연합 학습으로 구현하는 저전력 웨이크워드 탐지: “Hey Snips” 사례 연구
본 논문은 스마트 홈 음성 비서의 웨이크워드 검출 모델을 사용자 데이터를 중앙에 수집하지 않고도 학습할 수 있도록 연합 학습(Federated Learning, FL) 방식을 적용한다. 1,800명 이상의 크라우드소싱 참여자를 통해 수집한 “Hey Snips” 데이터셋을 공개하고, 기존 FedAvg에 Adam‑영감 적응형 평균(Per‑coordinate Adam) 기법을 도입해 통신 라운드 수를 크게 감소시켰다. 10 % 사용자 참여 비율(C=…
저자: David Leroy, Alice Coucke, Thibaut Lavril
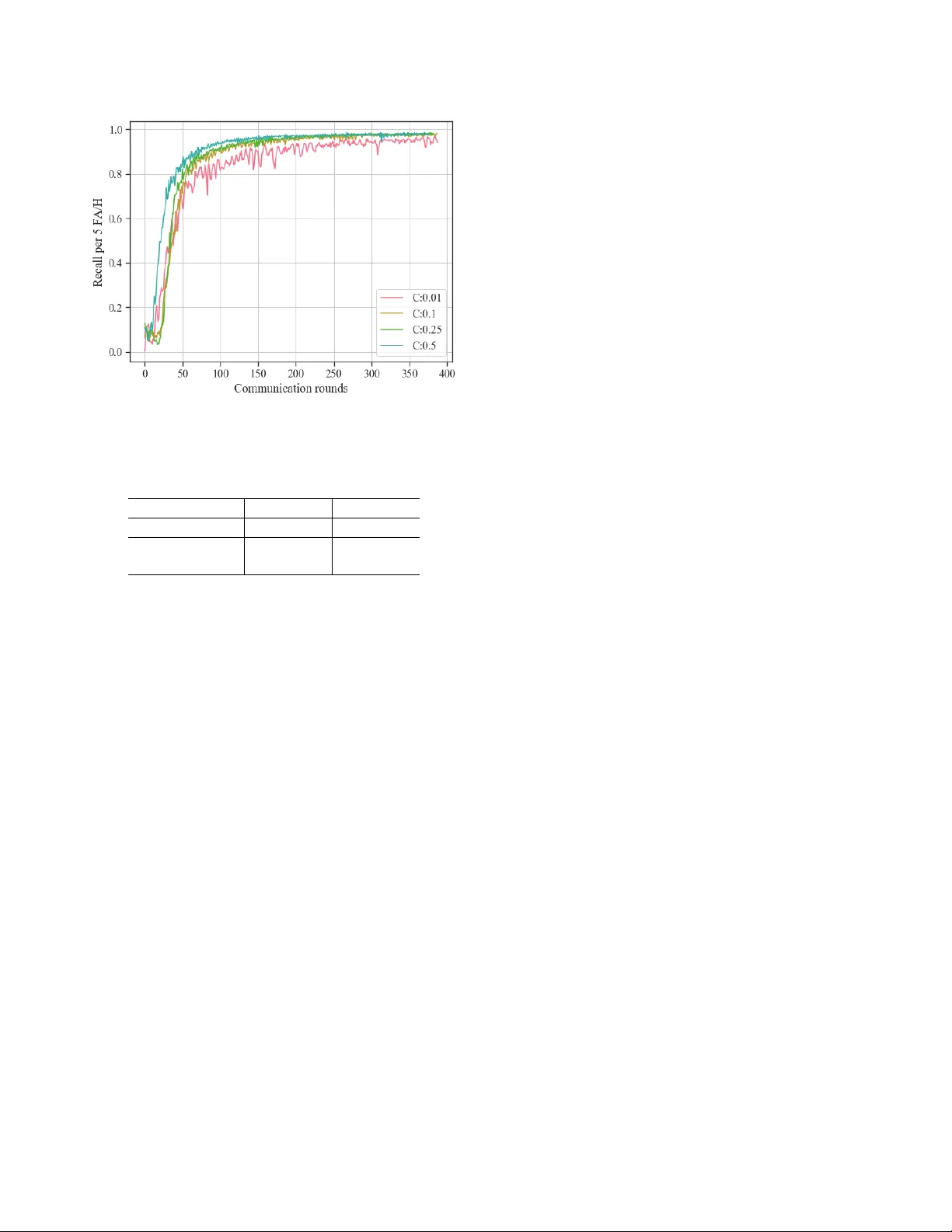
본 논문은 스마트 홈 음성 비서에서 사용되는 웨이크워드 검출 모델을 연합 학습(Federated Learning, FL) 기반으로 구현함으로써 데이터 프라이버시와 모델 성능 사이의 균형을 모색한다. 웨이크워드 검출은 항상 켜진 상태로 동작해야 하며, 제한된 메모리와 연산량(200 k 파라미터, 20 MFLOPS) 내에서 높은 재현율과 낮은 부정 알람을 달성해야 하는 까다로운 과제이다. 기존에는 사용자 음성을 중앙 서버에 수집해 대규모 데이터셋을 구축하고 학습했지만, 음성 데이터는 개인 정보에 민감하기 때문에 이러한 방식은 프라이버시 위험을 내포한다.
연구진은 이러한 문제를 해결하기 위해 두 가지 주요 접근을 제시한다. 첫째, “Hey Snips” 웨이크워드에 특화된 크라우드소싱 데이터셋을 구축하고 공개한다. 1,800명 이상의 기여자가 자신의 디바이스와 마이크로폰을 사용해 웨이크워드와 다양한 부정 문장을 녹음했으며, 데이터는 훈련(77 %), 검증(10 %), 테스트(13 %)로 사용자 기준으로 분리되어 비IID·비균형 특성을 그대로 유지한다. 전체 발화 수는 약 70 k이며, 긍정 발화 비율은 18 %이다.
둘째, 연합 학습 알고리즘을 기존 FedAvg에서 Adam‑영감 적응형 전역 평균으로 확장한다. FedAvg는 각 라운드에서 선택된 사용자 집합 Sₜ 에 대해 로컬 모델 업데이트 wₜ,ₖ 를 수행하고, 이를 파라미터 서버에서 가중 평균(사용자 데이터 수에 비례)하여 전역 모델 wₜ 를 만든다. 저자들은 이 평균 단계에 1차·2차 모멘트 추정치를 적용해 파라미터별 학습률을 자동 조정한다. 구체적으로 β₁=0.9, β₂=0.999, ε=10⁻⁸, 전역 학습률 η_global=0.001 을 사용한다. 이러한 적응형 평균은 비동질적인 사용자 데이터에서 발생하는 그래디언트 편차를 완화하고, 수렴 속도를 크게 향상시킨다.
실험 설정은 다음과 같다. 모델은 5개의 dilated convolution 레이어와 2개의 fully‑connected 레이어로 구성된 CNN이며, 총 파라미터 수는 190,852개이다. 입력은 40‑차원 MFCC를 32프레임(25 ms 윈도우, 10 ms 스트라이드)으로 스택한 형태다. 로컬 학습은 미니배치 SGD를 사용하고, 배치 크기 B, 로컬 에폭 E, 사용자 참여 비율 C 를 조절한다. 주요 실험에서는 C=10 % (전체 사용자 중 10 %가 매 라운드 참여), E=1, B=20을 사용했으며, 로컬 학습률은 0.01로 설정했다.
결과는 다음과 같다. 중앙 집중식 Adam 최적화 기준(400 스텝, 약 2 epoch)과 비교했을 때, Adam‑기반 전역 평균을 적용한 연합 학습은 100 라운드(≈8 MB 업로드) 내에 목표 재현율 95 %와 5 FA/H 기준을 달성했다. FedAvg(η_global=1)에서는 400 라운드 이후에도 목표 성능에 도달하지 못했으며, 전역 평균만 사용한 경우에도 성능이 크게 저하되었다. 사용자 참여 비율을 1 %로 낮추면 그래디언트 변동이 커져 학습이 불안정해졌고, 50 % 이상으로 늘려도 수렴 속도 향상이 미미했다. 로컬 에폭을 늘리면 통신 라운드 수는 감소하지만 전체 연산량이 증가해 효율성은 크게 개선되지 않았다.
통신 비용 측면에서는 모델 파라미터를 32‑bit 부동소수점으로 전송한다고 가정했을 때, 한 사용자가 100 라운드 동안 업로드하는 데이터 양은 약 8 MB이며, 전체 서버가 수신하는 데이터는 1.4 k 사용자 기준으로 약 110 GB이다. 이는 현재 가정용 브로드밴드 환경에서 충분히 감당 가능한 수준이다. 400 라운드까지 학습을 진행하면 사용자당 업로드량이 32 MB까지 늘어나지만, 재현율은 98 %에 달하고 부정 알람은 0.5 FA/H 수준으로 더욱 개선된다.
테스트 셋 평가에서는 95 % 재현율을 유지하면서 부정 알람이 3.2 FA/H(테스트 부정 데이터), 3.9 FA/H(Librispeech), 0.2 FA/H(내부 뉴스), 0.6 FA/H(수집된 TV 데이터)로 나타났다. 특히, 가까운 거리에서 녹음된 연속 음성 데이터에서 부정 알람이 다소 높게 나타났지만, 전반적인 성능은 기존 중앙집중식 모델과 동등하거나 우수했다.
결론적으로, 이 연구는 (1) 프라이버시를 보장하면서도 경량 웨이크워드 모델을 학습할 수 있는 연합 학습 프레임워크를 제시하고, (2) Adam‑기반 적응형 전역 평균이 비IID·비균형 음성 데이터에서 수렴 속도와 최종 성능을 크게 향상시킨다는 실증적 증거를 제공한다. 향후 연구에서는 실제 디바이스에서의 온‑디바이스 평가, 클라이언트 선택 전략 최적화, 그리고 압축 및 양자화 기법을 통한 통신 비용 추가 절감 방안을 탐구할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기