트랜스포머 기반 음절 단위 중국어 자동음성인식
본 논문은 Transformer 구조를 활용해 중국어 만다린 음성 인식 시스템을 구현하고, 음절 단위와 CI‑phoneme 단위를 비교한다. 음절 기반 모델이 CI‑phoneme 기반 모델보다 낮은 문자 오류율(CER)을 달성했으며, 최종 CER 28.77%를 기록해 기존 최첨단 결과와 경쟁한다. 또한 서브워드 → 단어 변환을 위한 greedy cascading decoder를 제안한다.
저자: Shiyu Zhou, Linhao Dong, Shuang Xu
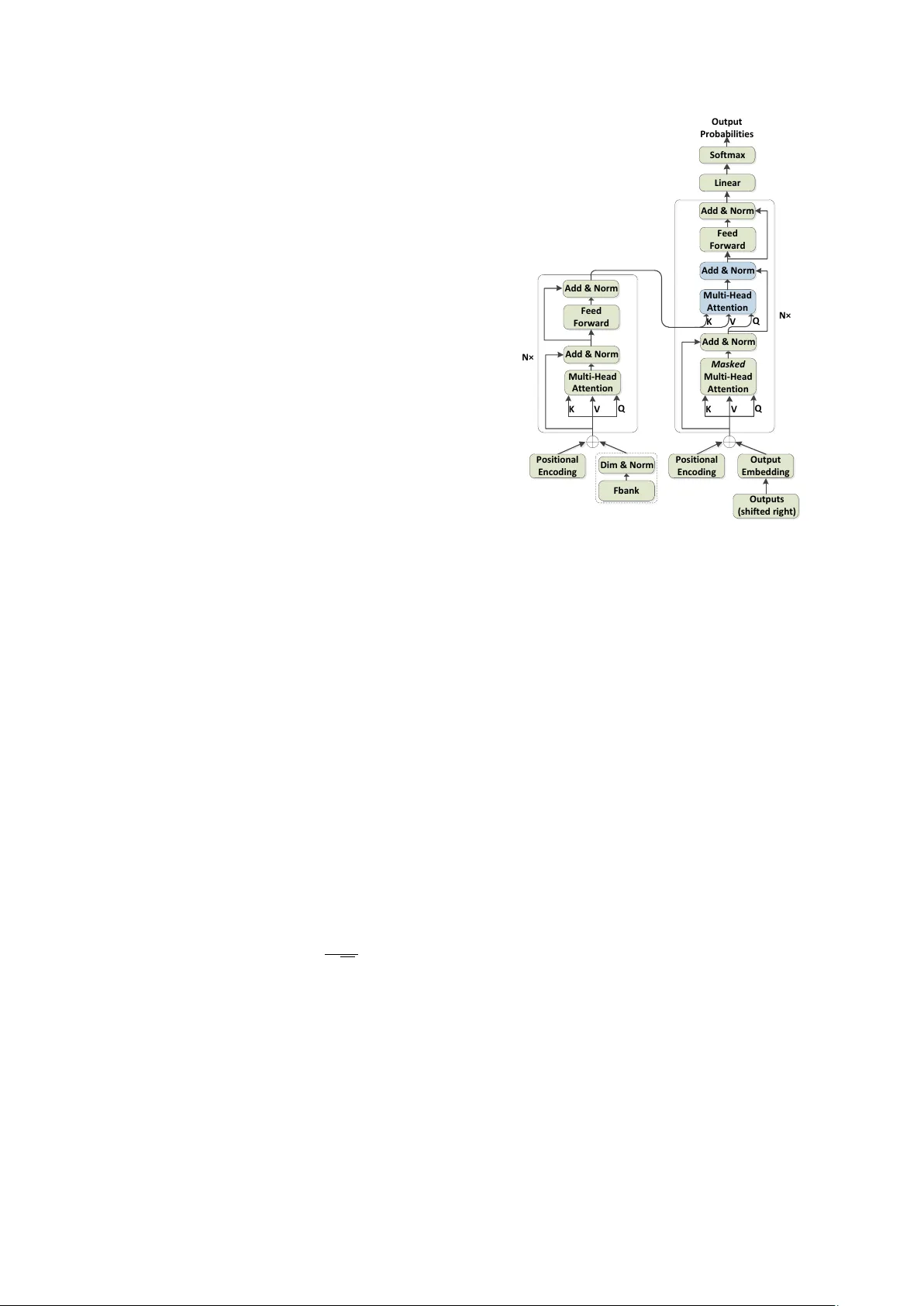
본 논문은 최신 자연어 처리 모델인 Transformer를 중국어 만다린 자동음성인식(ASR) 시스템에 적용하고, 서브워드 단위로 음절과 CI‑phoneme(음소) 두 가지를 비교함으로써 최적의 모델링 단위를 탐색한다. 연구 배경으로, 기존 sequence‑to‑sequence ASR 모델은 인코더와 디코더에 RNN을 사용해 시간 순차적 연산을 수행했으며, 이는 병렬화에 제약을 주어 학습 효율을 저하시켰다. Transformer는 완전한 self‑attention 메커니즘과 포지션 인코딩을 통해 전역적인 종속성을 한 번에 학습하면서도 높은 병렬성을 제공한다는 점에서 ASR에 적용할 경우 큰 이점을 기대할 수 있다.
논문은 먼저 Transformer의 기본 구조를 소개한다. 인코더는 N=6개의 레이어로 구성되며, 각 레이어는 다중 헤드 어텐션(MHA)과 포지션‑와이즈 피드‑포워드 네트워크로 이루어진다. 디코더도 동일한 구조를 갖지만, 추가로 인코더‑디코더 어텐션 서브레이어가 삽입되어 있다. 입력으로는 80차원 log‑Mel 필터뱅크 특징을 사용하고, 선형 변환과 레이어 정규화를 통해 모델 차원(d_model)과 맞춘다. 두 가지 모델 규모를 실험했는데, Base 모델은 d_model=512, 헤드 수 h=8이며, Big 모델은 d_model=1024, 헤드 수 h=16이다. 학습 최적화에는 Adam 옵티마이저와 warm‑up 스케줄, 라벨 스무딩(ε=0.1)을 적용하였다.
서브워드 단위 선택에 있어, 논문은 Mandarin이 음절 기반 언어라는 점을 강조한다. 음절은 약 1400개의 고정된 pinyin+톤 조합으로 구성되며, 각 문자와 1:1 매핑된다. 이는 OOV(Out‑Of‑Vocabulary) 문제를 자연스럽게 해결하고, 디코더가 선택해야 할 후보 수를 줄여 학습을 안정화한다. 반면 CI‑phoneme은 118개의 음소(톤 포함)로 구성되어 더 짧고 변동성이 크다. 두 단위를 각각 출력 vocab으로 설정하고, 추가 토큰(, , , )을 포함해 최종 출력 차원을 122(CI‑phoneme)와 1388(음절)로 정의하였다.
디코딩 단계에서는 서브워드 시퀀스를 단어 시퀀스로 변환하는 별도의 Transformer 모델을 학습시킨 뒤, 두 모델을 연속적으로 적용하는 greedy cascading decoder를 제안한다. 구체적으로, 첫 번째 Transformer는 음성 입력 X를 서브워드 시퀀스 s로 변환하고, beam size β=13을 사용한다. 두 번째 Transformer는 s를 단어 시퀀스 W로 변환하며, beam size γ=6을 적용한다. 이는 P(W|X)≈P(W|s)·P(s|X)라는 근사식을 구현한 것으로, 복잡한 검색 과정을 단순화하면서도 충분한 정확도를 확보한다.
실험은 HKUST 코퍼스(150시간, 873통화 훈련, 24통화 테스트)를 사용했다. 특징 추출은 25 ms 윈도우, 10 ms 스트라이드이며, 현재 프레임을 기준으로 좌우 3프레임을 스택해 30 ms 프레임 레이트로 다운샘플링한다. 데이터 증강으로 speed perturbation(0.9·1.1 배)도 적용했으며, 이는 음절 기반 모델에 긍정적인 영향을 미쳤다.
성능 평가는 문자 오류율(CER)로 측정했다. Base 모델에서는 CI‑phoneme이 32.94%, 음절이 31.80%를 기록했으며, Big 모델에서는 각각 30.65%와 29.87%를 보였다. speed perturbation을 적용한 Big 음절 모델은 최종 CER 28.77%를 달성했으며, 이는 기존 joint CTC‑attention 모델(28.0% CER)과 거의 동등한 수준이다. 반면, 동일 조건의 CI‑phoneme 모델은 30.72%로 약간 악화되었다. 이는 음절이 상대적으로 길고 변동성이 크기 때문에 작은 속도 변형이 발음에 미치는 영향이 적은 반면, 짧은 CI‑phoneme은 더 민감하게 반응한다는 해석이 가능하다.
표 3과 비교했을 때, 음절 기반 Transformer는 기존 9‑layer LSTM 기반 하이브리드 시스템(31.5% CER)보다 약 6% 상대 개선을 보였으며, joint CTC‑attention 네트워크(28.9% CER, 외부 LM 미사용)와도 경쟁한다.
결론적으로, 이 연구는 다음과 같은 주요 기여를 한다. 1) RNN‑free Transformer가 Mandarin ASR에서도 뛰어난 성능을 발휘함을 실증하였다. 2) 음절 단위가 CI‑phoneme보다 더 효율적인 서브워드 표현임을 실험적으로 입증하였다. 3) 서브워드 → 단어 변환을 위한 greedy cascading decoder를 제안해 복잡한 언어 모델 통합 없이도 실용적인 성능을 달성하였다. 향후 연구에서는 더 큰 규모의 데이터와 깊은 Transformer 구조, 그리고 외부 언어 모델(예: Transformer‑LM)과의 결합을 통해 CER를 25% 이하로 낮추는 것이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기