다중 화자 음성 인식을 위한 순열 불변 학습
본 논문은 단일 채널에 섞인 다중 화자 음성을 사전 분리 없이 직접 인식하기 위해, 교차 엔트로피 기반의 순열 불변 훈련(PIT‑ASR) 방식을 제안한다. 전체 발화 수준에서 가능한 레이블 순열을 모두 평가해 최소 CE를 갖는 순열을 선택하고, 해당 순열에 대해 네트워크를 최적화함으로써 레이블 혼동과 화자 추적 문제를 동시에 해결한다. 인공적으로 혼합한 AMI 데이터셋 실험에서 기존 BLSTM 기반 베이스라인 대비 큰 WER 감소를 확인하였다.
저자: Dong Yu, Xuankai Chang, Yanmin Qian
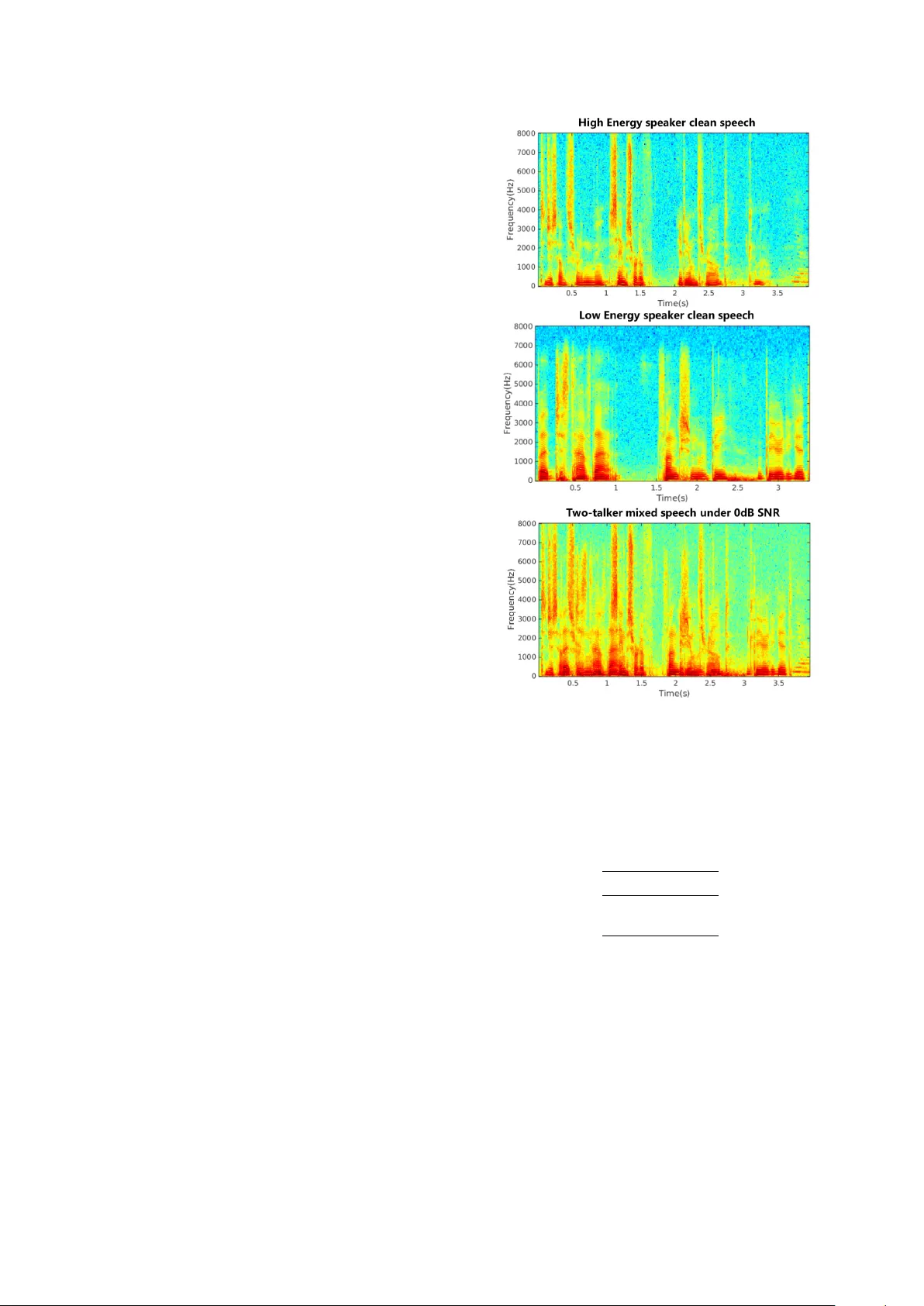
본 논문은 단일 마이크 채널에 섞인 다중 화자 음성을 사전 분리 없이 직접 인식하는 새로운 방법을 제시한다. 기존의 다중 화자 인식 연구는 크게 두 갈래로 나뉜다. 하나는 factorial GMM‑HMM과 같이 화자 간 상호작용을 모델링하는 전통적 방법이며, 다른 하나는 딥러닝 기반의 음성 분리 후 인식(예: Deep Clustering, Deep Attractor Network)이다. 그러나 전자는 화자를 사전에 알아야 하는 제약이 있고, 후자는 별도의 클러스터링 단계와 마스크 추정 과정이 필요해 복잡도가 높다. 특히, 레이블 순열 문제—어떤 출력이 어느 화자에 대응되는가—가 핵심 난제이다.
이에 저자들은 순열 불변 훈련(Permutation Invariant Training, PIT)을 교차 엔트로피 손실에 적용한 PIT‑ASR 모델을 설계한다. 모델은 입력 특성 Y(로그 필터뱅크)에서 시작해 4개의 양방향 LSTM 층을 통과하고, 마지막에 S개의 출력층(본 연구에서는 S=2)을 두어 각각의 화자에 대한 senone posterior를 출력한다. 학습 단계에서 각 발화 전체에 대해 가능한 모든 레이블 순열(2! = 2가지)을 평가하고, 평균 CE가 가장 낮은 순열을 선택해 그 순열에 대해 손실을 최소화한다. 이 과정은 발화 전체 수준에서 레이블 매핑을 고정하므로, 프레임 단위에서 화자가 번갈아가며 출력층을 바꾸는 현상을 방지한다.
실험은 AMI IHM 데이터셋을 기반으로 두 화자를 인공적으로 혼합한 데이터에서 수행되었다. 고에너지 화자와 저에너지 화자를 구분해 0 dB, 5 dB, 10 dB, 15 dB, 20 dB의 5가지 SNR 조건을 만든 뒤, 기존 단일 화자 BLSTM 모델을 그대로 적용한 베이스라인과 비교하였다. 베이스라인은 저에너지 화자에 대해 WER가 100 %에 달할 정도로 성능이 급격히 저하되었으며, SNR이 낮을수록 고에너지 화자조차도 큰 오류를 보였다. 반면 PIT‑ASR 모델은 모든 SNR 구간에서 고에너지 화자의 WER를 30~50 % 수준으로 유지했고, 저에너지 화자 역시 0 dB에서 56.9 %까지 크게 개선하였다. 특히 20 dB 조건에서는 고에너지 화자의 WER가 29.7 %로 원래 단일 화자 상황(26.6 %)에 근접하였다.
결과는 PIT‑ASR가 레이블 순열과 화자 추적 문제를 한 번에 해결함으로써, 별도의 음성 분리 과정 없이도 다중 화자 인식 성능을 크게 끌어올릴 수 있음을 보여준다. 그러나 현재는 로그 필터뱅크만 사용했으며, 고해상도 스펙트로그램이나 언어 모델 피드백을 활용하지 않았다. 또한 실험이 인공 혼합 데이터에 국한돼 실제 회의실 환경이나 다채널 마이크 배열에 대한 검증이 부족하다. 향후 연구에서는 더 정교한 음향 특징, 다채널 빔포밍 결과와의 결합, 그리고 다중 화자 디코더를 공동 최적화하는 end‑to‑end 구조를 탐색함으로써 성능을 더욱 향상시킬 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기