시각적 정합을 통한 하위 단어 음성 단위 발견
본 논문은 이미지와 연관된 원시 음성 파형을 학습한 5‑계층 CNN(DAVEnet)에서 중간층(conv2)의 활성화 패턴이 diphone 경계와 일치한다는 사실을 밝혀낸다. L2 노름으로 만든 활성화 envelope e
저자: David Harwath, James Glass
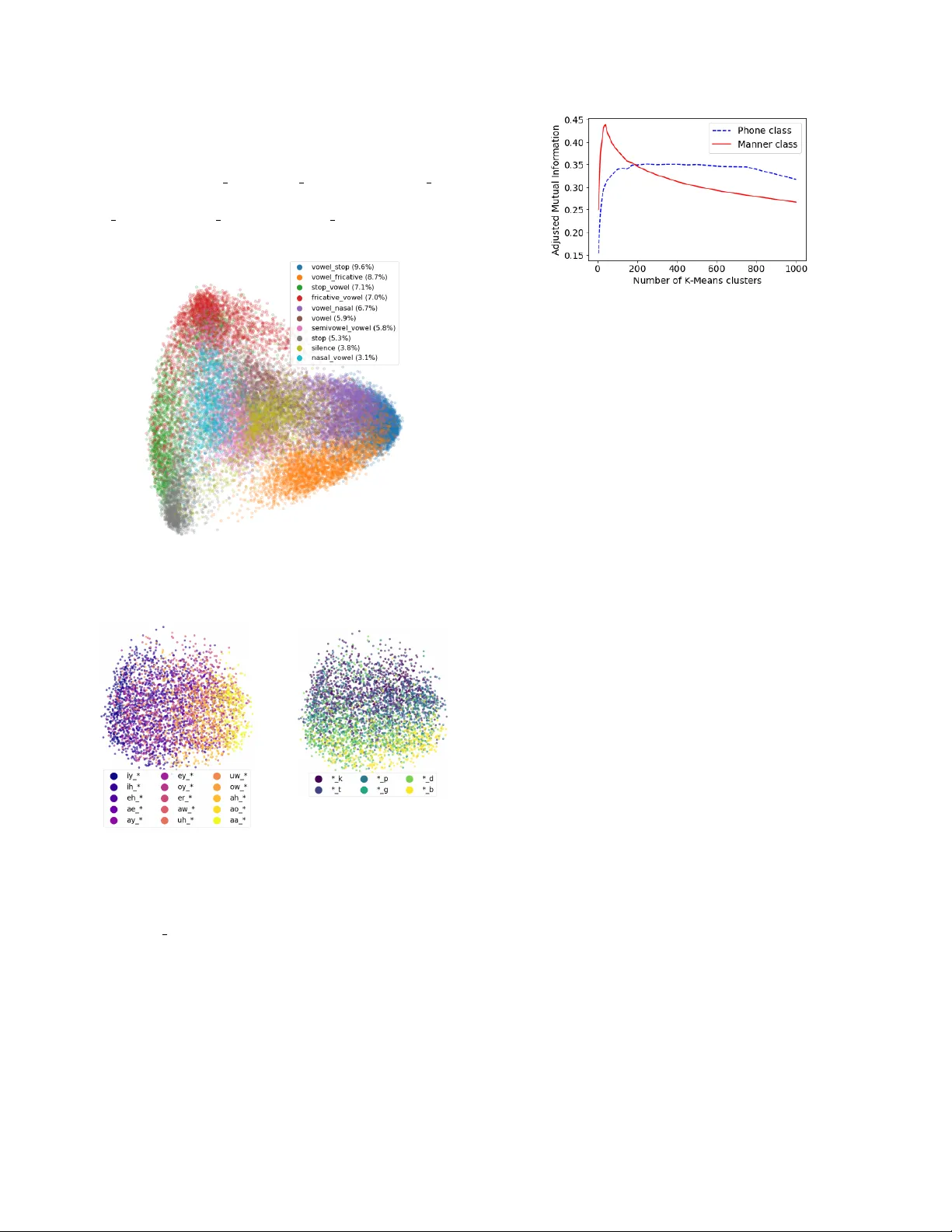
본 논문은 시각적 정합을 이용한 자기지도 학습 모델인 DAVEnet(Deep Audio‑Visual Embedding network)의 내부 표현이 어떻게 하위 단어 수준의 음성 단위를 자동으로 발견하는지를 체계적으로 탐구한다. 먼저 서론에서는 전통적인 ASR 시스템이 음소·음절·단어와 같은 계층적 라벨에 의존하는 반면, 라벨이 부족한 저자원 언어에 대한 비지도·약지도 접근법의 필요성을 강조한다. 최근 이미지‑음성 쌍을 활용한 self‑supervised 모델이 등장했으며, 특히 시각 정보를 이용해 음성의 의미적 구조를 학습한다는 점에서 주목받고 있다. 그러나 기존 연구(
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기