Syllable-Based Sequence-to-Sequence Speech Recognition with the Transformer in Mandarin Chinese
Sequence-to-sequence attention-based models have recently shown very promising results on automatic speech recognition (ASR) tasks, which integrate an acoustic, pronunciation and language model into a single neural network. In these models, the Trans…
Authors: Shiyu Zhou, Linhao Dong, Shuang Xu
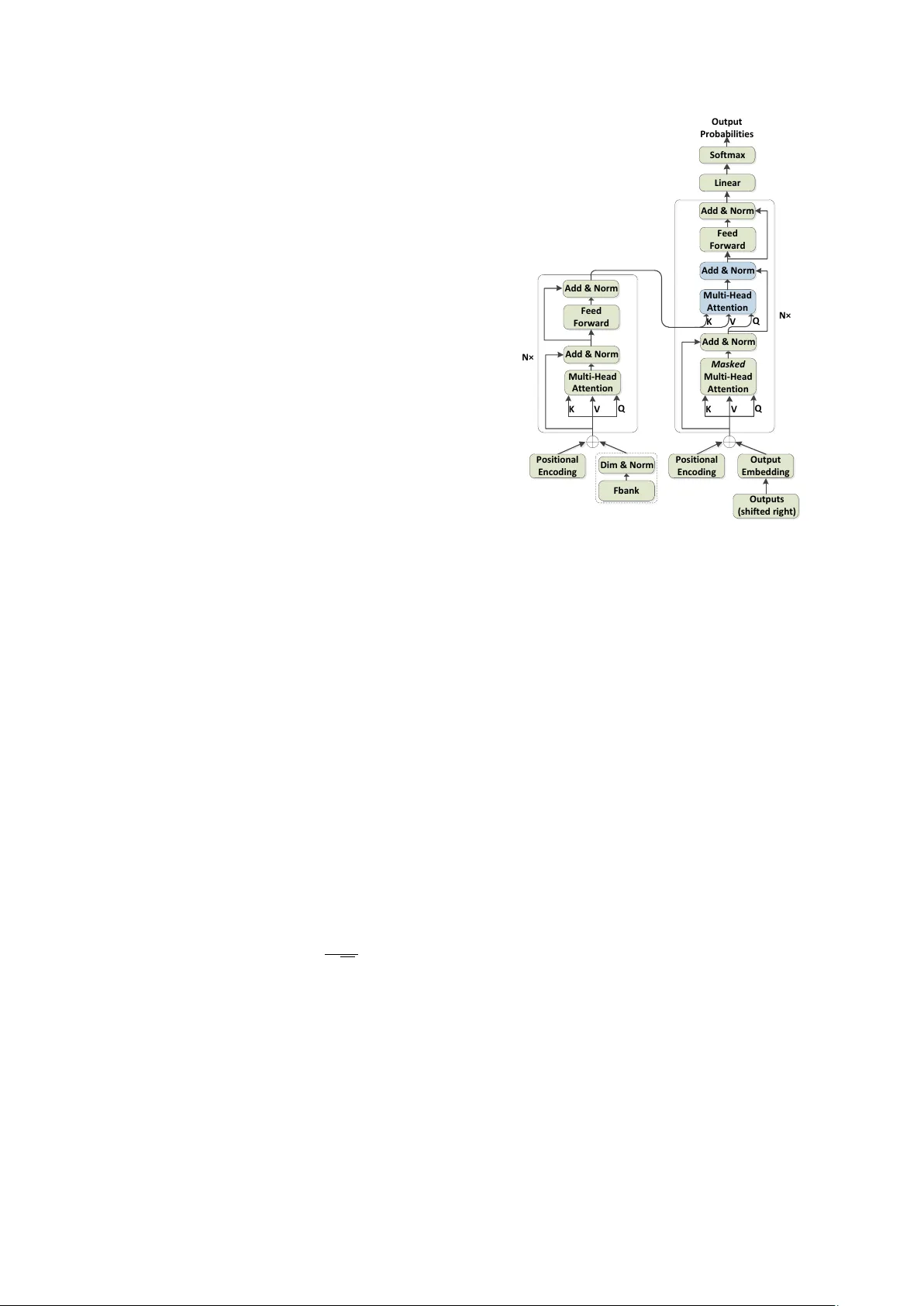
Syllable-Based Sequence-to-Sequence Speech Recognition with the T ransf ormer in Mandarin Chinese Shiyu Zhou 1 , 2 , Linhao Dong 1 , 2 , Shuang Xu 1 , Bo Xu 1 1 Institute of Automation, Chinese Academy of Sciences 2 Uni versity of Chinese Academy of Sciences { zhoushiyu2013, donglinhao2015, shuang.xu, xubo } @ia.ac.cn Abstract Sequence-to-sequence attention-based models hav e recently shown very promising results on automatic speech recognition (ASR) tasks, which integrate an acoustic, pronunciation and language model into a single neural network. In these models, the T ransformer , a ne w sequence-to-sequence attention-based model relying entirely on self-attention without using RNNs or con volutions, achieves a new single-model state-of-the-art BLEU on neural machine translation (NMT) tasks. Since the outstanding performance of the Transformer , we extend it to speech and concentrate on it as the basic architecture of sequence-to-sequence attention-based model on Mandarin Chi- nese ASR tasks. Furthermore, we inv estigate a comparison be- tween syllable based model and context-independent phoneme (CI-phoneme) based model with the T ransformer in Mandarin Chinese. Additionally , a greedy cascading decoder with the T ransformer is proposed for mapping CI-phoneme sequences and syllable sequences into word sequences. Experiments on HKUST datasets demonstrate that syllable based model with the T ransformer performs better than CI-phoneme based coun- terpart, and achieves a character error rate (CER) of 28 . 77% , which is competiti ve to the state-of-the-art CER of 28 . 0% by the joint CTC-attention based encoder-decoder netw ork. Index T erms : ASR, multi-head attention, syllable based acous- tic modeling, sequence-to-sequence 1. Introduction Experts hav e sho wn significant interest in the area of sequence- to-sequence modeling with attention [1, 2, 3, 4] on ASR tasks in recent years. Sequence-to-sequence attention-based models integrate separate acoustic, pronunciation and language models of a conv entional ASR system into a single neural network [5] and do not make the conditional independence assumptions as in standard hidden Markov based model [6]. Sequence-to-sequence attention-based models are com- monly comprised of an encoder , which consists of multiple re- current neural network (RNN) layers that model the acoustics, and a decoder , which consists of one or more RNN layers that predict the output sub-word sequence. An attention layer acts as the interface between the encoder and the decoder: it selects frames in the encoder representation that the decoder should at- tend to in order to predict the ne xt sub-word unit [5]. Howe ver , RNNs maintain a hidden state of the entire past that prevents parallel computation within a sequence. In order to reduce se- quential computation, the model architecture of the T ransformer has been proposed in [7]. This model architecture eschews re- currence and instead relies entirely on an attention mechanism The research work is supported by the National K ey Research and Dev elopment Program of China under Grant No. 2016YFB1001404. to draw global dependencies between input and output, which allows for significantly more parallelization and achie ves a ne w single-model state-of-the-art BLEU on NMT tasks [7]. Since the outstanding performance of the Transformer , this paper fo- cuses on it as the basic architecture of sequence-to-sequence attention-based model on Mandarin Chinese ASR tasks. Recently v arious modeling units of sequence-to-sequence attention-based models have been studied on English ASR tasks, such as graphemes, CI-phonemes, context-dependent phonemes and word piece models [1, 5, 8]. Howe ver , few related works hav e been explored by sequence-to-sequence attention-based models on Mandarin Chinese ASR tasks. As we know , Mandarin Chinese is a syllable-based language and syllables are their logical unit of pronunciation. These syllables hav e a fix ed number (around 1400 pinyins with tones are used in this work) and each written character corresponds to a syllable. In addition, syllables are a longer linguistic unit, which reduces the dif ficulty of syllable choices in the decoder by sequence-to- sequence attention-based models. Moreover , syllables have the advantage of a voiding out-of-v ocabulary (OO V) problem. Due to these advantages of syllables, we are concerned with syllables as the modeling unit in this paper and in vestigate a comparison between CI-phoneme based model and syllable based model with the Transformer on Mandarin Chinese ASR tasks. Moreover , Since we in vestigate the comparison between CI-phonemes and syllables, these CI-phoneme sequences or syllable sequences from the Transformer hav e to be conv erted into word sequences for the performance comparison in terms of CER. The conv ersion from CI-phoneme sequences or sylla- ble sequences to word sequences can be regarded as a sequence- to-sequence task, which is modeled by the Transformer in this paper . Then we propose a greedy cascading decoder with the T ransformer to maximize the posterior probability P r ( W | X ) approximately . Experiments on HKUST datasets re veal that the T ransformer performs very well on Mandarin Chinese ASR tasks. Moreover , we experimentally confirm that syllable based model with the T ransformer can outperform CI-phoneme based counterpart, and achieve a CER of 28 . 77% , which is compet- itiv e to the state-of-the-art CER of 28 . 0% by the joint CTC- attention based encoder-decoder netw ork [9]. The rest of the paper is organized as follows. After an ov erview of the related work in Section 2, Section 3 describes the proposed method in detail. we then show experimental re- sults in Section 4 and conclude this work in Section 5. 2. Related work Sequence-to-sequence attention-based models hav e sho wn v ery encouraging results on English ASR tasks [1, 8, 10]. Ho w- ev er , it is quite difficult to apply it to Mandarin Chinese ASR tasks. In [11], Chan et al. proposed Character -Pinyin sequence- to-sequence attention-based model on Mandarin Chinese ASR tasks. The Pin yin information was only used during training for improving the performance of the character model. Instead of using joint Character-Pin yin model, [12] directly used Chinese characters as network output by mapping the one-hot charac- ter representation to an embedding vector via a neural network layer . In this paper , we are concerned with syllables as the mod- eling unit. Acoustic models using syllables as the modeling unit have been in vestigated for a long time [13, 14, 15]. Gana- pathiraju et al. hav e first shown that syllable based acoustic models can outperform context dependent phone based acous- tic models with GMM [14]. Wu et al. experimented on sylla- ble based context dependent Chinese acoustic model and dis- cov ered that context dependent syllable based acoustic models can show promising performance [15]. Qu et al. [13] explored the CTC-SMBR-LSTM using syllables as outputs and verified that syllable based CTC model can perform better than CI- phoneme based CTC model on Mandarin Chinese ASR tasks. Inspired by [13], we e xtend their work from CTC based models to sequence-to-sequence attention-based models. Using syllables as the modeling unit, it is natural to con- sider the con version from Chinese syllable sequences to Chi- nese word sequences as a task of labelling unsegmented se- quence data. Liu et al. [16] proposed RNN based supervised sequence labelling method with CTC algorithm to achiev e a di- rect con version from syllable sequences to word sequences. 3. System over view 3.1. T ransformer model The T ransformer model architecture is the same as sequence-to- sequence attention-based models except relying entirely on self- attention and position-wise, fully connected layers for both the encoder and decoder [7]. The encoder maps an input sequence of symbol representations x = ( x 1 , ..., x n ) to a sequence of con- tinuous representations z = ( z 1 , ..., z n ) . Given z , the decoder then generates an output sequence y = ( y 1 , ..., y m ) of symbols one element at a time. 3.1.1. Multi-head attention An attention function maps a query and a set of ke y-value pairs to an output, where the query , keys, values, and output are all vectors. The output is computed as a weighted sum of the val- ues, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key [7]. Scaled dot-product attention is adopted as the basic atten- tion function in the T ransformer , which describes (1): Attention ( Q, K , V ) = sof tmax QK T √ d k V (1) Where the dimension of query Q and key K are the same, which are d k , and dimension of value V is d v . Instead of performing a single attention function, the Trans- former employs the multi-head attention (MHA) which projects the queries, keys and values h times with different, learned lin- ear projections to d k , d k and d v dimensions. On each of these projected versions of queries, keys and values, the basic atten- tion function is performed in parallel, yielding d v -dimensional output values. These are concatenated and projected again, re- sulting in the final values. The equations can be represented as M u l t i - H e a d A t t e n t i o n K V Q P o s i t i o n a l E n c o d i n g F e e d F o r w a r d A d d & N o r m A d d & N o r m M a s k e d M u l t i - H e a d A t t e n t i o n K V Q P o s i t i o n a l E n c o d i n g O u t p u t E m b e d d i n g M u l t i - H e a d A t t e n t i o n A d d & N o r m A d d & N o r m O u t p u t s ( s h i f t e d r i g h t ) F e e d F o r w a r d A d d & N o r m K V Q L i n e a r O u t p u t P r o b a b i l i t i e s S o f t m a x N × N × F b a n k D i m & N o r m Figure 1: The arc hitectur e of the ASR T ransformer . follows [7]: M ultiH ead ( Q, K, V ) = C oncat ( head 1 , ..., head h ) W O (2) wher e head i = Attention QW Q i , K W K i , V W V i (3) Where the projections are parameter matrices W Q i ∈ R d model × d k , W K i ∈ R d model × d k , W V i ∈ R d model × d v , W O ∈ R hd v × d model , h is the number of heads, and d model is the model dimension. MHA behaves like ensembles of relativ ely small attentions to allow the model to jointly attend to information from dif- ferent representation subspaces at different positions, which is beneficial to learn complicated alignments between the encoder and decoder . 3.1.2. T ransformer model ar chitectur e The architecture of the ASR Transformer is shown in Figure 1, which stacks MHA and position-wise, fully connected layers for both the encode and decoder . The encoder is composed of a stack of N identical layers. Each layer has two sub-layers. The first is a MHA, and the second is a position-wise fully connected feed-forw ard network. Residual connections are em- ployed around each of the two sub-layers, followed by a layer normalization. The decoder is similar to the encoder except in- serting a third sub-layer to perform a MHA over the output of the encoder stack. T o prevent leftward information flow and preserve the auto-regressi ve property in the decoder, the self- attention sub-layers in the decoder mask out all values corre- sponding to illegal connections. In addition, positional encod- ings [7] are added to the input at the bottoms of these encoder and decoder stacks, which inject some information about the relativ e or absolute position in the sequence to make use of the order of the sequence. Since our ASR experiments use 80-dimensional log-Mel filterbank features, we explore a linear transformation with a layer normalization to con vert the input dimension to the model dimension d model for dimension matching, which is marked out by a dotted line in Figure 1. 3.2. Greedy cascading decoder with the T ransformer As syllables and CI-phonemes are inv estigated in this paper , the CI-phoneme sequences or syllable sequences hav e to be con- verted into word sequences using a lexicon during beam-search decoding. The speech recognition problem can be defined as the prob- lem of finding word sequence W that maximizes posterior prob- ability P r ( W | X ) giv en observation X , and can transform as follows [17]. ˜ W = argmax W P r ( W | X ) (4) = argmax W X s P r ( W | s ) P r ( s | X ) (5) ≈ argmax W P r ( W | s ) P r ( s | X ) (6) Here, P r ( s | X ) is the probability from observation X to sub- word unit sequence s , P r ( W | s ) is the the probability from sub- word unit sequence s to word sequence W . According to equation (6), we propose that both P r ( s | X ) and P r ( W | s ) can be regarded as sequence-to-sequence trans- formations, which can be modeled by sequence-to-sequence attention-based models, specifically the Transformer is used in the paper . Then, the greedy cascading decoder with the T ransformer is proposed to directly estimate equation (6). First, the best sub- word unit sequence s is calculated by the T ransformer from observation X to sub-word unit sequence with beam size β . And then, the best word sequence W is chosen by the Trans- former from sub-word unit sequence to word sequence with beam size γ . Through cascading two sequence-to-sequence attention-based models, we assume that equation (6) can be ap- proximated. In this work we employ β = 13 and γ = 6 . 4. Experiment 4.1. Data The HKUST corpus (LDC2005S15, LDC2005T32), a corpus of Mandarin Chinese con versational telephone speech, is col- lected and transcribed by Hong Kong Univ ersity of Science and T echnology (HKUST) [18], which contains 150-hour speech, and 873 calls in the training set and 24 calls in the test set. All experiments are conducted using 80-dimensional log-Mel filter- bank features, computed with a 25ms window and shifted e very 10ms. The features are normalized via mean subtraction and variance normalization on the speaker basis. Similar to [19, 20], at the current frame t , these features are stacked with 3 frames to the left and downsampled to a 30ms frame rate. 4.2. T raining W e perform our experiments on the base model and big model (i.e. D512-H8 and D1024-H16 respecti vely) of the T ransformer from [7]. The basic architecture of these two models is the same but different parameters setting. T able 1 lists the experimental parameters between these two models. The Adam algorithm [21] with gradient clipping and warmup is used for optimiza- tion. During training, label smoothing of v alue ls = 0 . 1 is employed [22]. T able 1: Experimental parameter s configuration. model N d model h d k d v war mup D512-H8 6 512 8 64 64 4000 steps D1024-H16 6 1024 16 64 64 12000 steps First, for the T ransformer from observation X to sub-word unit sequence, 118 CI-phonemes without silence (phonemes with tones) are employed in the CI-phoneme based experi- ments and 1384 syllables (pinyins with tones) in the sylla- ble based experiments. Extra tokens (i.e. an unknown token ( < UNK > ), a padding token ( < P AD > ), and sentence start and end tokens ( < S > / < \ S > )) are appended to the outputs, mak- ing the total number of outputs 122 and 1388 respectively in the CI-phoneme based model and syllable based model. Sec- ond, for the Transformer from sub-word unit sequence to word sequence, we collect all words from the training data together with appended extra tokens and the total number of outputs is 28444 . In our experiments, we only train the T ransformer from sub-word unit sequence to word sequence by the base model. Standard tied-state cross-word triphone GMM-HMMs are first trained with maximum likelihood estimation to generate CI-phoneme alignments on training set and test set for han- dling multiple pronunciations of the same word in Mandarin Chinese. we then generate syllable alignments through these CI-phoneme alignments according to the lexicon. Finally , we proceed to train the T ransformer with these alignments. In order to verify the ef fectiv eness of the greedy cascading decoder proposed in this paper , the CI-phoneme and syllable alignments on test data are conv erted into word sequences using the trained P r ( W | s ) models. W e can get a CER of 4 . 70% on the CI-phoneme based model and 4 . 15% on the syllable based model respectively , which are the lower bounds of our exper- iments. If sub-word unit sequences, calculated by the T rans- former from observation X to sub-word unit sequence s , can approximate to these corresponding alignments, our experimen- tal results can approach the lower bounds using the greedy cas- cading decoder . Figure 2 visualizes the self-attention alignments in the en- coder layer and the vanilla attention alignments in the encoder- decoder layer by T ensorflo w [23]. As can be seen in the figure, both self-attention matrix and vanilla attention matrix appear very localized, which let us to understand how changing the at- tention window influences the CER. 4.3. Results of CI-phoneme and syllable based model Our results are summarized in T able 2. As can be seen in the table, CI-phoneme and syllable based model with the T rans- former can achieve competitiv e results on HKUST datasets in terms of CER. It rev eals that the Transformer is very suitable for the ASR task since its powerful sequence modeling capa- bility , although it relies entirely on self-attention without us- ing RNNs or con volutions. Furthermore, we note here that the CER of syllable based model outperforms that of correspond- ing CI-phoneme based model. The results suggest that the sub- word unit of syllables is a better modeling unit in sequence- to-sequence attention-based models on Mandarin Chinese ASR tasks compared to the sub-word unit of CI-phonemes. It vali- Figure 2: Self-attention (top) of encoder-encoder that both x- axis and y-axis r epr esent input frames. V anilla attention (bot- tom) of encoder -decoder that the x-axis r epresents input frames and y-axis corr esponds to output labels. dates the conclusion proposed on CTC based model [13]. Fi- nally , it is obvious that the big model always performs better than the base model no matter on the CI-phoneme based model or syllable based model. Therefore, our further e xperiments are conducted on the big model. W e further generate more training data by linearly scaling the audio lengths by factors of 0 . 9 and 1 . 1 (speed perturb .) [9]. It can be observed that syllable based model with speed perturb becomes better and achiev es the best CER of 28 . 77% compared to without it. Howe ver , CI-phoneme based model with speed perturb becomes very slightly worse than without it. The interpretation of this phenomenon is that syllables have a longer duration and more inv ariance than CI-phonemes, so small speed perturb would not affect the pronuciation of syl- lables too much, instead of providing more useful and various training data. Ho we ver , small speed perturb might have more impact on the pronuciation of CI-phonemes due to the short du- ration. T able 2: Comparison of CI-phoneme and syllable based model with the T ransformer on HKUST datasets in CER (%). sub-word unit model CER CI-phonemes D512-H8 32 . 94 D1024-H16 30.65 D1024-H16 (speed perturb) 30 . 72 Syllables D512-H8 31 . 80 D1024-H16 29 . 87 D1024-H16 (speed perturb) 28.77 4.4. Comparison with previous works In T able 3, we compare our e xperimental results to other model architectures from the literature on HKUST datasets. First, we can find that the result of CI-phoneme based model with the T ransformer is comparable to the best result by the deep mul- tidimensional residual learning with 9 LSTM layers in hybrid system [24], and the syllable based model with the T ransformer provides over a 6% relativ e improv ement in CER compared to it. Moreover , the CER 28 . 77% of syllable based model with the Transformer is comparable to the CER 28 . 9% by the joint CTC-attention based encoder-decoder network [9] when no e x- ternal language model is used, but slightly worse than the CER 28 . 0% by the joint CTC-attention based encoder-decoder net- work with separate RNN-LM, which is the state-of-the-art on HKUST datasets to the best of our knowledge. T able 3: CER (%) on HKUST datasets compar ed to pre vious works. model CER LSTMP-9 × 800P512-F444 [24] 30 . 79 CTC-attention+joint dec. (speed perturb ., one-pass) +VGG net +RNN-LM (separate) [9] 28 . 9 28.0 CI-phonemes-D1024-H16 30 . 65 Syllables-D1024-H16 (speed perturb) 28.77 4.5. Comparison of different frame rates Finally , table 4 compares different frame rates on CI-phoneme and syllable based model with the T ransformer . It indicates that the performance of CI-phoneme and syllable based model with the Transformer decreases as the frame rate increases. The de- creasing rate is relati vely slow from 30 ms to 50 ms, but deteri- orates rapidly from 50 ms to 70 ms. Thus, it shows that frame rate between 30 ms and 50 ms performs relatively well on CI- phoneme and syllable based model with the T ransformer . T able 4: Comparison of differ ent frame rates on HKUST datasets in CER (%). model frame rate CER CI-phonemes-D1024-H16 (speed perturb) 30 ms 50 ms 70 ms 30.72 31 . 68 33 . 96 Syllables-D1024-H16 (speed perturb) 30 ms 50 ms 70 ms 28.77 29 . 36 32 . 22 5. Conclusions In this paper we applied the T ransformer , a new sequence trans- duction model based entirely on self-attention without using RNNs or conv olutions, to Mandarin Chinese ASR tasks and verified its effectiv eness on HKUST datasets. Furthermore, we compared syllables and CI-phonemes as the modeling unit in sequence-to-sequence attention-based models with the T rans- former in Mandarin Chinese. Our experimental results demon- strated that syllable based model with the T ransformer performs better than CI-phoneme based counterpart on HKUST datasets. What is more, a greedy cascading decoder with the Transformer is proposed to maximize P r ( W | s ) P r ( s | X ) and then posterior probability P r ( W | X ) can be maximized. Experimental results on CI-phoneme and syllable based model v erified the ef fectiv e- ness of the greedy cascading decoder . 6. Acknowledgements The authors would like to thank Chunqi W ang for insightful discussions on training and tuning the T ransformer . 7. References [1] C.-C. Chiu, T . N. Sainath, Y . W u, R. Prabhav alkar , P . Nguyen, Z. Chen, A. Kannan, R. J. W eiss, K. Rao, K. Gonina et al. , “State- of-the-art speech recognition with sequence-to-sequence models, ” arXiv pr eprint arXiv:1712.01769 , 2017. [2] J. K. Choro wski, D. Bahdanau, D. Serdyuk, K. Cho, and Y . Ben- gio, “ Attention-based models for speech recognition, ” in Ad- vances in neural information processing systems , 2015, pp. 577– 585. [3] D. Bahdanau, J. Chorowski, D. Serdyuk, P . Brakel, and Y . Ben- gio, “End-to-end attention-based large vocabulary speech recog- nition, ” in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Confer ence on . IEEE, 2016, pp. 4945– 4949. [4] W . Chan, N. Jaitly , Q. V . Le, and O. V inyals, “Listen, attend and spell. arxi v preprint, ” arXiv preprint , vol. 1, no. 2, p. 3, 2015. [5] R. Prabhavalkar , T . N. Sainath, B. Li, K. Rao, and N. Jaitly , “ An analysis of attention in sequence-to-sequence models,, ” in Pr oc. of Interspeech , 2017. [6] H. A. Bourlard and N. Morgan, Connectionist speech reco gnition: a hybrid approac h . Springer Science & Business Media, 2012, vol. 247. [7] A. V aswani, N. Shazeer , N. Parmar , J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “ Attention is all you need, ” in Advances in Neural Information Pr ocessing Systems , 2017, pp. 6000–6010. [8] R. Prabhav alkar , K. Rao, T . N. Sainath, B. Li, L. Johnson, and N. Jaitly , “ A comparison of sequence-to-sequence models for speech recognition, ” in Proc. Inter speech , 2017, pp. 939–943. [9] T . Hori, S. W atanabe, Y . Zhang, and W . Chan, “ Advances in joint ctc-attention based end-to-end speech recognition with a deep cnn encoder and rnn-lm, ” arXiv preprint , 2017. [10] Y . Zhang, W . Chan, and N. Jaitly , “V ery deep con volutional net- works for end-to-end speech recognition, ” in Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Con- fer ence on . IEEE, 2017, pp. 4845–4849. [11] W . Chan and I. Lane, “On online attention-based speech recog- nition and joint mandarin character-pinyin training. ” in INTER- SPEECH , 2016, pp. 3404–3408. [12] C. Shan, J. Zhang, Y . W ang, and L. Xie, “ Attention-based end-to- end speech recognition on voice search. ” [13] Z. Qu, P . Haghani, E. W einstein, and P . Moreno, “Syllable-based acoustic modeling with ctc-smbr-lstm, ” 2017. [14] A. Ganapathiraju, J. Hamaker , J. Picone, M. Ordo wski, and G. R. Doddington, “Syllable-based large vocabulary continuous speech recognition, ” IEEE T ransactions on speec h and audio pr ocessing , vol. 9, no. 4, pp. 358–366, 2001. [15] H. W u and X. W u, “Conte xt dependent syllable acoustic model for continuous chinese speech recognition, ” in Eighth Annual Con- fer ence of the International Speech Communication Association , 2007. [16] Y . Liu, J. Hua, X. Li, T . Fu, and X. Wu, “Chinese syllable-to- character conversion with recurrent neural network based super- vised sequence labelling, ” in Signal and Information Pr ocess- ing Association Annual Summit and Confer ence (APSIP A), 2015 Asia-P acific . IEEE, 2015, pp. 350–353. [17] N. Kanda, X. Lu, and H. Kaw ai, “Maximum a posteriori based de- coding for ctc acoustic models. ” in Interspeech , 2016, pp. 1868– 1872. [18] Y . Liu, P . Fung, Y . Y ang, C. Cieri, S. Huang, and D. Graff, “Hkust/mts: A very large scale mandarin telephone speech cor- pus, ” in Chinese Spoken Language Processing . Springer , 2006, pp. 724–735. [19] H. Sak, A. Senior, K. Rao, and F . Beaufays, “Fast and accurate recurrent neural network acoustic models for speech recognition, ” arXiv pr eprint arXiv:1507.06947 , 2015. [20] A. Kannan, Y . W u, P . Nguyen, T . N. Sainath, Z. Chen, and R. Prabhav alkar, “ An analysis of incorporating an external lan- guage model into a sequence-to-sequence model, ” arXiv preprint arXiv:1712.01996 , 2017. [21] D. P . Kingma and J. Ba, “ Adam: A method for stochastic opti- mization, ” arXiv preprint , 2014. [22] C. Sze gedy , V . V anhoucke, S. Iof fe, J. Shlens, and Z. W ojna, “Re- thinking the inception architecture for computer vision, ” in Pr o- ceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , 2016, pp. 2818–2826. [23] M. Abadi, A. Agarwal, P . Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. De vin et al. , “T ensorflow: Large-scale machine learning on heterogeneous distributed sys- tems, ” arXiv preprint , 2016. [24] Y . Zhao, S. Xu, and B. Xu, “Multidimensional residual learning based on recurrent neural networks for acoustic modeling, ” Inter- speech 2016 , pp. 3419–3423, 2016.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment