Similarity measures for vocal-based drum sample retrieval using deep convolutional auto-encoders
The expressive nature of the voice provides a powerful medium for communicating sonic ideas, motivating recent research on methods for query by vocalisation. Meanwhile, deep learning methods have demonstrated state-of-the-art results for matching voc…
Authors: Adib Mehrabi, Keunwoo Choi, Simon Dixon
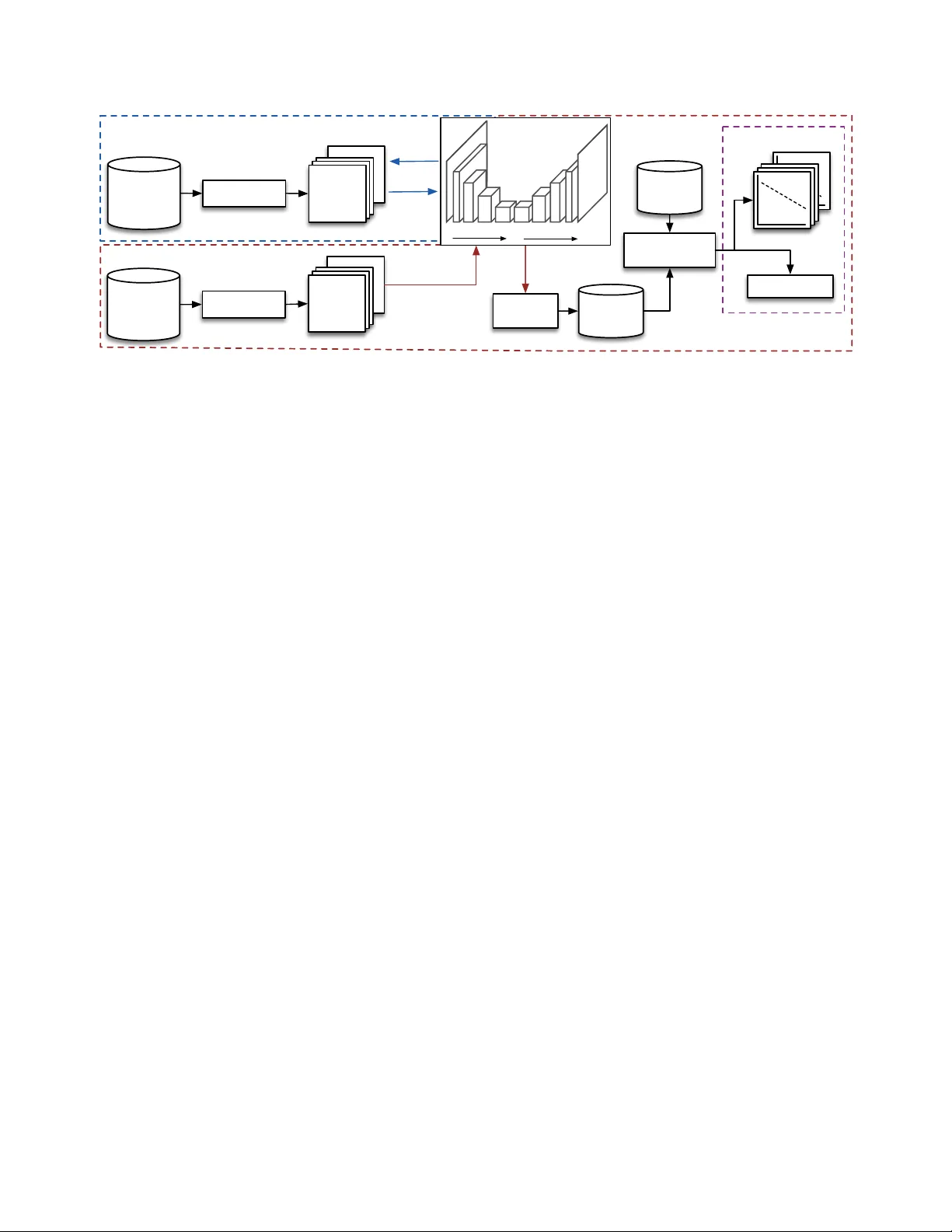
SIMILARITY MEASURES FOR V OCAL-B ASED DRUM SAMPLE RETRIEV AL USING DEEP CONV OLUTIONAL A UTO-ENCODERS Adib Mehrabi, K eunwoo Choi, Simon Dixon, Mark Sandler Queen Mary Uni versity of London, London, UK Centre for Digital Music, EECS E1 4FZ, London, UK { a.mehrabi, keunwoo.choi } @qmul.ac.uk ABSTRA CT The expressi ve nature of the voice provides a powerful medium for communicating sonic ideas, motiv ating recent research on methods for query by vocalisation. Meanwhile, deep learning methods ha ve demonstrated state-of-the-art results for matching vocal imitations to imitated sounds, yet little is kno wn about how well learned fea- tures represent the perceptual similarity between vocalisations and queried sounds. In this paper , we address this question using sim- ilarity ratings between vocal imitations and imitated drum sounds. W e use a linear mixed effect re gression model to show ho w features learned by conv olutional auto-encoders (CAEs) perform as predic- tors for perceptual similarity between sounds. Our experiments sho w that CAEs outperform three baseline feature sets (spectrogram-based representations, MFCCs, and temporal features) at predicting the subjectiv e similarity ratings. W e also inv estigate how the size and shape of the encoded layer ef fects the predicti ve power of the learned features. The results show that preservation of temporal information is more important than spectral resolution for this application. Index T erms — vocalisation, audio similarity , con volutional neural networks, auto-encoders 1. INTRODUCTION AND RELA TED WORK Searching for audio samples is a core part of the electronic music making process, yet is a time consuming task, and a key area for future technological development [1]. This task typically in volves browsing lists of badly labelled files, relying on filenames such as ‘big kick’ or ‘hi-hat22’. Such methods for browsing sound libraries limit the users’ ability to efficiently find the sounds they are looking for . Meanwhile, the voice provides an attracti ve medium for effec- tiv ely communicating sonic ideas [2, 3], as it can be used to express timbral, tonal and dynamic temporal variations [4]. Moreover , pre- vious research demonstrates that musicians are able to accurately vocalise important acoustic features of musical sounds [5, 6]. Query by vocalisation (QBV) is the process of searching for sounds based on v ocalised examples of the desired sound. T ypically , QBV systems extract audio features from a vocalisation, which can then be compared to the features of sounds in a sample library (to return class labels or a ranked list of sounds). Initial approaches to QBV used heuristic based features [7, 8]. Morphological fea- tures describing the high-lev el temporal ev olution of sounds hav e also been applied to QBV [9], howev er drum sounds generally have similar high-lev el temporal morphology (i.e. rise-fall), so these types of features are less applicable here. Recent work has shown that features learned using stacked auto- encoders (SAEs) outperform heuristic descriptors such as MFCCs (Mel-frequency cepstral coefficients) for QBV tasks. SAEs utilise a deep learning structure where multiple layers learn an efficient rep- resentation to encode the input. These have been applied in 2 QBV scenarios: supervised learning, using the features to train a classifier [10]; and unsupervised search, based on distance between sounds in a Euclidean feature space [11, 12]. Furthermore, in [13] the au- thors present a QBV system based on con volutional neural networks (CNNs) implemented in a semi-Siamese network structure. In this case the con volutional layers are trained to learn feature represen- tations from constant-Q spectrograms of vocal imitations and the imitated sounds. The CNN is followed by fully connected layers to match input vocalisations to audio samples, requiring each sam- ple in a sound library to be compared to a vocal query . The system shows promising results for matching vocal imitations to the imitated sounds, howe ver in the general case QBV systems require ef ficient, deployable querying. Using this method, a single query on a dataset with N data samples requires N forward-pass computations of the network, which is significantly demanding, for example compared to nearest neighbour search in a feature vector space. Whilst both SAE and CNN approaches sho w promising perfor- mance in terms of retrie ving an imitated sound from a set of audio samples, none of the above mentioned QBV methods consider the per ceptual similarity between the query and retrieved sounds. Cen- tral to the ev aluation of these approaches is the assumption that the target sound is indeed the sound that was imitated, and the task is to match the imitations and imitated sounds accordingly . Howe ver , we consider a use case in which the query is not necessarily an imi- tation of a sound in the database, and in vestigate which feature rep- resentations correlate well with the perceptual similarity between an imitation and a set of audio samples. In this paper we ev aluate the performance of both heuristic and learned features for QBV of drum sounds. An ov erview of our ap- proach is illustrated in Fig. 1. W e present a set of con volutional auto-encoders (CAEs) trained on a dataset of ∼ 33k audio samples and ∼ 6k vocalisations. These are used to extract features from 420 vocal imitations of 30 drum sounds. The feature sets are e valuated using perceptual similarity ratings between the vocal imitations and the imitated drum sounds. W e include 4 types of features: (1) a spec- trogram based representation from [14], which the authors show to correlate strongly with perceptual similarity between drum sounds; (2) MFCCs; (3) temporal descriptors; (4) encoded representations from the CAEs. W e compare 11 CAEs, which dif fer in both the size of the encoded feature tensor and the shape of the encoded layer in the temporal and spectral dimensions. Samples (N=33k) & imitations (N=6k) Preprocessing T raining Bark- grams …. …. TRAINING N=39k Similarity ratings (N=9k) Feature extraction LMER Model Fitting Distance calculation Distance T est Data N=2520 …. …. N=30 Slopes: rating~distance AIC (model fit) Drums (N=30) & imitations (N=420) Bark- grams …. …. N=450 Preprocessing EV ALUA TION Encoding Decoding Frequency Time CAE Encoded features Fig. 1 : Overview of the complete work flow . All audio (training and test data) is preprocessed to create 128x128 barkgram representations. The trained CAE is used to extract features from the test data. Euclidean distance between each imitation and its imitated sound is then computed, and fitted with the rating data to an LMER model. Performance of the 14 feature sets (3 baselines and 11 CAE networks) is measured by 1) AIC for model fit, and 2) the proportion of imitated sounds that ha ve a significantly negati ve slopes for rating ∼ distance . 2. PROBLEM DEFINITION The task is to establish which audio features best correlate with per- ceptual similarity between real drum sounds (the imitated sounds ) and vocal imitations of drum sounds (the imitations ). Specifically , we are interested in i) how heuristic descriptors perform compared to learned features using CAEs, and ii) the importance of temporal vs. spectral dimensions and the size of the encoded tensors from the CAEs. W e limit the problem to a set of 30 drum sounds: 6 from each of 5 classes (kick, snare, cymbal, hi-hat, tom-tom), and con- sider only the similarity between imitations and within-class sounds (e.g. between the imitation of a snare and the actual snare sounds). 3. EXPERIMENTS 3.1. Baseline Methods W e use 3 baseline methods. The first (PK08) is a spectrogram-based measure of similarity from [14]. This has been sho wn to correlate highly with perceptual similarity ratings between within-class drum sounds, and we are interested in how well it transfers to our appli- cation. In summary , similarity between 2 sounds is measured as the Euclidean distance between their vectorised barkgrams, constructed from a spectrogram with the following parameters: 93ms window; 87.5% ov erlap; Bark scale (72 bins); loudness in dB and scaled us- ing T erhardt’ s ear model [15]. The barkgrams are time-aligned, and where 2 sounds are not of the same length the shorter is zero padded to the length of the longer one. For the second method (MFCC) we calculate the first 13 MFCCs for each sound (excluding MFCC 0) with first and second order deriv ativ es, using a 93ms time window and 87.5% overlap. The mean and variance of each MFCC and its derivati ves are calculated for each sound, yielding 78 features. The third method (TEMP) is a set of 5 temporal features: log attack time (LA T); temporal centroid (TC); LA T/TC ratio; temporal crest factor (TCF); and duration. W e calculate LA T and TC as per the definition in [14]. TCF is calculated ov er the entire time domain signal (rectified), and is the maximum value di vided by the root mean squared. 3.2. CAE Networks 3.2.1. Model Ar chitectur e The basic architecture is a CAE with four 2D conv olution layers in its encoder/decoder . Each con volutional layer is followed by batch normalisation and ReLU acti vation layers. T o avoid checker board artefacts caused by decon volution layers [16] we apply upsampling prior to each decoding con volutional layer . As such, each decoding decon volution layer is an upsampling layer followed by a 2D con vo- lution layer with (1 , 1) stride. W e vary the kernel size of the first and last layers while using fixed (10 , 10) kernels for the other conv olu- tion layers. The encoding layers hav e [8, 16, 24, 32] kernels (layers 1-4 respectiv ely) which is mirrored in the decoder, i.e., [32, 24, 16, 8]. A single-channel con volution layer is used for the output layer . The activation of the last layer of the encoder is flattened and taken as the feature vector for a gi ven test sample. The kernel size and stride of the conv olution (or upsampling) layers are varied in order to compare the shape (i.e. square, wide, tall) and size of the encoded representation, respecti vely . Details for 11 variants of the abo ve model are giv en in T able 1. 3.2.2. T raining Data and Pr e-pr ocessing The network is designed to learn a broad range of vocal and per- cussion related sounds including i) short, percussiv e/non-percussive and pitched/unpitched sounds, and ii) non-verbal vocalisations. The training dataset is made up of 24,294 percussion sounds, 4,884 sound effects and 4,523 single note instrument samples. In addition, we include 4,429 vocal imitations of instruments, synthesisers and ev- eryday sounds from [17], and 1,387 vocal imitations of 72 short syn- thesised sounds from [6]. This results in a dataset of ∼ 39k sounds, of which ∼ 6k are vocal imitations. For each sound in the training set we compute the barkgrams from spectrograms with a 93 ms time window and 87.5% ov erlap, using 128 Bark bins. As with the PK08 baseline, the magnitudes are scaled (in dB) using T erhardt’ s ear model curves [15]. T o achieve a fixed size representation for all sounds, we either zero-pad or trun- cate the barkgrams to 128 frames ( ≈ 1.5 seconds). 3.2.3. T raining Procedur e The models are implemented using Keras [18] and T ensorflow [19]. T raining and validation sets are 70:30% split from the training data (Section 3.2.2). As the training dataset contains 5.5 times more au- dio samples than vocal imitations, and we are equally interested in learning both sound types, we specify a 50/50% split of audio sam- ples/vocal imitations for each batch (128 data samples). The models are all fitted using the Adaptiv e Moment estimation (Adam) opti- miser [20] with a learning rate of 0.001, and mean squared error loss function. W e use the early-stopping scheme for no improvement in validation loss after 10 epochs. The best (i.e. lowest v alidation loss) model for each parameter setting is selected for the analysis. 4. EV ALU A TION 4.1. T est data The 30 drum sounds were taken from the fxpansion 1 BFD3 Cor e and 8BitKit sample libraries, which include a range of acoustic and electronic drum samples. V ocal imitations of each sound were recorded by 14 musicians ( > 5 years experience), giving 420 imita- tions. The recordings took place in an acoustically treated room at the Centre for Digital Music, Queen Mary Univ ersity of London 2 . Per ceptual similarity ratings between the imitations and each of the within-class drum sounds were collected from 63 listeners via a web based listening test, using a format based on the MUSHRA protocol for subjective assessment of audio quality [21]. Whilst the MUSHRA standard specifies the use of expert listeners, it has re- cently been shown that lay listeners can provide comparable results to experts for measuring audio quality [22]. Each listener was pre- sented with 30 tests. F or each test the listener was presented with a (randomly selected) vocal imitation and the 6 within-class drum sounds (one being the imitated sound). The listener then rated the similarity between the imitation and each drum sound (gi ving 6 sim- ilarity ratings per test), on a continuous scale from ‘less similar’ to ‘more similar’. Of the 30 test pages, 28 were unique and 2 were random du- plicates. These were included for post-screening of the listeners, as recommended in the MUSHRA standard [21]. Listener reliability was assessed using the Spearman rank correlation between the tw o duplicate test pages for each listener . W e considered reliable listen- ers as those who were able to replicate their responses for at least one of the duplicates with ρ > = 0 . 5 , i.e. lar ge positiv e correla- tion [23]. There were 51 reliable listeners, for whom ρ = 0.63/0.04 (mean/standard error), giving 9,126 responses from 1521 tests (ex- cluding duplicates). W e then computed K endall’ s coefficient of con- cordance, W [24] on the ranked responses for each imitation. The mean/standard error of W = 0.61/0.01, indicating moderate to strong agreement amongst the reliable listeners [25]. Analysis of the ratings indicated that listeners were able to cor- rectly identify the imitated sound with above chance accuracy (37% of cases, chance = 16%), and the imitated sound was rated first or second most similar to the imitation in 60% of tests. This indicates that although the imitations were often rated as being most similar to the imitated sounds, there are a considerable number of cases (up to 40%) where 2 of the 6 within-class sounds were rated more similar to the imitation than the imitated sound. This highlights the poten- tial importance of perceptual similarity measures for tasks such as 1 https://www .fxpansion.com 2 http://www .eecs.qmul.ac.uk/facilities/vie w/control-room QBV , depending on whether the task is to identify and return an imi- tated sound, or to return the most similar sound. The 9126 similarity ratings are used as as a ground truth from which to measure the per- formance of each of the feature sets. 4.2. Linear mixed effect regression modelling For a given feature set, distance is measured between each of the 420 imitations and their respecti ve 6 within-class sounds, giving 2520 distance values. W e use Euclidean distance in keeping with the PK08 baseline method, and the distances for each feature set are normalised between 0–1. Linear mixed effect regression (LMER) models are then fitted for predicting the ratings from the distances. LMER is well suited to this task given that all listeners did not pro- vide ratings for all imitations but only a randomly-selected set of 28 imitations (gi ving an unbalanced dataset). In addition, it allo ws us to include the dependencies between ratings for each listener and imitated sound. Maximum likelihood parameters for the models are estimated using the lme4 package in R [26]. The general model is fitted with rating y ij k as the dependent variable for each rating i , random in- tercepts for each listener k , and fixed effects of distance x ij and imitated sound j , with an interaction term between distance and im- itated sound. The model is given by: y ij k = ν j + β 1 j x ij + γ k + ij k (1) where β 1 j is the slope of rating ov er distance for a given instance of j , and γ k is the random intercept for a giv en listener k . W e note that model analysis showed heteroskedasticity in the residuals. Parame- ter estimates were therefore compared to those from robust models [27], and no major dif ferences were found. As such the non-robust models were used for the analysis. W ald 95% confidence intervals (CIs) were then calculated for the slope of each interaction ( β 1 j ). For imitated sounds where the upper CI for β 1 j < 0 , we can infer the slope is significantly belo w 0 ( α < 0 . 05 ). This indicates that the feature set is a good predictor for the imitated sound in question. The performance of each feature set is ev aluated using two met- rics: The percentage of imitated sounds for which β 1 j is significantly below 0 (accuracy); and Akaike’ s information criterion (AIC), which giv es a measure of model fit (note: lower AIC = better model fit). An ideal feature set would have a significantly neg ativ e β 1 j (perfect predictor = -1.0) for all 30 imitated sounds, and be a good fit to the rating data giv en the model in Eq. 1. 5. RESUL TS AND DISCUSSION The results are given in T able 1. The encoded features from all CAEs outperform the baseline feature sets. The LMER model from the best performing feature set (11) gi ves fitted slopes for r ating ∼ distance that are significantly less than 0 ( α < 0 . 05 ) for 83.3% (25/30) of the imitated sounds, and has the lowest AIC. This shows the feature set is generally a good predictor of perceptual similarity between the vocal imitations and imitated sounds tested here, and has the best fitting LMER model. Interestingly , preservation of the temporal resolution is more im- portant than spectral resolution for our task: for CAEs wide in time and narrow in frequency (8–11) performance improves as the size of the encoded layer decreases. This indicates redundancy in the spectral information: encoded shapes with spectral dimensions > 1 hav e an adverse effect on performance. The similarity ratings are only for sounds in the same class (e.g. kick, snare etc.), and we T ype Feat. set L1/8 kernel Strides of con v ./upsampling layers Encoded layer (L4) Results L1/8 L2/7 L3/6 L4/5 Shape ( × 32) Size AIC Acc. CAE (Square) 1 (5, 5) (2, 2) (2, 2) (2, 2) (2, 2) (8, 8) 2048 1820 73.3 2 (5, 5) (2, 2) (2, 2) (2, 2) (4, 4) (4, 4) 512 1925 66.7 3 (5, 5) (2, 2) (2, 2) (4, 4) (4, 4) (2, 2) 128 1958 66.7 CAE (T all) 4 (5, 3) (2, 2) (2, 2) (2, 2) (2, 4) (8, 4) 1024 1609 73.3 5 (5, 3) (2, 2) (2, 2) (2, 4) (2, 4) (8, 2) 512 1647 70.0 6 (5, 3) (2, 2) (2, 4) (2, 4) (2, 4) (8, 1) 256 2361 63.3 7 (5, 3) (2, 2) (2, 4) (2, 4) (4, 4) (4, 1) 128 2523 56.7 CAE (W ide) 8 (3, 5) (2, 2) (2, 2) (2, 2) (4, 2) (4, 8) 1024 1921 66.7 9 (3, 5) (2, 2) (2, 2) (4, 2) (4, 2) (2, 8) 512 1866 73.3 10 (3, 5) (2, 2) (4, 2) (4, 2) (4, 2) (1, 8) 256 1395 83.3 11 (3, 5) (2, 2) (4, 2) (4, 2) (4, 4) (1, 4) 128 1298 83.3 PK08 12 – – – – – – – – 2388 53.3 TEMP 13 – – – – – – – – 2692 40.0 MFCC 14 – – – – – – – – 2703 46.7 T able 1 : Details of the CAEs and results for 14 feature sets. CAEs dif fer in the k ernel shape of L1 and L8, and the shape of the encoded layer (determined by strides). Results are giv en in terms of i) the LMER model fit (AIC), and ii) the percentage of imitated drum sounds for which the r ating ∼ distance slope is significantly less than 0 ( α < 0 . 05 ). Note: lower AIC = better model fit. Cymbals Hats Kicks Snares T oms 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 6 −0.8 −0.6 −0.4 −0.2 0.0 0.2 Imitated drum sound Fitted slope Fig. 2 : Slope estimates (with 95% CIs) for the LMER model fitted on the performing feature set (11). A negativ e slope indicates a decrease in perceptual similarity with an increase in distance, i.e. sounds for which the feature set performs well. expect high spectral similarity within each class. As such, ov erall energy differences in time may be more salient than the spectral distribution, providing the cues used by listeners when gi ving the ratings. This hypothesis is supported by comparing the square and tall CAEs: where reducing the size of the time dimension decreases performance. Howe ver there is also some redundancy in the tem- poral information, as can be seen comparing feature sets 10 and 11. As a post-hoc analysis we tested v ariants of CAE 11 using smaller encoded kernel shapes: ( 1 , 2 ) and ( 1 , 1 ), and found a decrease in per- formance below ( 1 , 4 ). This effect can also be seen in models 4–7, where performance decreases as width is reduced from 4 to 1. Regarding the baseline features, both TEMP and MFCC show similarly poor performance in terms of AIC (MFCC performs slightly better in terms of accuracy). This indicates that although the learned temporal features appear to be most important for our task, the 5 heuristic temporal features are not sufficient to capture the salient cues used by listeners. The benefits of learned features over MFCCs concur with previous work [10], ho wev er we see greater disparity in performance. This may be specific to the sounds used in the ev aluation (in [10] a much wider range of sounds was used). The improv ed performance of PK08 compared to the other baselines indicates that this measure is somewhat transferable to vocalised drum sounds, although still only achieving an accurac y of 53%. Further analysis of the LMER model for the best performing fea- ture set (11) shows the indi vidual slopes for each drum sound (Fig. 2). Here we observe considerable v ariation between the imitated sounds. In particular , we note that the 5 sounds for which the upper CI crosses 0 (3 kicks and 2 toms) are all pitched (although they are not the only pitched sounds in the dataset, indeed, all the toms are pitched). This suggests that reducing the size of the encoded spec- tral shape to 1 may work best ov er all the drum sounds used here, howe ver the predictions for some pitched sounds suf fer as a result. Finally , we note the slopes, although generally below 0, do not approach -1. Listener rating data is inherently noisy , and the con- cordance amongst listeners varies across the sounds. As such, there will clearly be a glass ceiling for performance, and a perfect model fit would not be useful for a real world application of the LMER model. Indeed, a perfect model fit is not desirable if one is interested in generalisability of the fitted LMER model. 6. CONCLUSIONS AND FUTURE WORK In this paper we apply con volutional auto-encoders (CAEs) to query by vocalisation (QBV) for drum sound retrie val. W e present a nov el ev aluation using perceptual similarity ratings between vocal imi- tations and the imitated drum sounds, providing insight into how learned features perform at predicting these ratings. Specifically , we compare CAEs that differ in both the size and shape of the encoded layer , in terms of the spectral and temporal dimensions. Our experiments sho w that CAEs outperform 3 sets of heuristic fea- tures by a considerable margin. Furthermore, we sho w that reducing the size of the encoded layer height (frequency) increases the pre- dictiv e power of the learned features, yet reducing the width (time) has the opposite effect. This finding is partly unexpected given that drum sounds generally hav e a similar ov erall temporal en velope (at- tack followed by a decay), ho wev er understandable given that we compare within-class sounds (e.g. kick, snare etc.), which are also likely to share similar spectral distributions. For future work we would lik e to in vestigate more fine-grained morphological features to represent the temporal e volution that appears to be so important here. In addition we would like to in vestigate the generalisability of the best performing fitted LMER model to other QBV tasks, to deter- mine how a model fitted on one set of sounds and similarity ratings performs giv en a larger sound library , as might be used in a typical music production en vironment. 7. A CKNO WLEDGEMENTS This work is supported by EPSRC grants for the Media and Arts T echnology Doctoral T raining Centre (EP/G03723X/1) and F AST IMP A Ct project (EP/L019981/1). 8. REFERENCES [1] Kristina Andersen and Florian Grote, “Giantsteps: Semi- structured con versations with musicians, ” in Pr oceedings of the 33r d Annual A CM Conference Extended Abstracts on Hu- man F actors in Computing Systems , Seoul, Korea, 2015, pp. 2295–2300. [2] Guillaume Lemaitre, Arnaud Dessein, Patrick Susini, and Karine Aura, “V ocal imitations and the identification of sound ev ents, ” Ecological Psychology , vol. 23, no. 4, pp. 267–307, 2011. [3] Guillaume Lemaitre and Davide Rocchesso, “On the ef fec- tiv eness of vocal imitations and verbal descriptions of sounds, ” The Journal of the Acoustical Society of America , vol. 135, no. 2, pp. 862–873, 2014. [4] Johan Sundberg, The Science of the Singing V oice , Northern Illinois Univ ersity Press, Illinois, USA, 1989. [5] Guillaume Lemaitre, Ali Jabbari, Olivier Houix, Nicolas Mis- dariis, and Patrick Susini, “V ocal imitations of basic auditory features, ” The Journal of the Acoustical Society of America , vol. 137, no. 4, pp. 2268–2268, 2016. [6] Adib Mehrabi, Simon Dixon, and Mark B Sandler, “V ocal imitation of synthesised sounds varying in pitch, loudness and spectral centroid, ” The Journal of the Acoustical Society of America , vol. 141, no. 2, pp. 783–796, 2017. [7] David Sanchez Blancas and Jordi Janer, “Sound retrie val from voice imitation queries in collaborative databases, ” in Pr oceed- ings of the 53rd Audio Engineering Society Confer ence , Lon- don, England, 2014, pp. 2–8. [8] Gerard Roma and Xavier Serra, “Querying freesound with a microphone, ” in Pr oceedings of the F irst W eb Audio Confer - ence , Paris, France, 2015. [9] Enrico Marchetto and Geoffroy Peeters, “ A set of audio fea- tures for the morphological description of vocal imitations, ” in Pr oc. of the 18th International Conference on Digital Audio Effects (D AFx) , T rondheim, Norway , 2015. [10] Y ichi Zhang and Zhiyao Duan, “Retrieving sounds by vocal imitation recognition, ” in Pr oceedings on the 25th IEEE Inter- national W orkshop on Machine Learning for Signal Pr ocess- ing , Boston, USA, 2015, pp. 1–6. [11] Y ichi Zhang and Zhiyao Duan, “Imisound: An unsupervised system for sound query by vocal imitation, ” in IEEE Interna- tional Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , Shanghai, 2016. [12] Y ichi Zhang and Zhiyao Duan, “Supervised and unsupervised sound retrie val by v ocal imitation, ” Journal of the Audio Engi- neering Society , vol. 64, no. 7/8, pp. 533, 2016. [13] Y ichi Zhang and Zhiyao Duan, “Iminet: Con volutional semi- siamese networks for sound search by vocal imitation, ” in IEEE W orkshop on Applications of Signal Pr ocessing to Au- dio and Acoustics , New Y ork, USA, 2017, pp. 304–308. [14] Elias P ampalk, Perfecto Herrera, and Masataka Goto, “Com- putational models of similarity for drum samples, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 16, no. 2, pp. 408–423, 2008. [15] Ernst T erhardt, “Calculating virtual pitch, ” Hearing r esearch , vol. 1, no. 2, pp. 155–182, 1979. [16] Augustus Odena, V incent Dumoulin, and Chris Olah, “Decon- volution and checkerboard artifacts, ” Distill , v ol. 1, no. 10, pp. e3, 2016. [17] Mark Cartwright and Bryan Pardo, “V ocalsketch: V ocally imi- tating audio concepts, ” in Pr oceedings of the 33rd Annual ACM Confer ence on Human F actors in Computing Systems , Seoul, K orea, 2015. [18] Franc ¸ ois Chollet et al., “Keras, ” 2015. [19] Mart ´ ın Abadi, Ashish Agarwal, P aul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S Corrado, Andy Davis, Jef- frey Dean, Matthieu Devin, et al., “T ensorflow: Large-scale machine learning on heterogeneous distributed systems, ” arXiv pr eprint arXiv:1603.04467 , 2016. [20] Diederik Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” arXiv preprint , 2014. [21] International T elecommunication Union, “ITU 1534-1: Method for the subjecti ve assessment of intermediate quality lev el of coding systems, ” T ech. Rep., International T elecom- munication Union, 2003. [22] Mark Cartwright, Bryan Pardo, Gautham J Mysore, and Matt Hoffman, “Fast and easy crowdsourced perceptual audio ev alu- ation, ” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2016, pp. 619–623. [23] Jacob Cohen, Statistical power analysis for the behavioral sci- ences , Erlbaum, NJ, USA, 2nd edition edition, 1988. [24] Maurice G Kendall and B Babington Smith, “The problem of m rankings, ” The Annals of Mathematical Statistics , vol. 10, no. 3, pp. 275–287, 1939. [25] Roy C Schmidt, “Managing delphi surve ys using nonparamet- ric statistical techniques, ” Decision Sciences , v ol. 28, no. 3, pp. 763–774, 1997. [26] Douglas Bates, Martin M ¨ achler , Ben Bolker, and Ste ve W alker, “Fitting linear mix ed-effects models using lme4, ” Journal of Statistical Software , v ol. 67, no. 1, pp. 1–48, 2015. [27] Manuel K oller , “rob ustlmm: An r package for robust estima- tion of linear mixed-ef fects models, ” Journal of statistical soft- war e , vol. 75, no. 6, 2016.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment