Recognizing Multi-talker Speech with Permutation Invariant Training
In this paper, we propose a novel technique for direct recognition of multiple speech streams given the single channel of mixed speech, without first separating them. Our technique is based on permutation invariant training (PIT) for automatic speech…
Authors: Dong Yu, Xuankai Chang, Yanmin Qian
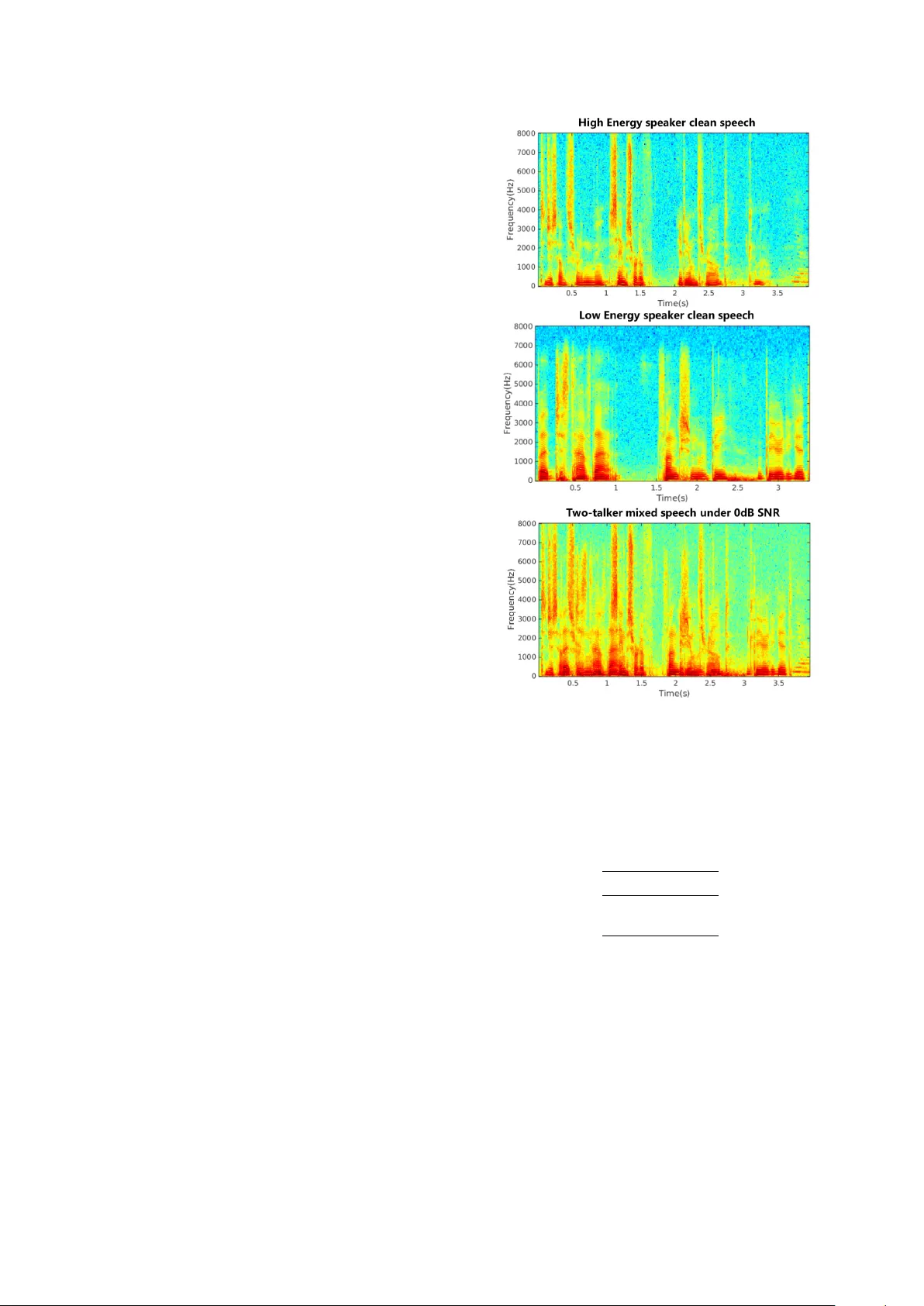
Recognizing Multi-talker Speech with P ermutation In v ariant T raining Dong Y u 1 , Xuankai Chang 2 , Y anmin Qian 2 1 T encent AI Lab, Seattle, USA 2 Department of Computer Science and Engineering, Shanghai Jiao T ong Uni versity , Shanghai, China dongyu@ieee.org, xuank@sjtu.edu.cn, yanminqian@sjtu.edu.cn Abstract In this paper , we propose a novel technique for direct recog- nition of multiple speech streams giv en the single channel of mixed speech, without first separating them. Our technique is based on permutation in v ariant training (PIT) for automatic speech recognition (ASR). In PIT -ASR, we compute the a ver- age cross entropy (CE) over all frames in the whole utterance for each possible output-target assignment, pick the one with the minimum CE, and optimize for that assignment. PIT -ASR forces all the frames of the same speaker to be aligned with the same output layer . This strategy elegantly solves the label permutation problem and speaker tracing problem in one shot. Our experiments on artificially mix ed AMI data sho wed that the proposed approach is very promising. Index T erms : permutation in variant training, LSTM, CNTK, multi-talker speech recognition 1. Introduction Thanks to the significant progresses made in the recent years [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20], the ASR systems no w surpassed the threshold for adoption in many real-world scenarios and enabled services such as Mi- crosoft Cortana, Apple’ s Siri and Google Now , where close-talk microphones are commonly used. Howe ver , the current ASR systems still perform poorly when far-field microphones are used. This is because man y difficulties hidden by close-talk microphones now surface un- der distant recognition scenarios. For example, the signal to noise ratio (SNR) between the target speaker and the interfering noises is much lo wer than that when close-talk microphones are used. As a result, the interfering signals, such as background noise, rev erberation, and speech from other talkers, become so distinct that they can no longer be ignored. In this paper, we aims at solving the speech recognition problem when multi-talkers speak at the same time and only a single channel of mixed speech is av ailable. Many attempts hav e been made to attack this problem. Before the deep learn- ing era, the most famous and effecti ve model is the factorial GMM-HMM [21], which outperformed human in the 2006 monaural speech separation and recognition challenge [22]. The factorial GMM-HMM, howe ver , requires the test speak- ers to be seen during training so that the interactions between them can be properly modeled. Recently , se veral deep learn- ing based techniques have been proposed to solve this problem Dong Y u and Y anmin Qian are the corresponding authors. 1. Part of the w ork was done while at Microsoft Research. 2. Xuankai Chang and Y anmin Qian was supported by the Shang- hai Sailing Program No. 16YF1405300, the China NSFC projects (No. 61573241 and No. 61603252) and the Interdisciplinary Program (14JCZ03) of Shanghai Jiao T ong University in China. Experiments hav e been carried out on the PI supercomputer at Shanghai Jiao T ong Univ ersity . [23, 24, 25, 26, 19, 20]. The core issue that these techniques try to address is the label ambiguity or permutation problem (refer to Section 3 for details). In W eng et al. [23] a deep learning model was de veloped to recognize the mixed speech directly . T o solve the label ambigu- ity problem, W eng et al. assigned the senone labels of the talk er with higher instantaneous energy to output one and the other to output two. This, although addresses the label ambiguity prob- lem, causes frequent speaker switch across frames. T o deal with the speaker switch problem, a two-speaker joint-decoder with a speaker switching penalty was used to trace speakers. This ap- proach has two limitations. First, energy , which is manually picked, may not be the best information to assign labels under all conditions. Second, the frame switching problem introduces burden to the decoder . In Hershey et al. [24, 25] the multi-talker mixed speech is first separated into multiple streams. An ASR engine is then applied to these streams independently to recognize speech. T o separate the speech streams, they proposed a technique called deep clustering (DPCL). They assume that each time-frequency bin belongs to only one speaker and can be mapped into a shared embedding space. The model is optimized so that in the embed- ding space the time-frequency bins belong to the same speaker are closer and those of different speakers are farther a way . Dur- ing ev aluation, a clustering algorithm is used upon embeddings to generate a partition of the time-frequency bins, i.e., speech separation and recognition are two separate components. Chen et al. [26] proposed a similar technique called deep attractor network (D ANet). Follo wing DPCL, their approach also learns a high-dimensional embedding of the acoustic sig- nals. Different from DPCL, ho wever , it creates cluster centers, called attractor points, in the embedding space to pull together the time-frequency bins corresponding to the same source. The main limitation of D ANet is the requirement to estimate at- tractor points during e valuation time and to form frequency-bin clusters based on these points. In Y u et al. [19] and Kolbak et al.[20], a simpler yet equally effecti ve technique named permutation in variant training (PIT) was proposed to attack the speaker independent multi-talker speech separation problem. In PIT , the source targets are treated as a set (i.e., order is irrelev ant). During training, PIT first de- termines the output-target assignment with the minimum error at the utterance level based on the forward-pass result. It then minimizes the error giv en the assignment. This strategy ele- gantly solved the label permutation problem and speaker trac- ing problem in one shot. Howe ver , in these original works PIT was used to separate speech streams from mixed speech. F or this reason, a frequency-bin mask was first estimated and then used to reconstruct each stream. The minimum mean square error (MMSE) between the true and reconstructed streams was used as the criterion to optimize model parameters. In this paper, we propose the PIT -ASR model that can directly recognize multiple streams of speech gi ven just the single-channel mixed speech, without first separating it into speech streams. Different from [19, 20], we define PIT ov er the cross entropy (CE) between the true and estimated senone pos- terior probabilities. W e ev aluate our approach on the artificially mixed AMI data and demonstrate that the proposed approach is very promising. The rest of the paper is or ganized as follows. In Section 2 we describe the speaker independent multi-talker mixed speech recognition problem. In Section 3 we apply PIT -ASR to directly recognize multi-streams of speech. W e report experimental re- sults in Section 4 and conclude the paper in Section 5. 2. Problem Setup In this paper , we assume that a linearly mix ed single- microphone signal y [ n ] = P S s =1 x s [ n ] is known, where x s [ n ] , s = 1 , · · · , S are S streams of speech sources. Our goal is to separate and recognize these streams. Howe ver , giv en only the mixed speech y [ n ] , the problem of recognizing all streams is under-determined because there are an infinite number of possible x s [ n ] (and thus recognition results) combinations that lead to the same y [ n ] . F ortunately , speech is not random signal. It has patterns that we may learn from a training set of pairs y and ` s , s = 1 , · · · , S , where ` s is the senone label sequence for stream s . In the single speaker case, where S = 1 , the learning prob- lem can be casted as a simple supervised optimization problem, in which the input to the model is some feature representation of y and the output is simply the senone posterior probability con- ditioned on the input. The model can be optimized to minimize the cross entropy between the senone label and the estimated posterior probability . When S > 1 , howe ver , it is no longer a simple supervised optimization problem due to the label ambiguity or permuta- tion problem. Because speech sources are symmetric giv en the mixture (i.e., x 1 + x 2 equals to x 2 + x 1 and both x 1 and x 2 hav e the same characteristics), there is no pre-determined way to assign the correct target to the corresponding output layer . Interested readers can find additional information in [19, 20] on how training progresses to nowhere when the conv entional su- pervised approach is used for the multi-talker speech separation. 3. Permutation In variant T raining T o address the label ambiguity problem, we propose a nov el model based on the permutation in variant training (PIT) [19, 20]. Note that, DPCL [24, 25] and DANet [26] are alterna- tiv e solutions to the label ambiguity problem when the goal is speech source separation. Howe ver , these two techniques are not suitable for direct recognition of multiple streams of speech because of the clustering step required during separation, and the assumption that each time-frequency bin belongs to only one speaker . Formally , gi ven some feature representation Y of the mixed speech y , our model will compute Figure 1: The two-talker speech recognition model with permu- tation in variant training H 0 = Y (1) H f i = RN N f i ( H i − 1 ) , i = 1 , · · · , N (2) H b i = RN N b i ( H i − 1 ) , i = 1 , · · · , N (3) H i = S tack ( H f i , H b i ) , i = 1 , · · · , N (4) H s o = Linear ( H N ) , s = 1 , · · · , S (5) O s = S of tmax ( H s o ) , s = 1 , · · · , S (6) using a deep bidirectional recurrent neural network (RNN), where H 0 is the input, H i , i = 1 , · · · , N is the i -th hidden layer in an N -hidden-layer network, R N N f i and RN N b i are the forw ard and backw ard RNNs at hidden layer i , respecti vely , H s o , s = 1 , · · · , S is the excitation at output layer for each speech stream s , and O s , s = 1 , · · · , S is the output layer for stream s . Note that, in this model each output layer repre- sents an estimate of the senone posterior probability for a speech stream. No additional clustering or speaker tracing is needed. Although various RNN structures can be used, in this study we used long short-term memory (LSTM) RNNs. It’ s clear that nothing is special in the forward computation. The key is in the training process. W e need to assign the correct label to each output layer for each training sample, i.e., deal with the label ambiguity problem, and to make sure the posterior probability for the same speaker is always associated with the same output layer across frames. PIT [19, 20], which is originally designed for speech separation, is e xtended here to guarantee these properties. More specifically , we minimize the objectiv e function J = 1 S min s 0 ∈ permu ( S ) X s X t C E ( ` s 0 t , O s t ) , s = 1 , · · · , S (7) where per mu ( S ) is a permutation of 1 , · · · , S . The model is illustrated in Figure 1. W e note two important ingredients in this objective function. First, we compute the average CE for each possible assignment of labels, pick the one with min- imum CE, and optimize for that assignment. In other words, it automatically finds the appropriate assignment no matter how the labels are ordered. Second, the CE is computed ov er the whole sequence for each assignment. This forces all the frames of the same speaker to be aligned with the same output layer . This strategy elegantly solves the label permutation problem and speaker tracing problem in one shot. Note, the computa- tional cost associated with label assignment is negligible com- pared to the network forward computation during training, and no label assignment (thus no cost) is needed during ev aluation. 4. Experimental Results T o e v aluate the proposed approach, a series of experiments were performed on an artificially mixed AMI corpus, and only two- talker mixed scenario is focused here. 4.1. Experimental data The AMI IHM (close-talk) data is used, which contains about 80 hours and 8 hours in training and ev aluation sets respectiv ely [27, 28], and the two-talk er mixed speech is artificially gener- ated with the sentences in the corpus. For the better and clear definition, we defined high energy (High E) and low energy (Low E) speakers within each two-talker mixed speech, and thus generated five dif ferent SNR conditions (i.e. 0dB, 5dB, 10dB, 15dB, 20dB) based on the energy ratio of the two-talkers. W e set a rule to make the length of the selected mixed speech pair comparable, so most speech duration in this ne w corpus is two- talker overlapped. All the utterance-pairs are randomly chosen from two dif ferent speakers, and the shorter one will be padded with small noise at the front and end to get the same length as the longer one. Figure 2 gives one spectrogram comparison of the original single-talker clean speech and the 0db two-talker mixed-speech in this new AMI corpus. It is observed that there is a huge dif fer- ence within the two-talker and single-talker spectrograms. T wo clean signals are sufficiently overlapped in the mixed speech and hard to separate them from each other . 4.2. Baseline setup In this work, all the neural networks were built using the lat- est Microsoft Cognitive T oolkit (CNTK) [29] and the decod- ing systems were built based on Kaldi [30]. W e first followed the officially released kaldi recipe to b uild an LD A-MLL T -SA T GMM-HMM model. This model uses 39-dim MFCC feature and has roughly 4K tied-states and 80K Gaussians. W e then used this acoustic model to generate the senone alignment for neural network training. W e trained the DNN and BLSTM- RNN baseline systems with the original AMI IHM data. 80- dimensional log filter bank features with CMVN were used to train the baselines. The DNN has 6 hidden layers each of which contains 2048 Sigmoid neurons. The input feature for DNN contains 11 frames contextual window . The BLSTM-RNN has 3 bidirectional LSTM layers which are followed by the soft- max layer . Each BLSTM layer has 512 memory cells. The input to the BLSTM-RNN is a single acoustic frame. All the models explored here are optimized with cross-entropy criterion. The DNN is optimized using SGD method with 256 minibatch size, and the BLSTM-RNN is trained using SGD and BPTT with 4 full-length utterances parallel processing. For decoding, we used a 50K-word dictionary and a tri- gram language model interpolated from the ones created using the AMI transcripts and the Fisher English corpus. The per- formance of these two baselines on the original single-speaker AMI corpus are presented in T able 1, and they are still compa- rable with other w orks [28] e ven without using adapted fMLLR feature. It is noted that adding more BLSTM layers did not Figure 2: Spectro gram comparison of original single-talker clean speech and the 0db two-talker mixed-speech in the new AMI corpus show substantial WER reduction in the baseline. T able 1: WER (%) of the baseline systems on original AMI IHM single-talker corpus Model WER DNN 28.0 BLSTM 26.6 T o test the baseline results on the two-talker mixed speech, the above baseline BLSTM-RNN model is utilized to decode the mixed speech directly . In scoring we compare the decoding outputs with the individual reference of two speakers respec- tiv ely to obtain two-talkers’ WERs, and the results are illus- trated in T able 2. It is observed that the ability of the single- speaker model is v ery limited on the multi-talk er mixed speech, and there is very large degradation in all conditions. The perfor - mance drop is increased very fast with the lower SNR, and the WERs for the low energy speaker e ven are all around 100.0%. These results demonstrate the huge challenge of the multi-talker speech recognition. Figure 3: Decoding results of baseline BLSTM-RNN system on 0db two-talker mixed speech sample Figure 4: Decoding results of the proposed PIT -ASR model on 0db two-talker mixed speech sample T able 2: WER (%) of the baseline BLSTM-RNN system on two- talker mixed AMI IHM speech SNR Condition High E Spk Low E Spk 0db 85.0 100.5 5db 68.8 110.2 10db 51.9 114.9 15db 39.3 117.6 20db 32.1 118.7 4.3. Evaluation on PIT -ASR models The experimental results on the proposed PIT -ASR model is de- scribed here. All the mixed data under the different SNR con- ditions are pooled together for training. The indi vidual senone alignments for the two-talkers in each mix ed speech utterance are from the single-speaker baseline alignment. For compati- bility , the alignment of the shorter utterance within the mixed speech is padded with the silence state at the front and the end. The PIT -ASR model is composed of 4 bidirectional LSTM lay- ers with 768 memory cells in each layer , and 40-dimensional log filter bank feature is used for the PIT -ASR model. The model was trained with 8 parallel utterances in the same minibatch, and the gradient was clipped with the threshold of 0.0003 to guarantee the training stability . T wo outputs of the PIT -ASR model are both used in decod- ing to obtain the hypotheses for two talkers. For scoring, we ev aluated the hypotheses on the pairwise score mode against the two references, and made the better WER as the final as- signment for each utterance. The results are shown in T able 3. The PIT -ASR model achiev es v ery large gains on both talkers compared with base- line results in T able 2 for all SNR conditions. The degra- dation increases slowly with the lower SNR for the high en- ergy speaker , and the improv ement is huge for the low energy speaker . In 0dB SNR scenario, the performances of two speak- ers are very close, and obtain 40.0% relati ve improvement for both high and lo w energy speakers. In 20dB SNR, the WER of the high energy speaker is still significantly better than the base- line, and e ven approaches the original single-speaker decoding in T able 1. T o giv e a better understanding on the results comparison, T able 3: WER (%) of the propsoed PIT -ASR model on two-talker mixed AMI IHM speech SNR Condition High E WER Low E WER 0db 49.74 56.88 5db 40.31 60.31 10db 34.38 65.52 15db 31.24 73.04 20db 29.68 80.83 the results of one 0db two-talker mixed speech utterance us- ing dif ferent models are illustrated in Figure 3 and 4. For the baseline using BLSTM-RNN decoding with the mixed speech directly , the hypotheses are erroneous and most outputs are wrong. In contrast, lots of words can be recognized correctly by the proposed PIT -ASR model for both speakers, and it seems that the PIT -ASR frame work can do the speech separation im- plicitly . 5. Conclusion In this paper, we proposed a nov el technique for direct recog- nition of multiple speech streams giv en the single channel of mixed speech, without first separating them. Our technique is based on permutation in variant training, which was originally dev eloped for separation of multiple speech streams. Our exper - iments on artificially mixed AMI data showed that the proposed approach is very promising. There are man y possible ways to further improv e the recog- nition accuracy . F or example, we only explored log filter bank features. It is well kno wn that finer frequency resolution can help better separate speech streams. In addition, we only used acoustic information in this work. Further accuracy improv e- ment can be achieved by feeding language model information back from the decoder to the speech separation component, and by jointly considering all streams of speech when making de- coding decision. Although we discussed and ev aluated our pro- posed approach on single channel mixed speech, the technique can be applied to multi-channel condition and can exploit beam- forming results to achiev e better results. 6. References [1] D. Y u and L. Deng, Automatic speech recognition: A deep learn- ing appr oach . Springer , 2014. [2] D. Y u, L. Deng, and G. E. Dahl, “Roles of pre-training and fine-tuning in context-dependent dbn-hmms for real-world speech recognition, ” in NIPS 2010 W orkshop on Deep Learning and Un- supervised F eatur e Learning , 2010. [3] G. E. Dahl, D. Y u, L. Deng, and A. Acero, “Context-dependent pre-trained deep neural networks for large-vocab ulary speech recognition, ” IEEE T ransactions on Audio, Speech and Language Pr ocessing , vol. 20, no. 1, pp. 30–42, 2012. [4] F . Seide, G. Li, and D. Y u, “Con versational speech transcrip- tion using context-dependent deep neural networks. ” in INTER- SPEECH , 2011, pp. 437–440. [5] G. Hinton, L. Deng, D. Y u, G. E. Dahl, A.-r . Mohamed, N. Jaitly , A. Senior, V . V anhouck e, P . Nguyen, T . N. Sainath et al. , “Deep neural netw orks for acoustic modeling in speech recognition: The shared vie ws of four research groups, ” IEEE Signal Pr ocessing Magazine , vol. 29, no. 6, pp. 82–97, 2012. [6] O. Abdel-Hamid, A.-r . Mohamed, H. Jiang, and G. Penn, “ Apply- ing conv olutional neural networks concepts to hybrid NN-HMM model for speech recognition, ” in ICASSP , 2012, pp. 4277–4280. [7] O. Abdel-Hamid, A.-r . Mohamed, H. Jiang, L. Deng, G. Penn, and D. Y u, “Con volutional neural networks for speech recogni- tion, ” IEEE/ACM T ransactions on Audio, Speech and Language Pr ocessing , vol. 22, no. 10, pp. 1533–1545, 2014. [8] T . N. Sainath, O. V inyals, A. Senior, and H. Sak, “Conv olutional, long short-term memory , fully connected deep neural networks, ” in ICASSP , 2015, pp. 4580–4584. [9] M. Bi, Y . Qian, and K. Y u, “V ery deep con volutional neural net- works for L VCSR, ” in INTERSPEECH , 2015. [10] Y . Qian, M. Bi, T . T an, and K. Y u, “V ery deep con volutional neural networks for noise rob ust speech recognition, ” IEEE/A CM T rans- actions on Audio, Speech, and Language Processing , vol. 24, no. 12, pp. 2263–2276, 2016. [11] Y . Qian and P . C. W oodland, “V ery deep con v olutional neural net- works for robust speech recognition, ” in SLT , 2016, pp. 481–488. [12] V . Mitra and H. Franco, “T ime-frequency con volutional netw orks for robust speech recognition, ” in ASRU , 2015, pp. 317–323. [13] V . Peddinti, D. Povey , and S. Khudanpur , “ A time delay neural network architecture for efficient modeling of long temporal con- texts, ” in INTERSPEECH , 2015. [14] T . Sercu, C. Puhrsch, B. Kingsbury , and Y . LeCun, “V ery deep multilingual con volutional neural networks for L VCSR, ” in ICASSP , 2016. [15] D. Amodei, R. Anubhai, E. Battenberg, C. Case, J. Casper , B. Catanzaro, J. Chen, M. Chrzano wski, A. Coates, G. Diamos et al. , “Deep speech 2: End-to-end speech recognition in English and Mandarin, ” arXiv pr eprint arXiv:1512.02595 , 2015. [16] S. Zhang, C. Liu, H. Jiang, S. W ei, L. Dai, and Y . Hu, “Feed- forward sequential memory networks: A new structure to learn long-term dependency , ” arXiv preprint , 2015. [17] D. Y u, W . Xiong, J. Droppo, A. Stolcke, G. Y e, J. Li, and G. Zweig, “Deep convolutional neural networks with layer-wise context expansion and attention, ” in INTERSPEECH , 2016. [18] W . Xiong, J. Droppo, X. Huang, F . Seide, M. Seltzer, A. Stolcke, D. Y u, and G. Zweig, “ Achie ving human parity in conversational speech recognition, ” arXiv pr eprint arXiv:1610.05256 , 2016. [19] D. Y u, M. Kolbk, Z.-H. T an, and J. Jensen, “Permutation in vari- ant training of deep models for speaker-independent multi-talker speech separation, ” in ICASSP , 2017. [20] M. K olbk, D. Y u, Z.-H. T an, and J. Jensen, “Multi-talker speech separation and tracing with permutation in variant training of deep recurrent neural networks, ” IEEE/ACM Tr ansactions on Audio, Speech and Language Pr ocessing , submitted, 2017. [21] Z. Ghahramani and M. I. Jordan, “Factorial hidden markov mod- els, ” Machine learning , vol. 29, no. 2-3, pp. 245–273, 1997. [22] M. Cooke, J. R. Hershey , and S. J. Rennie, “Monaural speech separation and recognition challenge, ” Computer Speech and Lan- guage , v ol. 24, no. 1, pp. 1–15, 2010. [23] C. W eng, D. Y u, M. L. Seltzer, and J. Droppo, “Deep neu- ral networks for single-channel multi-talker speech recognition, ” IEEE/ACM T ransactions on Audio, Speech and Language Pr o- cessing , vol. 23, no. 10, pp. 1670–1679, 2015. [24] J. R. Hershey , Z. Chen, J. L. Roux, and S. W atanabe, “Deep clus- tering: Discriminati ve embeddings for segmentation and sepa- ration, ” in Pr oc. IEEE Int. Conf. Acoust. Speech Signal Pr ocess (ICASSP). , 2016, pp. 31–35. [25] Y . Isik, J. L. Roux, Z. Chen, S. W atanabe, and J. R. Hershey , “Single-Channel Multi-Speaker Separation Using Deep Cluster- ing, ” in Pr oc. Annual Confer ence of International Speech Com- munication Association (INTERSPEECH) , 2016, pp. 545–549. [26] Z. Chen, Y . Luo, and N. Mesgarani, “Deep attractor network for single-microphone speaker separation, ” in ICASSP , 2017. [27] T . Hain, L. Burget, J. Dines, P . N. Garner, F . Gr ´ ezl, A. E. Han- nani, M. Huijbregts, M. Karafiat, M. Lincoln, and V . W an, “Tran- scribing meetings with the amida systems, ” IEEE T ransactions on Audio, Speech, and Language Processing , vol. 20, no. 2, pp. 486– 498, 2012. [28] P . Swietojanski, A. Ghoshal, and S. Renals, “Hybrid acous- tic models for distant and multichannel large vocab ulary speech recognition, ” in Pr oceedings of ASRU , 2013, pp. 285–290. [29] D. Y u, A. Eversole, M. Seltzer, K. Y ao, Z. Huang, B. Guenter , O. Kuchaiev , Y . Zhang, F . Seide, H. W ang et al. , “ An introduc- tion to computational networks and the computational network toolkit, ” Micr osoft T echnical Report MSR-TR-2014–112 , 2014. [30] D. Povey , A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P . Motlicek, Y . Qian, P . Schwarz et al. , “The kaldi speech recognition toolkit, ” in IEEE 2011 workshop on automatic speech r ecognition and understanding , no. EPFL- CONF-192584. IEEE Signal Processing Society , 2011.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment