다양한 음성 데이터가 알츠하이머 진단 모델의 일반화에 미치는 영향
본 연구는 사진 설명 과제에 한정된 알츠하이머(AD) 음성 데이터에, 여러 과제에서 수집된 정상인 음성 데이터를 추가함으로써 모델의 검출 성능과 과제 간 일반화 능력이 향상됨을 입증한다. 다중 과제 데이터는 F1 점수를 최대 9%까지 끌어올렸으며, 연령 편향을 최소화하고, 모델‑불가지론적 ‘앵커’ 해석을 통해 작업 간 유도 편향을 설명한다.
저자: Aparna Balagopalan, Jekaterina Novikova, Frank Rudzicz
본 논문은 알츠하이머병(AD) 조기 진단을 위한 음성 기반 머신러닝 모델이 과제 간 일반화에 취약하다는 문제점을 인식하고, ‘이질적 데이터(heterogeneous data)’를 활용한 접근법을 제시한다. 기존 연구는 주로 그림 설명(picture description)이라는 단일 과제에 의존했으며, 이는 모델이 특정 과제에 특화된 특징에 과적합될 위험을 내포한다. 저자들은 이러한 한계를 극복하기 위해, 동일한 언어·음향 특징을 추출한 다양한 과제의 정상인 데이터를 기존 AD 데이터베이스(DB)와 결합한다.
데이터 구성은 다음과 같다. DB는 DementiaBank에서 수집된 그림 설명 음성으로, AD 환자 180명과 정상인 229명을 포함한다. 보조 데이터는 세 가지로, (1) Healthy Aging Picture Description(HAPD) – 구조화된 그림 설명, (2) Healthy Aging Fluency & Paragraph(HAFP) – 언어 유창성 및 문단 읽기 과제, (3) Famous People(FP) – 일상 대화 형태의 비구조화된 과제이다. HAPD와 HAFP는 정상인만 포함하고, FP 역시 정상인만 포함한다.
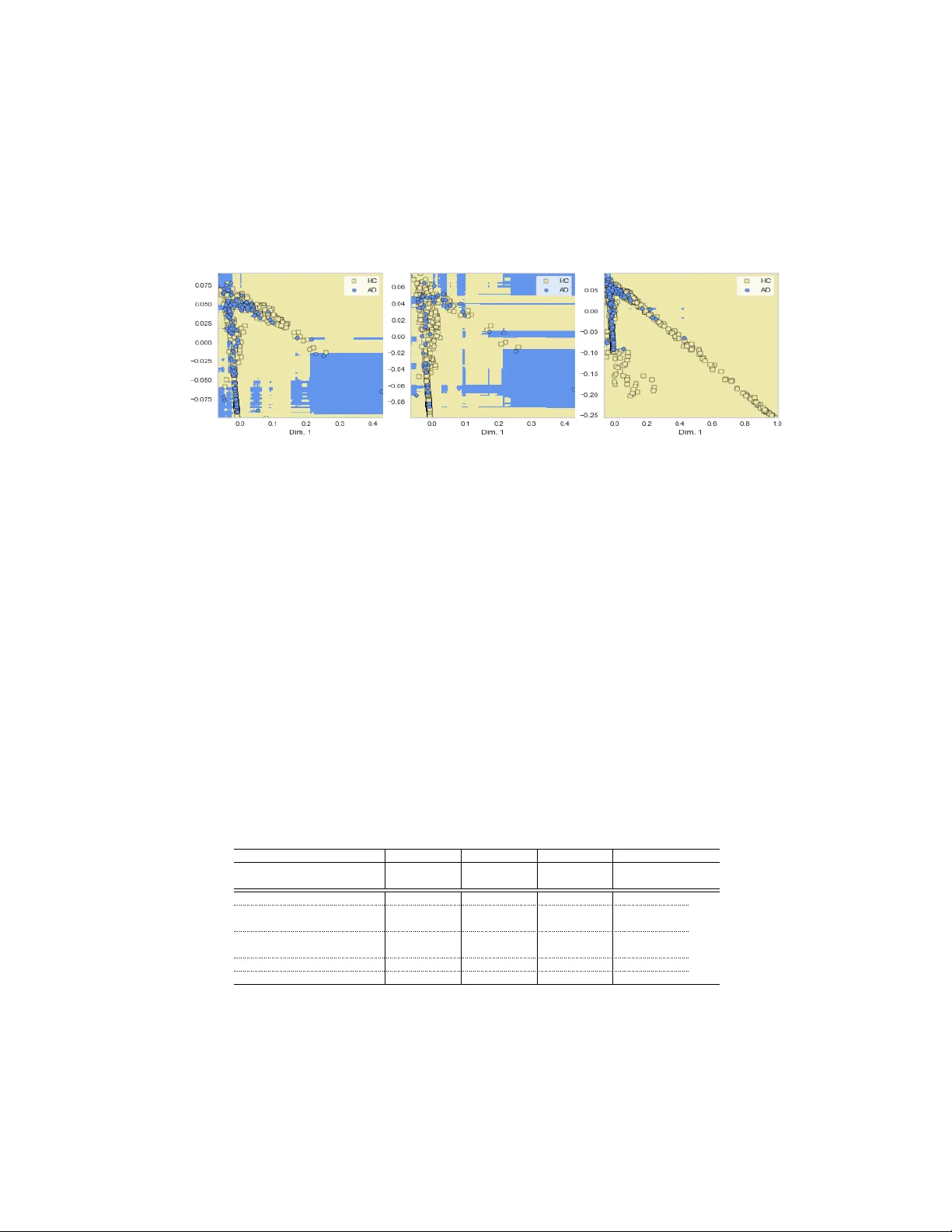
특징 추출 단계에서는 과제에 독립적인 297개의 언어학적 특징과 183개의 음향 특징을 사용한다. 언어학적 특징은 구문 복잡도, 어휘 규칙, 감성 사전, 전·국부 일관성 등을 포함하고, 음향 특징은 MFCC, 평균 멈춤 시간 등이다. 이렇게 고차원(480차원) 특징을 LLE(Locally Linear Embedding)로 2차원에 투영해 시각화함으로써, 서로 다른 과제의 데이터가 모델의 결정 경계에 미치는 영향을 직관적으로 확인한다. 그림 1은 DB 단독, DB+구조화된 과제, DB+비구조화된 대화 세 경우의 결정 경계를 보여주며, 비구조화된 대화를 포함한 경우(out-of-task error 3.6%)가 가장 일반화가 잘 됨을 시각적으로 입증한다.
분류 모델은 Random Forest(100 trees), Naïve Bayes, SVM(RBF), 2‑layer Neural Network(10 units, Adam, 500 epochs)이며, 5‑fold 교차 검증을 수행한다. 클래스 불균형은 훈련 단계에서 SMOTE를 적용해 보정하였다. 실험 결과는 표 2에 정리되어 있다. DB만 사용할 때 최고 F1 마이크로는 80.52%였으며, 동일 과제의 정상인 데이터를 추가한 경우(예: DB+HAPD) F1이 2~5% 상승한다. 특히 DB+HA(구조화된 과제와 비구조화된 대화를 모두 포함)에서는 F1 마이크로 89.31%, 매크로 82.32%에 도달해, 단일 과제 대비 최대 9% 향상을 보였다.
연령 편향 분석(표 3)에서는 60세 이상 샘플을 추가했을 때 성능 향상이 가장 크게 나타났으며, 이는 기존 데이터셋의 평균 연령이 60세 이상이기 때문이다. 그러나 연령 구간별 F1 차이는 0.5% 이하로, 모델이 연령에 대해 공정함을 유지한다는 점을 확인했다.
인덕티브 바이어스(Inductive Bias)와 특징 선택 메커니즘을 설명하기 위해 모델‑불가지론적 ‘앵커(Anchors)’ 기법을 적용하였다. 앵커는 특정 특징 임계값 조합이 모델 예측을 높은 정밀도로 설명할 수 있는 규칙이다. 다중 과제 모델에서 선택된 앵커의 커버리지는 단일 과제 모델에 비해 40.8% 증가했으며, 이는 다양한 과제에서 공통적으로 중요한 특징(예: 채워진 멈춤 비율, 특정 MFCC)의 강조를 의미한다. 이러한 ‘주의 집중(attention‑focusing)’ 효과와, 다중 과제 학습이 데이터 잡음 패턴을 다양화시켜 과적합을 방지한다는 점이 결정 경계 시각화 결과와 일치한다.
논문의 주요 기여는 다음과 같다. (1) 다중 과제 정상인 데이터를 활용해 AD 검출 성능을 최대 9% 향상시켰다. (2) 비구조화된 대화와 구조화된 과제를 결합하면 과제 간 일반화가 크게 개선된다. (3) 연령에 따른 공정성을 유지하면서도, 연령이 높은 샘플이 모델 성능에 더 큰 기여를 함을 실증했다. (4) 앵커 기반 해석을 통해 다중 과제 학습이 임상적으로 의미 있는 특징에 대한 인덕티브 바이어스를 형성함을 증명했다.
한계점으로는 AD 환자 데이터가 여전히 그림 설명에만 국한돼 있어, 실제 임상 현장의 다양한 대화 상황에 대한 검증이 부족하다는 점이다. 또한, 전통적인 엔지니어링 기반 특징에 의존하고 있어 최신 딥러닝 기반 음성/텍스트 임베딩과의 비교가 이루어지지 않았다. 향후 연구에서는 (i) 다양한 언어·문화권의 대화 데이터를 확보하고, (ii) 멀티모달(음성·텍스트·영상) 통합 모델을 개발하며, (iii) 학습된 앵커를 기반으로 임상 해석 가능한 바이오마커를 도출하는 방향을 제시한다.
결론적으로, 이질적 데이터와 다중 과제 학습은 AD 음성 진단 모델의 일반화와 공정성을 동시에 향상시킬 수 있음을 보여주며, 향후 작업 독립적인 조기 진단 시스템 구축에 중요한 설계 원칙을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기