변수 그룹을 위한 베이지안 네트워크 구조 학습
본 논문은 사전에 정의된 변수 그룹 간의 의존관계를 베이지안 네트워크 구조로 표현하기 위한 이론적 조건과 학습 알고리즘을 제시한다. 그룹별 조건부 독립성을 정확히 재현하려면 ‘그룹별 신실성(groupwise faithfulness)’이라는 강력한 가정이 필요하며, 그룹 간 인과관계를 추론하려면 개별 변수 수준의 관계까지 고려해야 함을 보인다. 이를 바탕으로 직접 그룹 독립성을 이용하는 방법, 개별 변수 네트워크를 먼저 학습한 뒤 그룹 구조를 추…
저자: Pekka Parviainen, Samuel Kaski
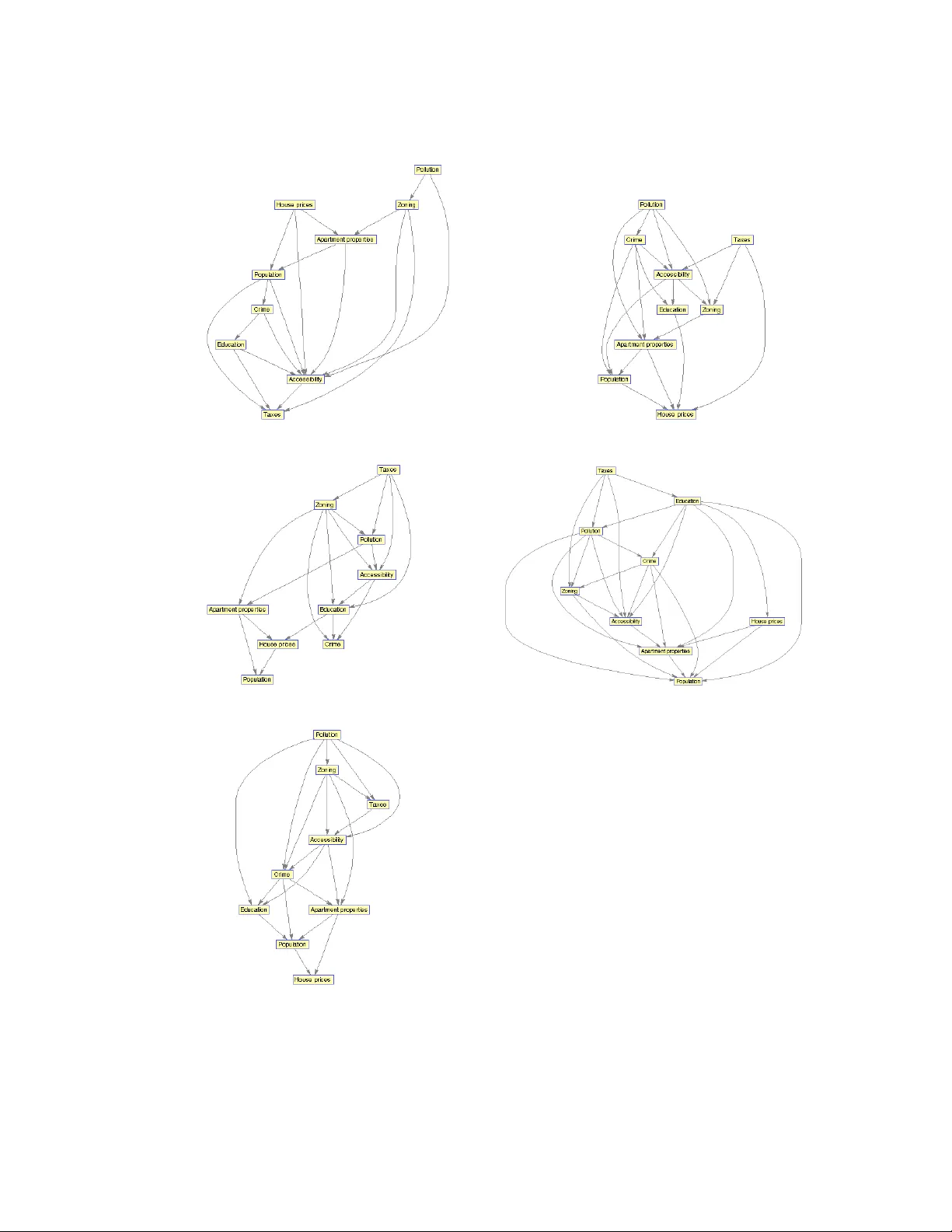
베이지안 네트워크(BN)는 확률 변수들의 결합 분포를 조건부 독립성 구조로 표현하는 강력한 도구이며, 구조 학습은 크게 제약 기반과 점수 기반 두 갈래로 나뉜다. 기존 연구는 개별 변수 간의 의존관계에 초점을 맞추었지만, 실제 데이터 분석에서는 변수들이 사전에 정의된 그룹으로 묶여 있는 경우가 빈번하다. 예를 들어, 동일 유전자를 여러 플랫폼에서 측정하거나, 같은 생물학적 경로에 속하는 유전자 집합을 하나의 그룹으로 보는 경우가 있다. 이러한 상황에서 연구자는 “그룹 간 의존관계” 자체를 모델링하고 싶어한다.
논문은 이러한 요구를 충족시키기 위해 먼저 이론적 기반을 마련한다. 변수 집합 N을 K개의 비공집합 그룹 W={W₁,…,W_K}로 분할하고, 각 그룹을 하나의 노드로 하는 그룹 DAG H를 정의한다. 목표는 데이터 분포 p가 변수 DAG G에 신실하게(faithful) 맞춰져 있을 때, 그룹 DAG H가 그룹 간 조건부 독립성( W_i ⟂⊥ W_j | S )을 정확히 재현하도록 하는 것이다. 그러나 DAG는 마진화나 집계에 대해 닫혀 있지 않으며, 변수 DAG에서 유도된 그룹 독립성 집합이 어떤 DAG로도 완전하게 표현되지 않을 수 있다. 이를 보여주는 대표적인 예가 그림 1(a)이며, 여기서는 V₁과 V₂가 V₃를 매개로 독립·조건부 독립을 동시에 만족하지만, 이를 만족하는 그룹 DAG는 존재하지 않는다.
이러한 문제를 해결하기 위해 저자는 ‘그룹별 신실성(groupwise faithfulness)’이라는 새로운 가정을 도입한다. 정의에 따르면, 분포 p가 그룹 DAG H에 대해 정확히 같은 조건부 독립성 집합을 갖는다면 p는 그룹별 신실하다고 한다. 이는 기존의 신실성 가정과 유사하지만, 변수 수준이 아닌 그룹 수준에서의 완전한 일치를 요구한다. 논문은 여러 사례를 통해 신실성만으로는 충분하지 않으며, 그룹 마코프 동등성(groupwise Markov equivalence)도 필요조건이 아니라는 점을 증명한다. 예를 들어, 변수 DAG가 신실하지만 특정 그룹 구성을 하면 그룹별 신실성이 깨지는 경우, 혹은 변수 DAG가 비신실하지만 XOR 같은 비선형 관계가 특정 변수에만 존재해 그룹 수준에서는 신실성을 유지하는 경우 등을 제시한다.
인과관계 학습에 대한 탐구에서는, 그룹 간 조건부 독립성만으로는 방향성을 결정할 수 없다는 결론에 도달한다. 그룹 DAG의 에지 방향을 추론하려면 변수 DAG에서 나타나는 v-structure와 같은 구조적 단서가 필요하다. 따라서 “그룹 간 인과관계”를 밝히기 위해서는 변수 수준의 인과 정보를 함께 고려해야 함을 강조한다.
알고리즘적 제안은 세 가지로 구분된다.
1) **그룹 직접 학습**: 그룹 간 조건부 독립성을 테스트하거나 로컬 점수를 계산해 직접 그룹 DAG를 구성한다. 이 방법은 데이터 요구량이 크고, 그룹별 신실성이 충족될 때만 정확한 구조를 복원한다.
2) **변수 → 그룹 전이**: 모든 변수 수준의 조건부 독립성을 먼저 학습하고, 이를 집계해 그룹 간 독립성을 유도한다. 변수 DAG가 정확히 추정되면, 그룹 DAG도 정확히 복원될 수 있다. 실험에서 이 방법은 데이터가 충분히 많을 때 높은 정확도를 보였다.
3) **통합 학습**: 변수와 그룹 두 수준을 동시에 최적화하는 프레임워크를 제시한다. 변수 DAG와 그룹 DAG 사이에 상호 제약을 두어, 하나의 단계에서 얻은 정보를 다른 단계에 피드백한다. 이 접근법은 특히 변수와 그룹 간 상호 의존성이 강한 경우에 유리하며, 실험 결과 두 번째 방법보다 약간 높은 정확도를 기록했다.
실험에서는 합성 데이터와 실제 유전자 발현 데이터를 사용해 세 알고리즘을 비교하였다. 결과는 (2)와 (3) 방법이 데이터 양이 중간 정도일 때도 높은 구조 복원률을 보였으며, (1) 방법은 데이터가 매우 풍부할 때만 경쟁력을 가졌다. 또한, 그룹별 신실성이 실제 데이터에서 자주 위배된다는 점을 확인했으며, 이는 이 가정이 현실에서 강력한 제약임을 시사한다.
결론적으로, 논문은 “그룹별 신실성”이라는 새로운 이론적 전제를 제시하고, 이를 기반으로 한 구조 학습 알고리즘을 설계·평가함으로써, 변수 그룹 간 관계를 베이지안 네트워크로 모델링하고자 하는 연구자들에게 중요한 지침을 제공한다. 다만, 가정이 강력하고 실제 데이터에서 충족되기 어려울 수 있다는 한계와, 인과관계 추론을 위해서는 변수 수준의 추가 정보가 필요함을 명확히 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기