보컬 기반 드럼 샘플 검색을 위한 심층 컨볼루션 오토인코더 유사도 측정
본 연구는 보컬 모방을 이용한 드럼 샘플 검색에서, 컨볼루션 오토인코더(CAE)로 학습한 특징이 청각적 유사도 평가와 얼마나 잘 맞는지를 검증한다. 33 k개의 오디오와 6 k개의 보컬 모방을 이용해 11가지 CAE 구조를 학습하고, 30개의 드럼 사운드와 420개의 보컬 모방에 대한 인간 청취자 평점과 비교하였다. 결과는 CAE 특징이 기존 스펙트로그램, MFCC, 시간적 특징보다 높은 예측력을 보이며, 특히 시간 해상도를 보존한 설계가 성능…
저자: Adib Mehrabi, Keunwoo Choi, Simon Dixon
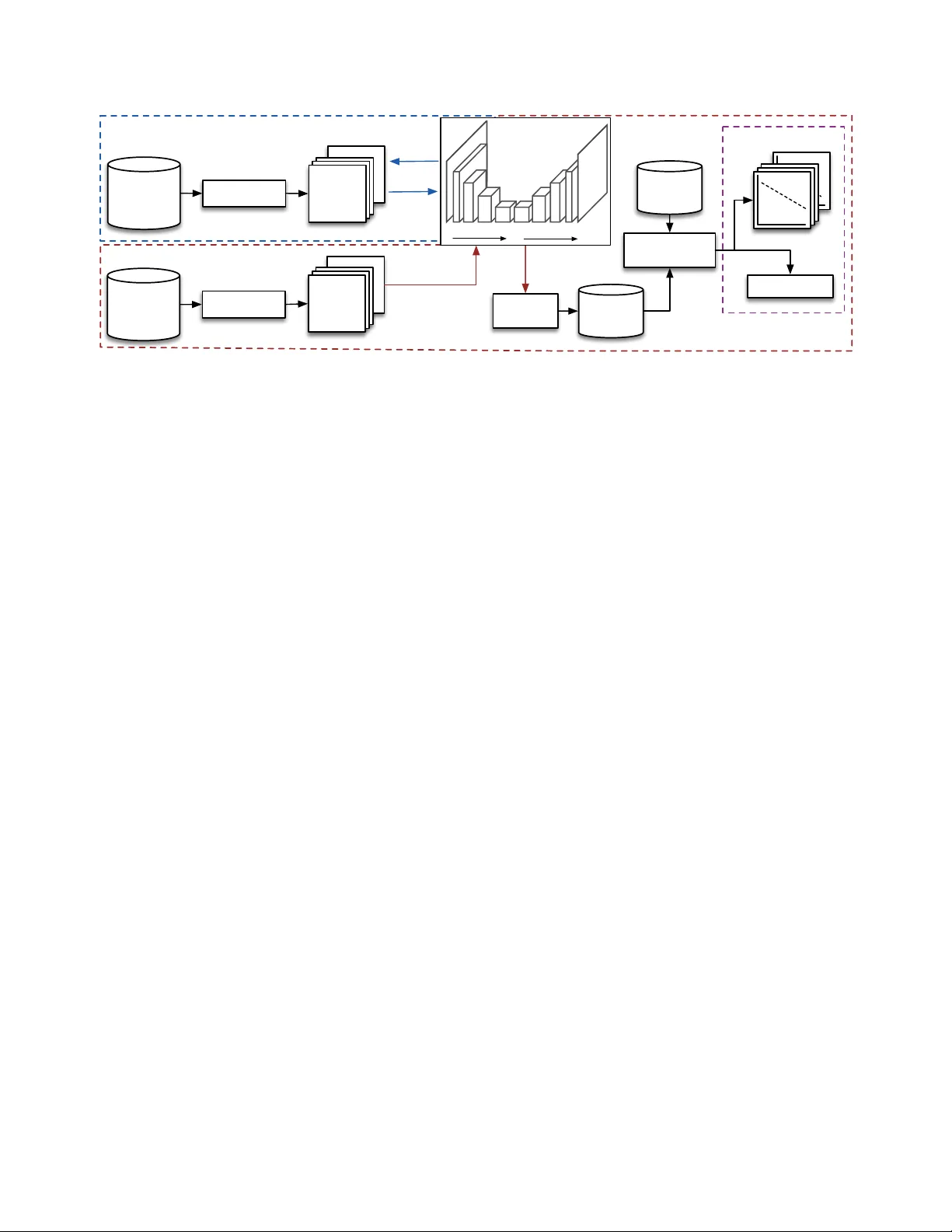
본 연구는 보컬 모방을 이용한 드럼 샘플 검색, 즉 “보컬 기반 쿼리(By Vocalisation, QBV)” 상황에서 청각적 유사도를 정량적으로 예측할 수 있는 특징 표현을 찾는 것을 목표로 한다. 기존 QBV 연구는 주로 보컬 모방과 정확히 일치하는 사운드를 찾는 매칭 정확도에 초점을 맞추었으며, 특징 선택에 대한 체계적 평가가 부족했다. 이에 저자들은 인간 청취자가 제공한 유사도 평점을 기반으로, 다양한 특징 집합이 거리와 인지적 유사도 사이의 관계를 얼마나 잘 설명하는지를 검증한다.
연구는 크게 네 단계로 진행된다. 첫째, 33 k개의 퍼커션 및 효과음, 6 k개의 보컬 모방을 포함한 대규모 데이터셋을 구축하고, 모든 오디오를 128 × 128 Bark‑gram 형태로 전처리한다. 둘째, 11가지 변형의 컨볼루션 오토인코더(CAE)를 설계한다. 각 CAE는 4계층 인코더·디코더 구조에 배치 정규화와 ReLU 활성화를 적용하고, 디코더에서는 업샘플링을 사용해 체크보드 아티팩트를 방지한다. 인코딩 레이어의 커널 크기와 스트라이드 조합을 달리해 “Square”(정사각형), “Tall”(시간 축 강조), “Wide”(주파수 축 강조) 형태의 텐서를 생성한다.
셋째, 30개의 드럼 사운드(킥, 스네어, 심벌, 하이‑햇, 톰)와 각각에 대한 14명의 뮤지션이 만든 420개의 보컬 모방을 수집한다. 63명의 청취자를 대상으로 MUSHRA 기반 웹 실험을 진행해, 각 보컬 모방과 동일 클래스 내 6개의 드럼 사운드 사이의 유사도를 0‑100 연속 척도로 평가받았다. 신뢰도 검증을 위해 중복 테스트와 스피어만 상관을 사용했으며, 51명의 청취자를 신뢰할 수 있는 데이터로 선정해 총 9 126개의 평점을 확보했다.
넷째, 각 특징 집합에 대해 보컬 모방과 6개의 드럼 사운드 사이의 유클리드 거리를 계산하고, 이를 0‑1로 정규화한다. 이후 선형 혼합 효과 회귀(LMER) 모델을 사용해 거리와 청취자 평점 사이의 관계를 추정한다. 모델은 청취자별 랜덤 인터셉트와 사운드별 고정 효과, 그리고 거리와 사운드 간 상호작용을 포함한다. 기울기 β₁ⱼ가 0보다 유의하게 작을 경우, 해당 특징이 거리와 인지적 유사도 사이에 부정적 상관관계를 강하게 설명한다는 의미이다. 모델 적합도는 AIC(아카이케 정보 기준)와 기울기 유의성 비율(정확도)로 평가한다.
베이스라인으로는 (1) PK08 스펙트로그램 기반 거리, (2) MFCC 평균·분산, (3) 5가지 시간적 특징(TEMP)을 사용했다. 결과는 모든 CAE 기반 특징이 베이스라인보다 우수했으며, 특히 모델 10과 11(시간 축에 넓고 주파수 축에 좁은 인코딩 형태)이 가장 낮은 AIC(1 298, 1 299)와 83.3 %의 유의미한 음수 기울기 비율을 기록했다. 이는 인코딩 차원을 최소화하면서도 시간 정보를 충분히 보존한 특징이 인간 청취자의 유사도 판단을 가장 잘 반영한다는 것을 보여준다. 반면, 스펙트럼 차원을 크게 유지한 모델(예: 모델 1, 2)이나 주파수 축에 넓은 형태는 성능이 떨어졌다.
또한, MFCC와 TEMP와 같은 전통적인 히스토리 기반 특징은 각각 46.7 %와 40.0 %의 정확도에 그쳤으며, AIC도 2 703, 2 692로 상대적으로 높았다. 이는 보컬 모방의 미세한 타이밍, 어택, 지속 시간 변화를 포착하는 데 전통적인 주파수 기반 특징이 한계가 있음을 시사한다.
연구는 몇 가지 실용적 시사점을 제공한다. 첫째, QBV 시스템에서 고해상도 스펙트럼보다 시간적 해상도를 강조한 저차원 특징이 검색 정확도와 연산 효율성을 동시에 개선한다. 둘째, 인코딩 차원을 크게 줄이면 메모리 사용량과 검색 시 거리 계산 비용이 감소하므로, 대규모 샘플 라이브러리에서도 실시간 검색이 가능해진다. 셋째, 인간 청취자의 유사도 평가를 직접 모델링함으로써, 단순 매칭이 아닌 “가장 유사한” 사운드를 반환하는 보다 인간 친화적인 검색 인터페이스 설계가 가능해진다.
결론적으로, 본 논문은 보컬 기반 드럼 샘플 검색에서 컨볼루션 오토인코더를 이용한 특징 학습이 기존 히스토리 기반 방법보다 우수함을 실험적으로 입증했으며, 특히 시간 정보를 충분히 보존한 설계가 핵심 요인임을 밝혀냈다. 이는 향후 QBV 시스템 및 음악 정보 검색 분야에서 딥러닝 기반 특징 추출이 실용적이고 효과적인 대안이 될 수 있음을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기