FPGA와 딥러닝: 과거·현재·미래의 융합
본 리뷰는 딥러닝 모델 가속에 있어 FPGA가 제공하는 유연성, 전력 효율성 및 설계 도구의 고수준화 추세를 조명한다. GPU와의 비교, 모델 수준 최적화 가능성, 현재 지원 현황 및 향후 연구 방향을 제시한다.
저자: Griffin Lacey, Graham W. Taylor, Shawki Areibi
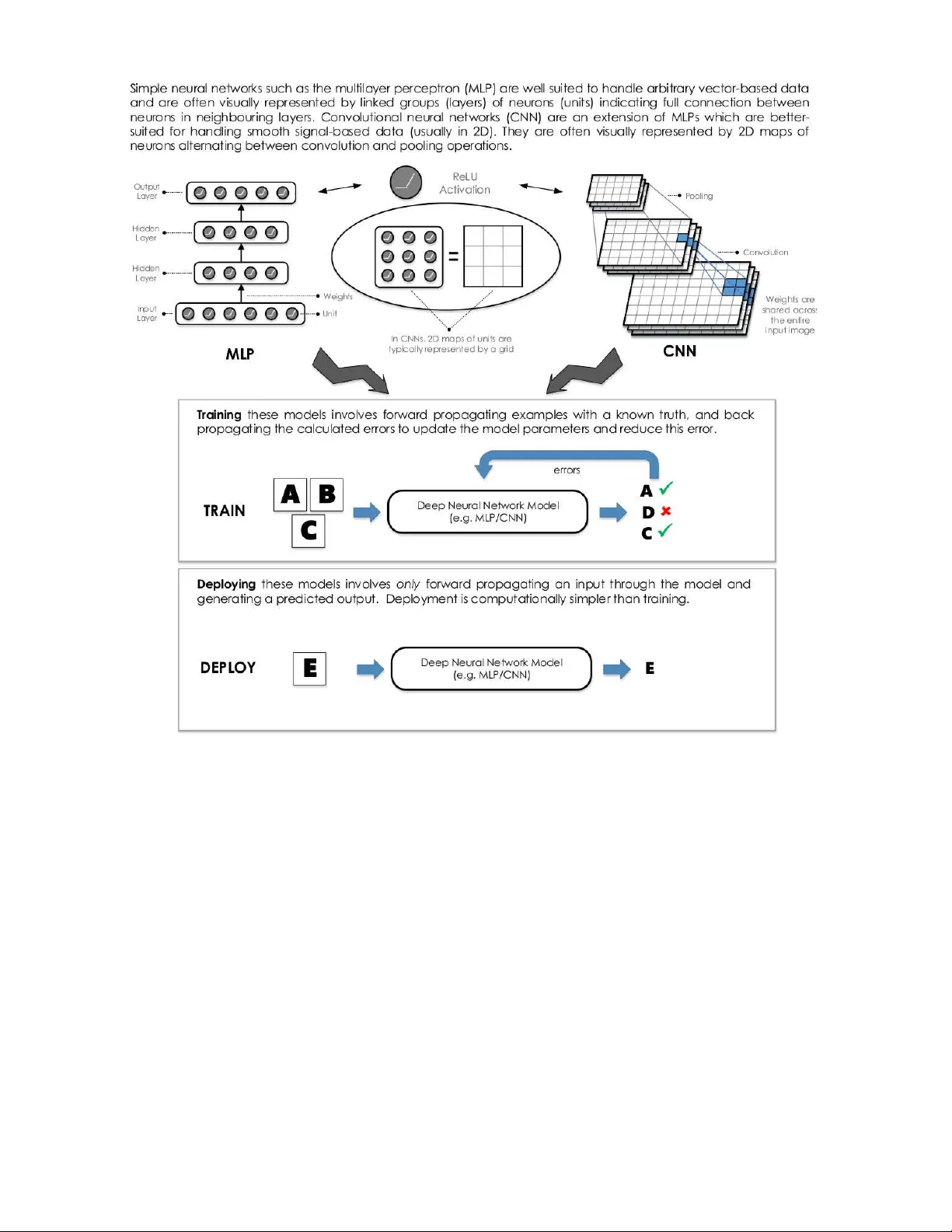
본 논문은 최근 데이터 규모와 인공지능 알고리즘 복잡도가 급격히 증가함에 따라, 딥러닝 모델을 효율적으로 학습·추론하기 위한 하드웨어 가속기의 필요성을 강조한다. 현재 딥러닝 가속의 주류는 GPU 기반 클러스터이며, CUDA와 OpenCL 같은 프로그래밍 모델을 통해 높은 병렬성을 확보하고 있다. 그러나 GPU는 고정된 아키텍처와 전력 효율성의 한계로 인해, 특히 대규모 서버 운영이나 전력 제한이 있는 임베디드 환경에서 제약을 받는다.
이에 대한 대안으로 FPGA가 제시된다. FPGA는 재구성 가능한 논리 블록(LUT, Flip‑Flop, BRAM, DSP)으로 구성되어 있어, 특정 딥러닝 연산에 최적화된 맞춤형 회로를 설계할 수 있다. 논문은 FPGA가 제공하는 주요 장점으로 (1) 높은 Performance‑per‑Watt, (2) 파이프라인 및 데이터 흐름 기반 병렬성, (3) 부분 재구성을 통한 동적 자원 할당, (4) 모델‑레벨 최적화(양자화, 프루닝, 특수 활성화 함수 구현) 등을 제시한다.
다음으로, 딥러닝 모델의 구조적 특성을 살펴본다. MLP와 CNN은 데이터 병렬성, 모델 병렬성, 파이프라인 병렬성이라는 세 가지 주요 병렬성을 내재하고 있다. 특히 CNN은 지역적 수용 영역과 공유 가중치 특성으로 인해 슬라이딩 윈도우 연산이 빈번히 발생하며, 이는 FPGA가 제공하는 맞춤형 데이터 경로와 온‑칩 메모리 활용에 최적화될 수 있다. 논문은 이러한 구조적 특성이 FPGA 설계 시 어떻게 활용될 수 있는지를 구체적인 예시와 함께 설명한다.
설계 도구 측면에서는 전통적인 HDL(Verilog/VHDL)에서 벗어나 OpenCL, C‑based HLS, Xilinx Vitis, Intel oneAPI 등 고수준 합성 툴이 등장하면서, 소프트웨어 개발자가 비교적 낮은 진입 장벽으로 FPGA 가속기를 구현할 수 있게 되었다. 이러한 툴은 자동 파이프라인 생성, 메모리 버퍼 최적화, 부분 재구성 지원 등을 제공해 설계·컴파일 시간을 단축한다. 그러나 여전히 Place‑and‑Route 단계에서 수시간에서 수일이 소요되는 문제와, 대규모 모델을 온‑칩에 모두 매핑하기 어려운 메모리 제약이 존재한다.
논문은 현재 FPGA가 딥러닝 가속에 적용된 사례들을 정리한다. 주요 연구는 MLP와 CNN에 초점을 맞추어, FPGA 기반 컨볼루션 엔진, 매트릭스 곱셈 가속기, 그리고 양자화된 네트워크 구현 등을 다룬다. 또한, FPGA와 GPU를 혼합한 하이브리드 시스템이 제시되었으며, 이는 연산 집약적인 레이어는 GPU, 메모리 효율이 중요한 레이어는 FPGA에서 처리하는 방식으로 성능과 전력 효율을 동시에 향상시킨다.
마지막으로, 향후 연구 방향을 제시한다. (1) 설계 컴파일 시간 단축을 위한 새로운 물리 설계 알고리즘 및 클라우드 기반 컴파일 서비스, (2) 온‑칩 메모리와 고대역폭 인터커넥트 확장을 통한 대규모 모델 지원, (3) 자동화된 모델‑하드웨어 공동 탐색 프레임워크(NAS‑aware FPGA synthesis), (4) 에너지 제한이 있는 엣지 디바이스에서의 실시간 추론을 위한 경량화된 FPGA 보드 개발 등이 있다. 이러한 연구가 진행될 경우, FPGA는 현재 GPU가 차지하고 있는 딥러닝 가속 시장에서 보완적 역할을 넘어, 맞춤형 고효율 가속기로서 독자적인 위치를 확보할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기