Articulatory information and Multiview Features for Large Vocabulary Continuous Speech Recognition
This paper explores the use of multi-view features and their discriminative transforms in a convolutional deep neural network (CNN) architecture for a continuous large vocabulary speech recognition task. Mel-filterbank energies and perceptually motiv…
Authors: Vikramjit Mitra, Wen Wang, Chris Bartels
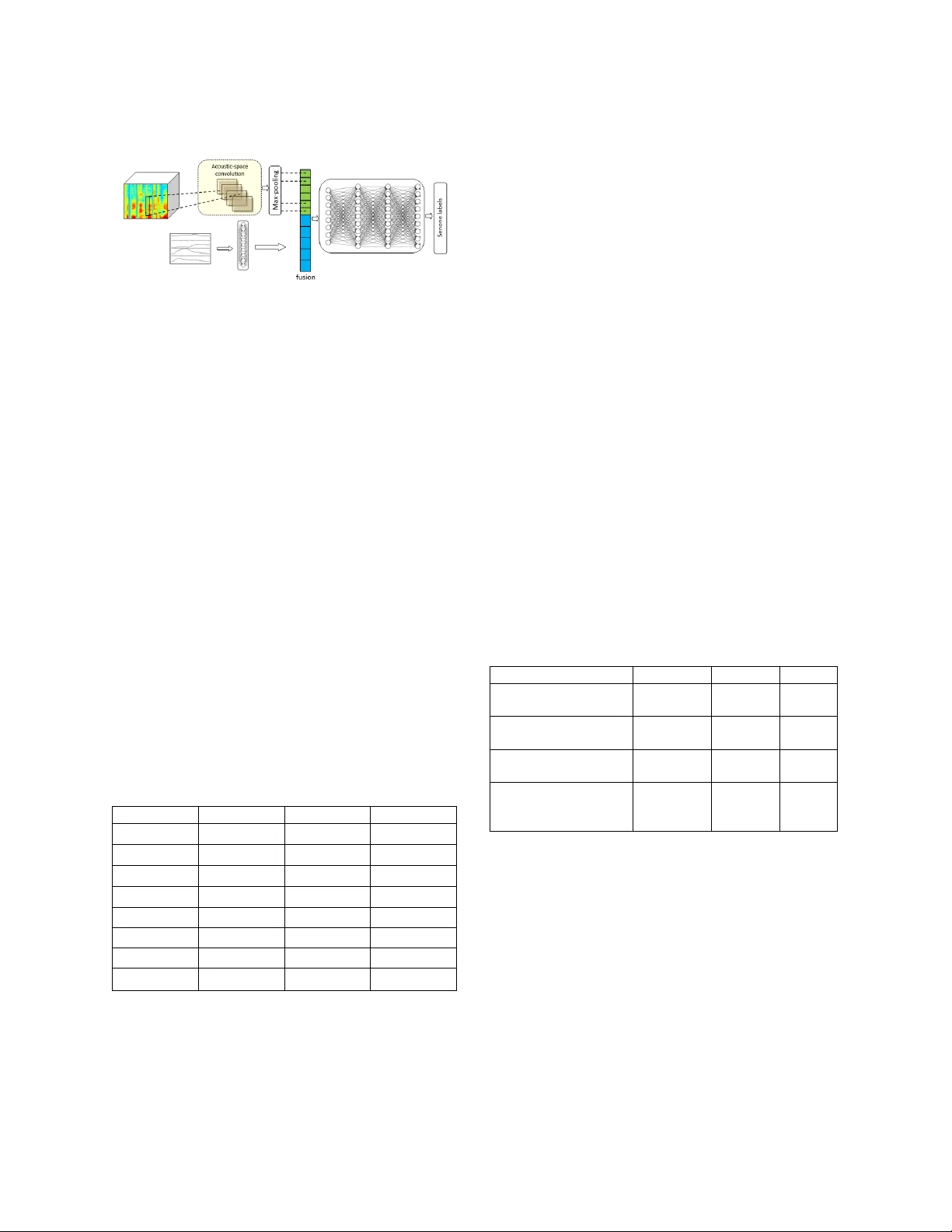
ARTICULATORY INFORMATION AND MULTIVIEW FEATURES FOR LARGE VOCABULARY CONTINUOUS SPEECH RECOGNITION Vikramjit Mitra * , Wen Wang, Chris Bartels, Horacio Franco, D imitra Vergyri University of M aryland , College Park, MD , U SA Speech Technolog y and Research Lab oratory, SRI International, Menlo Park, C A, USA vmitra@umd.edu, {w en.w ang, chris.bartel s, horacio.franco, dim itra.vergy ri }@sri.com ABSTRACT This paper ex plores the use of m ulti-view features and their discriminative transforms in a convolutional deep neural network (CNN) architecture for a continuous large vocabulary speech recognition task. Mel-filterbank ener gies and perceptually motivated forced damped oscillator coefficient (DOC) features ar e used after f eature-space maximum-likelihood linear reg ression (fMLLR) transforms, which ar e combined and f ed as a multi-view feature to a single CNN acoustic model. Use of multi-view feature r epresentation demonstrated s ignificant r eduction in word error rates (WERs) co mpared to the u se of individual features by themselves. In addition, when articulatory information was used as an additional inpu t to a fused deep neural network (DNN) and CNN acoustic model, it was found to demonstrate further redu ction in WER for the Switchboard subset and the CallHome subset (containing partly non -native acce nted speech) of the NIST 2000 conversational telephone speech test set, reducing th e error rate b y 12 % relative to the baseline in both cases. This work shows that m ulti-view features in association with articulatory information can im prove speech recognition robustness to spontan eous and non-native speech . Index Terms — multi-view features, feature c ombination, large vocabulary continuous speech recognition, robust speech recognition, articulatory features 1. INTRODUCTION Spontaneous speech ty picall y contains a signif icant amount of variation, which makes it difficult to model in automatic speech recognition (ASR) systems. Such variability stems from varying speak ers, pronu nciation variations, speaker stylistic differences, varying recording conditions and man y other factors. Recognizing words from conversational telephone s peech (CTS) can b e quite difficult due to the spontaneous nature o f sp eech, its informality, sp eaker variations, hesitations, disfluencies etc. The Switch board and Fisher [ 1] data co llections are lar ge collection of CTS datasets that hav e been used extensively by researchers working on conversational speech recognition [2, 3, 4, 5, 6 ]. Recent trends in speech recognition [7 , 8 , 9] have demonstrated impress ive performance on Switchboard and Fisher data. Deep neu ral network (DNN) b ased acoustic modeling has become the state- of -the-art in automatic speech recognition (ASR) systems [ 10 , 11 ] . I t has demonstrat ed impressive performance gains for almost all tried languages and _________ __________________ __________________ ______________ *The author perf ormed this wor k while at SRI Intern ational and is currently worki ng at Apple Inc. acoustic conditions. Ad vanced variants of DNN s , such as convolutional neural nets (CN Ns) [ 12 ], recurrent neural nets (RNNs) [ 13 ], l ong short-term memor y n ets (LSTMs) [ 14 ], time-delay neura l nets (TDNNs) [ 15 , 29], VGG -nets [8], have significan tly improved recognition perfo rmance , bringing them clos er to hu man perfo rmance [ 9]. Both abundance of data and sophistication of deep learning algorithms have symbiotically contributed to the advancement of speech recognition performance. The role of acoustic features has not been explored in comparable detail, and their po tential contribution to p erformance gains is unknown . This paper focus es on acoustic features and investigates how th eir select ion improves recognition performance using benchmark training datasets: Switchboard and F isher, when evaluated on the NIST 2000 CTS test set [2] . We in vestigated a t raditional CNN model and explored the following: (1) Use of multiple features both in isolation and in combination. (2) Explored different ways of using the feature space maximum-likelihood regression (fMLLR) transf orm, where we t ried (a ) learning the fMLLR tr ansforms directly using the filterb ank features and (b) lear ning the fMLLR transform on the cepstral version o f the features and then p erforming inverse d iscrete cosine transfo rm (IDCT) o n the fMLLR features to generate the fMLLR version of filterbank features. (3) I nvestigated the use of articulato ry features , wh ere the features represent a time series definition of how the vocal tract shape and constrictions change over time. Our experiments demonstrated th at the use of f eature combination s helped to improve p erformance over individual f eatures in isolation an d over traditionally used mel-filterbank (MFB) features . Articulatory features were found to be useful for improving recognition performance on both Switchboard and CallHome su bsets of the NI ST 2000 CTS test set. These findings indicate that the use of better aco ustic features can help improve speech recognition performance wh en using standard acoustic modeling tech niques, and can demonstrate p erformance as good as those ob tained from more sophisticated acou stic models th at exploit temporal memory. F or th e sake of simplicity, we u sed a C NN acoustic model in our experiment, where the baseline system ’ s performance is directly comparable to the state - of -the-art CNN performance rep orted in [8] . We expect our results using the CNN to carry o ver in to other neural network architectures as well. The outline of the pap er is as follows . I n Section 2 we present the dataset and t he recognition task . I n Section 3 we describe the acoustic features and the articulatory features that were used in ou r experiments. Section 4 present s the acoustic and language models used in our ex periments, followed b y experimental results in Sectio n 5 and conclusion and future directions in Section 6. 2 . DATA AND TASK The acoustic models in our experiments were train ed usin g the CTS Switchbo ard (SWB) [16] and Fisher (FSH) corpora . W e f irst investigated contribu tions of the features on models trained only with the SWB dataset, where the training data consisted of ~360 hours of speech d ata. We then evaluated the contributions of the features using acoustic models trained with a combination of both SWB and FSH (~20 00 hours). The mo dels were evaluated using the NIST 2000 CTS test set , wh ich consists of 2.1 hours (21.4K words, 40 speakers) of SWB audio and 1.6 hou rs (21.6K words, 40 sp eakers) of th e CallHome (CH) audio. The language model training da ta include d 3M words fro m Switchboard, CallHome, and Switchboard C ellular transcripts, 20M words f rom Fisher transcripts, 1 50M words from Hub4 bro adcast news transcrip ts an d language model training data, and 191M wo rds of “conversational” text retrieved from the Web b y searching for conversational n-grams extracted f rom the CTS transcripts [25]. A 4 -gram language model (LM) was generated b ased on word probability estimates f rom a SuperARV language model, which is a class-based language model with classes derived from Constraint Dependency Grammar parses [26]. F or first pass decoding the 4-gram LM was pruned to improve efficiency, and the full 4-gra m LM was used to rescore lattices generated from the first pass . 3 . FEATURES We us ed mel-filterbank ener gies (MFBs) as the baseline feature, where the features were generated using the implementation distributed with the Kaldi toolkit [ 17 ]. The second acou stic feature was Damped Oscillator Coefficients (DOCs) [18]. The DOC features model t he auditory hair cells using a bank of f orced damped oscillators, where g ammatone filtered band-limited subband speech signals are used as the forcing function. The oscillation energy f rom the damped oscillators was used as the DOC features after po wer-law compression. We perform ed the fMLLR transform on the acoustic features, wh ere we trained Gauss ian Mixture Models (GMMs) to generate alignments on the training dataset to learn the fMLLR transf orm for the f eature sets. We investigated two approaches: (1) we directly learned the fMLLR transf orms on th e 40 -dimensional filterb ank features , and (2) we investigated learning the f MLLR transform using the cepstral version of the f eatures. The cepstral version of the f eatures helps d ecorrelate the features, which in turn adheres to the diagonal co variance assumption of the GMMs. I n (2) the fMLL R transform wa s learned using 40 dimensional cepstral featu res (us ing all the cepstral dimensions extracted from 40 dimensional filterbanks). After the fMLL R transform was performed , an IDCT of th e features was obtained to generate the f MLLR version of filterbank featur es. The articulato ry features were estimated using the CNN system described in [19, 20], where the CNN performs speech- to -articulatory inversion or simply sp eech - inversion. Du ring speech -inversion, the acoustic features extracted from th e speech signal, in this case modulation features [19] , are used to predict the articulatory trajectories. The articulato ry f eatures contain time do main articulatory trajectories, with eight dimensions reflecting: glottal aperture, velic openin g, lip apertu re, lip p rotrusion , tongue tip location and degree, to ngue bod y locatio n and degree. More details regarding the articulatory features and their extraction are provided in [ 19 ]. 4. RECOGNITION SYSTEM We trained CNN acou stic models for the speech recognition tasks. To generate the alignments necessary for training the CNN system, a Gaussian Mixture Model - Hidden Markov Model (GMM-HMM ) based acoustic model was f irst trained with flat-start, which was used to produce the senone labels. Altogether, the GMM-HMM system produced 5.6K co ntext-dependent (CD) states f or the SWB training set. A fully connected DNN model was then trained using MFB features, which in t urn was used t o generate the senone alignments to train the baseline and other aco ustic models p resented in this work . The input features to the acoustic models were formed u sing a con text window of 15 frames (7 frames on either sid e of the current frame). The acoustic models wer e trained b y using cross-entrop y (CE) follo wed b y sequen ce train ing using maximum mutual information (MMI) criterion [17, 21] . For the CNN model , 200 convolutional f ilters of size 8 were used in the convolutional layer, and the pooling size was set to 3 without overlap. The sub sequent, fully connected n etwork had f ive hidden layer s, wit h 2048 nodes per hidden layer, and the output la y er included as many nodes as the number of CD states for the giv en dataset. The networks were trained usin g an initial four iteration s with a constant learning rate of 0.008 , followed b y learnin g- rate halvin g based on the cross-validation error decrease. Training stopped when no further signif icant reduction in cross - validation error was noted or when cross-validation error started to increase. Backpropagation was performed using stochastic gradient descent with a mini-batch of 256 training examples. In this work, we investigated a modified deep neural network architecture to jo intly model the acou stic and the articulatory spaces, as sho wn in Figure 1 . In this modified architecture, two parallel input la y ers are us ed to accept acoustic features and articulatory f eatures. The in put layer tied to the acoustic feature consists of a convolutional layer, with 2 00 filters and the input lay er tied to the articulatory features is a feed-forward layer with 100 neurons. The feature maps from the convolutional la y er and th e outputs from the feed-forward layer are fed to a full y connected DNN consis ting of 5 hidden lay ers and 20 48 neurons in each layer, as shown in figure 1 . Figure 1. Fused CNN-DNN acoustic model. The co nvolution input layer accepts acoustic features as inp ut and the feed- forward input layer accepts articulatory features (vocal tract constriction ( TV ) variabl es ) as input. 5. RESULTS We initiall y validated the performance of the f eatures (MFB, DOC and TVs) u sing th e 360 hours SWB training dataset. The baseline DNN and C NN models had six an d five h idden la y ers respectively, with 2048 neurons in each layer , and were trained with MFB feat ures and its f MLLR transformed version (MFB+fMLLR). The N IST R T- 04 dev04 dataset (3 hour test set f rom F isher, containing 36 conversations) [ 2] was used as the cross -validation set during th e acoustic m odel training step. Table 1 presents the word error rates (WER) from the baseline CNN model trained with the SWB data when evaluated on th e NIST 2000 CTS test set, for both cross-entrop y (CE) training and sequence training (ST) using MMI. Table 1 also shows the results obtained f rom the DOC f eatures with and withou t a fMLLR t ransform. W e present results from ST as they w ere found to be always better than the results C E training . We explored learning the fMLLR transf orm directly f rom the filterbank f eatures (MFB_fMLLR and DOC _ fMLLR) an d learning the f MLLR transforms on the full dimensi onal cepstral versions of the features, applying the transform and then performing IDCT (MFB+fM LLR and DOC + fMLLR). Table 1. WER from the 360 hours SWB trained ST acoustic models when evaluated on the NIST 2000 CTS test set, for MFB and DOC features respectively. Feature Model WER SWB WER CH MFB DNN 13.5 26.2 DOC DNN 12.6 23.7 MFB_fMLLR DNN 11.8 22.2 MFB+fMLLR DNN 11.6 21.9 DOC_fMLLR DNN 12.3 23.2 DOC+fMLLR DNN 12.0 22.9 MFB+fMLLR CNN 11.3 21.8 DOC+fMLLR CNN 11.3 20.6 Table 1 shows that the performance of fMLLR transforms learned from the cepstral version of t he features are better than the ones directly from the filterbank features, which is expected, as t he cep stral features are uncorrelated, which adheres to the diagonal covariance ass umption of the GMM models used to lear n those trans forms. Table 1 demonstrates th at the f MLLR transformed features alwa y s perf ormed better than the features with out fMLLR transf orm. Also, the CNN models always gave better results, co nfirming similar o bservations from studies repo rted earlier [8]. Also, note that Table 1 shows that the DOC f eatures performed slightly better than the M F B f eatures after the fMLLR transf orm, where th e performance improvement was more pronou nced for the CH subset of the NIST 2000 CTS test set. As a next step, we inv estigated t he efficac y of f eature combination and fo cused onl y on the CNN acoustic models. We app ended t he articulatory features (TVs) extracted from the SWB train ing set, d ev04 and NIST 2000 CTS test sets, and combined them with MFB+fMLLR and DOC+f MLLR features, respectively . Finally, we co mbined th e MFB+fMLLR and DOC+fMLL R features and added t he TVs to them. Table 2 presents the WERs obtained from evaluating all the models trained with different combination s of features. Note that all models using TVs used the fused CNN -DNN (f-CNN-DNN) architecture shown in Figure 1 , for jointly mod eling the di ssimilar acoustic and articulatory spaces. When combining the MFB+fMLLR and DOC+fMLLR features, we trained a CNN model instead. The number of convolutional filters in all the experiments was kept at 200, and only the patch size was increased from eight to twelve in the case of combined acoustic features (MF B+fMLLR + DOC+ fMLLR) as opposed to the individual acoustic features (i.e., MFB+fMLLR or DOC+fMLLR). Table 2. WER from the 360 hours SWB trained ST acoustic model when evaluated with the NIST 2000 CTS test set, for different feature combinations. Feature Model WER SWB WER CH MFB+fMLLR + TV f-CNN-DNN 11.2 20.8 DOC+fMLLR + TV f-CNN-DNN 11.0 20.5 MFB+fMLLR + DOC+fMLLR CNN 10.7 20.4 MFB+fMLLR + DOC+fMLLR +TV f-CNN-DNN 10.5 19.9 Table 2 shows that t he use of ar ticulatory features helped to lower the WER in all the cases. The DOC feature was always foun d to perform slightly b etter than the M FBs and the best results were obtained when all the features were combined together, indicating the benefit of usin g multi- view features. Note tha t o nly 10 0 additional neurons were used to accommodate the T V features, hence all the models were o f comparable size s. The benefit of the articulatory features stem med from the complementary in formation that they contain (reflecting degree an d location of articulatory constrictions in th e vocal tract), as d emonstrated by earlier studies [ 22 - 24 ]. Overall the f-CNN-DNN s ystem trained with the combined f eature set , MFB+fMLLR + DOC+fMLLR + TV, demons trated a relative reductio n in WER of 7% and 9 % compared to the MFB+fMLLR CNN baseline fo r SWB and CH subsets of th e NIST 20 00 CTS test set. T able 1 an d 2 also demonstrates that seq uence training always gave additi ve performance gain over cross- entropy training, supporting the in [8, 21]. As a next step, we focus ed on training the acoustic models using the 2000-hour SW B+FSH CTS d ata, focusing on the CNN acoustic models and multi -view features. No te that the MFB DNN baseline mod el was u sed to generate the alignments for the F SH part of the 2000 hours CTS training set and as a consequence the number of senone labels remained the same as th e 360- hour SWB models. Table 3 presents the results f rom the 2000 hours CTS trained models. The mod el configurations and th eir parameter size were kept the same as the 360 -hour SWB models. Figure 3 shows that t he u se of the additional F SH training data resulted in significant performance improvement for both SWB and the CH subsets of the NIST 2000 CTS test set. Add ing the FSH dataset resulted in relative WER reduction o f 4.4% and 1 2% respectively f or SWB and CH subsets of the NIST 20 00 CT S test set, using MF B+fMLLR features. Similar impro vement was observed f rom th e DOC+fMLLR features as well, where 8% and 12% relative reduction in WER for SWB and CH subsets was observed when F SH d ata was added to the tr aining data. Note that the CH subset of the NIST 2000 CTS test set w as more challenging than th e SWB subset, as it contain s non -native speakers of English, hence introducing accented speech into the evaluation set. The use of articulatory features helped to reduce the error rates for both SWB and CH tes t sets, indicating their robustness to model spontaneous speech in both native (SWB) and non -native (CH) speaking st y les. The FSH corpus contains speech from quite a diverse set o f speakers, helping to redu ce th e WER of the CH s ubset more significantly than th e SWB su bset, a trend reflected in results reported in the literature [8]. Table 3. WER from the 2000 hours SWB+FSH trained acoustic model when evaluated on the NIST 2000 CTS test set, for different feature combinations. Feature Model WER SWB WER CH MFB+fMLLR CNN 10.8 19.2 DOC+fMLLR CNN 10.4 18.1 MFB+fMLLR + DOC+fMLLR CNN 9.8 17.2 MFB+fMLLR + DOC+fMLLR +TV f-CNN-DNN 9.5 16.9 Table 3 demonstrates the benefit of using multi-view features, where a CNN trained with MFB+fMLLR and DOC+fMLLR resulted in reducing the WER b y 6% and 5% relatively, for SWB and CH evaluation sets respectively, when compared to th e best single feature s y st em DOC+fMLLR. When the articulatory features in th e fo rm of the TVs were us ed in addition to the M F B+fMLLR and DOC+fMLLR f eatures in a f -CNN-DNN model, the best performance f rom a sin gle acoustic model was obtained, which produced a relative WER reduction of 3% and 2% for SWB an d CH evaluation sets respectively , compared to the CNN acoustic model trained with MFB+fMLLR and DOC+fMLLR features. Table 4 shows the sy ste m fusion results after d umping 2000-best lists from the rescored lattices f rom each individual system of different front -end f eatures with fMLLR, i.e., MFB, DOC, MFB+DOC, MF B+DOC+ TV, then conducting M-wa y combination of the subsystems using N-best ROVER [27] impl emented in SRILM [ 28]. In this sy stem fusion experiment, all subsy stems have equ al weights for N-best ROVER. As can be s een from the table, N-best R OVER based 2 -way and 3 -way s ystem fus ion produced a f urther 2% and 4% relative redu ction in WER compared to the best single s y stem (MFB+fMLLR + DOC+fMLLR + TV), for SW B and CH evaluation sets respectively. Note that the first row of Table 4 is th e last row of Table 3, i.e., th e best single system. The last row 4 - way f usion is from combining the 4 individual systems presented in Table 3 . Table 4. WER from system fusion experime nts. System Fusion WER SWB WER CH Best Single System 9.5 16.9 Best 2-way fusion 9.3 [MFB+DOC, MFB+DOC+TV] 16.4 [MFB+DOC, MFB+DOC+TV] Best 3-way fusion 9.3 [MFB, MFB+DOC, MFB+DOC+TV] 16.3 [MFB, DOC, MFB+DOC+TV] 4-way fusion 9.3 16.7 6. CONCLUSION We repo rted the results ex ploring multip le features for ASR on English CTS data. We observed that the fMLLR transform h elped reduce the WER of the b aseline system significantly. We observed that u sing multiple acoustic features helped in improving the overall accuracy of the system. Use of r obust features an d articulatory features significantly reduced the WER for the more challenging CallHome subset of the NIST 2000 CTS evaluation set, with accented speech in that subset . We developed a fused- CNN-DNN architecture, where in put convolution was only performed on the acoustic features an d the articulatory features were process b y a f eed -forward la yer. We f ound this architecture eff ective for combinin g acoustic fea tures and articulatory features. The robu st features and articulatory featu res capture complementary inf ormation, and the addition of them resulted in the best single system performance, with 12 % relative reduction of WE R on SWB and CH evaluation sets respectivel y , compared to the MFB+fMLLR CNN baseline. Note that in this study the lan guage model has not been optimized. Future stu dies should in vestigate RNN or oth er neural network-based language modeling techniques th at are kno wn to perform better th an word n -gram LMs . Als o, advanced acoustic modelin g, through the use of time- delayed neu ral nets (TDNNs), long sho rt-term memory neural nets (LSTMs), and the VGG nets, should also be explored as th eir p erformance has been mostly r eported using MFB features, and the use of multi-view featu res can help further improve their p erformance. 8. REFERENCES [1] C. Cieri, D. Miller, and K. Walker, “ From switchboard to fisher: Telephone collection protoco ls, their u ses and y ields, ” Proc. Eurospeech, 2003. [2] G. Evermann, H.Y. Chan, M.J.F. Gales, B. Jia, D. Mrva, P.C. Woodland a nd K. Y u, “ Training LVCSR System s on Thousands of Hours of Data, ” P roc. of ICASSP, pp. 209 -212, 2005. [3] S. Matsoukas, J. -L. Gauvain, G. Adda, T. Co lthu rst, C.-L. Kao, O. Kimball, L. Lamel, F. Lefevre, J. Z. M a, J. Makhoul, et al., “ Advances in transcription of b roadcast news an d conversational telephone speech w ithin the combined ears BBN /LIMSI system ”, IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, pp. 1541 – 1556, 2006 . [4] A. Stolcke, B. Chen, H. Franco, V. R. R. Gadde, M. Graciarena, M.-Y. Hwang, K. Kirchhoff , A. Mandal, N. Morgan, X. Lei, et al., “ Recent inno vations in speech- to -text transcription at SRI-ICSI- UW ”, IEEE Transactions o n Audio , Speech, and Language P rocessing, vol. 14, pp. 1729 – 1744, 2006 . [5] A. Ljolje, “ The AT&T 200 1 LVCSR sy stem ”, NIST LVCSR Workshop, 2001. [6] J.-L. Gauvain, L. La mel, H. Schwenk, G. Adda, L. Chen, and F . Lef evre, “ Conversational telephone speec h recogni tion ”, in Proc. IEEE ICASSP, vol. 1, pp. I – 212. IEEE, 2003 . [7] F. Seide, G. Li, and D. Yu, “ Conversational sp eech transcription using con text-dependent deep neural n etworks ,” Proc. of Interspeech, 2011. [8] G. Saon, T. Sercu, S. J. Rennie, and H. J. Kuo, “ The IBM 2016 En glish conversational telephone speech recognition system, ” in Proc. Interspeech, pp. 7 – 11, 2016. [9] A. Stolcke and J. Dr oppo, “ Comparing Hu man and M achine Errors in Conversational Sp eec h Transcription, ” Proc. of Interspeech, pp. 137-141, 2017. [10] A. Mo hamed, G.E. Dahl, and G. Hinton, “ Acoustic modeling usin g deep belief n etworks, ” IEEE Trans. on ASLP, vol. 20, no. 1, pp. 14 – 22, 2012 . [11] G. Hinton, L. Deng, D. Yu, G. Dahl, A.-r. Mohamed, N. Jaitly, A . Senior, V . Vanhoucke, P. Nguyen, T. Sainath, and B. Kinsgbury, “ Deep neural network s for acoustic modeling in speech re cognition, ” IEEE Sig nal P rocess. Mag., v ol. 2 9, no. 6, pp. 82 – 97, 2012. [12] M . Bi, Y. Qian, and K. Yu, “ Very deep convolutional neural networks for LVCSR ”, in P roc. Interspeech, pp. 3259 – 3263, 2015 . [13] H. Sak, A. Senio r, K. Rao, and F. Beaufay s, “Fast and accurate recurrent neural network acou stic models for speech recognition ”, in Proc. Interspeech, pp. 1468 – 1472, 2015. [14] H. S ak, A. W. Senio r, and F. Beaufays, “ Long short-term memory recurren t neural network architectures for large scale acoustic modeling ”, in Proc. Interspeech, pp. 338 – 342, 2014. [15] V. P eddinti, G. Chen, V . M anohar, T. Ko, D. Povey, and S. Khudanpur, “ JHU ASpIRE system: Rob ust LVCSR with TDNNs, i -vector adaptation and RNN-LMS, ” P roc. of ASRU, 2015. [16] J. Godfrey and E. Holliman, “ S witchboard-1 Release 2, ” Linguistic Data Consortium, Philadelphia, 1997 . [17] D. Povey, A. Ghoshal, G. Boulianne, L . Burget, O. Glembek, N. Goel, M. Hannemann, P. Motl ı cek, Y. Qian, P . Schwarz et al., “ The kaldi speech recognition toolkit ” in Pro c. ASRU, 2011 . [18] V. Mitra, H. Franco and M. Grac iarena, “ Damped Oscillator Cepstral Coefficients for Robust Speech Recognition, ” Proc. of Interspeech, pp. 886 – 890, 2013. [19] V. Mitra, G. Sivaraman, H. Na m, C. Espy-Wilson, E. Saltzman and M . Tiede, “ Hybrid convolutional neural networks for articu latory and acoustic information based sp eech recognition, ” Speech Comm unication, Vol. 89, pp. 103 -112, 2017 [20] V. Mitra, G. Siva raman, C. Bartels, H. Nam, W. Wa ng, C. Espy-Wilson, D. V ergy ri, H. Franco, “ Joint m odeling of articulatory and acoustic spaces for contin uous speech recognition tasks, ” in Proc. ICA S SP 2017, pp. 5205-5209, March 2017. [21] K. Vesel ý, A. Ghoshal, L. Burget, and D. Povey, “ Sequence- discriminative t raining of deep neural networks, ” in INTERSPEECH, 2013, no. 1, pp. 2345 – 2349 . [22] V . Mitra, H. Nam , C. Espy-Wilson, E. Saltzman, L. Goldstein, “ Articulatory information for n oise robust speech recognition, ” IEEE Trans. on Audio, Speech and Language Processing, Vol. 19, Iss. 7, pp. 1913-1924, 2010. [23] V. Mitra, G. Sivaraman, H. Na m, C. Espy-Wilson, E. Saltzman, “ Articulatory features from deep neural networks and th eir role in speech recognition, ” Proc. of ICASSP, pp. 3041-3045, Florence, 2014. [24] V. Mitra, W. Wang, A. Stolcke, H. Nam, C. Richey, J. Yuan, M. Liberman, “ Articulatory features for large vocabulary speech recognition, ” Proc. of ICASSP, pp . 7145-7149, Vancouver, 2013. [25] I. Bulyko, M. Ostendorf and A. Stolcke. "Getting More Mileage from Web Text So urces for Conversational Speech Language Modeling u sing Class-Dependent Mixtures", Proceedings of HLT . 2003. [26] W. Wang, A. Stolcke, and M . P. Harper , “ The use of a linguistically motivated lan guage m odel in conve rsational speech recognition”, in Proc. ICASS P, pp. 261-264, 2004. [27] A. Sto lcke, H. Bratt, J. Butzberger, H. Franco, V. R. Rao Gadde, M. Plauche, C. Richey, E. Shrib erg, K. Sonmez, F. Weng, J. Zhen g, “The SRI March 2 000 Hub -5 Conversational Speech Transcription System”, Pro c. NIST Speech Transcription Workshop, College Park, MD, 2000. [28] A. Sto lcke, “SRILM – An Extensible Language Modeling Toolkit”, Proc. of ICSLP, pp. 901 -904, 2002. [29] A. Waibel, T. Hanazawa, G. Hin ton, K. Shikano, and K. Lang, “Phoneme recognitio n usin g time -delay n eural networks,” IEEE Transactions o n Acoustics, Speech, and Signal Processing, vol. 37, no. 3, pp. 328 – 339, Mar. 1989.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment