A Scalable Pipelined Dataflow Accelerator for Object Region Proposals on FPGA Platform
Region proposal is critical for object detection while it usually poses a bottleneck in improving the computation efficiency on traditional control-flow architectures. We have observed region proposal tasks are potentially suitable for performing pip…
Authors: Wenzhi Fu, Jianlei Yang, Pengcheng Dai
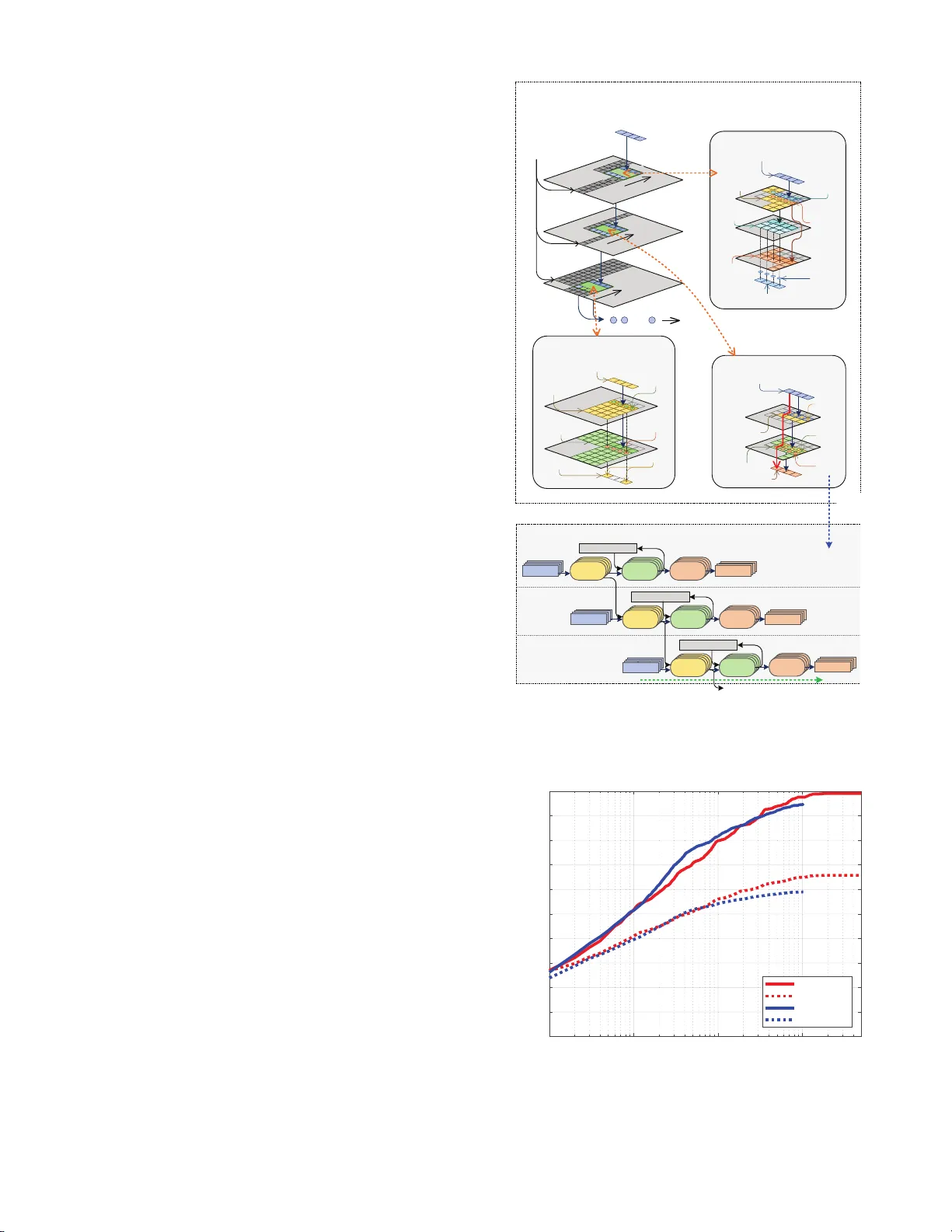
A Scalable Pipelined D at aflow Accelerator for Object Region Pr oposals on FPGA Platform ∗ W enzhi F u 1,3 , Jianlei Y ang 1,3 , Pengc heng Dai 2,3 , Yiran Chen 4 and W eisheng Zhao 2,3 1 School of Computer Science and Engineering, Beihang U niversi ty , Beijing, 100191, China. 2 School of Electronic and Information Engineering, Beihang Un ivers ity , Beijing, 100191, China. 3 F ert Beijing Researc h In stitute, BDBC, Beihang Universit y , Beijing, 100191, China. 4 Department of Electrical and Computer Engineering, Du ke Universi ty , Durham, NC 27708, USA. { jianlei, weisheng.zhao } @buaa.edu.cn ABSTRA CT Region prop osal is critical for ob ject detection while it usually p oses a b ottlenec k in improving the computation efficiency on traditio nal con trol-flo w arc hitectures. W e hav e observed region p roposal tasks are potentiall y suitable for performing pip elined paral lelism by exploiting dataflo w driv en acc elera- tion. In this p aper, a scalable pip elined dataflow accelerator is prop osed for efficient region prop osals on FPGA platform. The accelerator pro cesses image d ata by a streaming manner with three sequen tial stages: resizing, k ernel compu ting and sorting. First, Ping-Pong cache strategy is adopted for rota- tion loading in resize mo dule to guarantee continuous output streaming. Then, a multiple pipelines architecture with tiered memory is utilize d in k ernel compu t ing module to complete the main comput ation tasks. Finally , a bubble-p ushing heap sort metho d is exploited in s orting mo dule to fin d th e top- k largest cand idates efficiently . Our design is implemented with high level syn thesis on FPGA platforms, and experimental re- sults on VOC2007 datasets sh ow that it could ac hieve ab out 3.67X sp eedup s than traditional desktop C PU platform and > 250X energy efficiency improveme nt than e mbedded ARM platform. Keyw ords Scalable pip eline, Dataflow accelera tor, Region proposal, FPGA platform, Streaming pro cessing 1. INTR ODUCTION Recent years, deep n eural netw orks hav e made a great suc- cess in image classification tasks of single ob ject [ 1 ]. How - ever, it can not b e d irectly app lied to multi-ob ject detection, whic h is m uch more practical in real-worl d applications [ 2 , 3 ]. Ob ject detection first decides t h e interested regions whic h p o- tential ly include ob jects (so-called region prop osal) and then p erforms image cla ssification on these proposed re gions. Ef- ficient real-time ob ject detection is a prerequ isite for many kinds of unmann ed systems since th e energy efficiency of in- tensive computation is critical for them. There hav e b een many researc h works fo cused on hardware acceleration for im- ∗ This work was supp orted in part by the National Natural Science F oundation of China (61602022, 6150101 3, 61571023, 6152109 1 and 11570403 29), National Key T ec hnology Pro- gram of China (N o. 2017ZX0103 2101) and the 111 T alent Program B16001. age classi fication [ 4 ] but no one designed for region prop osals, whic h hav e p osed a b ottleneck in efficient ob ject detection. Recently sev eral computationally intensiv e approaches ha ve sho wn a b etter p erformance [ 5 ], how ever, it is n ot practical for them running on em bed ded platfor m with limited resources and restricted p ow er consumption. On t he other hand, bi- narized normed gradients (BING) meth od is prop osed as an effective approach for reg ion p roposal g eneration [ 6 , 7 , 8 , 9 ], whic h achiev es state-of-the-art detection rate. How ever, even though there hav e already b een several tec hniques to opti- mize the implementation of BING algorithm on CPU[ 6 ], due to t he control-flo w p rocessing style of V on Neumann architec- ture, it is still difficu lt fo r BING to run efficiently esp ecially in em b edded platform. In t h is work, a scalable dataflow accelera tor is prop osed for the BING algor ithm who has b een reformed to a dataflow- driven manner. With the memory hierarc hy , this efficiency of the streaming pro cessing can b e highly improv ed which o ver- comes the shortages of t he traditional p latform. F urthermore, this accelerator has a goo d scalabilit y t o b e scaled to a larger parallelism efficiently without the problem of synchronization. The main contributions of this w ork are listed as follo wing: (1) The BING algorithm is reformed as a dataflow-driv en manner t o obtain significant b enefits f rom dataflo w pro- cessing. (2) A dataflow arc hitecture is prop osed for the BING algo- rithm, whic h generate a contin ues inpu t stream th en pro- cess it in a streaming manner to fully deploy ed the lo calit y and minimized the intermediate data amount. 2. REGION PR OPOSAL WITH BING The aim of region prop osal is t o find the interested regions whic h p otenti ally contai n ob jects with minimized wind ows, whic h is imp ortant in multi-ob ject d etection tasks. Previous w orks [ 6 , 7 ] ha ve sh o wn that a simple 8 × 8 f eature by com- puting th e n ormed gradients could b e adopted as an efficient region prop osal. After b inarizing the normed gradien ts fea- ture, BING could achiev e efficient ob jectness estimation. The original image is first res ized to different sizes with differen t preset resizing ratios, therefore, the region p roposal candi- dates with different resolution in the orig inal image can be represented with 8 × 8 wi ndow uniformly in the resized im- ages. Then, the SV M (Sup p ort V ector Machine) stage I is adopted to ev aluate th e confidence for eac h region proposal. resize module kernel computing module Grad NMS heap sort-I heap sort-II SVM-II post. SVM-I img. (a) A ccelerator framew ork Per . 0 Pe r. 1 Per . 2 Grad SVM -I N M S Grad SVM - I Grad Ċ Ċ bat c h ban k bat c h orde r ban k orde r es iz e od u le erne l om put ing odu le r a d N M S e a p or t e a p or t I I S V M I I p r o p S V M im g (b) Pip elined kernel computing driven by resized im- ages Figure 1: D emonstration of our prop osed accelerator. F ollo wing that, the NMS (non-maximum sup pression) stage is utilized to red u ce the ov erlap among the prop osals. After that, t op- n larg est candidates are selected from the region prop osals correspondin g t o each resized image an d t he S V M stage I I is p erformed t o ev aluate the confidence among all of th e resized images. Finally , th e top- k lar gest candidates could b e obt ained as final prop osals by a sorting stage. Since the BIN G algorithm has few b ranc h or jump op erations, it could b e abstracted as a data-driven algorithm which is ideal to p erform dataflow driven acceleration. 3. PR OPOSED DA T AFLO W A CCELERA T OR 3.1 Accelerator F ramework Corresponding to the computation process of BING algo- rithm, the framework of the prop osed d ataflo w accelerator sho wn in Fig. 1(a) can also be divided into resizing mo dule, kernel compu ting mo dule and sorti ng module. The function of each mo dule is same as the corresp onding compu t ation in the algorithm but can b e completed in a different manner. As sho wn in Fig. 1(a) , the resizing mo dule first resize th e original image with preset ratios then partition the resized image in to a series of batch, which represent for four neigh b or pixels v er- tically . The follo wing kernel computing mod ule w orks in t h e gran ularity of batc h and can be divided into three stages: Cal- cGrad, SV M and NMS op erations, which can pro cess the con- tinuously batch streaming w ith a parallel pipelines arc hitec- ture and ex p orts a stream of candidates. The sorting mo dule is deigned to obtain the top- k or top- n candidates by perform- ing b ubble-pushing heap sort strategy to satisfy the through- put requirements. Finally , the region prop osals could b e ob- tained af ter post processing. Without los s of generality , the kernel computing module is demonstrated by four pip elines in this pap er whic h could b e extend ed as more pipelines as follo wing. And the bubble-p ushing heap sort model is very similar to [ 10 ] which is to o trivial to b e listed h ere. 3.2 Resi zing Module A naive resizing approach is carried out in [ 11 ] but it cannot satisfy our requiremen ts for streaming pro cessing. The kernel computing m o dule requires a con tinuous batch streaming out- put from resizing mo dule to make sure th e multiple pip elines are fully loaded. I n this w ork, the original image is parti- tioned in to four b locks uniformly a s sho wn in Fig . 2 . Only one p ort of the configured BRA Ms is assigned for each blo ck part1 part2 part3 part4 worker I worker II worker III worker IV 1 57 2 58 Ă Ă block0 3 59 4 60 Ă Ă block1 5 61 6 62 Ă Ă block2 7 63 8 64 Ă Ă block3 4 9 1 1 7 3 3 5 2 1 3 7 5 3 5 1 3 1 9 3 5 7 2 3 3 9 5 5 65 81 69 85 67 83 71 87 resized image 5 3 1 7 21 17 19 23 35 33 37 39 53 51 49 55 29 5 13 27 3 19 25 17 9 1 11 21 7 15 23 31 61 37 45 53 39 47 55 63 59 35 51 43 57 49 41 33 30 6 14 28 4 20 26 18 10 2 12 22 8 16 24 32 62 38 46 54 40 48 56 64 60 36 52 44 58 50 42 34 77 69 71 79 75 67 73 65 78 70 72 80 76 68 74 66 85 87 83 81 86 88 84 82 1st cycle 4th cycle 3rd cycle 2nd cycle Figure 2: Illustration of resizing mo dule. cache lane 0 worker I load 1 load 17 load 33 load 49 worker II load 19 load 35 load 51 load 3 worker III load 37 load 53 load 5 load 21 worker IV load 55 load 7 load 23 load 39 export 65 81 97 113 export 67 83 99 115 export 69 85 101 117 export 129 145 161 177 w o r k e r I w o r k e r I I w o r k e r I I I w o r k e r I V worker I w o r k er I I w o r k er I I I worker I V load 129 load 145 load 161 load 177 load 147 load 163 load 179 load 131 load 165 load 181 load 133 load 149 load 183 load 135 load 151 load 167 export 1 17 33 49 export 3 19 35 51 export 5 21 37 53 export 7 23 39 53 worker I worker II worker III worker IV load 83 load 99 load 115 load 67 load 101 load 117 load 69 load 85 load 119 load 71 load 87 load 103 load 65 load 81 load 97 load 113 w o r k e r I w o r k e r I I w o r k e r I I I w o r k e r I V worker I w o r k er I I w o r k er I I I worker I V load 193 load 211 load 229 load 247 export 71 87 103 119 cache lane 1 Figure 3: Contin uous batch streaming with Ping-Pong cac he. while tw o dual-p ort or four single -p ort BRAM are required for pro cessing eac h image. The pixels from four blo cks are fetc hed in parallel as pro cessed by four w ork ers. Since the fetc hed pixels from different blocks are discontin uous, a Ping- P ong cache, which consists of tw o cache lanes, is adopted here for buffering. Meanwhile , the cache is also partitioned as four parts which correspond t o the four BRA M p orts. The fetch- ing pro cedure loads the pixels in different blocks by a rotation style and feeds th em to d ifferen t part of cache. A s shown in Fig. 3 , tw o group s of work ers on tw o cache lanes could alter- nately provide contin uous batch streaming with Ping-Po ng cac he strategy . 3.3 Kernel Computing Module The kernel computing module includes Cal cGrad, SVM-I and NMS stage. First, we defi n e a distance in RGB colo r space b etw een pix el P a and P b as D ( P a , P b ) = max q ∈ { R,G,B } | P a ( q ) − P b ( q ) | The gradients on vertical d irection and horizon direction are defined as I x ( i, j ) and I y ( i, j ), resp ectively , where i and j represents the pixel lo cation. They could b e obtained by cal- culating the normed gradient b etw een n eigh b or p ixels I x ( i, j ) = D P ( i − 1 ,j ) , P ( i +1 ,j ) I y ( i, j ) = D P ( i,j − 1) , P ( i,j +1) and the gradient of each p ixel G ( i, j ) could b e calculated by G ( i, j ) = min { I x ( i, j ) + I y ( i, j ) , 255 } The obtained normed gradient of eac h pixel is reformulated as a tw o-dimension arra y . In the SVM-I stage, the normed gradients G 8 × 8 of every 8 × 8 window are formed by the gradients G 1 × 8 of each row and reshaped as a 64-dimension feature with a row-wis e manner. Then th e trained SVM weigh ts W S V M are adopted to p erform the classification and determine th e eva luation scores of each windo w s = G 8 × 8 · W S V M And all the scores s comp ose a tw o-dimensional array S . Dur- ing the NMS stage, th e max score max 5 × 5 for each 5 × 5 blo c k of S is determined by finding t h e max score max 1 × 5 for each ro w first and then maximum of them. F or all 5 × 5 blocks, only the window corresp onding to max 5 × 5 will b e selected for windo ws sequen ce outp ut. A rough approach to p erform CalcGrad, SV M-I and NMS tasks usually req u ires a temp oral tw o-dimensional arra y for intermedia te data buffering whic h can res ult in w aste of re- sources and computation cycles. In o ur design, these stages are reform ulated and delivere d on multiple pip elines for stream- ing processing as shown in Fig. 4 . Each o f the th ree stages has its own wo rkspace with its own p ipelines which p erforms operations in a streaming manner, and can b e conn ected seri- ally for pro cessing b atc h streaming continuously . Meanwhile, the data lo cality in eac h workspace is exploited by t he t iered cac he, whic h is b uilt with memory window and line bu ffer[ 12 ], by caching all the requ ired data fo r batc h p ass syn c hroniza- tion. Since the pip elines b ehav e similarly , the SVM-I stage is taken for pip elines illustration as an example without loss of generalit y . As sho wn in Fig. 4 , the input batch streaming can b e pro cessed conti nuously by the pip elines and consequently generate a streaming ou t put for the follow ing stage. Du ring the processing of e ach workspace, the d ata are con tinuously loaded from tiered cac he for th e calculation of G 8 × 8 , while the calculation results are restored t o the tiered cache for the next op eration sim ultaneously . At the end of the kernel computing modu le, the NMS oper- ation usually results in n on-contin uous output streaming. In this work, a FIFO structure is adopt ed as streaming buffer to make sure the pip elines run smoothly which could improv e the total efficiency of the prop osed accelerator. 4. EXPERIMENT AL RESUL TS 4.1 Experiment Setup The proposed accelerator is implemented by C language and synthesized with X ilinx Viva do HLS 2017 [ 13 ] on t w o target chips: Artix-7 (low voltage versio n) @ 3.3MHz for alwa y s-on & lo w p ow er application, and Kintex U ltraScale+ @ 100MHz for real-time & high p erformance app lication. A carefully quantization strategy is adopted to sp ecify v arious bit-width for different data storage p urp ose. The synthesized resources utilizations are illustrated in T able 1 . The p ow er consumption and system latency is obtained by C-R TL co-simulation in Viv ado. The VOC200 7 datasets [ 14 ] are adopted to ev aluate the quality of prop osed windows on the metrics by detection rate (DR v.s. #WIN), and mean avera ge b est o verlap (MABO v.s. #WIN), where #WI N is the num b er of given prop osals. The metric DR v .s. #WIN means the detection rate (DR) for the given #WIN proposals [ 6 ]. And M ABO v.s. #WIN means the mean av erage b est ov erlap for the giv en #WIN prop osals [ 7 ]. H ence, a l arger DR or MABO v alue means a b etter prop osal quality . 4.2 Perf ormance Evaluation A defined IoU (intersection-o ver-union) parameter in the previous works [ 7 ] is also adopted in our ev aluation. It is a scoring function to measure the affinity of tw o b ounding batch 0 batch 1 batch 2 c a l c G r a d 8 x 8 G r a d c a l c G r a d 1 x 8 c a l c s s G r a d c a l c G r a d 1 x 8 c a l c G r a d 8 x 8 c a l c s s G r a d c a l c G r a d 1 x8 c a l c G r a d 8 x8 c a l c s s Grad calc Grad 1x8 calc Grad 8x8 calc s s tiered cache c a l c G r a d 8 x 8 G r a d c a l c G r a d 1 x 8 c a l c s s G r a d c a l c G r a d 1 x 8 c a l c G r a d 8 x 8 c a l c s s G r a d c a l c G r a d 1 x 8 c a l c G r a d 8 x 8 c a l c s s Grad calc Grad 1x8 calc Grad 8x8 calc s s tiered cache c a l c G r a d 8 x8 G r a d c a l c G r a d 1 x 8 c a l c s s G r a d c a l c G r a d 1 x 8 c a l c G r a d 8 x 8 c a l c s s G r a d c a l c G r a d 1 x 8 c a l c G r a d 8 x 8 c a l c s s Grad calc Grad 1x8 calc Grad 8x8 calc s s tiered cache Pipeline diagram of SVM-I workspace pixel memory window of I y tiered cache of I x calc I y calc I x tiered cache of pixel calc G Grad CalcGrad workspace s memory window of S tiered cache of max 1x5 s calc max 1x5 calc max 5x5 select NMS workspace … to sort module line buffer slide slide slide from resize module batch pass batch pass batch pass calc s calc G 8x8 calc G 1x8 Grad memory window of G 1x8 tiered cache of G 8x8 s SVM-I workspace Demonstration of kernel computi ng module pipeline diagram Figure 4: Demonstration of ke rnel computing module with the diagram of SVM-I pip eline. 10 0 10 1 10 2 10 3 Number of object proposal windows (#WIN) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 DR / MABO Proposals Quality Comparison BING-DR BING-MABO FPGA-DR FPGA-MABO Figure 5: Q u alit y ev aluation of windo ws prop osals by co m- paring BING [ 6 ] and our prop osed FPGA accelerator. b o xes, defined by the interse ction area of t w o bound ing b oxes divided b y t h eir un ion. The D R and MABO metrics are mea- sured b y v arying the IoU o verla p threshold whic h is set as 0 . 4 as default for correct detection. T able 1: The FPGA resources utilizations comparison b e- tw een tw o target devices: Artix-7 and Kintex UltraScale+. Resources Artix-7 Low V olt. † @ 3.3MHz Kintex UltraScale+ ∗ @ 100MHz Av ailable Utilized Avai lable Ut ilized LUT 63400 54453 162720 56504 LUT-RAM 19000 4166 99840 3157 FF 126800 48611 325440 50079 BRAM 135 135 360 146 DSP 240 25 1368 25 BUF-G - - 256 8 † T argeted on A rtix-7 (lo w voltage ) xc7a100tlftg256-2L. ∗ T argeted on K intex UltraScale+ xcku3p-ffv a676-3-e. The detection accuracy of our prop osed accelerator is com- pared with BIN G [ 6 ] as shown in Fig. 5 . The BIN G algorithm generates 5000 ob ject windows t o ev aluate the accuracy . How- ever, we ha ve observed it only achiev es less than 3% accuracy impro vemen t compared with only 1000 ob ject windo ws g en- erated. H ence, only 1000 ob ject window s are prop osed in our design when considering th e si gnificantly increas ing require- ments on hardware resources. F or ev aluating 1000 propos- als, the detection rate of our prop osed approac h (denoted as FPGA-DR) is ab out 94 . 72% while BIN G is ab out 97 . 63%. T able 2: S p eed u p and p ow er efficiency compared with Intel i7 and AR M platforms. Kintex UltraScale+ Artix-7 Low V olt. Sp eedup P ow er efficiency Sp eedup P ow er efficiency Intel i7 3.67X > 220X 0.12X 66X ARM A53 68X > 250X 2.2X > 60X T able 3: P erformance ev aluation betw een targeted on Artix-7 and Kintex UltraScale+, where P tot is the total pow er con- sumption whic h includ es static p ow er and dynamic p ow er con- sumption, and P dy n is the dynamic p ow er consumption. Artix-7 Low V olt. @ 3.3MHz Kintex UltraScale+ @ 100MHz P tot P dy n Sp eed P tot P dy n Sp eed 97 mW 15 mW 35 f ps 821 mW 350 mW 110 0 f ps The implemented FPGA accelerators are compared with tw o con ven tional CPU platforms. T he BING algorithm is w ell-optimized and could achiev e a p roposal sp eed by 300 f p s on In tel i7-3940XM CP U (TDP: 55W) platfo rm with multi- threaded programming and subw ord p aralleli sm tec hniqu es [ 6 ]. W e also ev aluate BING on a Raspb erry- Pi 3B plat- form with 64-bit ARM A53 pro cessor, which could achiev e 16 f ps sp eed and 3W ∼ 4W [ 15 ] p o we r consump tion. How ev er, the prop osed accelerator on Kintex UltraScale+ target could ac hieve a proposal sp eed by 1100 f ps while the p ow er con- sumption is only 821 mW when running at 100MHz, whic h is applicable for real-time pro cessing of multi-camera sen- sor fusion app lications. H ence, it could a chiev e ab out 3.67X sp eed ups and > 220X energy efficiency improv ement compared with BING on I ntel i7 CPU. F urt h ermore, the prop osed ac- celerator targeted on lo w voltag e Artix-7 could achiev e 35 f p s with an extremely low p ow er consumption 97 mW when run- ning at 3.3M Hz, whic h is attractiv e for ultra-lo w pow er ap- plications with alw a ys-on w orkin g mod e w hose speed i s also sufficient for most of th e applications. The detai led compar- ison results of our prop osed FPGA accelerators against the tw o CPU platforms are show n in T able 2 . 5. CO NCLUSIONS Efficien t region prop osal generation is a critical task for ob - ject detection. A scalable dataflow accelera tor is prop osed in this pap er for efficient region prop osals on FPGA plat- form. The prop osal pro cedures in BING algorithm are re- form ulated as a dataflow driven manner and imp lemen ted on multiple pip elines architecture. All of the mo dules in the ac- celerator a re orga nized b y streaming processing mec hanisms so t hat these streaming data could guarantee the p ipelines are fully loaded. F urthermore, a tiered cac he sy stem is utilized to impro ve the bandwidth of data synchronization b etw een dif- feren t pro cessing stages. Ev aluations on V OC2007 datasets sho w that our prop osed accelerator ac hieves a very large scale of speedu ps and energy efficiency impro v ement with a little detection rate degradation. 6. REFERENCES [1] Alex Krizhevsky et al. Imagenet classification with deep con v olutional neural net works. In A dvanc es in NIPS , pages 1097–110 5, 2012. [2] Ziming Zhang et al. Group membership prediction. In Pr o c e e dings of the IEEE ICCV , pages 3916–3924, 2015. [3] Gregory Casta ˜ n´ on et al. Efficien t activity retriev al through seman tic graph queries. In Pr o c e e dings of the 23r d ACM Multime dia , pages 391–400, 2015. [4] Joel Emer et al. T utorial on hardware arc hitectures for deep neural netw or ks. http://eyeriss.mit.ed u/tutorial.html , 2016. [5] W ei Liu et al. Ssd: Single shot multibox dete ctor. In Pr o c e e dings of ECCV , pages 21–37, 2016. [6] Ming-Mi ng Cheng et al. BING: Binarized normed gradient s for ob j ectness estimation at 300fps. In Pr o c e e dings o f the IEEE CVPR , pages 3286–3293, 2014. [7] Ziming Zhang et al. Sequen tial optimization f or efficien t high-quality ob ject prop osal generation. IEEE TP AMI , 2017. [8] Y unc hao W ei et al. Hcp: A flexible cnn framework f or multi-label image classification. IEEE TP AMI , 38(9):1901 –1907, 2016. [9] Shengxin Zha et al . Exploiting image-trained cnn arc hitectures for unconstrained video classification. BMVC , 2015. [10] W o jciech M Zab o lotn y . Dual por t memory based heapsort implement ation f or FPGA. Pr o c e e dings of SPIE , 2011. [11] Nitish Kumar Sriv asta v a et al. Accelerating F ace Detection on Programmable SoC Usi ng C-Based Syn thesis. In Pr o c e e dings of ACM/SI GDA FPGA , pages 195–200, 2017. [12] F ernando Martinez V allina. Implementing memory structures for video pro cessing in the Vi v ado HLS tool. XAPP793 (v1. 0), Septemb er , 20, 2012. [13] Xilinx Inc. Viv ado HLx 2017. https://www.xilinx.c om/pr o ducts/design-to ols/vivado.html . [14] Mark Everingham et al. The P ASCAL Visual Ob ject Classes Challenge 2007 (VOC2007) Results. http://www.p asc alnetwork.or g/chal lenges/VO- C/vo c2007/workshop /index.html . [15] Raspberr y Pi Po wer Consumption Benchmarks . https://www.p idr amble.c om/wiki/b enchmarks/p ower- c onsump tion .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment