다중 의미가 빈도 분포에 미치는 영향
본 논문은 영어 텍스트와 한자 텍스트를 대상으로, 단어(또는 문자)를 앞의 L 글자만 남겨 코딩함으로써 의미의 중복성을 인위적으로 증가시킨다. 평균 의미 수 f(k)와 최대 엔트로피 기반 Random Group Formation(RGF) 모델을 결합해, 코드 길이 L 에 따라 변하는 빈도 분포 P(k)를 정량적으로 예측한다. 실험 결과, L=6~1까지의 모든 경우와 한자 코딩이 RGF 예측과 매우 높은 일치를 보이며, 빈도 분포의 형태 차이는 …
저자: Xiaoyong Yan, Petter Minnhagen
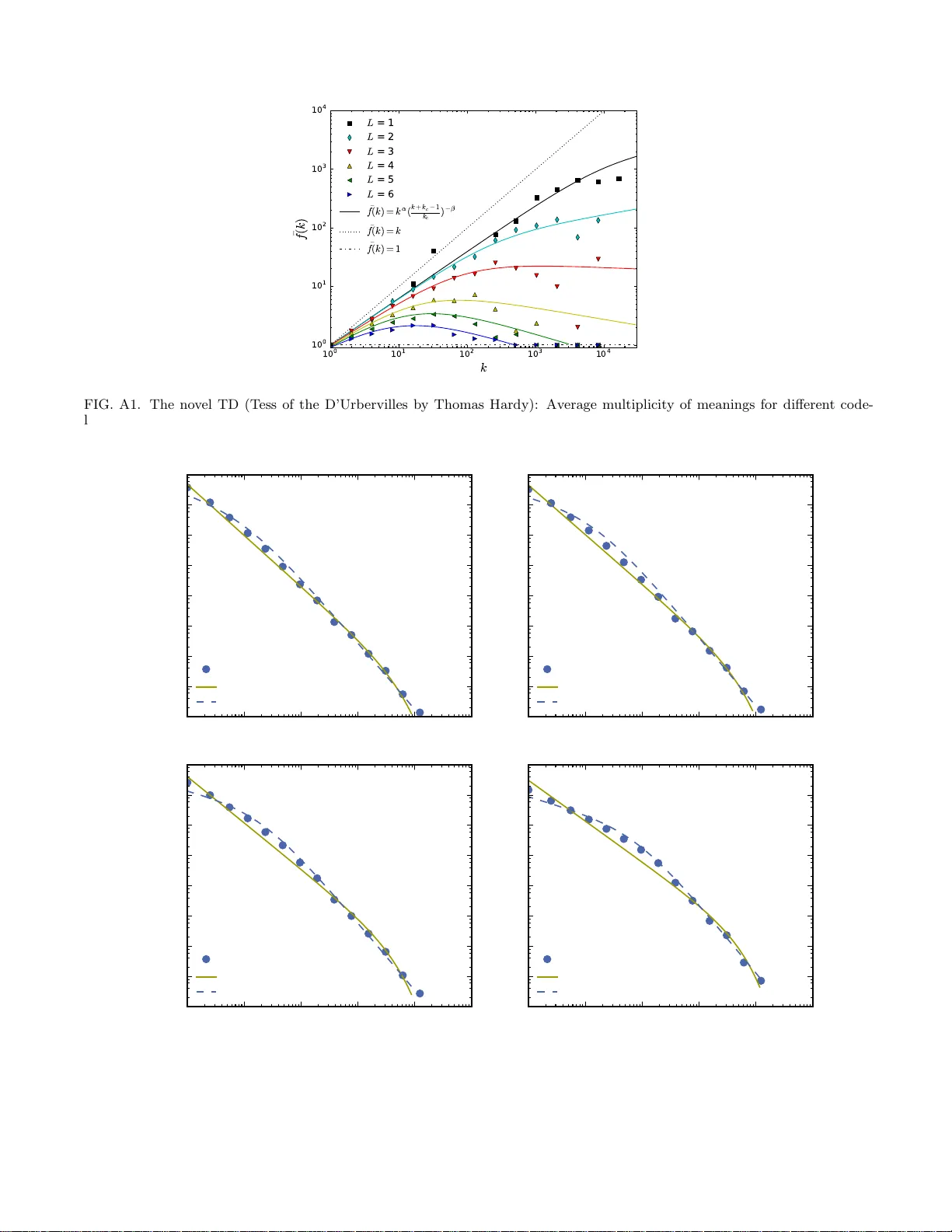
본 논문은 “단어(또는 문자)의 다중 의미가 빈도 분포에 미치는 영향”을 정량적으로 규명하고자 한다. 연구자는 먼저 영문 소설 Moby Dick을 대상으로, 각 단어를 앞의 L 글자만 남겨 코딩하는 L‑letter 모델을 제안한다. L=6은 원래 단어 그대로이며, L=1은 첫 글자만 남겨 26개의 코드만 존재한다. L이 작아질수록 동일 코드가 여러 실제 단어를 대변하게 되며, 이는 평균 의미 수 f(k) (코드가 k 번 등장할 때 평균 의미 수)로 측정된다. 실험적으로 f(k)는 k에 대해 증가하는 경향을 보이며, 이를
f(k)=k^α · ((k+k_c−1)/k_c)^−β
라는 3‑parameter 식으로 근사한다.
다음으로, 저자들은 Random Group Formation(RGF)이라는 최대 엔트로피 기반 모델을 도입한다. RGF는 그룹(코드) 크기 k 에 대한 확률 P(k) 를 세 가지 제약조건(정규화, 평균 M/N, 고정 엔트로피 S₀) 하에 정보량 I
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기