Eventness: Object Detection on Spectrograms for Temporal Localization of Audio Events
In this paper, we introduce the concept of Eventness for audio event detection, which can, in part, be thought of as an analogue to Objectness from computer vision. The key observation behind the eventness concept is that audio events reveal themselv…
Authors: Phuong Pham, Juncheng Li, Joseph Szurley
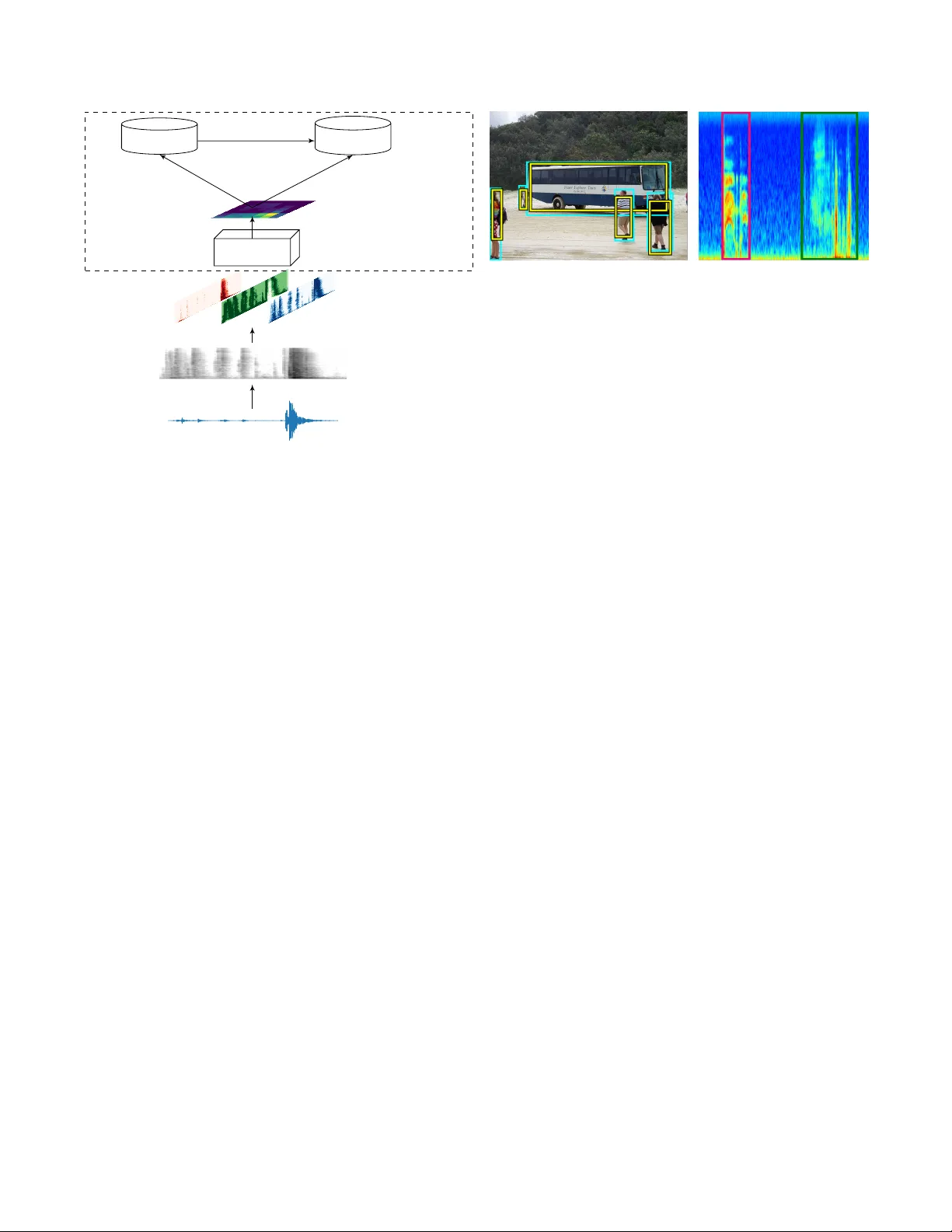
EVENTNESS: OBJECT DETECTION ON SPECTR OGRAMS FOR TEMPORAL LOCALIZA TION OF A UDIO EVENTS Phuong Pham, J uncheng Li, J oseph Szurle y , Samarjit Das phuongpham@cs.pitt.edu, junchenl@cs.cmu.edu, { joseph.szurley ,samarjit.das } @us.bosch.com ABSTRA CT In this paper , we introduce the concept of Eventness for au- dio ev ent detection, which can, in part, be thought of as an analogue to Objectness from computer vision. The key ob- servation behind the eventness concept is that audio ev ents rev eal themselves as 2-dimensional time-frequency patterns with specific textures and geometric structures in spectro- grams. These time-frequency patterns can then be viewed analogously to objects occurring in natural images (with the exception that scaling and rotation in variance properties do not apply). W ith this key observ ation in mind, we pose the problem of detecting monophonic or polyphonic audio e vents as an equi valent visual object(s) detection problem under partial occlusion and clutter in spectrograms. W e adapt a state-of-the-art visual object detection model to ev aluate the audio e vent detection task on publicly av ailable datasets. The proposed network has comparable results with a state-of-the- art baseline and is more robust on minority events. Provided large-scale datasets, we hope that our proposed conceptual model of eventness will be beneficial to the audio signal pro- cessing community to wards improving performance of audio ev ent detection. Index T erms — ev entness, audio ev ent detection, region proposal, time-frequency analysis 1. INTRODUCTION Recently , objectness-based deep learning networks using re- gion proposals hav e achie ved state-of-the-art performance in natural object detection tasks [1, 2, 3, 4]. In [1], a dramatic improv ement in object detection was achiev ed when feeding a con volutional neural network (CNN) with class-agnostic ob- jectness region proposals. This was later exte nd to a so-called MultiBox model [2], which integrated the objectness region proposal component into a deep neural network further im- proving performance. One drawback of these methods, ho wev er , is the large number of parameters utilized for dif ferent features of the region proposals causing a dramatic decrease in processing speed. Ren et al. [3] overcame this decrease in process- ing speed by implementing a so-called Faster R-CNN which shares the feature map between the objectness region proposal and the object classifier . This unification was shown to not only increase the processing speed but also improve perfor- mance. Audio e vent detection has recently been inv estigated from a similar computer vision perspectiv e that exploits the effec- tiv eness of deep CNNs [5, 6]. In order to exploit vision in- spired CNNs for audio ev ent detection, the audio signal is usually conv erted to a 2D time-frequency representation, or spectrogram. By using multiple con v olutional layers [6] or multiple conv olutional groups [5], these computer vision in- spired CNNs hav e become state-of-the-art in terms of perfor - mance for both ev ent detection and classification. In this paper , we borrow from the concept of Object- ness and propose a similar analogue for audio signals termed Eventness . When represented in the time-frequency domain, audio ev ents rev eal themselves as 2D patterns in spectro- grams, where each event has a specific geometric structure. These geometric structures then provide information on how the frequencies that comprise the audio event v ary with time. The patterns in the spectrograms can then be thought of synonymously to objects occurring in natural images. W e therefore look to leverage a number of components from objectness-based deep learning and harness them for temporal localization (detection) of audio ev ents from spectrograms 1 . For our proposed eventness model , we adapt a state-of- the-art object detection netw ork, namely a Faster R-CNN, for audio e vent detection. Audio signals are first conv erted into spectrograms and a linear intensity mapping is used to sepa- rate the spectrogram into 3 distinct channels. A pre-trained vision based CNN is then used to extract feature maps from the spectrograms, which are then fed into the Faster R-CNN. It should be noted that while the feature maps produced by the pre-trained vision based CNN aim to detect objects in natu- ral images, they can also be employed in a similar fashion to detect 2D patterns that are present in spectrograms. T o the best of our knowledge, this is the first time au- dio event detection, or temporal localization, has been ap- proached from a vision-inspired angle, i.e., objectness in au- dio spectrograms. Compared to other CNN based audio e vent detection models, ours differs in at least two aspects. First, we propose the regions of ev ents directly instead of infer- 1 W e note that the same rotation and scale in variance properties of natural images do necessarily translate to the audio domain. Raw audio signal Mel-spectrogram VGG-16 Colormap Output feature map RPN Classifier Region Proposals Event Classifier Region Proposal Network Fig. 1 : The en visaged ev entness model. ring these v alues based on: the concatenation of heuristics via merging same-class neighbors [7] [8], performing sequence labeling using HMM and V iterbi algorithms [9] [10], or es- timating the distance between the current time and the onset and of fset of the e vent [11]. Second, previous models use small temporal windows, typically between 25 ms − 100 ms , [7, 8, 9, 10, 11] which may not capture complete non-speech ev ents [12]. Therefore we use large temporals windows on the order of seconds or tens of seconds. W e ev aluate the model on publicly av ailable datasets, namely the UrbanSound8k [13] and the 2017 Detection and Classification of Acoustic Scenes and Events (DCASE)[14] both qualitati vely and quantitatively . In the qualitativ e anal- ysis we e xamine the ability of the proposed model to exploit both temporal and spectral content for region proposals, e ven for ov erlapping e vents. In the quantitativ e analysis, we com- pare both the proposed model and state-of-the-art baseline showing that comparable performance is achie ved along with a robustness to infrequent e vents. 2. THE EVENTNESS MODEL Figure 1 shows the envisaged model where audio signals are first con verted into log-scaled mel-spectrogams. A feature map is then created by passing the log-scaled mel- spec- trogram through a pre-trained CNN based on the VGG-16 model. This feature map is then fed to a Faster R-CNN consisting of two main components: an RPN and an e vent classifier , which will be described in Section 2.2 and 2.3 respectiv ely . It should be noted that the RPN and e vent classifier then use the same resulting feature map from the output of the pre-trained VGG-16 CNN to generate the region proposals and classify the audio ev ent. Fig. 2 : Objectness proposals in an natural image (left) and audio eventness proposals in a spectrogram image (right). 2.1. Spectrogram and feature map generation The raw audio signals are first segmented into long time windows of length T and con verted to log-scaled mel- spectrograms. The resulting log-scaled mel-spectrograms are then normalized in the range [0,1] and a linear inten- sity segment mapping is used to separate the the original spectrogram into 3 distinct channels. W e note that this map- ping is the same process used to map greyscale image to a higher dimensional space, i.e., a colormap, which in [15] w as shown to outperform single channel inputs of CNN based audio event classifiers. Other mappings have been proposed based on both the first- and second-order differences of the log-scaled mel-spectrograms, the so-called delta and delta- delta coef ficients [5, 6]. Ho we ver , in our experiments, the previously described linear intensity segment mappings hav e shown better performance. The linear intensity segment mapping effecti vely quan- tizes the original spectrogram based on the spectral intensi- ties, where strong spectral values will be more prominent in one channel while weak spectral values will be prominent in another . W e hypothesize that the subtle shapes introduced by this mapping can be better e xploited in the con v olutional lay- ers in the network. The resultant 3-channel spectrogram map- ping w as then fed into a pre-trained VGG-16 CNN to pro- duce a feature map. Only the con volutional layers are used from the pre-trained VGG-16 CNN, i.e., we discard the fully connected and classification layers. 2.2. Regional Proposal Network (RPN) The RPN in the proposed model uses anchors to generate multiple region proposals based on the output feature map of the pre-trained VGG-16 CNN. In particular, at each loca- tion of the feature map, the RPN will generate multiple re- gion proposals at different scales and aspect ratios. The intu- ition behind using this anchor approach is that an estimate of a complete object can be inferred e ven under partial observation or occlusion, e.g., in the left image of Figure 2 ev en though the bus is occluded by pedestrians, the RPN still generates a full proposal o ver the entire b us. This can then directly be translated to ov erlapping audio ev ents in both the time and frequency domain. Furthermore, the anchors from the RPN will generate e ventness proposals using both the temporal and spectral content as shown in the right image of Figure 2. 2.3. Event Classifier The event classifier employs a Region of Interest (RoI) pool- ing layer [16] to extract and normalize region proposals from the RPN. The RoI pooling layer performs a similar operation to a conv entional max-pooling layer , except that it can take inputs of non-uniform sizes to obtain fix ed-size feature maps. By focusing only on the re gion proposals provided by the RPN, the classifier can ignore other noisy (unimportant) areas of the feature map. Besides classifying the audio ev ent, this component also refines the region bounding box. The allows for a more accurate bounding box which is deri ved from a lar ger view of the ev ent instead of only one location in the feature map. The event classifier then uses a final softmax layer to predict the audio ev ent. 3. EXPERIMENT AND RESUL TS 3.1. Datasets and Perf ormance Metrics From a gi ven audio file, lar ge audio se gments ( T = 15 s from the UrbanSound8K dataset and T = 10 s from the DCASE 2017 dataset) were first extracted. 128-band log-scaled mel- spectrograms were generated from the audio segments with a window size of 2048 and hop length is 1024. Feature maps were then generated as described in Section 2.1 and fed to t he the RPN and classifier . The RPN then used 9 anchors at each location on the feature map to generate multiple eventness proposals. The performance metrics are used on either a segment based or event based level [14]. The segment-based met- rics, F 1 ,S B score and error rate denoted as E R S B , are used to compare the predicted events to the ground truth labels of seg- ments that are one second long. The same metrics are applied for ev ent-based metrics, F 1 ,E B score and error rate denoted as E R E B , which compare the amount of ov erlap between the predicted e vent and the ground truth labels. The definitions of the error rates are as follow: E R S B = max( N ref , N sy s ) − T P N ref E R E B = F N + F P N ref where N ref is total number of predicted events, N sy s is total number ground truths ev ents, and T P , F P , and F N are the number of true positiv es, false positiv e, and false ne gativ es respectiv ely . Mel-band Frequencies T ime 0 15 0 128 (a) 0 15 (b) 0 15 (c) 0 15 0 128 (d) 0 15 (e) 0 15 (f) 0 15 0 128 (g) 0 15 (h) 0 15 (i) Fig. 3 : Region proposals of se v eral audio ev ents for (a) siren, (b) car horn , (c) gun shot, (d) jackhammer , (e) dog bark, (f) car horn with dog bark, (g) gun shot with dog bark, (h) dog bark with siren, (i) dog bark with dog bark. 3.2. Qualitative Evaluation W e perform a qualitati ve analysis of the proposed model on the UrbanSound8K dataset which consists of more than 8000 audio clips comprised of 10 classes. W e select 5 target classes having good performance in a pilot experiment out of 10 classes, specifically: car horn, dog bark, gunshot, siren, and jackhammer . W e then randomly embed one or two e vents from these classes with background noise from the DCASE 2016 (task 3) [17] dataset which is meant to mimic multi- source conditions. This produced, in total, 5000 training clips and 3000 testing clips, with 30% being polyphonic. Figure 3 shows 5 monophonic spectrograms, i.e. siren (a), car horn (b), gun shot (c), jackhammer (d), and dog bark (e), and 4 polyphonic spectrograms, i.e. car horn-dog bark (f), gun shot-dog bark (g), dog bark-siren (h), and dog bark- dog bark (i). The Figure also has an o verlay of the region proposals where the areas surrounded by the green boxes are the ground truth labels and the areas surrounded by red box es are the predicted labels. The darker the shade of red indicates a higher confidence lev el of the prediction. In general, the region proposals are able to capture the audio ev ents with a very fine temporal resolution. In Fig- ure 3 (a), besides correctly identifying the siren audio event, the eventness model surprisingly detected another audio e v ent that was erroneously omitted from the ground truth labels. Furthermore in Figure 3 (g) the ev entness model detects an audio ev ent that is corrupted by noise and again erroneously omitted from the ground truth labels. In Figure 3 (h), the ev entness model detects ev ents with T able 1 : Performance of the ev entness model on the Urban- Sound8K dataset. Metric Car horn Dog bark Gun shot Jackhammer Siren Overall F 1 ,E B 0.86 0.61 0.79 0.75 0.55 0.71 E R E B 0.27 0.81 0.40 0.52 0.70 0.54 different temporal lengths, i.e., the dog bark ev ent is shorter than the siren e vent and can differentiate between partially ov erlapping ev ents. Furthermore, the proposed model also provides region proposals based on the spectral content, as noticed by their sizes in along the frequency axis, i.e., the vertical size of the bounding box is dif ferent for each unique ev ent. In Figure 3 (i), the same audio e vent occurs with some ov erlap. Remarkably , the ev entness model extrapolates this as a single e vent. This is a direct result of using larger tempo- ral windows as the eventness model has a larger global view when compared to other work using smaller temporal win- dows. 3.3. Quantitative Evaluation W e quantitati v ely e v aluate the eventness model on the Urban- Sound8k dataset as described in Section 3.2 and the DCASE 2017 task 3 dataset. The DCASE dataset is pre-divided into 4 folds, where we select the first fold for testing and synthe- size 10s audio clips from the remaining folds which contain 11,260 clips in total) 2 . Synthesized clips are generated by ran- domly assigning one or two annotated e vents with the back- ground noise (audio portion having no ground truth annota- tions) from the DCASE 2017. Even when we select an ev ent to synthesize, the selected event is usually ov erlapped with some other ev ents due to the natural recording en vironment. Audio clips in the test set are kept unchanged. T able 1 sho ws both the F 1 ,E B and E R E B for the Urban- Sound8k dataset. W e see that the ev entness model has a high F1 score, meaning it has both good recall and precision and a low error rate. T able 2 shows the performance of the proposed event- ness model and the baseline model provided by DCASE 2017 which utilizes a 2 layer neural network with small temporal windows, T = 40 ms . It can be seen that the e ventness model outperforms the baseline in ev ent-based metrics but not in segment-based metrics. This is due to the e v entness model fo- cusing on larger temporal segments which capture the entire ev ent whereas the baseline lev erages smaller temporal seg- ments which are better suited for segment-based tasks. Interestingly , the ev entness model exhibits more robust- ness to infrequent events when compared to the baseline model. The third event class, children is the least frequent 2 Even though ev aluation was performed on a single fold, we expect that performing 4 fold cross validation result would not significantly impact the accuracy . T able 2 : Performance on DCASE 2017. The reported num- bers are in the following format E R and ( F 1 ) Event class Segment-based Event-based Baseline Eventness Baseline Eventness Brakes squeaking 1(0) 0.97(0.29) 1(0) 1.75(0) Car 0.86(0.69) 1.12(0.61) 2.66(0.05) 1.55(0.04) Children 5.45(0) 1.86(0) 13(0) 2.18(0) Large v ehicle 1.15(0.31) 1.36(0.28) 5.92(0.03) 3.31(0) People speaking 1.34(0.03) 1.01(0.10) 3.47(0) 1.2(0.08) People walking 1.07(0.28) 1.08(0.25) 3.88(0.04) 1.81(0.03) Overall 0.95(0.45) 1.02(0.42) 3.53(0.03) 1.78(0.03) classes in the dataset and the error rate using the e ventness model has superior performance, although both models have similar F1 scores. 4. CONCLUSIONS AND FUTURE WORK W e proposed the concept of e ventness for audio e vents de- tection by utilizing a vision inspired CNN. Sharing similar characteristics with its vision based counterpart objectness in natural object detection, ev entness can lev erage components from natural object detection to detect audio e vents present in spectrograms. W e e v aluated a Faster R-CNN adaptation for audio data in a qualitative experiment and a quantitativ e experiment. The results showed that the proposed eventness model detected audio ev ents in spectrogram images compara- ble with the baseline model. Moreover , the eventness model is more robust to classifying infrequency ev ents. Qualitativ e results also sho wed that the e ventness model can e xploit both the temporal and spectral content of the audio ev ents. The work in this paper is a proof-of-concept for the e vent- ness model. In the future, there are sev eral other modifica- tions or research directions that will be explored. First, the feature maps are generated from a VGG-16 CNN that was pre-trained on the ImageNet dataset meaning that they are tailored to natural image representations. Recently , the Au- dioSet dataset [18] has been released with millions of audio clips thereby allowing for a CNN to be trained on purely au- dio data and removing the natural image representations in- herent in the feature maps. Other models to generate feature maps will also be explored that are not limited to the VGG- 16 model. Second, the current RPN using all locations on the feature map to generate proposals. Howe ver , the event- ness model itself can determine areas on the spectrogram with the highest importance for the classification task. W e there- fore propose to use attention based models [19] to automat- ically learn the proposals. Finally , we would like to modify the model such that a true end-to-end representation can be learned, i.e., where only the raw audio files are used as input instead of spectrograms as input to the Faster R-CNN. 5. REFERENCES [1] Ross Girshick, Jef f Donahue, Tre v or Darrell, and Jiten- dra Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation, ” in Pr oc. of the IEEE Conf. on Computer V ision and P attern Recogni- tion (CVPR) , 2014, pp. 580–587. [2] Christian Szegedy , Scott Reed, Dumitru Erhan, and Dragomir Anguelov , “Scalable, high-quality object de- tection, ” T ech. Rep., arXi v , 2015. [3] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun, “F aster R-CNN: T owards real-time object detec- tion with region proposal networks, ” in Advances in Neural Information Pr ocessing Systems (NIPS) , 2015. [4] Joseph Redmon, Santosh Di vv ala, Ross Girshick, and Ali Farhadi, “Y ou only look once: Unified, real-time object detection, ” in Pr oc. of the IEEE Conf. on Com- puter V ision and P attern Recognition (CVPR) , 2016, pp. 779–788. [5] Naoya T akahashi, Michael Gygli, Beat Pfister , and Luc V an Gool, “Deep conv olutional neural networks and data augmentation for acoustic e vent detection, ” in Pr oc. of INTERSPEECH , 2016, pp. 2982–2986. [6] Karol J. Piczak, “En vironmental sound classification with conv olutional neural networks, ” in Proc. of the IEEE Int. W orkshop on Machine Learning for Signal Pr ocess. (MLSP) , 2015, pp. 1–6. [7] Axel Plinge, Rene Grzeszick, and Gernot A Fink, “ A bag-of-features approach to acoustic e vent detection, ” in Pr oc. of the IEEE Int. Conf. on Acoustics, Speec h and Signal Pr ocess. (ICASSP) . IEEE, 2014, pp. 3704–3708. [8] Emre Cakir, T oni Heittola, Heikki Huttunen, and Tuo- mas V irtanen, “Polyphonic sound event detection using multi label deep neural networks, ” in Pr oc. of the IEEE Int. Joint Conf . on Neural Networks (IJCNN) , 2015, pp. 1–7. [9] Annamaria Mesaros, T oni Heittola, Antti Eronen, and T uomas V irtanen, “ Acoustic e vent detection in real life recordings, ” in Proc. of the Eur opean Signal Pr ocess. Conf. (EUSPICO) , 2010, pp. 1267–1271. [10] Jort F Gemmeke, Lode V ue gen, Peter Karsmakers, Bart V anrumste, et al., “ An exemplar -based NMF approach to audio event detection, ” in Pr oc. of the IEEE W ork- shop on Applications of Signal Pr ocess. to Audio and Acoustics (W ASP AA) , 2013, pp. 1–4. [11] Huy Phan, Marco Maaß, Radosla w Mazur, and Alfred Mertins, “Random regression forests for acoustic event detection and classification, ” IEEE/ACM T rans. on Au- dio, Speech, and Languag e Pr ocess. , v ol. 23, no. 1, pp. 20–31, 2015. [12] Y uji T okozume; T atsuya Harada, “Learning environ- mental sounds with end-to-end conv olutional neural net- work, ” in IEEE SigP ort , 2017. [13] Justin Salamon, Christopher Jacoby , and Juan Pablo Bello, “ A dataset and taxonomy for urban sound re- search, ” in Pr oc. of the ACM Int. Conf. on Multimedia (A CM MM) , 2014, pp. 1041–1044. [14] Annamaria Mesaros, T oni Heittola, Aleksandr Diment, Benjamin Elizalde, Ankit Shah, Emmanuel V incent, Bhiksha Raj, and T uomas V irtanen, “DCASE 2017 challenge setup: tasks, datasets and baseline system, ” in Pr oc. of the Detection and Classification of Acoustic Scenes and Events W orkshop (DCASE) , 2017. [15] Jonathan Dennis, Huy Dat Tran, and Haizhou Li, “Spec- trogram image feature for sound ev ent classification in mismatched conditions, ” IEEE Signal Pr ocess. Letters , vol. 18, no. 2, pp. 130–133, 2011. [16] Ross Girshick, “Fast R-CNN, ” in Pr oc. of the Int. Conf . on Computer V ision (ICCV) , 2015. [17] Annamaria Mesaros, T oni Heittola, and T uomas V irta- nen, “TUT database for acoustic scene classification and sound event detection, ” in Pr oc. of the European Signal Processing Confer ence (EUSIPCO) . IEEE, 2016, pp. 1128–1132. [18] Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, W ade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter, “ Audio set: An on- tology and human-labeled dataset for audio ev ents, ” in Pr oc. of the IEEE Int. Conf. on Acoustics, Speec h and Signal Pr ocess. (ICASSP) , 2017. [19] Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al., “Spatial transformer networks, ” in Advances in Neural Information Pr ocessing Systems (NIPS) , 2015, pp. 2017–2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment