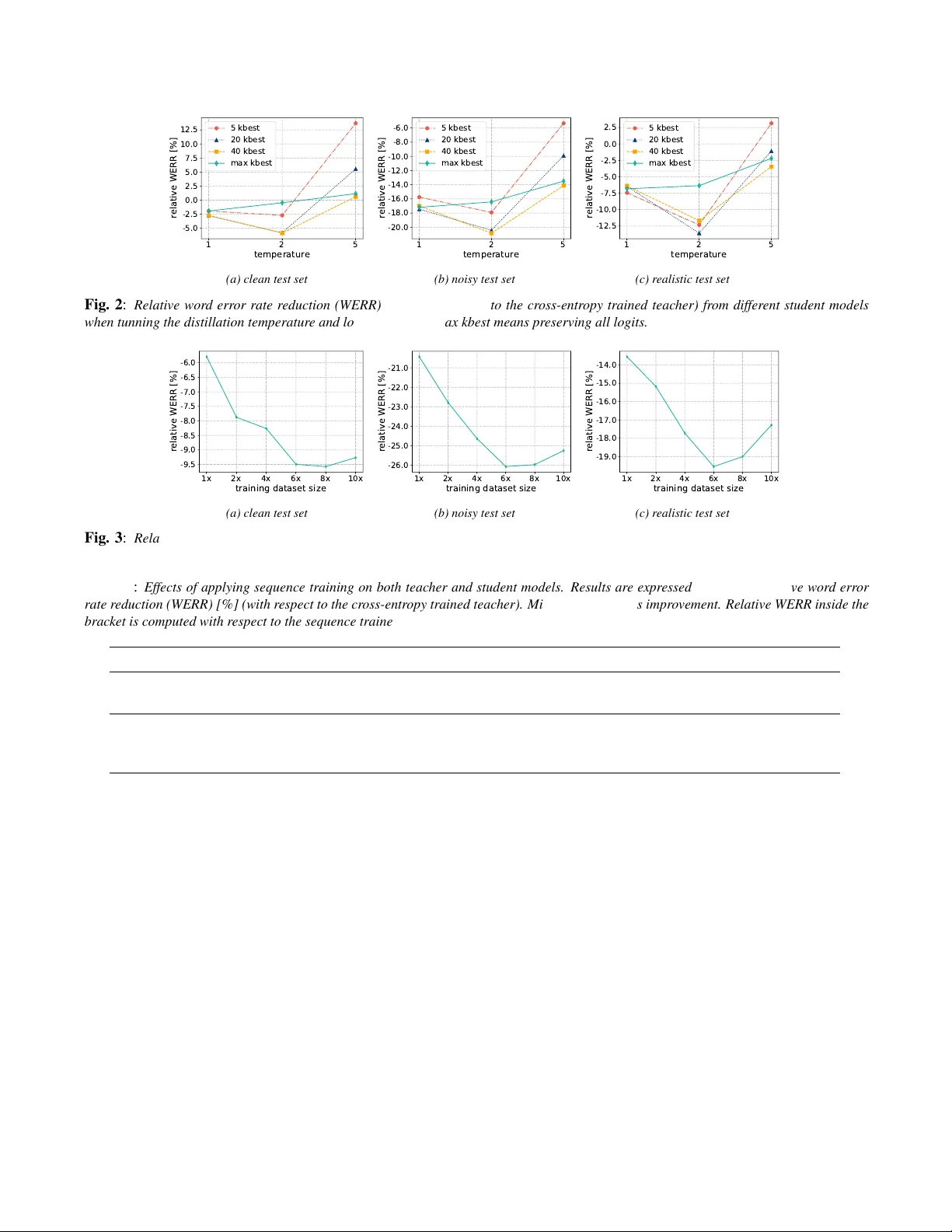
핵심 기법으로 로그잇 선택(logits selection)이 도입된다. 일반적인 소프트맥스 출력은 수천 개의 senone에 대해 확률을 제공하지만, 대부분의 확률 질량은 상위 몇 개에 집중된다. 따라서 상위 k 개의 로그잇만 남기고 나머지는 매우 작은 상수값으로 대체함으로써 저장·전송 비용을 크게 줄이고, 교사의 낮은 확률값이 학생에게 과도히 영향을 미치는 것을 방지한다. 실험에서는 온도 파라미터 T 와 k 값을 다양하게 조정했으며, 최적 조합은 T = 2와 k = 20이었다. 온도 T = 1은 출력이 지나치게 확정적이라 선택적 압축 효과가 미미했고, T = 5는 확률 분포가 평탄해져 잡음이 많은 senone까지 고르게 강조돼 학습이 혼란스러워졌다.
데이터 규모에 대한 실험에서는 비전사 병렬 데이터를 1배(800 h)부터 10배(8000 h)까지 확대했을 때, WER 감소는 지속적으로 향상되었지만 4800 h(6배)에서 정점에 도달했다. 이는 잡음 종류와 방 환경 시뮬레이션이 제한적이어서 추가 데이터가 중복 효과를 내기 때문일 가능성이 있다.
시퀀스 훈련(sMBR)과의 결합도 검증되었다. 먼저 교사를 sMBR로 미세조정해 성능을 향상시킨 뒤, 동일한 교사로부터 학생을 학습시켰다. 결과적으로, 교사 자체가 개선되면 학생도 그 혜택을 그대로 받으며, 최종적으로 학생을 다시 sMBR로 미세조정하면 전체 시스템이 가장 큰 성능 향상을 보였다. 구체적인 결과는 다음과 같다. 깨끗한 테스트 셋에서는 약 10 %의 상대 WER 감소, 시뮬레이션 잡음 셋에서는 약 29 % 감소, 실제 실내 잡음 셋에서는 약 22 % 감소를 달성했다.
전체적으로 이 연구는 (1) 전사 없이도 대규모 잡음 데이터 활용이 가능한 교사‑학생 기반 도메인 적응 방법을 제시하고, (2) 로그잇 선택을 통해 소프트 타깃 전송 효율성을 높이며 학습 안정성을 강화하고, (3) 시퀀스 훈련과의 시너지를 통해 최종 모델의 성능을 극대화한다는 세 가지 주요 기여를 한다. 이러한 접근은 실시간 음성 인식 서비스에서 비용 효율적으로 잡음 강인성을 확보하고자 하는 실제 적용 사례에 직접적인 가치를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기