엔드투엔드 언어 식별을 위한 NetFV와 NetVLAD 활용
본 논문은 가변 길이 음성 입력을 고정 차원 벡터로 변환하는 NetFV와 NetVLAD 레이어를 CNN 기반 엔드투엔드 프레임워크에 결합하여 언어 식별 성능을 향상시키는 방법을 제안한다. NIST LRE 2007 폐쇄형 테스트에서 기존 i‑vector 및 평균 풀링 기반 모델 대비 EER 및 Cavg가 크게 감소함을 실험적으로 입증한다.
저자: Jinkun Chen, Weicheng Cai, Danwei Cai
본 논문은 가변 길이 음성 신호를 고정 차원 벡터로 변환하는 두 가지 최신 풀링 기법, NetFV와 NetVLAD를 활용한 엔드투엔드 언어 식별 시스템을 제안한다. 기존의 GMM‑i‑vector 방식은 고차원 Supervector를 추출한 뒤 factor analysis를 통해 저차원 i‑vector로 압축하는 복합 파이프라인을 갖는다. 이러한 방식은 학습 단계와 추론 단계가 분리돼 있어 전체 시스템을 통합적으로 최적화하기 어렵고, 특히 짧은 발화나 길이 변동이 큰 입력에 대해 효율적인 처리가 제한적이다. 최근 딥러닝 기반 엔드투엔드 접근법이 등장했지만, 대부분은 평균 풀링(TAP)이나 RNN 기반의 마지막 타임스텝 출력에 의존해 전역적인 통계만을 이용한다. 이는 클러스터별 특성을 반영하지 못해 언어별 미세한 음향 차이를 충분히 포착하지 못한다는 한계가 있다.
이에 저자들은 두 가지 차별화된 인코딩 레이어를 도입한다. 첫 번째인 NetFV는 전통적인 Fisher Vector의 “soft assignment” 버전으로, GMM의 각 컴포넌트에 대해 1차(평균)와 2차(공분산) 통계 정보를 동시에 학습한다. 기존 FV는 파라미터가 고정돼 있어 전체 네트워크와 공동 학습이 불가능했지만, NetFV는 가중치 w_k와 바이어스 b_k를 학습 가능한 변수로 두어 역전파가 가능하도록 설계되었다. 두 번째인 NetVLAD는 VLAD의 연속형 확장으로, 클러스터 중심 µ_k와 소프트 어사인먼트 파라미터 w_k, b_k를 학습한다. VLAD는 1차 잔차(프레임과 클러스터 중심의 차)만을 집계하지만, 소프트 어사인먼트를 도입함으로써 미분 가능성을 확보하고, 클러스터별 가중치를 동적으로 조정한다. 두 레이어 모두 입력 시퀀스 X={x_i}에 대해 K개의 클러스터를 정의하고, 각 프레임을 클러스터에 부드럽게 할당한 뒤 잔차를 가중합해 K·C 차원의 고정 벡터 V를 만든다.
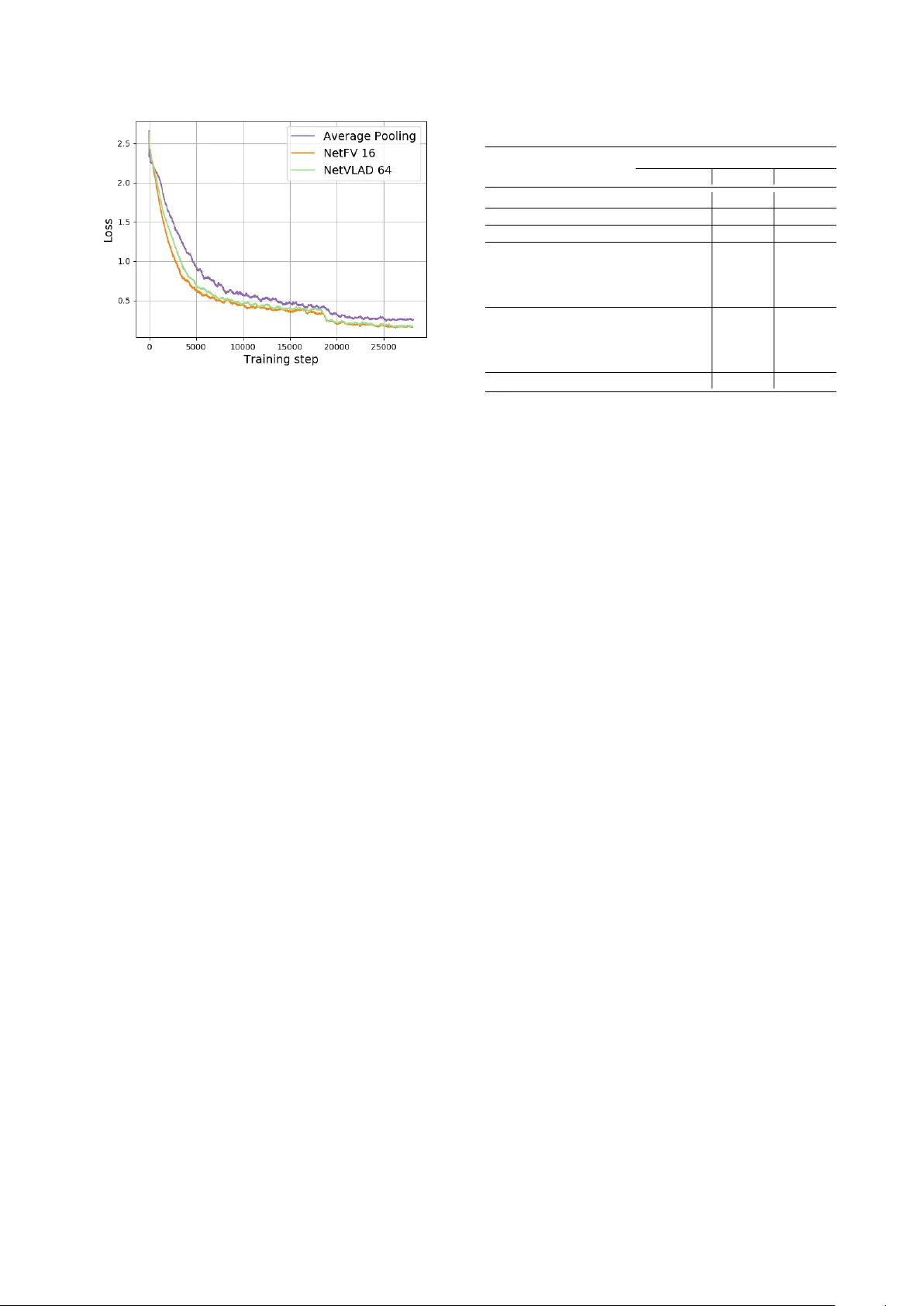
시스템 아키텍처는 ResNet‑34 기반 1‑D CNN을 프론트엔드로 사용한다. 64‑dim mel‑filterbank 특성을 300‑프레임 윈도우 평균 정규화 후 CNN에 입력하면, C=128 채널의 시퀀스 특징 맵이 생성된다. 이 특징 맵은 길이에 따라 가변적인 L′을 가지며, 이후 NetFV 혹은 NetVLAD 레이어가 적용돼 K=16, 32, 64, 128 중 최적값을 탐색한다. 인코딩된 벡터는 L2 정규화와 함께 전역 풀링을 거쳐 완전 연결층에 전달되고, 소프트맥스와 교차 엔트로피 손실을 통해 언어 라벨을 예측한다. 학습은 SGD(모멘텀 0.9, weight decay 1e‑4)와 초기 학습률 0.1을 사용하고, 60·80 epoch에서 10배 감소시킨다. 배치당 길이를
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기