Mapping distributional to model-theoretic semantic spaces: a baseline
Word embeddings have been shown to be useful across state-of-the-art systems in many natural language processing tasks, ranging from question answering systems to dependency parsing. (Herbelot and Vecchi, 2015) explored word embeddings and their util…
Authors: Franck Dernoncourt
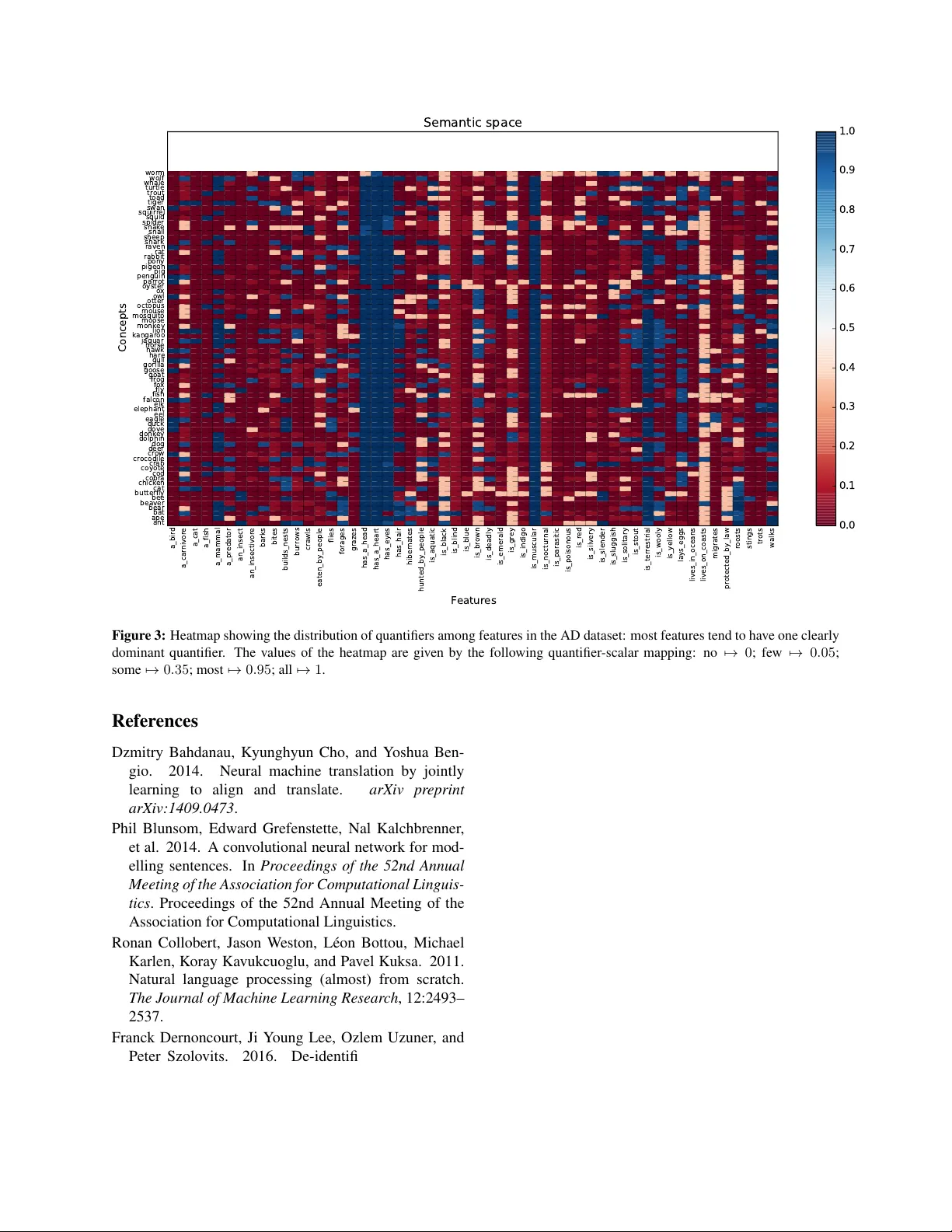
Mapping distrib utional to model-theor etic semantic spaces: a baseline Franck Dernoncourt MIT francky@mit.edu Abstract W ord embeddings hav e been sho wn to be use- ful across state-of-the-art systems in many natural language processing tasks, ranging from question answering systems to depen- dency parsing. (Herbelot and V ecchi, 2015) explored word embeddings and their utility for modeling language semantics. In particular , they presented an approach to automatically map a standard distributional semantic space onto a set-theoretic model using partial least squares re gression. W e sho w in this paper that a simple baseline achieves a +51% relati ve im- prov ement compared to their model on one of the tw o datasets they used, and yields compet- itiv e results on the second dataset. 1 Introduction W ord embeddings are one of the main components in many state-of-the-art systems for natural lan- guage processing (NLP), such as language model- ing (Mikolo v et al., 2010), text classification (Socher et al., 2013; Kim, 2014; Blunsom et al., 2014; Lee and Dernoncourt, 2016), question answering (W e- ston et al., 2015; W ang and Nyberg, 2015), machine translation (Bahdanau et al., 2014; T amura et al., 2014; Sunderme yer et al., 2014), as well as named entity recognition (Collobert et al., 2011; Dernon- court et al., 2016; Lample et al., 2016; Labeau et al., 2015). W ord embeddings can be pre-trained using large unlabeled datasets typically based on token co- occurrences (Mikolov et al., 2013; Collobert et al., 2011; Pennington et al., 2014). They can also be jointly learned with the task. Understanding what information word embed- dings contain is subsequently of high interest. (Her- belot and V ecchi, 2015) in v estigated a method to map word embeddings to formal semantics, which is the center of interest of this paper . Specifically , gi ven a feature and a word vector of a concept, they tried to automatically find ho w often the given con- cept has the gi v en feature. For e xample, the concept yam is alw ays a ve getable , the concept cat has a coat most of the time, the concept plug has sometimes 3 prongs, and the concept dog nev er has wings. The method they used was based on partial least squares re gression (PLSR). W e propose a simple baseline that outperforms their model. 2 T ask In this section, we summarize the task presented in (Herbelot and V ecchi, 2015). The follo wing is an example of a concept along with some of its fea- tures, as formatted in one of the tw o datasets used to e v aluate the model: yam a ve getable all all all yam eaten by cooking all most most yam gro ws in the ground all all all yam is edible all most all yam is orange some most most yam like a potato all all all The concept yam has six features ( a ve g etable , eaten by cooking , gr ows in the gr ound , is edible , is orang e , and like a potato ). Each feature in this dataset is annotated by three dif ferent humans. The annotation is a quantifier that reflects ho w frequently the concept has a feature. Fiv e quantifiers are used: no , few , some , most , and all . In this example, the concept yam has been annotated as some , most and most for the feature is orang e . Each of the five quantifiers is con verted into a nu- merical format with the following (someho w arbi- trary) mapping: no 7→ 0 ; fe w 7→ 0 . 05 ; some 7→ 0 . 35 ; most 7→ 0 . 95 ; all 7→ 1 . The value is av er- aged over the three annotators. Using this mapping, we can map a concept into a “model-theoretic vec- tor” (also called feature vector). If a feature has not been annotated for a concept, then the element in the model-theoretic v ector corresponding to the fea- ture will have value 0 . As a result, any element of a model-theoretic vector that has value 0 may cor- respond to a feature that has either been annotated as no by the three annotators, or not been annotated (presumed no ). Gi ven that there can be many fea- tures and it is possible that only some of them are annotated for each concept, the model-theoretic vec- tor may be quite sparse. In the yam example, if we only included fea- tures annotated with yam, the model-theoretic vector would be as follo ws: all + all + all 3 all + most + most 3 all + all + all 3 all + most + all 3 some + most + most 3 1+1+1 3 = 1+1+1 3 1+0 . 95+0 . 95 3 1+1+1 3 1+0 . 95+1 3 0 . 35+0 . 95+0 . 95 3 1+1+1 3 ≈ 1 0 . 967 1 0 . 983 0 . 75 1 The additional coordinates corresponding to all the remaining features would be zero. Each con- cept word will have a vector of the same dimension (number of unique features) in the same dataset. The coordinates mean the same from one concept to an- other . For example, the feature is vegetable ap- pears in the same coordinate position in all the vec- tors. 3 Datasets T wo datasets are used: • The Animal Dataset (AD) (Herbelot, 2013) contains 73 concepts and 54 features. All con- cepts are animals, and for each concept all features are annotated by 1 human annotator . There are 3942 annotated pairs of concept- feature ( 73 ∗ 54 = 3942 ). The dimension of the model-theoretic vectors will therefore be 54. • TheMcRae norms (QMR) (McRae et al., 2005) contains 541 concepts cov ering li ving and non- li ving entities (e.g., alligator , chair , accordion), as well as 2201 features. One concept is an- notated with 11.4 features on av erage by 3 hu- man annotators. There are 6187 annotated pairs of concept-feature ( 541 ∗ 11 . 4 ≈ 6187 ). The dimension of the model-theoretic vectors will therefore be 2201, and each model-theoretic vector will hav e on av erage 2201 − 11 . 4 = 2189 . 6 elements set to 0 due to unannotated features. 4 Model In the pre vious section, we hav e seen ho w to con vert a concept into a model-theoretic vector based on hu- man annotations. The goal of (Herbelot and V ecchi, 2015) is to analyze whether there exists a transfor- mation from the word embedding of a concept to its model-theoretic vector , the gold standard being the human annotations. The word embeddings are taken from the word embeddings pre-trained with word2v ec GoogleNe ws-vectors-ne gative300 1 (300 dimensions), which were trained on part of the Google News dataset, consisting of approximately 100 billion words. The transformation used in (Herbelot and V ecchi, 2015) is based on Partial Least Squares Regression (PLSR). The PLSR is fitted on the training set: the inputs are the word embeddings for each concept, and the outputs are the model-theoretic vectors for each concept. T o assess the quality of the predictions, the Spearman rank-order correlation coefficient is com- puted between the predictions and the gold model- theoretic vectors, ignoring all features for which a concept has not been annotated. The idea is that some of the features might be present but not gi ven as options during annotation. The method should therefore not be penalized for not suggesting them. Figure 1 illustrates the model. 1 https://code.google.com/p/word2vec/ - 1 . 2 0 . 3 0 . 4 2 . 1 - 0 . 9 … 1 . 5 2 . 5 - 1 . 2 - 0 . 4 0 . 7 0 . 1 0 . 7 - 0 . 1 … 0 . 5 0 . 1 1 . 2 P L S R 0 . 3 1 . 0 0 . 0 … 0 . 6 0 . 0 0 . 9 W o r d e m b e dd i n g f o r a c o n c e pt P r e di c te d m ode l - th e o r i c v e c to r G o l d m o de l - the or i c v e c to r 0 . 34 S pe ar m a n r ank - o r de r c o r r e l at i o n c o e f f i c i e nt Figure 1: Overvie w of (Herbelot and V ecchi, 2015)’ s system. The word embedding of a concept is transformed to a model- theoric vector via a PLSR. The quality of the predicted model-theoric vector is assessed with the Spearman rank-order correlation coefficient between the predictions and the gold model-theoretic v ectors. Note that some of the elements that equal 0 in the gold model-theoretic vector may correspond to features that are not annotated for the concept. Such features are omitted when e valuating the Spearman rank-order correlation coef ficient. Also, the dimension of the model-theoretic vectors could be larger or smaller than the dimension of the word embedding. Since the word embeddings we use have 300 dimensions, the model-theoretic vectors will be smaller than the word embeddings in the AD dataset, and lar ger in the QMR dataset. 5 Experiments W e compare (Herbelot and V ecchi, 2015)’ s model (PLSR + word2vec) against three baselines: random vectors, mode, and nearest neighbor . • Mode : A predictor that outputs, for each fea- ture, the most common feature value (i.e., the mode) in the training set. For example, if a fea- ture is annotated as all for most concepts, then the predictor will always output all for this fea- ture. When finding the most common v alue of a feature, we ignore all the concepts for which the feature is not annotated. The resulting pre- dictor does not take any concept into account when making a prediction. Indeed, the pre- dicted values are always the same, regardless of the concept. If a feature has the same v alue for most concepts, the predictor may perform reasonably well. • Nearest neighbor (NN) : A predictor that out- puts for any concept the model-theoretic v ector from the training set corresponding to the most similar concept in the training set. Similarity is based on the cosine similarity of the word vectors. This is a simple nearest neighbor pre- dictor . • Random vectors : (Herbelot and V ecchi, 2015) used pre-trained word embeddings as input to the PLSR, we instead simply use random vec- tors of same dimension (300, continuous uni- form distribution between 0 and 1). W e also apply retrofitting (Faruqui et al., 2014) on the word embeddings in order to le verage relational information from semantic lexicons by encouraging linked words to have similar vector representations. Using (Faruqui et al., 2014)’ s retrofitting tool 2 , we retrofit the word embeddings ( GoogleNe ws-vectors- ne gative300 ) on each of the 4 datasets present in the retrofitting tool ( framenet , ppdb-xl , wor dnet- synonyms+ , and wor dnet-synonyms . 2 https://github.com/mfaruqui/retrofitting AD QMR Min A verage Max Min A verage Max PLSR + word2v ec 0 . 435 0 . 572 0 . 713 0 . 244 0 . 332 0 . 407 PLSR + word2v ec + framenet 0 . 423 0 . 577 0 . 710 0 . 236 0 . 331 0 . 410 PLSR + word2v ec + ppdb 0.455 0 . 583 0 . 688 0 . 247 0 . 332 0 . 421 PLSR + word2v ec + wordnet 0 . 429 0 . 583 0 . 713 0 . 252 0 . 339 0 . 444 PLSR + word2v ec + wordnet+ 0 . 453 0.604 0 . 724 0 . 261 0 . 344 0 . 428 PLSR + random vectors 0 . 253 0 . 419 0 . 550 − 0 . 017 0 . 087 0 . 178 NN + word2v ec 0 . 338 0 . 524 0 . 751 0 . 109 0 . 215 0 . 291 NN + word2v ec + framenet 0 . 321 0 . 516 0 . 673 0 . 108 0 . 204 0 . 288 NN + word2v ec + ppdb 0 . 360 0 . 531 0 . 730 0 . 114 0 . 213 0 . 300 NN + word2v ec + wordnet 0 . 384 0 . 551 0 . 708 0 . 115 0 . 208 0 . 297 NN + word2v ec + wordnet+ 0 . 390 0 . 597 0.806 0 . 138 0 . 235 0 . 324 NN + random vectors 0 . 244 0 . 400 0 . 597 − 0 . 063 0 . 029 0 . 107 mode 0 . 432 0 . 554 0 . 643 0.420 0.522 0.605 true-mode 0 . 419 0 . 551 0 . 637 0 . 379 0 . 466 0 . 551 (Herbelot and V ecchi, 2015) (PLSR + word2v ec) ? 0 . 634 ? ? 0 . 346 ? T able 1: All the presented results are averaged over 1000 runs, except for the results of (Herbelot and V ecchi, 2015)) in the last row . PLSR stands for partial least squares regression, NN for nearest neighbor , ppdb for the Paraphrase Database (Ganitkevitch et al., 2013). There are two w ays to compute the mode: either taking the mode of the means of the 3 annotations ( mode ), or the mode for all annotations ( true-mode ). QMR has 3 potentially different annotations for each concept-feature pair, while AD has 3 only one annotation for each concept-feature pair: as a result, mode and true-mode hav e similar results for AD, but potentially different results for QMR. For each run, a train/test split was randomly chosen (60 training samples for AD, 400 for QMR, in order to have the same number of training samples as in (Herbelot and V ecchi, 2015)’ s T able 2). 6 Results and discussion T able 1 presents the results, using the Spearman correlation as the performance metric. The exper- iment was coded in Python using scikit-learn (Pe- dregosa et al., 2011) and the source as well as the complete result log and the two datasets are av ail- able online 3 . W e could reproduce the results for the QMR dataset using PLSR and word2vec em- beddings (0.346 in (Herbelot and V ecchi, 2015) vs. 0.332 in our experiments, b ut we could not ex- 3 https://github.com/Franck- Dernoncourt/ model- theoretic actly reproduce the results for the AD dataset (0.634 in (Herbelot and V ecchi, 2015) vs. 0.572 in our ex- periments): this discrepancy most likely results from the choice of the training set. Our experiments’ re- sults are averaged ov er 1000 runs, and for each run the training/test split is randomly chosen, the only constraint being having the same number of train- ing samples as in (Herbelot and V ecchi, 2015). For the AD dataset, our worst run achiev ed 0.435, and our best run achiev ed 0.713, which emphasizes the lack of robustness of the results with respect to the train/test split. The v ariability is much lower for the a_bird a_carnivore a_cat a_fish a_mammal a_predator an_insect an_insectivore barks bites builds_nests burrows crawls eaten_by_people flies forages grazes has_a_head has_a_heart has_eyes has_hair hibernates hunted_by_people is_aquatic is_black is_blind is_blue is_brown is_deadly is_emerald is_grey is_indigo is_muscular is_nocturnal is_parasitic is_poisonous is_red is_silvery is_slender is_sluggish is_solitary is_stout is_terrestrial is_wooly is_yellow lays_eggs lives_in_oceans lives_on_coasts migrates protected_by_law roosts stings trots walks 0 10 20 30 40 50 60 70 80 Distribution (number of concepts = 72) Distribution per feature No Few Some Most All Figure 2: Stacked bars showing the distribution of quantifiers among features in the AD dataset: most features tend to hav e one clearly dominant quantifier . For example, the feature a cat is almost always annotated with the quantifier no . QMR dataset (min: 0.244; max: 0.407), which is expected since QMR is significantly larger than AD. Furthermore, the mode baseline yields results that are good on the AD dataset (0.554, vs. 0.634 in (Herbelot and V ecchi, 2015) vs. 0.572 in our PLSR + word2v ec implementation), and significantly bet- ter than all other models on the QMR dataset (0.522, vs. 0.346 in (Herbelot and V ecchi, 2015), i.e. +51% improv ement). T o get an intuition of why the mode baseline w orks well, Figures 2 and 3 sho w that most features tend to have one clearly dominant quantifier in the AD dataset. A similar trend can be found in the QMR dataset. In the AD dataset, there are 54 fea- tures, each of them being annotated for all 73 con- cepts. In the QMR dataset, there are 2201 features, each of them being annotated for only 6187 2201 ≈ 2 . 81 concepts on av erage. As a result, it is much more dif ficult for the PLSR to learn the mapping from word embeddings to model-theoretic vectors in the QMR dataset than in the AD dataset. This explains why the mode baseline outperforms PLSR in the QMR dataset but not in the AD dataset. The random vector baseline with PLSR performs mediocrely on the AD dataset, and very poorly on the QMR dataset. The nearest neighbor baseline yields some competiti ve results on the AD dataset, but lower results on the QMR dataset. Lastly , us- ing retrofitting increases the performances on both AD and QMR datasets. This is expected as applying retrofitting to word embeddings lev erages relational information from semantic lexicons by encouraging linked words to ha ve similar vector representations. 7 Conclusion In this paper we hav e presented sev eral baselines for mapping distrib utional to model-theoretic se- mantic spaces. The mode baseline significantly out- performs (Herbelot and V ecchi, 2015)’ s model on the QMR dataset, and yields competitive results on the AD dataset. This indicates that state-of-the-art models do not efficiently map word embeddings to model-theoretic vectors in these datasets. a_bird a_carnivore a_cat a_fish a_mammal a_predator an_insect an_insectivore barks bites builds_nests burrows crawls eaten_by_people flies forages grazes has_a_head has_a_heart has_eyes has_hair hibernates hunted_by_people is_aquatic is_black is_blind is_blue is_brown is_deadly is_emerald is_grey is_indigo is_muscular is_nocturnal is_parasitic is_poisonous is_red is_silvery is_slender is_sluggish is_solitary is_stout is_terrestrial is_wooly is_yellow lays_eggs lives_in_oceans lives_on_coasts migrates protected_by_law roosts stings trots walks Features ant ape bat bear beaver bee butterfly cat chicken cobra cod coyote crab crocodile crow deer dog dolphin donkey dove duck eagle eel elephant elk falcon fish fly fox frog goat goose gorilla gull hare hawk horse jaguar kangaroo lion monkey moose mosquito mouse octopus otter owl ox oyster parrot penguin pig pigeon pony rabbit rat raven shark sheep snail snake spider squid squirrel swan tiger toad trout turtle whale wolf worm Concepts Semantic space 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 Figure 3: Heatmap sho wing the distribution of quantifiers among features in the AD dataset: most features tend to hav e one clearly dominant quantifier . The values of the heatmap are given by the following quantifier-scalar mapping: no 7→ 0 ; few 7→ 0 . 05 ; some 7→ 0 . 35 ; most 7→ 0 . 95 ; all 7→ 1 . References Dzmitry Bahdanau, Kyungh yun Cho, and Y oshua Ben- gio. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 . Phil Blunsom, Edward Grefenstette, Nal Kalchbrenner, et al. 2014. A con volutional neural network for mod- elling sentences. In Pr oceedings of the 52nd Annual Meeting of the Association for Computational Linguis- tics . Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Ronan Collobert, Jason W eston, L ´ eon Bottou, Michael Karlen, K oray Kavukcuoglu, and Pav el Kuksa. 2011. Natural language processing (almost) from scratch. The Journal of Machine Learning Resear ch , 12:2493– 2537. Franck Dernoncourt, Ji Y oung Lee, Ozlem Uzuner , and Peter Szolovits. 2016. De-identification of patient notes with recurrent neural networks. arXiv pr eprint arXiv:1606.03475 . Manaal Faruqui, Jesse Dodge, Sujay K Jauhar, Chris Dyer , Eduard Ho vy , and Noah A Smith. 2014. Retrofitting word vectors to semantic lexicons. arXiv pr eprint arXiv:1411.4166 . Juri Ganitkevitch, Benjamin V an Durme, and Chris Callison-Burch. 2013. PPDB: The paraphrase database. In Pr oceedings of NAA CL-HLT , pages 758– 764, Atlanta, Georgia, June. Association for Compu- tational Linguistics. Aur ´ elie Herbelot and Eva Maria V ecchi. 2015. Build- ing a shared world: Mapping distributional to model- theoretic semantic spaces. In Pr oceedings of the 2015 Confer ence on Empirical Methods in Natural Lan- guage Pr ocessing , pages 22–32. Aurelie Herbelot. 2013. What is in a text, what isnt, and what this has to do with lexical semantics. Pr oceed- ings of the T enth International Confer ence on Compu- tational Semantics (IWCS2013) . Y oon Kim. 2014. Con volutional neural networks for sen- tence classification. In Pr oceedings of the 2014 Con- fer ence on Empirical Methods in Natural Language Pr ocessing , pages 1746–1751. Association for Com- putational Linguistics. Matthieu Labeau, Ke vin L ¨ oser , and Alexandre Allauzen. 2015. Non-lexical neural architecture for fine-grained POS tagging. In Pr oceedings of the 2015 Confer ence on Empirical Methods in Natural Language Process- ing , pages 232–237, Lisbon, Portugal, September . As- sociation for Computational Linguistics. Guillaume Lample, Miguel Ballesteros, Sandeep Subra- manian, Kazuya Kaw akami, and Chris Dyer . 2016. Neural architectures for named entity recognition. arXiv pr eprint arXiv:1603.01360 . Ji Y oung Lee and Franck Dernoncourt. 2016. Sequen- tial short-text classification with recurrent and conv o- lutional neural networks. In Human Language T ech- nologies 2016: The Confer ence of the North American Chapter of the Association for Computational Linguis- tics, NAA CL HLT 2016 . Ken McRae, George S Cree, Mark S Seidenberg, and Chris McNorgan. 2005. Semantic feature production norms for a large set of living and nonliving things. Behavior r esearc h methods , 37(4):547–559. T omas Mikolov , Martin Karafi ´ at, Lukas Burget, Jan Cer- nock ` y, and Sanjeev Khudanpur . 2010. Recurrent neural network based language model. In INTER- SPEECH , volume 2, page 3. T omas Mikolo v , Ilya Sutske ver , Kai Chen, Greg S Cor- rado, and Jef f Dean. 2013. Distributed representa- tions of words and phrases and their compositionality . In Advances in neural information processing systems , pages 3111–3119. Fabian Pedregosa, Ga ¨ el V aroquaux, Alexandre Gram- fort, V incent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer , Ron W eiss, V in- cent Dubourg, et al. 2011. Scikit-learn: Machine learning in python. Journal of Machine Learning Re- sear ch , 12(Oct):2825–2830. Jeffre y Pennington, Richard Socher, and Christopher D Manning. 2014. GloV e: global vectors for word representation. Pr oceedings of the Empiricial Meth- ods in Natural Language Pr ocessing (EMNLP 2014) , 12:1532–1543. Richard Socher , Alex Perelygin, Jean Y W u, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursiv e deep models for semantic compositionality over a sentiment treebank. In Pr oceedings of the conference on empirical meth- ods in natural language pr ocessing (EMNLP) , v olume 1631, page 1642. Citeseer . Martin Sundermeyer , T amer Alkhouli, Joern W uebker , and Hermann Ney . 2014. T ranslation modeling with bidirectional recurrent neural networks. In EMNLP , pages 14–25. Akihiro T amura, T aro W atanabe, and Eiichiro Sumita. 2014. Recurrent neural networks for word alignment model. In A CL (1) , pages 1470–1480. Di W ang and Eric Nyberg. 2015. A long short-term memory model for answer sentence selection in ques- tion answering. In Pr oceedings of the 53r d Annual Meeting of the Association for Computational Linguis- tics and the 7th International Joint Confer ence on Nat- ural Language Pr ocessing (V olume 2: Short P apers) , pages 707–712, Beijing, China, July . Association for Computational Linguistics. Jason W eston, Antoine Bordes, Sumit Chopra, and T omas Mikolov . 2015. T owards AI-complete ques- tion answering: A set of prerequisite toy tasks. arXiv pr eprint arXiv:1502.05698 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment