스펙트로그램 기반 오디오 이벤트 검출을 위한 이벤트니스 개념
본 논문은 오디오 이벤트를 2차원 시간‑주파수 패턴으로 바라보고, 이를 이미지 객체 검출과 유사한 “이벤트니스(eventness)” 개념으로 정의한다. 로그‑멜 스펙트로그램을 3채널 이미지로 변환한 뒤, 사전학습된 VGG‑16 특징 추출기와 Faster R‑CNN을 결합해 이벤트의 위치와 종류를 동시에 예측한다. UrbanSound8K와 DCASE 2017 데이터셋에서 기존 베이스라인과 비슷한 성능을 보이며, 특히 소수 클래스에 대한 강인성을 …
저자: Phuong Pham, Juncheng Li, Joseph Szurley
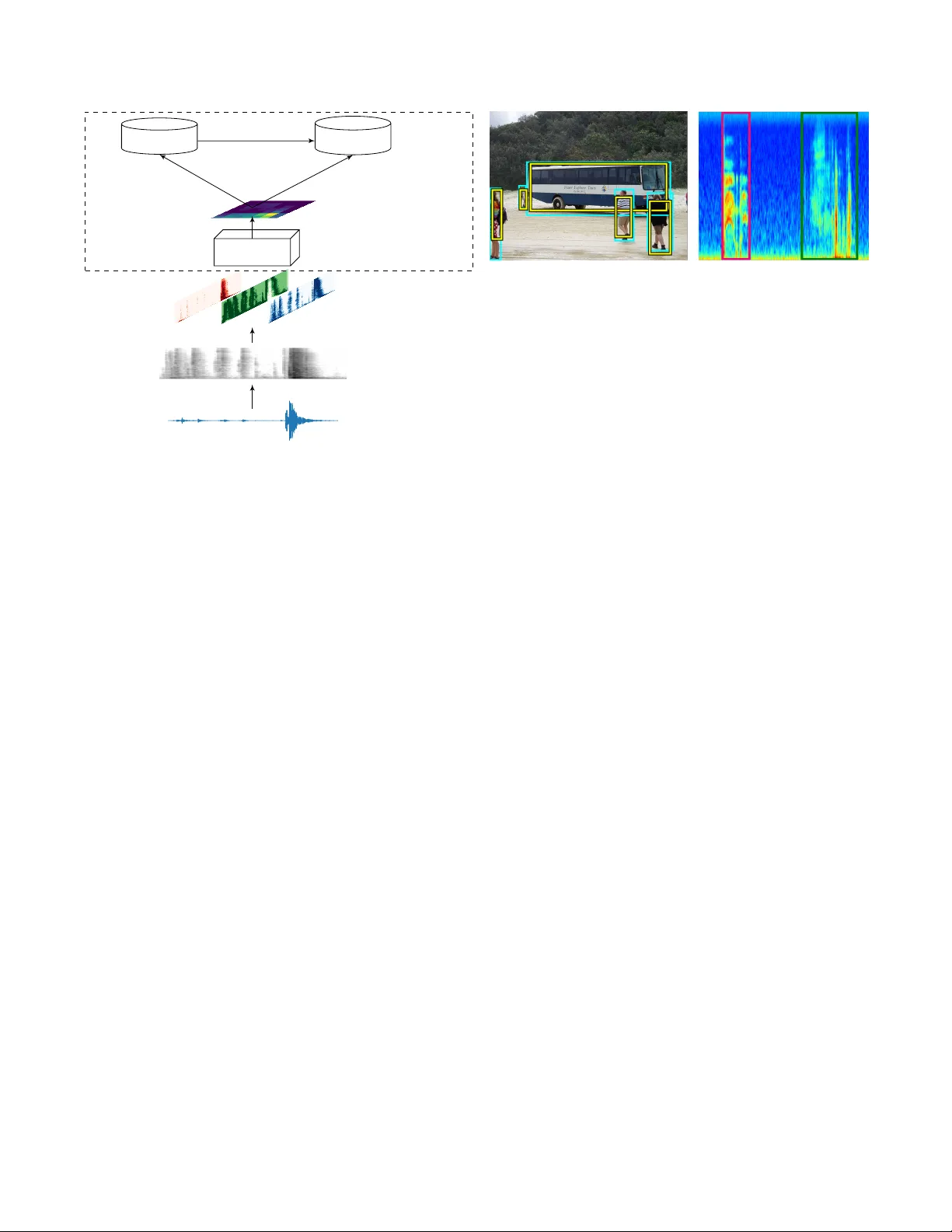
본 논문은 오디오 이벤트 검출을 이미지 객체 검출과 유사한 “이벤트니스(eventness)”라는 새로운 개념으로 정의하고, 이를 실제 시스템에 적용한 결과를 제시한다. 이벤트니스는 오디오 신호가 시간‑주파수 영역, 즉 스펙트로그램 상에서 2차원 패턴으로 나타난다는 관찰에 기반한다. 이러한 패턴은 텍스처와 기하학적 구조를 가지고 있어, 자연 이미지에서 객체가 갖는 특징과 유사하다고 본다. 다만 스펙트로그램은 회전·스케일 불변성이 적용되지 않으며, 시간 축과 주파수 축이 각각 의미를 갖는다.
시스템 파이프라인은 다음과 같다. 먼저 원시 오디오를 15 초(UrbanSound8K) 혹은 10 초(DCASE 2017) 길이의 긴 윈도우로 분할하고, 128‑밴드 로그‑멜 스펙트로그램을 생성한다. 생성된 스펙트로그램은 0‑1 정규화 후 선형 강도 구간 매핑을 통해 3채널 이미지로 변환한다. 이 3채널 스펙트로그램은 사전학습된 VGG‑16 CNN의 컨볼루션 레이어에 입력되어 특징 맵을 만든다. 여기서 완전 연결층은 사용되지 않는다.
특징 맵 위에 Faster R‑CNN의 Region Proposal Network(RPN)를 적용한다. RPN은 각 위치마다 9개의 앵커(다양한 스케일·비율)를 사용해 잠재적인 이벤트 영역을 제안한다. 앵커 기반 제안은 부분 가림이나 중첩된 이벤트에도 강인하게 동작하도록 설계되었다. 제안된 영역은 RoI 풀링을 통해 고정 크기 특징으로 변환되고, 이후 두 개의 헤드가 동시에 작동한다. 하나는 이벤트 종류를 softmax로 분류하고, 다른 하나는 경계 박스를 미세 조정한다.
실험은 두 가지 데이터셋을 사용했다. 첫 번째는 10 클래스, 8000개 이상의 클립을 포함하는 UrbanSound8K이며, 여기서 저자는 5개 클래스를 선택해 배경 잡음과 섞인 합성 데이터를 5000개(학습)와 3000개(테스트) 생성했다. 두 번째는 DCASE 2017 Task 3 데이터로, 4‑fold 중 첫 번째 폴드를 테스트용으로 사용하고 나머지 폴드에서 10 초 길이의 합성 클립을 만든다.
정량 평가에서는 이벤트 기반 F1 점수와 오류율(ER)을 주요 지표로 사용했다. UrbanSound8K에서 제안 모델은 전체 평균 F1 = 0.71, ER = 0.54를 기록했으며, 특히 소수 클래스(예: 사이렌)에서 높은 ER을 보였다. DCASE 2017에서는 기존 2‑layer NN 기반 베이스라인보다 이벤트 기반 F1과 ER에서 우수했지만, 세그먼트 기반 지표에서는 짧은 윈도우 모델에 비해 다소 낮은 성능을 보였다. 이는 긴 윈도우가 전체 이벤트를 포괄적으로 캡처하는 데 초점을 맞추었기 때문이다.
정성적 분석에서는 스펙트로그램 상에 제안된 영역이 시간 축과 주파수 축 모두에서 정확히 이벤트를 둘러싸는 것을 확인했다. 예를 들어, 사이렌과 개 짖음이 겹치는 경우에도 모델은 서로 다른 주파수 대역을 반영한 박스를 제시했으며, 동일 이벤트가 중첩될 때는 하나의 박스로 통합하는 경향을 보였다. 이는 긴 윈도우가 전역적인 시야를 제공함으로써 가능해진다.
논문의 한계로는 특징 추출기에 이미지 전용 VGG‑16을 사용했다는 점이다. 이는 스펙트로그램 고유의 주파수‑시간 패턴을 완전히 반영하지 못할 가능성을 내포한다. 저자들은 향후 AudioSet 등 대규모 오디오 전용 데이터셋으로 사전학습된 CNN을 활용하거나, 완전한 엔드‑투‑엔드 구조(원시 오디오 → 직접 특징 학습 → 이벤트 검출)로 전환하는 방안을 제시한다. 또한 RPN 대신 주의(attention) 메커니즘을 도입해 보다 효율적인 영역 제안을 기대한다.
결론적으로, 이벤트니스는 오디오 이벤트 검출에 시각적 객체 검출 기술을 성공적으로 적용한 사례이며, 특히 소수 클래스에 대한 강인성과 시간‑주파수 복합 정보를 활용한 정밀한 영역 제안에서 장점을 보인다. 앞으로 더 큰 규모의 오디오 데이터와 최신 딥러닝 기법을 결합한다면, 이벤트니스 기반 시스템은 실시간 복합 환경에서의 오디오 인식 성능을 크게 향상시킬 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기