분포 의미 공간을 모델 이론적 의미 공간으로 매핑하는 간단한 베이스라인
본 논문은 Herbelot와 Vechi(2015)의 부분 최소 제곱 회귀(PLSR) 기반 매핑 모델에 비해, 매우 단순한 “모드” 베이스라인이 QMR 데이터셋에서 51 % 이상의 상대적 향상을 보이며, 동물 데이터셋(AD)에서도 경쟁력을 유지한다는 것을 실험적으로 입증한다. 또한, 임의 벡터와 최근접 이웃, 레트로피팅을 포함한 여러 대조 실험을 통해 기존 모델의 한계를 진단한다.
저자: Franck Dernoncourt
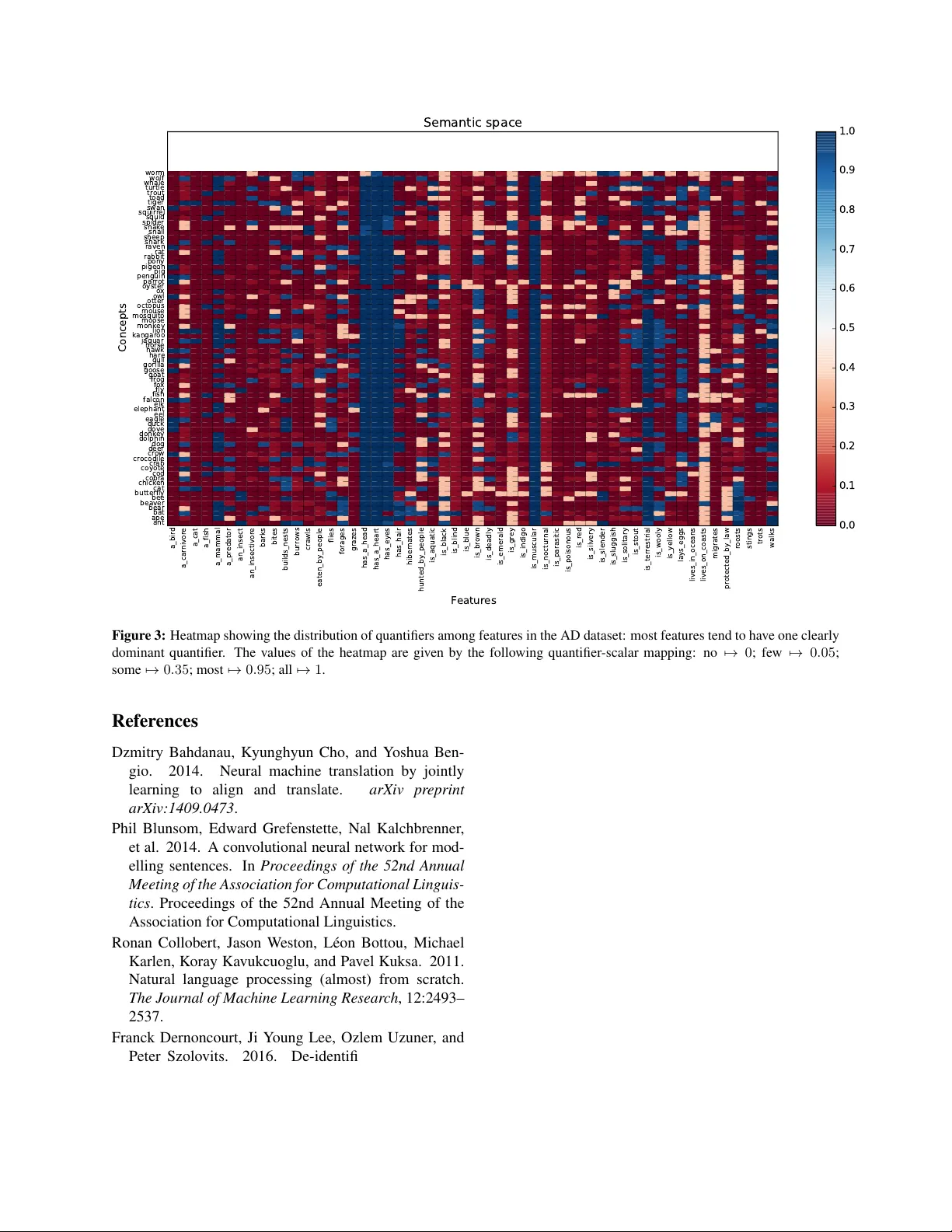
본 논문은 단어 임베딩을 모델‑이론적 의미 공간으로 변환하는 작업에 대한 기존 연구를 재검토하고, 간단한 베이스라인이 기존 복잡 모델을 능가할 수 있음을 실험적으로 입증한다. 먼저, Herbelot와 Vechi(2015)가 제안한 방법을 소개한다. 그들은 300차원 word2vec(Google News) 임베딩을 입력으로, 부분 최소 제곱 회귀(PLSR)를 통해 인간 어노테이션 기반 모델‑이론적 벡터(피처별 ‘no’, ‘few’, ‘some’, ‘most’, ‘all’ 정량화값)로 매핑했다. 성능 평가는 개별 피처에 대해 어노테이션이 존재하는 경우에만 스피어만 순위 상관계수를 계산하는 방식이었다.
연구에서는 두 개의 데이터셋을 사용한다. 첫 번째는 Animal Dataset(AD)으로, 73개의 동물 개념과 54개의 피처가 모두 어노테이션되어 있다(각 피처당 1명 어노테이터). 두 번째는 McRae Norms(QMR)로, 541개의 개념과 2201개의 피처가 존재하지만, 각 개념당 평균 11.4개의 피처만 어노테이션되어 있어 매우 희소하다. 이러한 데이터 특성은 모델‑이론적 벡터가 고차원(AD:54, QMR:2201)이며, 대부분의 요소가 0(미어노테이션)이라는 점에서 학습 난이도를 높인다.
논문은 세 가지 베이스라인을 설계한다. ① “모드” 베이스라인은 훈련 집합에서 각 피처별 가장 빈번한 정량화값을 전체 예측값으로 사용한다. 이는 개념 정보를 전혀 반영하지 않으며, 피처별 분포가 한쪽으로 치우친 경우(특히 AD) 높은 성능을 기대한다. ② 최근접 이웃(NN) 베이스라인은 코사인 유사도로 가장 가까운 훈련 개념의 모델‑이론적 벡터를 그대로 복사한다. 이는 임베딩 간 거리 정보를 활용하지만, 훈련 샘플이 제한적일 때 불안정할 수 있다. ③ 무작위 벡터를 입력으로 하는 PLSR은 임베딩 자체가 정보가 없다는 가정 하에 최악의 경우를 제공한다.
또한, word2vec 임베딩에 레트로피팅을 적용해 의미론적 사전(프레임넷, PPDB, WordNet)과 정합시켰다. 레트로피팅은 연결된 단어들 간 벡터 거리를 최소화함으로써 외부 관계 정보를 반영한다.
실험은 1000번의 랜덤 train/test 분할(AD:60, QMR:400)에서 평균 성능을 보고한다. 결과는 다음과 같다. AD 데이터셋에서 PLSR+word2vec은 평균 0.572(최저 0.435, 최고 0.713)이며, “모드”는 0.554, NN은 0.338~0.390, 무작위 PLSR은 0.253 수준이다. QMR에서는 PLSR+word2vec이 0.332, “모드”가 0.522, NN이 0.109~0.138, 무작위 PLSR이 0.244 수준으로 나타났다. 특히 QMR에서 “모드”는 Herbelot와 Vechi의 0.346 대비 +51 % 향상을 보이며, 가장 높은 성능을 기록했다.
레트로피팅을 적용한 경우, AD에서 최고 0.713, QMR에서 0.424까지 상승했으며, 이는 외부 의미론적 정보가 임베딩 품질을 향상시킨다는 점을 확인한다.
논문의 논의에서는 두 데이터셋의 피처 분포 차이를 강조한다. AD는 모든 개념에 대해 모든 피처가 어노테이션되어 피처별 정량화값이 명확히 한쪽으로 치우쳐 있다(예: ‘a_cat’는 대부분 ‘no’). 반면 QMR은 대부분의 피처가 거의 모든 개념에 대해 비어 있어, PLSR이 충분한 학습 신호를 얻기 어렵다. 따라서 단순히 전체 피처 평균을 예측하는 “모드”가 높은 정확도를 보이는 것이다.
결론적으로, 복잡한 회귀 기반 매핑 모델이 반드시 우수한 것은 아니며, 데이터의 희소성·불균형성을 고려한 베이스라인이 더 강력할 수 있음을 보여준다. 또한, 레트로피팅과 같은 외부 지식 통합이 임베딩 기반 모델의 성능을 보완할 수 있음을 시사한다. 향후 연구에서는 더 큰 어노테이션 규모, 다중 피처 상호작용 모델링, 그리고 비선형 매핑(예: 신경망) 등을 탐색함으로써 모델‑이론적 의미 공간과 분포 의미 공간 사이의 변환을 보다 정교하게 만들 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기