The Dependence of Frequency Distributions on Multiple Meanings of Words, Codes and Signs
The dependence of the frequency distributions due to multiple meanings of words in a text is investigated by deleting letters. By coding the words with fewer letters the number of meanings per coded word increases. This increase is measured and used …
Authors: Xiaoyong Yan, Petter Minnhagen
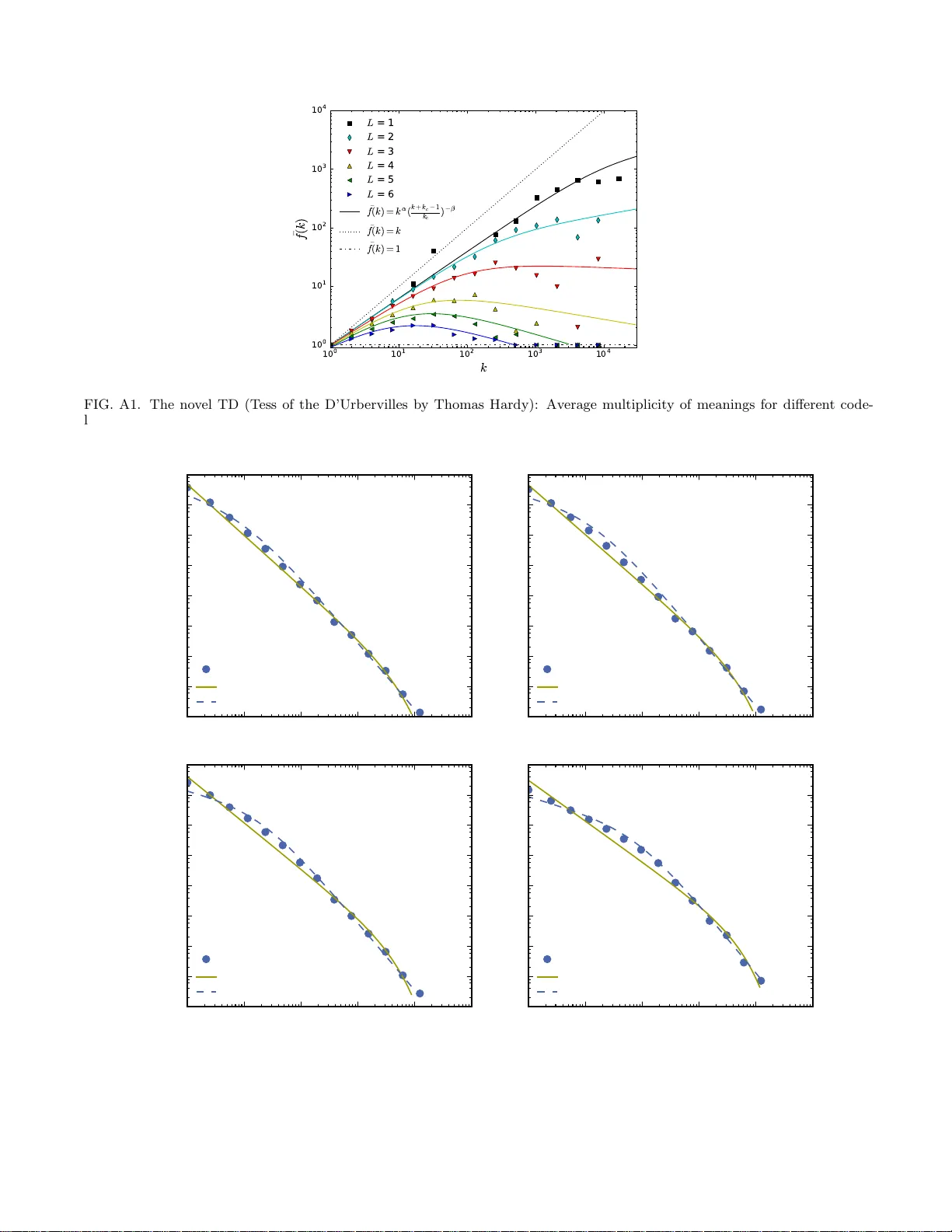
The Dep endence of F requency Distributions on Multiple Meanings of W ords, Co des and Signs Xiaoy ong Y an 1 and Petter Minnhagen 2 ∗ 1 Institute of T r ansp or tation Syste ms Scienc e and Engine er ing, Beijing Jiaotong University, Beij i ng 100044, China 2 Ic eL a b, Dep artment o f Physics, Ume ˚ a University, 901 87 Ume ˚ a, Swe den The dep endence of the frequency distributions du e to m ultiple meanings of w ords in a text is inv estigated by dele ting letters. By co ding th e w ords with few er letters the number of meanings p er coded w ord increases. This increase is measured and u sed as an input in a predictive theory . F or a text written in English, the w ord-frequency distribution is broad an d fat-tailed, whereas if the words are only represen ted by their first letter th e distribution b ecomes exp onential. Both distribution are w ell predicted by the theory , as is the whole sequence obtained b y consecutivel y representing th e w ords by the first L = 6 , 5 , 4 , 3 , 2 , 1 letters. Comparisons of texts written by Chinese c haracters and the same texts written by letter-codes are made and the similarity of the correspond ing frequen cy - distributions are interpreted as a consequence of the multiple meanings of Chinese c haracters. This further implies that the difference of the shap e for word-frequencies for an English text written by letters and a Chinese text written by Chinese c haracters is due to the coding and not to the language p er se . P ACS num bers: 89.75.Fb, 89.70-a I. INTRO DUCTION A ttempts to understand what linguistic information is hidden in the shap e of the word-frequency distribution has a long tradition [1 – 4]. A c e n tral question in this context is what sp ecial principle or proper t y of a language causes the ubiquitous obser ved ”fat tailed’ power-la w like distribution of word-frequencies[5 – 10]. The conc e pt of r a ndomness in a text da tes back to V. Mar k ov [1 1, 12]. Marko v demonstr a ted that a text when viewed a s a string of letters , contained random features like e.g . how often a ra ndomly c hosen letter is follow ed by a conso nant or a vow el. The concept of randomness in wor d-fr e quency distributions was empha- sized b y Simon in Re f. [13] who argued that since q uite a few completely different systems c lo sely hav e the same ”fat ta iled” p ow er- law like freq uency distributions, the explanation for this particular s hape m us t b e sto chas- tic and independent o f any sp ecific info rmation of the language itself. This R andomness-view was developed further in a series of paper in terms of concepts like Ran- dom Group F ormation (RGF), Random Bo ok T ransfor - mation and the Meta-b o ok [14 – 18]. According to the ”Randomness-v iew” the shap e of the word-frequency dis- tribution is a gener al consequence of randomness which carries no sp ecific informatio n of the intrinsic structure of a langua ge.[20] How ever, even if the frequency distribution of words do es not depend on the specifics o f the languag e, it may still dep e nd on how the words are coded by sym b ols. This is the sub ject of the present work. W e explore the connection b etw een, on the one hand, the sha pe of the ∗ Pe tter.Minnhagen@ph ysics.umu.se frequency-distribution o f the sym b ols used to repres en t a written text and, on the other , the informa tion conten t carried by individual s ym b ols. The relation b et ween infor mation conten t and the shap e of a word-frequency distribution go es back to Man- delbrot [5]. The fo cus in this earlier work was the infor- mation conten t obtained by co ding an individual word by symbols like individual letters . In the present case we instead star t o ut b y taking the written individual words as the symbols a nd fo cus on the information loss caused by the fact that an individua l written word in a text can hav e mo re than one meaning. In o r der to investigate this in a systematic wa y we v ary the multiplicit y of mea nings for a written word by deleting letters . F o r ex a mple in- vest , inv , and i are the 6-, 3- and 1 -first-letter-versions o f the full word investigate . The pap er is organized as follows: fir s t we in sec tion II define the L -letter c oding mo del. The multiplicities of words and the cor resp onding word-frequencies based on the novel Mo b y Dick by Herman Melville are mea sured for the L -letter word-versions o f the text. This directly leads to the ques tion of how the frequency-dis tr ibutions and multip licities are connected. Section I II uses the maximum entrop y estimate given by Random Gr oup F ormation(RGF)-form ulation [17 – 20] to obtain such a direct link. This is p ossible b ecause the RGF-estimate predicts the shap e of the frequency distribution using the multiplicities of meanings as a direct input [18, 20]. In the light of these findings we in section IV in vesti- gate the frequency distribution of C hines e characters for Moby Dick written by Chinese characters. It is fo und that the ch ara cter-frequency distribution is very similar to the L =3- co ding of Moby Dick in Eng lish. This sug- gests that the mult iple meaning s of Chinese characters are similar to the multiple meanings of the L = 3-co des. This is in acc o rdance with the findings of Ref.[18 ]. It 2 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 k 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 ¯ f ( k ) L = 1 L = 2 L = 3 L = 4 L = 5 L = 6 ¯ f ( k ) = k α ( k + k c − 1 k c ) − β ¯ f ( k ) = k ¯ f ( k ) = 1 FIG. 1. The av erage multiplicit y of meanings for different code- lengths L . The data are for the co de-lengths L = 1 − 6. F or L = 1 the data approximately follo ws th e straight line f ( k ) ≈ k 0 . 8 . More generally the data ben d s for large r k and can b e app ro ximated b y t h e function f = k α (( k + k c − 1) /k c ) − β (full curves in the figure), as describ ed in the text . The curves are data-fits to this functional form. This a pri- ori kn o wledge of the m ultiple meanings will serve as an input in the RGF-prediction.The horizonta l dashed - dotted line cor- respond s to the case when co des only ha ve single meanings, f ( k ) = 1.The dotted line corresponds to the sp ecial case when the co des increases linearly with k , f ( k ) = k . is also noticed that the co ding of a w ord in E nglish by a three-tw o-one letter sequence, such that invest igate is co ded by the four symbols inv, est, iga, te , leads to a n even closer similar ity . Finally s e c tion V contains a summary . An a nalysis of a second nov el (T ess of the D’Urb ervilles by Thomas Hardy) is given in an Appendix, as a v erificatio n o f ana l- ysis based on the novel Moby Dick by Herman Melville. II. MUL TIPLICITY AND L -LETTER CODING In an alphabe tic text ea c h w ord is coded by a combi- nation of letters. F or example the fir st word in the novel Moby Dick b y Herma n Melville is, when written in En- glish, c al l . Thus c al l is the letter -co de, or mo re generally the symbol, for the word a nd the letter- co de s for differ - ent words are separa ted by blanks. In principle different words ca n sometimes b e r epresented by the same letter- co de. This mea ns that a letter-co de can r epresent a word with more than one meaning in the text. The present inv estiga tion is addr e s sing the frequency distribution of co des with m ultiple meanings. The num b er of w ords with m ultiple meaning s within an E nglish nov el co ded by the English a lphabetic letter-co de are few and ca n to a firs t approximation be ignored [18, 1 9]. In order to systemat- ically inv estigate the effect of multiplicit y we instead use a r educed a lphabetic letter- c ode, the L -letter repr esen- tation. In this repr esentation a word is r epresented by only the first L letters in the Eng lish letter-co de. Thus for L = 6 r epr esente d b ecomes r epr es and c al l rema ins c al l , whereas for L = 3 r epr esente d beco mes r ep and c al l bec omes c al . In the most extr eme case L = 1 re pr esent e d bec omes r a nd c al l bec o mes c . The p oint is that the smaller the v alue L the harder b ecomes the interpreta- tion o f the tex t, b ecause the loss of infor mation ca used by shor tening the letter-co de. This missing informatio n has to be supplied b y the rea der and the a ctually amount of the informa tion loss is directly rela ted to choo s ing be- t ween the p oss ible mult iple meanings the co des hav e in the text. Figure 1 shows the av erage n umber of meanings , f ( k ), for L -co des which o ccurs k times in the text. An Eng lish text of the size of a nov el contains few words with multi- ple meanings within the novel. Hence the multiple mean- ings of a L-co de is o btained from the num b er o f differen t words which the pa rticular L-co de repres en ts within the text. Note that a code which o nly occ urs ones in the text can o nly hav e o ne meaning, so that a ll curves star t from f ( k = 1) = 1. Also note that the gener al trend is that f ( k ) increases with decr easing L for a fix e d o ccur rence k . This just means that the shorter the L -co de is for a given k the mor e meanings has a co de with this o ccur r ence on the av er age. How ever, apart from this, the f ( k )-cur ves for different L are non-trivia l and we will, in o rder to facilitate calculations, use the simple parametriza tion f ( k ) = k α k + k c − 1 k c − β (1) where α, β and k c are fr ee parameter s . This parametr iza- tion catches the essential feature s o f the av er age multiple- meaning function f ( k ) for different L -co des (compar e Fig. 1). Note that the explicit for m of the par ametriza- tion given b y Eq.(1) ha s no sig nificance p er se as long a s it catches the essen tial trend of the data. The question a ddressed in the present work is how this the average mult iple-meaning function f ( k ) for different L -co des is r e flected in the actual frequency distribution of the cor resp onding L -co des. Figures 2 and 3 gives the cor- resp onding frequency distributions fo r the L -co des. Fig- ure 2 show the frequency probability distributions, P ( k ), for the L -co de cases L = 6 , 5 , 4 , 3. In the case of L = 1 and 2 the num b er of different co des are to o few (o nly the 26 letters in the English alphab et in case of L = 1) to make a binning meaningful and a s a co nsequence the cu- m ulant distributions P ( > k ) give b etter represe ntations. Fig. 3 gives the cumulan t dis tributions P ( > k ) corr e- sp onding to L = 1 and 2. In the following section we show that f ( k ) given by Fig. 1 ca n b e explicitly linked to the distributions given in Figs 2 and 3. 3 10 0 10 1 10 2 10 3 10 4 10 5 10 − 9 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 P ( k ) 6 Letters (a) Binned Data ( M = 214675 , N = 11921 , k max = 14175) RGF ( γ = 1 . 73 , b = 1 . 09 e − 04) RGF with f ( k ) ( γ = 1 . 64 , b = 2 . 00 e − 05) 10 0 10 1 10 2 10 3 10 4 10 5 10 − 9 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 5 Letters (b) Binned Data ( M = 214675 , N = 9308 , k max = 14175) RGF ( γ = 1 . 67 , b = 1 . 26 e − 04) RGF with f ( k ) ( γ = 1 . 72 , b = 1 . 00 e − 05) 10 0 10 1 10 2 10 3 10 4 10 5 k 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 P ( k ) 4 Letters (c) Binned Data ( M = 214675 , N = 5555 , k max = 14175) RGF ( γ = 1 . 57 , b = 1 . 46 e − 04) RGF with f ( k ) ( γ = 1 . 85 , b = 1 . 00 e − 06) 10 0 10 1 10 2 10 3 10 4 10 5 k 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 3 Letters (d) Binned Data ( M = 214675 , N = 1899 , k max = 18088) RGF ( γ = 1 . 38 , b = 1 . 35 e − 04) RGF with f ( k ) ( γ = 2 . 13 , b = 1 . 00 e − 07) FIG. 2. F requency d istributions P ( k ) for the co des L = 6 − 3. The data in binned form are given by the filled dots. The qu estion is how these distributions are related to the multiple meanings given in Fig. 1 . A s describ ed in section I II , the RGF predicts P ( k ) if one a priori know s the t riple ( M , N , k max ) and the av erage multiplicit y f ( k ). The a p riori known v alues ( M , N , k max ) are giv en in the panels. The predictions are giv en by the dashed curves. The agreemen ts b etw een data and predictions are striking. F or comparison the predictions, when assuming that the co des only h a ve single meanings, are given by the full curves. This means th at the discrepancies b etw een t he full curves and the data are caused by the multiple meanings of the co des. II I. A D IRECT LINK BETWEEN MUL TIPLE MEANINGS AND FREQUENCY DISTRIBUTIONS In Ref. [18] it was argued that max im um entrop y within the R GF-formulation [17] provides a link between the m ultiple-meanings and the freq uenc y -distribution. The theore tical underpinning for this connec tio n has bee n further dev elop ed in Ref. [20]. The pres en t work go es o ne s tep further and shows that such a link is op en to quantitativ e testing . The RGF-form ulation of maximum e n tropy is bas e d on the information conten t [17, 20]. It starts out with a r andom gro up so rting based on the a ssumption that each o f a se t of M ob jects has a unique lab el i where i ∈ [1 , 2 , ..M ] [17, 1 8]. Suppo se that the num b er o f gr oups with k ob jects is N ( k ), then the total num b e r of ob jects in these groups are k N ( k ) and the information needed to lo calize one of them is ln[ k N ( k )] (in nats=na tural logarithms). The av e r age of this information over the v arious group s izes k is P k [ N ( k ) / N ] ln[ k N ( k )]. The group size distribution P ( k ) = N ( k ) / N is norma lized such that P k N ( k ) N = 1 a nd within the R GF approach this is just the probability distribution for the gr oup sizes. This mea ns that the av erage information for finding an ob ject is a functional o f the distr ibution P ( k ) and up to a constant given by I [ P ( k )] = P k P ( k ) ln[ k P ( k )]. The maximum e ntropy cor resp onds to the minimum of the functional I [ P ( k )] [17]. The RGF-approach min- imizes I [ P ( k )] under three c onstraints: fixed nor mal- ization ( P k P ( k ) = 1), fixe d a verage M / N , and fixed ent ropy S 0 . These constra in ts ar e handled with thr ee 4 10 0 10 1 10 2 10 3 10 4 k 10 − 2 10 − 1 10 0 C ( k ) 2 Letters (a) Binned Data ( M = 214675 , N = 261 , k max = 25709) RGF ( γ = 0 . 1 , b = 6 . 00 e − 04) RGF with f ( k ) ( γ = 0 . 98 , b = 4 . 00 e − 04) 0 5000 10000 15000 20000 25000 30000 35000 k 10 − 2 10 − 1 10 0 1 Letters (b) Binned Data ( M = 214675 , N = 26 , k max = 35259) RGF ( γ = 0 . 0 , b = 1 . 10 e − 04) RGF with f ( k ) ( γ = 0 . 0 , b = 1 . 10 e − 04) FIG. 3. F requency distributions in the cumulan t form P ( k > ) for the co de-lengths L = 1 and L = 2.The data (without binning) are give n by the filled dots. The dashed curves are the RGF-predictions in clu d ing the a priori k no wledge of the multiple meanings given by Fig. 1. The agreemen ts b etw een data and predictions are v ery goo d. The fulled curve s are the RGF-predictions assuming th at each code only ha ve a single meaning. On e notes that the d ifference b etw een the full and dashed curves is small and t hat b oth describe the data very w ell. The reason, as ex plained in the text, is that the closer the a verage multiple meanings are describ ed by f ( k ) = k α the smaller b ecomes th e difference b etw een th e dashed and full curves (compare Fig. 1). A lso note th at Fig. 3 (b) is plotted in log-lin which means that P ( > k ) is close to an exp onential in this case. Lagra ng ian multiplier a nd leads to the unique fun tional form P ( k ) = A exp( − bk ) /k γ (2) where A , b and γ ar e three constants stemming fro m the three Lag r angian m ultipliers. Since the functional form is unique, any sufficient a priori knowledge dire ctly ex- pressible in P ( k ) can b e used to determine the constants. The RGF-description uses the three v alues [ M , N , k max ]: the num be r of ob jects in the larges t gr oup, k max , is re- lated to P ( k ) by the relations P M k = k c P ( k ) = 1 / M and < k max > = P M k = k c k P ( k ) where the first determines a low er bo und on the in terv al [ k c , M ] which co n tains the largest group and the seco nd the av erag e size o f a group within this interv al. The a ctual largest group size k max is used as an input for this av erag e. One of the ass umption for R GF is that the ob jects can be uniquely lab eled. The question addres sed in the present work is how the RGF-form will change if the same lab el is used for many ob jects. This means that the information to lo calize an ob ject belo nging to a gr oup size ln[ k N ( k )] is lacking by some amount ln f ( k ). This amount is what has to b e supplied externally in order to uniquely iden tify the ob jects. Thus the informa tion av ailable within the sys tem is now instea d ln[ k N ( k )] − ln f ( k ) = ln[ k N ( k ) /f ( k )]. The av er age information I [ P ( k )] changes to I f [ P ( k )] = P k P ( k ) ln[ k P ( k ) /f ( k )] and the corr espo nding RGF-distribution changes to P ( k ) = A exp( − bk ) / ( k / f ( k )) γ (3) This mea ns that if the functional form of the information-los s function f ( k ) is known, t hen the dis tr i- bution P ( k ) can ag ain b e predicted fr o m the knowledge of the triple [ M , N , k max ]. Note that the lab eled entities which are so rted into groups of size k are no w themselves subgro ups n i where i la b els the subgroups and n i is the num b er of ob jects in the subgroup i . The information required to iden- tify an ob ject whic h b elongs to one of the gr oups which contain k subgroups is hence I = ln P i k n i k where i k nu merates a ll subgroups b elonging to groups of s ize k . In the case that n i k = 1 for all i k this reduces to I 1 = ln[ k N ( k )] where N ( k ) is the num b er of groups and each group contains k ob jects. Co nsequently the info-lo ss ln f ( k ) = I − I 1 is given by ln f ( k ) = ln X i k n i k k N ( k ) (4) or f ( k ) = 1 k N ( k ) X i k n i k (5) which means that f ( k ) is the av er age num b er of ob jects per s orted ent ity . In the sp ecific example of words, this translates to the average num b er of mea ning s for a word which o ccur k times in the text. Thus f ( k ) o btained in Fig. 1 ar e e q ual to f ( k ) provided the tiny mu ltiplicity of words w ithin the original Eng lish version of Moby Dic k can b e ignored. The statement, that the multiple meaning of w ords in the origina l v ersion of Mo b y Dick can b e ignored for 5 10 0 10 1 10 2 10 3 10 4 k 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 P ( k ) Binned data ( M = 214675 , N = 16698 , k max = 14175) RGF predicti on ( γ = 1 . 81 , b = 8 . 90 e − 05) FIG. 4. W ord-frequen cy distribution for Moby Dic k. T he RGF-prediction illustrates that the assumption that the w ords to large extent only carries single meanings gives an excellen t prediction p ro vided the words are fully written out: The p redicion is completely determined from the a pri- ori knowl edge of the v alues of ( M , N , k max ) and the single meaning assumpt ion f ( k ) = 1: Data; filled dot an d RGF- prediction; dashed curve. practical purp ose s , co rresp onds to the assumption that f ( k ) = 1 fo r all k . In this case the word frequency is predicted by Eq. (2) for the given known v alues of [ M , N , k max ]. Fig. 4 shows tha t this is indeed the case. F urthermore in Refs. [18, 19] it was shown that the sin- gle meaning a ssumption f ( k ) = 1 in ge neral g ives very go o d frequency distribution pre dic tio ns for texts written by nor mal letter-a lphabets, suggesting that the m ultiple meanings p er written word is small and often can b e ig- nored. In Fig. 2 the as sumption of single meanings f ( k ) = 1 is tested on the L -letter co des with L = 6 , 5 , 4 , 3. The predictions from the RGF-estimate corr esp ond to the full curves in the figure. F or L = 6 the deviation b et ween the data and the prediction is rather sma ll. Ho wev er , as L decreases the deviation be comes larger a nd for L = 3 it is substantial. In or de r to tes t if this deviatio n is due to the m ultiple meanings of the L - letter co des, all one has to do is to use the actual known mult iplicity f ( k ) = f ( k ) in the RGF-estimate instead of f ( k ) = 1 (compar e Fig. 1). This changes the RGF-prediction to the dashed curves in Fig. 2. The ag reement b etw een the predictions (dashed curves) a nd the data (dots) is strik ing. Thus the RGF- estimate pro vides a direct quantitativ e link betw een the m ultiplicity of meanings and the cor resp onding freq ue nc y distributions. Fig. 3 gives the cases for L = 1 a nd 2. The most striking ca s e is L = 1 , which c o rresp onds to repres en ting 10 0 10 1 10 2 10 3 10 4 10 5 k 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 P ( k ) MD Ch. Char. ( M = 368097 , N = 3604 , k max = 18521) MD 3-Letters ( M = 214675 , N = 1899 , k max = 18088) FIG. 5. Direct comparison b et wee n L = 3-co ding of Moby Dick in English and Mob y D ick in written Chinese by Chinese chara cters. Note the strong ove rlap. In case of t he L = 3-cod in g the shap e of the frequency distribution is d irectly connected to the multiple meanings of the co d es (compare discussion of Fig. 1). This suggest to us t h at the multiple meanings of Chinese characters is likew ise link to t he multiple meanings of t he Chinese characters. each word in the text b y just its first letter. As seen from Fig. 1, the log f ( k ) versus log k is r oughly linear, so that in this case f ( k ) = k α with α ≈ 0 . 8. This means tha t Eq.(3 r educes to the form Eq.(2). Conseq uen tly the full prediction with the known f ( k ) and the one assuming f ( k ) = 1 should in this case y ield approximately the same prediction. As seen in Fig. 3(b) this is indeed the case: b oth predictions descr ibe the data very well. Note that Fig. 3 (b) is plotted is in lin-log so that the fact that the da ta to g o od appr oximation falls an a s traight line shows that the corresp onding cum ulant P ( > k ), a nd as a consequence also P ( k ), are close to exp onential. It is in teresting to note that if f ( k ) = k , then the RGF- prediction given by Eq .(3) reduces to just an exp onential. The distribution of first letters in Moby Dick a pproaches this limiting ca s e (compar e Fig . 1). One may als o note that the RGF-estimate is not re- stricted to broad p ow e r -law like distr ibutions, as illus- trated by the case s L = 1 and L = 2. This feature has bee n further explored in Ref. [20]. IV. QUALIT A TIVE CONNECTION TO CHINESE CHARACTERS In Ref. [1 8] it was argued, that the dev iation betw een the RGF-estimate with f ( k ) = 1 for a text written by Chinese characters and the fr e quency distribution of the characters, was caused by the multiple meaning s of the Chinese characters. How ever, in the ca se o f Chinese char- acters there is no e a sy wa y to directly obtain the mult i- 6 10 0 10 1 10 2 10 3 k 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 P ( k ) 10 t h part (a) MD Ch. Char . ( M = 36810 , N = 2356 , k max = 1801) MD 3-Letters ( M = 21468 , N = 1301 , k max = 1807) 10 0 10 1 10 2 k 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 100 t h par t (b) MD Ch. Char . ( M = 3681 , N = 986 , k max = 187) MD 3-Letters ( M = 2147 , N = 597 , k max = 183) FIG. 6. Direct comparison b etw een L = 3-co ding of Moby Dick in English and Mob y D ic k in written Chinese b y Chinese chara cters when taking parts of t he texts. The multiple meanings of the L = 3-co des decrease when shortening th e text and th is changes the frequency distribution.Provided t he shape of the frequency distribution for Chinese c haracters is lik ewise linked to the multipli city of meanings, one ex pects a very similar c hange in th e distributions. Fig . 6 (a) and (b) shows that this exp ectation is indeed b orne out. The comparisons are for a 10 th -part (a) and a 100 th -part (b ). ple meanings of characters and hence the function cor- resp onding to f ( k ). Th us a direct link, like the one ob- tained for the L -letter co des, is harder to o bta in. How- ever, qualitatively f ( k ) corre s ponding to Chinese char- acters has to be a function starting from f ( k = 1) = 1 (beca use a character whic h only occur s o nc e in the text can only have one meaning), then it increase s with k , but with s ome cut-o ff beca use even the most common character do es hav e a limited num b er of meanings. Thus you exp ect something qualitative similar to the m ultiple meanings in Fig. 1. T o tes t this qualitative similarity , Fig. 5 compares the frequency distribution of L =3-letter co des for Moby Dick with the character distr ibution of Moby Dic k in Chinese tra nslation. In other words you compare the same text repres e ntated by t wo completely different s ym b olic sy stems. As seen in Fig . 5 the tw o cor- resp onding frequency distribution are very similar which suggests that the f ( k ) co rresp onding to Moby Dic k in Chinese characters are also akin to the one for the L = 3- letter co de g iv en in Fig. 1. This similarity is further enforced by compar ing par ts of Mo by Dick for the L =3- letter co des and the Chinese characters. Fig. 6 compares the 10 th -parts a nd 100 th -parts a nd aga in the clos e sim- ilarity r emains. In the case of the L =3-letter co des, we know that the s hape of the distribution is direc tly linked to the multiplicit y of meanings. The close similar it y with the same text-parts written by Chinese characters, sug- gest to us that the change in shap e is also in the case Chinese characters link ed to the multiplicit y of meanings . The sp ecial thing with the L -letter co ding is that for this co ding the mult iplicity of meaning s for the co des can be easily obtained. More gener ally you can, of course, de- vice o ther partia l le tter co des. Howev er for such co des it is often ha rder to directly extr act the m ultiplicity of meanings. Fig. 7 shows the frequency distr ibution for Moby Dick using the following partial letter-co de: an English word is c o ded by three- t wo-one letter sequences , such that se quenc e is co ded by the three symbols se q, uen, c e, . Represented in this way Mo b y Dic k consists of M = 382 049 co des of which N = 3322 are differ- ent and the most co mmon co de app ears k max = 1 8 584 times in the text. Moby Dick in Chinese written by Chi- nese characters contains M = 3680 97 characters of which N = 36 0 4 are different Chinese c hara cters a nd the most common app ears k max = 18 521 times. The p oint is that the triple ( M , N , k max ) is approximately the same for these tw o ca ses. R GF pr edicts the frequency distr ibu- tion fr o m this together with f ( k ). The r esults are given in Fig. 7: Fig. 7(a) is for the full Moby Dick writ- ten in the ab ov e par tial letter co de, whereas Fig . 7(b) is for the 1 00 th -parts. As expe cted the RGF prediction for f ( k ) = 1 g iv es a go o d agr eement for the 10 0 th -part bec ause the multiple meaning s for the c o des and charac- ters ar e almost neglig ible for text sufficiently short tex t. F or the full text there is , o n the other hand, a disc rep- ancy , which in Fig. 2(d) was attributed to the mult iple meanings of the c o des and characters for a long er text. If we assume that this multip licity , in case o f b oth the ab ov e par tial letter co de v ersion and Chinese characters in Fig. 7(a), are very similar to the L =3-letter co de ver- sion and use the co rresp onding L = 3 letter f ( k ) = f ( k ), the das hed curve in Fig. 7 is obta ine d. The close agree- men t again sugg e s t that the m ultiple meanings ar e di- rectly linked to the sha pe of the cor resp onding frequency distributions. One might mor e gener ally a sk, that if y ou co de the 7 10 0 10 1 10 2 10 3 10 4 k 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 P ( k ) Full part (a) RGF with f ( k ) ( γ = 2 . 13 , b = 1 . 00 e − 07) MD Ch. char . ( M = 368097 , N = 3604 , k max = 18521) MD letter code ( M = 382049 , N = 3322 , k max = 18584) 10 0 10 1 10 2 k 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 100 t h par t (b) RGF ( γ = 1 . 81 , b = 9 . 50 e − 03) MD Ch. char . ( M = 3681 , N = 986 , k max = 187) MD letter code ( M = 3821 , N = 968 , k max = 189) FIG. 7. Comparison b etw een Mo dy Dic k represented by Chinese characters and Moby Dick represented by the partial letter code describ ed in the text . These tw o representation of the same text have closely the same total num b er of codes, M , number of different co des, N , and th e number of rep etitions of the most frequ en t co d e k max . Fig. 7(a ) illustrates that also the correspondin g frequency distributions are closely the same. In addition Fig. 7(b) illustrates th at b oth frequ en cy distributions changes in the same w ay , when shortening the t ext: the 100 th -parts of t he tw o different cod es are also closely similar. F or the 100 th -parts the RGF-prediction, assuming single meanings ( f ( k ) = 1), gives a goo d p rediction for b oth co des (full curve, t he difference of triples ( M , N , k max are so small that the tw o RGF-predictions ov erlap). How ever, RGF-prediction assuming single meaning differs from the data in Fig. 7 (a). Inserting t he k no wn f ( k ) for the L = 3-case (compare Fig. 1 and Fig. 2(d)) into the RGF-prediction gives the dashed line in Fig. 7(a). This suggests th at m ultiple meanings are crucial for the shap e of the frequency distribution also in case of Chinese chara cters. same text in tw o difference ways, s uc h that the tota l nu mber of co des M , the num b er of different co des N and the o ccurrence of the most fr equen t co de k max are the same, would that also imply that the f ( k ) has to b e rather similar b ecaus e after all the information conten t in the total text is also clo s ely the same. Fig. 7 suggest that this might b e the case. V. SUMMAR Y The relation b etw ee n multiple meanings and the shap e of frequency distributions w ere explored b y using a particular letter-co ding of w ords in a text from whic h the multiple meanings of the co des could be extracted. By using the maxim um en tropy principle in the RGF information-bas ed form ulation together with the known m ultiplicity as an input, it was demonstrated that the corres p onding frequency distributions are predicted to very go o d approximation. F rom this we concluded that the shap e of the frequency distribution essentially is determined by how the text is co ded. More precisely we concluded that the shap e of the frequency dis tribution is to go o d a pproximation ob- tained from the maximum entrop y principle, provided one k nows the total num b er of symbols M, the num b er of sp ecific symbols, N, and the o ccur rence of the most frequent symbol, k max , tog ether with the average mul- tiplicit y of the sy mbo ls, f ( k ). Thus knowledge of the frequency of the most co mmon symbol and the av erag e m ultiplicity o f the s ym b ols to g ether with the total num- ber of symbols a nd the n umber of sp ecific symbols is basically the only information which is reflec ted in the frequency distribution. Or , express ed in another w ay , the frequency distribution for words or character s of a written languag e car ries basica lly no a dditional sp ecific information ab out the underlying languag e. More lan- guage sp ecific prop erties ar e instead reflected in c orrela- tions b etw e e n different words. Nevertheless, as shown in Ref.[15], the triple ( M , N , k max ) by itself is o n the av er - age different for tex ts written by differen t author s and can b e used as a ” author-finger print ”. F rom the similar ity of a text e x pressed b y a pa r tial let- ter co de and by Chinese characters, we concluded that the Chinese characters ar e s ym b ols in the same sense as the partial letter-co des. Thus also for texts wr itten by Chinese c haracter s the frequency distributions are to go o d approximation determined by just the tota l num b er of symbols, the n umber of sp ecific symbols a nd the oc - currence of the mo st frequent s y m b ol, together with the av er age multiplicit y . One may then ask how this conclusion is rela ted to the view that the particular sha pe of the Chinese charac- ter frequency distribution is explicitly related to partic- ular detailed fea tur es of the Chinese character co ns truc- tion like e.g. its hierar c hic structure.[21] The conclusio n drawn from the present work is that the shap e of the character distribution is unrela ted to such sp ecific fea- 8 tures. In a more genera l context the answer is that for complex systems , the global statistica l macrosc o pic fea- tures do often not dep end on the microscopic details of the system.[20] W e also no te that if a text is co ded by unknown sym- bo ls, an analys is of the symbol-fr e quency distribution may g iv e a clue to the av erag e m ultiple meanings of the symbols. If this analys is suggests almost no m ultiple meanings, this one implies that each symbol codes for a single word. App endix A: The purp ose of this App endix is show that the re- sults found in the present inv estigation are not spe- cial prop erties of a particular nov el. T o this end we give the results for the same analysis based on second nov el. W e hav e chosen T e s s of the D’Urb ervilles(TD) by Thomas Hardy which is characteriz e d by the triple ( M , N , k max ) = (152 952 , 1191 7 , 8 717) to b e compared to Mo b y Dic k which is c hara cterized by the triple ( M , N , k max ) = (214675 , 16 6 98 , 14175). According to RGF these t wo triples contain enough information for predicting the co rresp onding word- frequency distributions. The RGF-prediction TD is given in Fig.A4 which should be compar ed to the corr esp o nd- ing pr e diction for Moby Dick given in Fig.4. In b oth cases the ag r eement b etw een prediction and data is very go o d. F rom the p oint of view in the present paper, such a n excellent a greement presumes that the effect of m ultiple meanings of the w ords can b e ignored. If the multip le meanings cannot b e ignor ed then multiple meanings can be approximately taken into account from the average nu mber of meanings for a word whic h o ccur s k -times in the text, f ( k ). RGF then predicts the frequency distri- bution from the knowledge of ( M , N , k max , f ( k )). Fig.A1 shows the multiple meanings of the L-le tter co des fo r TD and should be compare d to corresp onding Fig.1 for Moby Dick. The tw o figures ar e very similar. Fig.A2 shows the TD-data for the L-letter co des L=6,5,4,3 together with the R GF prediction ignoring m ultiple mea nings (full drawn curves) and including mul- tiple meanings (dashed curves). The conclusion drawn in the present pap er is that the disc repancy b etw een the data and the full drawn cur ves ar e caused by the multiple meanings of the L-letter co des. The similar it y with the corres p onding Fig.2 for Moby Dick is r e -assuring. Co m- paring Fig.A3 for TD with Fig.3 for Moby Dick shows that also the t wo extreme L - letter co des L=1 ,2 show pre- cisely the same featur es fo r bo th the nov els. Finally as shown in Fig.A5, co mparing TD written in English L= 3 -letter co de with TD written in Chinese with Chinese c hara cters gives the same striking ov erla p a s the corres p onding data for Moby Dic k given in Fig.5. [1] J.B. Estroup, Les Gammes St´ enographiques, fourth ed., Institut Sten ographique de F rance, P aris, 1916. [2] G.K. Zipf, Selectiv e S tudies of the Principle of Relativ e F requen cy in Language, Harv ard Universit y Press, Cam- bridge, 1932. [3] G.K. Zipf, The Psyc ho-Biology of Language: an Intro- duction to D ynamic Philology , Mifflin, Boston, 1935. [4] G.K. Zipf, Human Bev avior and the Principle of Least Effort, Addison-W esley , Reading, 1949. [5] B. Mandelbrot, An In formational Theory of the Statisti- cal Stru cture of Languages, Butterw orth, W obu rn, 1953. [6] W. Li, R andom texts ex hibit Zipf ’s-law -like word fre- quency distribution, IEEE T. Inform. Theory 38 (1992) 1842-1845 . [7] R.H. Baa yen, W ord F requen cy D istributions, Kluw er Academic, Dordrech t, 2001. [8] R.F. i Cancho, R.V. S ol ´ e, Least effort and the origins of scaling in human language, Proc. N atl. Acad. Sci. U.S.A . 100 (2003) 788-791. [9] M.A. Montem u rro, Beyond the Zipf-Mandelbrot law in quantitativ e linguistics, Physica A 300 (2001) 567-578. [10] F, F ont-Close, G. Boleda, A. Corral, A scaling la w b e- yond Zipf ’s law and its relation t o Heaps’ law , New J. Phys 15 ( 2013) 093033. [11] A.A. Mark ov, An example of statistical investig ation of the tex t Eugene One gin concerning the connection of samples in chains, Sci. Context 19 (2006) 595-600. [12] B. Hayes , First links in Marko v chains, Am. Sci. 101 (2013),92-97 . H. Simon, On a class of skew distribution fun ctions, Biometrik a 42 (1955) 425-440. [13] H. Simon, On a class of skew distribution fun ctions, Biometrik a 42 (1955) 425-440. [14] S. Bernhardsson, L.E.C. da Ro c ha, P . Minnhagen, Size dep endent w ord frequencies and the t ranslational inv ari- ance of b ooks, Ph ysica A 389 (2010) 330-341. [15] S. Bernhardsson, L.E.C. da Ro c ha, P . Minnhagen, The meta b o ok and size-dep endent prop erties of written lan- guage, New J. Phys. 11 (2009) 123015. [16] S. Bernhardsson, S .K. Baek, P . Minnhagen, A paradoxi- cal prop erty of the monkey b o ok, J. Stat. Mech. 7 (2011) PO7013. [17] S.K. Baek, S. Bernhardsson, P . Minn hagen, Zipf ’s la w unzipp ed, New J. Phys. 13 (2011) 043004. [18] X. Y an, P . Minnh agen, Maxim um entrop y , w ord- frequency , Chinese characters, and multiple meanings, PLoS ONE 10 (2015) e0125592. [19] X. Y an, P . Minn hagen, Randomness versus sp ecifics for w ord-frequency distributions, Physica A, 444 (2016) 828- 837 [20] X. Y an, P . Minnh agen, H .J. Jensen , The like ly deter- mines the unlikely , Physica A 456 (2016) 112-119. [21] W. B. Deng, A .E. Allav erdyan, B.Li, Q .A. W ang, Rank- frequency relation for Chinese c h aracters, Eur. Phys. J. B 87 (2014) 47 9 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 k 1 0 0 1 0 1 1 0 2 1 0 3 1 0 4 ¯ f ( k ) L = 1 L = 2 L = 3 L = 4 L = 5 L = 6 ¯ f ( k ) = k α ( k + k c − 1 k c ) − β ¯ f ( k ) = k ¯ f ( k ) = 1 FIG. A1. The no vel TD (T ess of the D’Urb ervilles b y Thomas Hardy ): Average multiplicit y of meanings for different co de- lengths L . Compare Fig.1 whic h gives the same d ata for Moby Dick. 10 0 10 1 10 2 10 3 10 4 10 5 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 P ( k ) 6 Letters (a) Binned Data ( M = 152952 , N = 8925 , k max = 8717) RGF ( γ = 1 . 69 , b = 2 . 45 e − 04) RGF with f ( k ) ( γ = 1 . 6 , b = 1 . 00 e − 05) 10 0 10 1 10 2 10 3 10 4 10 5 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 5 Letters (b) Binned Data ( M = 152952 , N = 7095 , k max = 8717) RGF ( γ = 1 . 64 , b = 2 . 64 e − 04) RGF with f ( k ) ( γ = 1 . 66 , b = 1 . 00 e − 05) 10 0 10 1 10 2 10 3 10 4 10 5 k 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 P ( k ) 4 Letters (c) Binned Data ( M = 152952 , N = 4501 , k max = 8717) RGF ( γ = 1 . 53 , b = 3 . 12 e − 04) RGF with f ( k ) ( γ = 1 . 86 , b = 1 . 00 e − 06) 10 0 10 1 10 2 10 3 10 4 10 5 k 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 3 Letters (d) Binned Data ( M = 152952 , N = 1703 , k max = 11680) RGF ( γ = 1 . 35 , b = 2 . 67 e − 04) RGF with f ( k ) ( γ = 2 . 18 , b = 1 . 00 e − 07) FIG. A 2. The nov el TD: F requ ency distributions P ( k ) for the co des L = 6 − 3. Compare Fig.2 which gives the same data for Mob y Dick. 10 10 0 10 1 10 2 10 3 10 4 k 10 − 2 10 − 1 10 0 C ( k ) 2 Letters (a) Binned Data ( M = 152952 , N = 255 , k max = 16062) RGF ( γ = 0 . 11 , b = 8 . 00 e − 04) RGF with f ( k ) ( γ = 0 . 98 , b = 5 . 50 e − 04) 0 5000 10000 15000 20000 25000 k 10 − 2 10 − 1 10 0 1 Letters (b) Binned Data ( M = 152952 , N = 26 , k max = 24911) RGF ( γ = 0 . 0 , b = 1 . 55 e − 04) RGF with f ( k ) ( γ = 0 . 0 , b = 1 . 55 e − 04) FIG. A3. The nov el TD: F req uency d istributions in the cu mulant form P ( k > ) for th e co de-lengths L = 1 and L = 2. Compare Fig.3 which give s th e same data for Mob y Dick 10 0 10 1 10 2 10 3 10 4 k 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 P ( k ) Binned data ( M = 152952 , N = 11917 , k max = 8717) RGF with k max ( γ = 1 . 77 , b = 1 . 86 e − 04) FIG. A4. The word-frequency d istribution for the nov el TD. The R GF-prediction illustrates that the assumption that the w ords to large extent only carries single meanings give s an ex - cellen t pred iction provided the wo rds are fully written out : The predicion is completely determined from the a priori knowledge of the v alues of ( M , N , k max ) and t he single meaning assump- tion f ( k ) = 1: Data; filled dot and RGF-prediction; dashed curve. Compare Fig.4 whic h giv es the w ord-frequency distri- bution for the n o vel Mob y Dick. 10 0 10 1 10 2 10 3 10 4 10 5 k 10 − 8 10 − 7 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 P ( k ) TD Ch. Char. ( M = 297740 , N = 3418 , k max = 12447) TD 3-Letters ( M = 152952 , N = 1703 , k max = 11680) FIG. A5. Direct comparison b etw een L = 3-co ding of TD in English and TD in written Chinese by Chinese c haracters. Note the strong ov erlap. Compare Fig.5 which giv es the same data for Mob y Dick. In case of th e L = 3-co ding the shap e of the frequency distribu t ion is directly connected to the multi- ple meanings of the co des (comp are discussion of Fig. 1). This suggest to u s that the multiple meanings of Chinese charac- ters is likewise link to the multiple meanings of th e Chinese chara cters.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment