End-to-end Language Identification using NetFV and NetVLAD
In this paper, we apply the NetFV and NetVLAD layers for the end-to-end language identification task. NetFV and NetVLAD layers are the differentiable implementations of the standard Fisher Vector and Vector of Locally Aggregated Descriptors (VLAD) me…
Authors: Jinkun Chen, Weicheng Cai, Danwei Cai
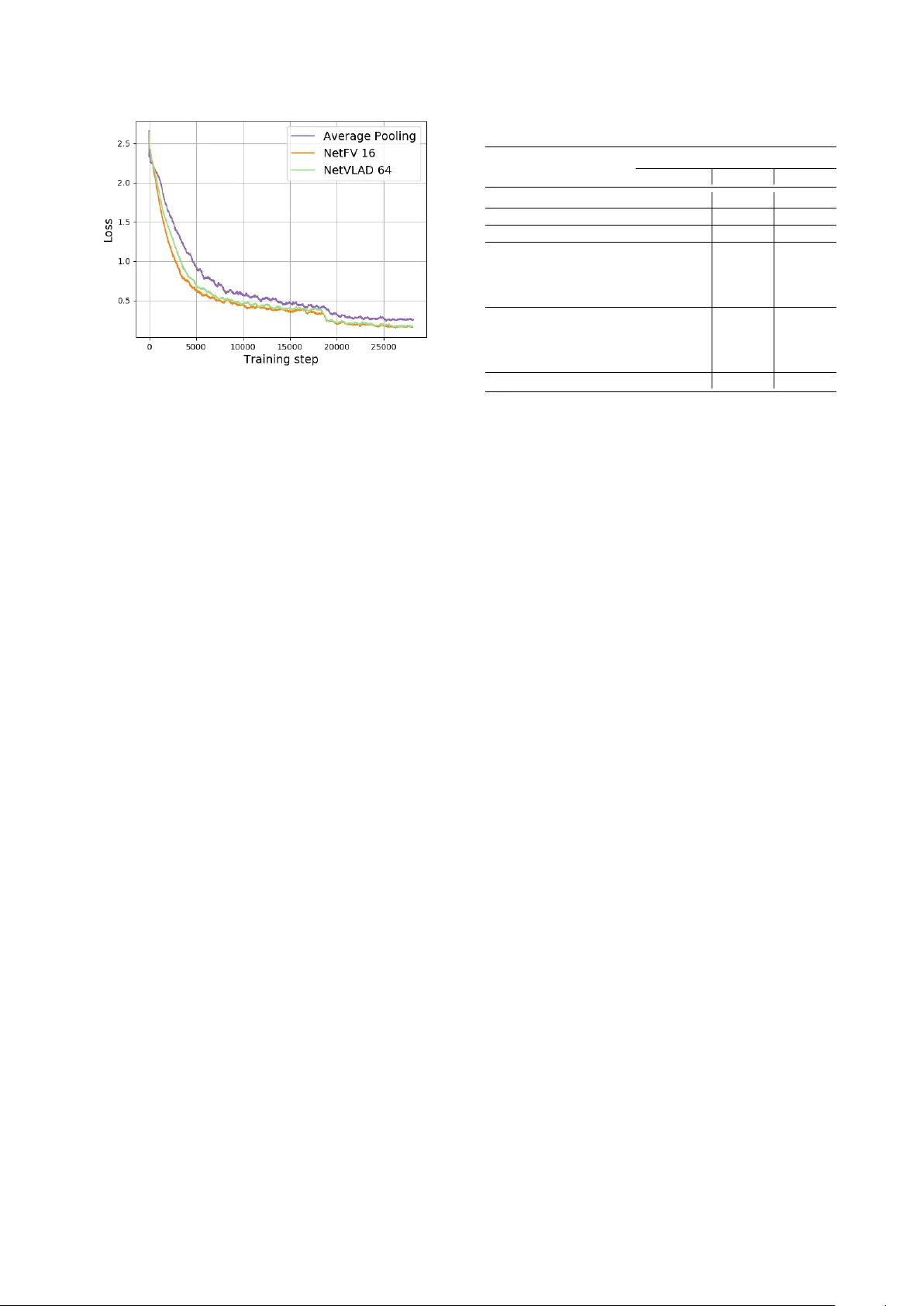
End-to-end Language Identification using NetFV and NetVLAD Jinkun Chen 2 , W eicheng Cai 1 , 2 , Danwei Cai 1 , Zexin Cai 1 , Haibin Zhong 3 , Ming Li 1 1 Data Science Research Center , Duke K unshan Univ ersity , K unshan, China 2 School of Electronics and Information T echnology , Sun Y at-sen Uni versity , Guangzhou, China 3 Jiangsu Jinling Science and T echnology Group Limited, Nanjing, China ming.li369@dukekunshan.edu.cn Abstract In this paper , we apply the NetFV and NetVLAD layers for the end-to-end language identification task. NetFV and NetVLAD layers are the differentiable implementations of the standard Fisher V ector and V ector of Locally Aggregated Descriptors (VLAD) methods, respectiv ely . Both of them can encode a se- quence of feature v ectors into a fixed dimensional vector which is v ery important to process those variable-length utterances. W e first present the relev ances and dif ferences between the clas- sical i-vector and the aforementioned encoding schemes. Then, we construct a fle xible end-to-end framew ork including a con- volutional neural network (CNN) architecture and an encoding layer (NetFV or NetVLAD) for the language identification task. Experimental results on the NIST LRE 2007 close-set task show that the proposed system achie ves significant EER reductions against the con ventional i-vector baseline and the CNN tempo- ral av erage pooling system, respectively . Index T erms : language identification, NetFV , NetVLAD, end- to-end, variable length 1. Introduction Language identification (LID) is a kind of utterance-lev el paralinguistic speech attribute recognition task with variable- length sequences as inputs. For the input utterances, the dura- tion might range from a few seconds to se veral minutes. Be- sides, there are no constraints on the lexical words thus the training utterances and test segments may have phonetic mis- match issue [1]. Therefore, our purpose is to find an ef fective and robust method to retriev e the utterance-level information and encode them into fixed dimensional v ector representations. T o address the variable-length inputs issue for acoustic feature based LID, many methods have been proposed in the last two decades. The deterministic V ector Quantization (VQ) model is used for LID in [2, 3]. VQ assigns the frame-lev el acoustic features to the nearest cluster in codebook and cal- culates the VQ distortions. Every language is characterized by an occupancy probability histogram. Compared to VQ, the Gaussian Mixture Model (GMM) is capable to model the com- plex distribution of the acoustic features [4] and generates soft posterior probabilities to assign those frame-lev el features to Gaussian components. Once the GMM is trained, the zero- order and first-order Baum-W elch statistics can be accumulated to construct a high dimensional GMM Supervector [1, 5, 6], which is considered as an utterance-le vel representation. Fur - thermore, the GMM Superv ector can be projected to a low This research was funded in part by the National Natural Sci- ence Foundation of China (61773413), Natural Science Foundation of Guangzhou City (201707010363), National Key Research and De vel- opment Program (2016YFC0103905). rank subspace using the factor analysis technique, which re- sults in the i-vector [7, 8]. Recently , the posterior statistics on each decision tree senones generated by the speech recogni- tion acoustic model are adopted to construct the phonetic aw are DNN i-v ector [9], which outperforms the GMM i-vector in LID tasks [10, 11, 12] due to the discriminative frame le vel align- ments. More recently , some end-to-end learning approaches are proposed for the LID task and achiev ed superior perfor- mances [13, 14]. Ho wev er, these methods may lack the flexibil- ity in dealing with duration-variant utterances. This is mainly because the deep learning module (fully-connected layer) or the de velopment platform usually requires fixed-length inputs. Each utterance with different number of frames has to be zero padded or truncated into fixed-size vectors. This is not a de- sired way to recognize spoken languages, speak er identities or other paralinguistic attributes on speech utterances with various durations. T o address this problem, recurrent neural networks (RNN), e.g. Long Short-T erm Memory (LSTM) [15], is intro- duced to LID and the last time-step output of the RNN layer is used as the utterance-le vel representation [16]. Stacked long- term time delay neural networks (TDNN) is adopted to span a wider temporal context on the inputs and a hierarchical structure is b uilt to predict the lik elihood over different languages [17]. Alternativ ely , modules like temporal av erage pooling (T AP), are proposed to perform statistic measures on the length-v ariant feature sequences in order to generate fixed dimensional repre- sentations for LID [18, 19]. These end-to-end systems perform well, howe ver , the simple statistic measures are performed glob- ally on all the frame le vel features (e.g. average pooling) which may smooth out the information on each clusters. In our early works, we imitate the GMM Superv ector encoding procedure and introduce a learnable dictionary encoding (LDE) layer for the end-to-end LID system [20, 21]. The success of LDE layer in the end-to-end LID framew ork inspires us to explore dif ferent encoding methods which may be feasible for the LID task. In this paper , we adopt NetFV [22] and NetVLAD [23] in our end-to-end LID task and e xplore the feasibility of this two methods. NetFV is the “soft assignment” version of stan- dard Fisher V ector (FV) [24, 25, 26] and is differentiable which could be easily integrated to an end-to-end trainable system. Meanwhile, V ector of Locally Aggre gated Descriptors (VLAD) proposed in [27] is a simplified non-probabilistic version of the standard FV and similarly , VLAD is further enhanced as a trainable layer named NetVLAD in [23]. Standard FV and VLAD hav e been widely employed in computer vision tasks such as image retrieval, place recognition and video classifica- tion [26, 27, 28]. Moreover , both NetFV and NetVLAD are considered as more powerful pooling techniques to aggregate variable-length inputs into a fixed-length representation. This two encoding layers have been widely used and perform well in vision tasks [22, 23, 29]. As for the LID task, we emplo y a residual networks (ResNet) [30] as the front-end feature e x- tractor , and use NetFV or NetVLAD to encode the v ariable-size CNNs feature maps into fix ed-size utterance-le vel representa- tions. Experimental results on NIST LRE 07 show that the pro- posed method outperforms the GMM i-vector baseline as well as the T AP layer based end-to-end systems. Moreover , the pro- posed end-to-end system is flexible, ef fective and robust in both training and test phases. The following of this paper is org anized as follo ws: Sec- tion 2 explains the LID methods based on the GMM i-vector , NetFV and NetVLAD as well as the overall end-to-end frame- work. Experimental results and discussions are presented in Section 3 while conclusions and future w orks are pro vided in Section 4. 2. Methods In this section, we elaborate the mechanisms of the GMM Su- pervector , NetFV and NetVLAD. Besides, we explain the rel- ev ances and differences of these three encoding schemes. Fur- thermore, we describe our fle xible end-to-end frame work in de- tails. 2.1. GMM Supervector Giv en a C -component Gaussian Mixture Model-Universal Background Model (GMM-UBM) with parameters set λ = { α c , µ c , Σ c , c = 1 , 2 , . . . , C } , where α c , µ c and Σ c are the mixture weight, mean vector and covariance matrix of the c th Gaussian component, respectively , and a L -frame speech utter- ance with D dimensional features X = { x i , i = 1 , 2 , . . . , L } , the normalized c th component’ s Supervector is defined as e F c = F c N c = P L t =1 P ( c | x t , λ ) · ( x t − µ c ) P L l =1 P ( c | x l , λ ) , (1) where P ( c | x c , λ ) is the occupancy probability for x t on the c th component of the GMM, the numerator F c and the denominator N c are referred as the zero-order and first-order centered Baum- W elch statistics. By concatenating all of the e F c together , we deriv e the high dimensional Supervector e F ∈ R C D × 1 of the corresponding utterance is e F = [ e F T 1 , e F T 2 , . . . , e F T C ] T . (2) Then, the supervector e F can be projected on a low rank sub- space using the factor analysis technique to generate the i- vector . 2.2. NetFV Layer 2.2.1. F isher V ector Let X = { x i , i = 1 , 2 , . . . , L } , x i ∈ R D × 1 , denote the se- quence of input features with L frames, the generation process of the data X is assumed to be modeled by a probability den- sity function u λ with its parameters λ . As argued in [24, 31], the gradient of the log-likelihood describes the contribution of the parameters to the data generation process and can be used as discriminative representation. The gradient v ector of X w .r .t. the parameters λ can be defined as G X λ = 1 L ∇ λ log u λ ( X ) . (3) A Fisher K ernel is introduced to measure the similarity between two data samples [24] and is defined as K ( X , Y ) = ( G X λ ) 0 F − 1 λ G Y λ , (4) where Y is a sequence of features like X , and F λ is the Fisher information matrix [24] of the probability density function u λ : F λ = E X ∼ u λ [ ∇ λ log u λ ( X ) ∇ λ log u λ ( X ) T ] . (5) Since the F λ is a symmetric and positi ve semidefinite matrix, we can deri ve the Cholesk y decomposition of the form F λ = B 0 λ B λ , where B λ is a lower triangular matrix. In this way , the Fisher kernel K ( X , Y ) is a dot-product between the normal- ized vectors G X λ = B λ G X λ , where G X λ is referred as the Fisher V ector of X . W e choose a K -component GMM to model the complex distrib ution of data, then u λ ( x i ) = P K k =1 α k u k ( x i ) , where λ = { α k , µ k , Σ k , k = 1 , 2 , . . . , K } is the parameters set of the GMM. The gradient vector is re written as G X λ = 1 L L X i =1 ∇ λ log u λ ( x i ) . (6) From the approximation theory of the Fisher information ma- trix [24, 25, 28], the covariance matrix Σ k can be restricted to a diagonal matrix, that is Σ k = diag ( σ 2 k ) , σ k ∈ R D × 1 . More- ov er, the normalization of the gradient G X λ by B λ = F − 1 / 2 λ is simply a whitening of the dimensions [31]. Let γ i ( k ) be the posterior probability of x i on the k th GMM component, γ i ( k ) = α k u k ( x i ) P K c =1 α c u c ( x i ) . (7) The gradient w .r .t. the weight parameters α k brings little addi- tional information thus it can be omitted [31]. The remain gra- dients of x i w .r .t. the mean and standard deviation parameters are deriv ed [31] as: ∇ µ k log u λ ( x i ) = 1 √ α k γ i ( k )( x i − µ k σ k ) , (8) ∇ σ k log u λ ( x i ) = 1 √ 2 α k γ i ( k )( ( x i − µ k ) 2 σ 2 k − 1) . (9) By concatenating the gradients in Eq. 8-9, we get the gradient vector G k ( x i ) with dimension 2 D × 1 . With the K -component GMM, the Fisher V ector of x i is in the form of G ( x i ) = [ G 1 ( x i ) T , G 2 ( x i ) T , . . . , G K ( x i ) T ] T , (10) which is a high dimensional vector in R 2 DK × 1 . Finally , for the utterance-lev el representation, the Fisher V ector of the whole sequence X is approximated by a mean pooling on all G ( x i ) , G X λ = 1 L L X i =1 G ( x i ) . (11) 2.2.2. NetFV Once the FV codebook is trained, the parameters λ of the tradi- tional FV are fixed and can’ t be jointly learnt with other mod- ules in the end-to-end system. T o address this issue, as pro- posed in [22], two simplifications are made to original FV : 1) Assume all GMM components ha ve equal weights. 2) Simplify the Gaussian density u k ( x i ) to u k ( x i ) = 1 p (2 π ) D exp {− 1 2 ( x i − µ k ) T Σ − 1 k ( x i − µ k ) } . (12) CNNsarchitecture EncodingLayer Fullyconnectedlayer Lossfunction C × L ′ C × K # c l a s s e s × 1 D × L V ariablelength acousticfeatures V ariablelength CNNsfeaturemaps Fixedsizerepresentation Softmaxprobability Figure 1: Sc hematic diagram of end-to-end LRE framework. Let w k = 1 / σ k and b k = − µ k , and with the assumption of Σ k = diag ( σ 2 k ) , the gradients in Eq. 8, Eq. 9 and the posterior probability γ i ( k ) in Eq. 7 are respectiv ely rewritten as the final form of NetFV [22]: ∇ µ k log u λ ( x i ) = γ i ( k )[ w k ( x i + b k )] , (13) ∇ σ k log u λ ( x i ) = 1 √ 2 γ i ( k )[( w k ( x i + b k )) 2 − 1] , (14) γ i ( k )= exp {− 1 2 ( w k ( x i + b k )) T ( w k ( x i + b k )) } P K c =1 exp {− 1 2 ( w c ( x i + b c )) T ( w c ( x i + b c )) } . (15) The three modified equations above are differentiable so the parameters set, i.e., { w k , b k } , can be learnt via the back- propagation algorithm. 2.3. NetVLAD Layer VLAD is another strategy used to aggregate a set of feature de- scriptors into a fix ed-size representation [27]. W ith the same inputs X = { x i , i = 1 , 2 , . . . , L } as FV and K clusters as- sumed in VLAD, i.e., { µ k , k = 1 , 2 , . . . , K } , the con ventional VLAD aligns each x i to a cluster µ k . The VLAD fixed-size representation V ∈ R K × D is defined as V ( k ) = L X i =1 β k ( x i )( x i − µ k ) , (16) where β k ( x i ) indicates 1 if µ k is the closest cluster to x i and 0 otherwise. This discontinuity prevents it to be dif ferentiable in the end-to-end learning pipeline. T o make the VLAD differ - entiable, The authors in [23] proposed the soft assignment to function β k ( x i ) , that is β k ( x i ) = exp( w T k x i + b k ) P K c =1 exp( w T c x i + b c )) , (17) where w k ∈ R D × 1 and b k is a scale. By integrating the soft alignment β k ( x i ) into Eq. 16, the final form of differentiable VLAD method is deriv ed as V ( k ) = L X i =1 exp( w T k x i + b k ) P K c =1 exp( w T c x i + b c ) ( x i − µ k ) , (18) which is so-called NetVLAD [23] with the parameters set of { µ k , w k , b k , k = 1 , 2 , . . . , K } . The fixed-size matrix in Eq. 18 is normalized to generate the final utterance-le vel representa- tions. 2.4. Insights into NetFV and NetVLAD Focusing on the GMM supervector (Eq. 1), the gradient com- ponents w .r .t. mean in Fisher V ector (Eq. 8) and the VLAD ex- pression (Eq. 16), we can found that these three methods calcu- late the zero-order and first-order statistics to construct fixed di- mensional representations in a similar way . The residual vector measures the differences between the input feature and its cor- responding component in GMM or cluster in codebooks. And all the three aforementioned methods store the weighted sum of residuals. Howev er, they might ha ve dif ferent formulas to com- pute the zero-order statistics. As for Fisher V ector , it captures the additional gradient components w .r .t. covariance which can be considered as the second-order statistics. Above all, these three encoding methods hav e theoretical explanations from dif- ferent perspectives but result in some similar mathematics for- mulas. Motiv ated by the great success of GMM Supervector , the NetFV and NetVLAD layers theoretically might hav e good potential in paralinguistic speech attribute recognition tasks. Compared to the temporal average pooling (T AP) layer , NetFV and NetVLAD layers are capable to heuristically learn more discriminativ e feature representations in an end-to-end manner while T AP layer may de-emphasize some important in- formation by simple average pooling. If the number of clusters C in NetFV or NetVLAD layer is 1, and its mean is zero, the encoding layer is just simplified to T AP layer . Our end-to-end framew ork is illustrated in Fig. 1. It com- prises a CNNs architecture with C output channels, an encoding layer with cluster size K and a fully connected layer . T aken the variable-length features X ∈ R D × L as input, the CNNs struc- ture spatially produces a v ariable-size feature maps in R C × L 0 , where L 0 is dependent on the input length L . The encoding layer then aggreg ates the feature maps into a fix ed-size repre- sentation V in R C × K . And the fully connected layer acts as a back-end classifier . All the parameters in this framework are learnt via the back-propagation algorithm. 3. Experiments 3.1. 2007 NIST LRE Closet-set T ask The 2007 NIST Language Recognition Evaluation(LRE) is a closed-set language detection task. The training set consists the datasets of Callfriend, LRE 03, LRE 05, SRE 08 and the dev el- opment part of LRE 07. W e split the utterances in training set into segments with duration in 3 to 120 seconds. This yields about 39000 utterances. In the test set, there are 14 tar get lan- guages with 7530 utterances in total. The nominal durations of the testing data are 3s, 10s and 30s. 3.2. Experimental Setup Raw audio is con verted to 7-1-3-7 based 56 dimensional shifted delta coefficients (SDC) feature, and a frame-level energy-based voice activity detection (V AD) selects features corresponding to speech frames. W e train a 2048-component GMM-UBM with full cov ariance and e xtract 600-dimensional i-v ectors followed by the whitening and length normalization. Finally , we adopt multi-class logistic regression to predict the language labels. For the end-to-end LID systems, the 64-dimension mel- Figure 2: The training loss curves of end-to-end systems. filterbank coefficients feature is extracted along with sliding mean normalization over a window of 300 frames. Afterwards, the acoustic features are fed to a random initialized ResNet-34 networks with 128 output channels to produce the utterance- dependent feature maps. The temporal av erage pooling (T AP) is adopted as the encoding layer to build the baseline end-to-end system. Meanwhile, the cluster size K ranges from 16 to 128 by step power of 2 to find out the best parameter setup in NetFV and NetVLAD layers, respecti vely . The softmax and cross en- tropy loss are inte grated behind the fully connected layer . Fi- nally , a stochastic gradient descent (SGD) optimizer with the momentum 0.9, the weight decay 1 × 10 − 4 and the initial learn- ing rate 0.1 is used for the back-propagation. The learning rate is divided by 10 at the 60 th and 80 th epoch. T o ef ficiently train the system, we set the mini-batch size of 128 in data parallelism ov er 4 GPUs. For each mini-batch data, a truncated-length L is randomly sampled from [200 , 1024] , and is used to truncate a segment of continuous L -frame fea- tures from a T -frame utterance. The beginning index of trun- cation randomly lies in the interv al of [0 , T − L − 1] . Con- sequently , a mini-batch data with unified-length samples in R 128 × 64 × L is loaded and L may change for different mini- batches. In the test phase, all the speeches in 3, 10 and 30 sec- onds durations are tested one-by-one on the same trained model. No truncation is used for the arbitrary-duration utterances. 3.3. Evaluation The training losses of the end-to-end systems are sliding smoothed with window size of 400, and illustrated in Fig. 2. The NetFV and NetVLAD based systems con verge faster and reach lower losses than that of the temporal av erage pooling (T AP) layer . With a closer look, NetFV is slightly better than NetVLAD but both of them are competitiv e in the training phase. The language identification results are presented in T a- ble 1. The performance is measured in the metrics of the aver - age detection cost C avg and equal error rate (ERR). From the T able 1, the end-to-end systems including T AP , LDE, NetFV and NetVLAD layers significantly outperform the con ventional GMM i-vector baseline. It shows that the proposed end-to-end framew ork for the LID task is feasible and effecti ve. The results of the systems based on the T AP and the remarkable LDE layers are provided in our early works [20]. Moreov er, we step further to compare the performances of T able 1: P erformances on 2007 NIST LRE task System description C avg (%) /E E R (%) 3s 10s 30s GMM i-vector 20.46/17.71 8.29/7.00 3.02/2.27 ResNet34 T AP 9.24/10.91 3.39/5.58 1.83/3.64 ResNet34 LDE 64 8.25 / 7.75 2.61 / 2.31 1.13 / 0.96 ResNet34 NetFV 16 9.47/9.04 2.96/2.59 1.31/1.08 ResNet34 NetFV 32 8.95/8.37 2.88/2.49 1.35/1.31 ResNet34 NetFV 64 8.91/8.26 2.88/2.74 1.19/1.15 ResNet34 NetFV 128 9.05/8.64 2.91/2.72 1.27/1.34 ResNet34 NetVLAD 16 8.23 / 8.06 2.90/2.62 1.36/1.17 ResNet34 NetVLAD 32 8.87/8.58 3.10/2.50 1.46/1.15 ResNet34 NetVLAD 64 8.59/8.08 2.80 / 2.50 1.32 / 1.02 ResNet34 NetVLAD 128 8.72/8.44 3.15/2.76 1.53/1.14 Fusion system 6.14 / 6.86 1.81 / 2.00 0.89 / 0.92 the T AP , NetFV and NetVLAD encoding layers. Both NetFV and NetVLAD based systems achiev e much lower C avg and EER than the ones with T AP layer . Especially on the long utter- ances (30s), the best C avg and EER of NetVLAD could be rel- ativ ely reduced by 27 . 87% and 71 . 98% respectively w .r .t. the results of T AP . If we concentrate on the NetFV and NetFV only , the performances are generally getting better while the cluster size ranges 16 to 64, and start to degrade when the cluster size reaches 128. Therefore, lar ger cluster size in the encoding layer may enhance the capacity of networks, ho wever , more data and training epochs may be required as well. In addition, the T AP based system shows the accuracy rates of 75.49%, 89.71% and 93.56% on the 3s, 10s and 30s test set respecti vely while the NetVLAD based system improves the accuracies to 76.14%, 91.43% and 96.85%. Overall, NetVLAD is slightly superior to NetFV in the test phase and achie ves the best performance when the cluster size is 64. Despite the best result corresponding to the NetVLAD is slightly inferior to that of the LDE layer, the performances of the NetFV , NetVLAD and LDE layers are comparable. What’ s more, these three powerful encoding methods are complemen- tary . W ith the cluster size is 64, we fuse the three systems based on the NetFV , NetVLAD and LDE respectiv ely at the score lev el. And as sho wn in the T able 1, the score lev el fusion system further reduces the C avg and EER significantly . 4. Conclusions In this paper , we apply these two encoding met hods in our end- to-end LID framew ork to inv estigate the feasibility and perfor- mance. The NetFV and NetVLAD layers are more powerful encoding techniques with learnable parameters and are able to encoding the v ariable-length sequence of features into a fixed- size representation. W e inte grate them to a flexible end-to-end framew ork for the LID task and conduct experiments on the NIST LRE07 task to e valuate the methods. Promising experi- mental results show effectiv eness and great potential of NetFV and NetVLAD in the LID task. This end-to-end framework might also work for other paralinguistic speech attribute recog- nition tasks, which will be our further works. 5. References [1] T . Kinnunen and H. Li, “ An ov erview of te xt-independent speaker recognition: From features to supervectors, ” Speech Communica- tion , vol. 52, no. 1, pp. 12–40, 2010. [2] D. Cimarusti and R. Ives, “Dev elopment of an automatic identi- fication system of spoken languages: Phase i, ” in IEEE Interna- tional Confer ence on Acoustics, Speec h, and Signal Pr ocessing (ICASSP) , vol. 7. IEEE, 1982, pp. 1661–1663. [3] M. Sugiyama, “ Automatic language recognition using acoustic features, ” IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) , pp. 813–816, 1991. [4] M. A. Zissman, “Comparison of four approaches to automatic lan- guage identification of telephone speech, ” IEEE Tr ansactions on Speech and Audio Processing , v ol. 4, no. 1, p. 31, 1996. [5] W . M. Campbell, D. E. Sturim, and D. A. Reynolds, “Support vec- tor machines using gmm supervectors for speaker verification, ” IEEE Signal Pr ocessing Letters , vol. 13, no. 5, pp. 308–311, 2006. [6] C. H. Y ou, H. Li, and K. A. Lee, “ A gmm-supervector approach to language recognition with adaptive rele vance factor , ” in Signal Pr ocessing Conference , 2010 18th Eur opean . IEEE, 2010, pp. 1993–1997. [7] N. Dehak, P . J. Kenny , R. Dehak, P . Dumouchel, and P . Ouellet, “Front-end factor analysis for speaker verification, ” IEEE T rans- actions on Audio, Speech, and Language Pr ocessing , vol. 19, no. 4, pp. 788–798, 2011. [8] N. Dehak, P . A. T orres-Carrasquillo, D. Reynolds, and R. Dehak, “Language recognition via i-vectors and dimensionality reduc- tion, ” in T welfth Annual Conference of the International Speech Communication Association , 2011. [9] Y . Lei, N. Scheffer , L. Ferrer, and M. McLaren, “ A novel scheme for speaker recognition using a phonetically-aware deep neural network, ” in 2014 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , May 2014, pp. 1695– 1699. [10] M. Li and W . Liu, “Speaker verification and spoken language identification using a generalized i-vector framework with pho- netic tokenizations and tandem features, ” in F ifteenth Annual Confer ence of the International Speech Communication Associ- ation , 2014. [11] D. Snyder , D. Garcia-Romero, and D. Pov ey , “T ime delay deep neural network-based universal background models for speaker recognition, ” in Automatic Speech Recognition and Understand- ing (ASR U), 2015 IEEE W orkshop . IEEE, 2015, pp. 92–97. [12] F . Richardson, D. Reynolds, and N. Dehak, “Deep neural network approaches to speaker and language recognition, ” IEEE Signal Pr ocessing Letters , vol. 22, no. 10, pp. 1671–1675, 2015. [13] I. Lopez-Moreno, J. Gonzalez-Dominguez, O. Plchot, D. Mar- tinez, J. Gonzalez-Rodriguez, and P . Moreno, “ Automatic lan- guage identification using deep neural networks, ” in IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2014, pp. 5337–5341. [14] J. Gonzalez-Dominguez, I. Lopez-Moreno, H. Sak, J. Gonzalez- Rodriguez, and P . J. Moreno, “ Automatic language identification using long short-term memory recurrent neural networks, ” in Fif- teenth Annual Confer ence of the International Speech Communi- cation Association , 2014. [15] S. Hochreiter and J. Schmidhuber , “Long short-term memory , ” Neural Computation , vol. 9, no. 8, pp. 1735–1780, 1997. [16] G. Gelly , J.-L. Gauvain, V . B. Le, and A. Messaoudi, “ A divide- and-conquer approach for language identification based on recur- rent neural networks. ” in Proc. Interspeech 2016 , 2016, pp. 3231– 3235. [17] D. Garcia-Romero and A. McCree, “Stacked long-term tdnn for spoken language recognition. ” in Pr oc. Interspeech 2016 , 2016, pp. 3226–3230. [18] D. Snyder , P . Ghahremani, D. Povey , D. Garcia-Romero, Y . Carmiel, and S. Khudanpur, “Deep neural network-based speaker embeddings for end-to-end speaker verification, ” in 2016 IEEE Spoken Language T echnology W orkshop (SLT) . IEEE, 2016, pp. 165–170. [19] C. Li, X. Ma, B. Jiang, X. Li, X. Zhang, X. Liu, Y . Cao, A. Kan- nan, and Z. Zhu, “Deep speaker: an end-to-end neural speaker embedding system, ” arXiv preprint , 2017. [20] W . Cai, , X. Zhang, X. W ang, and M. Li, “ A novel learnable dic- tionary encoding layer for end-to-end language identification, ” in IEEE International Confer ence on Acoustics, Speech, and Signal Pr ocessing (ICASSP) . IEEE, 2018. [21] W . Cai, Z. Cai, W . Liu, X. W ang, and M. Li, “Insights into end-to- end learning scheme for language identification, ” in IEEE Inter- national Conference on Acoustics, Speech, and Signal Processing (ICASSP) . IEEE, 2018. [22] P . T ang, X. W ang, B. Shi, X. Bai, W . Liu, and Z. Tu, “Deep fish- ernet for object classification, ” arXiv pr eprint arXiv:1608.00182 , 2016. [23] R. Arandjelovic, P . Gronat, A. T orii, T . Pajdla, and J. Sivic, “Netvlad: Cnn architecture for weakly supervised place recogni- tion, ” in 2016 IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) , 2016, pp. 5297–5307. [24] T . Jaakk ola and D. Haussler, “Exploiting generati ve models in dis- criminativ e classifiers, ” in Advances in neural information pr o- cessing systems , 1999, pp. 487–493. [25] F . Perronnin and C. Dance, “Fisher kernels on visual v ocabularies for image categorization, ” in 2007 IEEE Conference on Computer V ision and P attern Recognition (CVPR) . IEEE, 2007, pp. 1–8. [26] F . Perronnin, Y . Liu, J. S ´ anchez, and H. Poirier, “Large-scale image retrieval with compressed fisher v ectors, ” in 2010 IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) . IEEE, 2010, pp. 3384–3391. [27] H. J ´ egou, M. Douze, C. Schmid, and P . P ´ erez, “ Aggregating local descriptors into a compact image representation, ” in 2010 IEEE Confer ence on Computer V ision and P attern Recognition (CVPR) . IEEE, 2010, pp. 3304–3311. [28] J. S ´ anchez, F . Perronnin, T . Mensink, and J. V erbeek, “Image clas- sification with the fisher vector: Theory and practice, ” Interna- tional Journal of Computer V ision , vol. 105, no. 3, pp. 222–245, 2013. [29] A. Miech, I. Lapte v , and J. Si vic, “Learnable pooling with conte xt gating for video classification, ” arXiv preprint , 2017. [30] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in 2016 IEEE Conference on Computer V ision and P attern Recognition (CVPR) , 2016, pp. 770–778. [31] F . Perronnin, J. S ´ anchez, and T . Mensink, “Improving the fisher kernel for large-scale image classification, ” in European Confer- ence on Computer V ision . Springer , 2010, pp. 143–156.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment