Facilitating the Manual Annotation of Sounds When Using Large Taxonomies
Properly annotated multimedia content is crucial for supporting advances in many Information Retrieval applications. It enables, for instance, the development of automatic tools for the annotation of large and diverse multimedia collections. In the c…
Authors: Xavier Favory, Eduardo Fonseca, Frederic Font
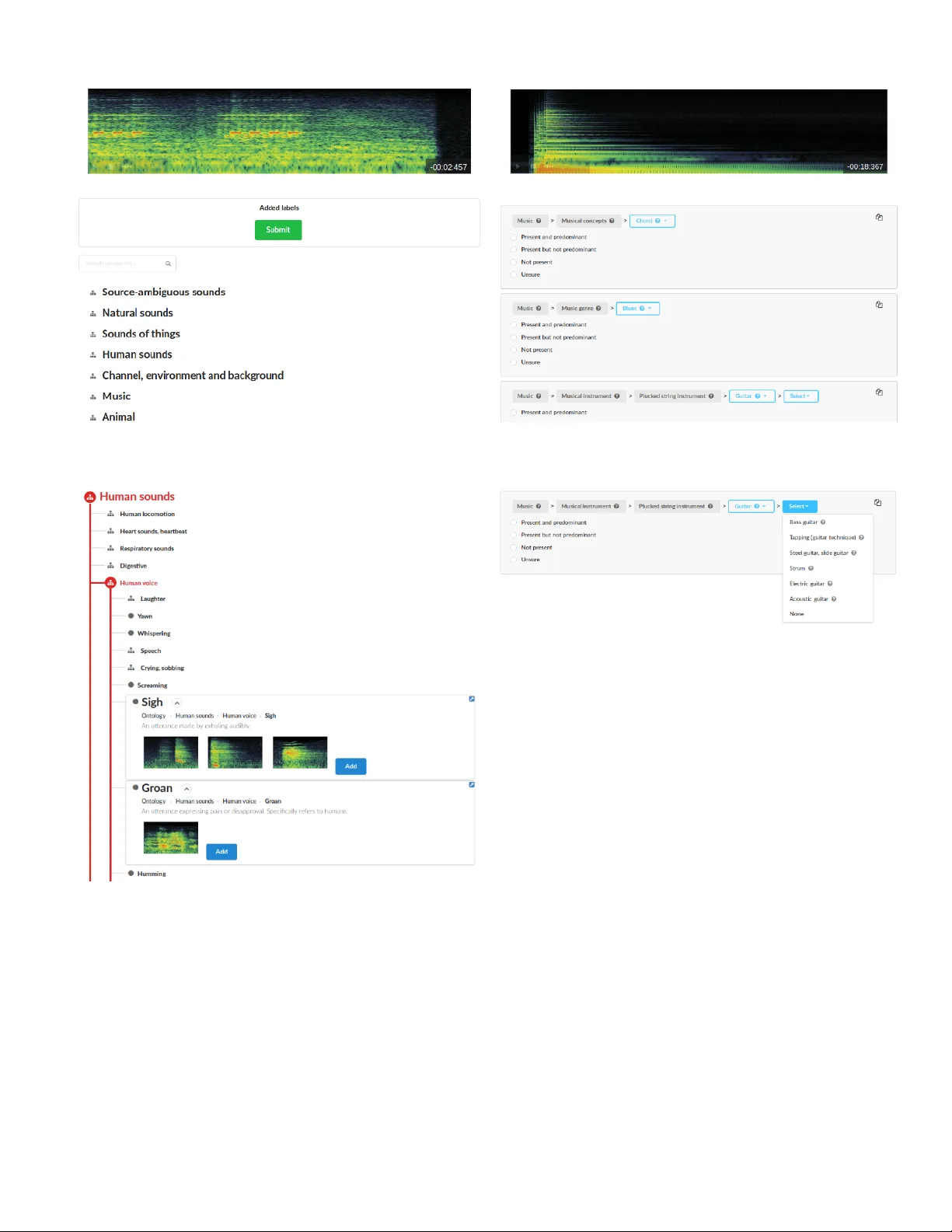
F acilitating the Manual Annotation of Sounds When Using Lar ge T axonomies Xavier Fa vory , Eduardo Fonseca, Frederic F ont, Xavier Serra Music T echnology Group - Univ ersitat Pompeu Fabra Barcelona, Spain name.surname@upf.edu Abstract —Properly annotated multimedia content is crucial for supporting advances in many Information Retrieval applica- tions. It enables, for instance, the development of automatic tools for the annotation of large and di verse multimedia collections. In the context of everyday sounds and online collections, the content to describe is very diverse and in volves many different types of concepts, often or ganised in large hierarchical structures called taxonomies. This makes the task of manually annotating content arduous. In this paper , we present our user-center ed dev elopment of two tools for the manual annotation of audio content from a wide range of types. W e conducted a preliminary evaluation of functional prototypes in v olving real users. The goal is to evaluate them in a real context, engage in discussions with users, and inspire new ideas. A qualitative analysis was carried out including usability questionnaires and semi-structur ed interviews. This revealed interesting aspects to consider when developing tools f or the manual annotation of audio content with labels drawn from large hierarchical taxonomies. I . I N T RO D U C T I O N Accessing multimedia content is one of the core challenges in multimedia research. In the past decades, automatic content description methods have proliferated and can be used, with different accuracies, for detecting semantic concepts from low- lev el features deri ved from the content digital representation. Howe v er , there is a persistent semantic gap [1] produced by the lack of accordance between the information that can be extracted from the data and the interpretation that the same data has for a user . Now adays, successful automatic description methods are based on approaches that often rely on a lot of data for training and ev aluation. As a consequence, manual generation of content description is of high importance for the realisation of intelligent systems able to produce meaningful automatic content descriptions. Recent adv ancements partially come from the popularity of online sharing platforms, which made avail- able a large amount of data [2]. In these platforms, description and tagging systems have become increasingly popular . Users can add textual descriptions or keyw ords (i.e., tags) to Internet resources (e.g., web pages, images, music) without relying on a controlled vocab ulary . This mak es it less demanding for users than, for example, classifying objects into prede- fined categories. Although these user-generated descriptions enable the de velopment of valuable searching tools for online- shared content [3], they are not alw ays directly adequate for the ef fecti ve management of multimedia content. Indeed, the interoperability of the content descriptions is fundamental to information sharing, exchange and reuse. Therefore, having se- mantic content metadata that is understandable and processable both by machines and humans is crucial. T o address this issue, taxonomies allow to organise and structure concepts. In the audio-related fields they are the first step to wards the classification of sounds into groups based on different subjectiv e or conte xtual properties [4]. Disparate taxonomies have been developed based on subjective similar- ity , sound source or common environmental context. Ho we ver , since sounds are multimodal, multicultural and multifaceted, there is not a common taxonomy that allo ws to organise large and diverse sound collections. Some works proposed taxonomies for en vironmental sounds, based on the interaction of materials [5] or according to their physical characteristics [4]. More recent research on studying soundscapes sho ws that the taxonomical categorisation of environmental sounds is not tri vial and in volv es many different fields, e.g., human perception or urban design [6, 7]. F or musical content, many music genre taxonomies appeared from the Music Industry and its consumers. Y et no standard taxonomy has been established since it depends highly on our cultural contexts. In fact, each distributor has his own strategy to wards its targeted market [8]. Despite all the accomplishment in designing specific tax- onomies, the creation of larger , general-purpose taxonomies has recently gained attention among the research commu- nity [9]. Instead of focusing on the recognition of a specific subset of sounds, general-purpose taxonomies enable tasks that aim to recognise and describe a wider (and usually more generic) range of sounds [10]. Methods to solve these tasks are desirable, for example, in en vironments such as smart buildings or smart cities and more generally in IoT applications. Another application is the automatic description of multimedia content in the context of lar ge online collections like Freesound (https://freesound.org/) [11] or Y outube. This can enable the enhanced or ganisation and retrie val of multimedia content, thus making it more accessible to the public. In these cases, training general-purpose systems with large-vocab ulary audio datasets seems more suitable to be able to describe a wide v ariety of content types. The recently released AudioSet Ontology proposes one of the biggest taxonomies which structures 632 audio-related categories [9]. Rather than being domain-specific, it contains the most common concepts used for describing e veryday sounds. AudioSet has a companion website that includes a web-interface to na vigate through the taxonomy and listen to sound examples, which provides an ov erview of its content (https://research.google.com/audioset/). Sounds are related to many things, such as nature, urban design, music and cul- ture. Consequently , sound related taxonomies are supposed to ev olve and adapt, and it is important for people to understand, use and discuss about them. For this reason, proposing tools and interfaces for browsing taxonomies would lead to vast advancements in the many related fields. Like wise, these tools can assist the annotation of the content in online sharing plat- forms, which w ould facilitate its use for research or multimedia sharing. In this paper , we advance our user-centered design process of proposing general-purpose annotation tools that can be used for annotating all sorts of audio content. W e take advantage of the AudioSet Ontology which provides a hierarchical tax- onomy of very broad acoustic categories. The main goal is to facilitate the exploration and use of predefined categories taken from large taxonomies. In section II, we first explain the context of this work by briefly presenting the current outcome of the Freesound Datasets initiati ve [12], which focuses on the annotation of sounds from the Freesound database. W e then motiv ate the need of two tools for the manual annotation of audio samples. In section III, we describe the two annotation tools we de veloped: one allo ws to add labels to audio samples, and another allows to refine pre viously existing labels. In section IV , we present a preliminary e valuation of the two tools carried out with real users. W e conclude the paper in section V . I I . M OT I V AT I O N S A. Conte xt In previous work [12], the authors describe FSD, a large- scale open audio dataset based on Freesound content annotated with categories drawn from the AudioSet Ontology . Currently , FSD presents annotations that express the presence of a sound category in audio samples. The creation of FSD started with the automatic population of each category in the AudioSet Ontology with a number of candidate audio samples from Freesound. This process automatically generated ov er 600k candidate annotations. T o verify the v alidity of these automatically generated annotations, we de veloped a v alidation tool with an interface that helps users to understand a category and its context in the AudioSet Ontology . This v alidation tool is deployed in the Freesound Datasets platform (https://datasets.freesound.org/). Fig. 1 sho ws the part of the interface used for the familiari- sation of a user with a category . It displays information such as the name, description, sibling and children categories of a specific category . B. Motivating new annotation interfaces This approach produced a considerable amount of an- notations which already helped communities of researchers to in vestigate new machine learning methods [10]. Howe ver , generating annotations automatically presents a number of shortcomings. For instance, an automatic process can generate incorrect or not specific labels, and it can also fail to generate some labels. W e ar gue that the usefulness and reliability of datasets increase with the proximity of its annotations towards what we denote as complete or exhaustive labeling (i.e., all the acoustic material present in the audio file is annotated). T o achie ve this complete labeling status through manual annotation, a number of actions would be required. First, Fig. 1. Screenshot of the familiarisation interface of the Freesound Datasets platform validation task assuming the existence of automatically generated annotations, it would be needed to v alidate them. Then, missing labels should be g enerated , and generic or unspecific labels should be further r efined . The two annotation tools presented in the next section address the two latter issues. I I I . T H E A N N OTA T I O N T O O L S In this section we describe the two novel interfaces that we dev eloped. The code is av ailable at: https://github .com/ MTG/freesound- datasets/tree/annotation- tools- FR UCT2018/. Both tools are implemented mostly with web client languages, which allows their easy integration in other projects. The Audio Commons Manual Annotator (A C Manual Annotator) aims at adding missing labels, whereas the Audio Commons Refinement Annotator (A C Refinement Annotator) allo ws to refine and specify existing labels. These tools can be useful not only to annotate during a post-precessing stage, like in Freesound Datasets, but also to provide annotations when a user publishes content in an online platform such as Freesound. Both of the tools focus on annotating a single sound resource at a time. The audio content is accessible from a player displaying the spectrogram of the sound, which can facilitate the localisation and recognition of sound events in the clip (Fig. 2 & 4) [13]. A. Generate annotations W ith the AC Manual Annotator , labels can be assigned to an audio clip. The main idea behind this interface is to provide a w ay to facilitate the quick overvie w of cate gories. Moreov er , considering the large size of the hierarchical structure in tax- onomies like AudioSet, it is important to show the location and context of the categories within the hierarchy . Another design criteria was to allow the comparison of dif ferent categories by simultaneously displaying their information. In the proposed interface, a text-based search allows to locate categories in the taxonomy table. W e used text from the category names and descriptions to perform some trigram based queries (a feature that Postgres, our database backend, implements). The taxonomy table allows users to open parts of the taxonomy in order to visualise children categories simultaneously . For each cate gory , textual descriptions are sho wn, along with sound examples when av ailable (Fig. 3). Fig. 2. Screenshot of the Audio Commons Manual Annotator Fig. 3. Screenshot of the Audio Commons Manual Annotator taxonomy table, showing the descriptions and examples of Sigh and Groan, together with their hierarchy location A typical use workflow would consist in: • Listen to the sound sample (Fig. 2, top). • Use the text-based search to locate categories in the taxonomy table (Fig. 2). • Explore the taxonomy table to understand well the located cate gory , and perhaps find other more relev ant categories (Fig. 3). Fig. 4. Screenshot of the Audio Commons Refinement Annotator displaying a sound sample and its three suggested label paths Fig. 5. Screenshot of the Audio Commons Refinement Annotator showing a dropdown displaying the children categories of Guitar B. Refine annotations The AC Refinement Annotator displays some previously existing labels as rows, as it can be seen in Fig. 4. The annotator can e xamine their location in the AudioSet hierarchy as well as their siblings and children categories. By making use of the hierarchy , the main goal of this tool is to aid the annotation process by pro viding an iterati ve way of specifying the type or nature of the content. Fig. 5 shows ho w the children categories of the proposed label “Guitar” are displayed in a dropdown, which allows to modify the label and define it more precisely . For e very label, popups show the category description and examples when a vailable (Fig. 6). Moreover , it is possible to duplicate a label using the icon at the top right corner of a label path. This allows, for instance, to specify a label by adding two of its children categories. In the final step of the refinement process, the user is asked to verify the pr esenceness of the selected category in the audio clip. A typical use workflow would consist in: • Listen to the sound sample (Fig. 4, top). • Inspect the proposed labels (Fig. 4). • Refine the proposed labels by inspecting the related siblings and children (Fig. 5 & 6). • V alidate the presence of the proposed or refined cate- gory . Fig. 6. Screenshot of the Audio Commons Refinement Annotator showing the description and examples of the Guitar category in a popup I V . P R E L I M I N A RY E V A L UAT I O N In the context of sound collections annotation, there is a need for proposing new manual interfaces to properly annotate audio content, with labels that are comparable and of the same nature. In this experiment, we present our user -centered design process on the de velopment of no vel tools for annotating audio content from a wide variety of types. W e use the annotator tools as technolo gy pr obes to observe their use in a real conte xt, to ev aluate their functionalities and to inspire new ideas [14]. A. Methodology W e gathered eight participants with different levels of expertise. Each one of them was provided with one of the tools and w as asked to annotate a list of sounds one by one. W e selected sounds from the Freesound Datasets platform featuring one or more of the following aspects: (i) containing multiple sound sources, (ii) presenting background noise or (iii) being hard to recognise. This process resulted in a list of 9 and 15 sounds for the generation and refinement tools re- spectiv ely . Some guidelines were shown to them, together with verbal explanations giv en by the e xaminator . At the end of the task, the y were provided with a questionnaire containing some usability and engagement questions. Finally , semi-structured interviews were carried out, including open-ended questions as well as specific questions related to observ ed beha viors during the development of the task. This enables discussion using thematic analysis in order to identify emerging themes from participants’ answers. B. Results and discussion Finding a category in the taxonomy . It is essential to provide ways for ef ficiently browsing and exploring such an extensi ve set of audio categories. T ext-based search pro vides a way for people to find categories with their own words. This is particularly ef ficient when the annotator recognises the sources and want to quickly add the corresponding audio category to the content. As a w ay to impro ve the retriev al from the text-based search, one participant proposed to add some of the children of the retrie ved categories to the results. This option was tested when developing the search engine, but was discarded because it tended to add a lot of results which made the localisation of the rele vant categories harder . Moreov er , we could also use external lexical resources such as W ordNet or W ikipedia to impro ve system’ s recall, by using synon yms terms and page content terms respectiv ely . Howe ver , text-based search can fail when the annotator is not familiar with the v ocabulary . She can then rely on the hierarchical structure of the categories. Tree visualisations are a direct representation of it, and can help by allowing to iterativ ely define more precise concepts starting from the broader upper lev els of the taxonomy . As well, tables are a natural way for browsing collections of items. The taxonomy table we provided in the A C Manual Annotator aims at com- bining tree and table structures in order to allow efficient and fast exploration of the categories. Moreo ver , locating similar categories close from each other helps to refine and v alidate the choice of a category (especially for categories that are almost identical and differ only in small details). Exploring the taxonomy . The hierarchy structuring the audio related concepts assumes that deep located categories con vey more information that the others. Therefore, it is important to use labels as specific as possible in order to accurately describe the audio content. When using the AC Refinement Annotator , some participants showed interest in seeing all the hierarchy at once. Howe ver , we believ e that the task is facilitated if only the rele v ant context for each step of the iterative process is shown. Specifying labels in an iterativ e fashion (i.e., progressively , such that their meaning is narrowed do wn in e very step) seems to be helpful. It can ease and speed up the generation of accurate labels by focusing on the most relev ant semantic audio aspects. Nonetheless, during the navigation through the different le vels of specificity in the hierarchy , a participant was sometimes not inspecting, or hesitating to check, the children of a category . This occurred due to sev eral reasons: (i) since no sound examples were av ailable in the present category , he assumed this would also be the case in deeper hierarchy lev els. Hence, he decided not to explore this branch due to lack of confidence with it; (ii) he also assumed that since the original cate gory was not appropriate, none of the children would be either (where in fact, one of them was). The A C Manual Annotator mitigates this problem and facilitates quick inspection of the categories, since the children can be automatically displayed when a category is selected in the taxonomy tree. Difficulty in recognising a sound identity . In the context of post-processing annotations of audio content, the annotator is typically not the publisher of the content. Hence, the annotator usually does not know the details of the recording conditions or what sound sources were captured. Furthermore, listening to the sound does not necessarily lead to the identi- fication of the sound source(s) as it can sometimes be a very complex task. Under these circumstances, for the audio content that annotators were not able to recognize, the following be- haviors were observed. When using the AC Manual Annotator, the annotators tended to choose abstract categories that do not con vey the source identity , b ut rather some other aspects of the sound source (e.g., onomatopoeic labels that phonetically imitate, resemble, or suggest the sound it describes). In the A C Refinement Annotator tool, where participants were guided tow ards the identification and specification of the sources, the y usually stopped at a certain hierarchical le vel, thus pro viding some imprecise labels. As e xpected, labels gathered with the generation tool were much more different than those gathered with the refinement tool. One of the reason was that with the A C Manual Annotator tool, users chose dif ferent abstract labels for describing the content, since their exact meaning seems to vary across annotators. T o improve the consistency of the produced labels, it was discussed to giv e access to the metadata that often accompany online shared media, e.g., title, description and tags. These informations can guide annotators on understanding the con- text and providing more accurate annotations. Howe ver , some participants argued that these informations should not be giv en at first. For them, access to metadata should be an additional aid that could be requested only after ha ving spent a certain effort on analysing the audio content. Providing directly the metadata would correspond more to a transcription task, where annotators could focus only on the metadata, and forget some important sound aspects that the metadata fail to conv ey . The annotators’ commitment is highly variable. In addition to the precision of labels, the A C Refinement An- notator also allo ws to explore siblings categories that can sometimes correspond to slightly different concepts. This en- ables correcting the, potentially noisy , automatically generated labels. Howev er, this feature led to variable results in terms of labels produced and time spent annotating. Users of the r efinement annotator spent from 35 minutes to 1h20 annotating 15 sounds. Some participants put a lot of efforts exploring sibling categories in the hierarchy , making them waste time when considering the amount of refined labels (from 23 to 34 labels with a present validation). In contrast, the users of the A C Manual Annotator spent from 25 to 30 minutes performing the task. Finally , it was observ ed that some participants ga ve a lot of importance to category sound examples and children, rather than relying on the name and te xtual description. This presents a risk since, in many occasions, neither the sound examples nor the listed children can be fully representative of a category div ersity and complexity . It is therefore important that the tools promote the utilization of all the av ailable information for annotators to take more solid and reliable decisions. V . C O N C L U S I O N S In this paper we motiv ated the need for nov el interfaces that facilitate the use of categories from large-scale taxonomies when annotating audio content. W e presented the context of the Freesound Datasets initiative, which aims at creating openly av ailable audio datasets. T wo annotation interf aces were presented, which allow to target specific shortcomings when automatically generating labels. A preliminary e valuation with users allo wed to ev aluate our first versions of the tools and engage discussions. Future work should focus on making the tasks faster , and aid the annotators on producing more exhausti ve and consistent annotations. It will include improvements on the design, such as making the sound player more reachable to allow simulta- neous exploration of category examples and comparison with the audio resource being annotated. Simplification of the A C Refinement Annotator task by disabling the exploration of sibling categories in the taxonomy hierarchy . In addition, im- prov ed and more detailed task instructions should be designed, containing specific indications to make users focus on specific sound aspects co vered by the taxonomy . These measures could help annotators to produce more comprehensiv e annotations. A C K N O W L E D G M E N T This work has received funding from the European Union’ s Hori- zon 2020 research and inno vation programme under grant agreement No 688382 “ AudioCommons” and from a Google Faculty Research A ward 2017. The authors thank Lorenzo Romanelli for his help with the development of the annotation tools, and the participants of the ev aluation for the valuable feedback gathered. R E F E R E N C E S [1] Oscar Celma, Perfecto Herrera, and Xa vier Serra. Bridging the music semantic gap. In W orkshop on Mastering the Gap: F r om Information Extraction to Semantic Repr esentation , volume 187. CEUR, 11-06-2006 2006. [2] Olga Russakovsky , Jia Deng, Hao Su, Jonathan Krause, et al. Imagenet large scale visual recognition challenge. International Journal of Computer V ision , 115(3):211–252, 2015. [3] Cameron Marlow , Mor Naaman, Danah Bo yd, and Marc Davis. Ht06, tagging paper , taxonomy , flickr , academic article, to read. In Pr oceedings of the seventeenth confer ence on Hypertext and hypermedia , pages 31–40. A CM, 2006. [4] R Murray Schafer . The soundscape: Our sonic envir onment and the tuning of the world . Simon and Schuster , 1993. [5] W illiam W Gav er . What in the world do we hear?: An ecological approach to auditory event perception. Ecological psycholo gy , 5(1):1–29, 1993. [6] AL Brown, Jian Kang, and Truls Gjestland. T owards standard- ization in soundscape preference assessment. Applied Acoustics , 72(6):387–392, 2011. [7] Justin Salamon, Christopher Jacoby , and Juan Pablo Bello. A dataset and taxonomy for urban sound research. In Pr oceedings of the 22nd A CM international confer ence on Multimedia , pages 1041–1044. ACM, 2014. [8] Franc ¸ ois Pachet and Daniel Cazaly . A taxonomy of musical gen- res. In Content-Based Multimedia Information Access-V olume 2 , pages 1238–1245. Centre de Hautes Etudes Internationale D’Informatique Documentaire, 2000. [9] Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, et al. Audio set: An ontology and human-labeled dataset for audio ev ents. In Acoustics, Speec h and Signal Pr ocessing (ICASSP), 2017 IEEE International Conference on , pages 776–780. IEEE, 2017. [10] Eduardo Fonseca, Manoj Plakal, Frederic Font, Daniel PW Ellis, Xavier Fav ory , Jordi Pons, and Xavier Serra. General-purpose tagging of freesound audio with audioset labels: T ask descrip- tion, dataset, and baseline. arXiv pr eprint arXiv:1807.09902 , 2018. [11] Frederic Font, Gerard Roma, and Xavier Serra. Freesound technical demo. In Pr oceedings of the 21st A CM international confer ence on Multimedia , pages 411–412. A CM, 2013. [12] Eduardo F onseca, Jordi Pons Puig, Xa vier Fa vory , Frederic Font, et al. Freesound datasets: a platform for the creation of open audio datasets. In Proceedings of the 18th International Society for Music Information Retrieval Conference , pages 486–493. ISMIR, 2017. [13] Mark Cartwright, A yanna Seals, Justin Salamon, et al. Seeing sound: Inv estigating the effects of visualizations and complexity on crowdsourced audio annotations. Pr oceedings of the ACM on Human-Computer Interaction , 1(1), 2017. [14] Hilary Hutchinson, W endy Mackay , Bo W esterlund, Benjamin B Bederson, et al. T echnology probes: inspiring design for and with families. In Pr oceedings of the SIGCHI conference on Human factors in computing systems , pages 17–24. ACM, 2003.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment