Deep Learning on FPGAs: Past, Present, and Future
The rapid growth of data size and accessibility in recent years has instigated a shift of philosophy in algorithm design for artificial intelligence. Instead of engineering algorithms by hand, the ability to learn composable systems automatically fro…
Authors: Griffin Lacey, Graham W. Taylor, Shawki Areibi
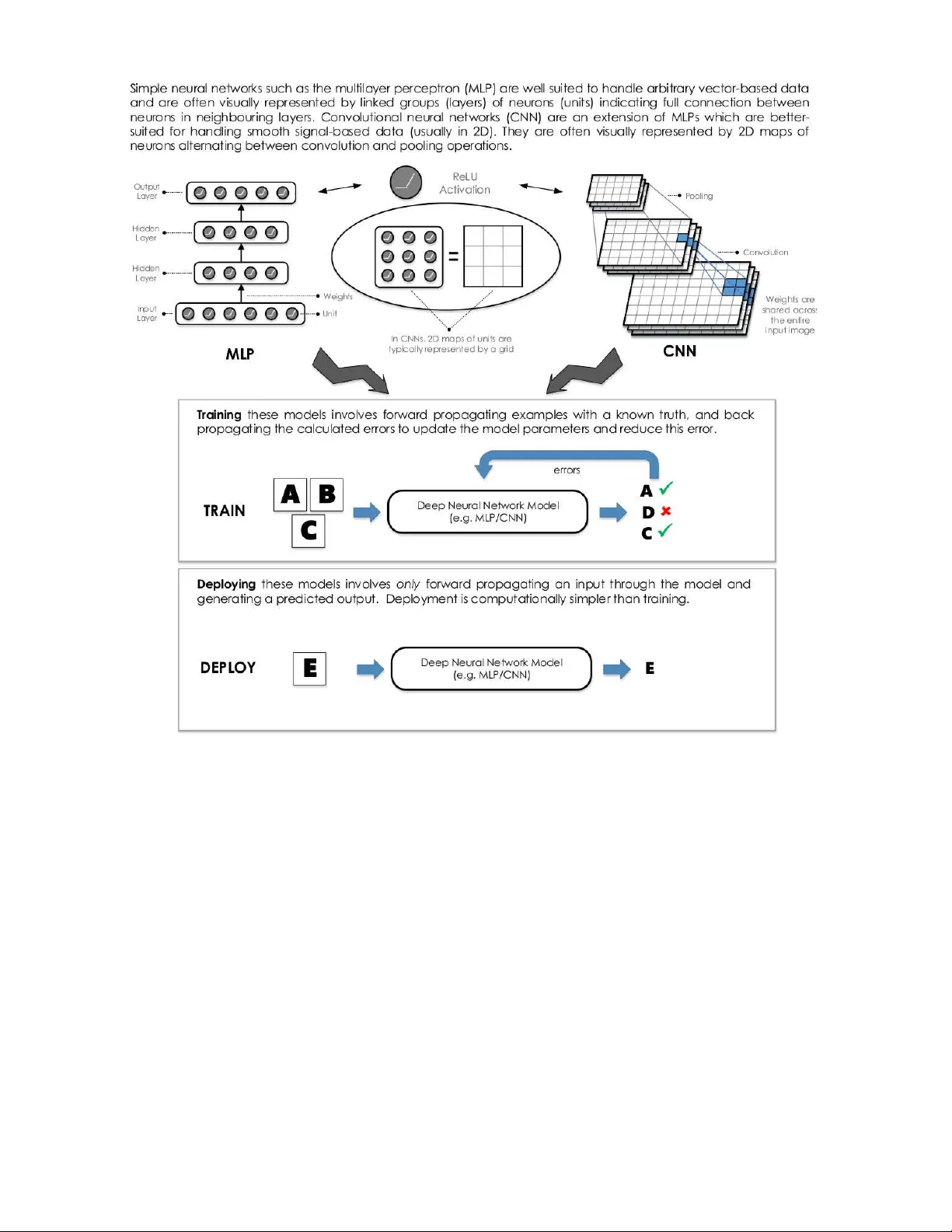
Deep Learning on FPGAs: P ast, Present, and Future Griffin Lacey Unive rs ity of Guelph 50 Stone Rd E Guelph, Ontario lace yg@uoguelph .ca Graham T a ylor Unive rs ity of Guelph 50 Stone Rd E Guelph, Ontario gwta ylor@uogue lph.ca Sha wki Areibi Unive rs ity of Guelph 50 Stone Rd E Guelph, Ontario sareibi@uo guelph.ca ABSTRA CT The rapid gro wth of data size and a ccessibility in rec ent years has instigated a shift of ph ilosoph y in algorithm de- sign for artificial in telligence. Instead of engineering algo- rithms by hand, the abilit y to learn comp osable systems au- tomatically from massiv e amoun ts of data has led to ground- breaking p erformance in imp ortant domains such as com- puter visi on, speech recognition, and natural language p ro- cessing. The most p opular class of techniques used in these domains is called de ep le arnin g , and is seeing significan t attentio n from industry . How ever, th ese mo dels require in- credible amoun ts of data and compute pow er to train, and are limited by the need for b etter hard ware acceleration to accommodate scaling b eyond current data and model sizes. While th e cu rrent solution has b een to use clusters of graphics pro cessing units (GPU) as general purp ose pro- cessors (GPGPU), the use of field programmable gate arra ys (FPGA) provide an interesting alternative. Curren t trend s in design tools for FPGAs hav e made them more compatible with the high-level softw are practices typically practiced in the deep learning communit y , mak ing FPGAs more accessi- ble to those who b uild an d deploy mod els. S ince FPGA ar- chitectures are flexible, this could also allow researchers the abilit y to explore mod el-level optimizations b eyond what is p ossible on fixed architectures such as GPUs. As well, FP- GAs tend to provide high p erformance p er watt of p o wer consumption, which is of particular imp ortance for app li- cation scien tists interested in large scale serv er-based de- plo yment or resource-limited embedd ed applications. T his review take s a look at deep lear nin g and FPGAs from a hardwa re acceleration p ersp ective, identifying trends and innov ations that make these tec hnologies a natural fit, and motiv ates a discussion on how FPGAs may b est serve the needs of the deep learning community moving forw ard. 1. INTR ODUCTION The effects of machine learning on our everyda y life are far-reac hing. Whether you are clic king through p ersonal- ized recommendations on websi tes, u sing sp eec h to commu- nicate with your smart-phone, or using face-detection to get the perfect picture on your digital camera, some fo rm of artificial intellig ence is inv olved. This new w av e of artifi- cial intell igence is accompanied b y a shift in ph ilosoph y for algorithm design. Where past attempts at lea rning from data inv olved muc h “feature engineering” by hand using ex- p ert domain-sp ecific knowle dge, the abilit y t o learn comp os- able feature extraction systems au t omatically from massiv e amounts of example data has led to ground-b reaking p er- formance in important domains suc h as computer vision, sp eech recognition, and natural language pro cessing. The study of t h ese data-driven techniques is called d eep learn- ing, and is seeing significant attention from tw o imp ortant groups of the technolog y comm un ity: researc h ers, who are interes ted in exp loring and training these mod els to achieve top p erformance across tasks, and application scien tists, who are interested in deploying these mo dels for no vel, real w orld applications. Ho wev er, b oth of t hese groups are limited by the need for b etter hardw are acceleration to accommodate scaling b eyond current d ata and algorithm sizes. The current state of hardware acceleration for deep learn- ing is largely dominated by using clusters of graphics pro- cessing un its (GPU) as general purpose processors (GPGPU) [18]. GPUs hav e orders of magnitude more computational cores compared to t raditional general purp ose pro cessors (GPP), and allow a greater abilit y to p erform parallel com- putations. In particular, the N VIDIA CUDA platform for GPGPU programming is most dominant, with ma jor deep learning to ols ut ilizing this platform to access GPU accel- eration [16, 26, 13, 19]. More recently , the op en parallel programming standard Op enCL has gained traction as an alternativ e tool for heterogeneous hardware programming, with interes t from these p opular to ols gaining momentum. Op enCL, while trailing CUDA in terms of supp ort in the deep learning comm un ity , has tw o u n ique features whic h dis- tinguish itself from CUDA. First is th e op en source, roy alty- free standard for developmen t, as opp osed to the single ven- dor su p p ort of CUDA. The second is the supp ort for a wide v ariet y of alternative hardw are including GPUs, GPPs, field programmable gate-arra ys (FPGA), and digital signal pro- cessors (DS P). 1.1 The Case f or FPGAs The imminent sup p ort for alternative h ardw are is esp e- cially important for FPGAs, a strong comp etitor to GPUs for algo rithm acceleration. Unlike GPUs, t hese devices h ave a flexible hardw are configuration, and often pro vid e b etter p erformance p er watt than GPUs for su b routines important to deep learning, such as sliding-windows computation [24]. How ever, programming of these devices requires hardware sp ecific knowledge that many researc h ers and ap p lication scien tists may not p ossess, and as such, FPGAs h ave b een often considered a specialist arc hitecture. Recently , FPGA tools hav e adopted soft ware-lev el programming mo dels, in- cluding Op enCL, which h as made th em a more attractive option for users trained in mainstream softw are devel opment practices. F or researc hers considering a va riety of design to ols, t he selection criteria is typically related to having user-friendly soft ware developmen t to ols, flex ible and upgradeable wa ys to d esign mo dels, and fast compu tation t o reduce the t rain- ing time of large models. Deep learning researc hers will b enefit from th e use of FPGAs giv en the trend of higher abstraction design to ols whic h are making FPGAs easier to program, the reconfigurabilit y which allow s customized ar- chitectures, and the large degree of parallelism which will accelerate execution sp eeds. F or application scientists , while similar to ol lev el prefer- ences exist, th e emphasis for hardware selection is to maxi- mize p erformance p er wa tt of p o wer consump tion, redu cing costs for large scale op erations. Deep learning app lication scien tists will benefit from the use of FPGAs giv en the strong p erformance p er w att that typically accompanies the ability to customize the architecture for a particular application. FPGAs serve as a logical design choice which app eal to the needs of these tw o imp ortant audiences. This review takes a lo ok at the current state of deep learning on FP- GAs, as w ell as current d evelopments whic h serve to bridge these tw o technologies. As su c h, this review serves three imp ortant purp oses. First, it identifies the opportu nity that exists within th e deep learning community for exploring new hardwa re acceleration platforms, and shows FPGAs as an ideal choice. Nex t, it out lines the cu rrent state of FPGA supp ort for deep learning, identifying p otentia l limitations. Finally , it makes key recommendations of future directions for FPGA hardware acceleration that would h elp in solving the deep learning problems of tomorro w. 2. DEEP LEARNING Con ventio nal approaches to artificial intelligence fo cused on using computation to solv e problems analytically , req uir- ing explicit knowledge ab out a given d omain [10]. F or sim- ple problems this approach was adequ ate, as the programs engineered by hand wer e small, and domain exp erts could carefully transform the mo dest amoun t of raw data into use- ful representations for learning. How ever, adv ances in arti- ficial intelligence created interest in solving more comp lex problems, where kno wledge is n ot easily expressed exp licitly . Exp ert k now ledge ab out problems such as face recognition, sp eech transcription, and med ical diagnosis is difficult to express formally , and conven tional approaches to artificial intel ligence faile d to account for the implicit information stored in the raw data. Moreo ver, tremend ous growth in data acquisition and storage means that using th is implicit information is more imp ortant than ever. Recently , these types of applications are seeing state-of-the- art p erformance from a class of techniques called d eep learning, where this implicit information is discov ered automatical ly by learn- ing task-relev ant features from ra w data. Interest in this researc h area has led t o several recent reviews [29, 34, 9]. The fi eld of deep learning emerged around 2006 after a long p erio d of relati ve disinterest around neural netw orks researc h. Interes tingly , th e early successes in t he field were due to unsup erv ised learning– techniques that can learn from unlab eled data. Sp ecifically , unsup erv ised learning w as used to “pre-train” (initialize) th e la yers of deep neural net- w orks, whic h we re thought at the time to b e to o difficult to train with the usual metho ds, i.e. gradient b ac kp ropaga- tion. H o wev er, with the introdu ction of GPGPU computing and the a v ailabilit y of larger datasets tow ards the end of the 2000’s and into the current decade, fo cus has shifted al- most exclusively to sup ervised learning. In particular, th ere are tw o types of n eural netw ork arc hitectures that hav e re- ceive d most of t he attention b oth in research and industry . These are multi-la yer perceptrons (MLP) and convo lutional neural netw orks (CNN ). Essentially all of t h e researc h on FPGA-based d eep learning has fo cused on on e of th ese ar- chitectures, and therefore we briefly describe them b elo w. Before describing any specific arc hitecture, h o wev er, it is w orth noting several characteri stics of most deep learning mod els and applications that, in general, make them we ll- suited for parallellizatio n using hardware accelerators. Data parallel ism – The parallelism inherent in pixel-based sensory input (e.g. images and v ideo) manifests itself in op- erations that apply concu rrently to all pixels or lo cal regions. As wel l, t he most p opu lar w ay of training mo dels is n ot b y presenting it with a single example at a time, b ut by pro- cessing “minibatches” of typicall y hundreds or t h ousands of examples. Ea ch ex ample in a minib atc h can b e pro cessed indep endently . Mode l paralleli sm – These biologically-inspired mo dels are comp osed of redu ndant pro cessing units which can b e distributed in h ardw are and up dated in parallel. R ecent w ork on accelerating CNNs using multiple GPUs has used very sophisticated strategies to balance data and mo del- based p arallism such that d ifferent parts of t he architecture are parallelized in d ifferent, but optimal w ays [27]. Pipe line Parallelism – The feed-forw ard natu re of com- putation in arc hitectures like MLPs and CNNs means that hardwa re which is well suited to exploit p ipeline parallelism (e.g. FPGAs) can offer a particular adv antage. While GPPs and GPUs rely on executing p arallel t hreads on multiple cores, FPGAs can create customized hardw are circuits whic h are deeply pip elined and inherently multithreaded. 2.1 Multi-layer P er ceptron s Simple feed-forwa rd deep netw orks are known as multi- la yer perceptrons (MLP), and are the backbon e of deep learning [11]. T o describ e t hese mo dels using n eural netw ork terminology , we refer to the examples fed to these mo dels as inputs , the predictions p rod u ced from t hese mo dels as outputs , each modular sub- function as a layer with hidden layers referring to those la yers b etw een the first ( input) la yer and last (output) lay er, eac h scalar ou t put of one of these la yers as a unit (analogous to a neuron in the biolog ical inspiration of these mo dels), and each connection b etw een units as a weight (an alogous to a synapse), which define the function of t he mo d el as they are the parameters that are adjusted du ring training [9]. Collections of units are some- times referred to as fe atur es , as to draw similaritie s to th e traditional idea of features in conv entional machine learn- ing, whic h were designed by domain exp erts. T o preven t the entire n etw ork from collapsing to a linear transforma- tion, each un it applies an element-wise nonlinear op eration to its input, with the most popular choice b eing th e rectified linear unit (ReLU). A basic MLP is illustrated in Figure 1. 2.2 Con volutional Neural Networks Deep con volutional n eural netw orks (CNN) are curren tly the most p opular deep learning arc hitectu res, esp ecially for pixel-based v isual recognition tasks. More formally , these netw orks are d esigned for data that has a measure of spatial or temp oral contin uity . This inspiration is drawn largely on Figure 1: Di fferences and si milaritie s b etw ee n MLPs and CNNs. w ork from Hub el and Wiesel, who describ ed t he function of a cat’s visual cortex as b eing sensitive to small sub - regions of the visual field [25]. Commonly , sp atial contin uity in data is found in imag es where a pixel at lo cation ( i, j ) shares similar intensit y or color prop erties to its neighbours in a local region of th e image. CNNs are comp osed of v arious combinations of a few im- p ortant lay er t yp es. These lay ers, in comparison to MLPs, are constructed as a 2D arrangement of units called fe atur e maps . Conv olution la yers, analogous to the linear feature ex- traction op eration of MLPs, are parameterized by learnable filters (kernels), which hav e lo cal connections to a small re- ceptive field of the inpu t feature map and shared at all loca- tions of th e input. F eature extraction in a CNN amounts to conv olution with these filters. Pooling la yers apply a simple reduction op eration (e.g. a max or av erage) to local regions of the feature maps. This redu ces the size of th e feature maps, which is fav orable to computation and reducing pa- rameters, b ut also yields a small amount of shift-inv ariance. Finally , in recognition applications CNNs typically apply one or more fully connected lay ers (the same lay ers used in MLPs) tow ards the outpu t lay er in order to reduce the spa- tially and/or temporally organized information in feature maps to a decision, such as a classificatio n or regression. 3. FPGAs T raditionally , when ev aluating hardw are platforms for ac- celeration, one m ust inevitably consider the trade-off b e- tw een flexibilit y and p erformance. On one end of the sp ec- trum, general purp ose pro cessors (GPP) provide a high de- gree of flexibility and ease of use, b ut p erform relativ ely inef- ficiently . These platforms tend to b e more readily accessible, can b e pro duced cheaply , and are appropriate for a wide v a- riet y of uses and reuses. On the other en d of the sp ectrum, application sp ecific integrated circuits (ASIC) pro vide high p erformance at the cost of b eing infl exible and more difficult to pro duce. These circuits are dedicated to a sp ecific app li- cation, and are ex p ensive and time consuming to pro duce. FPGAs serve as a compromise b etw een these tw o extremes. They b elong t o a more general class of programmable logic devices (PLD) and are, in the most simple sense, a reconfi g- urable integra ted circuit. As such, they provide the p erfor- mance b enefits of in tegrated circuits, with the reconfigurable flexibility of GPPs. At a lo w-level, FPGAs can implement sequential logic t hrough the use of flip-flops (FF) and com- binational logic through the use of look- up tab les (LUT). Modern FPGAs also contain hardened comp onents for com- monly used functions such as full p rocessor cores, communi- cation cores, arithmetic cores, and blo ck RAM (BRAM). In addition, current FPGA trends are tending tow ard a system- on-chip (SoC) design approach, where ARM coprocessors and FPGAs are commonly found on the same fabric. The current FPGA market is dominated by Xilinx and Altera, accounti ng for a combined 85 p ercent mark et share [8]. I n addition, FPGAs are rapidly replacing ASICs and applica- tion sp ecific standard p rodu cts (ASS P) for fixed fun ction logic. The FPGA market is exp ected to reac h the $10 bil- lion mark by 2016 [8]. F or deep learning, FPGAs p ro vide an obvious p otential for accelerati on ab ov e and beyond what is p ossible on tra- ditional GPPs. Soft ware-lev el execution on GPPs rely on the traditional V on Neumann architecture, whic h stores in- structions and d ata in external memory to b e fetched when needed. This is the motiv ation for cac hes, which alleviate muc h of the exp ensive external m emory op erations [8]. The b ottlenec k in th is arc hitecture is th e p ro cessor and memory comm un ication, whic h severely cripples GPP p erformance, especially for the memory- b ound techniques frequently re- quired in deep learning. In comparison, the programmable logic cells on FPGAs can b e used to implement th e data and control p ath found in common logic funct ions, which do not rely on th e V on Neumann architecture. They are also capable of exploiting distributed on - chip memory , as w ell as large degrees of pip eline parallelism, which fit nat- urally with th e feed-forw ard natu re deep learning metho ds. Modern FPGAs also sup p ort partial dynamic reconfigura- tion, where p art of the FPGA can b e reprogrammed while another part of the FPGA is b eing used. This can h a ve im- plications for large deep learning mod els, where individ ual la yers could be reconfigured on the FPGA whil e not dis- rupting ongoing computation in other la yers. This would accommodate mo dels which ma y b e too large to fit on a sin- gle FPGA, and also alleviate expensive global memory reads by keeping intermediate results in local memory . Most importantly , when compared to GPUs, FPGAs offer a differen t persp ective on what it means to accelerate designs on hardware . With GPUs and other fixed architectures, a soft ware ex ecution model is foll ow ed, and structured around executing tasks in parallel on indep end ent compute un its. As such, the goal in developing deep learning techniques for GPUs is to adapt algorithms to follow this mo del, where computation is done in parallel, and data interdepend en ce is ensured. In contrast, FPGA architecture is tailored for the application. When developing deep learning t ec hn iques for FPGAs, there is less emphasis on adapting algorithms for a fixed computational structure, allowi ng more freedom to explore algorithm level optimizations. T echniques which require man y complex low -level hardw are con trol operations whic h cann ot b e easily implemented in h igh- leve l soft ware languages are esp ecially attractive for FPGA implementa- tions. How ever, this flexibility comes at the cost of large compile (place and route) times, which is often problematic for researchers who need to qu ic kly iterate through d esign cycles. In addition to compile time, th e problem of attracting researc hers and application scien tists, who tend to fa vour high-level programming languages, to develo p for FPGAs has b een esp ecially difficult. While it is often the case that b eing fl uent in one softw are language means one can eas- ily learn another, the same cann ot b e said for translating skills to hardware languages. The most p opu lar languages for FPGAs hav e b een V erilog an d VHDL, b oth ex amples of hardwa re description languages (HDL). The main difference b etw een these languages and traditional softw are languages, is that HDL is simply describing hardw are, whereas soft ware languages such as C are describing sequential in structions with no n eed to und erstand hardware level implementation details. Describing hardware efficien tly requires a wo rkin g knowl edge of digital design and circuits, and while some of the lo w level implementation decisions can be left to auto- matic synthesizer to ols, t his do es not alwa y s result in effi- cien t designs. A s a result, researc hers and application sci- entis ts ten d to opt for a soft wa re design exp erience, which has matured to supp ort a large assortment of abstractions and con veniences that increase the produ ctivity of p rogram- mers. These trends ha ve p ushed the FPGA comm un it y to now fav our design to ols with a high-level of abstraction. 3.1 High-Lev el Abstraction T ools Both Xilinx and Altera ha ve fav oured the u se of high- leve l design tools whic h abstract a wa y many of the c hal- lenges of low level hardware p rogramming. These to ols are commonly termed h igh-level synthesis (HLS ) tools, which translate high-level designs into lo w-level register-transfer leve l (R TL) or H DL co de. A go od ov erview of H LS to ols is presented in [8], where t h ey are group ed in to five main cat- egories: mo del-based framew orks, h igh-level language b ased framew orks, HDL- like languages, C-based framew orks, and parallel computing framew orks (i.e. CUDA/OpenCL). Wh ile it is imp ortant to und erstand these different typ es of ab- straction tools, this rev iew fo cuses on parallel computing framew orks, as th ey provide the most sensible path to join deep learning and FPGAs. 3.2 OpenCL Op enCL is an op en source, standardized framew ork for algorithm acceleration on heterogeneous architectures. As a C-based language (C99), p rograms written in Op enCL can b e executed transparently on GPPs, GPUs, DSPs, and FP- GAs. S imilar to CUDA, Op enCL provides a standard frame- w ork for parallel programming, as well as lo w-level access to hardwa re. W h ile b oth CUDA and Op enCL provide similar functionalit y to programmers, key differences b etw een them hav e left most p eople divided. Since CUD A is t he current choi ce for most p opular deep learning to ols, it is impor- tant to discuss t h ese differences in detail, in the in terest of demonstrating h o w Op enCL could be used for d eep learning mo ving forw ard. The ma jor d ifference b etw een Op enCL and CUDA is in terms of ownership. CUDA is a proprietary framew ork cre- ated by the hardwa re manufacturer NVIDIA, kno wn for manufa cturing high p erformance GPUs. Op enCL is op en- source, roy alit y-free, and is maintai ned by the Khronos group. This gives Op enCL a u nique capability compared to CUDA: Figure 2: Prop osed deployment flow for image classi fication using F PGA for accele ration. Op enCL can supp ort programming a wide v ariet y of hard- w are platforms , including FPGAs. How ever, this flex ibil- it y comes at a cost, where all supp orted platforms are not guaran teed to supp ort all Op enCL fun ctions. In the case of FPGAs, only a sub set of O p enCL functions are cu rrently supp orted. Wh ile a detailed compariso n of Open CL and CUDA is outside t h e scope of t h is pap er, performance of b oth framewo rks has b een shown to b e very similar for given applications [22]. Beginning in late 2013, b oth Altera and Xilinx started to adopt Op en CL SDKs for their FPGAs [21, 7]. This mov e allo we d a m uch wider audience of sof tw are developers to take adv antage of the high-p erformance and low p ow er b en - efits that come with d esigning for FPGAs. C onvenien tly , b oth companies hav e taken similar approaches t o adopt ing Op enCL for their devices. 3.3 Pr oposed Design Flow for Deep Lear ning Deve lopment T o successfully integrate FPGAs in to d eep learning de- sign flows , the n eeds of researchers an d application scien- tists, who are familiar with GPU design flows, need to b e considered. While this is a challe nge given the arc hitec- tural differences of FPGAs and GPUs, we b elieve this goal is achiev able. The main chal lenge is related to design compile time. Both Altera and Xilinx su pp ort primarily offline compil- ing for Op enCL kernels. The main reason for t his is th at Op enCL kernel compilation t ime for b oth vendors is on the order of tens of min utes to hours, whereas compiling generic Op enCL kernels for GPPs/G PUs is on the order of millisec- onds to seconds. Obviously , this mak es iterating through th e design phase challenging if the compilation time is hours for each design iteration. Ho w ever, this is not n ecessarily futile for d eep learning, as deep learning t ools often reuse the same pre-compiled kernels d uring th e design phase. As w ell, deep learning tools sup p orted by CUDA use a similar metho d ology , as CUD A employs a just-in-time compiling approac h. As suc h, doing one-time offline compilatio n of commonly used d eep learning kernels is a reasonable com- promise th at does not limit application scien tists who are usually not designing these kernels, bu t just interested in using them. Figure 2 show s an example flow for deploymen t of an image classification mo del. F or researc hers who do hav e an interest in k ernel design, b oth A ltera and Xilinx supp ort integrated kernel profiling, debugging, and optimization in their O p enCL to ols. These features give researchers th e ab ility to sp eed up and opti- mize the developmen t of kernels. As w ell, b oth companies hav e sup p ort for kernel simulation in soft ware, whic h can cir- cumv ent t he hassle of dealing with long compile times when debugging non-hardware issues such as seman tic or syntax errors. 4. A REVIEW OF CNNS ON FPGAS One of the most limiting hardware realizations for deep learning techniques on FPGAs is design size. The trade- off b etw een d esign reconfigurabilit y and d ensity means t hat FPGA circuits are often considerably less dense t h an h ard- w are alternativ es, an d so implementing large n eural n et- w orks has n ot alwa y s b een p ossible. Ho w ever, as mo dern FPGAs conti nue to exploit smaller feature sizes to increase density , and incorp orate hardened computational units along- side generic FPGA fabric, deep netw orks hav e started b eing Figure 3: Ti meline of imp ortant events i n FPGA de ep learning researc h. implemented on single FPGA systems. A b rief timeline of imp ortant even ts in FPGA deep learning research is seen in Figure 3. The first FPGA implemen tations of n eural netw ork s b e- gan app earing in the early 1990’s, with the first implemen- tation credited to Co x et al. in 1992 [20]. How ever, the first FPGA implemen tations of CNN s b egan app earing a few y ears later. Cloutier et al. w ere among the first to ex- plore these efforts, but were strongly limited by FPGA size constrain ts at th e time, leading to the use of lo w-precision arithmetic [17]. In addition, b ecause FPGAs at this time did not contai n t he dense hardened multiply-accum ulate (MAC) units that are presen t in to day’s FPGAs, arithmetic w as also very slow in addition to b eing resource exp ensive. Since this time, FPGA technolog y has changed significantly . Most no- tably , there has b een a large increase in th e density of FPGA fabric, motiva ted by the decreasing feature (transistor) size, as w ell as an increase in the number of hardened compu - tational units present in FPGAs. State-of-the-art FPGA implementa tions of CNNs take adv anta ge of b oth of these design improv ements. T o th e best of our knowledge, state-of-the-art p erformance for forwa rd propagation of CNNs on FPGAs was ac hieved by a team at Microsoft. Ovtcharo v et al. hav e reported a throughput of 134 images/seco nd on the ImageNet 1K dataset [28], which amounts to roughly 3x the throughput of the next closest comp etitor, while op erating at 25 W on a Stratix V D 5 [30]. This p erformance is p ro jected to increase by using t op - of-the-line FPGAs, with an estimated through- put of roughly 233 images/second while consuming roughly the same p ow er on an Arria 10 GX1150. This is com- pared t o high-p erforming GPU implemen tations (Caffe + cuDNN), whic h achiev e 500-824 images/seco nd , while con- suming 235 W. I nteres tingly , this w as achiev ed using Microsoft- designed FPGA b oards and servers, an exp erimental pro ject whic h integrates FPGAs into datacenter applications. This pro ject has claimed to improv e large-scale searc h engine p er- formance by a factor of t wo, show ing promise for this t yp e of FPGA application [4]. Other strong efforts include the d esign prop osed by Zhang et al., referenced ab o ve as the closest comp etitor ac hieving a throughput of 46 images/ second on a Virtex 7 485T, with an unrep orted p ow er consumption [36] . In this p aper, Zhang et al. show their w ork to outp erform most of the main strong compet itors in this fi eld, including [14, 15, 23, 32, 33]. Most of these implementations contain arc hitecturally similar de- signs, commonly using off-chip memory access, confi gurable soft ware la yers, buffered inp ut and output, and many paral- lel processing elements implemented on FPGA fabric (com- monly used to p erform conv olution). Ho w ever, important FPGA sp ecific differences exist, such as u sing different mem- ory sub- sy stems, data transfer mechanisms , soft-cores, LUT types, op eration frequencies, an d enti rely d ifferent FPGAs, to name a few. As a result, it is hard to determine sp ecific optimal architecture decisions, as more researc h is needed . Since pre-trained CNNs are algo rithmically simple and computationally efficient, most FPGA efforts hav e invo lved accelerating th e forwa rd propagation of these mo dels, and rep orting on th e achiev ed th rou gh p ut. This is often of most imp ortance to application engineers who wish t o use pre- trained netw orks to pro cess large amoun ts of data as quickly and efficiently as p ossible. How ever, this only represents one aspect of CNN design considerations for FPGAs, as accel- erating backw ard propagation on FPGAs is also an area of interes t. Paul et al. were the first to completely p arallelize the learning phase on a Virtex E FPGA in 2006 [31]. 5. LOOKING FOR W A RD The future of deep learning on FPGAs, and in general, is largely depend ant on scalabilit y . F or th ese techniques to succeed on the problems of tomorrow , they must scale to accommodate data sizes and arc hitectures that contin ue to gro w at an incredible rate. FPGA technology is adapting to supp ort this trend, as th e hardware is headed tow ard larger memory , smaller feature sizes, and in terconnect impro ve- ments t o accommodate multi-FPGA configurations. The Intel acquisition of Altera, along with the partnership of IBM and Xilinx, indicate a c hange in t h e FPGA land scap e whic h may also see the integ ration of FPGAs in consumer and data cen ter applicatio ns in the very near future. I n addition, d esign to ols will likely tend tow ard higher levels of abstraction and softw are-like ex p eriences, in an effort to attract a wider technical range of users. 5.1 P opular Deep Learning Softwar e T ools Of th e most p opu lar softw are pac k ages for deep learning, sever al hav e b egan to take notice of the need for Op enCL supp ort in addition to CUDA supp ort. This supp ort will make FPGAs more accessible for the purp oses of deep learn- ing. While, to our knowledge, no deep learning t o ols ex ist yet which explicitly supp ort FPGAs, the follo wing list (sum- marized in T able 1) details some of the n otable Op enCL efforts which mo ve th ese tools in t h at direction: • Caffe, developed by the Berkeley Vision an d Learning T able 1: Ov erview of Deep Learning F ramew orks with OpenCL Supp ort T ool Core Language Bindings OpenC L User Base Caffe C ++ Python MA TLAB P artial Supp ort Large T or ch Lua - P artial Supp ort Large The ano Python - Minimal Su pp ort Large De epCL C++ Python Lua F ull Su pp ort Moderate Cen ter, has unofficial supp ort for Op enCL u nder the name pro ject GreenT ea [2]. There is also an AMD versi on of Caffe that sup p orts Op enCL [1]. • T orc h, a scientific computing framew ork written in Lua, is widely used and has unofficial support for Op enCL under th e pro ject CL T orch [6]. • Theano, developed by the Universit y of Montreal, has unofficial su pp ort for OpenCL u nder the w ork-in- p rogress gpuarra y back end [5]. • DeepCL is an Op enCL library to train deep convo - lutional neural netw orks, developed by H u gh P erkins [3]. F or those new to th is field who are looking to choose b e- tw een these t ools, our recommendation is to start with Caffe due to its p opu larit y , supp ort, an d easy to use interface. As w ell, using Caffe’s “mod el zo o” rep ository , it is easy to ex- p eriment with p opular p re-trained mod els. 5.2 Incr easing Degrees of Freed om for T rain- ing While one ma y expect the pro cess of training machine learning algori thm s to be fully autonomous, in practice there are tunable hyp er-parameters th at need to be adjusted. This is esp ecially true for deep learning, where complexity of the mod el in terms of number of parameters is often accompa- nied by many p ossible combinations of hyp er-parameters. The num b er of training iterations, the learning rate, mini- batch size, number of h idden u nits, and num b er of lay ers are all examples of hyper-parameters that can be adjusted. The act of tuning t h ese v alues is equiv alent to selecting whic h mod el, among the set of all p ossible mod els, is b est for a par- ticular problem. T raditionally , hyp er-parameters have b een set by experience or systematically by grid searc h or more effectivel y , random search [12]. V ery recently , researchers hav e tu rned to adaptive metho ds, which exploit the results of hyp er-parameter att emp ts. Among these, Ba yesian Opti- mization [35] is the most p opular. Regardless of the metho d selected to tune hyper-p arameters, current training pro cedures using fixed arc hitectures are some- what limited in their ability to gro w these sets of possi- ble mod els, meaning that we may b e viewing the solution space th rou gh a very narro w lens. Fixed architectures mak e it muc h easier to exp lore hyp er-parameter settings within mod els (e.g. number of hidden units, number of lay ers) but difficult to explore settings betw een mo d els (i.e. different typ es of models) as the t raining of models which d o not conv eniently conform to a particular fixed architecture may b e very slow . The flexible architecture of FPGAs, how ever, ma y b e better suited for these types of opt imizations, as a completely d ifferent hardwa re structure can b e programmed and accelerated at runtime. 5.3 Low P ower Compute Clusters One of the most intriguing aspects of deep learning models is the abilit y to scale. Whether the pu rp ose is to disco ver complex high level features in data, or to increase p erfor- mance for data center applications, deep learning techniques are often scaled up across multi-node computing infrastruc- tures. Curren t solutions to th is problem inv olve using clus- ters of GPUs with In finiband interconnects and MPI to allo w high leve ls of parallel computing p o wer and fast data trans- fer b etw een no des [18]. Ho wev er, as th e workloads of these large scale applications b ecome increasingly heterogeneous, the u se of FPGAs ma y prov e to b e a sup erior alternative. The programmabilit y of FPGAs w ould allo w reconfigurabil- it y b ased on the application and w orkload, and FPGAs pro- vide an attractive p erformance/w att that wo uld lo wer costs for the next generation of d ata centers. 6. CONCLUSION When addressing the hardw are needs of deep learning, FPGAs provide an attractiv e alternativ e to GPUs and GPPs. In particular, the ability to ex ploit pip eline parallelism and ac hieve an efficient rate of p ow er consumption giv e FPGAs a un ique adv antage o ver GPUs and GPPs for common deep learning practices. As well, design to ols hav e matu red to a p oin t where integrating FPGAs into p opu lar d eep learn- ing frameworks is now p ossible. Looking forwar d, FPGAs can eff ectively accommo date the trends of deep learning and provide architectural freedom for exploration and researc h. 7. REFERE NCES [1] Caffe-Op enCL. https://gi thub.com/amd/Ope nCL- caffe/wiki , 2015. [2] Caffe: pro ject greentea. https://gi thub.com/BVLC/ca ffe/pull/2195 , 2015. [3] DeepCL. https://github.co m/hughperkins/De epCL , 2015. [4] Microsoft Research: catapu lt, 2015. [5] Theano: gpuarray backe nd . http://deeplearni ng. net/softwa re/libgpuarray/i ndex.html , 2015. [6] T orc h: cltorch. https://gi thub.com/hughper kins/cltorch , 2015. [7] Xilinx: sdaccel, 2015. [8] D. F. Bacon, R . Rabbah, and S. Shukla. Fpga programming for th e masses. Communic ations of the ACM , 56(4):56–63, 2013. [9] Y. Bengio. Learning deep architectures for ai. F oundations and tr ends R in Machine L e arning , 2(1):1–127 , 2009. [10] Y. Bengio and O. D elalleau. On the expressive p ow er of deep arc hitectures. In Algorithmic L e arning The ory , pages 18–36. Springer, 2011. [11] Y. Bengio, I. J. Goo dfello w, and A. Courville. Deep learning. Bo ok in preparation for MIT Press, 2015. [12] J. Bergstra and Y. Bengio. Random searc h for hyper-parameter optimization. The Journal of Machine L e arning R ese ar ch , 13(1):281–305, 2012. [13] J. Bergstra, O . Breuleux, F. Bastien, P . Lamblin, R. Pasca nu, G. Desjardins, J. T urian, D. W arde-F arley , and Y. Bengio. Theano: A cpu and gpu math compiler in python. In Pr o c. 9th Python in Scienc e Conf , pages 1–7, 2010. [14] S. Cadambi, A. Ma jumdar, M. Becchi, S. Chakradhar, and H. P . Graf. A programmable parallel accelerator for learning and classification. In Pr o c e e dings of the 19th international c onfer enc e on Par al lel ar chite ctur es and c ompilation te chniques , pages 273–284. ACM , 2010. [15] S. Chakradhar, M. Sanka radas, V. Jakkula, and S. Cadambi. A d ynamically configurable copro cessor for conv olutional n eural netw orks. In ACM SIGARCH Computer Ar chite ctur e News , vol ume 38, pages 247–257 . A CM, 2010. [16] S. Chetlur, C. W o olley , P . V andermersch, J. Cohen, J. T ran, B. Catanzaro, and E. Shelhamer. cudn n: Efficien t primitives for deep learning. arXiv pr eprint arXiv:1410.0759 , 2014. [17] J. Cloutier, S. Pigeon, F. R. Bo yer, E. Cosatto, and P . Y. Simard. Vip: An fpga-b ased pro cessor for image processing and neural netw orks. I n micr oneur o , page 330. IEEE, 1996. [18] A. Coates, B. Hu v al, T. W ang, D. W u, B. Catanzaro, and N. A ndrew. D eep learning with cots hp c systems. In Pr o c e e dings of the 30th i nternational c onf er enc e on machine le arning , p ages 1337–1345 , 2013. [19] R. Collobert, S. Bengio, and J. Mari ´ ethoz. T orc h: a mod u lar machine learning softw are library . T ec hnical rep ort, IDI AP , 2002. [20] C. E. Cox and W. E. Blanz. Ganglion-a fast field-programmable gate arra y implementati on of a connectionist classifier. Solid-State Cir cuits, IEEE Journal of , 27(3):288–299, 1992. [21] T. S. Cza jko wski, U. A ydonat, D. Denisenko, J. F reeman, M. Kinsner, D. Neto, J. W ong, P . Yiannacouras, and D. P . Singh. F rom op encl to high-p erformance hardware on fpgas. In Fi eld Pr o gr ammable Lo gic and Applic ations (FPL), 2012 22nd International Confer enc e on , pages 531–534. IEEE, 2012. [22] J. F ang, A . L. V arbanescu, and H . Sips. A comprehensive p erformance comparison of cuda and open cl. In Par al lel Pr o c essing (IC PP), 2011 International Confer enc e on , pages 216–225. IEEE, 2011. [23] C. F arab et, C. Po ulet, J. Y. Han, and Y . LeCun. Cnp: An fpga-based processor for convol utional netw orks. In Fiel d Pr o gr am mable L o gic and Applic ations, 2009. FPL 2009. International C onf er enc e on , pages 32–37. IEEE, 2009. [24] J. F ow ers, G. Bro wn, P . Co oke, and G. Stitt. A p erformance and en ergy comparison of fpgas, gpus, and multicores for sliding-window applications. In Pr o c e e di ngs of the ACM/SIGD A international symp osium on Field Pr o gr ammable Gate Arr ays , pages 47–56. ACM, 2012. [25] D. H. Hub el and T. N. W iesel. Receptive fields and functional architecture of monkey striate cortex. The Journal of physiolo gy , 195(1):215–243, 1968. [26] Y. Jia, E. Shelhamer, J. Donahue, S. Karay ev, J. Long, R. Girshic k , S. Guadarrama, and T. D arrell. Caffe: Con volutional architecture for fast feature em b edd ing. arXiv pr eprint arXiv:1408.5093 , 2014. [27] A. Krizhevsky . On e we ird trick for p aralleliz ing conv olutional neural n etw orks. CoRR , abs/1404.599 7, 2014. [28] A. Krizhevsky , I. Sutskever, and G. E. Hinton. Imagenet classification with deep conv olutional neural netw orks. In A dvanc es i n neur al information pr o c essing syst ems , pages 1097–1105, 2012. [29] Y. LeCun, Y. Bengio, and G. Hinton. Deep learning. Natur e , 521:436–44 4, 2015. N ature Publishing Group, a division of Macmillan Publishers Limited. A ll Rights Reserved. [30] K. Ovtcharo v, O . Ruw ase, J.-Y. Kim, J. F o wers, K. Strauss, and E. S. Chung. Accelerating deep conv olutional neural n etw orks u sing sp ecialized hardwa re. Micr osoft R ese ar ch Whitep ap er , 2, 2015. [31] K. Paul and S. Ra jopadhy e. Back-propagation algorithm achieving 5 gops on the virtex-e. In FPGA Implementations of Neur al Networks , pages 137–165. Springer, 2006. [32] M. Peemen, A. Setio, B. Mesman, H. Corp oraal, et al. Memory-centric accelerator design for con volutional neural netw orks. In Computer Design (ICCD), 2013 IEEE 31st International Confer enc e on , pages 13–19. IEEE, 2013. [33] M. Sanka radas, V. Jakkula, S. Cadam bi, S. Chakradhar, I. Durdanovic, E. Cosatto, and H. P . Graf. A massiv ely parallel copro cessor for conv olutional neural n etw orks. In Appli c ation-sp e cific Systems, Ar chite ctur es and Pr o c essors, 2009. ASAP 2009. 20th I EEE Internat i onal Confer enc e on , pages 53–60. IEEE, 2009. [34] J. Schmidhuber. Deep learning in neural netw orks: A n o verview. Neur al Networks , 61:85–11 7, 2015. Published online 2014; based on TR arXiv:1404.7828 [cs.NE]. [35] J. Sno ek, H . Larochelle, and R. P . Adams. Practical bay esian optimization of machine learning algorithms. In A dvanc es in neur al information pr o c essing syst ems , pages 2951–2959, 2012. [36] C. Zhang, P . Li, G. Su n, Y . Guan, B. Xiao, and J. Cong. Optimizing fpga-based accelerator design for deep conv olutional neural netw orks. In Pr o c e e dings of the 2015 ACM/SIGD A I nternational Symp osium on Field-Pr o gr ammable Gate Ar r ays , pages 161–170. ACM , 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment