Federated Learning for Keyword Spotting
We propose a practical approach based on federated learning to solve out-of-domain issues with continuously running embedded speech-based models such as wake word detectors. We conduct an extensive empirical study of the federated averaging algorithm…
Authors: David Leroy, Alice Coucke, Thibaut Lavril
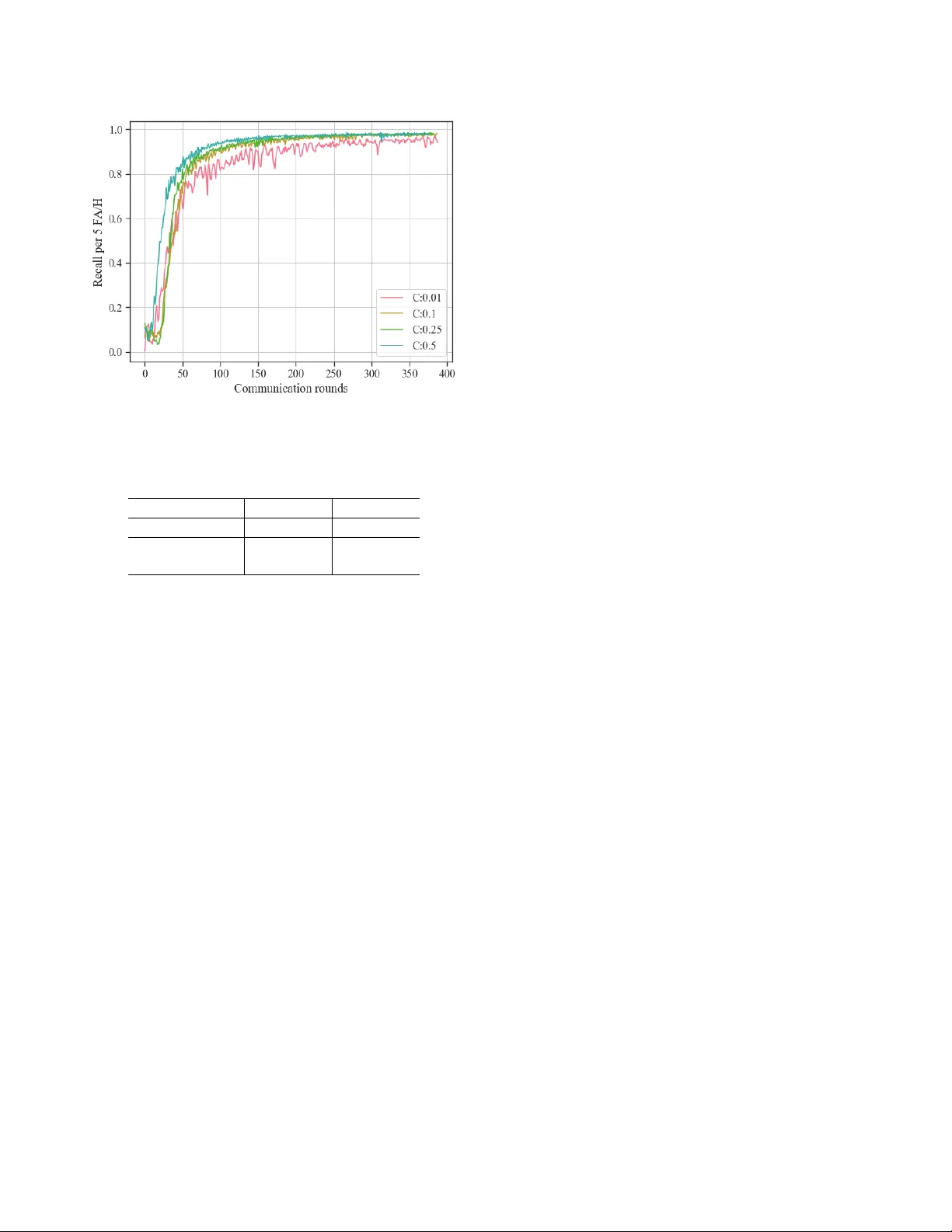
FEDERA TED LEARNING FOR KEYWORD SPO TTING David Ler oy , Alice Couck e, Thibaut Lavril, Thibault Gisselbr echt and J oseph Dur eau Snips, 18 rue Saint Marc, 75002 Paris, France ABSTRA CT W e propose a practical approach based on federated learn- ing to solve out-of-domain issues with continuously running embedded speech-based models such as wake w ord detec- tors. W e conduct an extensi ve empirical study of the fed- erated a veraging algorithm for the “Hey Snips” wake word based on a crowdsourced dataset that mimics a federation of wake word users. W e empirically demonstrate that using an adaptiv e av eraging strategy inspired from Adam in place of standard weighted model a veraging highly reduces the num- ber of communication rounds required to reach our target per- formance. The associated upstream communication costs per user are estimated at 8 MB, which is a reasonable in the con- text of smart home v oice assistants. Additionally , the dataset used for these e xperiments is being open sourced with the aim of fostering further transparent research in the application of federated learning to speech data. Index T erms — k eyword spotting, wake word detection, federated learning 1. INTR ODUCTION W ak e word detection is used to start an interaction with a voice assistant. A specific case of keyw ord spotting (KWS), it continuously listens to an audio stream to detect a predefined keyw ord or set of keywords. W ell-kno wn examples of wake words include Apple’ s “Hey Siri” or Google’ s “OK Google”. Once the wake word is detected, voice input is acti vated and processed by a spoken language understanding engine, po w- ering the perception abilities of the voice assistant [1]. W ak e w ord detectors usually run on device in an always- on fashion, which brings two major dif ficulties. First, it should run with minimal memory footprint and computational cost. The resource constraints for our w ake w ord detector are 200k parameters (based on the medium-sized model proposed in [2]), and 20 MFLOPS. Secondly , the wake word detector should behave consis- tently in any usage setting, and show robustness to back- ground noise. The audio signal is highly sensitive to record- ing proximity (close or far field), recording hardware, b ut a lso to the room configuration. Rob ustness also implies a strong speaker variability coverage. While the use of digital sig- nal processing front-ends can help mitigate issues related to bad recording conditions, speak er v ariability remains a major challenge. High accuracy is all the more important since the model can be triggered at any time: it is therefore e xpected to capture most of the commands (high recall) while not trigger - ing unintentionally (low f alse alarm rate). T oday , wake word detectors are typically trained on datasets collected in real usage setting e.g. users homes in the case of voice assistants. Speech data being by nature very sen- sitiv e, centralized collection raises major pri vac y concerns. In this work, we in vestigate the use of federated learning (FL) [3] in the context of an embedded wake word detector . FL is a decentralized optimization procedure that enables to train a central model on the local data of many users without the need to e ver upload this data to a central server . The training workload is mov ed to wards the user’ s devices which perform training steps on the local data. Local updates from users are then a veraged by a parameter server in order to create a global model. 2. RELA TED WORK Most research around decentralized learning has historically been done in the context of a highly controlled cluster/data center setting, e.g. with a dataset e venly partitioned in an i.i.d fashion. The multi-core and multi-gpu distributed training setting has been specifically studied in the context of speech recognition in [4]. Ef forts on decentralized training with highly distributed, unbalanced and non-i.i.d data is relativ ely recent, as the foundations were laid do wn in [3] with the intro- duction of the federated a veraging ( F edA vg ) algorithm and its application to a set of computer vision (MNIST , CIF AR-10) and language modeling tasks (applied to the Shakespeare and Google Plus posts datasets). T o our knowledge, the present work is the first experiment of its kind on user-specific speech data. The federated optimization problem in the context of con- ve x objectiv e functions has been studied in [5]. The authors proposed a stochastic variance-reduced gradient descent op- timization procedure ( SVRG ) with both local and global per- coordinate gradient scaling to improv e con vergence. Their global per-coordinate gradient averaging strategy relies on a sparsity measure of the gi ven coordinate in users local datasets and is only applicable in the context of sparse linear- in-the-features models. The latter assumption does not hold in the context of neural networks for speech-based applications. Sev eral improvements to the initial F edA vg algorithm hav e been suggested with a focus on client selection [6], budget-constrained optimization [7] and upload cost reduc- tion for clients [8]. A dynamic model averaging strategy ro- bust to concept drift based on a local model diver gence crite- rion was recently introduced in [9]. While these contributions present ef ficient strategies to reduce the communication costs inherent to federated optimization, the present work is as far as we know the first one introducing a dynamic per-coordinate gradient update in place of the global av eraging step. The next section describes the federated optimization pro- cedure, and ho w its global a veraging can be substituted by an adaptativ e averaging rule inspired from Adam. It is followed by the experiments section, where both the open-sourced crowdsourced data and model used to train our wake word detector are introduced. Results come next, and a commu- nication cost analysis is provided. Finally , the next steps to- wards training a wak e word detector on user data that is really decentralized are described. 3. FEDERA TED OPTIMIZA TION W e consider the standard supervised learning objectiv e func- tion f i ( w ) = l ( x i , y i , w ) that is the loss function for the pre- diction on example ( x i , y i ) when using a model described by a real-valued parameter vector w of dimension d . In a feder- ated setting, we assume that the datapoints i are partitioned across K users, each user being assigned their own partition P k , |P k | = n k . The optimization objective is therefore the following: min w ∈ R d f ( w ) where f ( w ) def = P K k =1 n k n × F k ( w ) with F k ( w ) = 1 n k P n k i =1 f i ( w ) (1) The F edA vg algorithm introduced in [3] aims at minimiz- ing the objective function 1 assuming a synchronous update scheme and a generic non-con vex neural network loss func- tion. The model is initialized with a given architecture on a central parameter server with weights w 0 . Once initial- ized, the parameter serv er and the user’ s de vices interact syn- chronously with each other during communication r ounds . A communication round at time t ∈ [1 , .., T ] is described belo w: 1. The central model w t − 1 is shared with a subset of users S t that are randomly selected from the pool of K users giv en a participation ratio C . 2. Each user k ∈ S t performs one or several training steps on their local data based on the minimization of their local objectiv e F k using mini-batch stochastic gradient descent (SGD) with a local learning rate η local . The number of steps performed locally is E × max ( ceil ( n k B ) , 1) , n k being the number of data- points available locally , E the number of local epochs and B the local batch size. 3. Users from S t send back their model updates w t,k , k ∈ S t to the parameter server once local training is fin- ished. 4. The server computes an a verage model w t based on the user’ s individual updates w t,k , k ∈ S t , each user’ s up- date being weighted by n k n r , where n r = P k ∈S t n k ≈ C × P K k =1 n k . When B = ∞ (i.e the batch size is equal to the local dataset size) and E = 1 , then a single gradient update is per- formed on each user’ s data. It is strictly equiv alent to doing a single gradient computation on a batch including all of se- lected user data points. This specific case is called F edSGD , e.g. stochastic gradient descent with each batch being the data of the federation of selected users at a given round. F edA vg (Federated av eraging) is the generic case when more than one update is performed locally for each user . The global av eraging step can be written as follo ws, using a global update rate η g l obal . w t ← w t − 1 − η g l obal X k ∈S t n k n ( w t − 1 − w t,k ) (2) Setting the global update rate η g l obal to 1 is equiv alent to a weighted a veraging case without moving a verage. Equation 2 highlights the parallel between global av eraging and a gra- dient update G t = P k ∈S t n k n ( w t − 1 − w t,k ) . This parallel motiv ates the use of adaptiv e per-coordinate updates for G t that have proven successful for centralized deep neural net- works optimization such as Adam [10]. Moment-based av- eraging allows to smooth the averaged model by taking into account the previous rounds updates that were computed on different user subsets. W e conjecture that the exponentially- decayed first and second order moments perform the same kind of regularization that occurs in the mini-batch gradient descent setting, where Adam has proven to be successful on a wide range of tasks with various neural-network based ar- chitectures. In this work, we set the exponential decay rates for the moment estimates to β 1 = 0 . 9 and β 2 = 0 . 999 and = 10 − 8 as initially suggested by the authors of [10]. In the federated setting, model ev aluation is also done in a distributed fashion on a set of users that are kept specifi- cally for this purpose. Model metrics are av eraged on the pa- rameter server with a similar weighting scheme as parameter av eraging. 4. EXPERIMENTS 4.1. Dataset Unlike generic speech recognition tasks, there is no reference dataset for wake word detection. The reference dataset for multi-class ke yword spotting is the speech command dataset [11], but the speech command task is generally preceded by a wake word detector and is focused on minimizing the con- fusion across classes, not robustness to f alse alarms. W e con- stituted a cro wdsourced dataset for the He y Snips wak e word. W e are releasing publicly 1 this dataset [12] in the hope it can be useful to the keyw ord spotting community . T rain set Dev set T est set T otal 1,374 users 200 users 200 users 1774 users 53,991 utt. 8,337 utt. 7,854 utt. 69,582 utt. T able 1 . Dataset statistics for the He y Snips wak e word - 18% of utterances are positiv e, with strong per user imbalance in the number of utterances (mean: 39, standar d dev: 32) The data used here was collected from 1.8k contributors that recorded themselves on their device with their own mi- crophone while saying sev eral occurrences of the Hey Snips wake word along with negati ve short sentences from various text sources (e.g. subtitles). This crowdsourci ng-induced data distribution mimicks a real-world non-i.i.d, unbalanced and highly distributed set- ting, and a parallel is therefore drawn in the following work between a crowdsourcing contributor and a voice assistant user . The statistics about the dataset comforting this analogy are summarized in T able 1. The train, dev and test splits are built purposely using distinct users, 77% of users being used solely for training while the remaining are used for parame- ter tuning and final ev aluation, measuring the generalization power of the model to ne w users. 4.2. Model Acoustic features are generated based on 40-dimensional mel- frequency cepstrum coefficients (MFCC) computed ev ery 10ms ov er a window of 25ms. The input window consists in 32 stacked frames, symmetrically distributed in left and right contexts. The architecture is a CNN with 5 stacked dilated con volutional layers of increasing dilation rate, followed by two fully-connected layers and a softmax inspired from [13]. The total number of parameters is 190,852, initialized using Xavier initialization [14]. The model is trained using cross- entropy loss on frames prediction. The neural network has 4 output labels, assigned via a custom aligner specialized on the target utterance “Hey Snips”: “Hey”, “sni”, “ps”, and “filler” that accounts for all other cases (silence, noise and other words). A posterior handling [15] generates a confi- dence score for every frame by combining the smoothed label posteriors. The model triggers if the confidence score reaches a certain threshold τ , defining the operating point that max- imizes recall for a certain amount of False Alarms per Hour (F AH). W e set the number of false alarms per hour to 5 as a stopping criterion on the dev set. The dev set is a “hard” dataset when it comes to false alarms since it belongs to the 1 http://research.snips.ai/datasets/ keyword- spotting same domain as data used for training. The model recall is fi- nally e valuated on the test set positive data, while false alarms are computed on both the test set negati ve data and various background negativ e audio sets. See section 4.3 for further details about ev aluation. 4.3. Results W e conduct an extensi ve empirical study of the federated av- eraging algorithm for the He y Snips wake word based on crowd- sourced data from T able 1. Federated optimization results are compared with a standar d setting e.g. centralized mini-batch SGD with data from train set users being randomly shuffled. Our aim is to ev aluate the number of communication rounds that are required in order to reach our stopping criterion on the dev set. For the purpose of this experiment early stopping is ev aluated in a centralized fashion, and we assume that the de v set users agreed to share their data with the parameter server . In an actual product setting, early stopping estimation would be run locally on the devices of the dev users, they would download the latest v ersion of the central model at the end of each round and e valuate the early stopping criterion based on prediction scores for their own utterances. These individual metrics would then be averaged by the parameter server to obtain the global model criterion estimation. Final e valuation on test users would be done in the same distributed fashion once training is finished. Standard baseline : Our baseline e.g. a standard central- ized data setting with a single training server and the Adam optimizer reaches the early stopping target in 400 steps ( ∼ 2 epochs) and is considered as our upper bound of performance. Adam provides a strong con ver gence speedup in comparison with standard SGD that remains under 87% after 28 epochs despite learning rate and gradient clipping tuning on the de v set. User parallelism : The higher the ratio of users selected at each round C , the more data is used for distributed local training, and the faster the con vergence is expected, assuming that local training does not di verge too much. Figure 1 shows the impact of C on con vergence: the gain of using half of users is limited with comparison with using 10%, specifically in the later stages of con vergence. A fraction of 10% of users per round is also more realistic in a practical setup as selected users hav e to be online. W ith lower participation ratios ( C = 1% ), the gradients are much more sensitive and might require the use of learning rate smoothing strategy . C is therefore set to 10%. Global av eraging : Global adapti ve learning rates based on Adam accelerates conv ergence when compared with stan- dard averaging strategies with or without moving averages. T able 2 summarizes experimental results in the F edSGD set- ting with optimized local learning rates. Applying standard global av eraging yields poor performances e ven after 400 com- munication rounds when compared with adaptiv e per -parameter av eraging. Fig. 1 . Effect of the share of users in volv ed in each round C on the dev set recall / 5 F AH, F edSGD , Adam global averag- ing, η g l obal = 0 . 001 , η local = 0 . 01 A vg. Strategy 100 rounds 400 rounds η g l obal = 1 . 0 29.9% 67.3% Adam η g l obal = 0 . 001 93.50% 98.29% T able 2 . De v set recall / 5 F AH for various a veraging strate- gies - F edSGD , C = 10% Local training : Our results show consistency across lo- cal training configurations, with limited improv ements com- ing from increasing the load of local training. The number of communication rounds required to reach the stopping cri- terion on the dev set ranges between 63 and 112 commu- nication rounds for E ∈ [1 , 3] and B ∈ [20 , 50 , ∞ ] , using C = 10% , Adam global averaging with η g l obal = 0 . 001 , and a local learning rate of 0.01. In our experiments, the best per - formances are obtained for E = 1 and B = 20 for an av erage of 2.4 local updates per worker taking part in a round, yield- ing a 80% speedup with comparison to F edSGD . The total number of training steps needed to reach the stopping crite- rion amounts to approximately 3300 for 100 communication rounds e.g. 8 . 25 times the number of steps required in the standard setting, with much smaller batches. Nev ertheless we observed variability across experiments with regard to ran- dom weight initialization and early stage behaviour . Unlike some experiments presented in [3], the speedup coming from increasing the amount of local training steps does not lead to order of magnitude improv ements on conv ergence speed, while local learning rate and global averaging tuning proved to be crucial in our work. W e conjecture that this difference is related to the input semantic v ariability across users. In the MNIST and CIF AR e xperiments from [3] the input semantics are the same across emulated users. In the wake word setting, each user has their o wn vocalization of the same wake word utterance with significant dif ferences in pitch and accent than can lead to diver ging lower stage representations that might perform poorly when av eraged. Evaluation : W e ev aluate the false alarm rates of the best model ( E = 1 and B = 20 ) for a fixed recall of 95% on the test set. W e observe 3.2 F AH on the negati ve test data, 3.9 F AH on Librispeech [16], and respectively 0.2 and 0.6 F AH on our internal news and collected TV datasets. Unsurpris- ingly , false alarms are more common on close-field continu- ous datasets than they are on background ne gative audio sets. 4.4. Communication cost analysis Communication cost is a strong constraint when learning from decentralized data, especially when users devices have lim- ited connectivity and bandwidth. Considering the asymmet- rical nature of broadband speeds, the communication bottle- neck for federated learning is the updated weights transfer from clients to the parameter server [8]. W e assume that the upstream communication cost associated with users in- volv ed in model ev aluation at each communication round is marginal, as they would only be uploading a few floating point metrics per round that is much smaller than the model size. The total client upload bandwidth requirement is pro- vided in the equation below: Clien tUploadCost = mo delSize f32 × C × N rounds (3) Based on our results, this would yield a cost of 8MB per client when the stopping criterion is reached within 100 com- munication rounds. The server receives 137 updates per round when C = 10% , amounting for 110GB over the course of the whole optimization process with 1.4k users in volv ed during training. Further experiments with latter con vergence stages (400 rounds) yielded 98% recall / 0.5 F AH on the test set for an upload budget of 32 MB per user . 5. CONCLUSION AND FUTURE WORK In this work, we in vestigate the use of federated learning on crowdsourced speech data to learn a resource-constrained wake word detector . W e show that a revisited F ederated A veraging algorithm with per-coordinate av eraging based on Adam in place of standard global averaging allows the training to reach a tar get stopping criterion of 95% recall per 5 F AH within 100 communication rounds on our cro wdsourced dataset for an associated upstream communication costs per client of 8MB. W e also open source the Hey Snips w ake word dataset. The next step towards a real-life implementation is to de- sign a system for local data collection and labeling as the wake word task requires data supervision. The frame labeling strategy used in this work relies on an aligner , which cannot be easily embedded. The use of of memory-efficient end-to- end models [12] in place of the presented class-based model could ease the work of local data labelling. 6. REFERENCES [1] Alice Coucke, Alaa Saade, Adrien Ball, Th ´ eodore Bluche, Ale xandre Caulier , Da vid Leroy , Cl ´ ement Doumouro, Thibault Gisselbrecht, Francesco Calta- girone, Thibaut La vril, Ma ¨ el Primet, and Joseph Dureau, “Snips voice platform: an embedded spoken language understanding system for priv ate-by-design voice inter- faces, ” CoRR , vol. abs/1805.10190, 2018. [2] Y undong Zhang, Naveen Suda, Liangzhen Lai, and V ikas Chandra, “Hello edge: Keyw ord spotting on mi- crocontrollers, ” CoRR , vol. abs/1711.07128, 2017. [3] H. Brendan McMahan, Eider Moore, Daniel Ramage, and Blaise Ag ¨ uera y Arcas, “Federated learning of deep networks using model a veraging, ” CoRR , vol. abs/1602.05629, 2016. [4] Daniel Pov ey , Xiaohui Zhang, and Sanjee v Khudan- pur , “Parallel training of deep neural networks with natural gradient and parameter averaging, ” CoRR , vol. abs/1410.7455, 2014. [5] Jakub Konecn ´ y, H. Brendan McMahan, Daniel Ram- age, and Peter Richt ´ arik, “Federated optimization: Dis- tributed machine learning for on-device intelligence, ” CoRR , vol. abs/1610.02527, 2016. [6] T akayuki Nishio and Ryo Y onetani, “Client selection for federated learning with heterogeneous resources in mobile edge, ” CoRR , vol. abs/1804.08333, 2018. [7] Shiqiang W ang, T iff any T uor , Theodoros Salonidis, Kin K. Leung, Christian Makaya, T ing He, and Ke vin Chan, “When edge meets learning: Adaptiv e control for resource-constrained distributed machine learning, ” CoRR , vol. abs/1804.05271, 2018. [8] Jakub K onecn ´ y, H. Brendan McMahan, Felix X. Y u, Pe- ter Richt ´ arik, Ananda Theertha Suresh, and Dave Ba- con, “Federated learning: Strategies for improving communication efficiency , ” CoRR , v ol. abs/1610.05492, 2016. [9] Joachim Sicking Fabian Hger Peter Schlicht Tim Wirtz Michael Kamp, Linara Adilo va and Stef an Wrobel, “Ef- ficient decentralized deep learning by dynamic model av eraging, ” CoRR , vol. abs/1807.03210, 2018. [10] Diederik P . Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” CoRR , v ol. abs/1412.6980, 2014. [11] Pete W arden, “Speech commands: A dataset for limited-vocab ulary speech recognition, ” CoRR , v ol. abs/1804.03209, 2018. [12] Alice Coucke, Mohammed Chlieh, Thibault Gissel- brecht, David Leroy , Mathieu Poumeyrol, and Thibaut Lavril, “Efficient keyword spotting using dilated con vo- lutions and gating, ” arXiv pr eprint arXiv:1811.07684 , 2018. [13] V ijayaditya Peddinti, Daniel Pove y , and Sanjeev Khu- danpur , “ A time delay neural network architecture for efficient modeling of long temporal contexts, ” in Six- teenth Annual Confer ence of the International Speech Communication Association , 2015. [14] Xavier Glorot and Y oshua Bengio, “Understanding the difficulty of training deep feedforward neural networks, ” in In Pr oceedings of the International Confer ence on Ar- tificial Intelligence and Statistics (AIST A TS10). Society for Artificial Intelligence and Statistics , 2010. [15] Guoguo Chen, Carolina P arada, and Geor g Heigold, “Small-footprint keyw ord spotting using deep neural networks, ” in Acoustics, speech and signal pr ocessing (icassp), 2014 ieee international confer ence on . IEEE, 2014, pp. 4087–4091. [16] V assil P anayotov , Guoguo Chen, Daniel Pov ey , and San- jeev Khudanpur , “Librispeech: An ASR corpus based on public domain audio books, ” in ICASSP . 2015, pp. 5206–5210, IEEE.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment