Enhancing Music Features by Knowledge Transfer from User-item Log Data
In this paper, we propose a novel method that exploits music listening log data for general-purpose music feature extraction. Despite the wealth of information available in the log data of user-item interactions, it has been mostly used for collabora…
Authors: Donmoon Lee, Jaejun Lee, Jeongsoo Park
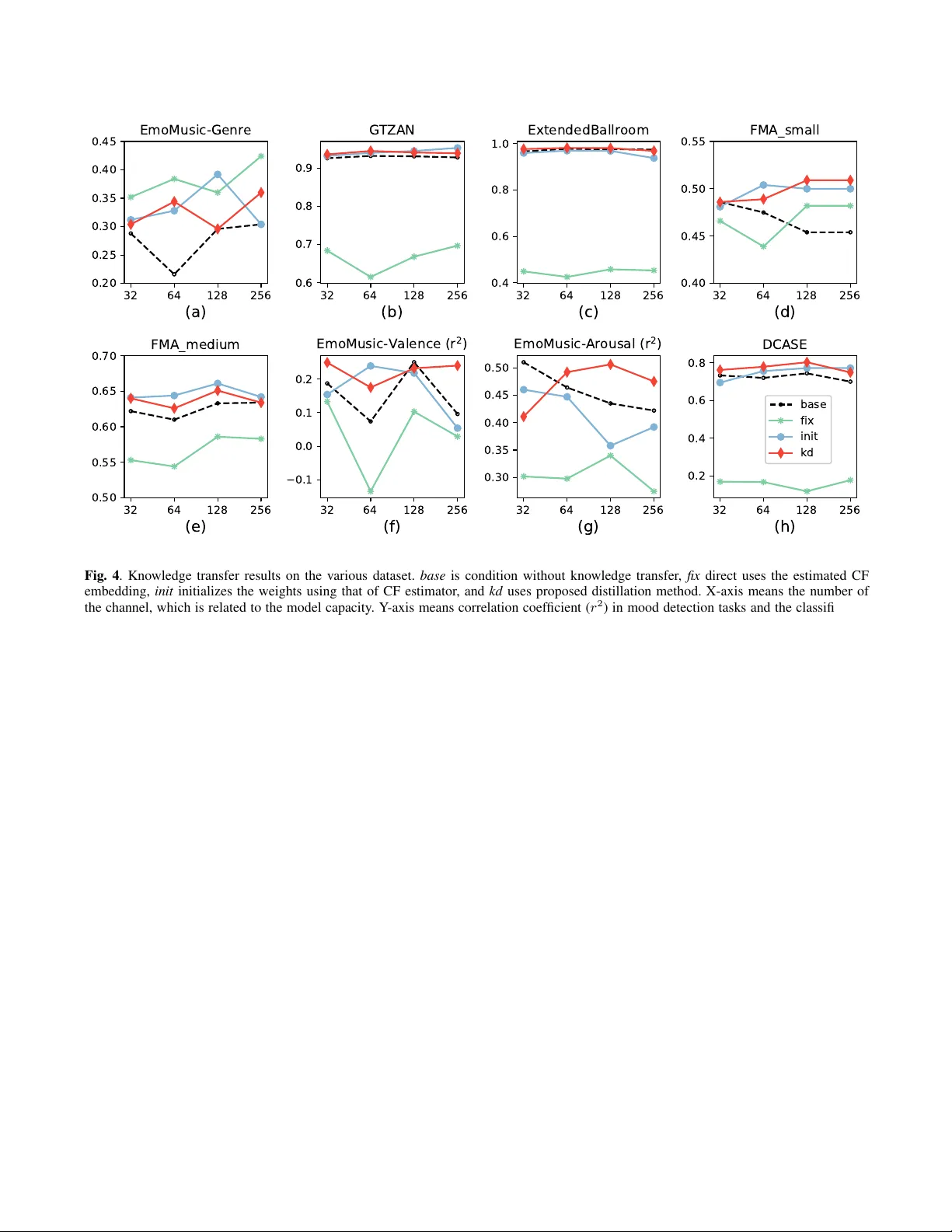
ENHANCING MUSIC FEA TURES BY KNO WLEDGE TRANSFER FR OM USER-ITEM LOG DA T A Donmoon Lee 1 , 2 , 3 , J aejun Lee 1 , J eongsoo P ark 2 , and K yogu Lee 1 , 3 1 Music and Audio Research Group, Seoul National Uni versity , Korea 2 Cochlear .ai, K orea 3 Center for Superintelligence, Seoul National Uni versity , Korea ABSTRA CT In this paper , we propose a novel method that exploits music lis- tening log data for general-purpose music feature extraction. De- spite the wealth of information av ailable in the log data of user- item interactions, it has been mostly used for collaborative filter- ing to find similar items or users and was not fully in vestigated for content-based music applications. W e resolv e this problem by ex- tending intra-domain knowledge distillation to cross-domain: i.e . , by transferring knowledge obtained from the user-item domain to the music content domain. The proposed system first trains the model that estimates log information from the audio contents; then it uses the model to improve other task-specific models. The experiments on various music classification and regression tasks show that the pro- posed method successfully improves the performances of the task- specific models. Index T erms — Music feature extraction, user-item log, knowl- edge distillation, knowledge transfer , neural networks. 1. INTR ODUCTION Recent advances in deep learning hav e shown to be very successful in many application areas, and music information retriev al (MIR) is not an exception. Remarkable performance gains seen in several MIR-related tasks such as genre classification, mood estimation, au- tomatic music transcription, and music recommendation, to name a few , are mainly due to powerful deep learning models trained on a large amount of data. One of the major drawbacks in this approach is, howe ver , that the performance of the deep learning-based algo- rithms is highly dependent on the amount of annotated training data. The process of labeling and verifying music data requires more time and ef fort than other types of data, such as images. Further - more, the fact that one music piece can have multiple attributes or labels mak e the process e ven more difficult. Some publicly a vailable datasets such as GTZAN [1] contain manually labeled tags; hence the quality of the tags are guaranteed. Ho wev er, the types of tags, as well as the amount of the data, are limited. The datasets such as million song dataset [2] and MagnaT agA T une [3] provide the user- generated label. The y are kno wn to provide a wide v ariety of unique tags; howe ver , they can cause false negati ve problems since the users create the labels based on the their own criteria, often skipping some crucial information. Hence, the con ventional research efforts were limited to use the tags that frequently appear [4, 5]. W e aim to alleviate the above-mentioned problems of the audio data with the use of user listening log data ( user -log ). This approach is mainly motiv ated by the pre vious music recommendation research which used audio content analysis to estimate missing user-log [6] and the follo w-up studies [7, 8]. According to Lee et al. [8], the user-log contains abundant useful information; their method based on the lo w-dimensional song representations derived from the user- log shows similar result compared to the audio-based approaches in the auto-tagging task. Besides, the main advantage of user-log is that unlike music tags, it can be collected without additional human efforts. It is constantly accumulating through the listening behavior of people. Figure 1 sho ws our pilot experiment to test whether we can ex- tract different types of information from the user-log data compared to the audio tags. The first model (’audio tags’) is trained with the genre tags provided in the dataset; the second model (’user-log’) is trained with the user-log embedding and concatenated to the linear classifier . Even if the second approach does not use the genre in- formation in network training, it successfully predicts the genre and the class-wise performance dif fers from the case of using audio tags. This suggests joint exploitation of the user-log data with the audio tags to be promising. Ne vertheless, the previous approaches failed to simultaneously exploit the user-log data with the audio tags due to the difficulty in the cross-domain data con version. W e tackle this problem with the training approach inspired by the knowledg e tr ansfer . Kno wledge transfer in the neural network implies the use of the weight of the learned model for other tasks. It is generally assumed that kno wledge transfer models ha ve e xtensiv e information because they are trained from large dataset or because the model capacity is large. Depending on the methods to utilize a trained model, it can be classified as transfer methods and distillation methods. The transfer methods directly use the outputs of the learned networks. Some methods exploited their intermediate acti vation as a feature for different tasks [9, 7]; while others used their outputs for the fine-tuning [10]. On the other hand, the distillation methods, of- ten referred to as teacher-student methods, utilize a posterior distri- bution of the teacher network itself to train other models [11]. Pre- vious distillation-based approaches were proposed to solve within- domain applications [12, 13] or semi-supervised tasks [14, 15] with the purpose of the network compression. In this paper , we introduce a novel method that transfers the knowledge from the user-log to music features. T o our best knowl- edge, this is the first approach to use the user-log data in the frame of knowledge transfer . W e train a model to predict the user-log in- formation from audio, transfer it to other task-specific models, and compare our approach with the con ventional transfer methods for various music-related tasks. ballad ccm classic dance electronica f-b-c hip-hop jazz jpop korean newage pop rnb-soul rock trot 0.0 0.2 0.4 0.6 0.8 Accuracy audio tags user-log Fig. 1 . Class-wise results of genre classification using user-log and audio tags in Melon dataset. (k orean and f-b-c indicate K or ean tradi- tional music and the union genre of folk, blues, and country , respec- tiv ely .) 2. PR OPOSED METHOD Figure 2 shows an overvie w of the proposed method. It is designed to improv e the performance of general music-related tasks by utilizing user-log information. The user-log specifically exists as a user-item matrix indicating whether a particular user has listened to a particular song. Since the raw user-log is sparse and high-dimensional, it is usually con verted into a compressed representation through dimension reduction meth- ods such as matrix f actorization. This is the typical representation of the song in the collaborati ve filtering (CF) method in the music rec- ommendation systems, which is referred to as CF embedding. One of the advantages of using CF embedding vectors is their size; it does not require human labor to generate the ground-truth. Therefore, it is relatively easy to obtain the CF embedding vectors from the large-scale music database compared to the other features that require human labeling. Nevertheless, it has only been used for the music recommendation systems since the method to utilize the CF embedding vectors has not been fully in vestigated. In order to successfully utilize the CF embedding vectors, we employ knowledge transfer method. T o this end, we first train the model (CF estimator) that estimates the CF embedding vectors from the audio contents using massi ve user-log data; then we use the CF estimator’ s output to regularize the task-specific models which are trained with small-scale datasets. In specific, we constrain the penul- timate layers of the task-specific models by using the estimated CF embedding to calculate additional loss function. 3. EXPERIMENTS 3.1. T raining CF estimator 3.1.1. Dataset Music and log data from Melon 1 are used to train the network. The songs are randomly drawn from the Melon’ s pre view excerpts which hav e played more than once in May 2018. A single log contains in- formation about who listened to which song. The number of the logs collected is about 4.7M, and when conv erting it to a binary user-item matrix, there are 5M users and 2.5M songs with non-zero values of 1 A music streaming service in K orea, https://www .melon.com Fig. 2 . The overvie w of the proposed system. The CF estimator model is first trained to estimate user-log based representation for a giv en song. A task-specific model is then simultaneously trained to estimate both their objectiv e and and CF embedding. 991M. W e optimized this using ALS algorithm based on the settings of the previous research [16]. The CF embedding vector dimension is set to 40 according to our experience on the music recommenda- tion task. W e randomly selected 244,975 songs for the experiment, which was divided into training set (187,404 songs), validation set (20,831 songs), and test set (36,740 songs). 3.1.2. Network ar chitectur e The structure of the teacher network is illustrated in T able 1. It uses 30-second wav eform as input, which is conv erted to mel spectrogram with a shape of (96, 1280, 1), each of which corresponds to the num- ber of mel bins, time frames, and channels. The network consists of a repetitive stack of double conv blocks and max-pooling layers with the fully-connected output layer [17]. All the double conv block consist of two sets of batch normalization, ReLU activ ation, and con volutional layer and one SE (Squeeze-and-excitation) [18] block following last con volutional layer . All con volutional layer in one model has the fixed filter size of (3x3) and the same number of the feature maps. All the ratio of SE block is set to 8. The size of the first four max-pooling layers are (4,5), (3,4), (2,4), and (2,4) in order . A global average pooling layer is attached to end of the fifth double conv block with follo w- ing 40-dimensional fully-connected layer with linear activ ation. The fully-connected layer is the output of the teacher network, and the dimension corresponds to that of the CF embedding. As a loss function, additional cosine proximity was used in addi- tion to the mean squared error used in previous studies [6, 8]. Since the direction is one of the important factors when dealing with the CF embedding. W e controlled the number of channels in the conv olution layer to see the ef fect of model capacity follo wing [19]. Four models with 32, 64, 128, and 256 channels were trained. 3.1.3. T raining details W e selected the middle-30 second, which is similar to previous stud- ies [4, 5], of the previe w excerpt and resampled to 16,000 Hz. Mel spectrogram is extracted on GPU using Kapr e [20] with the 512 FFT points (32ms) and hop size of 375 (23ms). For training, Layer Output shape Audio input (1,480000) Mel spectrogram (96, 1280, 1) Double conv block 4 x 5 Max-pooling (24, 256, F ) Double conv block 3 x 4 Max-pooling (8, 64, F ) Double conv block 2 x 4 Max-pooling (4, 16, F ) Double conv block 2 x 4 Max-pooling (2, 4, F ) Global av erage pooling ( F ) Fully-connected layer (40) T able 1 . The structure of the CF estimator network. The network is constructed using the successi ve double conv block and max- pooling layer . Double conv block has tw o stacks of batch normal- ization layer, ReLU, and conv olutional layer and SE block with the ratio of 8 after the last con volutional layer . All the con volutional lay- ers hav e (3 x 3) of filter size and the same number of channels. F means the number of channels. Adam [21] optimizer with a learning rate of 0.001 was used, and we choose the model which sho ws the least loss in the v alidation set. The experiment is implemented in Ker as [22] with T ensorflow [23] backend. 3.2. T ransfer to other tasks 3.2.1. List of tasks Since the CF embedding vector is a song-level descriptor, it is proper to apply the proposed method to the song-level classifica- tion/regression tasks. Six datasets are used in our experiments; fiv e of them are related to music and the other one contains acoustic scene data. The last dataset is used to in vestigate the applicability of the proposed method ev en when it is applied for the general audio classification task. • Genre classification tasks on the EmoMusic [24], GTZAN [1], ExtendedBallRoom [25], FMA small [26], and FMA medium datasets. • Music emotion regression task on the EmoMusic dataset. T wo in- dependent models are trained to predict valence and arousal. • Acoustic scene classification task on DCASE2016 [27] dataset. 3.2.2. Experiment configuration The purpose of the experiment is to inv estigate the transition in per- formance of the task-specific models when the proposed knowledge transfer method is applied. A total of four training methods includ- ing the proposed method are used. The baseline method ( base ) trains the network from scratch. The first transfer method ( fix ) uses CF es- timator as the feature extractor and only the output layer is trained for the regression or classification task. The second transfer method ( init ) uses weights of the CF estimator to initialize the weights of the task-specific model. In this case, the entire weights of the model hav e to be trained. The proposed method ( kd ) only adds distillation loss to base . The loss function is calculated with the activ ation of the Fig. 3 . Four training approaches used in experiment. base trains en- tire network from scratch, fix only trains classifier , init trains entire network with initialized weights, and kd trains entire network with an additional loss function. penultimate layer and the output of the CF estimator; the sum of the mean squared error and the cosine proximity is used to calculate the loss function. Except for GTZAN and BallRoomExtended datasets, the pre- defined training and test sets are used for e valuation. The two datasets without pre-defined set are ev aluated using stratified 10-fold cross-validation. W e use the models that hav e the least task-specific loss in training for evaluation. In a dataset without v alidation set or where we perform cross-validation, the v alidation set is selected out of the train set. 4. RESUL T AND DISCUSSION Experimental results are illustrated in the Figure 4. Except the results in Figure 4 (b) and (c) which are ev aluated through cross-validation, the remaining results are e valuated through single experiment. That is, the results listed include v ariants of the e xperiment, and addi- tional iterations are needed to determine statistical significance be- tween methods. Howe ver , we can see trends in each method through experimental results performed under v arious conditions. In various datasets and experimental conditions, kd shows not always, but mostly high performance. In particular, it always shows similar or higher performance than base , except for the 32 chan- nels of Figure 4 (g). For 24 experiments that performed classifica- tion tasks based on four model capacities in six datasets, kd sho ws statistically significant improvement of 2.62 % points over base (Stu- dent paired t-test). init also shows high performance in most experi- ments. Ho we ver , the tendency of improv ement is less stable than kd , as there is a case where the performance is lo wer than base as sho wn in Figure 4 (f). In fact, for all classification e xperiments, there is a performance improvement of 2.20 % points o ver base , which is slightly lower than that of kd . Howe ver , there is no statistically sig- nificant difference between the two methods. This suggests that the knowledge trained from user-log can be deli vered through both the proposed method and the con ventional transfer method. The proposed method has an advantage in that it can be applied irrespectiv e of the network structure. Because the distillation method is mainly used for the network compression, it is assumed that the structure of the task-specific network differs from that of the network which transfers the knowledge. Therefore, the proposed method is likely to be used in v arious ways in practical applications. Another advantage is that it does not cause se vere performance degradation. Even if the case of Figure 4 (h), where trained knowledge is not very helpful to the tar get task, the proposed method impro ves perfor- mance. W e assumed that the two loss functions competitively af fect 32 64 128 256 (a) 0.20 0.25 0.30 0.35 0.40 0.45 EmoMusic-Genre 32 64 128 256 (b) 0.6 0.7 0.8 0.9 GTZAN 32 64 128 256 (c) 0.4 0.6 0.8 1.0 ExtendedBallroom 32 64 128 256 (d) 0.40 0.45 0.50 0.55 FMA_small 32 64 128 256 (e) 0.50 0.55 0.60 0.65 0.70 FMA_medium 32 64 128 256 (f) −0.1 0.0 0.1 0.2 EmoMusic-Valence (r 2 ) 32 64 128 256 (g) 0.30 0.35 0.40 0.45 0.50 EmoMusic-Arousal (r 2 ) 32 64 128 256 (h) 0.2 0.4 0.6 0.8 DCASE base fix init kd Fig. 4 . Knowledge transfer results on the v arious dataset. base is condition without kno wledge transfer , fix direct uses the estimated CF embedding, init initializes the weights using that of CF estimator, and kd uses proposed distillation method. X-axis means the number of the channel, which is related to the model capacity . Y -axis means correlation coef ficient ( r 2 ) in mood detection tasks and the classification accuracy of the rest of tasks. the task-specific model, and the network selectively receives useful information for the task. CF embedding itself is not a generally well-defined descriptor for all music or audio related tasks. Since the direct use of the es- timated CF embedding ( fix ) always shows the lowest performance, except for the Figure 4 (a) and (d). In particular , the result of the acoustic scene classification task on Figure 4 (h), which is not a music-related task, sho ws slightly higher performance than a ran- dom guess. Meanwhile, in Figure 4 (a), fix shows the best accuracy in three out of four model capacities. Considering EmoMusic’ s ex- perimental results sho w low overall performance, it is assumed that the structure used in the experiment is not suitable for this data set. W e thought of the reason as the size of the dataset; EmoMusic is the smallest dataset in the experiment. In this case, CF embedding rather than the direct genre label is better ground-truth for network training. It suggests that estimated CF embedding contains the high- lev el information related to music and sometimes it is more powerful descriptor than the human labeled ground-truth. In a series of experiments, there is no noticeable trend between the capacity of the model and the transfer method. W e thought that model capacity w ould not ha ve had a significant impact because re g- ularization modules such as s batch normalization and SE blocks are used from base structure. In fact, the results of Figure 4 (b) and (c) are similar to state-of-the-art regardless of the capacity of the mod- els. Rather , there appears to be a relationship between learned knowl- edge and transfer effect. There is a similar trend between fix and init , fix and kd , which is more prominent in the latter . It implies that the type of learned kno wledge has a great influence on knowledge trans- fer , especially the proposed method, b ut further studies are required to clarify the key v ariables associated with it. 5. CONCLUSION In this study , we proposed the kno wledge transfer method that uses user-log information for music feature extraction. W e made song de- scriptors from the user-item log and trained the model that aims to predict the song descriptors from the audio contents. Then we tried to apply the learned knowledge to various task-specific networks. Ac- cording to the experimental results, the proposed distillation method successfully transferred the information of the user-log to the task- specific network as it utilized the information as an additional loss. Our method has advantages in that it can be similarly applied to var - ious music-related tasks as well as it is the first approach that suc- cessfully utilized user-log data in conjunction with the music content data. 6. A CKNO WLEDGEMENTS The authors are deeply grateful to K eunwoo Choi for the help on paper writing. This work was supported partly by Kakao and Kakao Brain corporations and partly by Ne xt-Generation Information Com- puting Development Program through the National Research Foun- dation of Korea (NRF) funded by the Ministry of Science and ICT (NRF-2017M3C4A7078548). 7. REFERENCES [1] George Tzanetakis and Perry Cook, “Musical genre classifica- tion of audio signals, ” IEEE T ransactions on speech and audio pr ocessing , vol. 10, no. 5, pp. 293–302, 2002. [2] Thierry Bertin-Mahieux, Daniel PW Ellis, Brian Whitman, and Paul Lamere, “The million song dataset., ” in Ismir , 2011, vol. 2, p. 10. [3] Edith Law , Kris W est, Michael I Mandel, Mert Bay , and J Stephen Downie, “Evaluation of algorithms using games: The case of music tagging., ” in ISMIR , 2009, pp. 387–392. [4] Keunw oo Choi, Gy ¨ orgy Fazekas, and Mark Sandler, “ Auto- matic tagging using deep con volutional neural networks, ” in The 17th International Society of Music Information Retrieval Confer ence, New Y ork, USA . International Society of Music In- formation Retriev al, 2016. [5] Jongpil Lee and Juhan Nam, “Multi-lev el and multi-scale feature aggreg ation using pretrained conv olutional neural net- works for music auto-tagging, ” IEEE signal pr ocessing letters , vol. 24, no. 8, pp. 1208–1212, 2017. [6] Aaron V an den Oord, Sander Dieleman, and Benjamin Schrauwen, “Deep content-based music recommendation, ” in Advances in neural information pr ocessing systems , 2013, pp. 2643–2651. [7] A ¨ aron V an Den Oord, Sander Dieleman, and Benjamin Schrauwen, “T ransfer learning by supervised pre-training for audio-based music classification, ” in Confer ence of the In- ternational Society for Music Information Retrieval (ISMIR 2014) , 2014. [8] Jongpil Lee, Kyungyun Lee, Jiyoung Park, Jangyeon P ark, and Juhan Nam, “Deep content-user embedding model for music recommendation, ” arXiv pr eprint arXiv:1807.06786 , 2018. [9] Keunw oo Choi, Gy ¨ orgy Fazekas, Mark Sandler, and Kyungh yun Cho, “Transfer learning for music classification and regression tasks, ” arXiv pr eprint arXiv:1703.09179 , 2017. [10] Juan S G ´ omez, Jakob Abeßer, and Estefanıa Cano, “Jazz solo instrument classification with con volutional neural networks, source separation, and transfer learning, ” . [11] Geoffre y Hinton, Oriol V inyals, and Jeff Dean, “Distill- ing the knowledge in a neural network, ” arXiv pr eprint arXiv:1503.02531 , 2015. [12] Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, An- toine Chassang, Carlo Gatta, and Y oshua Bengio, “Fitnets: Hints for thin deep nets, ” arXiv preprint , 2014. [13] Gregor Urban, Krzysztof J Geras, Samira Ebrahimi Kahou, Ozlem Aslan, Shengjie W ang, Rich Caruana, Abdelrahman Mohamed, Matthai Philipose, and Matt Richardson, “Do deep con volutional nets really need to be deep and con volutional?, ” arXiv pr eprint arXiv:1603.05691 , 2016. [14] Nicolas Papernot, Mart ´ ın Abadi, Ulfar Erlingsson, Ian Good- fellow , and Kunal T alwar , “Semi-supervised knowledge trans- fer for deep learning from pri vate training data, ” arXiv preprint arXiv:1610.05755 , 2016. [15] Zhong Meng, Jinyu Li, Y ifan Gong, and Biing-Hwang Juang, “ Adversarial teacher -student learning for unsupervised domain adaptation, ” in 2018 IEEE International Conference on Acous- tics, Speech and Signal Pr ocessing (ICASSP) . IEEE, 2018, pp. 5949–5953. [16] Y ifan Hu, Y ehuda K oren, and Chris V olinsky , “Collabora- tiv e filtering for implicit feedback datasets, ” in Data Min- ing, 2008. ICDM’08. Eighth IEEE International Confer ence on . Ieee, 2008, pp. 263–272. [17] Donmoon Lee, Subin Lee, Y oonchang Han, and Kyogu Lee, “Ensemble of con volutional neural networks for weakly- supervised sound event detection using multiple scale input, ” Detection and Classification of Acoustic Scenes and Events (DCASE) , 2017. [18] Jie Hu, Li Shen, and Gang Sun, “Squeeze-and-excitation net- works, ” . [19] Keunw oo Choi, Gyorgy Fazekas, Mark Sandler, and Kyungh yun Cho, “Con volutional recurrent neural net- works for music classification, ” in 2017 IEEE International Confer ence on Acoustics, Speech, and Signal Processing , ICASSP 2017 . Institute of Electrical and Electronics Engineers Inc., 2017. [20] Keunw oo Choi, Deokjin Joo, and Juho Kim, “Kapre: On-gpu audio preprocessing layers for a quick implementation of deep neural network models with keras, ” in Machine Learning for Music Discovery W orkshop at 34th International Conference on Machine Learning . ICML, 2017. [21] Diederik P Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” arXiv preprint , 2014. [22] Franc ¸ ois Chollet et al., “Keras, ” https://keras.io , 2015. [23] Mart ´ ın Abadi, Ashish Agarwal, P aul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jef- frey Dean, Matthieu De vin, Sanjay Ghemawat, Ian Goodfel- low , Andrew Harp, Geoffrey Irving, Michael Isard, Y angqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur , Josh Lev enberg, Dandelion Man ´ e, Rajat Monga, Sherry Moore, Derek Murray , Chris Olah, Mike Schuster , Jonathon Shlens, Benoit Steiner , Ilya Sutskev er, Kunal T alwar , Paul T ucker, V incent V anhoucke, V ijay V asudev an, Fernanda V i ´ egas, Oriol V inyals, Pete W arden, Martin W attenberg, Martin W icke, Y uan Y u, and Xiaoqiang Zheng, “T ensorFlow: Large-scale machine learning on heterogeneous systems, ” 2015, Software a vailable from tensorflow .org. [24] Mohammad Soleymani, Micheal N Caro, Erik M Schmidt, Cheng-Y a Sha, and Y i-Hsuan Y ang, “1000 songs for emo- tional analysis of music, ” in Pr oceedings of the 2nd ACM inter- national workshop on Cr owdsourcing for multimedia . A CM, 2013, pp. 1–6. [25] Ugo Marchand and Geoffro y Peeters, “The extended ballroom dataset, ” 2016. [26] Micha ¨ el Defferrard, Kirell Benzi, Pierre V anderghe ynst, and Xavier Bresson, “Fma: a dataset for music analysis, ” arXiv pr eprint arXiv:1612.01840 , 2016. [27] Annamaria Mesaros, T oni Heittola, and T uomas V irtanen, “T ut database for acoustic scene classification and sound event de- tection, ” in Signal Processing Confer ence (EUSIPCO), 2016 24th Eur opean . IEEE, 2016, pp. 1128–1132.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment