다중뷰와 조음 정보 융합으로 향상된 대규모 연속 음성 인식
본 연구는 멜 필터뱅크와 강제 감쇠 진동기 계수(DOC) 특징을 fMLLR 변환 후 다중뷰 형태로 결합하고, 조음 궤적 정보를 추가 입력으로 사용한 CNN‑DNN 모델을 설계하였다. 실험 결과, 다중뷰 특징만으로도 기존 단일 특징 대비 WER가 크게 감소했으며, 조음 정보를 결합했을 때 Switchboard와 CallHome 테스트에서 각각 12%의 상대적 WER 감소를 달성하였다. 이는 자발적 대화음성 및 비원어민 억양에 대한 인식 강인성을 …
저자: Vikramjit Mitra, Wen Wang, Chris Bartels
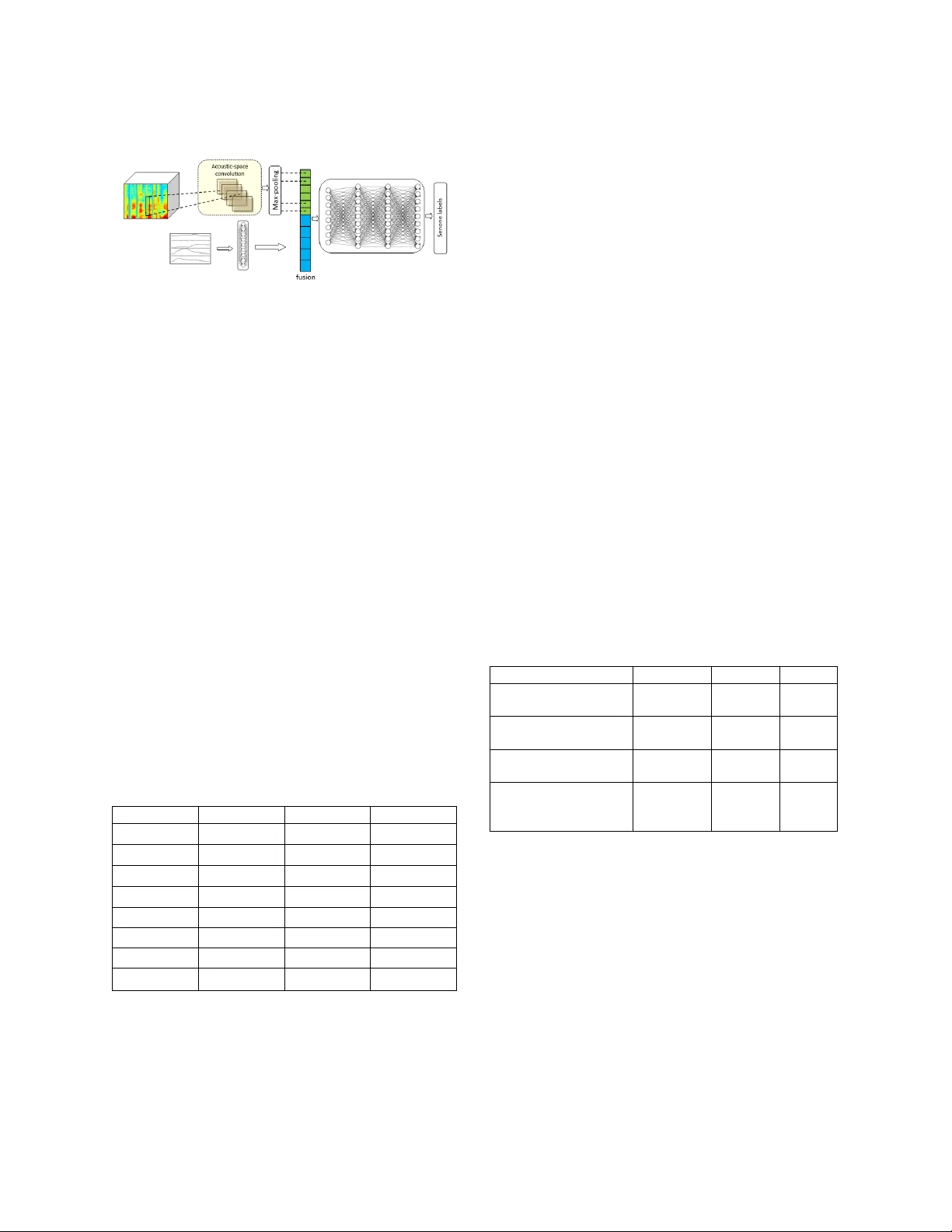
본 논문은 대규모 연속 음성 인식(large‑vocabulary continuous speech recognition, LVCSR) 시스템에서 음향 특징과 조음 정보를 어떻게 효과적으로 결합할 수 있는지를 탐구한다. 연구는 크게 두 부분으로 구성된다. 첫 번째는 멜 필터뱅크(MFB)와 강제 감쇠 진동기 계수(DOC)라는 두 가지 서로 다른 스펙트럼 특징을 fMLLR 변환 후 다중뷰 형태로 결합하는 방법을 제시한다. fMLLR 변환은 GMM‑HMM 기반 정렬을 이용해 학습되며, 변환을 직접 필터뱅크에 적용하는 경우와, 필터뱅크를 켑스트럴 형태로 변환한 뒤 학습하고 역변환(IDCT)하는 경우를 비교한다. 후자 방식이 특징 간 상관성을 감소시켜 변환 학습에 더 적합함을 실험적으로 확인하였다. 변환 후의 MFB와 DOC 모두 단일 특징보다 낮은 WER를 보였으며, 특히 DOC는 비원어민이 포함된 CallHome 서브셋에서 더 큰 개선을 나타냈다.
두 번째는 조음 정보(Articulatory TV)를 추가로 활용하는 것이다. 조음 정보는 CNN 기반 음성‑조음 역변환 모델을 통해 8차원 궤적으로 추출되며, 여기에는 성문 개구, 입술 돌출, 혀 위치·각도 등 구강·인두 형태를 나타내는 물리적 파라미터가 포함된다. 논문은 이 조음 특징을 기존 음향 특징과 병렬 입력으로 받는 ‘fused CNN‑DNN’ 구조를 설계하였다. 음향 스트림은 200개의 1‑D 컨볼루션 필터를, 조음 스트림은 100개의 완전 연결 레이어를 통해 각각 전처리한 뒤, 최종 DNN에 결합한다. 이 구조는 두 특징이 서로 보완적인 정보를 제공함을 이용해 인식 정확도를 높인다.
실험은 먼저 360시간 규모의 Switchboard(SWB) 데이터만을 사용해 기본 모델을 구축하였다. baseline CNN 모델은 MFB+fMLLR만을 사용했을 때 SWB에서 11.3%·CH에서 21.8%의 WER를 기록했다. DOC+fMLLR을 사용하면 SWB 11.3%·CH 20.6%로 약간 개선되었다. 이후 MFB+fMLLR와 DOC+fMLLR를 결합한 다중뷰 모델을 CNN에 적용하면 SWB 10.7%·CH 20.4%로 성능이 향상되었다. 여기에 조음 TV를 추가한 f‑CNN‑DNN 모델은 SWB 10.5%·CH 19.9%까지 낮추어, 다중뷰와 조음 결합이 가장 큰 이득을 제공함을 확인했다.
다음 단계에서는 2000시간 규모의 SWB+Fisher 데이터로 학습을 확대하였다. 데이터 양을 늘리면 전반적인 WER가 감소했으며, 다중뷰(CNN) 모델은 SWB 9.8%·CH 17.2%를 기록했다. 조음 TV를 포함한 f‑CNN‑DNN 모델은 SWB 9.5%·CH 16.9%로 최종 최고 성능을 달성했다. 특히 CallHome 서브셋은 비원어민 억양이 포함돼 어려운 평가 조건이었음에도, 조음 정보가 포함된 모델은 기존 음향만 사용한 모델 대비 상대적으로 7~9%의 WER 감소를 보였다.
마지막으로 시스템 레벨에서 2000‑best 리스트를 각 모델별로 결합한 결과, 다중뷰와 조음 정보를 모두 활용한 시스템이 가장 낮은 WER를 기록하였다. 이는 서로 다른 특징이 제공하는 보완적 정보가 최종 디코딩 단계에서도 시너지 효과를 낼 수 있음을 의미한다.
전체적으로, 이 연구는 (1) fMLLR 변환을 통한 스펙트럼 특징의 정규화, (2) MFB와 DOC의 다중뷰 결합, (3) 조음 궤적을 별도 입력으로 활용하는 f‑CNN‑DNN 구조라는 세 가지 핵심 기법을 제시한다. 실험 결과는 이들 기법이 각각 독립적으로도 성능을 향상시키지만, 모두 결합했을 때 가장 큰 이득을 제공한다는 것을 보여준다. 따라서 자발적 대화음성, 억양 변이, 비원어민 발화 등 다양한 실제 환경에서의 음성 인식 시스템에 적용할 수 있는 강력한 방법론을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기