Approximate Capacity of Gaussian Relay Networks
We present an achievable rate for general Gaussian relay networks. We show that the achievable rate is within a constant number of bits from the information-theoretic cut-set upper bound on the capacity of these networks. This constant depends on the…
Authors: Amir Salman Avestimehr, Suhas N. Diggavi, David N C. Tse
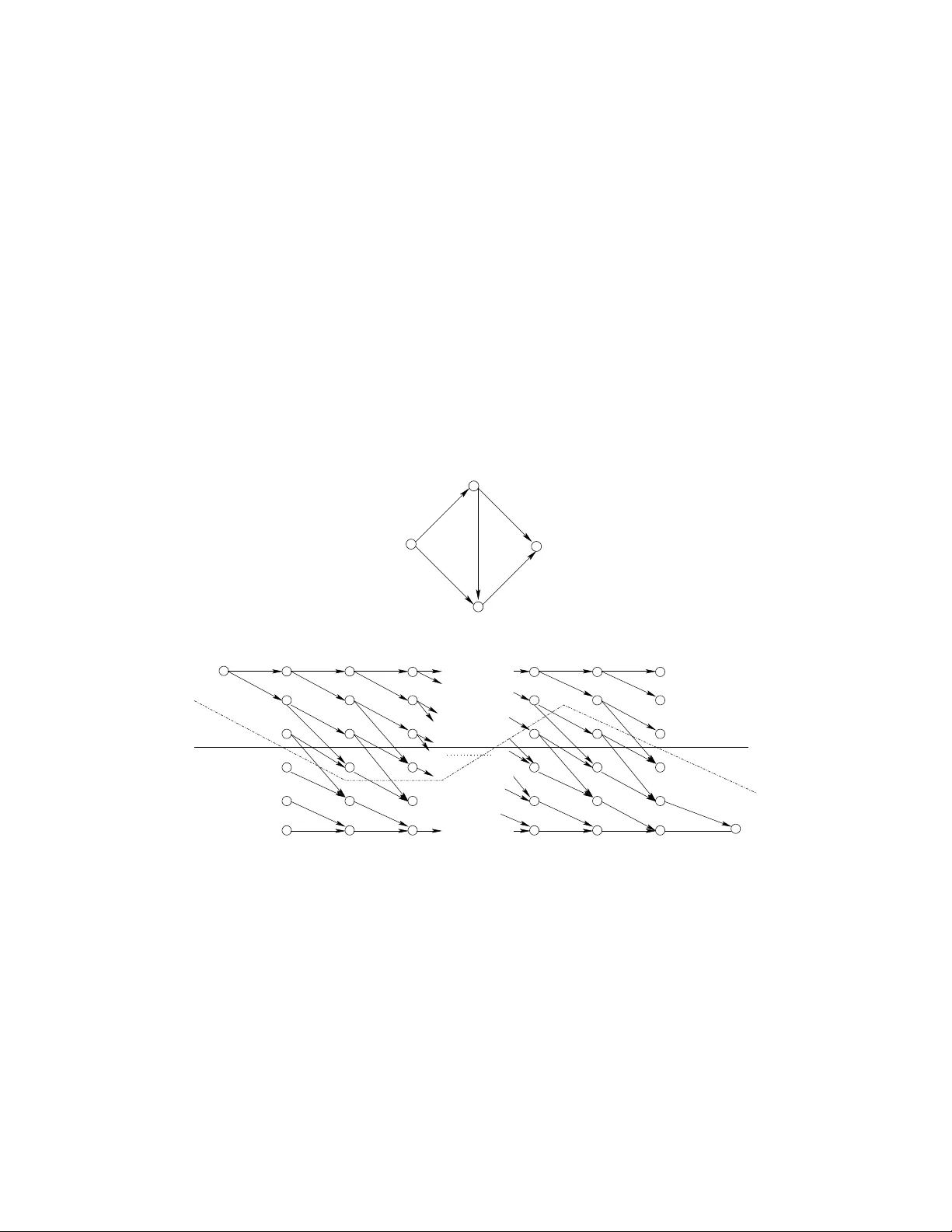
Approximate Capacity of Gaussian Relay Netw orks Amir Salman A v estimehr W ireless Foundations UC Berkeley , Berkele y , California, USA. a ve stime@eecs.berk ele y .edu Suhas N. Digga vi School of Comput er and Communication Sciences, EPFL, Lausanne, Switzerland. suhas.dig ga vi@epfl.ch David N C. Tse W ireless Foundations UC Berkeley , Berkele y , California, USA. dtse@eecs.be rkele y .edu Abstract W e present an achiev able rate for gen eral Ga ussian relay networks. W e show that the a chiev able rate is within a constant number of bits f rom the infor mation-the oretic cut-set up per b ound on the c apacity o f these networks. This constant depen ds on the topology of the network, but not the values of the c hannel gains. Therefore, we unifor mly ch aracterize the cap acity of Gau ssian relay n etworks with in a constant n umber of bits, for all channel parameters. I . I N T R O D U C T I O N Characterizing the capacity of w ireless relay networks has been a challenging prob lem over the past couple of decades. Although, m any comm unication schemes have been dev eloped [6]-[10], the capacity of e ven the simp lest Gauss ian relay network: si ngle source, s ingle desti nation, s ingle relay , is still unknown. In g eneral, the only known upper bound on the capacity of Gaussian relay networks is the informati on theoretic cut-set upper bound which is not achiev ed by any of those schemes, not ev en for a fixed re alization of t he channel gai ns. Furthermore, in a general network with a wide range of channel parameters, the gap between those achiev able rates and the cut-s et upper bound is unclear . As a result, we do not e ven have a g ood approxi mation of the capacity with an explicit guarantee. In this paper we introduce a si mple coding strategy for general Gauss ian relay networks. In this s cheme each relay first quantizes the recei ved signal at the noise le vel, then randomly maps it to a Gaussian code word and transmits it. W e show that we can achie ve a rate that is guranteed to be within a constant gap from t he cutset bo und. This cons tant depends on the topological parameters of the network (number of nodes in th e network), but not on the values o f the channel gains . Therefore, we get a u niformly good approxi mation of the capacity of Gaussian relay networks, u niform over all values of the channel gains, thus particularly g ood approx at high SNR . The presented schem e has close connectio ns to the random codin g scheme introd uced in [2] t o achieve t he capacity of wireline networks. It has also some connections with t he compress, hash, and forward protocol described i n [8], except here the destination is no t required to decode t he quantized signals at the relays. The ideas for the main approximati on result were inspired by the insight obtain ed by analyzing deterministic relay networks (see [5]). The det erministic approach was m otiv ated by the d e velopment of th e linear d eterministic model (see [3], [4]), which was seen to capture th e key features of wi reless channels. W e developed some of the connections between the l inear det erministic relay network and the Gaussian relay network in [4]. I I . P RO B L E M S TA T E M E N T A N D M A I N R E S U LT S Consider a network represented by a directed relay n etwork G = ( V , E ) w here V is the set of vertices representing the comm unication nodes in the relay network, and E is the set of edges between nodes. The communication problem considered is unicast. Therefore a special node S ∈ V is considered the source of the message and a s pecial node D ∈ V is the i ntended destinati on. All o ther nodes in the network facilitate communi cation between S and D . The receiv ed signal y j at node j ∈ V and tim e t is giv en by y [ t ] j = X i ∈N j h ij x [ t ] i + z [ t ] j (1) where each h ij is a com plex n umber representing the channel gain from node i to node j , and N j is the set of nodes th at are neighbors of j in G . Furth ermore, we assume there i s an ave rage power cons traint equal to 1 at each transmit ter . Als o z j , representing the channel noise, is m odeled as as complex normal (Gaussian) random variable z j ∼ C N (0 , 1) (2) For any relay network, there is a natural information-theoretic cut-set bound [11], which upperbounds the reliable transmiss ion rate R : R < C = max p ( { x j } j ∈V ) min Ω ∈ Λ D I ( Y Ω c ; X Ω | X Ω c ) (3) where Λ D = { Ω : S ∈ Ω , D ∈ Ω c } is all source-destination cut s (partiti ons). The following is our m ain result Theor em 2.1: Given a Gaussi an relay network, G = ( V , E ) , we can achieve all rates R up to C − κ . Therefore the capacity of t his network satisfies C − κ ≤ C ≤ C (4) Where C is the cut-set upper bound on the capacity of G as described in equation (3), and κ is a con stant and is upper bounded b y 5 | V | , where | V | is the to tal num ber of nodes in G . The gap ( κ ) h olds for all v alues of the channel gains and is relev ant particularly when the SNR is high and the capacity is large. While it is possib le to improve κ further , in th is paper we focus to prove such a constant, depending only on the topol ogy of G but not the channel parameters, exists in general. This constant gap resul t is a far stronger result than the degree of freedom result, no t only because i t is non-asymptoti c but also because it is uni form in the many channel SNR’ s. This is also the first constant gap approximati on of th e capacity of Gaussian relay networks. A s we will discuss in the next section, the gap between the achie vable rate of ot her well kn own relaying s chemes and the cut-set upper bound in general depends on the channel parameters and can becom e arbit rarily large. A. Examples In this section we use a fe w examples to show that th e gap between the achie vable rate of other relaying schemes and the cut-set upper bound depends on th e channel parameters and can become arbitrarily large. In p articular we focus on three well k nown st rategies: amplify-forward, decode-forward, and compress- forward. 1) Ampl ify-forwar d strate gy: Consider the diamond network with real channel gai ns shown in figure 1(a). As sume a is a l ar ge real number . The cut-set upper bound is approximately , C ≈ 5 log a (5) Now consi der an amplify-forward strategy in which no des A 1 and A 2 amplify the receiv ed signal by α 1 and α 2 and forwa rd them to the des tination. Then assumin g that x was transmitted at the source, t he recei ved signal at the destinatio n will be y D = a 3 α 1 a 5 x + z A 1 + a 5 α 2 a 2 x + z A 2 + z D (6) where z A 1 , z A 2 and z D are Gaussian noises with va riance 1 and x is the transm itted sign al with ave rage power constraint equal to 1. T o satisfy the avera ge transmit po wer constraint at A 1 and A 2 , for lar ge values of a we should have α 1 ≤ 1 a 5 , α 2 ≤ 1 a 2 (7) Now since (6) i s just li ke a point t o point channel from S to D , the achie vable rate of ampli fy-forward strategy will approximately be R AF = 1 2 log a 16 α 2 1 + a 14 α 2 2 a 6 α 2 1 + a 10 α 2 2 + 1 (8) ≤ 1 2 log 2 max { a 16 α 2 1 , a 14 α 2 2 } max { a 6 α 2 1 , a 10 α 2 2 , 1 } (9) ≤ 1 2 (1 + 6 log a ) (10) Now by comparing (10) and (5) we note that as a in creases the gap between the achiev able rate of amplify-forward strategy and the cut-set upper bound increa ses. No w by t heorem 3.7 in section III-C, which is a special case of our main theorem 2.1 for multi-stage networks, the achiev able rate of the relaying strategy propo sed in t his paper is wi thin 1 2 12 = 6 bi ts of t he cut-set upper bound of this network for al l channel parameters 1 . D S a 3 a 5 a 5 a 2 A 1 A 2 (a) S D a 2 a 2 A 1 A 2 B 1 B 2 a 5 a 3 a a 2 a 3 a 5 (b) S D a a 2 A 1 A 2 B 1 B 2 a 5 a a 3 a 5 a 2 a 2 (c) Fig. 1. Diamond network is shown in (a). A two layer network i s sho wn in (b). The effecti ve network for compress-forw ard strat egy is sho wn in (c). 2) Decode-forwar d strate gy: Consider the same example as shown i n figure 1(a). Now it is easy to show that th e achiev able rate of the decode-forward s trategy i s upper bounded by R D F ≤ 3 log a (11) Therefore, as a gets lar ger , the gap between th e achiev able rate of decode-forward st rategy and the cut-set upper bound (5) increases. 1 factor of 1 2 comes from the f act that here we are dealing with channels with real v alued gains 3) Compr ess-forwar d s trate gy: Consider the example shown in figure 1(b). For lar ge values of a , cut-set upper bound on the capacity of this relay network is approximately C ≈ 5 log a (12) Now consider the compress-forward strategy as described in [10] section V . The achie vable rate of this s cheme i s characterized in Theorem 3 ([10] page 9), which is in the form of a mutu al informati on maximization o ver auxili ary random variables U T and ˆ Y T . Eve n though thi s is written in single-letter form, sin ce there is no cardinality boun ds, the rate opt imization is still an infinite dim ensional optimizatio n problem. Howe ver , t o simpl ify this problem further , assume that auxiliary random variables U T are set to zero, and ˆ Y T are restricted to ha ve a Gauss ian dis tribution, whi ch leads to a finite dimensional prob lem. The s cheme i s such that the W yner − Ziv source-coding region of each layer m ust i ntersect t he channel - coding region of the next layer . As a result by look ing at layer { B 1 , B 2 } we note that node B 1 should compress its recei ved sign al to a Gaussian random v ariable with v ariance a 2 . In another words, just quantize the recei ved si gnal wit h distortion a . Therefore the effe ctiv e network will lo ok like the one shown in figure 1 (c). Note that now the cut-set upper boun d of this network is approxi mately , C ′ ≈ 4 log a . As a result, with this compress-forward scheme, it is n ot po ssible to get a rate m ore than 4 log a . As a increases the gap between the achiev able rate of comp ress-forward strategy and the cut-set upper bound increases. No w by Theorem 3.7 in section III-C, which is a special case of our main Theorem 2.1 for m ulti-stage networks, the achiev able rate of the relaying strategy proposed i n this paper is within 1 2 × 18 = 9 bits of the cut-set upper bound of thi s network for all channel parameters. B. Pr oof S trate gy Theorem 2.1 is th e main result of t he paper and t he rest of the paper is dev oted to sketch it s proof. For details of the proof, the reader is referred to [1]. First we focus on networks that have a layered structu re, i.e. all paths from the sou rce to the destination have equal l engths. W it h t his special structure we get a major si mplification: a sequence of m essages can each be encoded i nto a block of symbol s and the blocks do not interact with each other as t hey pass throu gh t he relay nodes in t he network. The proo f of the result for layered net work i s done in sectio n III. Second, we extend the result to an arbitrary network by considering its time-expanded representatio n. This is done in section IV 2 . The time-expanded n etwork i s layered and we can apply our result in the first step t o it. T o com plete the proof of the result, we need to establ ish a connection between th e cut values of the tim e-expanded network and those of the original network. W e do this usin g sub-m odularity properties of entropy function. I I I . L A Y E R E D N E T W O R K S In this sectio n we prove main theorem 2 .1 for a special case of layered networks, where all paths from the source to the destinati on in G ha ve equal length . In a layered network, for each node j we hav e a length l j from the source and all the incoming si gnals to node j are from n odes i whose distance from the source are l i = l j − 1 . Therefore, as in the example network of Figu re 2, we see that th ere is message synchronization, i .e., all signals arriving at node j are encoding the sam e sub-message. Suppose message w k is sent by the so urce in block k , then since each relay j operates only on block of lengths T , the signals receiv ed at blo ck k at any relay pertain to on ly message w k − l j where l j is the path length from s ource to relay j . T o explicitly indicate this w e denot e by y ( k ) j ( w k − l j ) as th e received signal at block k at node j . W e also deno te t he transmitted signal at block k as x ( k ) j ( w k − 1 − l j ) . 2 The concept of time-expand ed representation is also used in [2], but the use there is to handle cycles. Our main use is to handle interaction between m essages transm itted at different times, an issue that only arises when there is interferen ce at nodes. A. Encoding W e ha ve a single source S wi th m essage W ∈ { 1 , 2 , . . . , 2 RT } which is encoded by the source S in to a s ignal over T transm ission ti mes (sym bols), giving an ove rall transm ission rate of R . Each relay operates ov er blocks of tim e T symbols. In p articular block k of T receiv ed symbols at node i is denoted by y ( k ) i = { y [( k − 1) T +1] i , . . . , y [ k T ] i } and t he transmit symbo ls by x ( k ) i . Now th e achie vability st rategy is the foll owing: each recei ved sequence y ( k ) i at no de i is qu antized into ˆ y ( k ) i which is then randomly m apped i nto a Gaussian codew ord x ( k ) i using a random (binni ng) functi on f i ( ˆ y ( k ) i ) . For quantization, we use a Gauss ian vector quantizer . Since we have a layered n etwork, w ithout los s of generality consider the message w = w 1 transmitted by the source at bl ock k = 1 . At nod e j the si gnals pertaining to th is message are receiv ed by the relays at bl ock l j . Given the knowledge of all the encodi ng function s at the relays and signals recei ved at block l D , the decoder D , attempts to decode the mess age W by finding the message that is j ointly typical with its o bservations. B. Pr oof i llustration Consider the encod ing-decoding strategy as described i n section III-A. Our go al is to show th at, using this strategy , all rates d escribed in the theorem are achie vable. Th e method we use is based on a dist inguishabi lity ar gument. This ar gument w as used in [2] in the case o f wireline networks. In [5], we used similar arguments t o characterize the capacity of a general class of linear determinis tic relay networks with broadcast and mul tiple access. The main idea behind this approach is the following: due to the deterministic nature of these channels, each message is mapped t o a determini stic sequence of transmit code words th rough the network. The desti nation can n ot distingui sh between two mess ages i f and only if i ts recei ved signal under these two messages are identical. If so, there would be a partition of nodes in the n etwork such that the n odes on one si de of the cut can disti nguish between these two m essages and the rest can not. This n aturally correspond s to a cut separating the sou rce and the destination in the network and the probability that this happens can b e related to the cut-value. This i s the main tool that we u sed in [5] to show that thecut-set upper bound can actually be achie ved. Howe ver , in t he noisy case, the dif ference from t he pre vious analyses is that each message is potentially mapped t o a set of possible t ransmit sequences. The parti cular transmit sequence chosen depends on the noise realization, which ca n be considered “typical”. P ictorially it means that there is som e fuzziness around the sequence of transmit codewords ass ociated with each message. Hence, two m essages will st ill be d istinguis hable at the destination if th e fuzzy receiv ed signal associated with t hem are not overlapping. This intuitively m eans that if we can som ehow bound this randomness, a communicate rate clo se to the cut-set bou nd is achiev able. In order to illustrate the proof ideas of Theorem (2.1) we examine the n etwork shown in Figure 2. Can distinguish 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 0 0 1 1 Can distinguish Cannot distinguish Transmits same signal under Cannot distinguish D ∈ S c A 2 ∈ S c w, w ′ S ∈ S B 2 ∈ S c B 1 ∈ S A 1 ∈ S Fig. 2. An e xample of a layered Gaussian relay netowrk . Assume a message w is t ransmitted by t he sou rce. Once the destinati on recei ves y D , qu antizes it t o get ˆ y D . Then, it will decode the message by finding the u nique message t hat is joi ntly typical wit h ˆ y D (the precise definition o f typicality will be gi ven later). An error occurs if eit her w is not jointly typical with ˆ y D or there is another message w ′ such that ˆ y D is jo intly typ ical with both w , w ′ . Now for the relay network, a natural way to define whether a m essage w is typical with a recei ved sequence is whether we have a “plausible” transmit sequence 3 under w which is jointly t ypical wit h the recei ved sequence. More formall y , we hav e t he following definitions . Definition 3.1 : For a m essage w , we define the set of receiv ed sequences that are typical with the message as, Y i ( w ) = { ˆ y i : ( ˆ y i , w ) ∈ T δ } , (13) where we still need t o define what we mean by ( ˆ y i , w ) ∈ T δ . Definition 3.2 : For a message w , we define th e set of transmitt ed sequences that are typical w ith the message as, X i ( w ) = { x i : x i = f i ( ˆ y i ) , ˆ y i ∈ Y i ( w ) } , (14) which defines the “typical” transmit set associated wit h a message w . Note here that since x i = f i ( ˆ y i ) , then natu rally ( x i , ˆ y i ) ∈ T δ . This leads us t o the following definition, Definition 3.3 : W e define ( ˆ y i , w ) ∈ T δ if ( ˆ y i , { x j } j ∈ I n ( i ) ) ∈ T δ for s ome x j ∈ X j ( w ) , ∀ j ∈ I n ( i ) (15) where I n ( i ) is defined as the set of nodes wit h sig nals inci dent on node i . Therefore by thi s definition , if a m essage w is t ypical with a receiv ed sequence, we ha ve a sequ ence of ty pical transmit sequences in th e network that are jo intly t ypical with the w and the recei ved s equence at the destination . Now n ote the following important observ at ion, Observation: Note that if n ode i cannot dis tinguish between two messages w , w ′ , th is means that the signal recei ved at node i , ˆ y i is su ch t hat ( ˆ y i , w ) ∈ T δ and ( ˆ y i , w ′ ) ∈ T δ . Therefore we see that ˆ y i ∈ Y i ( w ) ∩ Y i ( w ′ ) . (16) Due to the mapping x i = f i ( ˆ y i ) , we therefore see that x i ∈ X i ( w ) ∩ X i ( w ′ ) . Therefore, there exists a sequence u nder w ′ which is the same as that transmitted under w and could therefore have been po tentially transmitted un der w ′ . Now , assum ing a message w is transmit ted by the source, an error occurs at the desti nation i f eith er w is not jointly typical with ˆ y D , or there is another message w ′ such that ˆ y D is jointly typical with both w , w ′ . By the l aw of large numbers, the probability of the first event becomes arbitrarily sm all as communication block length, T , goes t o i nfinity . So we just n eed to analyze the probabi lity o f the second e vent. T o do so, we ev aluate the probabili ty that ˆ y D is jointly t ypical with both w and w ′ , w here w ′ is another message independent of w . Then we use un ion boun d over all w ′ ’ s to bound the probability o f the second ev ent. Based on o ur earlier ob serv ation, if ˆ y D is jo intly typical with w , w ′ , then there must be a typical transm it sequence x ′ V = ( x ′ S , x ′ A 1 , x ′ A 2 , x ′ B 1 , x ′ B 2 ) under w ′ such that, ( ˆ Y D , x ′ B 1 , x ′ B 2 ) ∈ T δ . This means t hat the destination thinks this is a plaus ible sequence. Now for any such sequence there is a natu ral cut, Ω , in G such that the n odes on the righ t hand side of th e cut ( i.e. in Ω ) can tell x ′ V is not a pl ausible sequence, and tho se on the left hand side of th e cut ( i.e. in Ω c ) can not. Clearly this cut is a source-destination partition. 3 Plausibility essentially means that the transmit sequence is a member of the typ ical set of possible transmit sequen ces under w . For now , assu me that the cut is Ω = { S, A 1 , B 1 } , as shown in figure 2. Since A 2 , B 2 and D think x ′ V is a plausible sequence, we hav e ( ˆ Y A 2 , x ′ S ) ∈ T δ (17) ( ˆ Y B 2 , x ′ A 1 , x ′ A 2 ) ∈ T δ (18) ( ˆ Y D , x ′ B 1 , x ′ B 2 ) ∈ T δ (19) For any such sequence x ′ V , since w is independent of w ′ , we have P n ( ˆ Y A 2 , x ′ S ) ∈ T δ o ≤ 2 − T I ( X S ; Y A 2 ) (20) Now , for the layer ( A 1 , A 2 ) , we condit ion on a particular sequence x A 2 to ha ve been transmitted by A 2 . If x ′ A 2 = x A 2 , since x ′ A 1 is chos en i ndependent o f x A 1 we h a ve, P n ( ˆ Y B 2 , x ′ A 1 , x ′ A 2 ) ∈ T δ o ≤ 2 − T I ( ˆ Y B 2 ; X A 1 | X A 2 ) , (21) and similarly If x ′ A 2 6 = x A 2 , since x ′ A 1 , x ′ A 2 are chosen independent of x A 1 , x A 2 we h a ve, P n ( ˆ Y B 2 , x ′ A 1 , x ′ A 2 ) ∈ T δ o ≤ 2 − T I ( ˆ Y B 2 ; X A 1 ,X A 2 ) (22) ≤ 2 − T I ( ˆ Y B 2 ; X A 1 | X A 2 ) (23) Therefore in any case, P n ( ˆ Y B 2 , x ′ A 1 , x ′ A 2 ) ∈ T δ o ≤ 2 − T I ( ˆ Y B 2 ; X A 1 | X A 2 ) , (24) Similarly we can show that, P n ( ˆ Y D , x ′ B 1 , x ′ B 2 ) ∈ T δ o ≤ 2 − T I ( ˆ Y D ; X B 1 | X B 2 ) , (25) Therefore for any typ ical sequence x ′ V , the probabi lity that (17)-(19) are satisfied is upper bounded by 2 − T I ( X S ; Y A 2 ) × 2 − T I ( ˆ Y B 2 ; X A 1 | X A 2 ) × 2 − T I ( ˆ Y D ; X B 1 | X B 2 ) = 2 − T I ( X Ω ; ˆ Y Ω c | X Ω c ) (26) Now , by us ing the un ion boun d over all possible x ′ V ’ s and cut s, the probability of confusing w with w ′ can b e bo unded by P { w → w ′ } ≤ |X V ( w ′ ) | X Ω 2 − T I ( X Ω ; ˆ Y Ω c | X Ω c ) (27) In the next section, we make these arguments precise, and by boun ding |X V ( w ′ ) | we pro ve our main theorem 2.1 for networks with a layered structure. C. Pr oof for layer ed n etworks In this section we extend the idea from section III-B and analyze a l D -layer net work, G . Based on the proof st rategy illustrated in section III-B, we proceed with the error probabili ty analysis of our schem e that was described in section III-A. As sume message w is being transm itted. T o b ound the probability of error , we just need to analyze the probability that ˆ y D is jointly typi cal wit h both w , w ′ , for a m essage w ′ independent of w . W e d enote this ev ent by w → w ′ . If ˆ y D is jointl y typical wit h w ′ , then t here m ust be a typical transmit sequence x ′ V ∈ X V ( w ′ ) under w ′ such that ( ˆ Y D , x ′ γ l D − 1 ) ∈ T δ , where γ l D − 1 is th e set of nodes at layer l D − 1 of the network. This means that the destinati on thinks this is a pl ausible sequence. T herefore, t here is a natural source-destinati oncut, Ω , in G such that the nodes on the rig ht hand side of the cut ( i.e. in Ω ) can tell x ′ V is not a plausible sequence, and those on the left hand side of the cut ( i.e. in Ω c ) can not. Note that due t o the layered structure o f the network, for any s uch cut, Ω , we can create d = l D disjoint sub -networks of nodes corresponding to each layer of the network, with β l − 1 (Ω) nodes at distance l − 1 from S that are in Ω , on one side and β l (Ω c ) nodes at dist ance l from S that are in Ω c , on the other , for l = 1 , . . . , l D . Hence, by definiti on we hav e ( ˆ Y β l (Ω c ) , x ′ β l − 1 (Ω) , x ′ β l − 1 (Ω c ) ) ∈ T δ , l = 1 , . . . , l D (28) Therefore, si milar to the pairwise error analysis don e i n section III-B, w e can show P { w → w ′ } ≤ |X V ( w ′ ) | X Ω 2 − T I ( X Ω ; ˆ Y Ω c | X Ω c ) (29) As the last ingredient of the proo f, we state the foll owing lem ma which is prov ed in the appendix. Lemma 3 .4: Consider a layered Gaussian relay n etwork, G , then, |X V ( w ′ ) | ≤ 2 T κ 1 (30) where κ 1 = |V | is a constant depending on the total n umber of nodes in G . B S A D (a) D S ∞ S [1] A [1] B [1] D [1] S [2] A [2] B [2] D [2] S [3] A [3] B [3] D [3] D [ k − 1] B [ k − 1] A [ k − 1] S [ k ] A [ k ] B [ k ] D [ k ] ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ ∞ T [1] T [2] T [3] T [ k ] R [1] R [2] R [3] R [ k − 1] R [ k ] T [ k − 2] S [ k − 2] A [ k − 2] B [ k − 2] D [ k − 2] R [ k − 2] T [ k − 1] S [ k − 1] ∞ (b) Fig. 3. An examp le o f a general Gaussian network with un equal paths from S t o D is shown in ( a ) . The corresponding u nfolded network is sh o wn in ( b ) . An example of steady cuts and w iggling c uts a re respecti vely sho wn in ( b ) by solid and dotted lines. Therefore, by (29) and lemm a 3.4, we ha ve t he follo wing, Lemma 3 .5: Given a Gauss ian relay network G with a layered structure, all rates R satisfying the following condition are achiev able, R < min Ω ∈ Λ D I ( ˆ Y Ω c ; X Ω | X Ω c ) − κ 1 (31) where X i , i ∈ V , are iid with c omplex normal (Gaussian) distribution, and κ 1 = |V | is a constant dependi ng on the total number of nodes in G . T o prove our main th eorem 2 .1 for layered networks, we s tate t he fol lowing lemma whi ch i s p roved in th e append ix, Lemma 3 .6: Given a Gaussian relay network G , then C − min Ω ∈ Λ D I ( ˆ Y Ω c ; X Ω | X Ω c ) < κ 2 (32) where X i , i ∈ V , are iid wi th compl ex n ormal (Gaussi an) distribution, C is the cut-set upper bound on the capacity of G as described in equati on (3), and κ 2 = 2 |V | . Now b y lemm a 3.5 and l emma 3.6, we ha ve the following m ain result Theor em 3.7: Given a Gaussian relay network G with a layered s tructure, all rates R satisfying the following condition are achiev able, R < C − κ Lay (33) where C is the cut-set upper boun d on the capacity of G as described in equati on (3), and κ Lay = κ 1 + κ 2 = 3 |V | is a constant depend ing on the total num ber of nodes in G (denoted by |V | ). I V . P R O O F F O R G E N E R A L N E T W O R K S Giv en the p roof for layered networks with equal path lengt hs, we are ready to tackle the proof of Theorem 2.1 for general Gauss ian relay networks. The ingredient s are de veloped below . First is that any Gaussian network can be unfolded over time to create a l ayered Gaussian network (thi s idea was int roduced for graphs in [2] to handle cycles in a graph). The idea is to unfold the network to K stages such that i-th stage is representing what happens in the network durin g ( i − 1) T to iT − 1 symb ol times. For example in figure 3(a) a network with u nequal paths from S to D is shown. Figure 3 (b) shows the unfolded form of thi s network. As we notice each nod e V ∈ V is appearing at stage 1 ≤ i ≤ K as V [ i ] . No w we state the follo wing lemma which is a corollary of Theorem 3.7 Lemma 4 .1: Given a Gauss ian relay network, G , all rates R satisfying the following condition are achie vable, R < 1 K min Ω unf ∈ Λ D I ( Y Ω c unf ; X Ω unf | X Ω c unf ) − κ 1 (34) where G ( K ) unf is the time expanded graph ass ociated with G , random v ariables { X i [ t ] } 1 ≤ t ≤ K , i ∈ V are iid with com plex normal (Gaussian) dist ribution, and κ 1 = 3 |V | . Pr oof: By unfolding G we get an ac ycli c network such t hat all the p aths from the source to the destination hav e equal length. Therefore, by theorem 3.7, all rates R unf , s atisfying the following condi tion are achie vable in the tim e-expanded graph R unf < min Ω unf ∈ Λ D I ( Y Ω c unf ; X Ω unf | X Ω c unf ) − κ unf (35) where { X i [ t ] } 1 ≤ t ≤ K , i ∈ V are iid with compl ex normal (Gaussian) distribution, and κ unf = K |V | log 4 η . Since it takes K steps to translate and achiev able scheme in the time-expanded graph to an achiev able scheme in the original graph, and κ 1 = 1 K κ unf = |V | log 4 η , then t he L emma is proved. Note that the general achiev ability scheme that we use here is si milar to the one described in s ection III-A for layered networks, except now the message W ∈ { 1 , 2 , . . . , 2 K RT } is encoded by the source S into a signal over K T transmission times (symbols). Still , each relay operates ov er b locks of tim e T symbols. In p articular each receive d sequence y ( k ) i at node i is quantized into ˆ y ( k ) i which is t hen randoml y mapped into a Gaussian code word x ( k ) i using a random (binning) fun ction f i ( ˆ y ( k ) i ) . Given the knowledge of all the encodi ng functi ons at the relays and si gnals receiv ed over K + | V | − 2 blocks, the decoder D, attempts to decode the message W sent by the s ource. If w e look at diffe rent cuts in the time-e xpanded graph we notice t hat there are two t ypes of cuts. One ty pe separates t he nodes at different s tages identically . An example of such a steady cut is drawn with soli d li ne in figure 3 (b). Howe ver there is anoth er type of cut which d oes not behave i dentically at diffe rent stages. An example of such a wiggli ng cut is drawn with dot ted line in figure 3 (b). There is no correspondence b etween t hese cuts and the cuts in the original network. Now comparing Lemma 4.1 to the main Theorem 2.1 we want to prove, we notice that in thi s lemm a the achiev able rate is found by taking the mi nimum of cut-values o ver all cuts in the time-expanded graph (s teady and wiggli ng ones as s hown in figure 3). Howe ver in t heorem 2 .1 we want t o p rove that we can achiev e a rate by taking the minim um of cut-values over on ly the cuts in the original graph or similarly over the steady cuts in the t ime-expanded network. In the fol lowing l emma, which is proved in the appendix, we show that asympt otically as K → ∞ this dif ference (normalized by 1 /K ) vanishes. Lemma 4 .2: Consider a Gauss ian relay network, G . Then for any cut Ω unf on the unfolded graph we hav e, ( K − L + 1) min Ω ∈ Λ D I ( Y Ω c ; X Ω | X Ω c ) ≤ I ( Y Ω c unf ; X Ω unf | X Ω c unf ) (36) where L = 2 |V |− 2 , X i ∈V are iid with compl ex normal (Gaussian) dis tribution, and { X i [ t ] } 1 ≤ t ≤ K , i ∈ V are also ii d wit h compl ex normal (Gauss ian) dist ribution. Hence, by lemma 4.1 and lemma 4.2 we ha ve the following l emma, Lemma 4 .3: Given a Gaussian relay network G , all rates R satisfyi ng the following condi tion are achie vable, R < min Ω ∈ Λ D I ( Y Ω c ; X Ω | X Ω c ) − κ 1 (37) where X i , i ∈ V , are i .i.d. wi th com plex normal (Gaussi an) di stribution, and κ 1 = 3 |V | . Now b y lemma 3.6 we know that, C − min Ω ∈ Λ D I ( Y Ω c ; X Ω | X Ω c ) ≤ C − min Ω ∈ Λ D I ( ˆ Y Ω c ; X Ω | X Ω c ) ≤ 2 |V | (38) where X i , i ∈ V , are i id wit h comp lex no rmal (Gaussi an) di stribution. Therefore, by lemma 4.3 and inequali ty (38) all rates u p to C − |V | (3 + 2) = C − 5 | V | are achieved and the proof of ou r m ain th eorem 2.1 is complete. Acknowledgeme nts : The research of D. Tse and A. A v estimehr are support ed by t he Nati onal Science Foundation through grant CCR-01-18784 and the ITR grant: ”The 3R’ s of Spectrum Management:Reuse, Reduce and R ecycle. ”. The researc h of S. Digga v i i s sup ported i n part b y the Swis s National Science Foundation NCCR-MICS center . R E F E R E N C E S [1] A. S. A ve stimehr , S . N. Diggavi and D. N. C. Tse, “Information Flow Over W ireless Networks: A Deterministic Approach”, t o be submitted. [2] R. Ahlswede, N. Cai, S.-Y . R. Li, and R. W . Y eung, “Network information flo w , ” IEEE T ransactions on Informnation Theory ” , vol. 46, no . 4, pp. 1204 –1216, July , 2 000. [3] A. S . A vestimehr , S. N. Diggavi and D. N. C. Tse, “ A Deterministic Model for W ireless Relay Networks and its Capacity”, IEEE Information The ory W orkshop (ITW) , Bergen, Norway , pp 6–11, July 2007. [4] A. S. A vestimehr , S. N. Diggavi and D. N. C. Tse, “ A Deterministic Approach to Wireless Relay Netwo rks”, Proc eedings o f All erton Confer ence on Commun ication, Contr ol, an d Compu ting , Illinois, S eptember 2 007. [5] A. S . A v estimehr , S. N. Diggavi and D. N. C . Tse, “Wireless Network Information Fl o w”, Pr oceedings of Allerton C onfer ence on Communication, Contr ol, and Computing , Illinois, September 200 7. [6] T . M. Cov er and A. A. E. Gamal, “Capacity Theorems for the Relay Channel”, IEEE Trans. Info. Theory , vol. 2 5, n o. 5, Sept. 1979, pp. 57 284. [7] Brett E. Schein, “Distributed co ordination in network information theory”, Ph.D. dissertation, Massachuse tts Institute of T echnology , Cambridge, M A, 20 01. [8] Thomas M. Cov er and Y oung-Han Kim, “Capacity of a Class o f Deterministic Relay Channels”, arXiv:cs/06110 53 v1 [cs.IT ]. [9] M. R. Aref, “Informa tion Flo w in R elay Netw orks”, Ph.D. dissertation, Stanford Univ ., Stanford, CA, 1980. [10] G. Kramer , M. Gastpar, and P . Gupta, “Coope rativ e strategies and capacity theorems for relay networks”, IEEE T ransactions on Information The ory , 51(9 ):3037-3063 , September 2005. [11] T . M. Co ver an d J. A. Thomas, Elements of Infor mation Theory , New Y ork: W il ey , 199 1. [12] R . W . Y eung, A first co urse in information theory , Kluwer Acad emic/Plenum Publishers, 2002. [13] L .-L. Xi e and P . R. Kumar , ‘ An achie v able rate for the multiple-le vel relay channel”, IEEE T rans. Inf. Theory , vol. 51, no. 4, pp. 1348 − 135 8, A P P E N D I X I P R O O F O F B E A M - F O R M I N G L E M M A W e k now that the capa city of a r × t MI MO chann el H , with water filling is C wf = n X i =1 log(1 + ˜ Q ii λ i ) (39) where n = mi n ( r , t ) , and λ i ’ s ar e the sing ular values of H and ˜ Q ii is given by water filling solutio n satisfying n X i =1 ˜ Q ii = nP (40) W ith eq ual power allocation C ep = n X i =1 log(1 + P λ i ) (41) Now note that C wf − C ep = log Q n i =1 (1 + ˜ Q ii λ i ) Q n i =1 (1 + P λ i ) ! (42) ≤ log Q n i =1 (1 + ˜ Q ii λ i ) Q n i =1 max(1 , P λ i ) ! (43) = log n Y i =1 1 + ˜ Q ii λ i max(1 , P λ i ) ! (44) = log n Y i =1 1 max(1 , P λ i ) + ˜ Q ii λ i max(1 , P λ i ) !! (45) ≤ log n Y i =1 1 + ˜ Q ii λ i P λ i !! (46) = log n Y i =1 1 + ˜ Q ii P !! (47) Now note that n X i =1 (1 + ˜ Q ii P ) = 2 n (48) and there fore by arithm etic mean-geom etric mean inequality we h av e n Y i =1 1 + ˜ Q ii P ! ≤ P n i =1 (1 + ˜ Q ii P ) n ! n = 2 n (49) and hen ce C ep − C wf ≤ n (50) Hence, C ≤ min Ω ∈ Λ D I ( Y Ω c ; X Ω | X Ω c ) + |V | (51) where X i , i ∈ V , are restricted to be iid with co mplex normal (Gaussian) distribution. Next no te that ˆ Y is obtain ed b y quantizin g Y at the no ise lev el. The effect o f quantizatio n noise c an be comp ensated b y adding a factor of two mo re power at each transm itter . Therefo re, for each cut Ω we have I ( Y Ω c ; X Ω | X Ω c ) ≤ I ( ˆ Y Ω c ; X Ω | X Ω c ) + |V | log 2 (52) where X i , i ∈ V , are r estricted to be iid with c omplex n ormal (Gau ssian) distribution. Now by (51) and (52), the lemma is proved. A P P E N D I X I I P R O O F O F L E M M A 3 . 4 Assume message w ′ is transmitted. C onsider a relay , R , at the first layer . Then, the total numb er o f quantized o utputs at R would be 2 H ( ˆ Y R | X S ) = 2 T I ( Y R ; ˆ Y R | X S ) (53) Since we ar e using an optimal Gau ssian vector quan tizer at the noise level (i.e. with distor tion 1), we can wr ite ˆ Y R = αY R + N , (54) where N ∼ C N (0 , σ 2 N ) is a com plex Gaussian noise ind ependen t of Y R and α = σ 2 Y − 1 σ 2 Y , σ 2 N = (1 − α 2 ) σ 2 Y − 1 (55) Hence I ( Y R ; ˆ Y R | X S ) = log 1 + α 2 σ 2 N (56) = log(1 + α ) ≤ 1 (57) Hence the list size o f R would be smaller than 2 T . Now the list o f typical transm it sequ ences ca n be viewed as a tr ee such that at e ach node, due to the n oise, each path will be bran ched to at most 2 T other typic al p ossibilities. There fore, the to tal number of ty pical tran smit sequences would be smaller than the prod uct of the expansion co efficient ( i.e. 2 T ) over all no des in the g raph. Or, more precisely log ( |X V ( w ′ ) | ) = log ( |Y V ( w ′ ) | ) (58) = H ( ˆ Y V | w ′ ) = l D X l =1 H ( ˆ Y γ l | ˆ Y γ l − 1 ) (59) = l D X l =1 H ( ˆ Y γ l | X γ l − 1 ) (60) ≤ l D X l =1 T | γ l | = T |V | (61) Where γ l is the set of no des at the l -th layer of the n etwork. Hence, |X V ( w ′ ) | ≤ 2 T |V | (62) and the p roof is complete. A P P E N D I X I I I P R O O F O F L E M M A 4 . 2 First, we prove a lemma wh ich is a slight g eneralization of lem ma 6.4 in [5], Lemma 3.1: Let V 1 , . . . , V l be l n on iden tical sub sets of V − { S } such that D ∈ V i for all 1 ≤ i ≤ l . Also assume a produ ct distrib ution on co ntinuou s ra ndom variables X i , i ∈ V . T hen h ( Y V 2 | X V 1 ) + · · · + h ( Y V l | X V l − 1 ) + h ( Y V 1 | X V l ) ≥ l X i =1 H ( Y ˜ V i | X ˜ V i ) (63) where for k = 1 , . . . , l , ˜ V k = [ { i 1 ,...,i k }⊆{ 1 ,...,l } ( V i 1 ∩ · · · ∩ V i k ) (64) or in another words each ˜ V j is the union of l j sets such that each set is intersect of j of V i ’ s. Pr oof: First note th at h ( Y V 2 | X V 1 ) + · · · + h ( Y V l | X V l − 1 ) + h ( Y V 1 | X V l ) = h ( Y V 2 , X V 1 ) + · · · + h ( Y V l , X V l − 1 ) + h ( Y V 1 , X V l ) − l X i =1 h ( X V i ) and l X i =1 h ( Y ˜ V i | X ˜ V i ) = l X i =1 h ( Y ˜ V i , X ˜ V i ) − l X i =1 h ( X ˜ V i ) (65) Now define the set W i = { Y V i , X V i − 1 } , i = 1 , . . . , l (66) where V 0 = V l . It is ea sy to show that, l X i =1 h ( X V i ) = l X i =1 h ( X ˜ V i ) (67) Therefo re, we just need to prove that l X i =1 h ( W i ) ≥ l X i =1 h ( Y ˜ V i , X ˜ V i ) (68) Now , since the d ifferential en tropy function is a submo dular function we h av e, l X i =1 h ( W i ) ≥ l X i =1 h ( ˜ W i ) (69) where ˜ W r = [ { i 1 ,...,i r }⊆{ 1 ,...,l } ( W i 1 ∩ · · · ∩ W i r ) , r = 1 , . . . , l (70) Now for any r ( 1 ≤ r ≤ l ) we h av e ˜ W r = [ { i 1 ,...,i r }⊆{ 1 ,...,l } ( W i 1 ∩ · · · ∩ W i r ) = [ { i 1 ,...,i r }⊆{ 1 ,...,l } ( { Y V i 1 , X V i 1 − 1 } ∩ · · · ∩ { Y V i r X V i r − 1 } ) = [ { i 1 ,...,i r }⊆{ 1 ,...,l } ( { Y V i 1 ∩···∩V i r , X V ( i 1 − 1) ∩···∩ X V ( i r − 1) } ) = n Y S { i 1 ,...,i r } ( V i 1 ∩···∩V i r ) , X S { i 1 ,...,i r } ( V ( i 1 − 1) ∩···∩V ( i r − 1) ) o = { Y ˜ V r , X ˜ V r } Therefo re by equation (69) we have, l X i =1 h ( W i ) ≥ l X i =1 h ( ˜ W i ) (71) = l X i =1 h ( Y ˜ V i , X ˜ V i ) (72) Hence the Lem ma is proved. Now we are ready to prov e lemma 4.2. Fi rst no te that any cut in th e un folded graph, Ω unf , par titions the no des at eac h stage 1 ≤ i ≤ K to U i (on the left o f the cu t) and V i (on the right of the cut). If at one stage S [ i ] ∈ V i or D [ i ] ∈ U i then th e cut passes thro ugh one of the infinite capa city edges (cap acity K q ) and hence the lem ma is obvio usly proved. Th erefore without loss of gen erality assume that S [ i ] ∈ U i and D [ i ] ∈ V i for all 1 ≤ i ≤ K . Now since for each i ∈ V , { x i [ t ] } 1 ≤ t ≤ K are i.i.d distributed we can wr ite I ( Y Ω c unf ; X Ω unf | X Ω c unf ) = K − 1 X i =1 I ( Y V i +1 ; X U i | X V i ) (73) Consider the sequence of V i ’ s. Note that ther e are total of L = 2 |V |− 2 possible subsets of V that contain D but not S . Assume that V s is the first set that is revisited. Assume that it is revisited at step V s + l . W e hav e, s + l − 1 X i = s I ( Y V i +1 ; X U i | X V i ) = s + l − 1 X i = s h ( Y V i +1 | X V i ) − h ( Y V i +1 | X V i , X U i ) (74) Now by Lemma 3.1 we have s + l − 1 X i = s h ( Y V i +1 | X V i ) ≥ l X i =1 h ( Y ˜ V i | X ˜ V i ) (75) where ˜ V i ’ s are as described in lemm a 3.1. Next, note that h ( Y V i +1 | X V i , X U i ) is just the entro py o f chann el noises, and since for any v ∈ V we h av e |{ i | v ∈ V i }| = |{ j | v ∈ ˜ V j }| (76) , we get s + l − 1 X i = s h ( Y V i +1 | X V i , X U i ) = l X i =1 h ( Y ˜ V i | X ˜ V i , X c ˜ V i ) (77) Now by putting (7 5) and (77) tog ether, we get s + l − 1 X i = s I ( Y V i +1 ; X U i | X V i ) ≥ l X i =1 I ( Y ˜ V i ; X ˜ V c i | X ˜ V i ) (78) ≥ l min Ω ∈ Λ D I ( Y Ω c ; X Ω | X Ω c ) (79) Now since in any L − 1 time f rame there is at least on e loo p, the refore excep t at m ost a p ath of length L − 1 ev erything in P K − 1 i =1 I ( Y V i +1 ; X U i | X V i ) . can be rep laced with the value of the min-c ut. Therefor e, K − 1 X i =1 I ( Y V i +1 ; X U i | X V i ) ≥ ( K − L + 1 ) min Ω ∈ Λ D I ( Y Ω c ; X Ω | X Ω c ) (80) and hen ce the proo f is complete.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment