Learning Structures of Bayesian Networks for Variable Groups
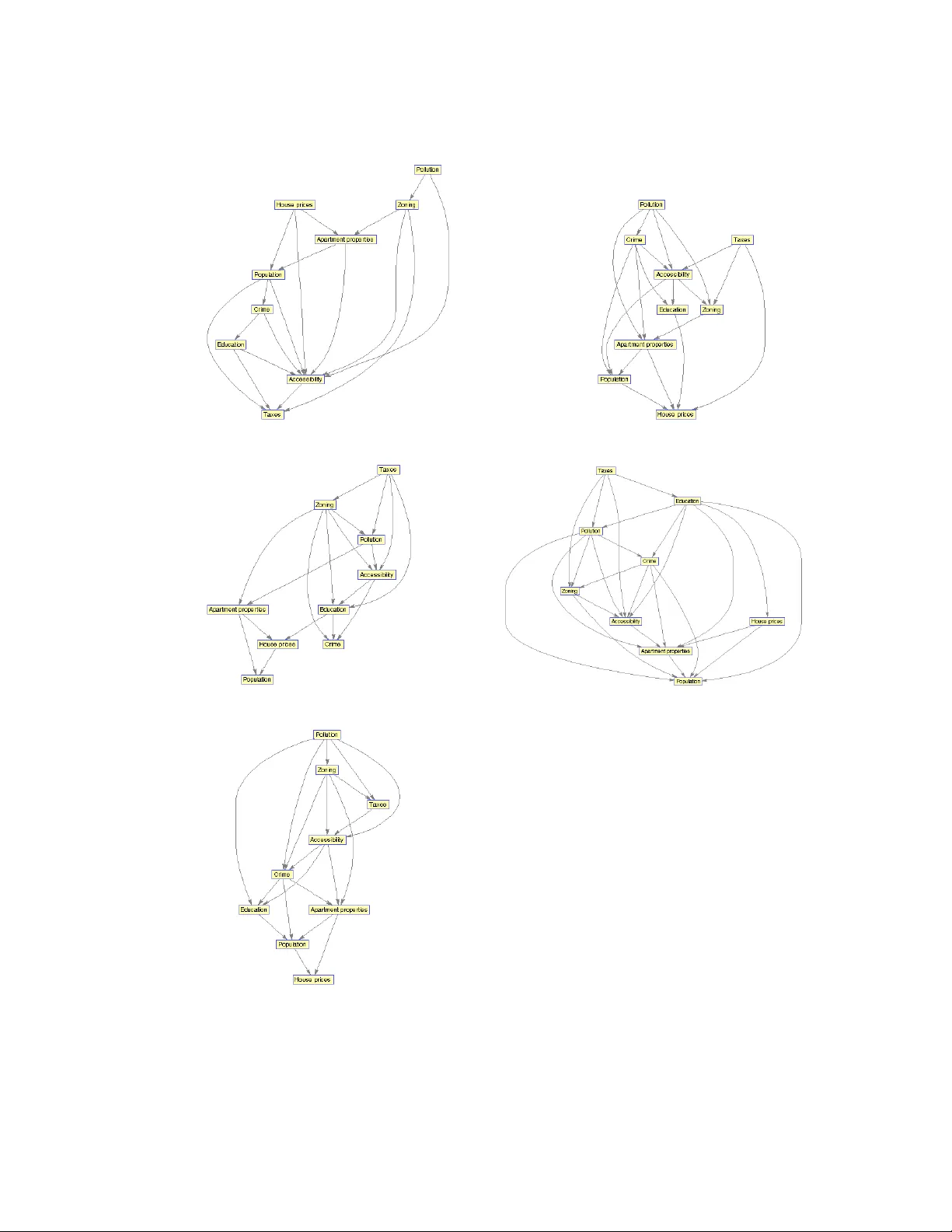
Bayesian networks, and especially their structures, are powerful tools for representing conditional independencies and dependencies between random variables. In applications where related variables form a priori known groups, chosen to represent diff…
Authors: Pekka Parviainen, Samuel Kaski
Learning Structures of Bayesian Networks for V ariable Groups 1 Pekka Parviainen and Samuel Kaski Helsinki Institute for Information T echnology HIIT , Department of Computer Science, Aalto Uni versity , Espoo, Finland Abstract Bayesian networks, and especially their structures, are po werful tools for represent- ing conditional independencies and dependencies between random variables. In ap- plications where related v ariables form a priori kno wn groups, chosen to represent dif ferent “vie ws” to or aspects of the same entities, one may be more interested in modeling dependencies between groups of v ariables rather than between individual v ariables. Moti v ated by this, we study prospects of representing relationships between v ariable groups using Bayesian network structures. W e show that for dependency structures between groups to be expressible exactly , the data have to satisfy the so- called groupwise faithfulness assumption. W e also show that one cannot learn causal relations between groups using only groupwise conditional independencies, but also v ariable-wise relations are needed. Additionally , we present algorithms for finding the groupwise dependency structures. K e ywor ds: Bayesian networks, structure learning, multi–vie w learning, conditional independence 1. Introduction Bayesian networks are representations of joint distributions of random variables. They are powerful tools for modeling dependencies between variables. They consist of two parts, the structure and parameters, which together specify the joint distribution. The dependencies and independencies between v ariables are implied by the structure of a Bayesian network, which is represented by a directed acyclic graph (D A G). The parameters specify local conditional probability distributions for each v ariable. 1 c 2017. This manuscript v ersion is made available under the CC-BY -NC-ND 4.0 license http: //creativecommons.org/licenses/by- nc- nd/4.0/ Pr eprint submitted to International J ournal of Appr oximate Infer ence J une 2, 2017 In practical applications it is common that the analyst does not know the structure of a Bayesian network a priori . Ho we ver , samples from the distribution of interest are commonly a v ailable. This has motiv ated dev elopment of algorithms for learning Bayesian networks from observ ational data. There are two main approaches to learn- ing the structure of a Bayesian network from data: constraint-based and score-based. The constraint-based appr oach (see, e.g., [18, 22]) relies on testing conditional inde- pendencies between v ariables. The network is constructed so that it satisfies the found conditional independencies and dependencies. In the scor e-based appr oac h (see, e.g., [6, 13]) one assigns each network a score that measures how well the network fits the data. Then one tries to find a network that maximizes the score. Although the problem is NP-hard [4], there exist plenty of exact algorithms [7, 14, 20] as well as theoret- ically sound heuristics [1, 5]. Learning the parameters giv en the structure is rather straightforward and thus we concentrate on structure learning. Bayesian networks model dependencies and independencies between indi vidual v ariables. Ho we ver , sometimes the relationships between groups of v ariables are e v en more interesting. An example is multiple different measurements of expression of the same genes, made with multiple measurement platforms, b ut the goal being to find relationships between the genes and not of the measurement platforms. The measure- ments of each gene would here be the groups. Another example is measurements of expression of indi vidual genes, with the goal of the analysis being to understand cross- talk between pathways consisting of multiple genes, or more generally , relationships on a higher le vel of a hierarchy tree in hierarchically org anized data. Here the path- ways would be the groups. In both cases, a Bayesian network for variable groups would directly address the analysis problem, and would also hav e fe wer variables and hence be easier to visualize. More generally , the setup matches multi-view learning where data consist of mul- tiple “vie ws” to the same entity , multiple aspects of the same phenomenon, or multiple phenomena whose relationships we want to study . For these setups, a Bayesian net- work for variable groups can be seen as a dimensionality reduction technique with which we e xtract interesting information from a larger , noisy data set. Note that our model is targeted for a very specific application, that is, on learning conditional inde- pendencies between kno wn v ariable groups. It is not a general-purpose dimensionality reduction technique such as, say , PCA. While the structure learning problem is well-studied for individual variables, knowl- edge about modeling relationships between variable groups using the Bayesian net- work frame work is scarce. Moti v ated by this, we study prospects of learning Bayesian network structures for variable groups. In summary , while Bayesian networks for v ari- able groups can be learned under some conditions, strong assumptions are required and hence they ha ve limited applicability . W e start by exploring theoretical possibilities and limitations for learning Bayesian networks for v ariable groups. First, we sho w that in order to be able to learn a struc- 2 ture that expresses exactly the conditional independencies between variable groups, the distribution and the groups need to together satisfy a condition that we call groupwise faithfulness (Section 3.1); our simulations suggest that this is a rather strong assump- tion. Then, we study possibilities of finding causal relations between variable groups. It turns out that one can dra w only very limited causal conclusions based on only the conditional independencies between groups (Section 3.2), and hence also dependen- cies between the indi vidual v ariables are needed. W e introduce methods for learning Bayesian network structures for variable groups. First, it is possible to learn a structure directly using conditional independencies or lo- cal scores between groups (Section 4.1). Ho we ver , this approach suf fers from needing lots of data. For the second approach, we observe that if all conditional independencies between individual v ariables are known, one can infer the conditional independencies between groups. The second approach is to construct a Bayesian network for indi vid- ual v ariables and then to infer the structure between groups (Section 4.2). The third approach is to learn structures for both indi vidual v ariables and groups simultaneously (Section 4.3). Finally , we ev aluate the algorithms in practice (Section 5). Our results suggest that the second and third approaches are more accurate. 1.1. Related W ork W e are not aware of any work with close resemblance with this study , b ut there hav e been some efforts to solve related problems. Next, we will briefly introduce some related and explain why we ha ve not based our work on them. Object-oriented Bayesian networks [15] are a generalization of Bayesian networks and enable representing groups of v ariables as objects. Hierarchical Bayesian net- works [12] are another generalization of Bayesian networks in which variables can be aggregations (or Cartesian products) of other variables and a hierarchical tree is used to represent relations between them. Both of these formalisms are very general and they are capable of representing conditional independencies between v ariable groups. Therefore, our results may be applied to these models. Howe ver , these models are unnecessarily complicated for our analysis and thus we do not consider them further here. Multiply sectioned Bayesian networks [24] model dependencies between ov erlap- ping v ariable groups. They are typically used to aid inference. They decompose a D A G into a hypertree where hypernodes are labelled by a subgraph and hyperlinks by sep- arator sets. Howe ver , multiply sectioned Bayesian networks require variable groups to be ov erlapping and thus are not suitable for modelling dependencies between non- ov erlapping variable groups. Module networks [19] hav e been designed to handle large data sets. The variables are partitioned into modules where the variables in the same module share parents and parameters. Module networks are particularly good for approximate density es- timation. Howe ver , their structural limitations make them unsuitable for analysing 3 conditional independencies between v ariable groups. Huf fman netw orks [8] are Bayesian networks were nodes represent v ariable groups. The y are designed to aid data compression and the v ariable groups are learned to enable ef ficient compression. Burge and Lane [3] hav e presented Bayesian networks for aggregation hierarchies which are related to hierarchical Bayesian networks. Groups of v ariables are aggre- gated by , for example, taking a maximum or mean and then networks are learned be- tween the aggre gated v ariables. From our point of vie w , the do wnside of this approach is that conditional independencies between aggregated variables do not necessarily correspond to conditional independencies between groups. Entner and Hoyer [9] have presented an algorithm for finding causal structures among groups of continuous v ariables. Their model works under the assumptions that v ariables are linearly related and associated with non-Gaussian noise. An earlier version of this paper [17] appeared in the proceedings of the PGM 2016 conference. Ne w contents of this paper include an analysis of the relationship between faithfulness and groupwise faithfulness (Theorems 3 and 4), an alternativ e definition of causality for v ariable groups and an analysis of it (Definition 6 and Theorem 8), a ne w algorithm for learning group D A Gs (Section 4.3), and more thorough e xperiments (Section 5). 2. Preliminaries 2.1. Conditional Independencies T wo random variables x and y are conditionally independent giv en a set S of ran- dom variables if P ( x, y | S ) = P ( x | S ) P ( y | S ) . If the set S is empty , variables x and y are marginally independent. W e use x ⊥ ⊥ y | S to denote that x and y are conditionally independent gi ven S . Conditional independence can be generalized to sets of random variables. T wo sets of random variables X and Y are conditionally independent giv en a set S of random v ariables if P ( X, Y | S ) = P ( X | S ) P ( Y | S ) . 2.2. Bayesian Networks A Bayesian network is a representation of a joint distribution of random v ariables. A Bayesian network consists of two parts: a structure and parameters. The structure of a Bayesian network is a directed ac yclic graph (D A G) which expresses the conditional independencies and the parameters determine the conditional distributions. Formally , a D A G is a pair G = ( N , A ) where N is the node set and A is the arc set. If there is an arc from u to v , that is, uv ∈ A then we say that u is a par ent of v and v is a child of u . The set of parents of v in A is denoted by A v . Nodes v and u are said to be spouses of each other if they ha ve a common child and there is no arc between v and u . Further , if there is a directed path from u to v we say that u is an ancestor of 4 v and v is a descendant of u . The cardinality of N is denoted by n . When there is no ambiguity on the node set N , we identify a D A G by its arc set A . Each node in a Bayesian network is associated with a conditional probability dis- tribution of the node gi ven its parents. The conditional probability distrib ution of the node is specified by the parameters. A D A G represents a joint probability distribu- tion o ver a set of random variables if the joint distribution satisfies the local Marko v condition , that is, e very node is conditionally independent of its non-descendants gi ven its parents. Then the joint distribution ov er a node set N can be written as P ( N ) = Q v ∈ N P ( v | A v ) where the conditional probabilities for node v are specified by the parameters θ v . W e denote the set of all local parameters by Θ . Finally , we define a Bayesian network to be a pair ( G, Θ) . The conditional independencies implied by a DA G can be extracted using a d- separation criterion. The skeleton of a D A G A is an undirected graph that is obtained by replacing all directed arcs uv ∈ A with undirected edges between u and v . A path in a D A G is a cycle-free sequence of edges in the corresponding skeleton. A node v is a head-to-head node along a path if there are two consecuti ve arcs uv and w v on that path. Nodes v and u are d-connected by nodes Z along a path from v to u if ev ery head-to-head node along the path is in Z or has a descendant in Z and none of the other nodes along the path is in Z . Nodes v and u are d-separated by nodes Z if they are not d-connected by Z along any path from v to u . Nodes s , t , and u form a v-structur e in a D AG if s and t are spouses and u is their common child. T wo D A Gs are said to be Marko v equivalent if they imply the same set of conditional independence statements. It can be shown that two D A Gs are Markov equi v alent if and only if they ha ve the same skeleton and same v-structures [23]. A distribution p is said to be faithful to a D A G A if A and p imply exactly the same set of conditional independencies. If p is faithful to A then v and u are conditionally independent giv en Z in p if and only if v and u are d-separated by Z in A . This generalizes to v ariable sets. That is, if p is faithful to A then v ariable sets T and U are conditionally independent giv en Z in p if and only if t and u are d-separated by Z in A for all t ∈ T and u ∈ U . 3. Groupwise Independencies In this section we introduce a ne w assumption, groupwise faithfulness, that is nec- essary for principled learning of D A Gs for variable groups. W e will also show that groupwise conditional independencies hav e a limited role in learning causal relations between groups. 3.1. Gr oupwise F aithfulness First, let us introduce some terminology . Recall that N is our node set. Let W = { W 1 , . . . , W k } be a collection of nonempty sets where W i ⊆ N ∀ i , and W forms a 5 partition of N . W e call W a gr ouping . W e call a D A G on N a variable D A G and a D A G on W a gr oup D AG ; Note that the nodes of the group D A G are subsets of N . W e try to solve the follo wing computational problem: W e are gi ven a grouping W and data D from a distribution p on v ariables N that is faithful to a variable D A G G . The task is to learn a group D AG H on W such that for all W i , W j ∈ W and S = ∪ l T l , with T = { T 1 , . . . , T k } ⊆ W \ { W i , W j } , it holds that W i and W j are d-separated by S in H if and only if W i ⊥ ⊥ W j | S in p . It is well-known that D A Gs are not closed under marginalization. That is, ev en though the data-generating distrib ution is faithful to a D A G on a node set N , it is possible that the conditional independencies on some subset of N are not exactly rep- resentable by any D A G. W e note that D AGs are not closed under aggregation, either . By aggregation we mean representing conditional independencies among groups using a group D A G. W e sho w that by presenting an example. Consider a distribution that is faithful to the D AG in Figure 1(a). W e want to express conditional independencies between groups V 1 , V 2 , and V 3 . By inferring conditional independencies from the vari- able D A G, we get that V 1 ⊥ ⊥ V 2 and V 1 ⊥ ⊥ V 2 | V 3 . There does not exist a D A G that expresses this set of conditional independencies e xactly . x 1 x 2 x 3 x 4 V 3 V 1 V 2 x 1 x 2 x 3 x 4 x 5 V 3 V 1 V 2 V 1 V 2 V 3 (a) (b) (c) Figure 1: (a) A variable D A G where conditional independencies among groups V 1 , V 2 , and V 3 cannot be expressed exactly using any D AG. (b) A causal v ariable D AG where conditional independencies among groups V 1 , V 2 , and V 3 lead to a group DA G in which v-structures cannot be interpreted causally . (c) A group D AG corresponding to causal v ariable D A G in (b). T o av oid cases where conditional independencies are not representable by any group DA G, we introduce a new assumption: groupwise faithfulness. Formally , we define groupwise faithfulness as follo ws. Definition 1 (Groupwise faithfulness) . A distribution p is gr oupwise faithful to a gr oup D A G H given a gr ouping W , if H implies the e xactly same set of conditional indepen- dencies as p over the gr oups W . Note that this assumption is analogous with the faithfulness assumption in the sense 6 that in both cases there exists a D A G that expresses exactly the independencies in the distribution. Sometimes it is con venient to in vestigate whether conditional independencies im- plied by a v ariable D A G gi ven a grouping are equiv alent to the conditional indepen- dencies implied by a group D A G. W e will use this notion later in this section when we in vestigate the strength of the groupwise f aithfulness assumption. Definition 2 (Groupwise Marko v equiv alence) . A variable D A G G is gr oupwise Markov equivalent to a gr oup D A G H given a gr ouping W , if H implies the exactly same set of conditional independencies as G over gr oups W . W e note that if a distrib ution p is faithful to a D A G G , and G is groupwise Marko v equi v alent to a D A G H giv en a grouping W , then p is groupwise faithful to H given W . This shows that faithfulness and groupwise Markov equiv alence together imply groupwise faithfulness. Howe ver , neither faithfulness nor groupwise Marko v equi va- lence alone is necessary or suf ficient for groupwise faithfulness. T o see this, let us consider the following examples. First, to see that faithfulness is not suf ficient for groupwise faithfulness, assume that we ha ve a distribution that is faithful to the D A G in Figure 1(a). Gi ven groups V 1 , V 2 , and V 3 , the distribution is groupwise unfaithful. Second, consider a distribution over the v ariable set x 1 , x 2 , x 3 , x 4 , and x 5 . Let us assume that the groups are V 1 = { x 1 , x 2 } , V 2 = { x 3 } , and V 3 = { x 4 , x 5 } and the Bayesian network factorizes according to the v ariable D A G in Figure 1(b). No w , it is possible to construct a distribution such that the local con- ditional distribution at node x 1 is exclusi ve or (XOR), and thus the variable D A G is unfaithful. If the other local conditional distributions do not introduce an y additional independencies then the distrib ution is groupwise faithful. This shows that faithfulness is not necessary for groupwise faithfulness. Next, let us consider the same structure but let us assume that both x 1 and x 5 are associated with XOR distributions. In this case the variable D A G is groupwise Markov equi valent to the group D A G but the dis- tribution is not groupwise faithful which sho ws that groupwise Markov equi valence is not suf ficient for groupwise faithfulness. Finally , consider the variable D A G and the grouping in Figure 1(a). This v ariable D A G is not groupwise Marko v equi valent to the group D A G giv en the grouping. Howe ver , if the distribution is unfaithful to the D A G and the v ariables x 1 and x 3 are independent then the distribution is groupwise faith- ful. This sho ws that groupwise Markov equi v alence is not necessary for groupwise faithfulness. As neither faithfulness nor groupwise Markov equi v alence is suf ficient or necessary for groupwise faithfulness, it follo ws that groupwise faithfulness implies neither faithfulness nor groupwise Marko v equiv alence. As neither faithfulness nor structural groupwise faithfulness is suf ficient or neces- sary for groupwise faithfulness, it follows that groupwise faithfulness implies neither faithfulness or structural groupwise faithfulness. 7 W e hav e also studied whether groupwise f aithfulness together with certain kinds of group D A Gs or groupings imply faithfulness. It turns out that groupwise f aithfulness implies faithfulness only when the maximum group size is one and in some special cases when the maximum group size is two as stated in the theorems belo w; the proofs of the theorems are found in Appendix A. Theorem 3. Let H be a gr oup D AG on a gr ouping W . Then every distribution p on ∪ W i that is gr oupwise faithful to H given W is faithful to some variable D A G on ∪ W i if max W i ∈ W | W i | = 1 or max W i ∈ W | W i | = 2 and no gr oup of size 2 has neighbors in H . Theorem 4. Let H be a gr oup D A G on a gr ouping W . If max W i ∈ W | W i | ≥ 3 , or max W i ∈ W | W i | = 2 and two gr oups of size 2 ar e adjacent in the gr oup D AG, then ther e exists a distribution p such that p implies the same set of gr oupwise conditional independencies as H on W and p is not faithful to any D A G. Note that there is a “gap” between the above theorems; we do not know whether or not groupwise faithfulness implies faithfulness when the maximum group size is 2 and the groups of size 2 ha ve neighbors of size 1 . Next, we will explore how strong the groupwise faithfulness assumption is. That is, ho w likely we are to encounter groupwise faithful distributions. T o this end, we consider distrib utions that are faithful to variable D A Gs. The joint space of D A Gs and groupings is too large to be enumerated and we are not aware of any formula for assessing the number of groupwise unfaithful netw orks. Therefore, we analyze the pre v alence of groupwise faithfulness by an empirical e valuation using simulations. In simulations, a key question is ho w to check groupwise f aithfulness. That is, gi ven a variable D A G and a grouping, how to check whether the conditional indepen- dencies entailed by the variable D A G over groups can be represented exactly using a group D A G. Because the data-generating distribution is faithful to a variable D A G, we check whether the v ariable D A G ov er groups is groupwise Marko v equi v alent to some group D A G. This can be done by first using the PC algorithm [22] to construct a group D A G; here we use d-separation in the v ariable D A G as our independence test. Once the group D A G has been constructed we can check that the set of conditional independencies entailed by the group D A G is exactly the set of groupwise conditional independencies implied by the variable D A G and the grouping. The PC algorithm is sound and complete so if there exists a D A G that implies exactly the set of giv en con- ditional independencies, then the PC algorithm returns (the equi v alence class of) that D A G. Thus, the conditional independencies match if and only if the v ariable D A G and the grouping are groupwise Marko v equi v alent to a group D A G. W e used the Erd ˝ os-R ´ enyi model [10, 11] to generate random D A Gs. A D A G from model G ( n, p ) has n nodes and each arc is included with probability p independently 8 of all other arcs; to get an acyclic directed graph, we fix the order of nodes. W e generated random D A Gs with n = 20 by varying the parameter p from 0 . 1 to 0 . 9 . W e also generated random groupings where group size was fixed to 2, 3, 4, or 5 (20 is not di visible by 3, so in this case one group is smaller than the others). For each value of p , we generated 100 random graphs. Then, we generated 10 groupings for each graph for each group size and counted the proportion of groupwise faithful D A G-grouping pairs. The results are sho wn in Figure 2. It can be seen that groupwise unfaithfulness is probable with sparse graphs and small group sizes. One should, howe ver , note that the simulation results are for random graphs and groupings, and real life graphs and groupings may or may not follo w this pattern. Figure 2: Proportion of D A G-grouping pairs that are groupwise faithful in random graphs of 20 nodes. Parameter p is the probability that an arc is present. 3.2. Causal Interpr etation Probabilistic causation between v ariables is typically defined to concern predicting ef fects of interventions. This means that an external manipulator interv enes the system and forces certain variables to take certain values. In our context, we say that a group V causes group U if intervening on V af fects the joint distribution of U . While the abov e definition does not require the distribution to be of any particular form, we concentrate on our analysis on distrib utions that can be represented using causal D A Gs. A D A G is called causal if it satisfies the causal Markov condition , that is, all v ariables are conditionally independent of their non-ef fects gi ven their direct causes. Assuming faithfulness and causal suf ficiency (if an y pair of observ ed v ariables has a common cause then it is observed), it is possible to identify causal effects using the do -operator [18]. The do -operator do ( v = v 1 ) sets the v alue of the variable v to 9 be v 1 . The probability P ( u | do ( v = v 1 )) is the conditional probability distrib ution of u giv en that the variable v has been forced to take value v 1 . In other words, one takes the original joint distrib ution, remo ves all arcs that head to v and sets v = v 1 ; then one computes the probability P ( u | v = v 1 ) in the ne w distrib ution. W e define a cause using the so-called operational criterion for causality [1], that is, we say that a v ariable v is a cause (direct or indirect) of a v ariable u if and only if P ( u | do ( v = v 1 )) 6 = P ( u | do ( v = v 2 )) for some v alues v 1 and v 2 . A straightforward generalization leads to the follo wing definition of causality for v ariable groups. Definition 5 (Group causality) . Assuming that P is a causal Bayesian network and given variable gr oups V and U , V is a cause of U if P ( U | do ( V = V 1 )) 6 = P ( U | do ( V = V 2 )) for some instantiations V 1 and V 2 of values of V . Note that the above definition allows causal cycles between groups. T o see this, consider a causal DA G on { v 1 , v 2 , v 3 , v 4 } which has arcs v 1 v 3 and v 4 v 2 . If there are two groups W 1 = { v 1 , v 2 } and W 2 = { v 3 , v 4 } then W 1 is a cause of W 2 (because there is a causal arc v 1 v 3 ) and W 2 is a cause of W 1 (because of a causal arc v 4 v 2 ). In the above, we assumed that the v ariable D A G is causal. An alternative scenario is to assume both the group D A G and the variable D A G are causal. This results in the follo wing, stronger definition of causality which does not allo w causal c ycles between groups. Definition 6 (Strong group causality) . Assuming that P is a causal Bayesian network and given variable gr oups V and U , V is a str ong cause of U if V is a cause of U and U is not a cause of V in P . Next, we will study to what extent causality between variable groups can be de- tected from observ ational data using only conditional independencies among groups. W e assume that the data come from a distribution that is faithful to a causal variable D A G. Further , we assume that we hav e no access to the ra w data but only to an ora- cle that conducts conditional independence tests. Formally , we assume that we hav e access to an oracle O G that answers queries W i ⊥ ⊥ W j | S , where W i , W j ∈ W and S = ∪ l T l with T = { T 1 , . . . T m } ⊆ W \ { W i , W j } . Note that in the standard sce- nario with conditional independencies between variables, we have an oracle O V that answers queries X ⊥ ⊥ Y | Z , where X, Y ∈ N and Z ⊆ N \ { X , Y } ; If max i | W i | > 1 then the oracle O V is strictly more po werful than O G . It is well-known that, under standard assumptions, a causal variable D A G can be learned up to the Marko v equi valence class. A Marko v equi valence class can be repre- sented by a completed partial D A G (CPD A G) where we ha ve both directed and undi- rected edges. Directed edges or arcs are the edges that point to the same direction in e very member of the equiv alence class whereas undirected edges express cases where the edge is not directed to the same direction in all members of the equiv alence class. 10 If there is a directed path from a variable v to a v ariable u in the CPD AG then v is a cause of u . In other words, existence of such a path is a suf ficient condition for causal- ity . Howe ver , it is not a necessary condition and it is possible that v is a cause of u e ven when there is no directed path from v to u in the CPD A G. Next, we consider causality in the group context. Manipulating an ancestor of a node af fects its distribution and thus the ancestor is a cause of its descendant. It is easy to see that giv en a causal variable D A G G , a group W i is a group cause of a group W j if and only if there is at least one directed path from W i to W j in G , that is, there e xists v ∈ W i and u ∈ W j such that there is a directed path from v to u . It is clear from the abov e that a suf ficient condition for a group W i to be a group cause of a group W j is that there is at least one directed path from W i to W j in the CPD A G. Standard constraint-based algorithms for causal learning start by constructing a skeleton and then directing arcs based on a set of rules. So let us take a look on these rules in the group context. The first rule is to direct v-structures. The follo wing theorem shows that arcs that are part of a v-structure in a group D A G imply group causality . Theorem 7. Let N be a node set and W a gr ouping on N . Let p be a distrib ution that is gr oupwise faithful to some gr oup D A G H given the gr ouping W . If ther e exist gr oups W i , W j , W k ∈ W such that (i) W i ⊥ ⊥ W k | S for some S ⊆ W \ { W i , W j , W k } and (ii) W i 6⊥ ⊥ W k | ( ∪ l T l ) ∪ W j for all T = { T 1 , . . . , T m } ⊆ W \ { W i , W j , W k } then W i is a gr oup cause of W j . Pr oof. It is sufficient to sho w that there exists a pair w i ∈ W i and w j ∈ W j such that w i is an ancestor of w j in the v ariable D A G. Due to (i), all paths that go from W i to W k without visiting S must have a head- to-head node. Due to (ii) there has to exist at least one path between W i and W k such that there are no non-head-to-head nodes in W \ { W i , W k } and all head-to-head nodes are unblocked by W j ; let us denote one such a path by R . W ithout loss of generality , we can assume that all nodes in R except the endpoints are in W \ { W i , W k } . Let s, t, u ∈ N be three consecuti ve nodes in path R such that there are edges st and ut . Nodes s and u cannot be head-to-head nodes along R and therefore s, u ∈ W i ∪ W k . Node t is a head-to-head node and therefore either t ∈ W j or t has a descendant in W j . In both cases there is a directed path from both s and u to the set W j . The path R has one end-point in W i and another in W k . Thus, there is a directed path from W i to W j in the v ariable D A G. Note that the proof of the previous theorem implies that there is a v-structure W i → W j ← W k in the group D A G only if there exists w i ∈ W i , w j ∈ W j , and w k ∈ W k such that there exists a v-structure w i → w j ← w k in the v ariable D A G. After v-structures hav e been directed, one can direct the rest of the edges that point to the same direction in ev ery D AG of the Marko v equiv alence class using four local rules often referred to as the Meek rules [16]. The rules are [18]: 11 R1: Orient v − s into v → s if there is an arrow u → v such that u and s are nonadjacent. R2: Orient u − v into u → v if there is a chain u → s → v . R3: Orient u − v into u → v if there are two chains u − s → v and u − t → v such that s and t are nonadjacent. R4: Orient u − v into u → v if there are two chains u − s → t and s → t → v such that s and v are nonadjacent and u and t are adjacent. W e would like to generalize these rules for v ariable groups. Howe ver , these rules are not sufficient to infer group causality if one does ha ve access only to the group- wise conditional independencies (and to nothing else). T o see this, consider a group D A G H = ( W, E ) where W = { S , T , U, V } and E = { S U, T U, U V } sho wn in Figure 3(a). No w , Theorem 7 says that S and T are causes of U . The rule R1 suggest that we could claim that U is a cause of V . Ho we ver , we can construct a causal variable D A G G = ( N , F ) with N = { s 1 , s 2 , t 1 , t 2 , u 1 , u 2 , u 3 , v 1 , v 2 } and F = { u 1 s 1 , v 1 u 1 , s 2 u 2 , t 1 u 2 , v 2 u 3 , u 3 t 2 } and S = { s 1 , s 2 } , T = { t 1 , t 2 } , U = { u 1 , u 2 , u 3 } , and V = { v 1 , v 2 } ; see Figure 3(b). Clearly , G implies the same conditional indepen- dencies on W as does H and there is no directed path from U to V in G . Thus, U is not a cause of V in G . S T U V s 1 s 2 t 1 t 2 u 1 u 2 u 3 v 1 v 2 S T U V (a) (b) Figure 3: (a) A group D AG and (b) a causal v ariable D AG that implies the same groupwise indepen- dencies. The above observation implies that the Meek rules cannot be used to infer causality in group D A Gs. Howe ver , it is not known whether there are some special conditions under which the Meek rules would apply in this context. Note that the abov e applies only when the conditional independencies between individual variables are not known; when the v ariable D AG is known, this information can be used to help to infer more causal relations. 12 Let us analyze detecting strong group causality . The theorem belo w sho ws that none of the arcs in the group D A G imply strong group causality if minimum group size is at least 2. Theorem 8. W e ar e given a node set N , a gr ouping W , and a gr oup DA G H . If | W i | > 1 for all i then W j being an ancestor of W k in H does not imply that W j is a str ong gr oup cause of W k . Pr oof. By the definition of strong group cause, if W j is a strong group cause of W k then W k is not a group cause of W j . Thus, to prove the theorem, it is suf ficient to sho w that for any group D A G H and a grouping W with | W i | > 1 for all i there exists a causal variable D A G in which W k is a group cause of W j . In other words, it is suf ficient to sho w that for any group D A G H on W , where W j is an ancestor of W k , it is possible to construct a causal variable D A G G on N such that G giv en W implies the same conditional independencies as H , and there exists a pair w k ∈ W k and w j ∈ W j such that there is a directed path from w k to w j in G . Next, we will show how to construct such a variable D A G. Let H be the group D A G on W expressing groupwise conditional independencies. W ithout loss of generality , we can choose tw o distinct nodes w 1 i and w 2 i from each group W i . No w consider the follo wing causal v ariable D A G G 0 on N . W e start by setting G 0 to be an empty D A G. Then, we add edges from w 1 i to w 1 l for all i and l such that there is an edge from W i to W l in H . Finally , we select a directed path R from W j to W k and add an edge from w 2 l to w 2 i to G 0 if there is an edge from W i to W l on R ; note that W j is an ancestor of W k so there exists at least one directed path from W j to W k . It remains to sho w that the abov e construction has the desired properties, that is, G 0 gi ven W implies the same conditional independencies as H , and there exists a pair w k ∈ W k and w j ∈ W j such that there is a directed path from w k to w j in G 0 . It is clear that the induced graph on w 1 i -v ariables imply exactly the same groupwise conditional independencies as H . Furthermore, there is a path from W j to W k in H and the w 2 i -v ariables encode the same path in re verse, and do not e xpress an y dependencies that are not already implied by the w 1 i -v ariables; in other words, if w 2 i and w 2 l are d- connected gi ven S ⊆ W \ { W i , W l } in G 0 then W i and W l are d-connected given S in H . Therefore, H implies exactly the same conditional independencies on W as G 0 gi ven W . Furthermore, due to the existence of a path from w 2 k ∈ W k to w 2 j ∈ W j in the causal variable D A G G 0 , W j is not a strong group cause of W k . This is suf ficient to sho w that one cannot infer strong group causality using only groupwise conditional independencies. 4. Learning gr oup DA Gs Next, we will introduce three approaches for learning group D A Gs. 13 4.1. Dir ect Learning The most straightforward approach is to learn a group DA G directly , that is, either using conditional independencies or local scores on a grouping W . In other words, we can consider each group as a v ariable. Assuming that the v ariables are discrete, the possible states of the new v ariable w i , corresponding to the group W i , are the Cartesian product of the states of the variables in W i . Now there is a bijecti ve mapping between joint configurations of v ariables in W i and states of w i . Thus W i ⊥ ⊥ W j | S 1 if and only if w i ⊥ ⊥ w j | S 2 where W l ⊆ S 1 if and only if w l ∈ S 2 . This leads to a simple procedure described in Algorithm 1. Algorithm 1 F I N D G R O U P DA G 1 Input: Data D on a node set N , a grouping W on N . Output: Group D A G G 1: Con vert v ariables x i ∈ N into new v ariables y j on W such that y j = × x i ∈ W j x i . 2: Learn a D A G G on the new variables on W using procedure F I N D V A R I - A B L E DA G. 3: retur n G The procedure F I N D V A R I A B L E D AG in the second step is an algorithm for find- ing a D A G; it can use either the constraint-based or score-based approach. In prin- ciple, F I N D V A R I A B L E D AG can be any learning algorithm. Howe ver , if F I N D V A R I - A B L E DA G is an exact algorithm then we can pro ve some theoretical guarantees; see Theorems 10 and 11 below . W e will next pro ve the correctness of the algorithm for the constraint-based approach. First, we state a well-known lemma that is used in the proof. Lemma 9 ([22]) . Given data D on variables V , if V is causally suf ficient, the data- gener ating distribution is faithful to a D A G A , and the sample size tends to infinity then the PC algorithm finds a D A G that is Markov equivalent to A . Theorem 10. Let data D be generated fr om a Bayesian network ( G, Θ) which is gr oupwise faithful to a D A G G 0 given a gr ouping W . If causal suf ficiency holds, the sample size tends to infinity , and the pr ocedure F I N D V A R I A B L E D AG uses the PC al- gorithm then Algorithm 1 r eturns a structur e H that is Markov equivalent to G 0 . Pr oof. Let an assignment of v alues of v ariables in W j be denoted by W j = w and assignment of the state of y j be denoted by y j = y . By the definition of y j , each value y of y j corresponds to exactly one assignment w . Thus, for ev ery y there e xists a w such that P ( y j = y | S ) = P ( W j = w | S ) for all S ∈ 2 W \ W j . Therefore, y i ⊥ ⊥ y j | S if and only if W i ⊥ ⊥ W j | S . 14 Causal suf ficiency and groupwise faithfulness guarantee that the data-generating distribution has a perfect map G 0 on W . Thus, by causal sufficienc y , groupwise faith- fulness, infinite sample size, and Lemma 9, Algorithm 1 returns a D A G G that is equi v alent to G 0 . The same result can easily be extended to the score-based approach; see Theo- rem 11 below . W e assume that the scoring criterion is consistent. T o this end, we say that a distribution p is contained in a D A G G if there exist parameters Θ such as ( G, Θ) represents p exactly . W e are giv en i.i.d. samples D from some distrib ution p . A scoring criterion S is said to be consistent if, when the sample size tends to infinity , (1) S ( G, D ) > S ( H , D ) for all G and H such that p is contained in G but not in H and (2) S ( G, D ) > S ( H , D ) if p is contained in both G and H and G has less parameters that H ; for a more formal treatment of consistency , see, e.g., [21]. The proof is analogous to the proof abov e; instead of Lemma 9 one simply uses the fact (Proposition 8 in [5]) that if V is causally sufficient, the data-generating distribution is faithful to a D A G, a consistent scoring criterion is used and the sample size tends to infinity , then exact score-based algorithms return a D A G that is equiv alent to the data-generating D A G . Theorem 11. Let data D be generated fr om a Bayesian network ( G, Θ) which is gr oupwise faithful to a D A G G 0 given the gr ouping W . If causal sufficiency holds, the sample size tends to infinity , and the pr ocedur e F I N D V A R I A B L E D AG uses an e x- act scor e-based algorithm with a consistent scoring criterion then Algorithm 1 r eturns a structur e H that is Markov equivalent to G 0 . 4.2. Learning via V ariable D AGs W e note that a D A G ov er individual v ariables specifies also all the conditional independencies and dependencies between groups. Thus, it is possible to learn a group D A G by first learning a v ariable D A G and then inferring the group D A G. Algorithm 2 summarizes this approach. Algorithm 2 F I N D G R O U P DA G 2 Input: Data D on a node set N , a grouping W on N . Output: Group D A G G 1: Learn a D A G H on N using procedure F I N D V A R I A B L E D AG. 2: Learn a group DA G G on W using the PC algorithm and d-separation in H as an independence test. 3: retur n G The procedure F I N D V A R I A B L E D AG can again be either constraint-based or score- based. The following theorem shows the theoretical guarantees of the algorithm as- suming that F I N D V A R I A B L E D AG is exact. 15 Theorem 12. Let data D be generated fr om a Bayesian network ( G, Θ) which is gr oupwise faithful to a DA G G 0 given the gr ouping W . If causal sufficiency and faith- fulness hold, the sample size tends to infinity , and the pr ocedur e F I N D V A R I A B L E D AG uses the PC algorithm, Algorithm 2 r eturns a structur e H that is Marko v equivalent to G 0 . Pr oof. As causal suf ficiency and faithfulness hold, there exists a v ariable D A G that is a perfect map of the data-generating distrib ution, and because of infinite sample size and Lemma 9, the D A G H is that perfect map. By groupwise faithfulness, the conditional independencies implied by H gi ven the grouping W , can be expressed exactly by a group D A G. Thus by Lemma 9, Algorithm 2 returns a D A G G that is Marko v equi v alent to G 0 . Again, the abo ve result holds also for score-based methods as summarized belo w . Theorem 13. Let data D be generated fr om a Bayesian network ( G, Θ) which is gr oupwise faithful to a D A G G 0 given gr ouping W . If causal sufficiency and faith- fulness hold, the sample size tends to infinity , and the pr ocedur e F I N D V A R I A B L E D AG uses an e xact scor e-based algorithm with a consistent scoring criterion, then Algo- rithm 2 r eturns a structur e H that is Markov equivalent to G 0 . 4.3. Combined learning The combined learning algorithm is based on the score-based approach and learns both the variable D A G and the group D A G simultaneously under an assumption that the topological orders of the variable D A G and the group D A G are compatible. This algorithm is a v ariant of the dynamic programming algorithm by Silander and Myl- lym ¨ aki [20]. The pseudocode is sho wn in Algorithm 3. For simplicity , we show only ho w to compute the score of the group D A G; the D A G can be constructed in the sim- ilar fashion as in Silander and Myllym ¨ aki [20], by keeping track of which parent sets contributed to the score. The algorithm begins with computing local scores for node–parent set pairs and finding the highest scoring parent set from the subsets of a gi ven set (Lines 1–4). Then the algorithm proceeds to find the highest scoring D A G for each subset of the groups using dynamic programming (Lines 6–14). For each subset, one variable group is going to be a sink, that is, it has no children in the particular subset. Assuming that W i is the sink of the set T , the algorithm computes score for node W i gi ven that the parents of W i are chosen from T \ W i . This is computed by finding the score of the best D A G for nodes in W i gi ven that each node is allowed to take parents from T (Lines 8–11). The parent set of W i is then the union of all groups in W j ∈ T \ W i such that at least one of the variables in W j is a parent of at least one v ariable of W i in the D A G found on Line 11. The score of the best group D A G on T gi ven that W i is a sink is the sum of the score of the sink and the score of the best D A G for the rest of the nodes. T o find 16 an optimal group D A G on T , one loops over all possible choices of sink and chooses the one with the highest score (Line 13). Finally , the optimal group D A G for the whole grouping is returned (Line 15). Algorithm 3 F I N D G R O U P DA G 3 Input: Data D on a node set N , a grouping W on N , the maximum number of parents c . Output: A group D A G H 1: f or all v ∈ N and S ⊆ N \ { v } , | S | ≤ c in the order of increasing cardinality of S do 2: Store the local score for v and S to s [ v , S ] 3: bs [ v , S ] = max U ⊆ S s [ v , S ] 4: end f or 5: B [ ∅ ] = 0 6: f or all T ∈ 2 W in the order of increasing cardinality do 7: f or all W i ∈ T do 8: f or all v ∈ W i and U ⊆ W i \ { v } do 9: bss [ v , U ] = max R ⊆ U ∪ ( T \ W i ) bs [ v , R ] 10: end f or 11: ss [ W i , T \ W i ] = the score of a highest scoring v ariable D A G on members of W i gi ven local scores bss [ v , U ] 12: end f or 13: B [ T ] = max W i ∈ T ss [ W i , T \ W i ] + B [ T \ W i ] 14: end f or 15: retur n B [ N ] Let us analyze the time requirement of the algorithm. Recall that we ha ve n vari- ables and k groups. Let us use n max = max i | W i | to denote the size of the largest group. The first loop (Line 1) is executed O ( n c +1 ) times. Finding the highest-scoring subset can be done using an additional O ( n ) time [20]. Thus, the first loop takes a total O ( n c +2 ) time. Let us consider the loop starting at Line 6. The outmost loop is ex e- cuted 2 k times and the second loop at most n max times. The loop on Line 8 is ex ecuted at most n max 2 n max − 1 times. The computation of Line 9 can be done re-using values computed in previous steps by a straightforward adaptation of methods presented by Silander and Myllym ¨ aki [20], with an additional cost of O ( n max ) . The computation of Line 11 uses the standard Silander -Myllym ¨ aki algorithm and is done in O ( n max 2 n max ) time. This yields a total time requirement O ( n c +2 + 2 k + n max n 2 max ) . Note that finding a highest-scoring v ariable D A G using dynamic programming takes O ( n 2 2 n ) time, so if the number of the groups and the sizes of the groups are approximately equal, the combined learning algorithm is considerably faster . The follo wing theorem provides theoretical guarantees for the algorithm. 17 Theorem 14. Let data D be generated fr om a Bayesian network ( G, Θ) which is gr oupwise faithful to a D A G G 0 given a gr ouping W and whose topological or der is compatible with G 0 . If causal suf ficiency and faithfulness hold, the sample size tends to infinity , and the pr ocedur e F I N D V A R I A B L E D AG uses an exact scor e-based algo- rithm with a consistent scoring criterion then Algorithm 3 r eturns a structur e H that is Markov equivalent to G 0 . Pr oof. Gi ven causal sufficienc y , faithfulness, infinite sample size, and a consistent scoring criterion, G is a highest scoring v ariable network. Because G and G 0 are compatible, all parents of members of W i in G are either in W i or in the members of parents of W i in G 0 . Therefore, the score of D AG G 0 equals the highest score and the algorithm returns G 0 . Note that the algorithm is guaranteed to find the equi v alence class of the data- generating structure only when the compatibility condition holds. Otherwise, the found variable network may be suboptimal e ven if the data-generating distribution is groupwise faithful. 5. Experiments 5.1. Implementations W e implemented our algorithms using Matlab . The implementation is a v ailable at http://research.cs.aalto.fi/pml/software/GroupBN/ . The imple- mentation of the PC algorithm from the BNT toolbox 2 was used as the constraint-based version of procedure F I N D V A R I A B L E DA G. As the score-based version, we used the state-of-the-art integer linear programming algorithm GOBNILP 3 . 5.2. Simulations Next, we will e v aluate the prospects of learning group D A Gs in practice. Our goal is to analyze 1) to what extent it is possible to learn group D A Gs from data and 2) which learning approach one should use. W e did two different simulation setups. In Experiment 1 , we generated data from three different manually-constructed Bayesian netw ork structures called structures 1, 2, and 3 having 30 , 40 , and 50 nodes, respectively , divided into 10 equally sized groups. All structures were groupwise faithful to the group D A G; the network structures are sho wn in Appendix B. For each structure we generated 50 binary-valued Bayesian networks by sampling the parameters uniformly at random. Then, we sampled data sets of size 100, 500, 2000, and 10000 from each of the Bayesian networks. 2 https://code.google.com/p/bnt/ 3 http://www.cs.york.ac.uk/aig/sw/gobnilp/ 18 In Experiment 2 , we randomly generated groupwise faithful structures. W e are not aware of an y efficient algorithm for generating groupwise faithful D A Gs. Also from the experiment in the Section 3.1 we know that selecting both DA Gs and group- ings at random tend to lead complete or near-complete group D A Gs. Thus, to get sparser group D A Gs and variable D A Gs that are groupwise faithful to them, we used to follo wing procedure. • Fix a node set N of nk nodes and a grouping W on N with k nodes in each group. • Generate a group D A G H with n = 10 nodes with fixed order such that each possible edge is included independently with probability p = 0 . 2 . • Select one node w i ∈ W i from each group. Initialize G such that w i w j ∈ G if and only if W i W j ∈ H . • Repeat 1000 times – Choose nodes u and v uniformly at random from N . – If uv ∈ G then G 0 = G \ { uv } else G 0 = G ∪ { uv } . – If G 0 is acyclic and G 0 gi ven grouping W implies the same conditional independencies as H then G = G 0 . • Return H and G . W e generated 100 group and v ariable D A Gs using the abov e procedure for group sizes k = 2 , 3 , 4 , 5 . Then we generated a binary-valued Bayesian network by sampling the parameters uniformly at random and sampled data sets of size 100, 500, 2000, and 10000 from each of the Bayesian networks. W e ran both the constraint-based and score-based v ersion of Algorithms 1 and 2. Conditional independence tests were conducted using signifance le vel 0 . 05 and the score-based algorithms used the BDeu score with equi valent sample size 1 . In all tests we used a 4 GB memory limit. As we are interested in conditional independencies, we con verted D A Gs into CPD A Gs and measured accuracy by computing structural Ham- ming distance (SHD) between the data-generating CPD A G and the learned CPD A G. The results from Experiments 1 and 2 are shown in Figures 4 and 5, respecti vely . T o answer our first research question, we notice that both experiments suggest that group D A Gs can be learned accurately when the groups are small and there are sufficiently many samples; see, e.g., Figure 5 with group size 2 and 10000 samples. Howe ver , the accuracy seems to decrease when the group size gro ws or the number of samples decreases. Intuiti vely , the decrease of accuracy when the groups size gro ws makes sense because the bigger the groups the more possibilities there are to add false positiv e edges to the group D A G. 19 Figure 4: A verage SHD (Structural Hamming Distance) between the learned group CPD AG and the true group CPD A G when the data were generated from three different structures (Experiment 1). DL = direct learning, VD = learning using v ariable D A Gs, CL = combined learning, CB = constraint-based, SB = score-based. The numbers on the x-axis are sample sizes. Missing bars for constraint-based direct learning are due to the algorithm running out of memory . W e also observ e that constraint-based direct learning struggles often and in many cases we do not get any results because the algorithm runs out of memory . This is due to the fact that variables in the direct learning approach have lots of states and thus direct learning requires lots of data to draw any conclusions. On the other hand, it seems that the constraint-based lerning via variable DA Gs performs well. Especially , it is generally the most accurate approach when there are few samples. The relativ ely good performance of the constraint-based approach when there is little data can be explained at least partially as follows. Intuitiv ely , learning a true positi ve edge in the group D A G is rob ust: T o include a true positi ve edge, it is enough that the learned v ariable D A G preserves only one d-connected path between the groups (out of possibly many such paths). On the other hand, e ven one f alse positi ve dependence between two nodes in dif ferent groups leads to connecting the two groups in the group D A G. Thus, too sparse variable D A Gs seem to result in more accurate group DA Gs than too dense v ariable D A Gs. This intuition is supported by our empirical observ ation that typically , learned group D A Gs hav e more false positiv e edges than f alse neg ati ves. Furthermore, we observ e that constraint-based methods tend to be more conserv ati ve, that is, if there is little data then the variable D A G learned with the constraint-based method tends to be sparser than the variable D A G learned with the score-based method; the sparsity may be due to type II errors in conditional independence tests. Furthermore, we observe that the accuracy of score-based direct learning is not sig- nificantly affected by the sample size. Score-based learning via v ariables D A Gs is very accurate when there are lots of samples. Ho wev er , its accurac y decreases substantially if the number of samples is lo w . Also combined learning ga ve accurate results, especially when the sample size 20 Figure 5: A verage SHD (Structural Hamming Distance) between the learned group CPD A G and the true group CPD A G when the data were generated by sampling groupwise faithful networks (Experiment 2). DL = direct learning, VD = learning using variable D A Gs, CL = combined learning, CB = constraint- based, SB = score-based. The numbers on the x-axis are sample sizes. Missing bars for constraint-based direct learning are due to the algorithm running out of memory . was lar ge, although all other methods hav e better theoretical guarantees than com- bined learning. Combined learning forces the topological orders of the variable and group D A G to be compatible and this might act as some kind of implicit re gularization. Note that in Experiment 1 combined learning benefits from the fact that the topolog- ical orders of the data-generating v ariable and group D A Gs were compatible b ut it was still quite accurate in Experiment 2 were the topological orders were not always compatible. T o answer our second question, we conclude that constraind-based learning via v ariable DA Gs is the most accurate method if there are only few (less than 500) sam- ples. If there are plenty samples then combined learning and score-based learning via v ariable D A Gs are the most accurate approaches. 5.3. Real data Next, we demonstrate learning of group D A Gs from real data and challenges that are faced in this scenario. A prominent challenge here is the dif ficulty of assessing the quality of the learned group D A Gs in the absence of ground-truth. W e applied the learning methods to the H O U S I N G data that is av ailable at the UCI machine learning repository [2]. The data contain 14 v ariables for 506 observations, 21 measuring multiple factors affecting housing prices in dif ferent neighborhoods in the Boston area. W e grouped the v ariables into 9 groups. Group Accessibility consisted of v ariables CHAS, DIS, and RAD, group Zoning consisted of v ariables ZN and INDUS, group Apartment pr operties consisted of variables RM and A GE, and group P opulation consisted of variables B and LST A T . Five of our groups consisted of one variable: Crime of CRIM, P ollution of NO X, Education of PTRA TIO, House prices of MED V , and T axes of T AX. W e learned a group D A G using each of the fiv e algorithms; all group D A Gs (as well as corresponding vari able D A Gs when applicable) are shown in Appendix B. W e sho w here only two representativ e networks. Our simulations (Section 5.2) sho wed that constraint-based learning via a v ariable D A G and combined learning resulted in smallest a verage SHD with sample size 500 so we chose them as representati ve meth- ods; the group D A G from constraint-based learning is shown in Figure 6(a) and the corresponding v ariable D A G in Figure 6(b). The D A Gs from combined learning are sho wn in Figure 7. (a) (b) Figure 6: (a) The group D AG learned from H O U S I N G data using constraint-based learning via a variable D AG. (b) The corresponding v ariable D A G. W e can make sev eral observations from Figure 6. W e notice that the group D A G in Figure 6(a) has a v-structure Apartment pr operties → House prices ← T axes . By Theorem 7, this implies that Apartment pr operties and T axes are group causes of House prices and thus manipulating them would af fect house prices; this seems a plausible conclusion. W e see from the variable D A G that, indeed, there are directed paths from both Apartment pr operties and T axes to House prices . Howe ver , the v ariable D A G sho wn in Figure 6(b) is not groupwise faithful to the group DA G giv en the grouping. T o see this, we notice that Zoning and Crime are conditionally independent in the v ariable D A G gi ven P ollution and Apartment pr operties b ut not in the group D A G. 22 (a) (b) Figure 7: (a) The group D AG learned from H O U S I N G data using combined learning. (b) The corre- sponding variable D AG. Thus, the group D A G e xpresses some dependencies that are not present in the v ariable D A G. W e see that the D A Gs in Figure 7 dif fer from the ones in Figure 6. For example, House prices is a neighbor of Apartment pr operties but not with T axes in the group D A G. Overall, structural Hamming distance between the group D A Gs is 19 . While this case study is not enough to warrant any statistical conclusions, we recommend one not to trust blindly on the learned group D A Gs because results may be sensiti ve to the choice of an algorithm. 6. Discussion In this paper we introduced the concept of group D A G for modeling conditional independencies and dependencies between groups of random variables, and studied prospects of learning group D A Gs. It turned out, perhaps unsurprisingly , that many aspects become more complicated when moving from individual variables to groups of variables. W e sho wed that in order to have theoretical guarantees for the qual- ity of learned networks, one has to assume groupwise faithfulness, which is a rather strong assumption. Further, inferring causal relationships between groups becomes more tricky . In this paper , we studied structure learning. Naturally , it is possible to extend group D A Gs to group Bayesian networks by learning parameters. As each group can 23 be treated as a v ariable, we can use any standard method for learning parameters. Ho we ver , it should be noted that the group variables tend to hav e lots of states which may render the estimation of parameters inaccurate. Therefore, if the goal is to use the learned network to infer probabilities then one may want to use a standard Bayesian network instead of a group Bayesian network. Our experiments suggest that data does not alw ays beha ve “nicely”. One ine vitable dif ficulty is that data are often groupwise unfaithful. The other practical challenge is that principled methods add an edge to the group D A G if there e xists ev en one weak dependency between two groups. Therefore, erroneous dependencies from conditional independence tests or local scores can lead into lots of f alse positi ve edges in the group D A G. In practice, it may be desirable to take a less principled approach and use some kind of regularization to get rid of spurious edges. One way to alle viate this problem is to use a lo w significance le vel in the conditional independence tests. W e hav e assumed that the v ariable groups are kno wn beforehand, as prior knowl- edge, and asked what can be done with the extra prior kno wledge. A natural follo w-up question is that can the groups be learned from data. Even though this interesting ques- tion is superficially related it is, howe ver , a distinct and very different problem that is likely to require a dif ferent machinery . Multiple dif ferent goals for such a clustering of v ariables are possible and sensible. Acknowledgements The authors thank Cassio de Campos, Antti Hyttinen, Esa Junttila, Jefrey Lijf fijt, Daniel Malinsk y , T eemu Roos, and Milan Studen ´ y for useful discussions. The work was partially funded by The Academy of Finland (Finnish Centre of Excellence in Computational Inference Research COIN). The experimental results were computed using computer resources within the Aalto Uni versity School of Science ”Science-IT” project. References [1] C.F . Aliferis, A. Statnikov , I. Tsamardinos, S. Mani, and X.D. K outsoukos. Local Causal and Markov Blanket Induction for Causal Disco very and Feature Selec- tion for Classification Part I: Algorithms and Empirical Evaluation. J ournal of Machine Learning Resear ch , 11:171–234, 2010. [2] K. Bache and M. Lichman. UCI machine learning repository , 2013. [3] J. Burge and T . Lane. Improving Bayesian Network Structure Search with Ran- dom V ariable Aggregation Hierarchies. In ECML , pages 66–77. Springer , Berlin, Heidelberg, 2006. 24 [4] D.M. Chickering. Learning Bayesian networks is NP-Complete. In Learning fr om Data: Artificial Intelligence and Statistics , pages 121–130. Springer-V erlag, 1996. [5] D.M. Chickering. Optimal Structure Identification W ith Greedy Search. Journal of Machine Learning Reseac h , 3:507–554, 2002. [6] G.F . Cooper and E. Herskovits. A Bayesian Method for the Induction of Proba- bilistic Networks from Data. Machine Learning , 9(4):309–347, 1992. [7] J. Cussens. Bayesian network learning with cutting planes. In U AI , pages 153– 160. A U AI Press, 2011. [8] S. Davies and A. Moore. Bayesian network for lossless dataset compression. In Pr oceedings of the fifth ACM SIGKDD international confer ence on Knowledge discovery and data mining (KDD) , pages 387–391, 1999. [9] D. Entner and P .O. Hoyer . Estimating a Causal Order among Groups of V ariables in Linear Models. In ICANN , pages 83–90. Spinger , 2012. [10] P . Erd ˝ os and A. R ´ enyi. On random graphs i. Publicationes Mathematicae , 6:290– 297, 1959. [11] E.N. Gilbert. Random graphs. Annals of Mathematical Statistics , 30:1141–1144, 1959. [12] E. Gyftodimos and P .A. Flach. Hierarchical Bayesian networks: a probabilistic reasoning model for structured domains. In ICML-2002 W orkshop on Develop- ment of Repr esentations , 2002. [13] D. Heckerman, D. Geiger , and D.M. Chickering. Learning Bayesian Net- works: The Combination of Kno wledge and Statistical Data. Machine Learning , 20(3):197–243, 1995. [14] T . Jaakkola, D. Sontag, A. Globerson, and M. Meila. Learning Bayesian Network Structure using LP Relaxations. In AIST A TS , pages 358–365, 2010. [15] D. Koller and A. Pfeffer . Object-oriented Bayesian networks. In U AI , pages 302–313. Morg an Kaufmann Publishers Inc., 1997. [16] C. Meek. Causal Inference and Causal Explanation with Background Kno wl- edge. In U AI , pages 403–410. Morgan Kaufmann, 1995. [17] P . Parviainen and S. Kaski. Bayesian networks for variable groups. In JMLR: W orkshop and Confer ence Pr occedings , volume 52, pages 380–391, 2016. 25 [18] J. Pearl. Causality: Models, Reasoning, and Infer ence . Cambridge uni versity Press, 2000. [19] E. Segal, D. Pe’er , A. Rege v , D. K oller, and N. Friedman. Learning Module Networks. Journal of Mac hine Learning Reseach , 6:557–588, October 2005. [20] T . Silander and P . Myllym ¨ aki. A simple approach for finding the globally optimal Bayesian network structure. In U AI , pages 445–452. A U AI Press, 2006. [21] N. Slobodianik, D. Zaporozhets, and N. Madras. Strong limit theorems for the bayesian scoring criterion in bayesian networks. J ournal of Machine Learning Resear ch , 10:1511–1526, 2009. [22] P . Spirtes, C. Glymour , and R. Scheines. Causation, Pr ediction, and Sear ch . Springer V erlag, 2000. [23] T .S. V erma and J. Pearl. Equi v alence and synthesis of causal models. In U AI , pages 255–270. Else vier , 1990. [24] Y . Xiang, D. Poole, and M. P . Beddoes. Multiply sectioned bayesian networks and junction forests for large kno wledge-based systems. Computational Intelli- gence , 9:171–220, 1993. 26 A ppendix A. Proofs of Theor ems 3 and 4 Next, we will prov e Theorems 3 and 4. W e will start by proving some lemmas that are used in the proof of Theorem 3. Lemma 15. Let H be a gr oup D A G on a gr ouping W and let max i | W i | = 1 . Then any distribution p on ∪ W i that is gr oupwise faithful to H given W is faithful to some variable D A G on ∪ W i . Pr oof. As all groups consist of exactly one variable, the conditional independencies implied by the group D A Gs has to be expressed exactly by the data-generating dis- tribution, that is, the v ariable D A G (up to a relabelling). Thus, the data-generating distribution p has to be faithful to a D A G. Lemma 16. Let H be a gr oup D AG on gr ouping W and let max i | W i | = 2 . If no gr oup of size 2 has neighbor s, then all distrib utions on ∪ W i that ar e gr oupwise faithful to H given W ar e faithful to a variable D A G. Pr oof. Clearly , none of the members of the groups of size 2 cannot be connected to any v ariables outside the group. The tw o v ariables inside a group are either independent or dependent. In both cases their joint distrib ution is faithful to a D A G. By Lemma 15, the v ariable D A G corresponding to the subgraph of the group D A G induced by the groups of size 1 is f aithful to a D A G. Thus, the distrib ution p is faithful to a D A G No w , we are ready to prov e Theorem 3 which follo ws straightforwardly from the pre vious lemmas. Theorem 3. Let H be a gr oup D AG on a gr ouping W . Then every distribution p on ∪ W i that is gr oupwise faithful to H given W is faithful to some variable D A G on ∪ W i if max W i ∈ W | W i | = 1 or max W i ∈ W | W i | = 2 and no gr oup of size 2 has neighbors in H . Pr oof. F ollo ws directly from Lemmas 15 and 16. Next, we will pro ve Theorem 4. W e start by proving two lemmas. In the following proofs we will e xploit the well-known fact that an exclusi ve or (XOR) distrib ution is unfaithful. That is, if we hav e three binary v ariables X , Y , and Z where P ( X = 1) = P ( Y = 1) = 1 / 2 and Z = XOR ( X, Y ) then the conditional independencies cannot be expressed exactly using any D A G. T o see this, we note that Z depends on both X and Y . Ho wev er , it is marginally independent of both of them. Lemma 17. Let H be a gr oup DA G on gr ouping W and let max i | W i | = 2 . If two gr oups of size 2 ar e neighbors, then not all distributions on ∪ W i that ar e gr oupwise faithful to H given W ar e faithful to a variable D A G. 27 Pr oof. It suf fices to show that for an y group D AG–grouping pair there e xists a dis- tribution p that implies exactly the same groupwise conditional independencies as H gi ven W b ut p is not faithful to an y v ariable D A G. W ithout loss of generality , let us assume that | W 1 | = | W 2 | = 2 and W 1 is a parent of W 2 in the group D A G. Further , let w i ∈ W i be a specified element of a group. No w let us construct a variable D A G G as follows. If there is an arc from W i to W j in H then there is an arc from w i to w j in G . Further , there are arcs uv and w 2 v in G , where u ∈ W 1 \ { w 1 } and v ∈ W 2 \ { w 2 } . If we choose parameters such that the marginal distribution on ∪ W i \ { u, v } is faithful to the induced subgraph G [ ∪ W i \ { u, v } ] and the local conditional distribution of node v is an exclusi ve or (XOR) distribution, then the distrib ution p e xpresses e xactly the same groupwise conditional independencies as H but is not faithful to an y D A G. Lemma 18. Let H be a gr oup DA G on gr ouping W and let max i | W i | ≥ 3 . Then not all distributions on ∪ W i that ar e gr oupwise faithful to H given W ar e faithful to a variable D A G. Pr oof. It is enough to show that for any group D A G–grouping pair there exists a dis- tribution p that implies exactly the same conditional independencies as H but p is not faithful to an y v ariable D A G. W ithout loss of generality , let us assume that | W 1 | ≥ 3 . Further , let w i ∈ W i be a specified element of a group. Now let us construct a variable D A G G as follows. If there is an arc from W i to W j in H then there is an arc from w i to w j in G . Further , there are arcs w 1 u and v u in G , where u, v ∈ W 1 . If we choose parameters such that the mar ginal distrib ution on ∪ W i \ { u, v } is faithful to the induced subgraph G [ ∪ W i \ { u, v } ] and the local conditional distribution of the node u is an exclusi ve or (XOR) distribution, then the distribution p expresses exactly the same groupwise conditional independencies as H but is not faithful to an y D A G. W e are ready to prove Theorem 4. Theorem 4. Let H be a gr oup D A G on a gr ouping W . If max W i ∈ W | W i | ≥ 3 , or max W i ∈ W | W i | = 2 and two gr oups of size 2 ar e adjacent in the gr oup D AG, then ther e exists a distribution p such that p implies the same set of gr oupwise conditional independencies as H on W and p is not faithful to any D A G. Pr oof. F ollo ws directly from Lemmas 17 and 18. 28 A ppendix B. Additional figures 29 (a) (b) (c) (d) Figure B.8: (a) The data-generating group DA G. (b) The variable D A G of the first data-generating structure. Groups are following: v 1 = { 1 , 2 , 3 } , v 2 = { 4 , 5 , 6 } , v 3 = { 7 , 8 , 9 } , v 4 = { 10 , 11 , 12 } , v 5 = { 13 , 14 , 15 } , v 6 = { 16 , 17 , 18 } , v 7 = { 19 , 20 , 21 } , v 8 = { 22 , 23 , 24 } , v 9 = { 25 , 26 , 27 } , and v 10 = { 28 , 29 , 30 } . (c) The variable D A G of the second data-generating structure. Groups are following: v 1 = { 1 , 2 , 3 , 31 } , v 2 = { 4 , 5 , 6 , 32 } , v 3 = { 7 , 8 , 9 , 33 } , v 4 = { 10 , 11 , 12 , 34 } , v 5 = { 13 , 14 , 15 , 35 } , v 6 = { 16 , 17 , 18 , 36 } , v 7 = { 19 , 20 , 21 , 37 } , v 8 = { 22 , 23 , 24 , 38 } , v 9 = { 25 , 26 , 27 , 39 } , and v 10 = { 28 , 29 , 30 , 40 } . (d) The variable DA G of the third data-generating structure. Groups are following: v 1 = { 1 , 2 , 3 , 31 , 41 } , v 2 = { 4 , 5 , 6 , 32 , 42 } , v 3 = { 7 , 8 , 9 , 33 , 43 } , v 4 = { 10 , 11 , 12 , 34 , 44 } , v 5 = { 13 , 14 , 15 , 35 , 45 } , v 6 = { 16 , 17 , 18 , 36 , 46 } , v 7 = { 19 , 20 , 21 , 37 , 47 } , v 8 = { 22 , 23 , 24 , 38 , 48 } , v 9 = { 25 , 26 , 27 , 39 , 49 } , and v 10 = { 28 , 29 , 30 , 40 , 50 } . 30 (a) (b) (c) (d) (e) Figure B.9: The group D A G learned from H O U S I N G data using (a) constraint-based direct learning, (b) constraint-based learning via variable D A G, (c) score-based direct learning, (d) score-based learning via variable D AG, and (e) combined learning. 31 (a) (b) (c) Figure B.10: The v ariable DA G learned from H O U S I N G data using (a) constraint-based learning, (b) score-based learning, and (c) combined learning. 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment