FPGA 기반 객체 영역 제안을 위한 확장 가능한 파이프라인 데이터플로우 가속기
본 논문은 BING 알고리즘을 데이터플로우 방식으로 재구성하고, 이미지 리사이징·핵심 연산·정렬 3단계를 스트리밍 파이프라인으로 구현한 FPGA 가속기를 제안한다. Ping‑Pong 캐시를 이용한 연속 배치 스트리밍, 다중 파이프라인·계층 메모리를 활용한 커널 연산, 버블‑푸싱 힙 정렬을 통한 Top‑k 추출을 통해 저전력 Artix‑7 및 고성능 Kintex UltraScale+ 보드에 구현했으며, 기존 i7 CPU 대비 3.67배 가속, A…
저자: Wenzhi Fu, Jianlei Yang, Pengcheng Dai
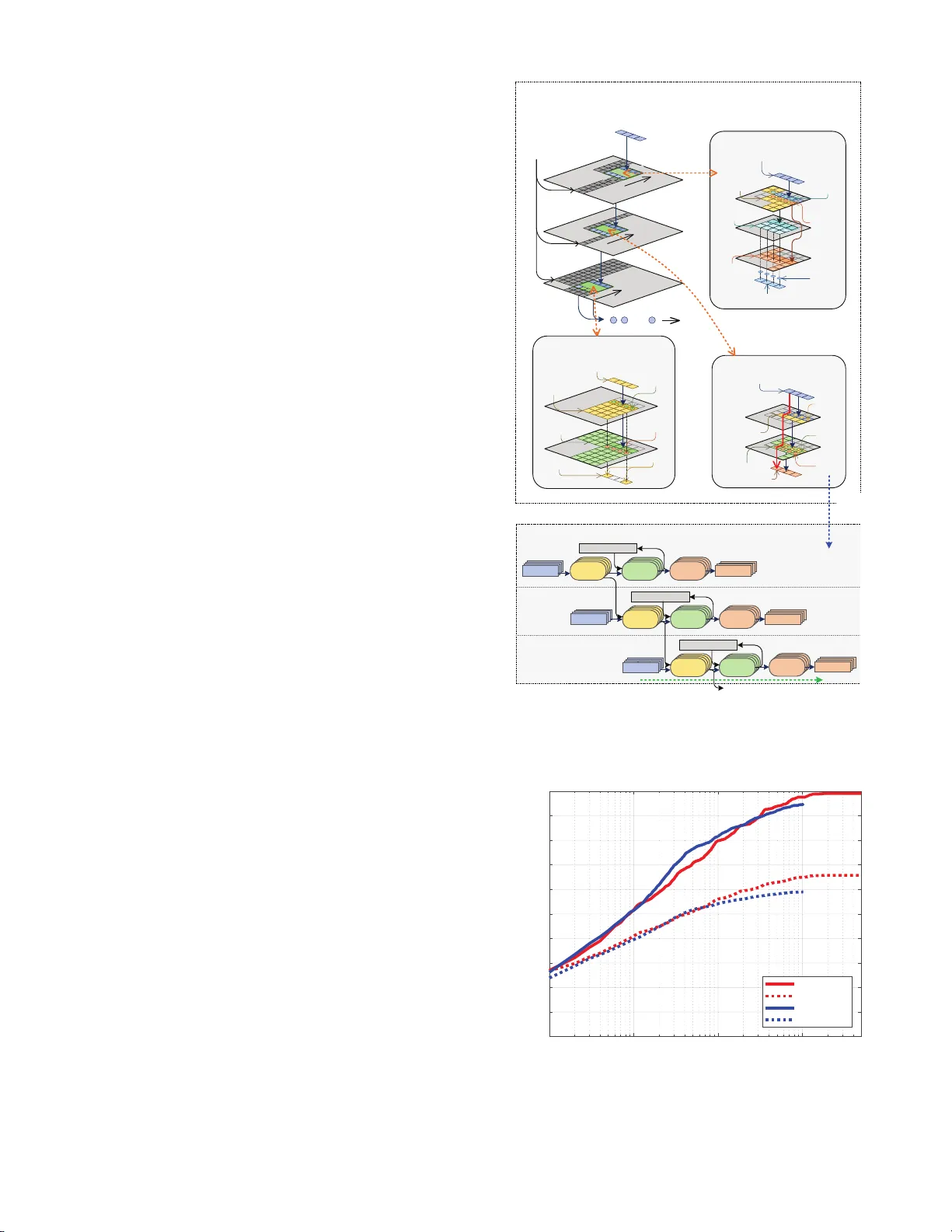
본 논문은 객체 검출 시스템에서 핵심적인 전처리 단계인 영역 제안(region proposal)을 FPGA에서 고속으로 수행하기 위한 데이터플로우 기반 가속기를 설계하고 구현하였다. 기존 BING(Binarized Normed Gradients) 알고리즘은 8×8 윈도우에 대한 정규화 그라디언트를 계산하고, 이를 SVM으로 평가해 후보 영역을 생성하는 방식으로, 연산량은 적지만 메모리 접근 패턴이 비연속적이고 제어 흐름이 복잡해 CPU에서 효율적인 파이프라인 구현이 어려웠다.
논문은 BING을 세 단계, 즉 리사이징, 핵심 연산(GradCalc, SVM‑I, NMS), 정렬로 분리하고, 각각을 스트리밍 파이프라인으로 구현하였다.
1) **리사이징 모듈**
원본 이미지를 4개의 블록으로 균등하게 분할하고, 각 블록을 별도의 BRAM 포트에 매핑한다. 두 개의 캐시 라인(‘Ping’과 ‘Pong’)을 교대로 사용해 블록 간 로딩을 회전식으로 수행함으로써 연속적인 배치 스트림을 생성한다. 이 방식은 BRAM 포트 충돌을 방지하고, 다음 단계인 커널 연산에 데이터를 끊김 없이 공급한다.
2) **커널 연산 모듈**
CalcGrad 단계에서는 인접 픽셀 간의 최대 색상 차이를 이용해 수직·수평 그라디언트를 구하고, 이를 8×8 윈도우 단위로 결합해 64차원 피처를 만든다. SVM‑I 단계에서는 사전 학습된 가중치와 내적을 수행해 각 윈도우의 점수를 산출한다. NMS 단계에서는 5×5 블록 내 최대 점수를 선택해 중복을 제거한다. 각 단계는 독립적인 워크스페이스와 ‘tiered cache’를 갖추어, 라인 버퍼와 윈도우 버퍼를 결합한 메모리 구조로 데이터 지역성을 극대화한다. 또한, 4개의 파이프라인을 병렬 배치해 배치 단위 연산을 동시에 진행한다. 파이프라인 간 데이터 흐름은 FIFO 버퍼로 연결해 비동기성을 흡수한다.
3) **정렬 모듈**
Top‑k 후보를 빠르게 추출하기 위해 버블‑푸싱 힙 정렬을 적용하였다. 기존 힙 정렬의 복잡도를 파이프라인에 맞게 재구성해 삽입·삭제 연산을 연속적인 스트림으로 처리한다. 이를 통해 정렬 단계에서 발생할 수 있는 병목을 최소화한다.
하드웨어 구현은 Vivado HLS 2017을 이용해 C 코드 기반 고수준 합성을 수행했으며, 두 가지 FPGA 보드에 매핑하였다. Artix‑7 저전압 버전은 3.3 MHz에서 35 fps를 달성하고 전력 소모는 97 mW에 불과해 초저전력 임베디드 시스템에 적합하다. Kintex UltraScale+는 100 MHz에서 1100 fps를 기록했으며, 동적 전력은 350 mW, 정적 전력을 포함한 총 전력은 821 mW 수준이다.
성능 평가에서는 VOC2007 데이터셋을 이용해 검출률(DR)과 평균 최적 겹침(MABO)을 측정하였다. 1,000개의 후보 윈도우에 대해 FPGA 구현은 DR 94.72%를 달성했으며, 원본 BING이 97.63%를 기록한 것과 비교해 약 3% 차이지만, 전력·면적 효율성을 크게 개선했다. 속도 면에서는 Intel i7‑3940XM(55 W TDP) 대비 3.67배 가속, ARM Cortex‑A53(3 W) 대비 250배 이상의 에너지 효율 향상을 보였다.
결론적으로, 이 연구는 데이터플로우 기반 설계가 메모리 중심의 비전 알고리즘을 FPGA에서 고효율로 구현할 수 있음을 입증하였다. 파이프라인 수와 메모리 대역폭을 조정하면 더 높은 처리량을 얻을 수 있으며, 설계는 BING 외에도 HOG, SIFT, 초기 YOLO 전처리 등 다양한 컴퓨터 비전 워크로드에 확장 가능하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기