Minimum Regret Search for Single- and Multi-Task Optimization
We propose minimum regret search (MRS), a novel acquisition function for Bayesian optimization. MRS bears similarities with information-theoretic approaches such as entropy search (ES). However, while ES aims in each query at maximizing the informati…
Authors: Jan Hendrik Metzen
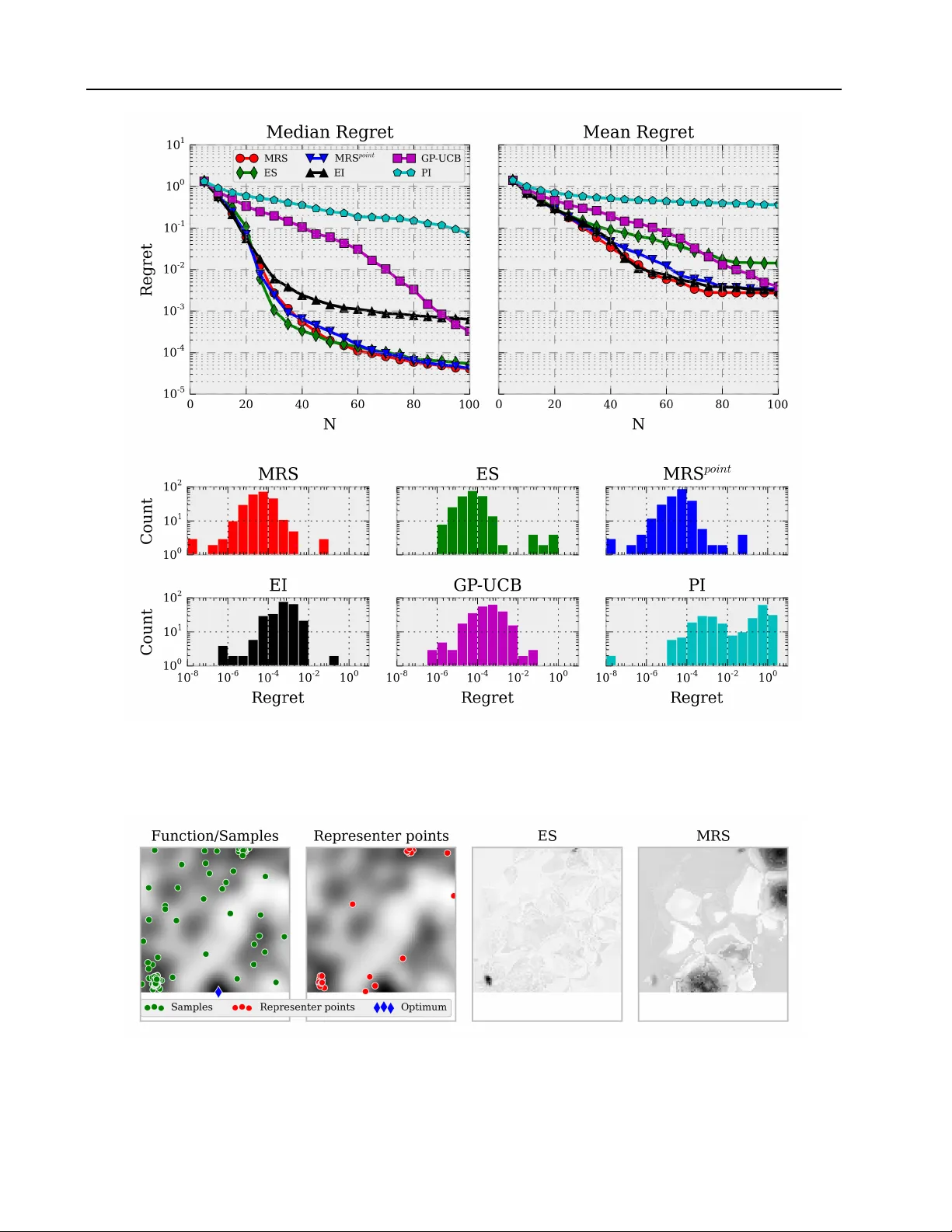
Minimum Regr et Sear ch f or Single- and Multi-T ask Optimization Jan Hendrik Metzen JA N M E T Z E N @ M A I L B OX . O R G Univ ersit ¨ at Bremen, 28359 Bremen, Germany Corporate Research, Robert Bosch GmbH, 70442 Stuttgart, Germany Abstract W e propose minimum regret search (MRS), a nov el acquisition function for Bayesian op- timization. MRS bears similarities with information-theoretic approaches such as en- tropy search (ES). Howe ver , while ES aims in each query at maximizing the information gain with respect to the global maximum, MRS aims at minimizing the e xpected simple re gret of its ultimate recommendation for the optimum. While empirically ES and MRS perform similar in most of the cases, MRS produces fewer out- liers with high simple re gret than ES. W e provide empirical results both for a synthetic single-task optimization problem as well as for a simulated multi-task robotic control problem. 1. INTR ODUCTION Bayesian optimization (BO, Shahriari et al., 2016) denotes a sequential, model-based, global approach for optimiz- ing black-box functions. It is particularly well-suited for problems which are non-con v ex, do not necessarily pro- vide deri v ati v es, are expensi ve to e v aluate (either computa- tionally , economically , or morally), and can potentially be noisy . Under these conditions, there is typically no guaran- tee for finding the true optimum of the function with a finite number of function ev aluations. Instead, one often aims at finding a solution which has small simple r e gr et (Bubeck et al., 2009) with regard to the true optimum, where sim- ple regret denotes the difference of the true optimal func- tion value and the function v alue of the “solution” selected by the algorithm after a finite number of function e valu- ations. BO aims at finding such a solution of small sim- ple regret while minimizing at the same time the number of ev aluations of the expensi ve target function. For this, BO maintains a probabilistic surrogate model of the objec- tiv e function, and a myopic utility or acquisition function, Pr oceedings of the 33 rd International Conference on Machine Learning , New Y ork, NY , USA, 2016. JMLR: W&CP v olume 48. Copyright 2016 by the author(s). which defines the “usefulness” of performing an additional function e valuation at a certain input for learning about the optimum. BO has been applied to a diverse set of problems, rang- ing from hyperparameter optimization of machine learn- ing models (Bergstra et al., 2011; Snoek et al., 2012) ov er robotics (Calandra et al., 2015; Lizotte et al., 2007; Kroemer et al., 2010; Marco et al., 2015) to sensor net- works (Sriniv as et al., 2010) and en vironmental monitoring (Marchant & Ramos, 2012). For a more comprehensi ve ov erview of application areas, we refer to Shahriari et al. (2016). A critical component for the performance of BO is the ac- quisition function, which controls the exploratory behav- ior of the sequential search procedure. Different kinds of acquisition functions hav e been proposed, ranging from improv ement-based acquisition functions over optimistic acquisition functions to information- theoretic acquisition functions (see Section 2). In the latter class, the group of entropy search-based approaches (V illemonteix et al., 2008; Hennig & Schuler, 2012; Hern ´ andez-Lobato et al., 2014), which aims at maximizing the information gain re- garding the true optimum, has achiev ed state-of-the-art per- formance on a number of synthetic and real-world prob- lems. Howe ver , performance is often reported as the me- dian ov er many runs, which bears the risk that the median masks “outlier” runs that perform considerably worse than the rest. In fact, our results indicate that the performance of sampling-based entropy search is not necessarily better than traditional and cheaper acquisition functions accord- ing to the mean simple regret. In this work, we propose minimum regret search (MRS), a nov el acquisition function that explicitly aims at minimiz- ing the expected simple regret (Section 3). MRS performs well according to both the mean and median performance on a synthetic problem (Section 5.1). Moreo ver , we discuss how MRS can be extended to multi-task optimization prob- lems (Section 4) and present empirical results on a simu- lated robotic control problem (Section 5.2). Minimum Regret Search for Single- and Multi-T ask Optimization 2. B A CKGR OUND In this section, we provide a brief overvie w of Bayesian Optimization (BO). W e refer to Shahriari et al. (2016) for a recent more extensiv e re view of BO. BO can be applied to black-box optimization problems, which can be framed as optimizing an objectiv e function f : X → R on some bounded set X ⊂ R D . In contrast to most other black- box optimization methods, BO is a global method which makes use of all previous evaluations of f ( x ) rather than using only a subset of the history for approximating a lo- cal gradient or Hessian. For this, BO maintains a pr oba- bilistic model for f ( x ) , typically a Gaussian process (GP , Rasmussen & W illiams, 2006), and uses this model for de- ciding at which x n +1 the function f will be ev aluated next. Assume we ha ve already queried n datapoints and observed their (noisy) function values D n = { ( x i , y i ) } n i =1 . The choice of the next query point x n +1 is based on a utility function over the GP posterior , the so-called acquisition function a : X → R , via x n +1 = arg max x a ( x ) . Since the maximum of the acquisition function cannot be com- puted directly , a global optimizer is typically used to deter- mine x n +1 . A common strategy is to use DIRECT (Jones et al., 1993) to find the approximate global maximum, fol- lowed by L-BFGS (Byrd et al., 1995) to refine it. The first class of acquisition functions are optimistic poli- cies such as the upper confidence bound (UCB) acquisition function. a U C B aims at minimizing the regret during the course of BO and has the form a U C B ( x ; D n ) = µ n ( x ) + κ n σ n ( x ) , where κ n is a tunable parameter which balances exploita- tion ( κ n = 0 ) and exploration ( κ n 0 ), and µ n and σ n denote mean and standard de viation of the GP at x , respec- tiv ely . Sriniv as et al. (2010) proposed GP-UCB, which en- tails a specific schedule for κ n that yields prov able cumu- lativ e regret bounds. The second class of acquisition functions are impro vement- based policies , such as the probability of improvement (PI, Kushner, 1964) over the current best value, which can be calculated in closed-form for a GP model: a P I ( x ; D n ) := P [ f ( x ) > τ ] = Φ( γ ( x )) , where γ ( x ) = ( µ n ( x ) − τ ) /σ n ( x ) , Φ( · ) denotes the cumu- lativ e distribution function of the standard Gaussian, and τ denotes the incumbent, typically the best function value ob- served so f ar: τ = max i y i . Since PI exploits quite aggres- siv ely (Jones, 2001), a more popular alternativ e is the ex- pected impr ovement (EI, Mockus et al., 1978) o ver the cur- rent best value a E I ( x ; D ) := E [( f ( x ) − τ ) I ( f ( x ) > τ )] , which can again be computed in closed form for a GP model as a E I ( x ; D ) = σ n ( x ) ( γ ( x )Φ( γ ( x )) + φ ( γ ( x ))) , where φ ( · ) denotes the standard Gaussian density function. A generalization of EI is the knowledge gradient factor (Frazier et al., 2009), which can better handle noisy ob- servations, which impede the estimation of the incumbent. The knowledge gradient requires defining a set A n from which one would choose the final solution. The third class of acquisition functions are information- based policies , which entail Thompson sampling and entropy search (ES, V illemonteix et al., 2008; Hennig & Schuler, 2012; Hern ´ andez-Lobato et al., 2014). Let p ? ( x |D n ) denote the posterior distribution of the unkno wn optimizer x ? = arg max x ∈X f ( x ) after observing D n . The objective of ES is to select the query point that results in the maximal reduction in the differential entropy of p ? . More formally , the entropy search acquisition function is defined as a E S ( x , D n ) = H ( x ? |D n ) − E y | x , D n [ H ( x ? |D n ∪ { ( x , y ))] , where H ( x ? |D n ) denotes the differential entropy of p ? ( x |D n ) and the expectation is with respect to the predic- tiv e distribution of the GP at x , which is a normal distribu- tion y ∼ N ( µ n ( x ) , σ 2 n ( x ) + σ 2 ) . Computing a E S directly is intractable for continuous spaces X ; prior work has dis- cretized X and used either Monte Carlo sampling (V ille- monteix et al., 2008) or expectation propagation (Hennig & Schuler, 2012). While the former may require many Monte Carlo samples to reduce v ariance, the latter incurs a run time that is quartic in the number of representer points used in the discretization of p ? . An alternati ve formulation is obtained by exploiting the symmetric property of the mu- tual information, which allo ws re writing the ES acquisition function as a P E S ( x , D n ) = H ( y |D n , x ) − E x ? |D n [ H ( y |D n , x , x ? )] . This acquisition function is known as predictive entropy search (PES, Hern ´ andez-Lobato et al., 2014). PES does not require discretization and allows a formal treatment of GP hyperparameters. Contextual Policy Search (CPS) denotes a model-free ap- proach to reinforcement learning, in which the (low-le vel) policy π θ is parametrized by a vector θ . The choice of θ is gov erned by an upper-le vel policy π u . For general- izing learned policies to multiple tasks, the task is char- acterized by a context vector s and the upper-lev el policy π u ( θ | s ) is conditioned on the respectiv e context. The ob- jectiv e of CPS is to learn the upper-le vel policy π u such that the expected return J over all contexts is maximized, where J = R s p ( s ) R θ π u ( θ | s ) R ( θ , s )d θ d s . Here, p ( s ) is the distribution ov er contexts and R ( θ , s ) is the expected return when ex ecuting the low level policy with parameter θ in conte xt s . W e refer to Deisenroth et al. (2013) for a re- cent overvie w of (contextual) policy search approaches in robotics. Minimum Regret Search for Single- and Multi-T ask Optimization 3. MINIMUM REGRET SEARCH Information-based policies for Bayesian optimization such as ES and PES hav e performed well empirically . Ho w- ev er , as we discuss in Section 3.3, their internal objectiv e of minimizing the uncertainty in the location of the opti- mizer x ? , i.e., minimizing the differential entropy of p ? , is actually different (albeit related) to the common exter - nal objectiv e of minimizing the simple r e gret of ˜ x N , the recommendation of BO for x ? after N trials. W e define the simple regret of ˜ x N as R f ( ˜ x N ) = f ( x ? ) − f ( ˜ x N ) = max x f ( x ) − f ( ˜ x N ) . Clearly , x ? has zero and thus minimum simple regret, but a query that results in the maximal decrease in H ( x ? ) is not necessarily the one that also results in the maximal de- crease in the expected simple regret. In this section, we pro- pose minimum re gret sear ch (MRS), which explicitly aims at minimizing the expected simple re gret. 3.1. Formulation Let X ⊂ R D be some bounded domain and f : X 7→ R be a function. W e are interested in finding the maximum x ? of f on X . Let there be a probability measure p ( f ) ov er the space of functions f : X 7→ R , such as a GP . Based on this p ( f ) , we w ould ultimately like to select an ˜ x which has minimum simple regret R f ( ˜ x ) . W e define the e xpected simple regret ER of selecting parameter x under p ( f ) as: ER ( p )( x ) = E p ( f ) [ R f ( x )] = E p ( f ) [max x f ( x ) − f ( x )] In N -step Bayesian optimization, we are gi ven a budget of N function ev aluations and are to choose a sequence of N query points X q N = { x q 1 , . . . , x q N } for which we ev aluate y i = f ( x q i ) + to obtain D N = { x q i , y i } N i =1 . Based on this, p N ( f ) = p ( f |D N ) is estimated and a point ˜ x N is recommended as the estimate of x ? such that the expected simple regret under p N is minimized, i.e., ˜ x N = arg min x ER ( p N )( x ) . The minimizer ˜ x N of the ex- pected simple re gret under fixed p ( f ) can be approximated efficiently in the case of a GP since it is identical to the maximizer of the GP’ s mean µ N ( x ) . Howe ver , in general, p ( f ) depends on data and it is de- sirable to select the data such that ER is also minimized with regard to the resulting p ( f ) . W e are thus interested in choosing a sequence X q N such that we minimize the ex- pected simple regret of ˜ x N with respect to the p N , where p N depends on X q N and the (potentially noisy) observa- tions y i . As choosing the optimal sequence X q N at once is intractable, we follow the common approach in BO and select x q n sequentially in a myopic way . Howe ver , as ˜ x N itself depends on D N and is thus unkno wn for n < N , we have to use proxies for it based on the currently av ail- able subset D n ⊂ D N . One simple choice for a proxy is to use the point which has minimal expected simple regret under p n ( f ) = p ( f |D n ) , i.e., ˜ x = arg min x ER ( p n )( x ) . Let us denote the updated probability measure on f after performing a query at x q and observing the function value y = f ( x q ) + by p [ x q ,y ] n = p ( f |D n ∪ { x q , y } ) . W e define the acquisit ion function MRS point as the expected reduction of the minimum expected re gret for a query at x q , i.e., a MRS point ( x q ) = min ˜ x ER ( p n )( ˜ x ) − E y | p n ( f ) , x q [min ˜ x ER ( p [ x q ,y ] n )( ˜ x )] , where the expectation is with respect to p n ( f ) ’ s predictive distribution at x q and we drop the implicit dependence on p n ( f ) in the notation of a MRS point . The next query point x q n +1 would thus be selected as the maximizer of a MRS point . One potential drawback of MRS point , ho wever , is that it does not account for the inherent uncertainty about ˜ x N . T o address this shortcoming, we propose using the measure p ? D n = p ? ( x |D n ) as defined in entrop y search (see Section 2) as proxy for ˜ x N . W e denote the resulting acquisition function by MRS and define it analogously to a MRS point : a MRS ( x q ) = E ˜ x ∼ p ? n [ ER ( p n )( ˜ x )] − E y | p n ( f ) , x q [ E ˜ x ∼ p ? D n ∪{ ( x q ,y ) } [ ER ( p [ x q ,y ] n )( ˜ x )]] . MRS can thus be seen as a more Bayesian treatment, where we marginalize our uncertainty about ˜ x N , while MRS point is more akin to a point-estimate since we use a single point (the minimizer of the expected simple regret) as proxy for ˜ x N . 3.2. Appr oximation Since several quantities in MRS cannot be computed in closed form, we resort to similar discretizations and ap- proximations as proposed for entropy search by Hennig & Schuler (2012). W e focus here on sampling based approx- imations; for an alternativ e way of approximating E p ( f ) based on expectation propagation, we refer to Hennig & Schuler (2012). Firstly , we approximate E p ( f ) by taking n f Monte Carlo samples from p ( f ) , which is straightforward in the case of GPs. Secondly , we approximate E y | p ( f ) , x q by taking n y Monte Carlo samples from p ( f ) ’ s predictiv e distribution at x q . And thirdly , we discretize p ? to a finite set of n r rep- resenter points chosen from a non-uniform measure, which turns E ˜ x ∼ p ? n in the definition of MRS ( x q ) into a weighted sum. The discretization of p ? is discussed by Hennig & Schuler (2012) in detail; we select the representer points as follows: for each representer point, we sample 250 candi- date points uniform randomly from X and select the repre- senter point by Thompson sampling from p ( f ) on the can- didate points. Moreov er, estimating p ? D n on the representer Minimum Regret Search for Single- and Multi-T ask Optimization Figure 1. (Left) Illustration of GP posterior , probability of maximum p ? , expected regret ER, and E [max( f ( x ) − f (1 . 5) , 0)] (scale on the right-hand side). (Right) Illustration of GP posterior and different acquisition function. Absolute values have been normalized such that the mean value of an acquisition function is 0 . 5 . Best seen in color . points can be done relatively cheap by reusing the samples used for approximating E p ( f ) , which incurs a small bias which had, howe ver , a negligible effect in preliminary ex- periments. The resulting estimate of a MRS would hav e high variance and would require n f to be chosen relati vely large; ho w- ev er , we can reduce the v ariance considerably by using common random numbers (Kahn & Marshall, 1953) in the estimation of ER ( p )( x ) for different p ( f ) . 3.3. Illustration Figure 1 presents an illustration of different acquisition functions on a simple one-dimensional target function. The left graphic shows a hypothetical GP posterior (illustrated by its mean and standard deviation) for length scale l = 0 . 75 , and the resulting probability of x being the optimum of f denoted by p ? . Moreover , the expected simple regret of selecting x denoted by ER ( x ) is sho wn. The minimum of ER ( x ) and the maximum of p ? are both at ˜ x = 1 . 5 . The expected regret of ˜ x is approximately ER ( ˜ x ) = 0 . 07 . W e plot E [max( f ( x ) − f ( ˜ x ) , 0)] additionally to shed some light onto situations in which ˜ x = 1 . 5 would incur a signif- icant regret: this quantity shows that most of the expected regret of ˜ x stems from situations where the “true” optimum is located at x ≥ 3 . 5 . This can be explained by the obser- vation that this area has high uncertainty and is at the same time largely uncorrelated with ˜ x = 1 . 5 because of the small length-scale of the GP . The right graphic compares different acquisition functions for n f = 1000 , n r = 41 , n y = 11 , and fixed representer points. Since the assumed GP is noise-free, the acquisition- value of any parameter that has already been e valuated is approximately 0 . The acquisition functions dif fer consid- erably in their global shape: EI becomes large for areas with close-to-maximal predicted mean or with high uncer- tainty . ES becomes large for parameters which are informa- tiv e with regard to most of the probability mass of p ? , i.e., for x q ∈ [0 . 5 , 3 . 0] . In contrast MRS point becomes maximal for x q ≈ 4 . 0 . This can be explained as follo ws: according to the current GP posterior , MRS point selects ˜ x = 1 . 5 . As shown in the Figure 1 (left), most of the e xpected re gret for this value of ˜ x stems from scenarios where the true opti- mum would be at x ≥ 3 . 5 . Thus, sampling in this param- eter range can reduce the expected regret considerably— either by confirming that the true value of f ( x ) on x ≥ 3 . 5 is actually as small as expected or by switching ˜ x n +1 to this area if f ( x ) turns out to be large. The maximum of MRS is similar to MRS point . Howe ver , since it also takes the whole measure p ? into account, its acquisition surface is smoother in general; in particular, it assigns a larger value to regions such as x q ≈ 3 . 0 , which do not cause regret for ˜ x = 1 . 5 but for alternati ve choices such as ˜ x = 4 . 0 . Why does ES not assign a large acquisition value to query points x q ≥ 3 . 0 ? This is because ES does not take into account the correlation of different (representer) points un- der p ( f ) . This, howe ver , would be desirable as, e.g., re- ducing uncertainty regarding optimality among two highly correlated points with large p ? (for instance x 1 = 1 . 5 and x 2 = 1 . 55 in the example) will not change the expected regret considerably since both points will hav e nearly iden- tical value under all f ∼ p ( f ) . On the other hand, the v alue of two points which are nearly uncorrelated under p ( f ) and hav e non-zero p ? such as x 1 and x 3 = 4 . 0 might differ con- siderably under dif ferent f ∼ p ( f ) and choosing the wrong one as ˜ x might cause considerable regret. Thus, identifying which of the two is actually better would reduce the regret considerably . This is exactly why MRS assigns large v alue to x q ≈ 4 . 0 . Minimum Regret Search for Single- and Multi-T ask Optimization 4. MUL TI-T ASK MINIMUM REGRET SEARCH Sev eral extensions of Bayesian optimization for multi-task learning have been proposed, both for discrete set of tasks (Krause & Ong, 2011) and for continuous set of tasks (Metzen, 2015). Multi-task BO has been demonstrated to learn efficiently about a set of discrete tasks concurrently (Krause & Ong, 2011), to allow transferring knowledge learned on cheaper tasks to more expensiv e tasks (Swersky et al., 2013), and to yield state-of-the-art performance on low-dimensional contextual policy search problems (Met- zen et al., 2015), in particular when combined with active learning (Metzen, 2015). In this section, we focus on multi- task BO for a continuous set of tasks; a similar extension for discrete multi-task learning would be straightforward. A continuous set of tasks is encountered for instance when applying BO to contextual policy search (see Section 2). W e follow the formulation of BO-CPS (Metzen et al., 2015) and adapt it for MRS were required. In BO-CPS, the set of tasks is encoded in a context vector s ∈ S and BO- CPS learns a (non-parametric) upper-le vel polic y π u which selects for a giv en context s the parameters θ ∈ X of the low-le vel policy π θ . The unknown function f corresponds to the e xpected return R ( θ , s ) of ex ecuting a low-le vel pol- icy with parameters θ in context s . Thus, the probability measure p ( f ) (typically a GP) is defined over functions f : X × S 7→ R on the joint parameter-context space. The probability measure is conditioned on the trials performed so far , i.e., p n ( f ) = p ( f |D n ) with D n = { (( θ i , s i ) , r i ) } n i =1 for r i = R ( θ i , s i ) . Since p n is defined over the joint param- eter and context space, experience collected in one context is naturally generalized to similar contexts. In passiv e BO-CPS on which we focus here (please refer to Metzen (2015) for an acti ve learning approach), the con- text (task) s n of a trial is determined externally according to p ( s ) , for which we assume a uniform distribution in this work. BO-CPS selects the parameter θ n by conditioning p ( f ) on s = s n and finding the maximum of the acquisi- tion function a for fixed s n , i.e., θ n = arg max θ a ( θ , s n ) . Acquisition functions such as PI and EI are not easily gen- eralized to multi-task problems as they are defined rela- tiv e to an incumbent τ , which is typically the best function value observed so far in a task. Since there are infinitely many tasks and no task is visited twice with high proba- bility , the notion of an incumbent is not directly applica- ble. In contrast, the acquisition functions GP-UCB (Srini- vas et al., 2010) and ES (Metzen et al., 2015) ha ve been extended straightforwardly and the same approach applies also to MRS. 5. EXPERMENTS 5.1. Synthetic Single-T ask Benchmark In the first experiment 1 , we conduct a similar analysis as Hennig & Schuler (2012, Section 3.1): we compare differ - ent algorithms on a number of single-task functions sam- pled from a generative model, namely from the same GP- based model that is used by the optimization internally as surrogate model. This precludes model-mismatch issues and unwanted bias which could be introduced by resorting to common hand-crafted test functions 2 . More specifically , we choose the parameter space to be the 2-dimensional unit domain X = [0 , 1] 2 and generate test functions by sampling 250 function values jointly from a GP with an isotropic RBF kernel of length scale l = 0 . 1 and unit sig- nal v ariance. A GP is fitted to these function values and the resulting posterior mean is used as the test function. More- ov er, Gaussian noise with standard deviation σ = 10 − 3 is added to each observation. The GP used as surrogate model in the optimizer employed the same isotropic RBF kernel with fixed, identical hyperparameters. In order to isolate effects of the different acquisition functions from effects of different recommendation mechanisms, we used the point which maximizes the GP posterior mean as recommenda- tion ˜ x N regardless of the employed acquisition function. All algorithms were tested on the same set of 250 test func- tions, and we used n f = 1000 , n r = 25 , and n y = 51 . W e do not provide error-bars on the estimates as the data sets have no parametric distrib ution. Howe ver , we provide additional histograms on the regret distrib ution. Figure 2 summarizes the results for a pure exploration set- ting, where we are only interested in the quality of the algo- rithm’ s recommendation for the optimum after N queries but not in the quality of the queries themselves: according to the median of the simple regret (top left), ES, MRS, and MRS point perform nearly identical, while EI is about an order of magnitude worse. GP-UCB performs even worse initially but surpasses EI ev entually 3 . PI performs the worst as it exploits too aggressi vely . These results are roughly in correspondence with prior results (Hennig & Schuler, 2012; Hern ´ andez-Lobato et al., 2014) on the same task; note, howe ver , that Hern ´ andez-Lobato et al. (2014) used a lower noise level and thus, absolute values are not com- parable. Howe ver , according to the mean simple regret, the picture changes considerably (top right): here, MRS, 1 Source code for replicating the reported experiment is av ail- able under https://github.com/jmetzen/bayesian_ optimization . 2 Please refer to the Appendix A for an analogous experiment with model-mismatch. 3 GP-UCB would reach the same le vel of mean and median simple regret as MRS ev entually after N = 200 steps (in mean and median) with no significant difference according to a W ilcoxon signed-rank test. Minimum Regret Search for Single- and Multi-T ask Optimization Figure 2. (T op) Median and mean simple regret over 250 repetitions for different acquisition functions. Shown is the simple regret of the recommendation ˜ x N after N trials, i.e., the point which maximizes the GP posterior mean. (Bottom) Histogram of the simple regret after performing N = 100 trials for different acquisition functions (note the log-scales). Figure 3. Illustration of acquisition functions on a target function for 100 gi ven samples and 25 representer points; darker areas cor- respond to larger v alues. ES focuses on sampling in areas with high density of p ? (many representer points), while MRS focuses on unexplored areas that are populated by representer points (non-zero p ? ). Minimum Regret Search for Single- and Multi-T ask Optimization MRS point , and EI perform roughly on par while ES is about an order of magnitude worse. This can be explained by the distribution of the simple regrets (bottom): while the distri- butions are fairly non-normal for all acquisition functions, there are considerably more runs with very high simple re- gret ( R f ( ˜ x N ) > 10 − 2 ) for ES (10) than for MRS (4) or EI (4). W e illustrate one such case where ES incurs high simple regret in Figure 3. The same set of representer points has been used for ES and MRS. While both ES and MRS assign a non-zero density p ? (representer points) to the area of the true optimum of the function (bottom center), ES assigns high acquisition value only to areas with a high density of p ? in order to further concentrate density in these areas. Note that this is not due to discretization of p ? but because of ES’ objectiv e, which is to learn about the precise loca- tion of the optimum, irrespectiv e of how much correlation their is between the representer points according to p ( f ) . Thus, predictiv e entropy search (Hern ´ andez-Lobato et al., 2014) would likely be affected by the same deficiency . In contrast, MRS focuses first on areas which hav e not been explored and ha ve a non-zero p ? , since those are areas with high expected simple regret (see Section 3.3). Accordingly , MRS is less likely to incur a high simple regret. In sum- mary , the MRS-based acquisition functions are the only ac- quisition functions that perform well both according to the median and the mean simple regret; moreover , MRS per- forms slightly better than MRS point and we will focus on MRS subsequently . 5.2. Multi-T ask Robotic Behavior Learning W e present results in the simulated robotic control task used by Metzen (2015), in which the robot arm COMPI (Bargsten & de Gea, 2015) is used to throw a ball at a tar - get on the ground encoded in a two-dimensional context vector . The tar get area is S = [1 , 2 . 5] m × [ − 1 , 1] m and the robot arm is mounted at the origin (0 , 0) of this coordinate system. Contexts are sampled uniform randomly from S . The low-le vel policy is a joint-space dynamical movement primitiv es (DMP , Ijspeert et al., 2013) with preselected start and goal angle for each joint and all DMP weights set to 0. This DMP results in throwing a ball such that it hits the ground close to the center of the target area. Adaptation to different target positions is achiev ed by modifying the pa- rameter θ : the first component of θ corresponds to the ex- ecution time τ of the DMP , which determines ho w far the ball is thro wn, and the further components encode the final angle g i of the i -th joint. W e compare the learning perfor- mance for different number of controllable joints; the not- controlled joints keep the preselect goal angles of the initial throw . The limits on the parameter space are g i ∈ − π 2 , π 2 and τ ∈ [0 . 4 , 2] . All approaches use a GP with anisotropic Mat ´ ern kernel for representing p ( f ) and the kernel’ s length scales and signal variance are selected in each BO iteration as point estimates using maximum marginal likelihood. Based on preliminary experiments, UCB’ s exploration parameter κ is set to a constant value of 5 . 0 . For MRS and ES, we use the same parameter values as in the Section 5.1, namely n f = 1000 , n r = 25 , and n y = 51 . Moreover , we add a “greedy” acquisition function, which always selects θ that maximizes the mean of the GP for the giv en con- text (UCB with κ = 0 ), and a “random” acquisition func- tion that selects θ randomly . The return is defined as R ( θ , s ) = −|| s − b s || 2 − 0 . 01 P t v 2 t , where b s denotes the position hit by the ball, and P t v 2 t denotes a penalty term on the sum of squared joint velocities during DMP ex ecution; both b s and P t v 2 t depend indirectly on θ . Figure 4 summarizes the main results of the empirical e val- uation for different acquisition functions. Shown is the mean offline performance of the upper-le vel policy at 16 test contexts on a grid ov er the context space. Selecting parameters randomly (“Random”) or greedily (“Greedy”) during learning is shown as a baseline and indicates that generalizing experience using a GP model alone does not suffice for quick learning in this task. In general, perfor- mance when learning only the ex ecution time and the first joint is better than learning several joins at once. This is be- cause the e xecution time and first joint allo w already adapt- ing the throw to dif ferent contexts (Metzen et al., 2015); controlling more joints mostly adds additional search di- mensions. MRS and ES perform on par for controlling one or two joints and outperform UCB. F or higher -dimensional search spaces (three or four controllable joints), MRS per- forms slightly better than ES ( p < 0 . 01 after 200 episodes for a Wilcoxon signed-rank test). A potential reason for this might be the increasing number of areas with poten- tially high re gret in higher dimensional spaces that may re- main unexplored by ES; howe ver , this hypothesis requires further in vestigation in the future. 6. DISCUSSION AND CONCLUSION W e hav e proposed MRS, a new class of acquisition func- tions for single- and multi-task Bayesian optimization that is based on the principle of minimizing the expected simple regret. W e hav e compared MRS empirically to other ac- quisition functions on a synthetic single-task optimization problem and a simulated multi-task robotic control prob- lem. The results indicate that MRS performs fav orably compared to the other approaches and incurs less often a high simple regret than ES since its objecti ve is explicitly focused on minimizing the regret. An empirical compari- son with PES remains future work; since PES uses the same objectiv e as ES (minimizing H ( x ? ) ), it will likely show Minimum Regret Search for Single- and Multi-T ask Optimization Figure 4. Learning curves on the ball-throwing task for different acquisition functions and different number of controllable joints (first joint, first and second joint, and so on). Shown are mean and standard error of mean ov er 30 repetitions of the greedy upper-lev el policy if learning would ha ve been stopped after N episodes. the same deficit of ignoring areas that hav e small probabil- ity p ? but could nev ertheless cause a large potential regret. On the other hand, in contrast to ES and MRS, PES al- lows a formal treatment of GP hyperparameters, which can make it more sample-ef ficient. Potential future research on approaches for addressing GP hyperparameters and more efficient approximation techniques for MRS would thus be desirable. Additionally , combining MRS with acti ve learn- ing as done for entropy search by Metzen (2015) would be interesting. Moreov er , we consider MRS to be a v aluable addition to the set of base strategies in a portfolio-based BO approach (Shahriari et al., 2014). On a more theoret- ical le vel, it would be interesting if formal regret bounds can be prov en for MRS. Acknowledgments This work was supported through two grants of the German Federal Ministry of Economics and T echnology (BMW i, FKZ 50 RA 1216 and FKZ 50 RA 1217). References Bargsten, V inzenz and de Gea, Jose. COMPI: Development of a 6-DOF compliant robot arm for human-robot coop- eration. In Pr oceedings of the 8th International W ork- shop on Human-F riendly Robotics (HFR-2015) . T ech- nische Univ ersit ¨ at M ¨ unchen (TUM), October 2015. Bergstra, James, Bardenet, Remi, Bengio, Y oshua, and Ke gl, Balazs. Algorithms for Hyper-Parameter Opti- mization. In Advances in Neural Information Pr ocessing Systems 24 , 2011. Bubeck, S ´ ebastien, Munos, R ´ emi, and Stoltz, Gilles. Pure Exploration in Multi-armed Bandits Problems. In Algo- rithmic Learning Theory , number 5809 in Lecture Notes in Computer Science, pp. 23–37. Springer Berlin Hei- delberg, October 2009. Byrd, Richard H., Lu, Peihuang, Nocedal, Jorge, and Zhu, Ciyou. A Limited-Memory Algorithm for Bound Con- strained Optimization. SIAM J ournal on Scientific Com- puting , 16:1190–1208, 1995. Calandra, Roberto, Seyfarth, Andr, Peters, Jan, and Deisen- roth, Marc P . Bayesian Optimization for Learning Gaits under Uncertainty . Annals of Mathematics and Artificial Intelligence (AMAI) , 2015. Deisenroth, Marc Peter , Neumann, Gerhard, and Peters, Jan. A Survey on Policy Search for Robotics. F oun- dations and T rends in Robotics , 2(1-2):1–142, 2013. Minimum Regret Search for Single- and Multi-T ask Optimization Frazier , Peter, Powell, W arren, and Dayanik, Sav as. The Knowledge-Gradient Policy for Correlated Normal Be- liefs. INFORMS J ournal on Computing , 21(4):599–613, May 2009. Hennig, Philipp and Schuler , Christian J. Entropy Search for Information-Efficient Global Optimization. JMLR , 13:1809–1837, 2012. Hern ´ andez-Lobato, Jos ´ e Miguel, Hof fman, Matthe w W , and Ghahramani, Zoubin. Predicti ve Entropy Search for Efficient Global Optimization of Black-box Functions. In Advances in Neural Information Pr ocessing Systems 27 , pp. 918–926, 2014. Ijspeert, Auke Jan, Nakanishi, Jun, Hoffmann, Heiko, Pas- tor , Peter , and Schaal, Stefan. Dynamical Movement Primitiv es: Learning Attractor Models for Motor Behav- iors. Neural Computation , 25:1–46, 2013. ISSN 0899- 7667. Jones, D. R., Perttunen, C. D., and Stuckman, B. E. Lip- schitzian optimization without the Lipschitz constant. Journal of Optimization Theory and Applications , 79(1): 157–181, October 1993. Jones, Donald R. A T axonomy of Global Optimization Methods Based on Response Surfaces. J ournal of Global Optimization , 21(4):345–383, 2001. Kahn, H. and Marshall, A. W . Methods of Reducing Sam- ple Size in Monte Carlo Computations. Journal of the Operations Resear ch Society of America , 1(5):263–278, Nov ember 1953. ISSN 0096-3984. Krause, Andreas and Ong, Cheng S. Contextual Gaussian Process Bandit Optimization. In Advances in Neural In- formation Pr ocessing Systems 24 , pp. 2447–2455, 2011. Kroemer , O. B, Detry , R., Piater , J., and Peters, J. Combin- ing activ e learning and reactiv e control for robot grasp- ing. Robot. Auton. Syst. , 58(9):1105–1116, September 2010. ISSN 0921-8890. Kushner , H. J. A New Method of Locating the Maximum Point of an Arbitrary Multipeak Curve in the Presence of Noise. Journal of Fluids Engineering , 86(1):97–106, 1964. Lizotte, Daniel, W ang, T ao, Bowling, Michael, and Schuur- mans, Dale. Automatic gait optimization with gaussian process regression. pp. 944–949, 2007. Marchant, R. and Ramos, F . Bayesian optimisation for in- telligent en vironmental monitoring. In Intellig ent Robots and Systems (IR OS), 2012 IEEE/RSJ International Con- fer ence on , pp. 2242–2249, Oct 2012. Marco, Alonso, Hennig, Philipp, Bohg, Jeannette, Schaal, Stefan, and T rimpe, Sebastian. Automatic LQR T un- ing based on Gaussian Process Optimization: Early Ex- perimental Results. In Proceedings of the Second Ma- chine Learning in Planning and Contr ol of Robot Motion W orkshop , Hamburg, 2015. IR OS. Metzen, Jan Hendrik. Acti ve Contextual Entropy Search. In Pr oceedings of NIPS W orkshop on Bayesian Opti- mization , pp. 5, Montreal, Qu ´ ebec, Canada, 2015. Metzen, Jan Hendrik, Fabisch, Alexander , and Hansen, Jonas. Bayesian Optimization for Contextual Policy Search. In Pr oceedings of the Second Machine Learn- ing in Planning and Contr ol of Robot Motion W orkshop. , Hambur g, 2015. IROS. Mockus, J., T iesis, V ., and Zilinskas, A. The application of Bayesian methods for seeking the extremum. T oward Global Optimization , 2, 1978. Rasmussen, Carl and W illiams, Christopher . Gaussian Pr o- cesses for Machine Learning . MIT Press, 2006. Shahriari, B., Swersky , K., W ang, Z., Adams, R.P ., and de Freitas, N. T aking the Human Out of the Loop: A Revie w of Bayesian Optimization. Proceedings of the IEEE , 104(1):148–175, January 2016. Shahriari, Bobak, W ang, Ziyu, Hof fman, Matthew W ., Bouchard-C ˆ ot ´ e, Alexandre, and de Freitas, Nando. An Entropy Search Portfolio for Bayesian Optimization. In NIPS workshop on Bayesian optimization , 2014. Snoek, Jasper , Larochelle, Hugo, and Adams, Ryan P . Practical Bayesian Optimization of Machine Learning Algorithms. In Advances in Neural Information Pr ocess- ing Systems 25 , pp. 2951–2959, 2012. Sriniv as, Niranjan, Krause, Andreas, and Seeger , Matthias. Gaussian process optimization in the bandit setting: No regret and experimental design. In Pr oceedings of the 27th International Conference on Machine Learning , 2010. Swersky , K evin, Snoek, Jasper , and Adams, Ryan P . Multi- T ask Bayesian Optimization. In Bur ges, C. J. C., Bottou, L., W elling, M., Ghahramani, Z., and W einberger , K. Q. (eds.), Advances in Neural Information Pr ocessing Sys- tems 26 , pp. 2004–2012. Curran Associates, Inc., 2013. V illemonteix, Julien, V azquez, Emmanuel, and W alter, Eric. An informational approach to the global opti- mization of expensiv e-to-ev aluate functions. Journal of Global Optimization , 44(4):509–534, September 2008. Minimum Regret Search for Single- and Multi-T ask Optimization A. Synthetic Single-T ask Benchmark with Model Mismatch W e present results for an identical setup as reported in Sec- tion 5.1, with the only difference being that the test func- tions hav e been sampled from a GP with rational quadratic kernel with length scale l = 0 . 1 and scale mixture α = 1 . 0 . The kernel used in the GP surrogate model is not modified, i.e., an RBF k ernel with length scale l = 0 . 1 is used. Thus, since dif ferent kind of kernel govern test functions and sur- rogate model, we have model mismatch as would be the common case on real-world problems. Figure 5 summa- rizes the results of the experiment. Interestingly , in contrast to the experiment without model mismatch, for this setup there are also considerable differences in the mean simple regret between MRS and ES: while ES performs slightly better initially , it is outperformed by MRS for N > 60 . W e suspect that this is because ES tends to explore more locally than MRS once p ? has mostly settled onto one re- gion of the search space. More local exploration, howe ver , can be detrimental in the case of model-mismatch since the surrogate model is more likely to underestimate the func- tion value in regions which hav e not been sampled. Thus a more homogeneous sampling of the search space as done by the more global exploration of MRS is beneficial. As a second observation, in contrast to a no-model-mismatch scenario, MRS point performs considerably worse than MRS when there is model-mismatch. This emphasizes the im- portance of accounting for uncertainty , particularly when there is model mis-specification. According to the median simple regret, the difference be- tween MRS, MRS point , ES, and EI is less pronounced in Figure 5. Moreov er , the histograms of the regret distribu- tion exhibit less outliers (reg ardless of the method). W e suspect that this stems from properties of the test functions that are sampled from a GP with rational quadratic rather than from the model-mismatch. Howe ver , a conclusive an- swer on this would require further experiments. Minimum Regret Search for Single- and Multi-T ask Optimization Figure 5. (T op) Median and mean simple regret over 250 repetitions for different acquisition functions. Shown is the simple regret of the recommendation ˜ x N after N trials, i.e., the point which maximizes the GP posterior mean. (Bottom) Histogram of the simple regret after performing N = 100 trials for different acquisition functions (note the log-scales).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment