The Effect of Heterogeneous Data for Alzheimers Disease Detection from Speech
Speech datasets for identifying Alzheimer's disease (AD) are generally restricted to participants performing a single task, e.g. describing an image shown to them. As a result, models trained on linguistic features derived from such datasets may not …
Authors: Aparna Balagopalan, Jekaterina Novikova, Frank Rudzicz
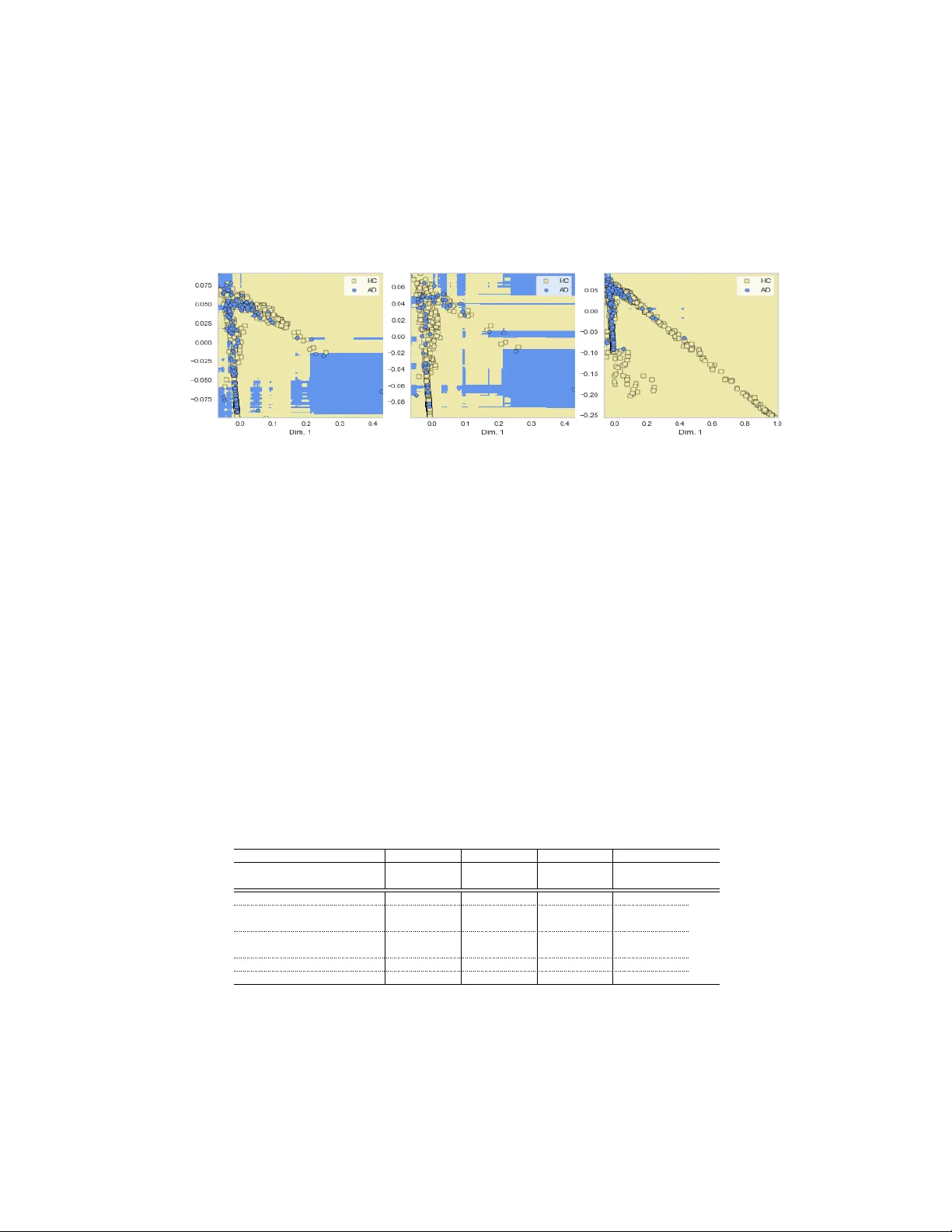
The Effect of Heter ogeneous Data f or Alzheimer’ s Disease Detection fr om Speech Apar na Balagopalan 1,2 , Jekaterina Noviko va 1 , Frank Rudzicz 1,2,3,4,5 and Marzyeh Ghassemi 2,3 1 W interlight Labs, T oronto, ON 2 Department of Computer Science, Univ ersity of T oronto, ON 3 V ector Institute for Artificial Intelligence, T oronto, ON 4 Li Ka Shing Knowledge Institute, St Michael’ s Hospital, T oronto, ON 5 Surgical Safety T echnologies Inc., T oronto, ON {aparna,jekaterina}@winterlightlabs.com,{frank,marzyeh}@cs.toronto.edu Abstract Speech datasets for identifying Alzheimer’ s disease (AD) are generally restricted to participants performing a single task, e.g. describing an image sho wn to them. As a result, models trained on linguistic features deri ved from such datasets may not be generalizable across tasks. Building on prior work demonstrating that same- task data of healthy participants helps improv e AD detection on a single-task dataset of pathological speech, we augment an AD-specific dataset consisting of subjects describing a picture with multi-task healthy data. W e demonstrate that normativ e data from multiple speech-based tasks helps improve AD detection by up to 9%.V isualization of decision boundaries rev eals that models trained on a combination of structured picture descriptions and unstructured conv ersational speech hav e the least out-of-task error and sho w the most potential to generalize to multiple tasks. W e analyze the impact of age of the added samples and if the y affect fairness in classification. W e also provide explanations for a possible inductive bias effect across tasks using model-agnostic feature anchors. This work highlights the need for heterogeneous datasets for encoding changes in multiple facets of cognition and for dev eloping a task-independent AD detection model. 1 Introduction Alzheimer’ s disease (AD) is a neurodegenerati ve disease affecting over 40 million people world- wide with high costs of acute and long-term care [ 17 ]. Recruitment of participants with cogniti ve impairment has historically been a bottleneck in clinical trials [ 24 ], making AD datasets relati vely small. Additionally , though cognitiv e assessments test domains of cognition through multiple tasks, most av ailable datasets of pathological speech are restricted to participants performing a single task. Picture description using an image to elicit narrative discourse samples is one such task that has prov ed to be successful in detecting AD [ 7 ]. Howe ver , it is important to de velop ML models of high performance that would produce results generalizable across dif ferent tasks. Sev eral studies ha ve used natural language processing and machine learning to distinguish between healthy and cogniti vely impaired speech of participants describing a picture. Fraser et al. [ 8 ] used linguistic and acoustic features to classify healthy and pathological speech transcripts with an accuracy of 82% . Similarly , Karlekar et al. [ 10 ] classified utterances of speakers as AD or health y (HC) with an accuracy of 91 . 1% using an enlarged, utterance-le vel vie w of transcripts of picture descriptions. In line with pre vious research, we use linguistic and acoustic features of speech as input to our ML model. Furthermore, we extend the model to using data from se veral differ ent tasks. Machine Learning for Health (ML4H) W orkshop at NeurIPS 2018. Noorian et al. [ 14 ] demonstrated that using within-task data of healthy participants describing a picture improv ed AD detection performance by up to 13%. In this paper , we ev aluate if model performance improv es with the addition of data from healthy participants, with v arying ages, performing either the same or differ ent tasks. W e find that models trained on datasets of picture description tasks augmented with con versational speech of healthy speakers learn decision boundaries that are more generalizable across activities with lower out-of-task errors. W e observe a 9% increase in AD detection performance when normativ e data from dif f erent tasks are utilized. W e also analyze if each task provides domain- specific inductiv e bias for other tasks to obtain a model setting capable of detecting AD from any sample of speech using high-precision model-agnostic e xplanations proposed by Ribeiro et al. [ 18 ] and computation of various error metrics related to classification. 2 Data Dataset Samples Subjects Age T asks in Dataset Dementia Bank[3] (DB) 409 (180 AD) 210 45 - 90 Picture Description Healthy Aging Picture Description (HAPD) 122 50 50 - 95 Picture Description Healthy Aging Fluency & P aragraph tasks (HAFP) 427 V erbal Fluency , Reading Famous People[15] (FP) 231 9 30 - 88 Con versational Speech T able 1: Speech datasets used. Note that HAPD, HAFP and FP only have samples from healthy subjects. Detailed description in App. 2. All datasets sho wn in T ab. 2 were transcribed manually by trained transcriptionists, employing the same list of annotations and protocols, with the same set of features e xtracted from the transcripts (see Sec. 3). HAPD and HAFP are jointly referred to as HA. 3 Methods Featur e Extraction: W e extract 297 linguistic features from the transcripts and 183 acoustic features from the associated audio files, all task-independent. Linguistic features encompass syntactic features (e.g. syntactic complexity [ 12 ]), lexical features (e.g. occurrence of production rules). Acoustic features include Mel-frequency Cepstral Coef ficients (MFCCs) & pause-related features (e.g., mean pause duration). W e also use sentiment le xical norms [23], local, and global coherence features [4]. Featur e Predicates as Anchors for Prediction: Giv en a black box classifier f with interpretable input representation, Ribeiro et al. [ 18 ] define anchors A as a set of input rules such that when conditions in the rule are met, humans can confidently predict the beha vior of a model with high precision. Since the inputs to the classifier are engineered features with finite ranges,we can obtain sufficient conditions for the prediction f ( x ) in terms of interpretable feature thresholds for an unseen instance x . Anchors are found by maximizing the metric of co verage, defined as the probability of anchors holding true to samples in the data distribution p , in [ 18 ]. Hence, cov ( A ) = E p ( z ) [ A ( z )] is maximized, where pr ecision ( A ) > τ . W e show in Sec. 5.4 that anchors identified from a model trained on multiple tasks ha ve more cov erage ov er the data distribution than those obtained from a model trained on a single task. Such a scenario is possible when task-independant, clinically rele v ant speech features are selected as anchors (e.g., fraction of filled pauses in speech [ 11 ], acoustic features [ 20 ] etc. ). Additionally , such selected anchors must also be associated with thresholds applicable across multiple types of speech. 4 Experiments Binary classification of each speech transcript as AD or HC is performed. W e do 5-fold cross- v alidation, stratified by subject so that each subject’ s samples do not occur in both training and testing sets in each fold. The minority class is oversampled in the training set using SMO TE [ 6 ] to deal with the class imbalance. W e consider a Random Forest (100 trees), Naïve Bayes (with equal priors), SVM (with RBF kernel), and a 2-layer neural network (10 units, Adam optimizer , 500 epochs)[ 16 ]. Additionally , we augment the DB data with healthy samples from FP with v aried ages. 2 5 Results and Discussion 5.1 V isualization of Class Boundaries Since data of dif ferent tasks have dif ferent noise patterns, the probability of overfitting to noise is reduced with samples from dif ferent tasks. This can also be visualized as decision boundaries of models trained on various dataset combinations. F or Fig.5.1, we embed the 480-dimensional feature vector into 2 dimensions using Locally Linear Embeddings [22] trained on DB. (a) Pic. descriptions (PD); 28.6% (b) PD + structured tasks; 17.8% (c) PD + general speech; 3.6% Figure 1: Decision boundaries with RF classifier for datasets with their out-of-task error sho wn in bold; scattered points sho wn belong to the train set in each case. F or models trained using general, task-independent features on picture description (Fig.1a) & other structured tasks from HAFP such as fluency (Fig.1b), decision boundaries are patchy as a result of fe w , far-lying points from the classes (e.g, in the fourth quadrant), leading to misclassifications on other tasks with v arying feature ranges. Howe ver , on datasets consisting of general, unstructured con versations, this does not happen Fig.1c. In datasets consisting of picture descriptions and con versational speech (DB + FP), the feature ranges increase as compared to picture description tasks, so it is expected that a classifier trained on structured tasks only (DB + HAFP) would incorrectly classify healthy samples in the fourth quadrant (error rates for tasks not in dataset is 17.8%). Howe ver , decision boundaries for models trained on a mix of structured tasks and unstructured con versational speech seem to be more generalizable across tasks. E.g., decision boundaries obtained from DB + FP could apply to most datapoints in HAFP (out of task error rate is 3.6%). Clinically , some of the features used such as the patterns in usage of function words like pronouns have sho wn to reflect stress-related changes in gene expression, possibly caused due to dementia [ 13 ] which would not depend on the task type and could explain such a common underlying structure to features. 5.2 Classification Perf ormance Results of binary classification with dif ferent dataset combinations (i.e., the proportion of each dataset used) are in T ab . 5.2. The highest F1 score on DB is 80 . 5% with SVM as obtained by Noorian et al. [14], enabling similar comparisons. Data Size Naïve Bayes SVM RF NN F1 F1 F1 F1 F1 F1 F1 F1 (mi.) (ma.) (mi.) (ma.) (mi.) (ma.) (mi.) (ma.) DB 229 HC 62.90 60.01 80.52 73.01 73.52 67.82 75.92 72.76 DB + HAPD 351 HC 63.99 63.37 82.97 78.65 79.00 74.76 81.39 78.07 DB + 0.29*HAFP 352 HC 60.00 58.62 82.53 77.26 78.94 72.80 82.24 78.54 DB + 0.42*HA 460 HC 65.06 63.90 82.74 78.58 78.09 73.70 84.69 80.02 DB + FP 460 HC 56.05 52.38 83.71 80.21 77.41 73.92 82.19 79.26 DB + HAFP 656 HC 74.08 70.97 87.43 80.21 82.59 77.60 86.53 79.53 DB + HA 778 HC 74.63 70.33 89.31 82.32 85.62 76.44 88.08 80.50 T able 2: AD vs HC classification. Highest F1 scores are sho wn in bold for datasets of similar size. W e see the same trend of increasing model performance with normative data from the picture description task, as shown by Noorian et al. [ 14 ]. W e observe that this increase is independent of the nature of the task performed – normati ve picture description task data of similar size as in [ 14 ] and the same amount of normative data from dif ferent structured tasks of fluency tests and paragraph reading prov e to be helpful, bringing about a similar increase in scores (+2%, +5% absolute F1 micro 3 and macro) 1 . Interestingly , performance of detecting the majority (healthy) class (reflected in F1 micro) as well as the minority (AD) class (reflected in F1 macro) increases with additional data. Augmenting DB with same amount of samples from structured tasks (HA) and from con versational speech (FP) brings about similar performance 2 . Doubling the initial amount of control data with data from a different structured task (HA, HAFP) results in an increase of up to 9% in F1 scores. 5.3 Impact of Age Age bin Number of samples F1(mi.) F1(ma.) 30 - 45 years 50 72.37 68.36 45 - 60 years 50 77.20 74.49 60 - 75 years 50 81.45 79.47 75 - 90 years 50 81.48 79.38 T able 3: Augmenting DB with healthy data of v aried ages. Scores averaged across 4 classifiers. W e augment DB with healthy samples from FP with varying ages (T ab .5.3), considering 50 samples for each 15 year duration starting from age 30. Adding the same number of samples from bins of age greater than 60 leads to greater increase in performance. This could be because the a verage age of participants in the datasets (DB, HA etc.) we use are greater than 60. Note that despite such a trend, addition of healthy data produces fair classifiers with respect to samples with age < 60 and those with age > 60 (balanced F1 scores of 75.6% and 76.1% respectiv ely; further details in App. A.5.) 5.4 Inductive Bias of T asks Each task performed in the datasets is designed to assess dif ferent cogniti ve functions, e.g. fluency task is used to ev aluate the ability to organize and plan [ 25 ] and picture description task – for detecting discourse-related impairments [ 9 ]. As a result, it is expected that the nature of decision functions and feature predicates learned on data of each of these tasks would be different. Performance of AD identification with addition of normati ve data from multiple tasks (T ab . 5.2), despite the possibly different nature of decision functions, suggests that training the model with samples from each task provides domain-specific inducti ve bias for other tasks. W e study possible underlying mechanisms responsible for this, suggested by Caruana et al. [5] and Ruder et al. [19]. Attention-focusing on Rele vant Featur es: Ruder et al. [ 19 ] claim that in a small, high-dimensional dataset, information reg arding relev ance or irrelev ance of particular features is difficult to capture. Howe ver , data related to multiple tasks can help identify features relev ant across different acti vities. W e can use anchor v ariables [ 18 ] to sho w this ef fect. The co verage of features anchoring the prediction of an instance indicates the applicability of the feature predicate to the rest of the data distrib ution and hence the importance of the feature across the data distribution. The coverage of the anchors selected for a test set which is 10% (50 samples) of DB changes by 40.8% (from 0.05 to 0.07) on the addition of the HA, which indicates that there is an attention focusing effect. Representation bias: As sho wn by Schulz et al. [ 21 ], models trained on data from multiple tasks perform better than with single-task information when little training data is av ailable for the main task. The non-linear trend of increase in model performance with the addition of dif ferent amounts of data is shown in App.A.4. The F1 micro score of the best performing model trained on DB + HA is 82.28% for picture description tasks, 95.4% for paragraph reading and 97.01% for fluency tasks. This shows greater than tri vial performance for each task and impro vement in performance for picture description task from training a model purely on DB. Such an ef fect helps the model achiev e non-trivial performance on AD detection for nov el tasks measuring multiple domains of cognition, giv en a sufficiently large number of training tasks according to algorithms provided by Baxter et al. [ 1 ]. Hence, training models on many speech-based tasks could help dev elop an algorithm capable of detecting AD from any sample of spontaneous speech. Ongoing work is on detailed analysis of nature and polarity of feature trends across v arious speech tasks. Future work will focus on learning interpretable latent representations based on the observ ations made, capable of good predictiv e performance across a multitude of tasks. 1 Friedman chi-squared = 2, df = 1, p-value = 0.1573; not significant dif ference 2 Friedman chi-squared = 0, df = 1, p-value = 1; not significant dif ference 4 References [1] Jonathan Baxter . A model of inducti ve bias learning. Journal of Artificial Intellig ence Resear ch , 12:149–198, 2000. [2] James T Becker , François Boiler , Oscar L Lopez, Judith Saxton, and Karen L McGonigle. The natural history of Alzheimer’ s disease: description of study cohort and accuracy of diagnosis. Ar chives of Neur ology , 51(6):585–594, 1994. [3] Francois Boller and James Becker . Dementiabank database guide. University of Pittsb ur gh , 2005. [4] Lenisa Brandão, T atiane Machado Lima, Maria Alice de Mattos Pimenta Parente, and Jordi Peña-Casanov a. Discourse coherence and its relation with cognition in Alzheimer’ s disease. Revista Psicologia em P esquisa , 7(1), 2017. [5] R Caruna. Multitask learning: A knowledge-based source of inducti ve bias. In Machine Learning: Pr oceedings of the T enth International Confer ence , pages 41–48, 1993. [6] Nitesh V Chawla, K e vin W Bo wyer , Lawrence O Hall, and W Philip Ke gelmeyer . SMO TE: synthetic minority over -sampling technique. Journal of artificial intelligence r esear ch , 16:321– 357, 2002. [7] Katrina E Forbes-McKay and Annalena V enneri. Detecting subtle spontaneous language decline in early Alzheimer’ s disease with a picture description task. Neur ological sciences , 26(4):243–254, 2005. [8] Kathleen C Fraser , Jed A Meltzer , and Frank Rudzicz. Linguistic features identify Alzheimer’ s disease in narrativ e speech. J ournal of Alzheimer’ s Disease , 49(2):407–422, 2016. [9] Zahra Ghayoumi, Fariba Y adegari, Behrooz Mahmoodi-Bakhtiari, Esmaeil Fakharian, Mehdi Rahgozar , and Maryam Rasouli. Persuasiv e discourse impairments in traumatic brain injury . Ar chives of tr auma r esearc h , 4(1), 2015. [10] Sweta Karlekar , T ong Niu, and Mohit Bansal. Detecting linguistic characteristics of Alzheimer’ s dementia by interpreting neural models. arXiv pr eprint arXiv:1804.06440 , 2018. [11] Hyeran Lee, Frederique Gayraud, Fabrice Hirsch, and Melissa Barkat-Defradas. Speech dysfluencies in normal and pathological aging: a comparison between Alzheimer patients and healthy elderly subjects. In the 17th International Congress of Phonetic Sciences (ICPhS) , pages 1174–1177, 2011. [12] Xiaofei Lu. Automatic analysis of syntactic comple xity in second language writing. Interna- tional journal of corpus linguistics , 15(4):474–496, 2010. [13] Matthias R Mehl, Charles L Raison, Thaddeus WW Pace, Jesusa MG Are v alo, and Steve W Cole. Natural language indicators of differential gene re gulation in the human immune system. Pr oceedings of the National Academy of Sciences , 114(47):12554–12559, 2017. [14] Zeinab Noorian, Chloé Pou-Prom, and Frank Rudzicz. On the importance of normati ve data in speech-based assessment. arXiv pr eprint arXiv:1712.00069 , 2017. [15] Jekaterina Noviko va, Aparna Balagopalan, Maria Y anchev a, and Frank Rudzicz. Early predic- tion of AD from spontaneous speech. Under Submission , 2018. [16] Fabian Pedregosa, Gaël V aroquaux, Alexandre Gramfort, V incent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer , Ron W eiss, V incent Dubourg, et al. Scikit- learn: Machine learning in Python. Journal of machine learning r esearc h , 12(Oct):2825–2830, 2011. [17] Martin Prince, Adelina Comas-Herrera, Martin Knapp, Maëlenn Guerchet, and Maria Karagian- nidou. W orld Alzheimer report 2016: improving healthcare for people li ving with dementia: cov erage, quality and costs now and in the future. 2016. 5 [18] Marco T ulio Ribeiro, Sameer Singh, and Carlos Guestrin. Anchors: High-precision model- agnostic explanations. In AAAI Confer ence on Artificial Intelligence , 2018. [19] Sebastian Ruder . An overvie w of multi-task learning in deep neural networks. arXiv pr eprint arXiv:1706.05098 , 2017. [20] Frank Rudzicz, Leila Chan Currie, Andrew Danks, T ejas Mehta, and Shunan Zhao. Automati- cally identifying trouble-indicating speech beha viors in Alzheimer’ s disease. In Pr oceedings of the 16th international A CM SIGACCESS confer ence on Computers & accessibility , pages 241–242. A CM, 2014. [21] Claudia Schulz, Stef fen Eger , Johannes Daxenber ger , T obias Kahse, and Iryna Gurevych. Multi- task learning for argumentation mining in lo w-resource settings. In Pr oceedings of the 2018 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Language T echnolo gies, V olume 2 (Short P apers) , v olume 2, pages 35–41, 2018. [22] Jianzhong W ang. Locally linear embedding. In Geometric Structur e of High-Dimensional Data and Dimensionality Reduction , pages 203–220. Springer , 2012. [23] Amy Beth W arriner , V ictor K uperman, and Marc Brysbaert. Norms of valence, arousal, and dominance for 13,915 English lemmas. Behavior r esear ch methods , 45(4):1191–1207, 2013. [24] Jennifer L W atson, Laurie Ryan, Nina Silverber g, V icky Cahan, and Marie A Bernard. Obstacles and opportunities in alzheimer’ s clinical trial recruitment. Health Affair s , 33(4):574–579, 2014. [25] Douglas M Whiteside, T ammy Keale y , Matthew Semla, Hien Luu, Linda Rice, Michael R Basso, and Brad Roper . V erbal fluency: Language or executi ve function measure? Applied Neur opsychology: Adult , 23(1):29–34, 2016. 6 A A ppendix A.1 Detailed Description of Datasets DementiaBank (DB): The DementiaBank 3 dataset is the largest av ailable public dataset of speech for assessing cognitiv e impairments. It consists of narrati ve picture descriptions from participants aged between 45 to 90 [ 2 ]. In each sample, a participant describes the picture that they are shown. Out of the 210 participants in the study , 117 were diagnosed with AD ( N = 180 samples of speech) and 93 were healthy (HC; N = 229 samples) with many subjects repeating the task with an interv al of a year . Demographics of age, sex, and years of education are provided in the dataset. Healthy Aging (HA) : The Healthy Aging dataset consists of speech samples of cognitively healthy participants ( N = 50 ) older than 50 years. Each participant performs three structured tasks – picture description (HAPD), verbal fluency test 4 , and a paragraph reading task. Fluency and paragraph tasks are jointly referred to as HAFP . The average number of samples per participant is 14.46. The dataset constitutes 8.5 hours of total audio. Famous P eople (FP): The Famous People dataset [ 15 ] consists of publicly a vailable spontaneous speech samples from 9 famous individuals (e.g., W oody Allen & Clint Eastwood) o ver the period from 1956 to 2017, spanning periods from early adulthood to older age, with an av erage of 25 samples per person. W e use speech samples of these subjects who are considered to be healthy ( N = 231 ), giv en an absence of any reported diagnosis or subjecti ve memory complaints. This healthy control (HC) group cov ers a variety of speak er ages, from 30 to 88 ( µ = 60 . 9 , σ = 15 . 4 ). A.2 Featur es A list of 480 features belonging to three groups - acoustic, semantic/ syntactic and lexical. These features include constituency-parsing based features, syntactic complexity features extracted using Lu Syntactic Complexity analyzer [ 12 ], MFCC means, v ariances and other higher order moments. Few of these features are listed belo w : • Phonation rate : Percentage of recording that is v oiced. • Mean pause duration : Mean duration of pauses in seconds. • Pause w ord ratio : Ratio of silent segments to v oiced segments. • Short pause count normalized : Normalized number of pauses less than 1 second. • Medium pause count normalized : Normalized number of pauses between 1 second and 2 seconds in length. • ZCR kurtosis : Kurtosis of Zero Crossing Rate (ZCR) of all voiced segments across frames. • MFCC means : Mean of velocity of MFCC coefficient ov er all frames (this is calculated for multiple coefficients). • MFCC kurtosis: Kurtosis of mean features. • MFCC v ariance: V ariance of acceleration of frame energy o ver all frames. • Moving-a verage type-tok en ratio (MA TTR): Moving av erage TTR (type-token ratio) ov er a window of 10 tok ens. • Cosine cutof f : Fraction of pairs of utterances with cosine distance ≤ 0.001. • Pauses of type ‘uh’ : The number of ‘uh’ fillers o ver all tok ens. • Numbers of interjections/numerals : The number of interjections/numerals used over all tokens. • Noun ratio: Ratio of number of nouns to number of nouns + verbs. • T emporal cohesion feature : A verage number of switches in tense. 3 https://dementia.talkbank.org 4 During the fluency test, the e xperimenter asks the participant to say aloud as many names of items belonging to a certain category and as man y words as possible starting with a specific letter in a 1 minute trial 7 • Speech graph features : Features e xtracted from graph of spoken w ords in a sample including av erage total de gree, number of edges, a verage shortest path, graph diameter (undirected) and graph density . • Filled pauses : Number of non-silent pauses. • Noun frequency : A verage frequency norm for all nouns. • Noun imageability: A v erage imageability norm for all nouns. • Features from parse-tree : Number of times production rules such as number of noun phrases to determiners occurrences, occur o ver the total number of productions in the transcript’ s parse tree. • Syntactic complexity features: Ratio of clauses to T -units 5 , Ratio of clauses to sentences etc. [12] A.3 Hyper -parameters: Gaussian Naiv e Bayes with balanced priors is used. The random forest classifier fits 100 decision trees with other default parameters in [16]. SVM is trained with radial basis function kernel, regularization parameter C = 1 and γ = 0 . 001 . The NN consists of one hidden layer of 10 units. The tanh activ ation function is used at each hidden layer . The network is trained using Adam for 100 epochs with other default parameters in [16]. A.4 Effect of data from differ ent tasks: The effect of augmenting DB with data from a dif ferent structured task (HAFP) is shown in A.4. Figure A.4: Effect of addition of data from a dif ferent structured task on F1 (micro) and F1 (macro) F1 scores (micro and macro) increase non-linearly with the addition of data. A.5 Fair ness with Respect to Age: W e e valuate fairness of classification with respect to tw o groups - samples with age < 60 and those with age > 60. A fair classifier w ould produce comparable classification scores for both groups. F or the best performing classifier on DB, the F1 (micro) score for samples with age < 60 is 85.9% and with age > 60 is 76.4%. W ith the addition of HA, the F1 (micro) score for samples with age < 60 and with age > 60 is more balanced (75.6%, 76.1% respectiv ely) for the same set of data points from DB. Note that the av erage age in both datasets are similar ( µ ag e ≈ 68 ). 5 T -unit: Shortest grammatically allo wable sentences into which writing can be split or minimally terminable unit 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment