On Transitive Consistency for Linear Invertible Transformations between Euclidean Coordinate Systems
Transitive consistency is an intrinsic property for collections of linear invertible transformations between Euclidean coordinate frames. In practice, when the transformations are estimated from data, this property is lacking. This work addresses the…
Authors: Johan Thunberg, Florian Bernard, Jorge Goncalves
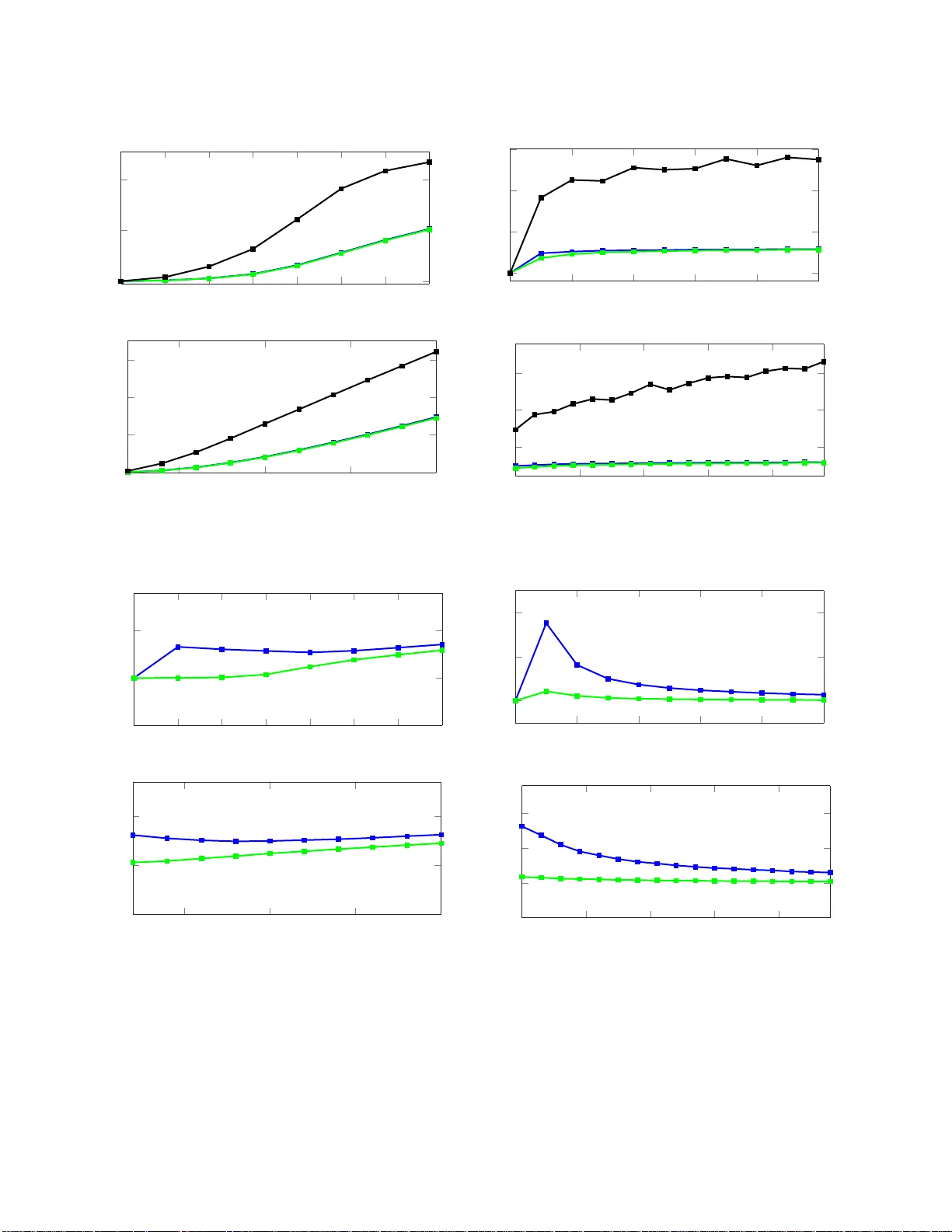
On T ransitiv e Consistency for Linear In v ert ible T ransformations b et ween Euclidean Co ordinate Systems ⋆ Johan Th un b erg a , Florian Bernard a , b , Jorge Goncalves a , c a Luxemb our g Centr e for Systems Biome di cine, University of Luxemb our g, Esch-sur- Alzet te, LUXEMBOURG b Centr e Hospitali er de Luxemb our g, Luxemb our g City, LUXEMBOURG c Contr ol Gr oup, Dep artment of Engine ering, Uni versity of Cambridge, Cambridge, UNITED KINGDOM Abstract T ransitiv e consis tency is an intrinsic prop erty for collections of linear inv ertible transformations b etw een Euclidean co ordinate frames. In practice, when the transformations are estimated from data, this property is lacking. This w ork add resses the problem of sync hronizing transforma tions that are not transitively consisten t. Once the transformations hav e been synchronized, they satisfy the transitive consistency condition – a transformation from frame A to frame C is equal to the comp osite transformatio n of fi rst transforming A to B and then transforming B to C . The co ordinate frames corresp ond to n od es in a graph and the transformations correspond to edges in the same graph. Tw o direct or central ized synchronization methods are presented for different graph top ologies; the first one for quasi-strongly connected graphs, and the second one for connected graphs. As an extension of t he second meth od , an iterative Gauss-Newton metho d is presented, whic h is later adapted to the case of affine and Euclidean tran sformations. Tw o distributed synchronization methods are also presented for orthogonal matrices, whic h can be seen as d istributed ver sions of t he t w o direct or centrali zed metho ds; they are simil ar in nature to standard consensus protocols used for d istributed av eraging. Wh en the transformatio ns are orthogonal matrices, a b ound on the optimalit y g ap can b e computed. Simulations show that the gap is almost tight, even for noise large in magnitude. This w ork als o contributes on a th eoretical level by providing linear algebraic relationships for transitivel y consisten t transformations. On e of the b enefits of the prop osed metho ds is their simplicit y – basic linear algebraic meth od s are used, e.g., the Singular V alue Decomposition (SVD). F or a wide range of parameter settings, the metho ds are numerically val idated. Key wor ds: Distributed optimization, transformation synchronizatio n, Pro crustes problem, consensus algorithms, graph theory . 1 In tro duction Collections of linear inv ertible transformations betw e e n Euclidean co ordinate systems must b e tra nsitively con- sistent. In practice howev er , when the tra ns formations are estimated fr om data, this condition does not ho ld. This issue is present in the 3D lo calization pr oblem, where transformations are rig id and estimated from e.g., camera measurements; in the multiple images registra - tion problem where the transformatio ns are affine (or linear b y using homogeneo us coo rdinates); in the gen- eralized P ro crustes problem where s cales, rotations and ⋆ The authors gratefully ackno wledge th e fin ancial sup - p ort from the F onds National de la Recherc he, Lux embourg (6538106 , 8864515 ). Email addr esses: jo han.thunberg @uni.lu (Johan Thun berg), bernard.fl orian@chl.l u (Fl orian Bernard), jorge.gonc alves@uni.l u (J orge Goncalve s). translations are calculated from m ultiple p oint clouds. I n order to resolve the is s ue, the estimated transforma tions need to b e synchronized in the sense of finding transi- tively consistent transformations close to the estimated ones. 1.1 Pr oblem This work addres ses the problem of synch ronizing lin- ear in vertible transfo rmations or ma trices b etw ee n Eu- clidean co o rdinate systems or frames. More precisely , given a collection { G ij } of matrices in GL ( d, R ), another collection { G ∗ ij } of matrice s in GL ( d, R ) is constructed such that G ∗ ij G ∗ j k = G ∗ ik , for all i, j, k , (1) where G ∗ ij is “c lose” to G ij for a ll i, j . By satisfying (1), the collectio n { G ∗ ij } is sa id to b e transitively consis tent. 1.2 Backgr ound There a re man y applica tions for the pro p o sed metho ds . One such application is the 3D lo calization problem in camera net works [1] where a netw ork of camera s are ob- serving a sc e ne and epip olar geometry is used to c a l- culate/measur e G ij transformatio ns b etw e e n ( i, j )-pairs of camera s. If the camer as a r e fully calibra ted these transformatio ns a r e Euclidean, otherwise they could b e e.g., affine (or linear by using homog eneous co or dinates). Since the transformations are calculated from measure- men ts, they do not satisfy (1) in general. Hence o ur pro - po sed methods ca n b e used to synchronize the matrices. F or the 3D lo caliza tion problem, we do not hav e to limit ourselves to the case of cameras and epipola r ge ome- try . The trans fo rmations could be ca lculated in a setting where the geometry of the s cene is known. In the case of known p oint features, the p ers p ective-n-p oint problem can b e solved in order to ge t estimates of the relative transformatio ns [2]. Another impo rtant pro blem is image regis tration, which has attracted muc h attention in the medical imaging communit y . The num b er of applications is v ast, rang- ing from surger y planning to longitudinal studies. T o register a (mo ving) image with another (fixed) image is to tr ansform the former into the the la tter in such wa y that they fit in the “b est” w ay . F or that, optimization metho ds are used to calculate a tra nsformation which minimizes a suitable ob jective. Registration of m ultiple images po ses a g reater c hallenge. There are several ap- proaches in the literature. F or example: Finding a path of pairwise transfo r mations, whic h contains a ll images [3]; aligning imag es with a reference frame [4]; imag e congealing, where v aria bility along known axes of v ar i- ation is r e mov e d in an iter a tive manner [4 ]; consider - ing a minimum description length (MDL) approach of a statistical s ha p e mo del built from the corresp o ndences given due to g roupwise ima g e registra tion [5]; Bay esian formulations and Exp ected Maximiza tion (EM) [6]. Another w ay to solve the (affine) mu ltiple images regis- tration pr oblem is to use the transitive consistency c ri- terion (1) [7]. Let the G ij corres p o nd to the affine trans - formations calcula ted from pairwise re g istrations, then our metho d can b e us ed to cre a te transitively consistent G ∗ ij transformatio ns. Reg istration metho ds using transi- tive consistency have also b een prop osed for deformable transformatio ns [8,9]. A related pro blem to the one p osed in this pap er is the problem of calculating the “b es t” translations, rotatio ns and scales b etw een pairs o f p oint clouds. If o nly one pair is co nsidered the problem is referred to as the Pr o crustes Problem [10]. This problem ca n be so lved b y means of singular v alue decomp os ition or eigenv alue deco mp o s i- tion [1 1,12,13], o r in the case case of 3D transfor mations, by a quaternion-based approa ch [14,15]. The pr o blem restricted to 3D is refer red to as the abso lute orientation problem [1 3,14]. In the general setting, when n p oint clouds ar e cons ider ed, the problem is re ferred to as the Generalized Procr ustes Problem [10]. In order to solv e this problem, iter ative metho ds are o ften used; w he n the dimension is tw o or thr e e, direct methods have r ecently bee n pr op osed [16]. Our previous work in [17] has tackled the Generalized P ro crustes Pro blem using an appr oach based on tra nsitive consistency . The pr esent pap er will extend and generalize these ideas a s well as describ e many theoretica l proper ties of the generalizations. Our methods c a n b e used for solv ing the Gener alized Pro cr us tes Pro ble m in the following way: Betw een each pair o f p oint clouds a G ij transformatio n is calculated using any s tandard technique [11,12,13], then our meth- o ds ar e use d to improv e the pairwise transfor ma tions b y calculating transitively consistent transformations. In the sp ec ia l case when the G ij are orthog onal ma trices, Singer et al. have presented metho ds for the optimiza- tion of transitive consistency [18,19,20,21]. These works were later adapted by Pachauri et al. to the special case when the G ij are p ermutation matrices [22]. In the latter work, a relaxa tio n of the orig ina l problem is consider ed – in the original problem the transformations shall be o r- thogonal matrices – a nd then per mutation matrices are obtained by means of pro jection from the s olution of the relaxed problem. The metho d presented b y Singer et al. is s a id to b e a synchronization metho d for minimiza tio n of transitive consistency er r ors – a forma lism adopted in this w ork. 1.3 Metho ds and r esult s The a ppr oach in this work shar e s imilarities with the ap- proaches of Singer et al. and Pach auri et al. ; it contin ues along the lines of the the recently propos ed metho ds in [17,23]. In [17,23] a so called Z -matrix is constructed from t he G ij matrices. If the index set fo r the (av ailable) tr a nsfor- mations has a certain prop er ty , transitively consisten t transformatio ns ca n b e obtained b y a metho d where the Singular V alue Decompos ition (SVD) is calc ula ted for Z . The prop er ty that must be fulfilled fo r the index set { ( i, j ) } = E , is that it is the edge set of a qua si-strong ly connected (QSC) directed gr aph (see Definition 2). In the Z -matrix appro ach, a set of linear a lgebraic equa- tions a re formulated – equations which sha ll b e satisfied for the ca se of transitively consistent transformations. When the transforma tions ar e no t transitively consis- ten t, the problem is solved in the sense of least squa res minimization. 2 As we will sho w in this w ork, the Z -matrix a ppea rs in the co nstruction o f a Hess ia n ma trix H for a quadratic conv ex function of the G ij , and under certain co nditions it holds that H = Z + Z T . F rom the SVD of the Hessian matrix H , transitively consis tent transfor mations ca n b e calculated in the sa me manner as for the Z -matrix . The justification for using the H -matr ix stems from the fact that it is the Hessian matrix of the ob jective function in a r elev ant optimization problem. The justification of using the Z -matrix stems purely from the linear alge- braic constra int s that s hould b e satisfied for transitively consistent transfo rmations. The Z -matrix method and the H -matrix metho d ar e bo th direct metho ds , i.e., the solutio n is found at once. As a n e x tension we also pro p ose a n iter ative Gauss- Newton metho d, whic h us e s the so lution from the H - matrix metho d as initialization. F or or thogonal matrices one can prove that this itera tive scheme ca nnot decrea se the ob jective function at a ll. The Gauss-Newton method is also ada pted to the cases of affine and Euclidea n tra ns- formations. In this case – as opp osed to the r esult for orthogo nal matr ices – sig nificant impr ovemen t over the Z -ma tr ix metho d and the H -matrix metho d can b e seen in n umerical simulations. Many prop er ties of the Z - matrix and the H -matrix are prov ed in this work. F or example it is shown that transi- tive consistency in the case of connected graphs is equiv- alent to the condition that the nullspace o f H has dimen- sion d . F urthermore, the tra nsitively co nsistent tr ansfor- mations can be obtained as the d × d blo cks in a matr ix, the columns o f which span the nullspace of H . F or the Z -ma tr ix only a weaker condition is for m ulated; if the graph is Q SC and t he transformations are tra ns itively consistent, the t ransfor mations can be obtained as the d × d blocks in a matr ix, the columns of w hich span the nu llspace of Z . Now, in mos t asp ec ts the H - matrix a pproach seems to b e sup e rior to the Z -matrix approach. How ever, one larg e bene fit of using the Z - ma trix o ver the H -ma trix is tha t it can b e used in a distr ibuted alg o rithm w hen the com- m unication graph is directed. In a la ter part o f the pap er, tw o distributed metho ds are intro duced f or the case of orthogona l G ij transfor- mations. The first metho d is using the Z -matr ix un- der the assumption that the co mm unication graph is directed and QSC. The other metho d is using the H - matrix under the assumption that the communication graph is symmetric. The p erforma nce of the tw o meth- o ds are almost the s ame in n umerical exper iments. The distributed metho ds ar e similar in structure to linea r consensus proto cols [2 4,25,26,27,28]. Key differ ences to those appro aches is that the states here are matrices in- stead of vectors, and the states combined con verge to a d -dimensional linea r subspace instead of the consensus set. The dis tr ibuted iterative metho ds a re intro duced mainly with commu nication b e tween agents in mind, e.g., in net works of rob ots with limit ed communication rang e, where the ro bo ts only communicate w ith their neigh- bo rs (directly o r indirectly). How ever, a further scenario of the distributed metho ds is parallelisatio n in order to better deal with the computational burden in the case of v ery large problem instances. When it is known that the trans itively consistent trans- formations are o rthogona l matrices, i.e., elemen ts of O ( d ) = { R : R ∈ R d × d , R T R = I } , a metho d is pro- vided for calculating an upp er b ound on the optimality gap. In the ca se when the G ij are also o rthogona l, sim- ulations show that this gap is a lmost tig ht . As an exam- ple, for n = 100 coordina te systems, dimension d = 3, and randomly generated G ij matrices in O (3), the g ap is smaller than a tenth of a p ercent in av erage. There are (and will be e ven more in the future) applications where la r ge netw orks of ca meras, rob ots, sa tellites or unmanned v ehicles, ne e d to sync hronize their pairwise relative rota tio ns. In such a pplications methods that are near optimal and run almo s t in re a l time ar e of utmost impo rtance to hav e. 1.4 Outline The pap er pro ceeds as follows. In Section 2, graphs and prop erties thereof are intro duced, fo llowed by the in tro- duction of the G ij transformatio ns and their connections to the graphs. W e have chosen to inco rp orate graphs in the very definition of transitive consistency . Section 3 ad- dresses linear in vertible transfo rmations. In Sec tio n 3.1 , the Z -matrix is introduced, follow ed by a collection of results a nd a lea st squa res metho d. In Section 3.4, the H - matrix is intro duced; in the same manner as in Sec - tion 3.1, a collection of results is pro vided in conjunc- tion with an a lg orithm. In Section 3.7 a Gauss-Newton metho d is presented, where the matrices obtaine d from the H -matrix metho d ar e used as initialization. Sectio n 4 consider the sp ecia l case of ortho gonal matrices, i.e., el- ement s of O ( d ). The sectio n sta rts with s ome bounds on the optimality gap, and contin ues in Se c tion 4 .1 with the in tr o duction of distributed algorithms. The re a der int erested in the distributed metho ds can go direc tly to this section and consult the ear lier sections only for ref- erence. Section 4.2 is a small detour, where a gradient flow metho d is presented for orthogo nal matrice s . This metho d is employ ed as a baseline metho d, use d for com- parison in some o f the simulations in Section 5 – the section where the pr op osed metho ds are thoroughly nu- merically ev aluated. 3 2 Preliminaries 2.1 Dir e cte d Gr aphs Let G = ( V , E ) b e a directed graph, where V = { 1 , 2 , . . . , n } is the no de set and E ⊂ V × V is the e dge set. The set N i is defined b y N i = { j : ( i, j ) ∈ E } . The adjacency matrix A = [ A ij ] for the gra ph G is de- fined b y A ij = 1 if ( i, j ) ∈ E , 0 else. The graph Laplacian matrix is defined b y L = diag( A 1 n ) − A, where 1 n ∈ R n is a vector wit h all en tries equal to 1. In order to emphasize that the adjacency matrix A , the Laplacian matrix L and the N i sets depe nd on the graph G , we may wr ite A ( G ), L ( G ) and N i ( G ) r esp ectively . F or simplicity howev er, we mostly omit this notation a nd simply write A , L , and N i . Definition 1 (connected gr aph, undirected path) The dir e cte d gr aph G is c onne cte d if ther e is an undir e cte d p ath f r om a ny no de in the gr aph to any othe r no de. A n undir e cte d p ath is define d as a (finite) se quenc e of unique no des such t hat for any p air ( i, j ) of c onse cutive no des in the se quenc e it holds that (( i, j ) ∈ E ) or (( j, i ) ∈ E ) . Definition 2 (quasi- strongly co nnected g raph, center, directed path) The dir e cte d gr aph G is quasi-str ongly c onn e cte d (QS C) if it c ontains a c enter. A c en ter is a n o de in the gr aph to which t her e is a dir e cte d p ath fr om any other no de in the gr aph. A dir e cte d p ath is define d as a (finite) se quenc e of unique no des such that any p air of c onse cutive no des in the se quenc e c omprises an e dge in E . Definition 3 (symmetric gr aph) The dir e cte d gr aph G = ( V , E ) is symmetric if (( i, j ) ∈ E ) ⇒ (( j, i ) ∈ E ) for al l ( i, j ) ∈ V × V . Given a graph G = ( V , E ), the graph ¯ G = ( V , ¯ E ) is the graph constructed by re versing the direction of the edges in E , i.e., ( i, j ) ∈ ¯ E if and only if ( j, i ) ∈ E . It is easy to see that A ( ¯ G ) = ( A ( G )) T and L ( ¯ G ) = diag(( A ( G )) T 1 d ) − A ( G ) T . 2.2 T r ansformations Given a directed g raph G = ( V , E ), let there be a co llec- tion of ma trices { G ij } ( i,j ) ∈E where G ij ∈ GL ( d, R ) for all ( i, j ) ∈ E . Let n = |V | . The G ij are not neces sarily transitively consistent in that G ik 6 = G ij G j k may hold if ( i, j ) , ( j, k ) and ( i, k ) are elemen ts of E . In the methods to b e defined, the g oal is to find a tran- sitively cons istent collection { G ∗ ij } ( i,j ) ∈E of matrices in GL ( d, R ), suc h that for all ( i, j ) ∈ E , G ∗ ij is close to G ij in some a ppropriate sense. Notation-wise, G ∗ ij is simply (a na me of ) a ma trix. This notatio n should not be mixed up with the conjugate tr ansp ose – in this paper, all ma- trices considere d a r e real and the conjugate tra ns po se will not be used. Definition 4 (transitive consistency) (1) The matric es in the c ol le ction { G ∗ ij } ( i,j ) ∈V ×V of ma- tric es in GL ( d, R ) ar e transitively consis ten t for the complete graph if G ∗ ik = G ∗ ij G ∗ j k for al l i , j and k . (2) Given a gr aph G = ( V , E ) , the matric es in the c ol le ction { G ∗ ij } ( i,j ) ∈E of matric es in GL ( d, R ) ar e transitively consistent for G if ther e is a c ol- le ction { G ∗ ij } ( i,j ) ∈V ×V ⊃ { G ∗ ij } ( i,j ) ∈E such that { G ∗ ij } ( i,j ) ∈V ×V is tr ansitively c onsistent for the c omplete gr aph. If it is apparent by the context, sometimes we will be less strict and omit to men tion whic h g raph a collection of transformatio ns is transitively consistent fo r. A sufficient condition for tr ansitive consistency of the G ∗ ij matrices for any gra ph is that there is a collection { G ∗ i } i ∈V of matrices in GL ( d, R ) suc h that G ∗ ij = G ∗− 1 i G ∗ j for all i, j . Lemma 6 b elow and the pr o of thereof provides additional impor tant informa tio n. The result is similar to that in [1]. F or the statement of the lemma, the fol- lowing definition is needed. Definition 5 Two c ol le ctions { G ∗ i } i ∈V and { G ∗∗ i } i ∈V of matric es in GL ( d, R ) ar e e qual up to tr ansformation fr om the left, if t her e is Q ∈ GL ( d, R ) such that QG ∗ i = G ∗∗ i for al l i . 4 Lemma 6 F or any gr aph G = ( V , E ) and c ol le ct ion { G ∗ ij } ( i,j ) ∈E of matric es in GL ( d, R ) that ar e tra nsitively c onsistent for G , (1) ther e is a c ol le ct ion { G ∗ i } i ∈V of matric es in GL ( d, R ) such that G ∗ ij = G ∗− 1 i G ∗ j for al l ( i, j ) ∈ E , (2) (2) al l c ol le ctions { G ∗ i } i ∈V satisfying (2) ar e e qual u p to tr ansformation fr om the left if and only if G is c onne cte d, (3) ther e is a un ique c ol le ction { G ∗ ij } ( i,j ) ∈V ×V ⊃ { G ∗ ij } ( i,j ) ∈E of tr ansitively c onsistent matric es for the c omplete gr aph, if and only if al l c ol le ct ions { G ∗ i } i ∈V satisfying (2) ar e e qual up to tr ansforma- tion fr om the left. Pr o of: All matrices a pp ea ring in this pro of, if the con- trary is no t explicitly stated, are as s umed to b e elements of GL ( d, R ). (1) Since the matrices in { G ∗ ij } ( i,j ) ∈E are tr ansitively consistent for G , there is { G ∗ ij } ( i,j ) ∈V ×V ⊃ { G ∗ ij } ( i,j ) ∈E in whic h the matrices are transitively cons istent for the complete graph. Let the G ∗ i in a collection { G ∗ i } i ∈V be defined b y G ∗ i = G ∗ 1 i . W e shall prov e that G ∗− 1 i G ∗ j = G ∗− 1 1 i G ∗ 1 j = G ∗ ij for all i, j. Using the fact that G ∗ 11 is in vertible and the fact that G ∗ 11 = G ∗ 2 11 , one ca n sho w that G ∗ 2 11 = I . No w, G ∗ 1 i G ∗ i 1 = G 11 = I ; th us G ∗− 1 1 i = G ∗ i 1 . But then G ∗− 1 1 i G ∗ 1 j = G ∗ i 1 G ∗ 1 j = G ∗ ij . (2) W e know that transitive consis tency of { G ∗ ij } ( i,j ) ∈E for G is equiv alent to the statement that there is a col- lection { G ∗ i } i ∈V of matrices in GL ( d, R ) suc h that G ∗ ij = G ∗− 1 i G ∗ j for all ( i, j ) ∈ E . Let G ∗ ij = G − 1 i G i for all i, j ∈ V . F or any other collec tion { G ∗∗ i } i ∈V of matrices in GL ( d, R ) suc h that G ∗ ij = G ∗∗− 1 i G ∗∗ j for all ( i, j ) ∈ E , it holds that h G ∗∗ T 1 G ∗∗ T 2 . . . G ∗∗ T n i T = diag ( Q 1 , Q 2 , . . . , Q n ) · h G ∗ T 1 G ∗ T 2 . . . G ∗ T n i T , where the Q i matrices are element s of GL ( d, R ). If : Now, if the gr aph is connected and at le ast tw o of the Q i are not equal, there is ( j, k ) ∈ E suc h that Q j 6 = Q k . W e know G ∗ j G ∗ j k G ∗− 1 k = I d , but since Q j 6 = Q k we ca n calculate this entit y to G ∗ j G ∗ j k G ∗− 1 k = Q − 1 j Q k 6 = I d , which is a c ontradiction. I d ∈ R n × n is the identit y ma- trix. Only if : On the other hand, if the graph is not co nnected there ar e tw o disjoint sets V 1 and V 2 such that V 1 ∪ V 2 = V , for which there is no pair ( i, j ) ∈ E suc h that ( i ∈ V 1 and j ∈ V 2 ) or ( j ∈ V 1 and i ∈ V 2 ). Thus, the no des in V 1 and the corresp onding edges, respective the no des in V 2 and t he corresp onding edges, can be seen as tw o different disconnected (sub)gr a phs, each o f them being connected; the G ∗ i matrices in the first graph can be m ultiplied with a matrix Q 1 from the left and the G ∗ i matrices in the second g raph ca n b e multip lied with a matrix Q 2 from the left, where Q 1 6 = Q 2 , g enerating a collection of matrices { G ∗∗ i } i ∈V not equal to { G ∗ i } i ∈V up to transformation from the left. (3) If: Any other collection { G ∗∗ i ∈V } of matrice s in GL ( d, R ) suc h that G ∗ ij = G ∗∗− 1 i G ∗∗ j for all ( i, j ) ∈ E , is equal to { G ∗ i } up to transformation from the left. Now, for an y ( i, j ) ∈ ( V × V ) − E it holds that G ∗∗− 1 i G ∗∗ j = G ∗− 1 i Q − 1 QG ∗ j = G ∗− 1 i G ∗ j = G ∗ ij for some matrix Q ∈ GL ( d, R ). Only if: The approach here is similar to that in 2) ab ove. Suppo se for { G ∗ i ∈V } satis fying (2), there is another col- lection { G ∗∗ i ∈V } of matrices in GL ( d, R ) a lso sa tisfying (2), but the ma trices in the t wo collections ar e not equal up to transformation from the le ft. Then it holds that h G ∗∗ T 1 G ∗∗ T 2 . . . G ∗∗ T n i T = diag ( Q 1 , Q 2 , . . . , Q n ) · h G ∗ T 1 G ∗ T 2 . . . G ∗ T n i T , where the Q i matrices are elements of GL ( d, R ) and there is a pa ir ( k , l ) for which Q k 6 = Q l . Now G ∗∗− 1 k G ∗∗ l = G ∗− 1 k Q − 1 k Q l G ∗ l 6 = G ∗− 1 k G ∗ l . 5 Lemma 6 states that connectivity is a necessary pr op- erty to determine a unique (up to trans formation from the left) colle ction { G ∗ i } satisfying (2). As it turns out, a stronger type of connectivity – quasi-strong connectiv- it y – is useful in order to dev elop linear algebraic meth- o ds for solving our synchronization problem. The first metho d w e present is based on the so called Z -matrix . 3 Linear in v erti b l e transformations 3.1 The Z -matrix In this sectio n a certa in matrix is defined – referred to as Z . It is used as a building blo ck in a matrix H , cor re- sp onding to the Hessia n of a co nv ex quadratic function, see Section 3 .4. After its definition, its proper ties ar e in- vestigated. Amongst o ther things, it is sho wn that if the G ij transformatio ns are or thogonal, i.e., G T ij G ij = I , the matrix ( − Z ) is (critically ) stable in the linear dynami- cal sys tems sense (cf. Lemma 14). This means that, for directed gr aphs, the matrix Z can b e used in a linear distributed algorithm for synchronizing ortho gonal ma- trices (Section 4.1). Define the matrix W ( G , { G ∗ ij } ( i,j ) ∈E ) = [ W ij ( G ∗ ij )] , where W ij ( G ∗ ij ) = G ∗ ij if j ∈ N i , 0 else, and the matrix Z ( G , { G ∗ ij } ( i,j ) ∈E ) = diag( A ( G )1 ) ⊗ I d − W ( G , { G ∗ ij } ( i,j ) ∈E ) . The symbol ⊗ denotes the Kroneck e r pro duct. Remark 7 A mor e gener al way of c onstructing the W - matrix and the Z -matrix with p ositive weights is as fol- lows. R eplac e the W ij in the definition of W with a ij W ij , and r eplac e diag ( A ( G )1) ⊗ I d in the definition of Z with diag ( X j ∈N 1 a 1 j , X j ∈N 2 a 2 j , . . . , X j ∈N n a nj ) ⊗ I d . The a ij ar e p ositive f or al l i, j . Equivalent r esult s t o al l the r esults obtaine d for the Z -matrix in this se ction c an also b e formulate d for the alternative Z -matrix with p os- itive weights. The alternative Z - m atrix c an b e u s e d in a distribute d algorithm, e qu ivalent to the one t hat will b e pr esente d in Se ction 4.1.1. F or the collection { G ∗ i } i ∈V of matrices in GL ( d, R ), let U 1 ( { G ∗ i } i ∈V ) = h G ∗− T 1 G ∗− T 2 . . . G ∗− T n i T , U 2 ( { G ∗ i } i ∈V ) = h G ∗ 1 G ∗ 2 . . . G ∗ n i . Lemma 8 F or any (QSC) gr aph G = ( V , E ) , c ol le c- tion { G ∗ ij } ( i,j ) ∈E of matric es in GL ( d, R ) – tr ansitively c onsistent for G – and c ol le ct ion { G ∗ i } i ∈V of matric es in GL ( d, R ) it hold s that G ∗ ij = G ∗− 1 i G ∗ j for al l ( i, j ) ∈ E (if and) only if im ( diag ( G ∗ 1 , G ∗ 2 , . . . , G ∗ n ) V ) = ker ( L ⊗ I d ) , (3) for any m atrix V , wher e the c olumns ther e of form a b asis for ker ( Z ( G , { G ∗ ij } ( i,j ) ∈E )) . In p articular, if G is Q S C, (3) c an b e state d as im ( U 1 ( { G ∗ i } i ∈V )) = ker ( Z ( G , { G ∗ ij } ( i,j ) ∈E )) . Pr o of: Only if: Suppose it holds that G ∗ ij = G ∗− 1 i G ∗ j for all ( i, j ) ∈ E . Then Z ( G , { G ∗ ij } ( i,j ) ∈E ) (4) = diag( G ∗− 1 1 , G ∗− 1 2 , . . . , G ∗− 1 n )( L ⊗ I ) · diag( G ∗ 1 , G ∗ 2 , . . . , G ∗ n ) . Now, Z ( G , { G ∗ ij } ( i,j ) ∈E ) V = 0 ⇔ ( L ⊗ I )diag( G ∗ 1 , G ∗ 2 , . . . , G ∗ n ) V = 0 ⇔ im(diag ( G ∗ 1 , G ∗ 2 , . . . , G ∗ n ) V ) = ker( L ⊗ I d ) . If: This part is only pro ven for the case when the graph G is QSC. Since { G ∗ ij } ( i,j ) ∈E is transitively cons is tent for G , there is { G ∗∗ i } i ∈V of matrices in GL ( d, R ) suc h tha t Z ( G , { G ∗ ij } ( i,j ) ∈E ) = diag( G ∗∗− 1 1 , G ∗∗− 1 2 , . . . , G ∗∗− 1 n )( L ⊗ I ) · diag( G ∗∗ 1 , G ∗∗ 2 , . . . , G ∗∗ n ) . Thu s, the n ull-space of Z ( G , { G ∗ ij } ( i,j ) ∈E ) is given by ker( Z ( G , { G ∗ ij } ( i,j ) ∈E )) = im( V ) , 6 where V = diag( G − 1 ∗∗ 1 , G − 1 ∗∗ 2 , . . . , G − 1 ∗∗ n )([1 , 1 , . . . , 1] T ⊗ I d ) . Now, supp ose (3) holds. Then diag ( G ∗ 1 , G ∗ 2 , . . . , G ∗ n ) V = ([1 , 1 , . . . , 1] T ⊗ I d ) Q, where Q is some matrix in GL ( d, R ). This means that diag G ∗ 1 G − 1 ∗∗ 1 , G ∗ 2 G − 1 ∗∗ 2 , . . . , G ∗ n G − 1 ∗∗ n = I n ⊗ Q , which implies that { G ∗∗ i } i ∈V and { G ∗ i } i ∈V are equal up to transforma tio n fro m the left. B y using Lemma 6 we can conclude that G ∗ ij = G ∗− 1 i G ∗ j for all ( i, j ) ∈ E . Remark 9 In L emma 8, the r elation im ( diag ( G ∗ 1 , G ∗ 2 , . . . , G ∗ n ) V ) = ker ( L ⊗ I d ) holds if and only if for any matrix V 2 , wher e the c olumns ther e of c omprise a b asis for ker ( L ⊗ I d ) , ther e is a matrix Q such that diag ( G ∗ 1 , G ∗ 2 , . . . , G ∗ n ) V = V 2 Q. Remark 10 In Le mma 8, if G is c onne cte d but not QSC, it c an hold that A T is the adjac ency m at rix of a QSC gr aph G ′ = ( V ′ , E ′ ) . Then it hold s that im ( U 1 ( { G ∗− T i } i ∈V ) = ker ( Z ( G ′ , { G ∗ T ij } ( i,j ) ∈E ) . Lemma 8 is imp ortant as it provides a wa y of finding ma - trices { G ∗ i } i ∈V fulfilling (2). In the following subsection, this lemma is used to pro vide a least sq uares metho d. 3.2 A le ast squar es metho d Suppo se the graph G = ( V , E ) is QSC, and the colle c tio n { G ij } ( i,j ) ∈E of matr ic e s in GL ( d, R ) are no t tra ns itively consistent for G , but clo se to be ing transitively consis tent (closeness is in the sense of so me matrix norm in R d × d ). Then, motiv ated by Lemma 8, the collec tio n { G ∗ i } i ∈V of matrices in GL ( d, R ) such that (2) holds ca n b e found by using the following a pproach. Algo rithm 1 (1) So lve the problem min V k Z ( G , { G ij } ( i,j ) ∈E ) V k 2 F , where V ∈ R nd × d , V T V = I d . This is done by means o f the Singular V a lue Decomp ositio n of Z ( G , { G ij } ( i,j ) ∈E ). Let V 1 be the optimal so lution. (2) Identify the G ∗ i in the collection { G ∗ i } i ∈V by V T 1 = [ G ∗− T 1 , G ∗− T 2 , . . . , G ∗− T n ] . The algorithm is motiv ated by L e mma 8. Note that the metho d is a pplicable if a nd only if the graph G is QSC, (Lemma 8). In the sp ecia l case when the transforma- tions are known to b e Euclidean (or b e long to some other desirable subset of GL ( d, R )), the co llection { G ∗∗ i } can be o btained by pr o jecting the G ∗ i onto the set o f Eu- clidean transforma tions (or any other desirable subset of GL ( d, R )). If { G ij } ( i,j ) ∈E is close to b eing tra nsitively consisten t, the d × d blo c k matrices in V 1 are in vertible a nd can be identified with the G ∗− T 1 . This is g uaranteed by the following lemma [23]. Lemma 11 In this lemma Z or Z ( G , { G ij } ( i,j ) ∈E ) is fixe d, wher e as the matrix ˜ Z is r e gar de d as a variable i n R nd × nd . L et S 1 = { U ∈ R nd × d : U T U = I } , S 2 ( ˜ Z ) = arg min U ∈S 1 trace( U T ˜ Z T ˜ Z U ) . F or ǫ > 0 , ther e is δ ( ǫ ) > 0 such that if k ˜ Z − Z k F < δ, it holds that for al l U ∈ S 2 ( ˜ Z ) , k U k S 2 ( Z ) < ǫ, wher e k U k S 2 ( Z ) = inf V ∈S 2 ( Z ) k U − V k F . 3.3 F u rther r esults Lo ops in the graph G are essential for the p erfo r mance of Algor ithm 1 – if the graph is QSC and has no lo ops, improv emen t is not p oss ible, see the follo wing lemma. Lemma 12 If the QS C gr aph G is a sp anning tr e e (c on- taining a c en t er), any c ol le ct ion { G ij } ( i,j ) ∈E of matric es in GL ( d, R ) is t r ansitively c onsistent for G . 7 Pr o of: Z ( G , { G ij } ( i,j ) ∈E ) = I ∗ ∗ . . . ∗ ∗ 0 I ∗ . . . ∗ ∗ . . . . . . . . . . . . . . . . . . 0 0 0 . . . I ∗ 0 0 0 . . . 0 0 , where all but one of the ∗ at each (blo ck) row is nonzero and a n invertible matrix. Due to this structur e , there is a colle c tion { G ∗ i } i ∈V of ma trices in GL ( d, R ) s uch that (4) holds, which in turn mea ns that G ij = G ∗− 1 i G j for all ( i, j ) ∈ E . No w since G is QSC, th is means that G ij = G ∗− 1 i G ∗ j for all ( i, j ) ∈ V × V . Due to Lemma 12, if G is QSC and a spanning tree and if { G ij } ( i,j ) ∈E corres p o nds to “distur be d” versions of { G ∗ ij } ( i,j ) ∈E , the solution to Algor ithm 1 will only pro- vide the { G ij } ( i,j ) ∈E once again. Lemma 11 provides us with the p ositive result that the solution to Algorithm 1 dep ends contin uo usly on the G ij transformatio ns. A so mewhat negative r esult is provided by Lemma 13 below. Unfor tunately it is not true that (3) implies transitive consis tency . Lemma 13 L et G = ( V , E ) b e any QSC gr aph satisfying that at le ast one element in t he ve ctor A ( G )[1 , 1 , . . . , 1] T is gr e ater or e qual t o 2. L et { G ∗ ij } ( i,j ) ∈E b e a c ol le ct ion of matric es in GL ( d, R ) , tr ansitively c onsistent for G . L et { G ∗ i } i ∈V b e a c ol le ction of matric es in GL ( d, R ) for which it holds that G ∗ ij = G ∗− 1 i G ∗ j for al l ( i, j ) ∈ E . Now, for any ǫ > 0 , ther e is a c ol le ction { G ij } ( i,j ) ∈E of matric es in GL ( d, R ) that ar e not tr ansitively c onsistent for G such that X ( i,j ) ∈E k G ij − G ∗ ij k F ≤ ǫ , (5) and (3) holds for { G ij } ( i,j ) ∈E and a c ol le ction { G i } i ∈V of matric es in GL ( d, R ) . Pr o of: Suppo se the k th element of the vector A ( G )[1 , 1 , . . . , 1] T is larg er or equal to 2. Then there is l , m such that l 6 = k , m 6 = k , G ∗ kl , G ∗ km ∈ GL ( d, R ). F or 0 < α < 1 let G kl = (1 + α ) G ∗ kl and G km = (1 − α ) G ∗ km . F urthermore , let G ij = G ∗ ij for all ( i, j ) 6∈ { ( k , l ) , ( k , m ) } . It is easy to see that the left-hand side o f (5) is less than or equal to α ( k G ∗ kl k F + k G ∗ km k F ). No w w e choose α < ǫ k G ∗ kl k F + k G ∗ km k F and (5) is sa tisfied. By construction, a ll the G ij are ele- men ts of GL ( d, R ). Let G i = G ∗ i for all i . It ho lds that Z ( G , { G ij } ( i,j ) ∈E ) = diag( G − 1 1 , G − 1 2 , . . . , G − 1 n )(( L + Q ) ⊗ I ) · diag( G 1 , G 2 , . . . , G n ) , where Q = [ Q ij ], Q kl = α , Q km = − α and Q ij = 0 for all ( i, j ) 6∈ { ( k , l ) , ( k , m ) } . Since k er(( L + Q ) ⊗ I ) ⊃ ker ( L ⊗ I ), (3) holds for the G i . Accor ding to Lemma 8, if the G ij are transitively consis tent and G is Q SC, (3) is a condition to guara ntee (2 ). But ( 2) is not fu lfilled since G k G kl G − 1 l = (1 + α ) I . Thus, the G ij are no t transitively consistent. After the introduction of Lemma 13 , one might be lead to belie ve that Algorithm 1 do es not work well in practice. How ever, as will be seen in Section 5, this is definitely not the case. Now, to reca p: T ransitive co nsistency is equiv a lent to (2). Lemma 8 sta tes that when G is QSC and tr ansitive consistency holds, (2) and (3) ar e e q uiv alent. How ever, Lemma 1 3 sta tes that (3) is not eq uiv alent to transitive consistency for QSC graphs. Now we show a sta bilit y prop erty of − Z . If the G ij are transitively consistent, it is easy to see (from (4)) t hat − Z ( G , { G ij } ( i,j ) ∈E ) is critically stable, s ee definition in Lemma 14 below. How ever, the following r esult shows that if the G ij transformatio ns are elemen ts in O ( d ), i.e., G T ij G ij = I for all i, j , t he matrix − Z ( G , { G ij } ( i,j ) ∈E ) is c ritically stable regar dless if trans itive consistency is fulfilled or not. Lemma 14 F or any gr aph G = ( V , E ) and c ol le ction { G ij } ( i,j ) ∈E wher e G ij ∈ O ( d ) for al l ( i, j ) ∈ E , t he matrix − Z ( G , { G ij } ( i,j ) ∈E ) is critic al ly stable, i.e., for any ǫ > 0 , ther e is δ ( ǫ ) such that for x (0) = x 0 ∈ R nd , k x (0) k < δ it holds that k x ( t ) k < ǫ, when ˙ x ( t ) = − Z ( G , { G ij } ( i,j ) ∈E ) x ( t ) . F u rthermor e, if ther e ar e eigenvalues exactly on the imag- inary axis, those eigenvalues ar e e qual to zer o. 8 Pr o of: Let ˙ x ( t ) = − Z x ( t ) , x ( t ) ∈ R nd , (6) where x (0) is the initial state. W e can write x ( t ) as x ( t ) = [ x T 1 ( t ) , x T 2 ( t ) , . . . , x T n ( t )] T , where x i ( t ) ∈ R d for all i . Define the function V ( x ) = max i ( x T i x i ) . If there is some eigenv alue o f Z with nega tive real part or if there is a Jor dan blo c k of dimension larg er than one corres p o nding t o an eigenv alue on the imaginary axis, there is x 0 such that for the state x ( t ) with initial state x 0 , V ( x ( t )) → ∞ as t → ∞ . W e w ant to s how that this is not possible. Let us firs t define the set I max ( t ) = { i : V ( x ( t )) = x T i ( t ) x i ( t ) } . Now, D + ( V ( x ( t ))) = max i ∈I max ( t ) d dt x T i ( t ) x i ( t ) (7) = max i ∈I max ( t ) x T i ( t ) X j ∈N i ( G ij x j ( t ) − x i ( t ) ≤ 0 , where D + is the upper Dini-deriv ative. A pro of of the first equality (7) ca n b e found in [29] using the res ults in [30] and [31]. The result app ea r s frequently in the litera- ture [32 ,3 3]. Now we can us e the Compa r ison Lemma [34] to sho w that V ( x ( t )) is decr easing indep endently of the choice of x 0 . The inequality in (7) is a consequence of the fact that the G ij are orthogo na l matrices. Now we s how that there are no non-zero eigenv alues on the imag inary axis. Suppos e there are non-zer o eigen- v alues o n the imag inary axis, then there must be a nontrivial p erio dic solution ¯ x ( t ) = [ ¯ x T 1 , ¯ x T 1 , . . . , ¯ x T n ] T to (6 ), i.e., ¯ x ( t ) is per io dic and ¯ x ( t 1 ) 6 = ¯ x ( t 2 ) for some t 1 6 = t 2 . It can be shown that D + ( V ( ¯ x ( t ))) = 0 for all t and it ca n also b e shown that a necessar y condition for this to hold is that ¯ x i ( t ) = ¯ x i ( t ) for all t and G ij = I for all ( i, j ). The pro cedure to sho w the latter is a bit int ricate and is based on an induction argument hing- ing on the fact tha t G is QSC. No w, if the G ij 6 = I , the neces s ary condition is not fulfilled, hence we hav e a contradiction. In the case when the G ij = I it ho lds that Z ( G ) = L ( G ) ⊗ I d and the latter matrix do es not hav e any non-zero eigenv alues on the imaginary axis. 3.4 Optimization pr oblems and the H -matrix In this subsection a matrix H is defined a s the Hessia n of a quadratic conv ex function. In the previous subsection the approa ch was to define a set of linear co nstraints, which are fulfilled for transitively consistent transfor - mations, and then use these constrain ts to formulate a least squa res optimization problem. In this section the approach is different. Optimization pr oblems a r e formu- lated dir ectly , without taking a detour via algebraic con- straints. An assumption throughout this section is that G is connected. Given the graph G = ( V , E ) and the collection { G ij } ( i,j ) ∈E of matrices in GL ( d, R ), we for mulate three optimization problems, wher e the the firs t, (P1), cor- resp onds to the ex a ct problem w e wan t to solve. The ob jective function is no n-conv ex and the constra int set is non-compact. The second problem (P 2) is a restric- tion of the first pr oblem having a compact constraint set (with a non-convex ob jective function). In contrast, the third problem (P3 ) has a quadratic convex ob jective function of the G − 1 i as well as a co mpact co nstraint set. (P1) min { G i } i ∈V P ( i,j ) ∈E 1 2 k G ij − G − 1 i G j k 2 F , s.t. G i ∈ GL ( d, R ) . (P2) min { G i } i ∈V P ( i,j ) ∈E 1 2 k G ij − G − 1 i G j k 2 F , s.t. G i ∈ O ( d ) . (P3) min { G i } i ∈V P ( i,j ) ∈E 1 2 k G ij G − 1 j − G − 1 i k 2 F , s.t. U 1 ( { G i } i ∈V ) T U 1 ( { G i } i ∈V ) = Q ≻ 0 . Define the t w o functions f ( { G − 1 i } i ∈V ) = X ( i,j ) ∈E 1 2 k G ij G − 1 j − G − 1 i k 2 F , g ( { G i } i ∈V ) = X ( i,j ) ∈E 1 2 k G ij − G − 1 i G j k 2 F . (8) The matrix Q is symmetric and p ositive definite. W e implicitly assume that g a nd f a re pa rameterized b y { G ij } ( i,j ) ∈E . There is a similar problem to (P3), de- fined b y left-m ultiplication by the G i instead of right- m ultiplication by the G − 1 i : (P4) min { G i } i ∈V P ( i,j ) ∈E 1 2 k G i G ij − G j k 2 F , s.t. U 2 ( { G i } i ∈V ) U 2 ( { G i } i ∈V ) T = Q ≻ 0 , The tw o problems are eq uiv alent. W e choos e to study (P3) instead of (P4) in order to more eas ily see the con- nection b etw e e n the Hessian (the H -ma trix) in the prob- lem and the ma trix Z (cf. Section 3.5). 9 The problem (P2 ) and v ar iants thereof has received at- ten tion lately [1 ]. Exac t so lutions do not e xist in ge n- eral a nd lo cal g radient descent methods are use d. One of the mor e imp ortant co ntributions of this w ork is that we provide a lo wer b ound for the glo bal solution of this problem a s well a s a metho d for which the bound is al- most tigh t in n umerical expe r iments. 3.5 Pr oblem (P3) and its c onne ction to pr oblem (P1) – definition of the H -matrix Let X = U 1 ( { G i } i ∈V ). By a sligh t a buse of notation, let f ( X ) = f ( { G − 1 i } i ∈V ) = X ( i,j ) ∈E 1 2 k G T ij G − 1 i − G − 1 j k 2 F . Now ∇ f ( X ) = X T H ( G , { G ij } ( i,j ) ∈E ) , where H ( G , { G ij } ( i,j ) ∈E ) = Z ( G , { G ij } ( i,j ) ∈E ) + Z 2 ( ¯ G , { ¯ G ij } ( i,j ) ∈ ¯ E ); and Z 2 ( ¯ G , { ¯ G ij } ( i,j ) ∈ ¯ E ) = diag( W ( ¯ G , { ¯ G ij } ( i,j ) ∈ ¯ E ) W ( ¯ G , { ¯ G ij } ( i,j ) ∈ ¯ E ) T ) − W ( ¯ G , { ¯ G ij } ( i,j ) ∈ ¯ E ); ¯ G ij = G T j i for all i, j and ¯ G = ( V , ¯ E ) is the g r aph constructed r eversing the direction of the edg es in G . The op erator diag( · ) is here understo o d in the blo ck- matrix sens e, i.e ., for a matr ix B ∈ R nd × nd , dia g ( B ) = ( I n ⊗ 1 d 1 T d ) ⊙ B , where ⊙ denotes ele ment -wise multi- plication, I n is the n -dimensional identit y matrix and 1 d is the d -dimensional v ector con taining ones. Remark 15 A mor e gener al formulation of the obje ct ive functions f and g with p ositive weights is ˜ f ( { G − 1 i } i ∈V ) = X ( i,j ) ∈E 1 2 a ij k G ij G − 1 j − G − 1 i k 2 F , ˜ g ( { G i } i ∈V ) = X ( i,j ) ∈E 1 2 a ij k G ij − G − 1 i G j k 2 F . The a ij ar e p ositive for al l i, j . This way of defining the obje ctive functions le ad to a slight mo dific ation of the H - matrix. Equivalent r esults to a l l the r esults obtaine d in this se ction for the H -matrix c an also b e formulate d for this alternative definition of the H -matrix with weights. The alternative H -matrix c an al so b e us e d in an e quiv- alent distribute d algorithm t o the one pr esente d in Se c- tion 4.1.2 . Lemma 16 In the sp e cial c ase when al l the G ij ar e ele- ments of O ( d ) , i.e., ortho gonal matric es, Z 2 ( ¯ G , { ¯ G ij } ( i,j ) ∈ ¯ E ) = Z ( ¯ G , { ¯ G ij } ( i,j ) ∈ ¯ E ) . F u rthermor e, if the gr aph G is also symmetric, Z 2 ( ¯ G , { ¯ G ij } ( i,j ) ∈ ¯ E ) = Z ( G , { G ij } ( i,j ) ∈E ) T . Lemma 17 F or any c onne ct e d gr aph G = ( V , E ) , and c ol le ction { G ∗ ij } ( i,j ) ∈E of matric es in GL ( d, R ) , the c ol- le ction { G ∗ ij } ( i,j ) ∈E is t r ansitively c onsistent for G if and only if ther e is a c ol le ction { G ∗ i } i ∈V of matric es in GL ( d, R ) such that im ( U 1 ( { G ∗ i } i ∈V )) ⊂ ker ( H ( G , { G ∗ ij } ( i,j ) ∈E )) . The c ol le ction { G ∗ i } i ∈V satisfies (2) . Pr o of: Supp ose { G ij } ( i,j ) ∈E is tr ansitively consistent, then, according to Lemma 6, there is { G ∗ i } i ∈V such that (2) holds, whic h in turn can b e used to sho w that f ( { G ∗− 1 i } i ∈V ) = U 1 ( { G ∗ i } i ∈V ) T H ( G , { G ∗ ij } ( i,j ) ∈E ) U 1 ( { G i } i ∈V ) = 0 . (9) On the other hand, if { G ∗ ij } ( i,j ) ∈E is not trans itively consistent, there is no { G ∗ i } i ∈V such that (2) holds. It can now b e shown that (9) does not hold for any collec- tion { G ∗ i } i ∈V of matrices in GL ( d, R ). Lemma 18 F or any c onne cte d gr aph G = ( V , E ) and c ol le ction { G ∗ ij } ( i,j ) ∈E of m atric es in GL ( d, R ) – tr ansi- tively c onsistent for G – it holds that dim ( ker ( H ( G , { G ∗ ij } ( i,j ) ∈E ))) = d. Pr o of: D ue to Lemma 17, w e know that dim(ker( H ( G , { G ∗ ij } ( i,j ) ∈E ))) ≥ d. (10) Thu s, w e need to show that the inequality in (10) ca n- not b e strict. Since { G ∗ ij } ( i,j ) ∈E is tr ansitively consis tent , there is { G ∗ i } i ∈V fulfilling (2). Suppo se the inequa lit y is stric t for { G ∗ ij } ( i,j ) ∈E . W e know there is { G ∗ i } i ∈V where G ∗ i ∈ GL ( d, R ) for all i , such tha t im( U 1 ( { G ∗ i } i ∈V )) ⊂ k er( H ( G , { G ∗ ij } ( i,j ) ∈E )) . 10 Now ther e must b e a vector y = [ y T 1 , y T 2 , . . . , y T n ] T ∈ R nd , where the y i are in R d , such that y ∈ ker( H ( G , { G ∗ ij } ( i,j ) ∈E )) , y 6 = 0, and y T U 1 ( { G ∗ i } i ∈V ) = 0. Ther e m ust be k and l such tha t the l th element o f y k is nonzero. The set of transformations { G ∗− 1 k G ∗ i } i ∈V satisfy (2) (Lemma 6) and f ( { ( G ∗− 1 k G ∗ i ) − 1 } i ∈V ) = 0. Now, let ¯ X = [ ¯ x 1 , ¯ x 2 , . . . , ¯ x d ] = U 1 ( { G ∗− 1 k G ∗ i } i ∈V ) , and ¯ Y = [ ¯ x 1 , ¯ x 2 , . . . , ¯ x l − 1 , y , ¯ x l +1 , ¯ x d ] = U 1 ( { G ∗− 1 k G ∗ i } i ∈V ) . W e know that H ( G , { G ij } ( i,j ) ∈E ) ¯ Y = 0. F or all i , let ¯ Y i be the i th d × d blo ck matr ix in ¯ Y . W e know by construction that ¯ Y k ∈ GL ( d, R ). Now, for any j ∈ N k it holds that k G ∗ kj ¯ Y j − ¯ Y k k F = 0 , which implies that ¯ Y j ∈ GL ( d, R ). Also , for any i suc h that k ∈ N i , it holds that k G ∗ ik ¯ Y k − ¯ Y i k F = 0 , which implies that ¯ Y i ∈ GL ( d, R ). Now, due to the fact that G is connected, an induction argument can b e used to sho w that all the ¯ Y i are element s in GL ( d, R ). The collection { ¯ Y i } i ∈V satisfies G ∗ ij = ¯ Y i ¯ Y − 1 j for all ( i, j ) ∈ E . It is ea sy to see that the t wo collections { ¯ Y − 1 i } i ∈V and { ¯ G ∗ i } i ∈V are no t equal up to transfor mation fro m the left. But, since the gr aph is co nnected, the t wo m ust b e equal up to transfor mation from the left (Lemma 6). This is a contradiction. Hence it is a false assumption that the inequalit y in (10) is strict. W e summar ize the results of Lemma 17 and Lemma 18 in the followin g prop osition. Prop ositi on 19 The c ol le ction { G ∗ ij } ( i,j ) ∈E is tr ansi- tively c onsistent for the c onne ct e d gr aph G if and only if t her e is a c ol le ction { G ∗ i } i ∈V of matric es in GL ( d, R ) such that im ( U 1 ( { G ∗ i } i ∈V )) = ker ( H ( G , { G ∗ ij } ( i,j ) ∈E )) . The G ∗ i satisfy (2) . Pr o of: Direct application of Lemma 17 and Le mma 18 . The following prop osition provides a simila r, but some- what stronger result. Prop ositi on 20 The c ol le ction { G ∗ ij } ( i,j ) ∈E of matric es in GL ( d, R ) is tr ansitively c onsistent for the c onne ct e d gr aph G i f and only if dim ( ker ( H ( G , { G ∗ ij } ( i,j ) ∈E ))) = d. Pr o of: If: Le t ¯ Y = [ y 1 , y 2 , . . . , y nd ] T ∈ R nd × d be a ny full rank matrix such that H ( G , { G ∗ ij } ( i,j ) ∈E ) ¯ Y = 0 . All the y i ∈ R d . Let ¯ Y i be the i th d × d block ma tr ix in ¯ Y . Since ¯ Y is full rank, there is a (finite) sequence { y i j } d j =1 such that [ y i 1 , y i 2 , . . . y i d ] ∈ GL ( d, R ). Now, for k ∈ V w e know that for any j ∈ N k it holds that k G ∗ kj ¯ Y j − ¯ Y k k F = 0 , which implies that im( ¯ Y T j ) = im( ¯ Y T k ). Also, for any i such that k ∈ N i , it holds that k G ∗ ik ¯ Y k − ¯ Y i k F = 0 , which implies that im( ¯ Y T i ) = im( ¯ Y T k ). Now, due to the fact that G is connected, an induction ar gument can b e used to show that im( ¯ Y T j ) = im( ¯ Y T i ) for all i, j . But then im([ y i 1 , y i 2 , . . . y i d ]) ⊂ im( ¯ Y T j ) for all j, which together with the fact that [ y i 1 , y i 2 , . . . y i d ] ∈ GL ( d, R ) is full rank, can b e us e d to s how that ¯ Y i ∈ GL ( d, R ) for all i . Th us, im( U 1 ( { ¯ Y − 1 i } i ∈V )) = ker( H ( G , { G ∗ ij } ( i,j ) ∈E )) , and the desired result follows from Prop ositio n 19 w he r e the G ∗ i are replaced b y the ¯ Y − 1 i . Only if: Direct application of Lemma 18. Lemma 21 The optimal solution to (P3) is X ∗ = V P , wher e P ∈ R d × d , and V ∈ R nd × d . The matrix V is given by the solution to t he pr oblem (P5) ( min W tr ac e ( W T H ( G , { G ij } ( i,j ) ∈E ) W ) , W ∈ R nd × d , W T W = I . 11 and P is given by the solution to the pr oblem (P6) ( min ˜ P tr ac e ( ˜ P T ( V T H ( G , { G ij } ( i,j ) ∈E ) V ) ˜ P ) , ˜ P ∈ R d × d , ˜ P T ˜ P = Q. Pr o of: In the new notation, problem (P3) is written as ( min W , ˜ P trace( ˜ P T ( W T H ( G , { G ij } ( i,j ) ∈E ) W ) ˜ P ) , ˜ P ∈ R d × d , ˜ P T ˜ P = Q, W ∈ R nd × d , W T W = I . In the following deriv atio ns it is a ssumed tha t ˜ P and W belong to the constra int sets defined in the pr oblem ab ov e. min W , ˜ P trace( ˜ P T ( W T H ( G , { G ij } ( i,j ) ∈E ) W ) ˜ P ) = min W , ˜ P trace( ˜ P T ( Q T ( W ) D ( W ) Q ( W )) ˜ P ) = min W , ˜ P trace( ˜ P T D ( W ) ˜ P ) = min ˜ P trace( ˜ P T ( V T H ( G , { G ij } ( i,j ) ∈E ) V ) ˜ P ) , where Q T ( W ) D ( W ) Q ( W ) is the spe c tr al factorization of W T H ( G , { G ij } ( i,j ) ∈E ) W . Prop ositi on 22 F or any Q 1 ≻ 0 and Q 2 ≻ 0 let { G ∗ i } i ∈V and { G ∗∗ i } i ∈V b e the tr ansformations obtaine d fr om the optimal solutions of pr oblem (P3) with Q e qual to Q 1 and Q e qual to Q 2 r esp e ctively. It holds that g ( { G ∗ i } i ∈V ) = g ( { G ∗∗ i } i ∈V ) , i.e., the value of g is indep endent of Q . Pr o of: According to Lemma 21 the trans formations are equal up to transformation from the left. Remark 23 It i s imp licitly assume d in Pr op osition 22 that the G ∗ i and t he G ∗∗ i ar e in GL ( d, R ) . This is guar an- te e d if the G ij ar e sufficiently close to b e tr ansitively c on- sistent. The re sult to gu ar ante e this is omitte d but anal- o gous to the statement in L emma 11 for the Z -matrix. Lemma 24 F or any gr aph G = ( V , E ) and c ol le ction { G ij } ( i,j ) ∈E wher e G ij ∈ GL ( d, R ) for al l ( i, j ) ∈ E , the matrix − H ( G , { G ∗ ij } ( i,j ) ∈E ) is critic al ly stable, i.e., for any ǫ > 0 , ther e is δ ( ǫ ) such that for any x (0) = x 0 ∈ R nd , k x (0) k < δ it hold s that k x ( t ) k < ǫ, when ˙ x ( t ) = − H ( G , { G ∗ ij } ( i,j ) ∈E ) x ( t ) . Pr o of: The matr ix H ( G , { G ∗ ij } ( i,j ) ∈E ) is the Hessian matrix and hence positive semi-definite. 3.6 A le ast squar es metho d Prop os itio n 22 is impo rtant, it states that w e can with- out loss of generality assume tha t Q = I , since the choice of Q does no t affect the v alue of g , i.e., the cost function we wan t to minimize. The v alue of f changes with Q , but this is of less imp ortance. Motiv ated by these r esults we intro duce a least s quares metho d along the lines of Algorithm 1. Algo rithm 2 (1) Let V 1 be the optimal solution to problem (P5). (2) Identify the G ∗ i in the collection { G ∗ i } i ∈V by V T 1 = [ G ∗− T 1 , G ∗− T 2 , . . . , G ∗− T n ] . The algorithm is motiv a ted b y Prop os ition 19 and Prop os itio n 2 2. If the collection { G ij } ( i,j ) ∈E is clo se enough to be transitively cons is tent , s tep 2) can b e executed, i.e., eac h d × d s ub-blo ck o f the ma trix V 1 is inv er tible. The result that guarantees this is analog o us to the statemen t in Lemma 11. 3.7 A Gauss-Newton metho d In this section a Ga us s-Newton metho d is presented. The solution obtained in Algorithm 2 is used as the initial- ization for the algorithm. The F r´ ec het deriv atives of the identit y map and the in- verse map at the po int G i in the direction E i are given by L id ( G i , E i ) = E i , L inv ( G i , E i ) = − G − 1 i E i G − 1 i , resp ectively . Higham [35] provides a go o d intro ductio n to F r´ ec het der iv atives for matrix functions . Let { E i } i ∈V be a collectio n of matrices in R n × n . It holds that g ( { G i + E i } i ∈V ) = X ( i,j ) ∈E 1 2 k G ij − G − 1 i G j − G − 1 i L id ( G j , E j ) − L inv ( G i , E i ) G j + o ( k [ E i , E j ] k 2 F ) k 2 F . 12 Let ¯ g ( { G i } i ∈V , { E i } i ∈V ) = X ( i,j ) ∈E 1 2 k G ij − G − 1 i G j − G − 1 i L id ( G j , E j ) − L inv ( G i , E i ) G j k 2 F = X ( i,j ) ∈E 1 2 k G ij − G − 1 i G j − G − 1 i E j + G − 1 i E i G − 1 i G j k 2 F . Consider the following proble m (P7) n min { E i } i ∈V ¯ g ( { G i } i ∈V , { E i } i ∈V ) . Problem (P 7) is solved in each Gauss-Newton step of the metho d we pr e s ent below (Algor ithm 3). Its solution is given by the collection { E ∗ i } i ∈V obtained by vec ( U 2 ( { E ∗ i } i ∈V )) = x, (11) where x is obtained b y the s olution of H GN ( { G i } i ∈V , { G ij } ( i,j ) ∈E ) x = − c GN ( { G i } i ∈V , , { G ij } ( i,j ) ∈E ); (12) vec ( · ) is the vectorizatio n op erato r, i.e., it r eturns a vec- tor with the stacked columns (in consecutive or der) of its matrix-ar gument. The matrix H GN ∈ R nd 2 × nd 2 and the vector c GN ∈ R nd 2 are defined a s follows (for simplicit y we hav e omitted the explicit dep endence of { G i } i ∈V and { G ij } ( i,j ) ∈E ): H GN = [ ¯ H ij ] , where ¯ H ij ∈ R d 2 × d 2 for all i, j . When i 6 = j , ¯ H ij is defined b y ¯ H ij = 0 if ( j 6∈ N i ) , ( i 6∈ N j ) , − (( G − 1 i G j ) ⊗ ( G − T i G − 1 i )) if ( j ∈ N i ) , ( i 6∈ N j ) , n − (( G T i G − T j ) ⊗ ( G − T j G − 1 j )) if ( j 6∈ N i ) , ( i ∈ N j ) , − (( G − 1 i G j ) ⊗ ( G − T i G − 1 i )) − (( G T i G − T j ) ⊗ ( G − T j G − 1 j )) if ( j ∈ N i ) , ( i ∈ N j ) . When i = j , ¯ H ii is defined b y ¯ H ii = X j ∈N i (( G − 1 i G j G T j G − T i ) ⊗ ( G − T i G − 1 i ))+ X { j : i ∈N j } I d ⊗ ( G − T j G − 1 j ) . Now, c GN = [ c T 1 , c T 2 , . . . , c T n ] T , where c i ∈ R d 2 for all i . The c i are defined b y c i = X j ∈N i (( G − 1 i G j ) ⊗ G − T i )vec( G ij − G − 1 i G j ) − X { j : i ∈N j } I d ⊗ G − T j vec ( G j i − G − 1 j G i ) . Algo rithm 3 (1) Run Algorithm 2 and let { G ∗ i } i ∈V bet the collection of matrices obtained in step (2) of that a lgorithm. (2) Let R d × d ∋ E ∗ i = 0 for i = 1 , 2 , . . . , n . (3) rep eat: (a) G i → G i + E ∗ i for all i, (b) Up date the E ∗ i by (11) a nd (12), i.e., vec ( U 2 ( { E ∗ i } i ∈V )) = x, where x is the solution to (12). The stoping criteria in step (3 ) of Algorithm 5 could be that the improv ement of the co s t function is smalle r than a certa in thre s hold for t wo consecutive iterations, or it could be that a certa in num b er of iterations hav e bee n executed etc. It should be noted that H GN is both po sitive definite and spars e. In order to solve (12) one can use for example the Co njugate Gradient metho d [36,37]. 3.8 Affine and Euclide an tr ansformations In this subsec tion we c o nsider affine and Euclidea n tra ns- formations. These transfor mations are linear when ho- mogenous co o rdinates are us e d. T o b e more precise, an element in Aff( d, R ) is a matrix G = " Q t 0 1 # , where Q ∈ GL ( d, R ), t ∈ R d and 1 is a sca lar. Its inv er se is giv en b y G − 1 = " Q − 1 − Q − 1 t 0 1 # . 13 Euclidean tr a nsformations , E ( d ), is a sp ecial ca se of affine transformations where the matrix Q ∈ O ( d ). F or any co nnected g raph G = ( V , E ) (due to Lemma 6), if and only if the collection { G ∗ ij } ( i,j ) ∈E is transitively con- sistent a nd co ntains only affine transfo r mations, there is a unique (up to transformation from the left by a ffine transformatio ns) co llection { G i } i ∈V of affine transfor- mations suc h that G ∗ ij = G − 1 i G j . Each G i is given by G = " Q i t i 0 1 # , and eac h G ∗ ij is given by G ∗ ij = " Q − 1 i Q j Q − 1 i ( t j − t i ) 0 1 # . Now, let { G ∗ ij } ( i,j ) ∈E be a collection of matr ices in Aff( d, R ) that ar e no t necessar ily trans itively consistent. It holds that (b y a slight abuse of notation) g ( { G i } i ∈V ) = X ( i,j ) ∈E 1 2 k G ij − G − 1 i G j k 2 F = g ( { Q i } i ∈V ) + X ( i,j ) ∈E 1 2 k t ij − Q − 1 i ( t j − t i ) k 2 F , (13) where t ij is the trans lational par t of the transformation G ij . W e see that there is a sp ecial structure of (13), where the cost function cons is ts o f t wo par ts. The first part is only a function o f the Q i , wher e as the second par t is a function of both rotatio ns and tra nslations. Define the follo wing optimization problem (P8) min { t i } i ∈V P ( i,j ) ∈E 1 2 k t ij − Q − 1 i ( t j − t i ) k 2 F . Let c Aff = [ c T 1 , c T 2 , . . . , c T n ] T , where c i = X j ∈N i Q − T i t ij − X { j : i ∈N j } Q − T j t j i . Let H Aff = [ ˜ H ij ] , where ˜ H ij ∈ R ( d − 1) × ( d − 1) for all i , j . When i 6 = j , ˜ H ij is defined b y ˜ H ij = 0 if ( j 6∈ N i ) , ( i 6∈ N j ) , − Q − T i Q − 1 i if ( j ∈ N i ) , ( i 6∈ N j ) , n − Q − T j Q − 1 j if ( j 6∈ N i ) , ( i ∈ N j ) , − Q − T i Q − 1 i − Q − T j Q − 1 j if ( j ∈ N i ) , ( i ∈ N j ) . When i = j , ˜ H ii is defined b y ˜ H ii = X j ∈N i Q − T i Q − 1 i + X { j : i ∈N j } Q − T j Q − 1 j . The matrix H Aff and the vector c Aff depe nd on { G i } i ∈V and { G ij } ( i,j ) ∈E . The solutions to the problem (P8) is given by the ele- men ts in the set {{ t i } i ∈V : H Aff [ t T 1 , t T 2 , . . . , t T n ] T = − c Aff } . The Gauss-Newton metho d de velop ed in Section 3 .7, i.e., Algorithm 3, can be adapted to the case of affine transformatio ns. Now w e r equire that E i ⊙ B = E i for all i, where B = " 1 d 1 T d 1 d 0 0 # . W e remind the rea der that ⊙ denotes element-wise m ul- tiplication. In each iteration (in the mo dified s tep (3) of Algorithm 3) the collection { E ∗ i } i ∈V is obtained by vec ( U 2 ( { E ∗ i } i ∈V )) = x, (14) where x = X v , v is obtained by the so lution to X T H GN X v = − X T c GN , (15) and X ∈ R nd 2 × n ( d − 1) d is defined below. X = I n ⊗ ( I d ⊗ ¯ B ) , 14 where ¯ B = " I d − 1 0 # ∈ R d × ( d − 1) . Now we pr e s ent the following algor ithm for a ffine trans- formations. Algo rithm 4 (1) Run Algorithm 2 for the c o llection { Q ij } ( i,j ) ∈E and let { Q i } i ∈V be the matrices obtained in s tep (2) o f that algorithm. (2) So lve problem (P8) for the t i using the Q i from (1) and let G i = " Q i t i 0 1 # for all i. (3) Let R d × d ∋ E ∗ i = 0 for i = 1 , 2 , . . . , n . (4) whi le a stoping criteria has no t been met: (a) G i → G i + E ∗ i for all i, (b) Up date the E ∗ i by (14) a nd (15), i.e., vec ( U 2 ( { E ∗ i } i ∈V )) = x, where x is the solution to (14). Remark 25 Ther e ar e many variations of Algorithm 4 that c an b e employe d. The most simple one is to omit steps (3) and (4). Another one is to run the Gauss- Newton metho d (Algorithm 3) for the Q i matric es after step (2). The expr ession in (13 ) c an also b e ch ange d to include weigh ts. F or example, if the ortho gonal matric es ar e closer to b e t r ansitively c onsisten t than the tra nsla- tions, the first p art of the expr ession, i.e., g ( { Q i } i ∈V ) , c ould b e weighte d with a p ositive weight lar ger than 1 . Remark 26 After a slight mo dific ation, Algo rithm 4 c an b e use d for Euclide an tr ansformations i nste ad of affine ones. In this c ase Al gorithm 5 ( s e e Se ction 4) is use d in (1) to gener ate the Q i tr ansformations inste ad of Al- gorithm 2. Numeric al simulations (se e Se ction 5) show that this is a go o d metho d in c omp arison to Algo rithm 1 or Algo rithm 2 (wher e the matric es ar e final ly pr oje cte d onto the set of Euclide an tr ansformations E ( d ) ). 4 Orthogonal matrices In this section pr oblem (P2) is studied. F or or tho gonal matrices the ob jective functions f and g are equiv alent. The Ga uss-Newton method (Algo rithm 3) is henc e not necessary . F ur thermore, the o rthogona l matrices is an impo rtant clas s of matrices, not the least in dimension d = 3 . W e b egin by formulating the fo llowing result. Prop ositi on 27 F or the c onne cte d gr aph G = ( V , E ) , let { G ij } ( i,j ) ∈E b e a c ol le ction of matric es in GL ( d, R ) . L et { G i } i ∈V b e a c ol le ction o f matric es obtaine d fr om Alg o- rithm 2. L et { G ∗ i } i ∈V b e a c ol le ction of matric es solving the optimizatio n pr oblem (P2). It holds that f ( { √ nG − 1 i } i ∈V ) ≤ g ( { G ∗ i } i ∈V ) . Pr o of: It is easy to verify that for o rthogo na l matrices, (P3 ) is a relaxatio n of (P2) when Q = nI . Now, (Prop osition 22) the so lution to (P3 ) with Q = nI is provided by the ma- trices obtained b y Algorithm 2 after scaling b y 1 √ n . Let us now e xtend Algo rithm 1 (Algorithm 2) in the following wa y . Algo rithm 5 (1) Sa me as in Algorithm 1 (same as in Algor ithm 2). (2) Sa me as in Algorithm 1 (same as in Algor ithm 2). (3) Let G ∗∗ i be the pro jection o f G ∗ j onto O ( d ), i.e., G ∗∗ i = Q V T , where QD V T is the SVD of G ∗ i . Let G ∗ ij = G T ∗∗ i G ∗∗ j . The collection { G ∗ ij } ( i,j ) ∈E is the final transitiv ely consistent collectio n. Prop os itio n 2 7 can now be used to provide pe r formance guarantees. An upper b ound on the closenes s to opti- mality is given by g ( { G ∗∗ i } i ∈V )) − f ( √ nG ∗− 1 i } i ∈V ) , (16) where the G ∗ i are o btained from Algorithm 2 and the G ∗∗ i are obtained from Algorithm 5 – assuming the first t wo steps are the same as in Algorithm 2. If the G ij are a ls o elements in O ( d ), the difference in (16) is almost tight. F or example, in the case when d = 3, n = 10 0, and the G ij are generated from G i -matrices and R ij -matrices matrices b y G ij = G − 1 i G j R ij ( R ij is an orthog onal matr ix with g eo desic distance to I less or 15 equal to π / 4. It is generated by drawing a s kew s ymmet- ric matrix from the uniform distribution ov er the closed ball with r adius π / 4 and then taking the matrix expo- nent ial of that matrix). Let h ( { G ∗∗ i } i ∈V , { G ∗− 1 i } i ∈V ) = g ( { G ∗∗ i } i ∈V )) − f ( { √ nG ∗− 1 i } i ∈V ) f ( { √ nG ∗− 1 i } i ∈V ) . (17) F or 1000 exp eriments we observe that h ( { G ∗∗ i } i ∈V , { G ∗− 1 i } i ∈V ) ≤ 6 ∗ 10 − 4 . This means that the so lution obtained b y Algorithm 5 is closer than 0 . 0 6% to the global optimum of problem (P2). The gra phs in these exp er iments w ere QSC and the adjacency matrices cont ained 100 zero en tries. 4.1 Distribute d algorithms In this subse c tion we s how that Algor ithm 5 can b e implemen ted in a distributed wa y . Beside s the g raph G = ( V , E ), which describ es what transforma tio ns are av aila ble, another graph G com = ( V , E com ) is used. It is alwa ys assumed E ⊂ E com . The graph G com is referred to as the c ommunic ation gr aph . The as sumptions on the communication graph G com differ b etw een the tw o pr e - sented algor ithms. 4.1.1 Ortho gonal matric es and Q SC c ommunic ation gr aph Here it is a ssumed that all transformations a re orthog- onal matr ices, i.e., elements in O ( d ). Tha t is, the G ij matrices as well a s the G ∗ ij matrices and the G ∗ i matrices are assumed to be elements in O ( d ). The algor ithm will now b e pr esented, after which an ex- planation and justification is provided. I n this algo rithm it is assumed that G = G com is QSC. The notation N i is used to denote N i ( G ) = N i ( G com ). Algo rithm 6 Let X (0) = [ X T 1 (0) , X T 2 (0) , . . . , X T n (0)] T , where, for all i , the element s of the matr ix X i (0) ∈ R d × d are dr awn from U ( − 0 . 5 , 0 . 5), i.e., the uniform distr ibu- tion with the o p e n in ter v al ( − 0 . 5 , 0 . 5) as s uppo rt. Let X i ( t ) for t ∈ N b e defined b y the following distributed algorithm: X 1 ( t + 1) = X 1 ( t ) + ǫ X j ∈N 1 ( G 1 j X j ( t ) − X 1 ( t )) , X 2 ( t + 1) = X 2 ( t ) + ǫ X j ∈N 2 ( G 2 j X j ( t ) − X 2 ( t )) , . . . X n ( t + 1) = X n ( t ) + ǫ X j ∈N n ( G nj X j ( t ) − X n ( t )) , where ǫ > 0 .1 In compact notation this is written as X ( t + 1) = X ( t ) − ǫZ ( G , { G ij } ( i,j ) ∈E )) X ( t ) . (18) F or a sufficient ly large t , let G T ∗ i be the pro jection of X i ( t ) onto O ( d ), and let G ∗ ij = G T ∗ i G ∗ j for all i, j . It should b e noted that if the sp ectral r adius is no t known, in practice it is enough to c hoo se ǫ to something small. Analy sis of the algorithm In this section the theor etical a na lysis o f the algor ithm is provided. The firs t thing we need to guara ntee is that the matrix I − ǫZ ( G , { G ij } ( i,j ) ∈E ) , app earing in the right-hand side of the discrete time lin- ear sy stem (18 ), is critically stable in the linear dynami- cal s ystems sense. This means that all eigen v alues m ust be smaller than or equa l to 1 in absolute v alue and any Jordan- blo c k co rresp onding to an eigenv alue whose ab- solute v alue is 1 m ust be o ne - dimensional [38]. Lemma 28 If G ( V , E ) i s QSC a nd ǫ > 0 smal l en ough it holds that I − ǫZ ( G , { G ij } ( i,j ) ∈E ) is critic al ly stable. Pr o of: According to Lemma 14 it holds that Z is crit- ically sta ble and ha s no non-zero eig env alues on the imaginary axis. This means that for ǫ small enough the eigenv alues o f ǫZ ( G , { G ij } ( i,j ) ∈E ) are lo cated in the closed unit disc cen tered at − 1; the eigenv alues o n the bo undary are simple. Remark 29 Num eric al simulations se em to indic ate that in pr actic e one c an cho ose ǫ ∈ 0 , 1 ρ ( Z ( G , { G ij } ( i,j ) ∈E )) , wher e ρ ( Z ( G , { G ij } ( i,j ) ∈E )) is the sp e ctr al r adius. 16 Now we c an deduce that if ǫ is chosen small eno ug h, X ( t ) conv erges (to something). It eas y t o verify (Lemma 8) that if the G ij were transitiv ely co ns istent, X ( t ) w ould conv erge with exp o nent ial rate of con vergence to ¯ X = [ ¯ x 1 , ¯ x 2 , . . . , ¯ x d ] = [ ¯ X T 1 , ¯ X T 2 , . . . , ¯ X T n ] T , where ¯ x i is the pro jection o f the i th column of X (0) onto k er( Z ) and ¯ X i ∈ R d × d for all i . Since the X i (0) are drawn from the distribution ( U ( − 0 . 5 , 0 . 5)) d × d , it is extremely unlikely that (probability ze r o) ¯ X has not full rank. If all the ¯ X i are full rank matrices, G ij = ¯ X i ¯ X T j for all i, j. Now, if the G ij are not transitively consistent, in gener al the X i ( t ) conv er ge to 0, whic h is not fav orable. How- ever, if the G ij are close to b eing transitiv ely cons istent, since the eig env alues o f Z are co nt inuous in the G ij , the d smallest eigen v alues are significantly smaller in mag - nitude than the o ther eigenv alues; also the d s mallest singular v alues are s ig nificantly smaller than the o ther singular v alues. Up to rotation, the rig ht-singular vec- tors corr esp onding to the d smalles t singular v a lues are contin uous in the G ij , see Lemma 11. Let the right-singular vectors corresp onding to the d smallest singula r v a lues comprise the columns of the ma- trix Y ∈ R nd × d . The matrix Y is e q ual to V obtained in the first step of Algo rithm 1 (up to tra nsformation from the left). No w, as t → ∞ , under the a ssumption that the G ij are clo se to the G ∗ ij , the columns of X ( t ) con- verge to im( Y ) muc h faster than X ( t ) conv erges to 0. Thu s, for t large enoug h X ( t ) is approximately equal to Y up to tr a nsformation from the left. This co nv er gence can be seen in Figure 9 for different c hoices o f n , d , and magnitudes of noise. The last step of the algorithm is justified by Lemma 8. 4.1.2 Ortho gonal matric es and symmetric c onne cte d c ommunic ation gr aph In this section a general distributed algo rithm is pre- sented, whic h works for G ij matrices in GL ( d, R ), a di- rected connected gr aph G , and a symmetric communica- tion gra ph G com . W e will make the assumption tha t G com is the union g raph of G and ¯ G , i.e., G com = ( V , E ∪ ¯ E ). The difference b etw een Algorithm 6 and Algor ithm 7 pre- sented here, is that the Z -matrix is used in the for mer, whereas the H -matrix is used in the latter. Here, differ- ent from Section 4.1.1, it do es not hold that N i ( G com ) = N i ( G ) for all i . When we write N i this is shortha nd for N i ( G com ). Algo rithm 7 Let X (0) = [ X T 1 (0) , X T 2 (0) , . . . , X T n (0)] T , where the elements of the matrix X i (0) ∈ R d × d are drawn fro m U ( − 0 . 5 , 0 . 5). Let X i ( t ) for t ∈ N be defined by the following distributed alg orithm: X 1 ( t + 1) = X 1 ( t ) + ǫ X j ∈N 1 Q 1 j X j ( t ) − V 1 j X 1 ( t )) , X 2 ( t + 1) = X 2 ( t ) + ǫ X j ∈N 2 ( Q 2 j X j ( t ) − V 2 j X 2 ( t )) , . . . X n ( t + 1) = X n ( t ) + ǫ X j ∈N n ( Q nj X j ( t ) − V nj X n ( t )) , where ǫ ∈ 0 , 1 ρ ( H ( G , { G ij } ( i,j ) ∈E )) ; ρ ( H ( G , { G ij } ( i,j ) ∈E )) is the sp e ctral radius and Q ij = G ij + G T j i , V ij = I d + G T j i G j i . In compact notation this is written as X ( t + 1) = X ( t ) − ǫ H ( G , { G ij } ( i,j ) ∈E )) X ( t ) . (19) F or a s ufficiently larg e t , let G ∗− 1 i = X i ( t ) and let G ∗ ij = G ∗− 1 i G ∗ j for all i, j . It should be noted that if the s pe ctral radius is not known, in practice it is e no ugh to cho ose ǫ to something small. Remark 30 In the definitions of Q ij and V ij , in the c ase when ( j, i ) 6∈ G , the symb ol G ij should b e interpr ete d as the matrix in R d × d c ontaining only zer o-elements. Analy sis of the algorithm The co nv er gence analysis of this Algo rithm is ana logous simpler than that of Algor ithm 6. The eigenv alues of the H - matri ar e re a l since the matrix is symmetric. Instead of using Lemma 1 4, Lemma 24 is used ins tead. 4.2 Gr adient flow for ortho gonal matric es Under the assumption t hat all the G ij are ele ment s in O ( d ), we here pr ovide a method, whic h will b e used for compariso n to our ear lier metho ds. Results, along the lines of the ones prese nt ed in this se c tio n, can be found in [39,40,41]. 17 F or all i , define the cost functions g i : ( O ( d )) n → R + by g i ( G 1 , G 2 , . . . , G n ) = X j ∈N i A ij k G i G ij G T j − I k 2 F . The ov e r all cost function g : ( O ( d )) n → R + is equal to g , i.e., g ( { G ∗ i } i ∈V ) = n X i =1 g i ( G 1 , G 2 , . . . , G n ) . The (nega tive) gra die nt flow on ( O ( d )) n of g is given by ˙ G i ( t ) = − X j ∈N i A ij (( G i ( t ) G ij G j ( t ) T ) T (20) − ( G i ( t ) G ij G j ( t ) T )) G i ( t ) − X { j : i ∈N j } A ij (( G j ( t ) G T ij G i ( t ) T ) T − ( G j ( t ) G T ij G j ( t ) T )) G i ( t ) , for all i ∈ V . Now we pr esent an algorithm, which improves on Algo- rithm 5 . How ever, as will b e seen in Section 5, this im- prov ement is mar ginal. Algo rithm 8 (1) Run Algorithm 5 and let { G ∗∗ i } be the orthogona l matrices obtained in step (3) of the algorithm. (2) So lve (2 0) numerically (for ex ample by using o de45 in Matlab) for a sufficiently larg e time interv al [0 , T ] with the G ∗∗ i as initial conditions. (3) Let { G i ( t ) − 1 G j ( t ) } ( i,j ) ∈V ×V be the colle ction of transitively co nsistent matrices. Remark 31 In step (3) of Alg orithm 8, if the G i ( T ) ar e not elements of O ( d ) (due to err ors fr om numeric al inte gr ation), they ne e d to b e pr oje cte d onto O ( d ) . 5 Numerical v eri fication In our exper iment s, we consider Algor ithm 8 first. Sub- sequently , the centralised Z- and H-matr ix methods ar e ev aluated for differe nt co nfigurations. Even tually , the analogo us distributed metho ds are used in our sim ula - tions. In order to compa re the metho ds, an assumption throughout this section is that the graph G – describing what transformations are a v ailable – is QSC. 5.1 Gener ating gr aphs and t r ansformations F or ea ch of the following exp eriments, the co llection { G ∗ i } n i ∈V is gener ated by drawing ra ndom matrices in O ( d ) [17]. F rom that, the (full) se t of transitively co nsis- ten t matrices { G ∗ ij = G ∗− 1 i G ∗ j } i,j ∈V is crea ted. The no is y set of pairwis e transformatio ns { G ij } i,j ∈V is generated by adding element-wise Gaussia n noise with z e ro mean and standard deviation σ to each G ∗ ij . After adding the element-wise Ga ussian noise, the matrix is a dditionally pro jected ont o O ( d ). F urthermor e, a quasi-strongly connected (QSC) gra ph with g raph density ρ – not mix up with the spec tr al r a- dius of a matrix – is gener ated in the following manner . F or generating a minimum QSC g raph G = ( V , E ), tw o lists are used. One list L G keeps track of the no des that are already considered, and one list L ¯ G keeps trac k of the no des tha t hav e not b een considered. By a mini- mum QSC graph we mea n a QSC gra ph that is a (spa n- ning) tree, i.e., one with exactly n − 1 edges. Initially , we s et V = { 1 , . . . , n } , E = { ( i, i ) : i ∈ V } , L G = { r } , where r ∈ V is a rando mly s e le cted no de, and L ¯ G = { 1 , . . . , n } − { r } . Then, the followin g pro cedure is re- pea ted n − 1 times: pick random no des i ∈ L ¯ G and j ∈ L G , a dd the edge ( i, j ) to E , and up da te L ¯ G and L G according ly . After n − 1 rep etitions a (minimum ) QSC graph has b een genera ted. At this p o int w e store the edge set E and call it E QSC . Next, random edges are a dded to E until the the density of the g raph is la rger than or equal to ρ , which is defined below. W e r emind the reader that A is the adjacency matrix of G with element s A ij . The graph density ρ ( G ) is defined by ρ ( G ) = 1 n 2 − |E QSC | n X ( i,j ) / ∈E QSC A ij . (21) The intuition behind the gra ph density is that it is the prop ortion of the num b er of present edges in G with resp ect to a fully connected gr aph (ha ving n 2 edges) excluding the edges in E QSC . With tha t, ρ = 0 denotes a minim um Q SC gr aph, whereas ρ = 1 denotes a fully connected graph. Generating random QSC graphs with different v alues o f the par ameter ρ allows us to consider different degr ees o f missing transformations. Using the gr aph G with density ρ , the co lle ction { G ij } ( i,j ) ∈E is the one that is even tually used for the 18 ev aluation. In the s imulations, for each individual sub- figure the simulations hav e b een p erformed with 1 00 random sets of or thogonal transfor ma tions (the tr ansi- tively c onsistent ones and the s y nt hetically g enerated noisy versions thereo f ) and QSC g raphs. Shown in the sub-figures is the mean of all r uns. 5.2 Algo rithm 8 – ortho gonal matric es F or d = 3 , Figure 1 shows upp er b ounds on the gap betw een the optimal v alue and the v alue of the ob jec- tive function obtained by tw o methods – Algo rithm 5, green curv e, a nd Algorithm 8 , blue curv e. In Algor ithm 8, the initial states ar e given b y the solutio n to Algo- rithm 5. The O DE in (20) is solved numerically in Mat- lab by o de45. F or each num b er of co o r dinate systems n , 100 simulations a re conducted and averages ar e shown in Figure 1. In eac h sim ulation a se t of transitively consis- ten t ortho gonal matrices { G ∗ ij } ( i,j ) ∈V ×V are g enerated from a s et of or thogonal ma trices { G ∗ i } i ∈V according to the description in Section 5.1 b elow. The gr a ph G used in each of the exp eriments is the complete gra ph. F or a sing le n umerica l exp eriment, Figure 2 sho ws the improv emen t of h when Algorithm 8 is used. One can see that Algor ithm 5 generates matrice s that are close to a loca l optim um of problem (P2). It ca n b e seen that only a marg inal improv ement can be ma de using the significantly more computationally exp ensive Algorithm 8. Due to the heavy computational burden, in the following simu lations we o mit Algo rithm 8 and fo cus o n the metho ds based on the Z- and H-matrix . n 6 7 8 9 10 11 12 13 14 15 h × 10 -3 5 5.5 6 6.5 7 7.5 8 8.5 9 9.5 10 Performance of Algorithm 3 vs. Algorithm 6 (complete graph) Fig. 1. Upp er b oun ds on the optimality gap, i.e., h , for the solution o f Algorithm 5 , green line, and A lgorithm 8, blue line. The graph is complete. time 0 0.1 0.2 0.3 0.4 0.5 0.6 h × 10 -3 1.8305 1.831 1.8315 1.832 1.8325 1.833 1.8335 1.834 1.8345 Performance increase when using Algorithm 6 (complete graph) Fig. 2. Improv emen t of h when Algorithm 8 is u sed. In this case when n = 15, d = 3, and the graph is complete. 5.3 Centr alize d metho ds for matric es in O ( d ) In this set of ex pe riments we co mpa re the H-matrix metho d, the Z-matrix metho d and a (naive) reference- based metho d, where the la tter serves as base line for the compariso n. 5.3.1 The r efer en c e-b ase d metho d F or the reference- ba sed method, a minimum QSC g raph G min-QSC = ( V , E min-QSC ⊆ E ) w ith n − 1 edges is ran- domly drawn as a subgra ph of G = ( V , E ). F o r that, a ll centers (see Def. 2) o f the gra ph G are initially deter- mined b y loo k ing at the n × n distance matrix betw een all n no des . F rom the set of cen ters, a no de c is randomly selected. Since G is QSC, there is at least one such cen- ter. Le t L G min-QSC = { c } b e the list of no des that have a l- ready b een considered and initialise E min-QSC = ∅ . The following pro cedure is rep eated until |E min-QSC | = n − 1: randomly select a no de r ∈ L G min-QSC , select a random no de r ′ ∈ { i : ( i, r ) ∈ E } , if there is such an r ′ , add the edge ( r ′ , r ) to E min-QSC and add r ′ to L G min-QSC . Per co nstruction, the gra ph G min-QSC is a spanning tr ee that contains a center. Th us, accor ding t o Lemma 12, the set { G ij } ( i,j ) ∈E min-QSC is transitively consistent for G min-QSC . W.l.o.g., by setting G ∗ c = I for the c ent er c of G min-QSC , all (other) G ∗ i are (uniquely) determined as G ∗ i = G ∗ j G − 1 ij for i 6 = c, ( i, j ) ∈ E min-QSC . (22) T o summarise, in the r eference-bas e d method a (ran- dom) r o oted spa nning tree graph is considered as sub- 19 graph of G , i.e., all but n − 1 relative tra nsformations G ij (accounting for the transitive inco nsistency) ar e dis- carded s uch that the remaining n − 1 relative transfor- mations are transitively consis tent . In Fig. 3 the results of the exp eriments are shown. On the vertical axis, a normalised v ersion of the function in (8), defined b y g ′ ( { G i } i ∈V ) = 1 |E | X ( i.j ) ∈E k G ij − G − 1 i G j k 2 F (23) is used. E a ch sub-figure shows a different v ary ing pa ram- eter on the horizontal axis. The title of each sub-figure indicates the fixed parameters. It can b e seen that in a ll cases the Z-matrix approach is ne a rly as go o d as the H-matrix appro ach when lo ok- ing at orthogo nal t ransfor mations. Ho w ever, as a nt ici- pated, the reference-based metho d per fo rms worse than bo th prop osed metho ds. F or the case of different de - grees of noise (Fig. 3, top left) it can b e seen t hat the total error increa ses with increasing noise. Similar ly , in the case of differen t dimensions (Fig. 3, b ottom le ft), the erro r increases with incr easing dimensionality . This can be explained by the fact that the F r ob enius nor m in (23) sums over d 2 v alues. F or v arious v a lues of the gra ph density (Fig. 3, t op righ t), the err or for the H- and Z- matrix metho d is approximately constant (apa rt from the cas e o f a ro oted spanning tree at ρ = 0, ac c ording to Lemma 12.). 5.4 Centr alize d metho ds for matric es in GL ( d, R ) In this set of ex pe riments we compare the H-matrix metho d and the Z-matrix method. Using the reference-bas ed method for the case o f linear transformatio ns is problematic b ecaus e this metho d inv er ts the matr ices G ij for ( i, j ) ∈ E min-QSC (see (23)). Therefore, for r easonably large noise, it is likely that ther e is some ( i, j ) ∈ E min-QSC where G ij is ill- conditioned, resulting in the corresp onding ter m in g ′ blowing up. In Fig . 5 this problem is illustrated, where the horizontal axis is shown in lo g-sca le . The lines of the Z- and H-matr ix metho ds a lmost co inc ide , so only the green line of the H-matrix metho d is visible. The reference-bas ed method’s (blac k) line results in extremely larg e error s. Due to this reas on, and since we hav e already shown that for the cas e of orthogo na l transformatio ns the reference - based metho d is inferio r, in the following the reference ba sed metho d is not used in the comparisons. F or the complete graph case, in Figure 7 the improv ed per formance the Gauss -Newton method, i.e., Algo rithm 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 10 − 40 10 − 10 10 20 σ error (log-scale) n =30 , d = 3 , ρ =0 . 5 Fig. 5. Normalised error in (23) on the horizontal axis show n as log-scale for the Z-matrix metho d (blue), the H-ma- trix metho d (green) and the reference-based meth od (black) when considering transformations in GL ( d, R ). Note that t he blue and green line coincide. d 2 3 4 5 6 7 8 9 10 g’ 0 1 2 3 4 5 6 7 8 9 10 σ = 0 . 3, n = 10, ρ = 1 Fig. 7. Performance of the Z -matrix metho d (blue), the H -matrix method ( green), and the Gauss-Newton method with th e solution of the H -matrix meth od as in itialization (blac k). 3, (with the solution of the H -matrix metho d as initial- ization) is s hown. The Gauss-Newton method run 5 iter- ations, but from inspe ction it could b e deduced that the main con vergence o ccur s already after tw o iterations. In Fig. 6, the co mparisons of the H -matrix method and the Z -matrix metho d are sho wn. It can b e seen tha t for small noise (Fig. 6, top left) b o th metho ds ar e compar a- ble, whereas for a la rger amount o f noise the H-ma trix metho d is able to obtain a smaller erro r . Similarly , for transformatio ns with small dimensionality (Fig. 6, b ot- tom left), b o th metho ds are compar able whereas for larger dimensions the ga p b etw een b oth approaches in- creases. On the contrary , (Fig. 6, top right) illustrates that with increasing gr aph density the line of the Z- matrix method approaches that of the H-matrix metho d (apart from the spanning tree cas e when ρ = 0, anal- ogous to the orthogo nal transformation exp er iments). This indicates that the H-matrix metho d p er forms bet- 20 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 2 4 σ g’ n =30 , d = 3 , ρ =0 . 5 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 0 . 5 1 1 . 5 ρ g’ σ = 0 . 3 , n =30 , d =3 5 10 15 20 0 10 20 30 d g’ σ = 0 . 3 , n =30 , ρ =0 . 5 10 20 30 40 50 0 . 5 1 1 . 5 n g’ σ = 0 . 3 , d =3 , ρ =0 . 5 Fig. 3. Normalised error in (23) for the reference-based method (b lac k), the Z-matrix metho d (blue) and the H -matrix metho d (green) when considering transformations in O ( d ). In eac h sub-figure, a differen t parameter v aries along the horizontal ax is. 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 − 0 . 1 0 0 . 1 σ h n =30 , d =3 , ρ =0 . 5 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 0 . 2 0 . 4 ρ h σ = 0 . 3 , n =30 , d =3 5 10 15 20 − 0 . 1 0 0 . 1 d h σ =0 . 3 , n =30 , ρ =0 . 5 10 20 30 40 50 − 0 . 1 0 0 . 1 0 . 2 n h σ =0 . 3 , d =3 , ρ =0 . 5 Fig. 4. Gap function in (17) for the Z-matrix method (blue) and the H -matrix metho d ( green) when considering transformations in O ( d ). In each sub-figure, a differen t parameter v aries along the horizon tal axis. ter than the Z-matr ix metho d if there is o nly little infor- mation av ailable. A similar o bs erv atio n can b e made for v ario us n (Fig. 6, bottom rig ht ). F or each subfig ure, 100 simulations for a certain configuration of σ , n , d , a nd ρ are shown. 5.5 Metho ds for affine and Euclide an tr ansformations In Figur e 8 – for affine and Euclidean transfor mations – a comparison betw een four different metho ds can be found. The G ij transformatio ns are affine resp ective Eu- clidean, but o nly the Algorithm 4 metho ds (red and 21 0 0 . 1 0 . 2 0 . 3 0 . 4 0 . 5 0 . 6 0 . 7 0 2 4 6 8 10 σ g’ n =30 , d =3 , ρ =0 . 5 0 0 . 2 0 . 4 0 . 6 0 . 8 1 0 2 4 6 8 10 ρ g’ σ =0 . 3 , n =30 , d =3 5 10 15 20 0 20 40 60 d g’ σ =0 . 3 , n =30 , ρ =0 . 5 10 20 30 40 50 1 2 3 n g’ σ = 0 . 3 , d = 3 , ρ =0 . 5 Fig. 6. Normalised error in (23) for the Z- matrix meth od (blue) and t he H-matrix metho d (green) when considering transfor- mations in GL ( d, R ). In each su b -figure, a different parameter v aries along the horizon tal axis. d 2 3 4 5 6 7 8 9 10 g’ 0 0.5 1 1.5 2 2.5 3 3.5 4 σ = 0 . 3, n = 10, ρ = 1 d 2 3 4 5 6 7 8 9 10 g’ 0 0.5 1 1.5 2 2.5 σ = 0 . 3, n = 10, ρ = 1 Fig. 8. Left figure: Perf ormance of the metho ds for affine transformations. The Z -matrix metho d (blue), the H -matrix meth o d (green), the first tw o steps of Algorithm 4 (red), an d Algorithm 4 (blac k). R ight figure: Perf ormance of the metho ds for Euclidean transformations. The Z -matrix method (blue), the H -matrix me tho d (green), the first tw o steps of Algori thm 4 where Algorithm 5 h as been used instead of Algorithm 2 (red ), and Algorithm 4 where Algorithm 5 has been used instead of Algorithm 2 (blac k). black) preserve this prop er ty . In the b ottom r ight fig- ure the G i transformatio ns obtained in the Z -ma trix metho d re sp ective the H -matrix metho d hav e been pro- jected onto E ( d ), i.e., the set of Euclidean trans fo rma- tions. The or thogonal matrix pa rt of the G ij transforma- tions were gene r ated accor ding to the description ab ov e. The elements in the transna tional v ectors were dra wn from the unifor m distribution over ( − 5 , 5) a nd addi- tional elemen t-wise noise was added. 5.6 Distribute d metho ds Results o f the distributed Z-matrix metho d are s hown in Fig. 9 and results for the distributed H-matrix metho d are sho wn in Fig. 10. 22 50 100 150 0 2 4 6 t g’ σ = 0 . 1 , n =30 , d =3 , ρ =0 . 5 50 100 150 0 2 4 6 t g’ σ =0 . 2 , n =30 , d =3 , ρ =0 . 5 50 100 150 0 2 4 6 t g’ σ = 0 . 3 , n =30 , d =3 , ρ =0 . 5 50 100 150 0 2 4 6 t g’ σ = 0 . 4 , n =30 , d =3 , ρ =0 . 5 50 100 150 0 2 4 6 8 t g’ σ = 0 . 3 , n =30 , d =4 , ρ =0 . 5 50 100 150 0 2 4 6 8 10 t g’ σ =0 . 3 , n =30 , d =5 , ρ =0 . 5 50 100 150 0 5 10 t g’ σ = 0 . 3 , n =30 , d =6 , ρ =0 . 5 50 100 150 0 5 10 t g’ σ =0 . 3 , n =30 , d =7 , ρ =0 . 5 200 400 0 1 2 3 t g’ σ = 0 . 3 , n =3 , d =3 , ρ =0 . 5 200 400 0 2 4 t g’ σ = 0 . 3 , n =5 , d =3 , ρ =0 . 5 50 100 150 0 2 4 6 t g’ σ =0 . 3 , n =20 , d =3 , ρ =0 . 5 50 100 150 0 2 4 6 t g’ σ = 0 . 3 , n =50 , d =3 , ρ =0 . 5 200 400 600 800 0 2 4 t g’ σ =0 . 3 , n =30 , d =3 , ρ = 0 . 1 50 100 150 0 2 4 6 t g’ σ =0 . 3 , n =30 , d =3 , ρ =0 . 3 50 100 150 0 2 4 6 t g’ σ =0 . 3 , n =30 , d =3 , ρ =0 . 8 50 100 150 0 2 4 6 t g’ σ = 0 . 3 , n =30 , d =3 , ρ =1 Fig. 9. N ormalised error in (23) on the vertica l ax is for the Z-matrix metho d (b lue) and its distributed version (red) when considering transformatio ns in O ( d ) . The horizontal axis show s the n umber of steps, where th e step size has b een chose n as ǫ = 0 . 01 in each sub-figure. Conclusions This worked a ddressed trans itive consistency of linea r inv er ible transfor mations b etw een Euclidea n co ordinate systems. Given a set of linear inv ertible tr ansformatio ns (or matr ices) – that ar e not transitively consistent – the prop o sed metho ds sync hronize the tra nsformations. This mea ns that they provide transfo r mations that are bo th tra nsitively consistent and clos e to the or iginal non-synchronized trans formations. First tw o different direct o r centralized appr oaches were prop osed. In the first approach – the Z -matrix approach – linea r algebraic conditions were for m ulated that must hold for transitively consistent tra nsformations. Then the sought transfor mations are o bta ined from the so lution of a least s q uares pro blem. In the second a pproach – the H -ma trix approach – optimization proble ms were formulated directly , without tak ing a detour via linear algebraic c o nstraints. The sought transfo r mations are obtained from the so lution o f the o ptimization problems. A Gauss-Newton iter ative metho d was also prop osed where the solution from the H - matrix metho d was used as initializa tion. This metho d was la ter adapted to the ca s e of affine and Euclidean tr a nsformations . It was shown in numerical simulations that for the case of a ffine a nd Euclidean tra nsformations, this approa ch outp e rforms t he H -matrix approach and the Z - matrix approach. Howev er , for orthogonal transfor mations no improv emen t is p oss ible o ver the H -matrix method. In a later part of the pap er, for o rthogona l matr ices, tw o distributed algo rithms were pr esented. These alg orithms share s imilarities with linear consensus algo rithms fo r distributed averaging. It was shown that these simple consensus-like pr oto cols can b e used to provide a solu- tion to o ur problem that is very close to the global opti- m um – even for noise large in magnitude. The prop osed metho ds – b oth the direct/centralized and the itera - tive/distributed – hav e b een v erified to work in numer- ical ex pe riments for a wide range of parameter settings. References [1] R. T ron and R. Vidal. Distri buted 3-d l ocali zation of camera sensor net works from 2-d image measurement s. T r ansactions on Autom atic Contr ol , 59(12) :3325–3340, 2014. [2] V. Lepetit, F. Moreno-Noguer, and P . F ua. Epnp: An accurate o ( n) solution to the pnp problem. International journal of c omputer vi sion , 81( 2):155–166, 2009. 23 20 40 0 2 4 t g’ σ = 0 . 1 , n =30 , d =3 , ρ =0 . 5 20 40 0 2 4 t g’ σ = 0 . 2 , n =30 , d =3 , ρ =0 . 5 20 40 0 2 4 t g’ σ = 0 . 3 , n =30 , d =3 , ρ =0 . 5 20 40 1 2 3 4 t g’ σ =0 . 4 , n =30 , d =3 , ρ =0 . 5 20 40 0 2 4 6 t g’ σ = 0 . 3 , n =30 , d =4 , ρ =0 . 5 20 40 0 2 4 6 8 t g’ σ = 0 . 3 , n =30 , d =5 , ρ =0 . 5 20 40 2 4 6 8 10 t g’ σ =0 . 3 , n =30 , d =6 , ρ =0 . 5 20 40 0 2 4 6 8 10 t g’ σ = 0 . 3 , n =30 , d =7 , ρ =0 . 5 200 40 0 0 1 2 3 t g’ σ = 0 . 3 , n =3 , d =3 , ρ =0 . 5 200 40 0 0 1 2 3 t g’ σ =0 . 3 , n =5 , d =3 , ρ =0 . 5 20 40 0 2 4 t g’ σ = 0 . 3 , n =20 , d =3 , ρ =0 . 5 20 40 0 2 4 t g’ σ = 0 . 3 , n =50 , d =3 , ρ =0 . 5 50 10 0 150 200 0 1 2 3 4 t g’ σ =0 . 3 , n =30 , d =3 , ρ =0 . 1 20 40 60 80 0 2 4 t g’ σ =0 . 3 , n =30 , d =3 , ρ =0 . 3 20 40 0 2 4 t g’ σ = 0 . 3 , n =30 , d =3 , ρ =0 . 8 2 4 6 8 10 0 2 4 t g’ σ = 0 . 3 , n =30 , d =3 , ρ =1 Fig. 10. Normalised error in (23) on the v ertical axis for the H -matrix metho d (green) and its distributed vers ion (red) when considering transformatio ns in O ( d ) . The horizontal axis show s the n umber of steps, where th e step size has b een chose n as ǫ = 0 . 01 in each sub-figure. [3] O. ˇ Skrinjar, A. Bisto quet, and H. T agare. Symmetric and transitive registration of im age sequences. Journal of Biome dic al Imaging , 2008:14, 2008. [4] S. Joshi, B. Davis, M. Jomier, and G. Gerig. Unbiased diffeomorphic atlas construction f or computational anatomy . Neur oImage , 23:S151–S16 0, 2004. [5] T.F. Cootes, S. Marsland, C.J. Twining, K . Smi th, and C.J. T aylor. Group wise diffeomorphic non-rigid registration for automatic mo del building. In Computer Vision-ECCV 2004 , pages 316–327. Springer, 2004. [6] S. Allassonni` ere, Y. A mit, and A. T rouv´ e. T ow ards a coheren t statistical framework for dense deform able template estimation. Journal of the R oyal Statistic al So ciety: Series B (Statistic al Metho dolo gy) , 69(1) :3–29, 2007. [7] F. Bernard, J. Thun b erg, A. Husc h, L. Salamanc a, P . Gemmar, F. Hertel, and J. Goncalves. T ransitively consisten t and un biased m ulti-image registration usi ng n umerically stable tr ansf ormation sync hronisation. In Workshop on Sp e ctr al Analysis in Med ic al Imaging (SAM I), to app e ar . MICCAI, 2015. [8] T. Gass, G. Szek ely , and O. Goksel. Detec tion and correction of i nconsistency-based errors in non-rigid registration. In SPIE Me dic al Imaging , pages 90341B–90341B. In ternational Society for Optics and Photonics, 2014. [9] X. Geng. T r ansitive i nverse-c onsistent image r e gistr ation and evaluation . ProQuest, 2007. [10] J.C. Gow er and G.B. Dijksterhuis. Pr o crustes pr oblems , v olume 3. Oxford Universit y Press Oxford, 2004 . [11] K.S. Ar un, T. S. Huang, and S.D. Bl ostein. Least-squares fitting of t wo 3-D poi n t sets. IEEE T r ansactions on Pattern Ana lysis and Machine Intel ligenc e , (5):698 –700, 1987. [12] P .H. Sc h¨ o nemann. A generalized solution of the orthogonal procr ustes problem. Psyc hometrika , 31(1) :1–10, M arch 1966. [13] B.K.P . Horn, H.M. Hilden, a nd S. Negah darip our. Closed- form solution of absolute orientation using orthonormal matrices. Journal of the O ptic al So ciety of Americ a A , 5(7):1127, 1988. [14] B.K.P . H orn. Closed-for m solution of absolute orientat ion using unit quaternions. Journal of the Opti c al So ciety of Am eric a A , 4(4):629 –642, 1987. [15] M.W. W al k er, L. Shao, and R.A. V olz. Estimating 3-D lo cation parameters using dual num ber quaternions. CVGI P: Image Understanding , 54(3):358– 367, No ve mber 1991. [16] D. Pizarr o and A. Bartoli. Global optimization f or optimal generalized procr ustes analysis. In Computer Vi sion and Pattern R e c o gnition (CVPR), 2011 IEEE Confer enc e on , pages 2409–241 5. IEEE, 2011. [17] F. Bernard, J. Thun berg, P . Gemmar, F. Hertel, A. Husch, and J. Goncalv es. A solution f or multi-alignmen t b y transformation synchronisation. In Confer e nc e on Computer Vision and Pattern R e c o gnition . IEEE, 2015. 24 [18] A. Singer and Y. Shk olnisky . Three-Dimensional Structure Determination from Common Lines in Cr yo-EM by Eigen ve ctors and Semidefinite Programming. SIAM journal on imaging scienc es , 4(2) :543–572, June 2011. [19] R. Hadani and A. Singer. Represen tation Theo retic Patterns in Thr ee-Dimensional Cryo-Electron Microscopy I I—The Class Averag ing Problem. F oundations of c omputational mathematics (New Y ork, N.Y.) , 11(5):589 –616, 2011. [20] R. Hadani and A. Singer. Represen tation theoretic patterns in three dimensional Cryo-Electron Microscopy I: The int rinsic reconstitution algorithm. Annals of m athematics , 174(2):121 9, 2011. [21] K.N. Chaudhury , Y. Khoo, and A. Singer. Global registration of multiple p oint cl ouds using semidefinite pr ogramming. arXiv.or g , June 2013. [22] D. Pac hauri, R. Kondor, and V. Singh. Solving the multi- wa y matching problem b y p ermut ation synch ronization. In A dvanc es in neur al information pr o c essing systems , pages 1860–186 8, 2013. [23] J. T hun ber g, F. Bernard, and J. Goncalv es. Cen tralized and distributed transf or mation synchronizat ion under partial information. Submitte d to: T r ansactions on Pattern Analysis and Machine Intel ligence . [24] M. Mesbahi and M. Egerstedt . Gr aph the or etic m etho ds in multiagent networks . Princeton Universit y Press, 2010. [25] A. Jadbabaie and A. S. Morse. Co ordination of groups of mobile autonomous agen ts using nearest ne ighbor rules. IEEE T r ansactions o n A utomatic Contr ol , 48(6):988– 1001, 2003. [26] R. Olfati-Sab er and R. Mur ray . Consensus problems in net w orks of agen ts with switch ing top ology and time-delays. IEEE T r ansactions on Automatic Contr ol , 49(9):15 20–1533, 2004. [27] R. Olfati-Sab er, J.A. F ax, and R.M. M urray . Consensus and coop eration in net w orked m ulti-agent systems. Pr o ce e dings of the IEEE , 95(1) :215–233, 2007. [28] R. Olfati-Saber and R. M. M urray . Consensus problems in net w orks of agen ts with switch ing top ology and time-delays. IEEE T r ansactions on Automatic Contr ol , 49(9):15 20–1533, 2004. [29] J. Thun ber g. Consensus and Pursuit-Evasion in Nonline ar Multi-A gent Systems . PhD thesis, KTH Ro yal I nstitute of T echnology , 2014. [30] T. Y oshizaw a. Stability the ory by Liapunov’s se c ond metho d . Mathematical So ciet y of Japan (T okyo), 1966. [31] F.H. Cl arke. Gene ralized gr adients and applications. T r ansactions of the Americ an Mathematic al So ciety , 205:247–262 , 1975. [32] G. Shi and Y. Hong. Global target aggregation and state agreemen t of nonlinear m ulti-agen t systems with switc hing topologies. Autom atic a , 45(5):1165 –1175, 2009. [33] Z. Lin, B. F rancis, and M. M aggiore. State agreemen t for con tin uous-time coupled nonlinear systems. SIAM Journal on Contr ol and Opti mization , 46(1) :288–307, 2007. [34] H. K. Khalil. Nonline ar systems , volume Third Edition. Prent ice hall, 2002. [35] Nic holas J Higham. F unctions of matric es: the ory and c omputation . Siam, 2008. [36] D.G. Luen b erger. Intr o duction to line ar and nonline ar pr o g r amming , volume 28. Addison-W esley Reading, MA, 1973. [37] A. F orsgren and T. Odland. On the connection betw een the conjugate gradient method and quasi-newton methods on quadratic problems. Computationa l optimization and applic ations , 60(2 ):377–392, 2015. [38] A. Lindquist and J. Sand. An i n tro duction to mathematical systems theory . K TH L e ct ur e Notes, Division of Optimization and Sy stems The ory, R oyal Institute of T e chnolo gy (K TH) , 1996. [39] B. Af s ari. Riemannian Lp cent er of mass: Existence, uniqueness and con vex ity . In Pr o c. Amer. Math. So c , volume 139, pages 655–6 73, 2011. [40] B. Afs ari and P .S. Kr ishnaprasad. Some gradien t based joint diagonalization methods for ica. In Indep endent Comp onent Ana lysis and Blind Signal Sep ar ation , pages 437– 444. Springer, 2004. [41] A. Sarlette, R. Sepulc hre, and N.E. Leonard. Autonomous rigid bo dy att itude s ynchronization. Automa tic a , 45(2):572– 577, 2009. 25
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment