Towards Visually Grounded Sub-Word Speech Unit Discovery
In this paper, we investigate the manner in which interpretable sub-word speech units emerge within a convolutional neural network model trained to associate raw speech waveforms with semantically related natural image scenes. We show how diphone bou…
Authors: David Harwath, James Glass
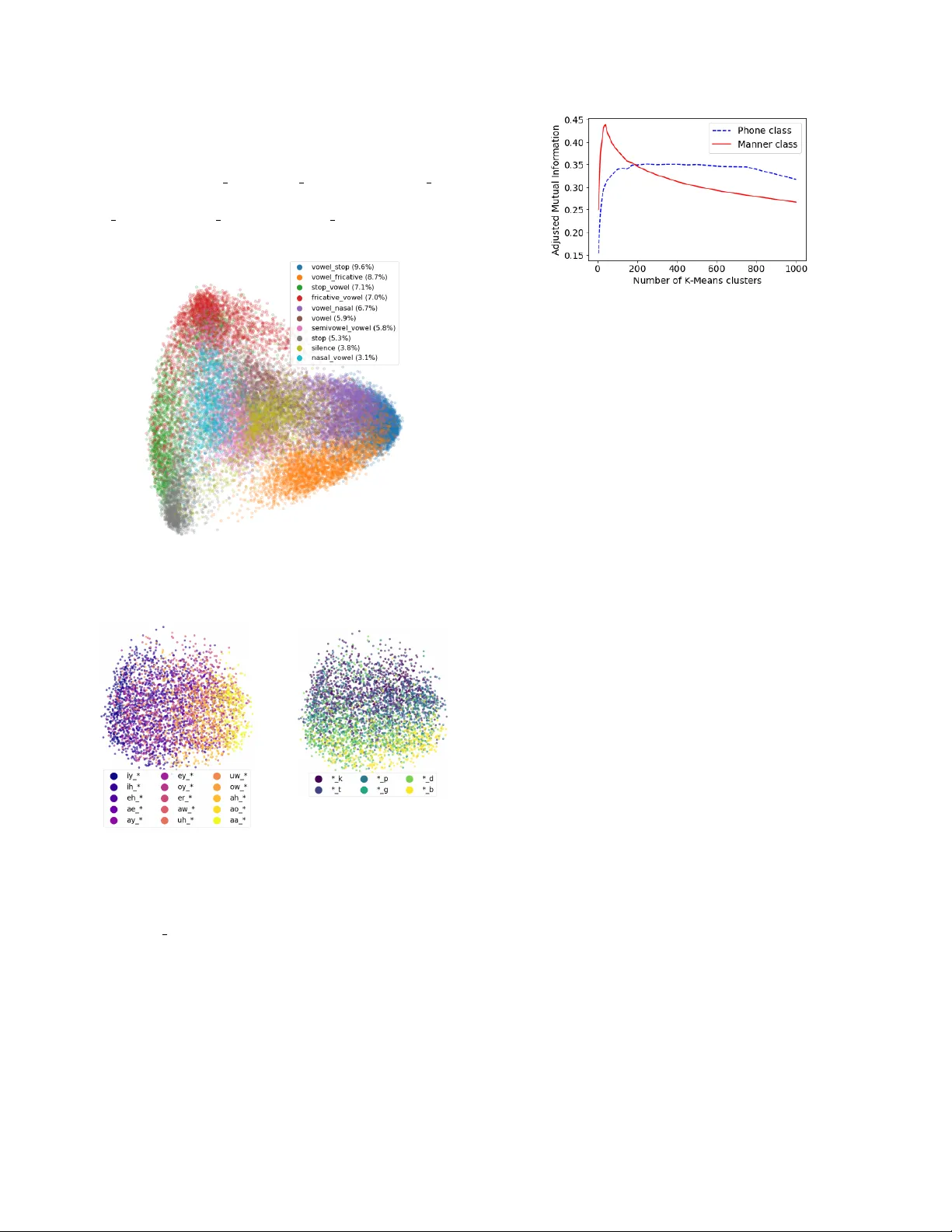
TO W ARDS VISU ALL Y GR OUNDED SUB-WORD SPEECH UNIT DISCO VER Y David Harwath and J ames Glass MIT Computer Science and Artificial Intelligence Laboratory Cambridge, Massachusetts, 02139, USA dharwath@csail.mit.edu, glass@mit.edu ABSTRA CT In this paper , we in vestigate the manner in which interpretable sub-word speech units emerge within a con volutional neu- ral network model trained to associate raw speech wa veforms with semantically related natural image scenes. W e sho w how diphone boundaries can be superficially extracted from the activ ation patterns of intermediate layers of the model, sug- gesting that the model may be le veraging these ev ents for the purpose of word recognition. W e present a series of experi- ments in vestigating the information encoded by these e vents. Index T erms — V ision and language, multimodal speech processing, unsupervised speech processing 1. INTR ODUCTION AND PRIOR WORK The cornerstone of automatic speech recognition (ASR) sys- tems is the taxonomy of discrete, linguistic units modeled by the recognizer . The most salient of these is the vocabulary of words that can be recognized, but “under the hood” many ASR systems utilize a compositional hierarchy of units, e.g. words are composed of phonemes, and phonemes are com- posed of senone states. This hierarchy of linguistic units is advantageous because it offers fle xibility (new words may be specified in the lexicon in terms of existing phonetic models) and data ef ficiency (phonetic models can be re-used across many different words, allowing for a large degree of param- eter sharing between word models). Howe ver , it comes at a cost: the training data must be transcribed in terms of the acoustic units, and the compositional mapping between units (e.g. the lexicon mapping phonemes to words) must be spec- ified in advance by an expert linguist. These annotations are expensi ve to collect, especially for less widely spoken, “low- resource” languages. Unsupervised or weakly-supervised ap- proaches to ASR often attempt to address this problem via the automatic, data-driven discov ery of these linguistic units. Some proposed approaches operate at the word le vel [1, 2, 3], while a separate line of work is concerned with sub-word modeling [4, 5, 6, 7]. Other works hav e jointly learned sub- word as well as word-lev el units in a unified framew ork [8, 9]. A central difficulty faced by unsupervised models of speech is the fact that the acoustic speech wav eform is the result of a complex entanglement of many different sources of variability , such as speaker , background noise, re verbera- tion, microphone characteristics, etc. Self-supervised models [10] hav e recently garnered increased attention as an alter- nativ e approach to the traditional supervised-unsupervised dichotomy . In lieu of labels, self-supervised learning algo- rithms leverage informative context found e.g., in another modality . An early example of this is the CELL model introduced by [11] which learned to associate words, rep- resented by phoneme strings, with the visual images they described. Recently , [12, 13, 14] introduced models capa- ble of learning the semantic correspondences between raw speech wa veforms and natural images at the pixel le vel. Sub- sequent works hav e continued to explore the lev eraging of visual information to guide models of speech audio data [15, 16, 17, 18, 19, 20], and several papers hav e begun to in- vestigate the nature of the internal representations learned by these visually-grounded models [21, 22]. This paper follows the same general theme, but with a different focus. While [21] and [22] examined the utility of the intermediate rep- resentations of visually-grounded speech models to perform tasks such as speaker , phoneme, and word discrimination, they did not in vestigate if and ho w discrete, sub-word units may be emerging within the models. V isually-grounded, self-supervised models such as D A VEnet make relatively few assumptions about how sub-w ord units should be represented. Therefore, if interpretable sub-word unit structure emerges naturally within the network as a by-product of training, the learned structure could provide a fruitful direction for sub- sequent research on acoustic unit learning. In this paper , we present e xperiments that suggest that diphone-like structure is being learned by the intermediate layers of the D A VEnet (Deep Audio V isual Embedding network) audio model [20]. 2. THE VISU ALL Y -GROUNDED A COUSTIC MODEL For our experiments, we lev erage the D A VEnet 5-layer speech CNN described in [20]. This model takes as input log Mel-filterbank spectrograms representing a speech sig- nal, and outputs an embedded representation of the speech intended to capture the high-level semantics of the utter - ance. This is enforced by training the model to associate Fig. 1 . The DA VEnet audio-visual model. W e analyze the activ ation en velope e [ n ] of the conv2 layer . natural image scenes (encoded with a separate CNN) with spoken captions describing the content of the images (Figure 1). Model performance is measured via Recall@10 on an image/caption retrie val task. The speech model is trained from randomly initialized weights, without any traditional linguistic supervision such as word or phonetic transcrip- tions, a pronunciation lexicon, etc. As in [20], we train the model on 400,000 image/caption pairs from the Places Audio Caption dataset [20, 13, 23]. W e make two small modifica- tions to the model training. First, we employ within-batch semi-hard negati ve mining [24, 25]. As in [25], we blend the semi-hard negati ve triplet loss with the standard random- sampled triplet loss; for our experiments we simply weight these terms equally . Second, rather than Matchmap-based similarities, we employ global average pooling to the outputs of both networks, and compute their similarity with a dot product. This is mathematically equiv alent to the SISA loss described in [20], but is more computationally efficient for negati ve mining. Using semi-hard negati ve mining, we see a boost in Recall@10 from .559 to .641 for image retriev al, and from .506 to .616 for caption retrie val when using a visual model pre-trained on ImageNet [26]. 3. EXPERIMENTS W e focus our analysis on the representations learned by the conv2 layer of D A VEnet, which was previously shown by [21] to encode more phonetic information than other layers of the network. This makes intuitiv e sense because its recep- tiv e field size (125 ms) more closely corresponds to a typical phonetic segment duration (82 ms on the TIMIT database) than the recepti ve field size of the conv1 layer (25 ms) or the conv3 layer (400 ms). When visually e xamining the outputs of the conv2 layer , we observed that the activ ations tend to oscillate with time (Figure 2). This inspired us to inv estigate the reason for these oscillations in more depth. Giv en an input spectrogram of N frames, we denote the the acti vation map output by the second con volutional layer (post-nonlinearity , pre-maxpooling) of D A VEnet as A ∈ R N x 256 , where A [ n, f ] represents the output of filter f at frame n . W e compute the activ ation env elope signal e [ n ] by taking the L2 norm across Algorithm Precision Recall F1 e [ n ] peaks .893 .712 .792 [4] .764 .762 .763 [29] .748 .819 .782 [30] .740 .700 .730 T able 1 . Boundary detection on the full TIMIT test. Note that [4] reflects scores on the training set, not the testing set. all filter channels, i.e. e [ n ] = ( P f A [ n, f ] 2 ) . 5 . Figure 2 de- picts e [ n ] and its associated spectrogram for TIMIT [27] ut- terance fisb0 sx49 . An interesting property of e [ n ] is that it is relativ ely smooth, and exhibits distinct peaks, indicating that there are particular moments in time that trigger strong activity within the layer . These peaks appear to synchronize with phoneme transitions in the spectrogram, which we vali- date by applying a simple peak-picking algorithm to the en- velope signal and measuring the temporal correspondence be- tween these peaks and the ground-truth phonetic boundary an- notations for TIMIT . While any standard peak picking algo- rithm could be used here, we con volve e [ n ] with a deriv ativ e of Gaussian (DoG) filter (whose shape is controlled via a sin- gle hyperparameter σ ), i.e. d [ n ] = D oG σ [ n ] ∗ e [ n ] . Peaks cor- respond to positiv e-to-negativ e zero crossings in d [ n ] , which are further filtered by a sharpness threshold τ which compares the maximum slope on the rising edge of a peak to the mini- mum slope on the falling edge; we keep only those peaks for which the difference between these slopes e xceeds τ . Our first experiment measures how well the peaks ex- tracted from e [ n ] correspond to phonetic boundaries on the full test set of the TIMIT corpus, computing precision, re- call, and F1 against the ground-truth boundaries. W e use the Places audio caption D A VEnet model as-is, and do not do an y further training or adaptation on the TIMIT data. W e follow [28] and use a 20ms tolerance window for boundary detec- tion. W e performed a grid search over τ and σ , and achiev ed a maximum F1 of .792 at τ = 0 . 15 and σ = 0 . 5 ; but perfor- mance was not v ery sensitiv e to these exact settings. In T able 1, we compare against se veral published approaches for blind phone boundary detection. Our method outperforms all of them in terms of F1 score, but does not constitute a fair com- parison because our model underwent self-supervised training on the Places audio captions. The key takeaway is the fact that e [ n ] performs very well as a phone boundary detector despite nev er being explicitly trained to do so. Giv en that some regions of an input spectrogram give rise to peaks in the activ ation pattern of the conv2 layer of D A VEnet, our second experiment examines to what extent the DA VEnet model is leveraging the information contained in these peaks to perform cross-modal retriev al. Here, we fix all of the weights of the D A VEnet model except the bias vector of the conv3 layer . W e then insert an ablation layer between conv2 and conv3 . This layer computes the peaks in the e [ n ] signal and then uses them to create a mask matrix Fig. 2 . The spectrogram for TIMIT utterance fisb0 sx49 (bottom) and its associated e [ n ] signal (top, blue curve). Peaks found in e [ n ] shown by blue diamonds, and ground-truth TIMIT phone boundaries denoted by the vertical dashed red lines). Fig. 3 . R@10 scores using various ablation methods. M ∈ R N x 256 , where M [ n, f ] = 1 if e [ n ] has a peak at n , and M [ n, f ] = 0 otherwise. The ablated outputs of conv2 are then computed as ˆ A = M A , and ˆ A is fed as input to the subsequent layers of the network. Because the ablation layer changes the magnitude of the summed input seen by each neuron in the conv3 layer , we fine-tune only the bias of this layer on the ablated outputs from conv2 , using the image and caption ranking objectiv e described in Section 2. By comparing the retrie val recall scores achiev ed by the ablated network against those of the original model, we can infer to what extent the conv olutional filters of the already- trained DA VEnet model have learned to focus on the conv2 activ ation peaks, as opposed to other regions of the conv2 output. Figure 3 displays the av erage of the image-to-caption and caption-to-image recall @ 10 scores as a function of the number of fine-tuning epochs. The horizontal black line represents the recall score when no ablation is used (0.629), and the red solid line sho ws the score achieved when using the peak-picking based ablation. After a single epoch of fine-tuning, the R@10 score rebounds from 0.117 to 0.351, where it remains constant. W e compare the peak-picking ablation against uniform sampling, random sampling, and sampling the midpoint frame between each consecutiv e pair of e [ n ] peaks. For uniform and random sampling, we keep the number of ablated frames constant for each utterance; if a given utterance of length N was found to hav e N p peaks in its e [ n ] signal, then we retain N p uniformly-spaced or randomly sampled conv2 activ ation frames across the utter- ance. On average, 1 out of every 11.84 frames was found to be a peak, meaning that 91.6% of the conv2 output frames were set to zero. In Figure 3, we see that while all ablation methods suffer a loss in retriev al accuracy , the peak-picking ablation model still achiev es 60% of the performance of the non-ablated model. All other methods fare worse, indicating that the filters of the D A VEnet audio model have learned to lev erage the e [ n ] peaks for word discrimination much more than other parts of the speech signal. Thus far , we have shown that the conv2 layer of the D A VEnet audio model is highly sensitiv e to specific regions of an input spectrogram, that these regions are especially in- formativ e for inferring the semantics (and thus the lexical content) of an utterance, and that these regions tend to oc- cur at the transition point between two phones. Our last ex- periments in vestigate the geometry of the embedding space in which these activ ation peaks reside. W e first extracted a total of 39,871 peaks for the 1,344 utterances comprising the TIMIT complete test set. W e represent each peak with its cor- responding 256-dimensional embedding vector produced by the conv2 layer of DA VEnet. W e then assign a label to each peak according to the ground-truth sequence of phones that fall within a 40 ms windo w around the peak. W e follow a sim- ilar scheme to the 39-phone mapping for TIMIT , but map stop closures to their associated stop phoneme instead of silence. Under this mapping, we found that approximately 18.1% of the peaks fell within a single phone segment, 76.5% of peaks captured a diphone boundary , and 5.3% of the peaks over - lapped three phones. In addition to a phonetic label for each peak, we also deriv e a manner label by mapping each phone to its associated broad manner class (vo wel, stop, nasal, frica- tiv e, semivo wel, affricate, flap, and silence). W e projected the peak embeddings down to 2 dimensions using PCA, and plot the peaks corresponding to the 10 most frequently occur- ring broad manner class labels in Figure 4. W e can see that peaks belonging to the same underlying manner class clus- ter together quite well. Furthermore, we observe that CV , V , and VC syllable structure is captured by the first princi- pal component; vo wel stop, v owel fricativ e, and vo wel nasal peaks are concentrated on right-hand side of the space, while stop vowel, fricativ e v owel, and nasal vo wel reside on the left-hand side of the space. Fig. 4 . PCA analysis of e [ n ] peaks extracted from the TIMIT full test set. Fig. 5 . PCA analysis of the peaks corresponding to vo wel- stop transitions. In Figure 5, we examine the properties of peaks belonging to the vowel stop class in more detail. W e compute a second PCA transform specific for this class, and plot the associated peaks along their first two principal components. In the left- hand scatter plot, the peaks are color coded according to the vo wel in the left context of the peak; in the right-hand plot, they are color coded according to their right-hand stop con- text. Broadly speaking, the first principal component seems to select for frontness of the vo wel, while the second compo- nent captures the voicing of the stop consonant. Our qualitativ e analysis suggests that the discovered peaks cluster by manner class at a coarse scale, and by pho- Fig. 6 . Adjusted mutual information between K-means clus- tering of peaks and their underlying phone and manner class sequences. netic identity at a finer scale. W e quantify this by clustering the peak vectors using K-means, and computing the adjusted mutual information (AMI) [31] between the clustering output and the underlying phone and manner class sequences for each peak (Figure 6). AMI is maximized for the manner class label sequences at K = 40 clusters and steadily falls off as more clusters are specified, while the AMI for phonetic labels plateaus between 200 and 700 clusters. 4. CONCLUDING DISCUSSION In this paper , we in vestigated the encoding of sub-word infor- mation in the conv2 layer of the D A VEnet visually-grounded speech model. W e observed that the magnitude of the activ a- tions within this layer tend to e xhibit local maxima at diphone transitions, which we quantified by using these maxima to detect phone boundaries on TIMIT . Furthermore, we per- formed ablation experiments for an image/caption retriev al that suggested that the DA VEnet audio model le verages the e [ n ] /“diphone” peaks more than other regions of the signal for the purpose of word recognition. Finally , we examined the geometry of the space occupied by the peak embedding vectors and found the emergence of clusters of diphone units which share broad phonetic manner class membership; within these clusters, dif ferent dimensions appear to correlate with distinctiv e features such as vowel frontness or stop voicing. In our future work, we plan to further explore the topic of lev eraging visually-grounded acoustic models to discover discrete, pseudo-linguistic units. W e would like to explicitly incorporate mechanisms into D A VEnet for inferring a dis- crete, compositional hierarchy of interpretable phone-like, syllable-like, w ord-like, phrase-lik e, etc. units that could pro- vide a rich account of a spoken language in a self-supervised fashion. Finally , we believe that our ablation analysis in Section 3 points the way tow ards a non-linear downsampling scheme that would enable acoustic observation sequences to be more closely aligned with phone or character sequences, which could find application in supervised ASR systems. 5. REFERENCES [1] Alex Park and James Glass, “Unsupervised pattern discov ery in speech, ” IEEE T ransactions on Audio, Speech and Language Process- ing , vol. 16, no. 1, pp. 186–197, 2008. [2] Aren Jansen, Kenneth Church, and Hynek Hermansky , “T oward spo- ken term disco very at scale with zero resources, ” in Proc. Annual Con- fer ence of International Speec h Communication Association (INTER- SPEECH) , 2010. [3] Herman Kamper, Aren Jansen, and Sharon Goldwater , “ A segmen- tal framew ork for fully-unsupervised large-vocab ulary speech recogni- tion, ” Computer Speech and Language , vol. 46, no. 3, pp. 154–174, 2017. [4] Chia-Y ing Lee and James Glass, “ A nonparametric Bayesian approach to acoustic model discovery , ” in Pr oc. Annual Meeting of the Associa- tion for Computational Linguistics (A CL) , 2012. [5] Balakrishnan V aradarajan, Sanjeev Khudanpur , and Emmanuel Dupoux, “Unsupervised learning of acoustic sub-word units, ” in Pr oc. Annual Meeting of the Association for Computational Linguis- tics (A CL) , 2008. [6] Lucas Ondel, Luka ˇ s Burget, and Jan ˇ Cernock ´ y, “V ariational inference for acoustic unit discovery , ” 2016. [7] Aren Jansen, Samuel Thomas, and Hynek Hermansky , “W eak top- down constraints for unsupervised acoustic model training, ” in ICASSP , 2013. [8] Herb Gish, Man-Hung Siu, Arthur Chan, and W illiam Belfield, “Unsu- pervised training of an HMM-based speech recognizer for topic classi- fication, ” in Pr oc. Annual Confer ence of International Speech Commu- nication Association (INTERSPEECH) , 2009. [9] Chia-ying Lee, Timothy O’Donnell, and James Glass, “Unsupervised lexicon discov ery from acoustic input, ” T ransactions of the Association for Computational Linguistics , vol. 3, pp. 389–403, 2015. [10] V irginia de Sa, “Learning classification with unlabeled data, ” 1994. [11] Deb Roy and Alex Pentland, “Learning words from sights and sounds: a computational model, ” Cognitive Science , vol. 26, pp. 113–146, 2002. [12] David Harwath and James Glass, “Deep multimodal semantic embed- dings for speech and images, ” in Pr oc. IEEE W orkshop on Automfatic Speech Recognition and Understanding (ASR U) , 2015. [13] David Harwath, Antonio T orralba, and James R. Glass, “Unsupervised learning of spoken language with visual context, ” in Proc. Neural In- formation Pr ocessing Systems (NIPS) , 2016. [14] Gabriel Synnaeve, Maarten V ersteegh, and Emmanuel Dupoux, “Learning words from images and speech, ” in In NIPS W orkshop on Learning Semantics , 2014. [15] David Harwath and James Glass, “Learning word-like units from joint audio-visual analysis, ” in Pr oc. Annual Meeting of the Association for Computational Linguistics (A CL) , 2017. [16] Herman Kamper, Shane Settle, Gregory Shakhnarovich, and Karen Liv escu, “V isually grounded learning of keyword prediction from un- transcribed speech, ” in INTERSPEECH , 2017. [17] Grzegorz Chrupala, Lieke Gelderloos, and Afra Alishahi, “Represen- tations of language in a model of visually grounded speech signal, ” in ACL , 2017. [18] Odette Scharenborg, Laurent Besacier, Alan W . Black, Mark Hasega wa-Johnson, Florian Metze, Graham Neubig, Sebastian St ¨ uker , Pierre Godard, Markus M ¨ uller , Lucas Ondel, Shruti Palaskar, Philip Arthur , Francesco Ciannella, Mingxing Du, Elin Larsen, Danny Merkx, Rachid Riad, Liming W ang, and Emmanuel Dupoux, “Linguistic unit discovery from multi-modal inputs in unwritten languages: Sum- mary of the ”speaking rosetta” JSAL T 2017 workshop, ” CoRR , vol. abs/1802.05092, 2018. [19] David Harwath, Galen Chuang, and James Glass, “V ision as an inter- lingua: Learning multilingual semantic embeddings of untranscribed speech, ” in ICASSP , 2018. [20] David Harwath, Adri ` a Recasens, D ´ ıdac Sur ´ ıs, Galen Chuang, Antonio T orralba, and James Glass, “Jointly discov ering visual objects and spo- ken words from ra w sensory input, ” 2018. [21] Jennifer Drexler and James Glass, “ Analysis of audio-visual features for unsupervised speech recognition, ” in Gr ounded Language Under- standing W orkshop , 2017. [22] Afra Alishahi, Marie Barking, and Grzegorz Chrupala, “Encoding of phonology in a recurrent neural model of grounded speech, ” in CoNLL , 2017. [23] Bolei Zhou, Agata Lapedriza, Jianxiong Xiao, Antonio T orralba, and Aude Oliv a, “Learning deep features for scene recognition using places database, ” in Proc. Neural Information Pr ocessing Systems (NIPS) , 2014. [24] Florian Schrof f, Dmitry Kalenichenko, and James Philbin, “Facenet: A unified embedding for face recognition and clustering, ” 2018. [25] Aren Jansen, Manoj Plakal, Ratheet Pandya, Daniel PW Ellis, Shawn Hershey , Jiayang Liu, R Channing Moore, and Rif A Saurous, “Unsu- pervised learning of semantic audio representations, ” 2018. [26] Jia Deng, W ei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei- Fei, “Imagenet: A large scale hierarchical image database, ” in Pr oc. IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2009. [27] John Garofolo, Lori Lamel, W illiam Fisher , Jonathan Fiscus, David Pallet, Nancy Dahlgren, and V ictor Zue, “The TIMIT acoustic-phonetic continuous speech corpus, ” 1993. [28] Odette Scharenborg, V incent W an, and Mirjam Ernestus, “Unsuper- vised speech segmentation: An analy- sis of the hypothesized phone boundaries, ” The journal of the acoustical society of america (JASA) , vol. 127, pp. 1084–1095, 2010. [29] Paul Michel, Okko R ¨ as ¨ anen, Roland Thiolli ´ ere, and Emmanuel Dupoux, “Blind phoneme segmentation with temporal prediction er- rors, ” in Proceedings of the ACL Student Researc h W orkshop , 2017. [30] Okko R ¨ as ¨ anen, “Basic cuts revisited: T emporal segmentation of speech into phone-like units with statistical learning at a pre-linguistic le vel., ” in Pr oceedings of the 36th Annual Confer ence of the Cognitive Science Society , 2014. [31] Nguyen Xuan V inh, Julien Epps, and James Bailey , “Information the- oretic measures for clusterings comparison: V ariants, properties, nor- malization and correction for chance, ” J . Mach. Learn. Res. , vol. 11, pp. 2837–2854, Dec. 2010.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment