사용자 로그를 활용한 음악 특징 강화와 지식 전이
본 논문은 대규모 음악 청취 로그를 이용해 CF 임베딩을 예측하는 모델을 학습하고, 이를 지식 증류 방식으로 다양한 음악 분류·회귀 태스크에 전이함으로써 기존 모델 대비 성능 향상을 달성한다.
저자: Donmoon Lee, Jaejun Lee, Jeongsoo Park
본 논문은 음악 청취 로그 데이터를 활용해 일반적인 음악 특징을 추출하고, 이를 다양한 MIR(음악 정보 검색) 태스크에 전이함으로써 기존 딥러닝 기반 모델의 한계를 보완하고자 한다. 연구 배경으로는 라벨링 비용이 높은 음악 데이터와, 사용자‑아이템 상호작용 로그가 풍부한 메타데이터임에도 불구하고 주로 협업 필터링에만 활용되어 왔다는 점을 들었다. 이러한 로그는 인간이 직접 라벨링하지 않아도 지속적으로 축적되며, 곡 간의 청취 패턴을 반영한 고차원 임베딩(CF 임베딩)으로 변환될 수 있다.
**1. 데이터와 사전 학습**
- 로그 데이터: 멜론 서비스에서 2018년 5월에 수집된 4.7 M개의 청취 로그, 5 M 사용자·2.5 M 곡, 이진 사용자‑아이템 매트릭스로 변환 후 ALS를 이용해 40차원 CF 임베딩을 추출.
- 오디오 입력: 30 초 wav 파일을 16 kHz로 리샘플링하고, 96 mel‑bin × 1280 프레임의 스펙트로그램으로 변환.
- 모델 구조: 5개의 double‑conv 블록(각 블록에 batch‑norm, ReLU, 3×3 conv, SE 블록 포함)과 max‑pooling을 거쳐 global average pooling 후 40‑dim fully‑connected 레이어로 CF 임베딩을 예측. 채널 수는 32, 64, 128, 256 네 가지로 변형해 용량 효과를 검증.
- 손실 함수: 평균 제곱 오차(MSE)와 코사인 유사도 손실을 가중합해 임베딩의 크기와 방향을 동시에 학습.
**2. 지식 전이 방법**
학습된 CF 추정기를 기반으로 세 가지 전이 전략을 설계했다.
- **fix**: 추정기의 출력 임베딩을 고정 피처로 사용하고, 최종 분류/회귀 레이어만 학습.
- **init**: 추정기의 전체 가중치를 초기값으로 복사해, 새로운 태스크에 대해 전체 네트워크를 미세조정.
- **kd (knowledge distillation)**: 베이스 모델을 처음부터 학습하면서, penultimate layer와 추정기의 출력 사이에 MSE + 코사인 손실을 추가해 두 네트워크가 유사한 표현을 만들도록 유도. 이는 구조에 구애받지 않는 전이 방식이며, 기존 지식 증류가 모델 압축에 초점을 맞춘 것과 차별화된다.
**3. 실험 설정**
전이 대상 태스크는 다음과 같다.
- 장르 분류: EmoMusic, GTZAN, ExtendedBallroom, FMA‑small, FMA‑medium (총 5개 데이터셋).
- 감정 회귀: EmoMusic에서 valence와 arousal을 각각 독립 모델로 예측.
- 음향 장면 분류: DCASE2016 (음악 외 일반 오디오).
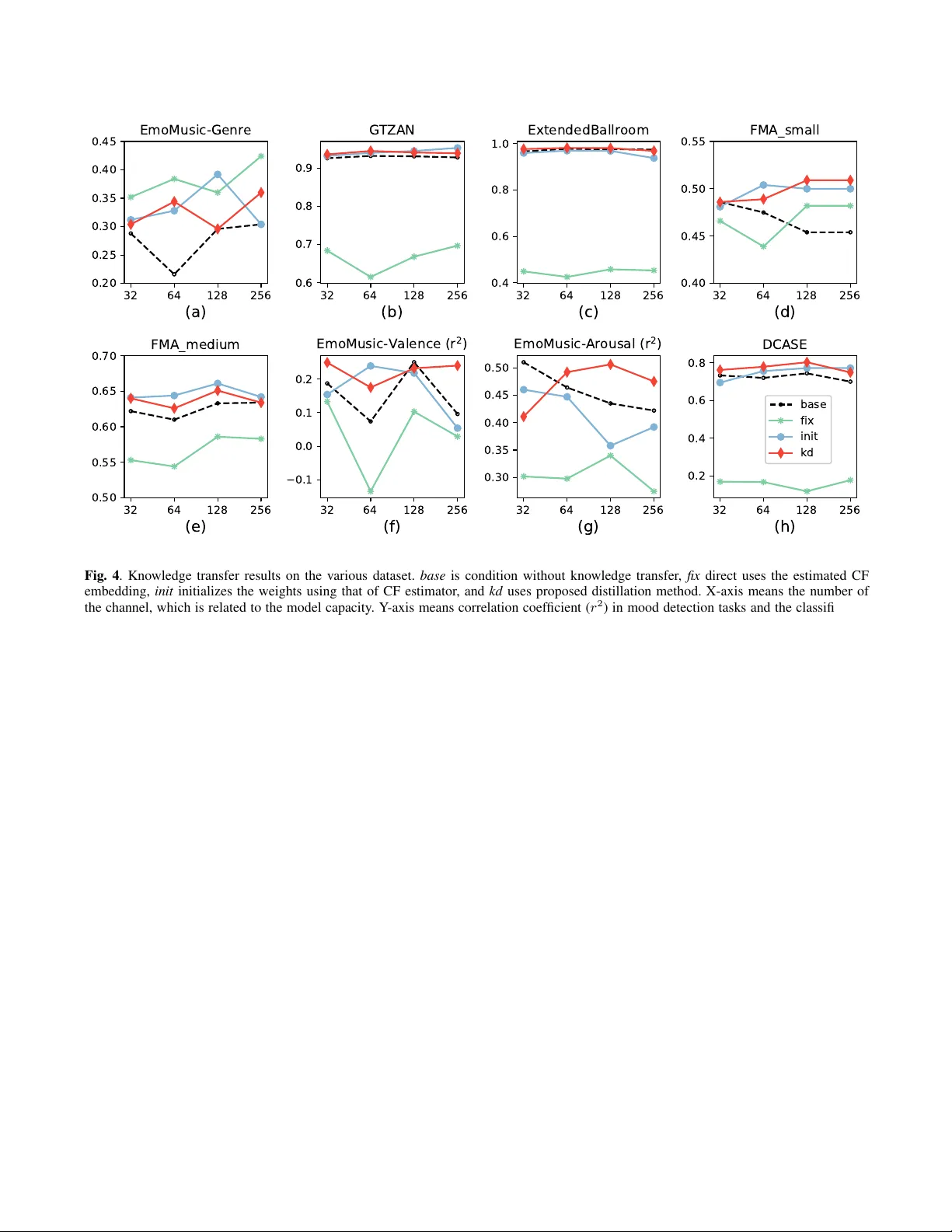
각 데이터셋은 사전 정의된 train/validation/test split을 사용하거나, split이 없을 경우 stratified 10‑fold cross‑validation을 적용했다. 모델 용량(채널 수)별로 4가지 전이 방법을 모두 실험했으며, 최종 성능은 정확도(분류)와 R²(회귀)로 평가했다.
**4. 결과 및 해석**
- **kd**는 대부분의 경우 베이스 모델보다 높은 정확도/회귀 성능을 보였으며, 24개의 분류 실험에서 평균 2.62 %p(통계적으로 유의) 향상을 기록했다.
- **init**도 전반적으로 좋은 성능을 보였지만, 경우에 따라 베이스보다 낮은 결과가 나타났다(예: Figure 4 f).
- **fix**는 직접 임베딩을 피처로 사용할 때 가장 낮은 성능을 보였지만, EmoMusic‑Genre처럼 데이터가 작고 라벨이 불안정한 경우에는 오히려 최고 성능을 기록했다. 이는 CF 임베딩이 인간 라벨보다 더 일반적인 고수준 음악 정보를 담고 있음을 의미한다.
- 모델 용량과 전이 효과 사이에 뚜렷한 상관관계는 없었으며, BN·SE와 같은 정규화 기법 덕분에 작은 모델에서도 전이가 가능했다.
- 비음악 태스크인 DCASE2016에서도 kd가 약간의 향상을 보였으며, 이는 로그 기반 지식이 음악 도메인에 국한되지 않고 일반 오디오 특성에도 일부 전이될 수 있음을 시사한다.
**5. 논문의 의의와 한계**
- 로그 데이터를 고차원 CF 임베딩으로 변환하고, 이를 오디오와 연결하는 파이프라인을 최초로 제시했다.
- 지식 증류를 구조‑무관 전이 수단으로 활용함으로써, 기존 전이(가중치 초기화)와 달리 네트워크 구조가 달라도 적용 가능하게 했다.
- 실험 결과는 다양한 MIR 태스크에서 일관된 성능 향상을 보여, 실제 서비스에서 라벨이 부족한 상황에 로그 기반 지식을 활용할 수 있는 실용적 방안을 제공한다.
- 한계점으로는 CF 임베딩 자체가 모든 음악/오디오 특성을 포괄하지 못한다는 점과, 현재는 40차원이라는 고정 차원을 사용했지만 차원 수에 따른 최적화 연구가 필요하다는 점을 들 수 있다. 또한, 로그 데이터의 품질(스팸 청취, 비활동 사용자 등)과 프라이버시 이슈에 대한 논의가 부족하다.
**6. 결론**
사용자 청취 로그를 통해 얻은 CF 임베딩을 오디오 기반 모델이 예측하도록 학습하고, 이를 지식 증류 방식으로 다양한 MIR 과제에 전이함으로써 라벨링 비용을 절감하고 성능을 향상시킬 수 있음을 입증했다. 제안된 kd 방식은 모델 구조에 구애받지 않으며, 기존 전이 방법보다 안정적인 성능 개선을 제공한다. 향후 로그 데이터의 다양성 확대와 임베딩 차원 최적화, 프라이버시 보호 방안 등을 연구하면 더욱 실용적인 시스템 구축이 가능할 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기