대규모 음향 분류 체계 활용 수동 라벨링 지원 도구
본 논문은 AudioSet과 같은 방대한 계층형 음향 분류 체계를 이용해 일상 소리를 수동으로 라벨링하기 위한 두 가지 웹 기반 도구, “Audio Commons Manual Annotator”와 “Audio Commons Refinement Annotator”를 설계·구현하고, 8명의 실제 사용자를 대상으로 예비 평가를 수행하였다. 텍스트 기반 검색, 계층 테이블·드롭다운 UI, 스펙트로그램 시각화 등을 결합한 인터페이스가 라벨 탐색·추가·세…
저자: Xavier Favory, Eduardo Fonseca, Frederic Font
본 논문은 일상 소리와 온라인 음원 컬렉션을 대상으로, 방대한 계층형 음향 분류 체계인 AudioSet Ontology를 활용한 수동 라벨링 작업을 지원하기 위한 두 가지 웹 기반 도구를 설계·구현하고, 실제 사용자들을 대상으로 예비 평가를 수행한 연구이다. 서론에서는 멀티미디어 검색·인식 분야에서 정확한 메타데이터의 중요성을 강조하고, 기존 자동 라벨링이 갖는 ‘정확도·세분화 부족’ 문제를 지적한다. 특히, 소리의 문화·맥락적 다양성으로 인해 통일된 표준 분류 체계가 부재한 상황에서, 대규모 일반 목적 온톨로지(AudioSet)의 활용 가능성을 제시한다.
관련 연구 파트에서는 Freesound Datasets 프로젝트에서 자동으로 생성된 60만 건 이상의 후보 라벨을 검증하기 위해 개발된 ‘검증 도구’를 소개한다. 이 도구는 카테고리 이름·설명·형제·자식 정보를 테이블 형태로 제공해 사용자가 특정 라벨의 의미와 위치를 파악하도록 돕는다. 그러나 자동 라벨링은 오류·불명확 라벨을 포함하고, 누락 라벨을 생성하지 못한다는 한계가 있다. 따라서 라벨의 ‘완전·포괄적’ 표기를 목표로, 두 가지 새로운 인터페이스를 개발하였다.
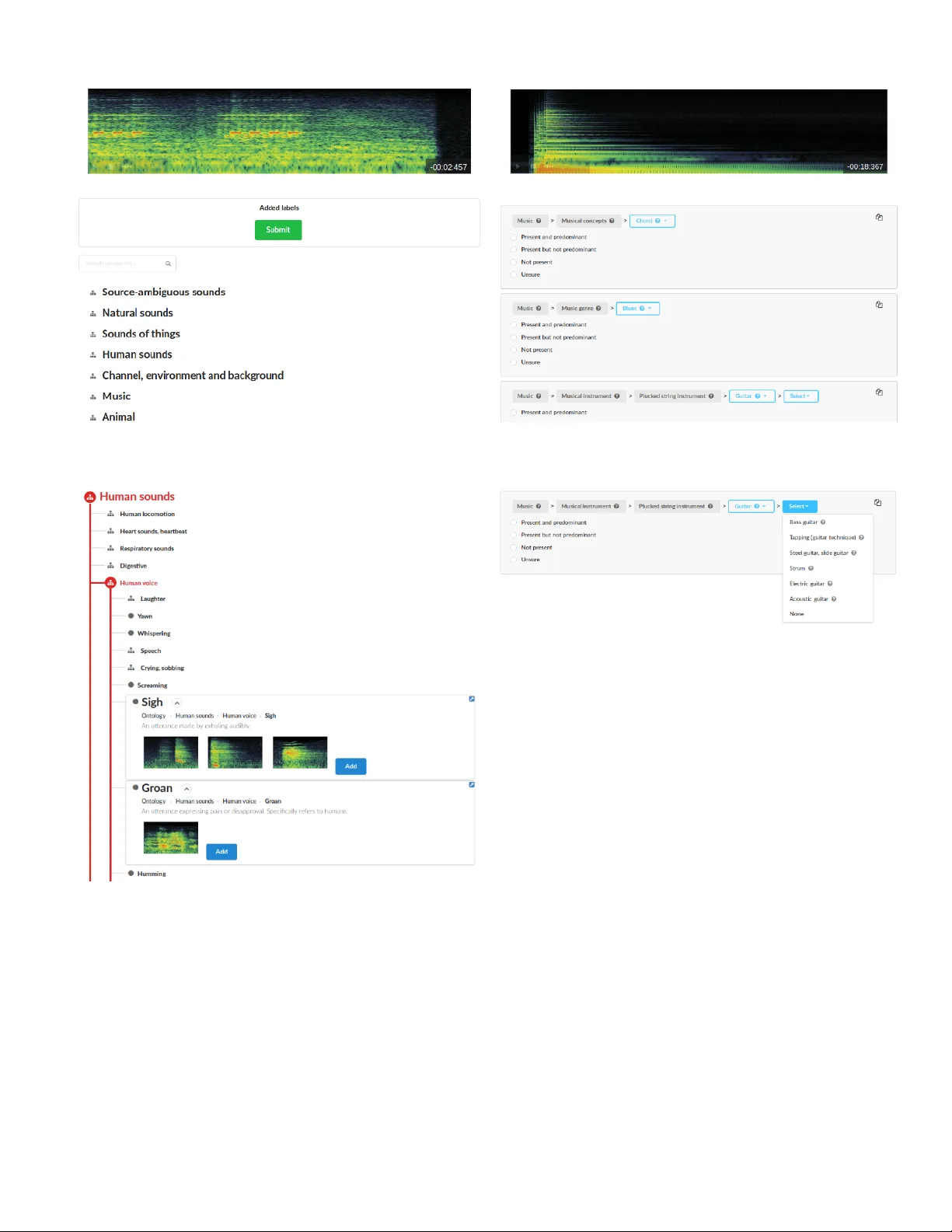
첫 번째 도구, Audio Commons Manual Annotator(AC Manual Annotator)는 사용자가 음원을 청취하면서 텍스트 기반 검색을 통해 원하는 카테고리를 찾고, 트리·테이블 형태의 계층 구조를 확장해 상세 설명·예시 음성을 확인하도록 설계되었다. 검색 엔진은 PostgreSQL의 trigram 인덱스를 활용해 부분 일치를 지원하며, 카테고리 선택 시 자동으로 자식 노드를 표시해 탐색 효율을 높인다. UI는 스펙트로그램 시각화와 재생 컨트롤을 포함해 소리 이벤트의 위치를 파악하도록 돕는다.
두 번째 도구, Audio Commons Refinement Annotator(AC Refinement Annotator)는 기존에 부여된 라벨을 보다 구체적인 하위 카테고리로 세분화하는 작업에 초점을 맞춘다. 각 라벨은 행으로 표시되며, 드롭다운 메뉴를 통해 자식 카테고리를 선택할 수 있다. 팝업 창에서는 카테고리 설명과 예시 음성을 제공해 의미적 차이를 직관적으로 판단하게 한다. 라벨 복제 아이콘을 통해 동일 상위 카테고리의 여러 자식을 동시에 지정할 수 있어 복합 음원 라벨링이 가능하다. 최종 단계에서는 사용자가 선택한 라벨이 실제 음원에 존재하는지 확인하도록 설계돼 있다.
평가 방법으로는 8명의 참가자를 두 그룹으로 나누어 각각의 도구를 사용하게 했으며, 총 24개의 음원을 대상으로 라벨링 작업을 수행했다. 참가자들은 라벨링 전후에 시스템 사용성 설문(SUS)과 참여도 질문에 답했으며, 작업 종료 후 반구조화 인터뷰를 진행해 경험을 심층적으로 탐색했다. 분석 결과는 다음과 같다.
1. **텍스트 검색 효율성**: 사용자가 익숙한 용어를 입력하면 빠르게 카테고리를 찾을 수 있었지만, 전문 용어나 동의어가 부족하면 검색 결과가 부정확하거나 과다하게 나타났다. 일부 참가자는 검색 결과에 자식 카테고리를 포함시키면 도움이 될 것이라 제안했지만, 실제 구현에서는 결과가 과도하게 늘어나 탐색이 어려워졌다. 향후 WordNet·Wikipedia와 같은 외부 어휘 자원을 활용해 검색 리콜을 향상시킬 필요가 있다.
2. **계층 시각화와 테이블 결합**: 트리와 테이블을 결합한 계층 테이블은 유사 카테고리를 나란히 비교하고, 선택된 카테고리의 자식을 즉시 확인할 수 있게 해 사용성이 높았다. 그러나 전체 계층을 한 번에 보여줄 경우 복잡도가 급증해 사용자가 혼란스러워했으며, 단계별로 관련 컨텍스트만 노출하는 점진적 확장이 더 효율적이었다.
3. **라벨 세분화 과정**: Refinement Annotator를 사용할 때 일부 참가자는 상위 레벨에서 멈추어 불명확한 라벨을 남겼다. 이는 자식 카테고리의 예시 음성이 제공되지 않을 경우, 해당 하위 카테고리의 존재감을 인식하지 못하기 때문이다. 따라서 모든 레벨에 예시 음성을 연결하거나, ‘예시 없음’ 표시를 명확히 해 사용자의 탐색 의지를 유지시켜야 한다.
4. **소리 정체성 인식 어려움**: 라벨링 대상이 익숙하지 않은 소리일 경우, 참가자들은 추상적이거나 의성어적 라벨(예: “삐걱”, “우웅”)을 선택하는 경향을 보였다. Manual Annotator에서는 이러한 추상 라벨이 많이 생성되었으며, Refinement Annotator에서는 상위 라벨에서 멈추는 현상이 관찰되었다. 이는 라벨링 정확도를 높이기 위해 청취 보조(스펙트로그램 확대, 구간 반복 재생)와 라벨 후보 자동 제시 기능을 보강해야 함을 시사한다.
5. **다중 라벨 복제 기능**: 복합 음원(예: “기타+배경 소음”)에 대해 라벨을 복제하고 각각의 자식을 선택하는 방식이 유용했지만, UI가 복잡해지는 단점이 있었다. 직관적인 아이콘 디자인과 단계별 가이드라인을 추가하면 사용 효율을 더욱 향상시킬 수 있다.
결론에서는 두 도구가 대규모 음향 온톨로지를 활용한 수동 라벨링의 진입 장벽을 낮추었으며, 사용자 피드백을 통해 검색·시각화·청취 보조 기능을 개선할 구체적 방향을 제시한다. 향후 연구 과제로는 자동 라벨 제안 모델과의 연동, 대규모 사용자 베타 테스트, 그리고 라벨링 작업 흐름을 지원하는 협업 플랫폼 구축이 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기