Multi-stage Multi-task feature learning via adaptive threshold
Multi-task feature learning aims to identity the shared features among tasks to improve generalization. It has been shown that by minimizing non-convex learning models, a better solution than the convex alternatives can be obtained. Therefore, a non-…
Authors: Yaru Fan, Yilun Wang
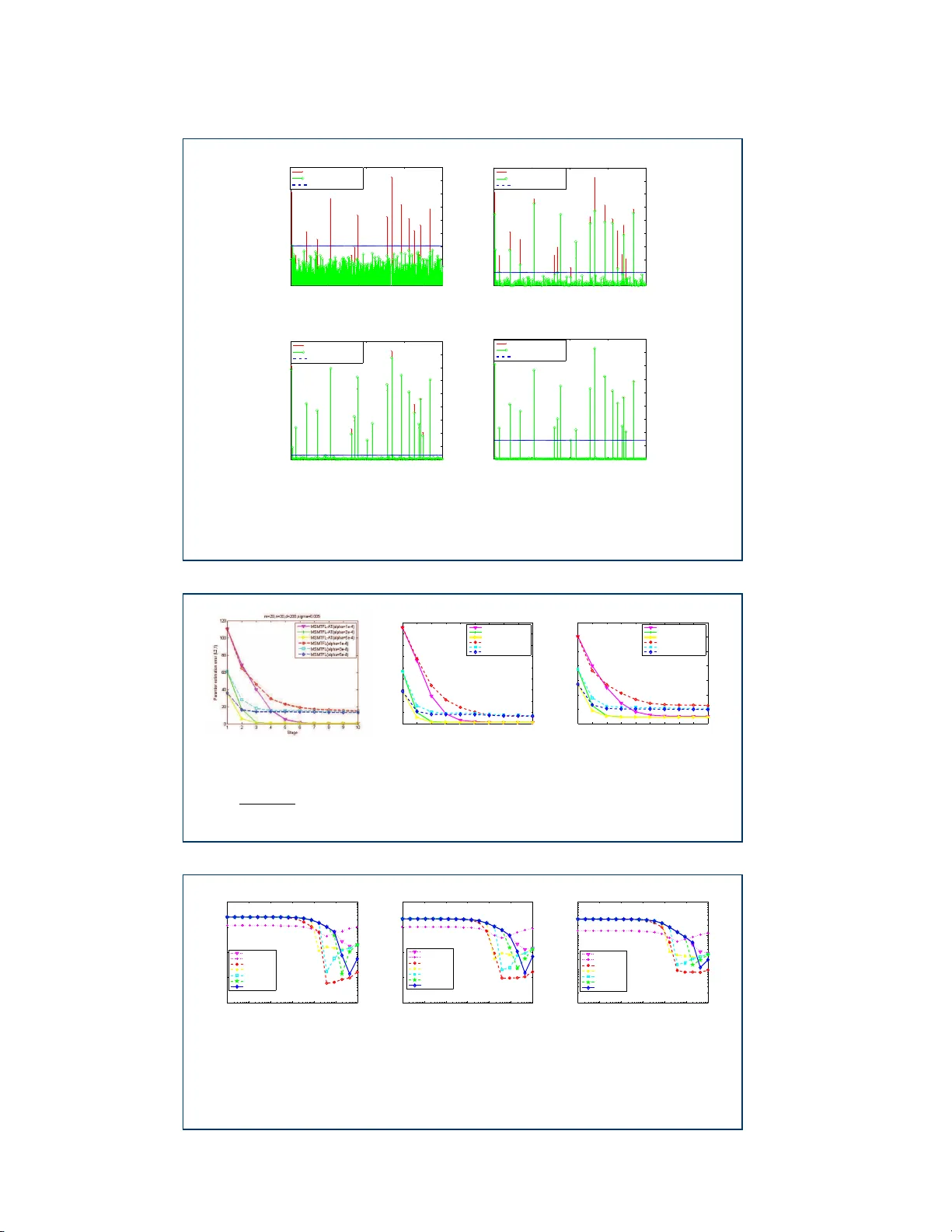
F an et al. RESEARCH Multi-stage Multi-task feature lea rning via adaptive threshold Y a ru F an 1 , Yilun W ang 1 , 2 , 3 * and Tingzhu Huang 1 * Co rrespo n dence: yilun.wang@rice.e du 1 School of Mathematical Sciences, Universit y of Electronic Science and T echnology of China, Xiyuan Ave, 611731 Che ngdu, China F ull list of author information is available at t he e nd of the a rticle Abstrac t Multi-task feature learning aims to identity the s hared features amo ng task s to improve g eneralization. It has b een shown that by mini mizing non-convex learning mo dels, a b etter soluti on than the convex alternati ves can b e obtai ned. Therefore, a no n-convex mo del based on the c app ed- ℓ 1 , ℓ 1 regularization was pr op osed in [ 1 ], and a correspondi ng efficient multi-st a ge multi-task feature learning algorithm (MSMTFL) was presented. How ever, this algorithm har nesses a pr escrib ed fi xed th reshold in the definitio n of the capp ed- ℓ 1 , ℓ 1 regularization and the lack of adapti vity might result i n sub opt i mal p erformance. In this pap er we prop ose to employ an adaptive thresh o ld in the capp ed- ℓ 1 , ℓ 1 regularized for mulation, where the c orresp onding variant of MSMT FL will inc orporate a n additional c o mp onent to adap tively determine the th resh old valu e. This variant is expe c ted to achi eve a b etter feature selection p e rformance over the original MSMTFL a lgorithm. In particular, the emb edded adapti ve threshold comp one n t comes from o ur prev iously propo s ed iterati ve supp ort detec tion (ISD) metho d [ 2 ]. Empirical studies on b ot h synthetic and real-wor ld data s ets demo nstrate the effectiveness of thi s new variant over the original MSM T FL. Keyw o rds: multi-task feature learning; no n-convex optimi zation; adaptive threshold; the capp ed- ℓ 1 , ℓ 1 regularization 1 Intro duction A fundamen tal limitation of the common machine learning metho ds is the cost incurred by the preparation of the larg e training samples required for g o o d general- ization. Multi-task learning (MTL) o ffers a p o ten tial remedy . Unlik e common single task lear ning, MTL acco mplishes tasks simultaneously with o ther related ta sks, us- ing a sha r ed representation. One general assumption of multi-task lea rning is that all tasks should share some common structures, including a similarity metric matrix [ 3 ], a low rank subspace [ 4 , 5 ], par ameters o f Ba yesian models [ 6 ] or a common set of features [ 7 , 8 , 9 ]. Improv ed gener a lization is achiev ed b ecause wha t is lear ned from each task c an help with the lear ning of other tasks [ 10 ]. MTL has b een s uccessfully applied to many applications such as sto ck selection [ 3 ], sp eech classification [ 11 ] and medical diag noses [ 12 ]. While the ma jority o f existing multi-task feature learning algorithms assume that the relev ant features are shared by all tas ks, so me studies have begun to consider a more genera l ca s e where features can b e commo nly shared only among most, but no t necessarily all of them. In other word, they try to learn the featur es sp ecific to each task as well as the common features share d among tasks [ 1 ]. In a ddition, MTL is commonly formu lated as a conv ex reg ularizatio n problem. Th us the resultant mo dels F an et al. Pag e 2 of 13 are r estrictive and sub optimal. In order to remedy the ab ov e tw o shortcomings , a sp ecific non-conv ex for m ulation ba sed on the capp ed- ℓ 1 , ℓ 1 regular iz ed formulation for multi-task sparse feature learning , was pro po sed in [ 1 ]. Then a corres po nding Multi-Stage Multi-T ask F eature Learning (MSMTFL) algorithm is pr e sented. This non-conv ex mo del and corres po nding algorithm usually achieves a b etter solution than the corres po nding conv ex models. How ev er, lik e many non-conv ex algorithms, it may not get a globally optima l solution whic h is often co mputatio nally prohibitive to obtain in practice. Notice that the ab ove capped- ℓ 1 , ℓ 1 regular iz ed formulation employs a prescrib ed fixed threshold v alue in it s definition, a nd the MSMTFL employs the same fixed threshold v alue. This t hreshold v alue is used t o determine the large r ows of the unknown weigh t matrix . Ho w ev er, the result is difficult to prescrib e befor e hand, bec ause this v alue is da ta-dep endent. Thus a na tural idea is to adaptively deter- mine it in practice, in order to achiev e even b etter p erfo r mance. In this pap er, we prop ose to incorp or ate an adaptiv e thresho ld estimatio n sc heme into the MSMTFL. In pa r ticular, we consider the structure information of the intermediate estimated solution of the current stage a nd make use o f this infor ma tion to estimate the threshold v alue, which will be us ed in the next sta g e. This wa y , the threshold v alue and the resultan t solution will be up dated in an alternative way . As for the a dopted threshold v alue estimation sc he me, we are motiv ated b y the iter ative supp or t detec- tion metho d firs t prop ose d by W ang et al [ 2 ] which employ ed the “first significant jump” heuristic r ule to es timate the adaptive threshold v alue. W e leverage the rule to the MSMTFL in o rder to solve the non-conv ex f eature lea r ning formulation with the a daptive threshold, though other metho ds of determining the a daptive thr e sh- old could b e applied. Wit h the help of the adaptiv e thre s hold v alue, rather than a presc r ib ed fixed v a lue, a n even better feature lea rning r e s ult is expected t o b e obtained for b oth synthetic and real data tests. Organization : Firs t, we will review the origina l MSMTFL algo rithm in sec- tion 2 . In section 3, w e will pres e n t the method to ada ptively set the threshold in MSMTFL. In section 4, several numerical experiments verify the effectiveness of our new algo rithm. In the co nclusion we will describ e future work. Notation : Scala rs and vectors are denoted b y lo w er ca se letters. Matrices a nd sets are denoted by capital letters. The E uclidean norm, ℓ 1 norm, ℓ ∞ norm, ℓ p norm, ℓ 0 norm and F r ob enius norm are denoted by k · k , k · k 1 , k · k ∞ , k · k p , k · k 0 and k · k F , r esp ectively . w i and w j denote the i -th column and j -th r ow o f matrix W , resp ectively . | · | denotes the abs olute v alue of a sca lar or the num ber of elements in a set. Then we define N m as the set { 1 , · · · , m } and N ( µ, σ 2 ) as a Gaussian distribution with mean µ and standard deviation σ . 2 Review of the MSMTFL Algo rithm In this section, we first give a brief in tro duction to multi-task fea tur e lea r ning (MTFL) exploiting the shared fea tures among ta sks. Then we review the cappe d- ℓ 1 , ℓ 1 regular iz ed feature learning model and cor r esp onding MSMTFL algorithm prop osed in [ 1 ]. Consider m lear ning task s ass o ciated with the given training data { ( X 1 , y 1 ), · · · , ( X m , y m ) } , wher e X i ∈ R n i × d is the data ma tr ix of the i − th task with each row F an et al. Pag e 3 of 13 being a sample, y i ∈ R n i is the resp o nse of the i − th task, and n i is the num- ber of s a mples fo r t he i − th task. Each column of X i represents a f eature and d is the n umber of fea tures. In the scenario o f MTL, it is assumed that t he differ- ent ta s ks share the s ame set of fea tures, i.e. the columns of differ ent X i represent the same features . The purp ose of featur e se le c tion is to learn a weight matrix W = [ w 1 , · · · , w m ] ∈ R d × m , consisting of the weight vectors for m linea r predictors: y i ≈ f i ( X i ) = X i w i , i ∈ N m . The quality o f prediction is measured thro ugh a los s function l ( W ) and we assume that l ( W ) is co nv ex in W throughout the pap er. F o r each X i , the magnitude of the co mpo nents of w i reflects the imp ortance of the cor- resp onding column (feature) of X i . In MTL, the importa n t features a mo ng differ ent tasks ar e assumed to b e almost the s ame and should be used when es ta blishing a n MTL mo del. W e consider MTL in the scena rio tha t d ≫ m , i.e there are many more fea tures than tasks, b eca use this situatio n co mmonly ar ises in many applications. In such cases, an unconstr ained empirical risk minimization is inadeq uate to obtain a reli- able so lution b ecause ov erfitting of the training da ta is likely to o ccur . A standard remedy for this problem is to impo se a co ns traint o n W to obtain a regula rized fea- ture lear ning mo del. This constra in t or re gularizatio n reflects our pr ior knowledge of the des ired solution. F or example, we hav e lea rned that one imp ortant a s pe ct of W is sparsity , beca use only a small p ortion of the featur e s are r eally relev a nt to the given tas ks. It is well known that the L 0 regular iz ation is a natural choice fo r the sparsity r e g ularizatio n. If the spar sity pa r ameter k for the targ et vector is known, a feature lear ning mo del based o n L 0 regular iz ation is a s follows: c W = arg min W l ( W ) s.t. || w i || 0 ≤ k i = 1 , . . . , m. (1) where l ( W ) is usua lly the quadr atic loss function of W , i.e. l ( W ) = P m i =1 1 mn i k X i w i − y i k 2 . Howev e r, the spar sity par ameter k is often unknown in practice and the fol- lowing unconstr ained for m ulation ca n b e considere d instead. c W = arg min W { l ( W ) + λg ( W ) } (2) where g ( W ) . = P m i =1 || w i || 0 is the s pa rsity regularization term and λ ( > 0) is a parameter balancing the empirica l loss and the regula r ization term. How e ver, either ( 1 ) or ( 2 ) se ems to cons ide r the spars ity of w i individually and fails to make use of the fac t that different tasks share almost the same r elev ant features, i.e. the solution of MTL has a jo int s parsity structure. In addition, a nother fundamen tal difficult y for this mo del is the pro hibitive computational burden since the L 0 norm minimization is an NP-har d problem. In o rder to make use of the joint sparsity structure o f the solutio n o f MTL, o nes often tur n to the mixed ℓ p,q norm ba sed joint spar sity regula rization [ 13 ]. g ( W ) . = k W k p,q = d X j =1 ( k w j k q p ) 1 /q F an et al. Pag e 4 of 13 where w j is the j -th r ow of W , p ≥ 1 and q ≥ 0. One common choice o f p, q is that p = 2 and q = 1 [ 14 ]. It assumes that all these tasks sha r e exactly the same set of the fea tur es, i.e. the relev a n t features to b e shared by a ll tasks . How ever, it is to o res trictive in real-world applications to require the relev a nt features to b e shared b y all tasks. In order for a certain feature to be shar ed b y some but not all tasks, many efforts have b een made. [ 15 ] propose d to use ℓ 1 + ℓ 1 , ∞ regular iz ed formulation to leverage the co mmon features shared among tasks . How ever, ℓ 1 + ℓ 1 , ∞ regular iz er is a conv ex relaxa tion of an ℓ 0 -type one, for example, ℓ 1 , 0 . The conv ex reg ularizer is known to b e to o loose to approximate the ℓ 0 -type one and often achiev es suboptimal pe r formance. With 0 ≤ q < 1, the r egulariza tion || W || p,q is non-co nv ex a nd exp ects to achiev e a b etter solution theor etically . How- ever, it is difficult to solve in practice. Moreov er, the solution o f the non-conv ex formulation heavily dep ends on the sp ecific optimization alg orithms employ ed and may r esult in different solutions. In [ 1 ], a non-conv ex formulation, based on a capp ed- ℓ 1 , ℓ 1 regular iz ed mo del for m ulti-task feature learning is pr op osed, and a corresp onding Multi-Stage Multi-T ask F eature Learning (MSMTFL) alg orithm is also g iven. The capp ed- ℓ 1 , ℓ 1 regular iz a- tion is de fined a s g ( W ) = P d j =1 min( k w j k 1 , θ ). This prop osed mo del aims to simul- taneously lear n the features sp ecific to e a ch task and the common fea tures sha r ed among ta sks. The adv an tage of MSMTFL is that the conv ergence, repr o ducibility analysis, and theore tica l a nalysis for b etter per formance o v er the conv e x mo dels are given. In addition, the capp ed- ℓ 1 , ℓ 1 regular iz ation is a go o d approximation to ℓ 0 -type norm b ecause as θ → 0, P j =1 min( k w j k 1 , θ ) / θ → || W || 1 , 0 , which is mo stly preferred for its theoretica lly optimal spars ity enforcement. Spec ific a lly , the model for multi-task feature learning with the cappe d- ℓ 1 , ℓ 1 reg- ularization is as follows: min W { l ( W ) + λ d X j =1 min( k w j k 1 , θ ) } , (3) where θ ( > 0 ) is a thresholding par ameter, whic h distinguishes nonzeros and zero comp onents; w j is the j -th ro w of the matrix W . Obviously , due to the capp ed- ℓ 1 , ℓ 1 pena lty , the optimal s o lution o f problem (3) de no ted as W ⋆ has ma n y zer o rows. Due to the ℓ 1 pena lty on each row of W , so me entries of the nonzero r ow may b e zero. Therefore, a certain feature can b e sha red by some but not nece ssarily all the tasks under the formulation (3). The m ulti-stage m ulti-task feature lea r ning (MSMTFL) a lgorithm (see A lgorithm 1) base d on the work [ 16 , 1 7 ] is prop os ed in [ 1 ] to solve problem (3). No te tha t for the first step of MSMTFL ( ℓ = 1), the MSMTFL algor ithm is equiv alen t to so lving the ℓ 1 , 1 regular iz ed m ulti-task feature lear ning mo del (Las s o for MTL ). Ther efore, the final solutio n of the MSMTFL algor ithm can b e consider ed as a refinement of Lasso’s for MTL. Althoug h MSMTFL may not find a globally optimal so lution, [ 1 ] has theor etically shown that t he s o lution o btained by Algor ithm 1 improv ed the per formance of the par a meter estimation erro r b ound a s the multi-stage itera tion pro ceeds, under certain circumstances. More details about intuitiv e in terpretations, parameter settings and conv e r gence analysis of the MSMTFL algorithm a re pro- vided in [ 1 ]. In addition, we need to p oint out that the key thresho lding par ameter F an et al. Pag e 5 of 13 θ is b ounded b e low, that is θ ≥ amλ , where a is a constant. An e xact solution could be o btained from the Algorithm 1 with an appropr iate thresholding para meter. Algorithm 1 The MSMTFL Algorithm 1.Initialize λ 0 j = λ ; 2.for ℓ = 1 , 2 , · · · , do (a) Let ˆ W ( ℓ ) be a s olution o f the following problem: min W { l ( W ) + P d j =1 λ ( ℓ − 1) j k w j k 1 } . (b) Let λ ( ℓ ) j = λI ( k ( ˆ w ( ℓ ) ) j k 1 < θ )( j = 1 , · · · , d ), where ( ˆ w ( ℓ ) ) j is the j − th row o f ˆ W ( ℓ ) and I ( · ) denoted the { 0 , 1 } v alued indicator function. end. 3 Our Proposed F o rmulation and Algori thm In this paper, w e would lik e to present a further study on the ca pped- ℓ 1 , ℓ 1 reg- ularization based multi-task feature learning mo del and co rresp onding MSMTFL algorithm. One limitation of the f ormulation (3) is to employ a fixed thres hold θ to learn a w eig ht ma trix W . This prescrib ed v alue ma y b e far from optimal beca use t he choice of θ may v ary greatly for diff erent k inds of training data X and difficult to determine b eforeha nd. In order to achieve a b etter p erfor mance, we prop os e an empirical heur istic method, which a ims to learn an adaptive threshold adopted in the non-co nv ex m ulti-task fea ture le a rning for m ulation ( 3). The key p oint is that w e can refine thre s hold adaptively in each stag e according to the W result of the last stage. In particular, w e make use of the “first significant jump” r ule prop osed in [ 2 ], which auto ma tically determines an appro pr iate threshold v alue of the cur r ent sta ge based on the rec e nt W result, though other p ossible wa ys to adaptively deter mine the θ can also b e applied. Spec ific a lly , we prop os e to modify the original non-conv ex m ulti-task feature lear n- ing for mulation ( 3 ) with a n unknown threshold v alue θ ( W ) , a s follows. min W { l ( W ) + λ d X j =1 min( t [ j ] , θ ( W ) ) } , (4) where l ( W ) is still the quadra tic los s function as defined ab ov e; λ ( > 0) is a para m- eter balancing the quadr atic loss and the regula rization; t [ j ] = k w j k 1 . W e can see that the difference b etw een the mo dels ( 4 ) and ( 3 ) is the thre s hold parameter. In the new mo del, θ ( W ) is data dep endent and ass umed to b e unknown, r ather than a prescrib ed known v alue . While it seems to b e na tural idea, the determination o f the θ ( W ) is not trivia l and we will present an efficient a daptive method bas ed on the ”first s ig nificant jump” rule to estimate it. More details a b out “fir s t significant jump” will b e reviewed in Section 3.1 . T o so lve the ab ove optimiza tion problem ( 4 ), w e corresp o ndingly mo dify the m ulti-stage m ulti-task feature learning a lgorithm pr op osed in [ 1 ] by inco rp orating an adaptive threshold estimation step (MSMTFL-A T) (see Algorithm 2 for mor e details). A t eac h stage (itera tion, or step) in the Algo rithm 2, the threshold θ ( ℓ ) will F an et al. Pag e 6 of 13 be up da ted a ccording to the most r e c ent ly lea rned s o lution ˆ W ( ℓ ) . θ ( ℓ ) keeps upda t- ing as iterations pro ceed and even tually r e aches a stable and small rang e empir ic a lly . Algorithm 2 The MSMTFL-A T Algo rithm 1.Initialize λ 0 j = λ ; 2.for ℓ = 1 , 2 , · · · , do (a) ˆ W ( ℓ ) ← min W { ℓ ( W ) + P d j =1 λ ( ℓ − 1) j t [ j ] } ; (b) θ ( ℓ ) ← “firs t significant jump” rule, us ing ˆ W ( ℓ ) as the refer ence; (c) λ ( ℓ ) j = λI ( ˆ t ( ℓ ) [ j ] < θ ( ℓ ) ) ( j = 1 , · · · , d ), where ˆ t ( ℓ ) [ j ] = k ( ˆ w ( ℓ ) ) j k 1 (( ˆ w ( ℓ ) ) j is the j -th row o f ˆ W ( ℓ ) ) and I ( · ) denoted the { 0 , 1 } v alued indicato r function ; end. As shown in [ 1 ], the MSMTFL achiev e s a better estimatio n error bound than the conv ex a lter native such as the ℓ 1 , 1 regular iz ed mo del, though in genera l it only leads to a lo cal critical point for the non- conv ex pr oblem ( 3 ). This enhancemen t is achiev ed b ecause this lo cal critical p oint is a r efinement based on the so lutio n of the initial co nv e x mo del, which is the ℓ 1 , 1 regular iz ed mo del. F urthermor e, o ur prop osed MSMTFL-A T is exp ected to achiev e an even b etter estimation accur acy than the orig inal MSMTFL beca use of the incorp ora ted adaptive thresho ld esti- mation scheme. Her e we only present an intuitiv e explanation, which is par tially bo rrow ed from the idea of the analysis of the iterative reweigh ted ℓ 2 algorithm for ℓ p ( 0 ≤ p < 1 ) based non- c o nv ex compressive sensing in [ 18 ]. W e e x tended it from the common s parsity re g ularizatio n to joint spar sity regular ized considered in this pap er. Note that the no n-conv ex f ormulations ( 3 ) or ( 4 ) based on capp ed- ℓ 1 , ℓ 1 reg- ularization ca n be a go o d approximation to L 0 regular iz ation if θ o r θ ( W ) is small, bec ause P d j =1 min( t [ j ] , θ ) / θ is close to || t || 0 , where t = [ t [1] , t [2] , . . . , t [ d ] ]. Indeed, in practice, the θ ( ℓ ) of Algorithm 2 usually decrease s gradually as the iteratio n pro - ceeds, though not necessarily always monotonically , due to the inher ent estimation error s. Based on this observ ation, an intuitiv e expla nation wh y MSMTFL-A T could achiev e a b etter p erfor mance than MSMTFL, is that an adaptive but relatively large θ ( ℓ ) at the be ginning o f MSMTFL-A T res ults in undes ir able lo cal minima be- ing “ filled in”. Once ˆ W ( ℓ ) is in the c orrect ba s in, decre a sing θ ( ℓ ) allows the basin to deep en and ˆ W ( ℓ ) is exp ected to a pproach the true W more clos e ly . W e ex pec t to turn these no tio ns into a rigor ous pro o f in the future work. In a ddition, supp ose that lim ℓ →∞ θ ( ℓ ) exists and we denote it as θ ( ¯ W ) , then we in tuitively exp ect that ˆ W ( ℓ ) of MSMTFL-A T con v erges to a cr itical po int of the pro blem ( 4 ) with θ ( W ) being θ ( ¯ W ) . The rigor ous pro of will also constitute an imp ortant future research topic. The repro ducibility of the MSMTFL-A T alg orithm can b e guar anteed, a s can the original MSMTFL. Theorem 2 in [ 1 ] proves that the optimization pro blem 2(a) in MSMTFL (Algor ithm 1) has a unique solution if X i ∈ R n i × d has entries dr awn from a c o ntin uous probability distr ibutio n o n R n i d . Consider ing that problem 2(a) in MSMTFL-A T (Algo rithm 2) has the same formula as the one in MSMTFL, the solution ˆ W ( ℓ ) of the MSMTFL-A T is also unique, for a ny ℓ ≥ 1. The main difference b etw e en MSMTFL-A T and MSMTFL is Step 2(b), which ha s a unique F an et al. Pag e 7 of 13 output. Therefor e the s olution genera ted by Algorithm 2 is also unique, since Steps 2(a), 2(b) and 2(c) all r eturn unique res ults. 3.1 Adaptive Thresh old in MSMT FL-A T While there could b e ma ny different r ules for θ ( ℓ ) , our choice is ba sed on lo cating the “firs t significa nt j ump” in the incre a singly so rted se quence | ˆ t ( ℓ ) [ j ] | . F or simplicity , after so r ting, we still use the sa me no tation, where | ˆ t ( ℓ ) [ j ] | deno tes the j -th smallest among all { ˆ t ( ℓ ) [ j ] } d j =1 by magnitude, as used in [ 2 ]. Denote ˆ t ( ℓ ) = [ ˆ t ( ℓ ) [1] , ˆ t ( ℓ ) [2] , . . . , ˆ t ( ℓ ) [ d ] ]. This rule lo o ks for the s mallest j such that | ˆ t ( ℓ ) [ j +1] | − | ˆ t ( ℓ ) [ j ] | > τ ( ℓ ) . (5) This amounts to sweeping the increa sing s equence | ˆ t ( ℓ +1) [ j ] | and lo oking for the fir st jump larger than τ ( ℓ ) . Then we se t θ ( ℓ ) = | ˆ t ( ℓ ) [ j ] | . This rule has prov ed ca pa ble of detecting many true nonzer os with few false alar ms if the seq uence | ˆ t ( ℓ ) [ j ] | has the fast-decaying prop erty [ 2 ]. In addition, several simple and heuris tic metho ds hav e bee n adopted to define τ ( ℓ ) for different kinds of data matrix, as s uggested in [ 2 ]. In this pap er, we a dopt the following metho d for following b oth synthetic and re al data exp er iment s, thoug h other heuristic formulas could b e prop osed and tried. τ ( ℓ ) = n − 1 k ˆ t ( ℓ ) k ∞ , (6) where n = P m i =1 n i is the num ber of all samples. An excessively larg e τ ( ℓ ) results in p enalizing to o many true no nzeros, while an exces sively small τ ( ℓ ) results in ignoring to o ma ny false nonzeros and leads to low quality of solution. MSMTFL- A T will b e q uite effective with a n appropria te τ ( ℓ ) , though the pro pe r r a nge of τ ( ℓ ) might b e case-dep endent [ 2 ], due to the No F ree Lunch theorem for the nonconv ex optimization or lear ning [ 19 ]. How ever, n umerical exp eriments hav e shown that the practical p erfor mance of MSMTFL-A T is less se ns itive to the choice of τ ( ℓ ) . In addition, we need to p o int out that the tuning par ameter θ ( ℓ ) > 0 is a key parameter, which typically dec reases fro m a large v alue to a sma ll v alue to detect more corre c t nonzeros f rom the gr adually improv ed in ter mediate learning results as the iter ation pr o ceeds (as ℓ increases ). Int uitively , t he “first significa nt jump” rule works well par tly beca use the true nonzeros of ˆ t ( ℓ ) are lar ge in ma gnitude and small in num ber , while the false ones are lar ge in num be r and s mall in mag nitude. T her efore, the magnitudes of the true nonzeros are sprea d out, while those of the fa lse ones ar e cluster ed. The phenomenon of “first significa nt ju mp” was first observed in compress ive sensing [ 2 ] and ha s bee n observed in other r elated sparse pattern reco gnition pro blems [ 20 , 21 ]. While it is o nly a heuristic rule, it is still o f pr actical impo rtance, b eca use a theo retically rigoro us w ay to set the thr eshold v alue while keeping co nt rol of the false detections is still a challenging task in statistics [ 2 2 ]. 3.2 A Simple Demo W e pr esent a demo to show the effectiveness of the “first significant jump” rule in m ulti-stage m ulti-task feature learning in Figure 1. W e generate a sparse w eigh t F an et al. Pag e 8 of 13 matrix ¯ W ∈ R 200 × 20 and randomly s e t 90% rows of it as zero v ectors and 8 0% elements of the remaining nonzero en tries as zeros. W e set n = 30 and genera te a da ta matrix X ∈ R 30 × 200 from the Ga ussian distribution N (0 , 1). The noise δ ∈ R 30 × 20 is sampled i.i.d from the Gaussian distribution N (0 , σ 2 ) with σ = 0 . 005. The res po nses are computed as Y = X ¯ W + δ . The parameter estimation er ror is defined a s || ˆ W − ¯ W || 2 , 1 . In Figure 1, ¯ t (a column vector) c o rresp onds to the true weigh t matrix ¯ W and ˆ t ( ℓ ) corres p o nds to t he learning weight matrix ˆ W in the ℓ - th iteration. Subgraphs (a)-(d) plot ˆ t (1) , ˆ t (4) , ˆ t (7) , ˆ t (10) , res pec tively , in comparison with ¯ t . F rom s ubgraph (a), it is clear that ˆ t (1) , which represents the solutio n of a La sso-like model, contains a large nu mber of false nonzero s and has a lar ge recov ery error , as ex p ected. As iteration pro ceeds, the intermediate learning result b eco mes more a ccurate. F or example, ˆ t (4) has a s ma ller error, and we c a n see that mos t of tr ue nonzeros with large magnitude hav e b een correctly identified. Then, ˆ t (7) well matches the true learning matrix ¯ t even be tter , with only a tin y n um ber of false no nzero components. Finally , ˆ t (10) exactly ha ve the same nonzero components as the true ¯ t , and the er ror is quite small. In short, Figure 1 shows that our pro po sed algorithm is insensitiv e to a small false num ber in ˆ t a nd has an attractive self-corr ection capacity . 4 Numerical Experiments In this section, we demonstr a te the be tter p erfor ma nce o f the prop osed MSMTFL- A T in terms of sma ller recovery error s . W e compa re the MSMTFL- A T with a few comp eting m ulti-task feature lea rning algorithms: the MSMTFL, ℓ 1 -norm m ulti- task fea ture learning algo rithm (Las so), ℓ 2 , 1 -norm multi-task feature lea rning algo- rithm (L2,1), an e fficie nt ℓ 2 , 1 -norm multi-task feature learning alg o rithm (Efficient - L2,1) [ 23 ] and a robust m ulti-task fea ture lea r ning a lg orithm (rMTFL) [ 24 ]. 4.1 Synthetic Data Exp eriments As a bove, we deno te the num b er of tasks as m and e a ch task has n s amples. The nu mber o f features is deno ted as d . E ach elemen t of the da ta matrix X i ∈ R n × d for the i -th task is sampled i.i.d. from the Gaussian distribution N (0 , 1) and eac h entry of the true w e ight ¯ W ∈ R d × m is sampled i.i.d. from the uniform distribution defined in the interv al [-10 , 1 0]. Here we r andomly s et 90% rows o f ¯ W as zer o vectors and 80% elements of the remaining nonzer o entries as zeros. E ach e n try of the noise δ i ∈ R n is sampled i.i.d. fro m the Gaussia n distribution N (0 , σ 2 ). The resp o nses are computed as y i = X i ¯ w i + δ i . The q ua lity of the recovered weigh t matrix is measured b y the av eraged param- eter estimation er ror k ˆ W − ¯ W k 2 , 1 , which ha s a theor etical bo und referring to [ 1 ]. W e present the a veraged parameter estimation error k ˆ W − ¯ W k 2 , 1 vs. S tage ℓ in compariso n with the MSMTFL a nd the MSMTFL-A T in Figure 2. It is clear that the parameter e s timation er rors of all tested algo rithms decrea se as the stage num- ber ℓ increases, which shows the adv a n tage of MSMTFL and MSMTFL-A T o ver the plain Lasso-like mo del ( ℓ = 1). It is worth noting t hat the MSM TFL-A T is alwa ys superior to the MSMTFL under the s ame settings. Moreover, the para meter estimation erro r of our MEMTFL-A T decr eases more rapidly a nd is more stable in most stag es. F an et al. Pag e 9 of 13 In order to show that the p erfo rmance of MSMTFL-A T is insensitive to the set- tled v alue of the parameter τ to ce r tain degr ee, we depict the av eraged pa rameter estimation err or k ˆ W − ¯ W k 2 , 1 corres p o nding to different τ v a lues . The default v alue of τ is based on the heur is tic formula ( 6 ) a nd we a lso tried o ther v alues such a s several times the default v a lue . The resultant recov ery err o rs a re listed in T able 1. W e ca n see that, with differen t τ v alue s , our MSMTFL-A T achiev es almost the same recovery accur acy and demonstrates the insensitiveness to the choice o f the τ v a lue. Th us, in following numerical experiments we just se le c t τ bas ed o n the heuristic for mula ( 6 ). In Figure 3, we presen t the a veraged par ameter estimation error k ˆ W − ¯ W k 2 , 1 vs. la m b da λ in comparison w ith the MSMTFL with differen t θ ( θ 1 = 50 mλ , θ 2 = 10 mλ , θ 3 = 2 mλ and θ 4 = 0 . 4 mλ ), the MSMTFL-A T, the ℓ 1 -norm multi-task feature learning algorithm (Lasso) and the ℓ 2 , 1 -norm m ulti-task feature learning algorithm (L2,1). The settings of the para meter s of these inv olved alternative al- gorithms fo llow t he same settings in their original pa p e rs. W e c o mpared the av- eraged pa rameter es timation er r ors o f all the tested a lgorithms. As exp ected, the error of o ur MSMTFL-A T was the smalles t among them. Spec ific a lly , our pr op osed MSMTFL-A T significan tly outp erfor med the plain MSMTFL algorithm with the same se ttings sugg ested in [ 25 ]. In order to further demonstrate t he adv antage of the MSMTFL-A T, w e compared it with an efficien t ℓ 2 , 1 -norm m ulti-task featur e learning alg o rithm (Efficient-L2,1) prop osed in [ 23 ] and a r obust multi-task feature learning algor ithm (rMTFL) pro- po sed in [ 24 ]. The Efficient-L2,1 solves the ℓ 2 , 1 -norm r egularized regres sion mo del via N esterov’s metho d. The rMTFL employs the accelera ted gradient descent to efficiently solve the corres p o nding mult i-task lear ning pro blem, a nd ha s shown the scalability to large-s iz e pr oblems. The results a re plotted in Figur e 4. W e see that our MSMTFL-A T outpe r forms these tw o alternative algorithms in terms of achiev- ing the smallest recovery error . In short, these empirical results demons tr ate the effectiv eness of our prop osed MSMTFL-A T. In particular, we hav e observed that (a) when no is e level ( σ = 0 . 05) is relatively larg e , the MSMTFL-A T also outp e rforms other tested alg orithms and shows its robustness to the noise. (b) When λ excee ds to a cer tain degree , the spar- sity regular ization weighs to o muc h and the so lutions ˆ W obtained by the inv olved algorithms will b e to o sparse. In such cas e s, the er rors of a ll tested a lgorithms increase. Ther efore, prop er choice of λ v alue is also very imp ortant. 4.2 Real -Wo rld Data Exp eriments W e co nduct a typical r eal-world data set, i.e. the Isolte data set (this data can b e found at www.zj ucadc g.cn/dengcai/Data/data.html ) in this experiment. W e aim to demonstra te the high efficiency of our alg o rithm in prac tical problems. This Isolet data set is collected fro m 1 50 sp eakers who sp eak the name of each Eng lish letter of the alphab et twice. Hence, we hav e 52 training sa mples from ea ch spe aker. The sp eakers are gro upe d into 5 subsets, each of which has 30 similar sp ea kers. The s e subsets are referred to as isolet1, isolet2 , isolet3, iso let4, and isolet5, r esp ectively . Thu s, there are 5 tasks and ea ch ta sk corres po nds to a subse t. The 5 tasks have 1560, 1560, 1560, 1558 and 1559 samples, resp ectively (three sa mples historically F an et al. Pag e 10 of 13 are missing), where ea ch sample has 617 featur e s and the resp onse is the E nglish letter lab el (1- 2 6). F or our exp er iment s, the le tter la b els are trea ted a s the regressio n v alues for the Isolet sets. W e ra ndomly extrac t the training s amples from ea ch task with different training ratios (15%, 20% and 25%) and use t he rest of the samples to form the test set. W e ev a lua te four multi-task feature learning a lgorithms accor ding to normalized mean s q uared error (nMSE) a nd av eraged means sq ua red err or (aMSE), whose definitions ar e as follows: nM S E = n || ˆ y − ¯ y || 2 F || ˆ y || 1 · || ¯ y || 1 , (7) aM S E = || ˆ y − ¯ y || F || ¯ y || F , (8) where ˆ y is the predictiv e v alue from tested alg orithms and ¯ y is the referent true v alue fro m the who le Iso let data s e t. B oth nMSE and aMSE are commonly us e d in m ulti-task le a rning pro ble ms [ 1 , 26 ]. The exp erimental results ar e shown in Figure 5. W e can see that our pr o p osed MSMTFL-A T is sup erio r to the Efficient-L2,1, rMTFL and MSMTFL algor ithms in terms of achieving the smallest nMSE and a MSE. The MSMTFL-A T per forms esp ecially well even in the case of a sma ll training r atio. All o f the exp erimental results ab ove s uggest that the prop osed MSMTFL-A T a lg orithm is a promising approach. 5 Conclusions This pap er pro p oses a non-co nv e x mult i-task fea ture learning for m ulation with an adaptive thr eshold parameter and in tro duces a cor resp onding MSMTFL-A T algo- rithm. The MSMTFL-A T is a com bina tion of a n adaptive thres hold lear ning via “first significa nt jump” rule prop osed in [ 2 ] with the MSMTFL algorithm pr o- po sed in [ 1 ]. The intuition is to refine the estimated thres ho ld b y using intermedi- ate solutions o btained from the recen t stage. This alter native pro ce dur e betw een threshold v alue estimation and feature lear ning, leads to a gr adually appro priate threshold v a lue, a nd a gradua lly improv ed solution. The exp erimental r esults o n bo th synthetic data a nd real-world data demonstr ate the effectiv eness of our pro - po sed MSMTFL-A T in comparis o n with se veral state- of-the-art multi-task feature learning algo rithms. In the future, we will giv e a theoretical analy s is about the con- vergence o f MSMTFL-A T. In addition, we exp ect to per fo rm a rigorous analysis ab out wh y MSMTFL-A T co uld achieve a b etter practical p erfor mance than the original MSMTFL. Ackno wledgements This work was supp orted by the Natio nal Ke y Ba s ic Resea rch Pr ogra m o f China (No. 20 15CB85 6000 ), the Natur a l Science F oundation of China (Nos. 11201 054, 91330 201) and by the F unda men tal Resear ch F unds f or the Cen tr a l Univ ersities( No. ZYGX2013Z005). W e w ould also like to thank the anonymous reviewers for their many construc tive sugg estions, which hav e greatly impr ov ed this pap er. F an et al. Pag e 11 of 13 k ˆ W − ¯ W k 2 , 1 0.5 τ τ 5 τ m=25, n=25, d=180, σ =0.05 8.2556 8.2725 8.8131 m=15, n=40, d=250, σ =0.01 0.9467 0.9458 1.0258 m=20, n=30, d=200, σ =0.005 0.6442 0.6346 0.6785 T able 1 A veraged p arameter estimation erro r fo r t he τ wi th different times . Author details 1 School of Mathematical Sciences, Uni versity of Elec tronic S cience and T echnology of China, Xiyuan Ave, 611731 Chengdu, China. 2 Center for Infor mation in B iomedicine, University of El ectronic Sc ience and T echnology of China, Xiyuan Ave, 6 11054 Chengdu, C hina. 3 Center for Applied Mathematics, Co rnell University , Xiyuan Ave, 611731 Chengdu, China. Referen ces 1. P . Gong, J. Y e and C.Zhang.: Multi-Stage Multi- T ask Feature Learning. The Journal of Machine Learning Resear ch a rchive. 14 , 2979-3010 (2013). 2. Y. W an g and W. Yin.: Sparse si g nal reconstruction via iteration supp ort d etection. SIAM Journal on Ima ging Sciences. 3 , 462-491(2010). 3. J. Ghosn and Y. Bengio.: Multi-task lea rning for sto ck selection. Advance s in Neural Information Processing Systems(1997). 4. J. C hen, J. Liu, and J. Y e.: Lea rning incoherent spa rse and low-rank patterns from multiple tasks. ACM T ransactions on Kn owledge Dis covery from Da ta. 5 , 1-31(2012 ). 5. S. Negahban and M.Wainwright.: Estimation of (nea r) low-rank matrices with noi se and high -dimensional scaling. The Annals of Statistics. 39 , 1069- 1 097(2011). 6. K. Y u, V. T resp, and A. Schw a ighofer.: Learning gauss ian processes from multiple tasks. ICML’ 05 Pro ceedings of the 22nd international conference on Machine learning. 1012-1019(2005). 7. A. Argy riou, T. Evgeniou, and M. Pontil.: Convex multi-task feature learning. Machine Learning. 73 , 243-272(2008). 8. S. Kim a nd E. Xi n g.: T ree-guided group lasso for multi-resp onse regression with structured sparsity , with an application to e QTL mapping. The Annals of Applied St atistics. 6 , 1095-1117(2012). 9. K. Lounici, M. P ontil, A. Tsybak ov, and S. V a n De Gee r.: T aking advantage o f spa rsity i n multi-task le arning. In COL T.73-82(2009). 10. P . Gong, J. Zhou , W. Fan and J. Y e.: Efficient multi- task feature learning with calib ration. KDD ’14 Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. 761-770(2014). 11. S. P arameswa ra n an d K. W einb erger.: Large margin multi- task metric learning. In N IPS. 1867-1875(2 010). 12. J. Bi, T. Xiong, S. Y u, M. Dundar, a n d R. Ra o.: An i mproved multi-tas k learning approach with applications in medical di a gnosis. Machine Learning and K nowledge Discovery in Databa ses Lecture Notes in Computer Science. 5211 , 117-132(2008). 13. Kow alski, Matthieu.: Spa rse regression using mixed no rms. Applied and C omputational Ha rmonic Analysis. 27 , 303-324(2009). 14. M. Y ua n, Y. Li n.: Mo del selection a nd estimation i n regre ssion with group ed variables. Journal of the Ro y al Statistical So ciet y Serie B. 68 , 49 - 67(2006). 15. Jala li, A., Ra vikumar, P ., Sanghavi, S.: A dirt y mo del for multiple sparse regression. IEEE T ransactions on Information Theo ry . 59 , 7947-7968(2013). 16. T. Zhang.: Analysis of mu l ti-stage convex re laxation for sparse regularization. JMLR. 11 , 1 081-1107(2010). 17. T. Zhang.: Multi-stage convex re laxation for feature s election. Bernoulli. 19 , 227 7 -2293(2013). 18. R. Cha rtrand and W. Yin.: Iteratively rew eighted al grithms for comp ressive s ensing. IEEE International Conference on Ac oustics, Sp eech a nd Signal P rocessi n g. 3869- 3872(2008). 19. WOLPERT, David H ., and William G. MA CREAD Y.: No fre e lunch theo rems fo r optimiza tion. IEEE T ransactions on Evolutio n ary Computation. 1 , 67-8 2(1997). 20. Y. W a n g, J. Zheng, S.Zha ng, X. Du an, and H . Chen.: Ra ndomized Structural S parsit y via Cons tra i ned Blo ck Subsampling for Improved Sensitivity of Dis criminative Vo xel Identification. Neuroimage, in p ress (2015). 21. Y. W a n g, S. Zhang, J. Zheng and H. Chen.: Randomized Structural Sparsity based Fe ature S election with Applications to Bra in Mappin g of Autism Sp ectrum Dis order: A Multimo da l and Multi-center Rep roducibili t y Study . IEEE T rans actions on Autonomou s Mental Dev elopment, in p ress(2015). 22. Barbera, Rina F oy gel, and Emmanuel Candes.: Controllin g the False Dis covery Rate via Kno ckoffs. arXiv pre print. 23. J. Liu, S. Ji, a nd J. Y e.: Multi-task feature learning via efficient ℓ 2 , 1 -norm mi nimization. In UA I ’09 Proceedings of the Twent y-Fifth Conference on Uncertaint y in A rtificial Intelli gence. 339- 3 48(2009). 24. P . Gong, J. Y e, and C. Zhang.: Rob u st multi-task fe ature learning. KDD ’12 P ro ceedings of the 18th ACM SIGKDD international confer ence on Kno wledge discovery and data mining. 12 , 8 95-903(2012). 25. T. Zhang.: Some sharp performance b ounds fo r least squares regression with ℓ 1 regularization. The Annals of Statistics, 37 , 2109-2144(2009). 26. Y. Zhang and D. Y eung.: Multi-task learning using generaliz ed t process. JMLR W & C P . 9 , 964-971(2010). F an et al. Pag e 12 of 13 0 50 100 150 200 0 5 10 15 20 25 30 35 40 45 1st iteration , Err = 1.59e+02 true weight dictionary learning weight dictionary threshold (a) 0 50 100 150 200 0 5 10 15 20 25 30 35 40 45 4th iteration , Err = 6.40e+01 true weight dictionary learning weight dictionary threshold (b) 0 50 100 150 200 0 5 10 15 20 25 30 35 40 45 7th iteration , Err = 2.24e+01 true weight dictionary learning weight dictionary threshold (c) 0 50 100 150 200 0 5 10 15 20 25 30 35 40 45 10th iteration , Err = 2.10e+00 true weight dictionary learning weight dictionary threshold (d) Figure 1 a demo of ”first significant jump” rule in multi-stage multi-task feature lea rning. (a)1st iteration, Erro r=1.59e+02 , (b)4th iteration, Error=6.40 e+01, (c)7th iteration, Error=2.24e+0 1, (d)10t h i teration, Erro r=2.10e+00. (a) 1 2 3 4 5 6 7 8 9 10 0 10 20 30 40 50 60 70 80 90 Stage Paramter estimation error (L2,1) m=15,n=40,d=250,sigma=0.01 MSMTFL−AT(alpha=1e−4) MSMTFL−AT(alpha=3e−4) MSMTFL−AT(alpha=5e−4) MSMTFL(alpha=1e−4) MSMTFL(alpha=3e−4) MSMTFL(alpha=5e−4) (b) 1 2 3 4 5 6 7 8 9 10 0 20 40 60 80 100 120 140 Stage Paramter estimation error (L2,1) m=25,n=25,d=180,sigma=0.05 MSMTFL−AT(alpha=1e−4) MSMTFL−AT(alpha=3e−4) MSMTFL−AT(alpha=5e−4) MSMTFL(alpha=1e−4) MSMTFL(alpha=3e−4) MSMTFL(alpha=5e−4) (c) Figure 2 Average d pa rameter estimation error k ˆ W − ¯ W k 2 , 1 vs. Stage ( ℓ ) plots for M SMTFL-A T and MSMTFL algo rithms on the synthetic data set (averaged over 10 runs). W e set λ = α p ln ( dm ) /n , θ = 50 mλ referring to [ 1 ] . (a)m=20, n=30, d=200, σ =0.005 (b)m=15, n=40, d=250, σ =0.01 (c)m=25, n=25, d=180 , σ =0.05. 10 −6 10 −5 10 −4 10 −3 10 −2 10 −1 10 0 10 −1 10 0 10 1 10 2 10 3 Lambda Paramter estimation error (L2,1) m=20,n=30,d=200,sigma=0.005 Lasso L2,1 MSMTFL−AT MSMTFL(theta1) MSMTFL(theta2) MSMTFL(theta3) MSMTFL(theta4) (a) 10 −6 10 −5 10 −4 10 −3 10 −2 10 −1 10 0 10 −1 10 0 10 1 10 2 10 3 Lambda Paramter estimation error (L2,1) m=15,n=40,d=250,sigma=0.01 Lasso L2,1 MSMTFL−AT MSMTFL(theta1) MSMTFL(theta2) MSMTFL(theta3) MSMTFL(theta4) (b) 10 −6 10 −5 10 −4 10 −3 10 −2 10 −1 10 0 10 0 10 1 10 2 10 3 Lambda Paramter estimation error (L2,1) m=25,n=25,d=180,sigma=0.05 Lasso L2,1 MSMTFL−AT MSMTFL(theta1) MSMTFL(theta2) MSMTFL(theta3) MSMTFL(theta4) (c) Figure 3 Averaged pa rameter estimation erro r k ˆ W − ¯ W k 2 , 1 vs. L ambda ( λ ) plots fo r Lasso, L 2,1, MSMTFL-A T and MSMTFL(the ta1,2,3,4) al go rithms on the synthetic data set (averaged over 10 runs). W e set θ 1 = 50 mλ , θ 2 = 10 mλ , θ 3 = 2 mλ and θ 4 = 0 . 4 mλ for MSMTFL referring to [ 1 ].(a)m=20, n=30, d=200, σ =0.005 (b)m=15, n=40, d=250, σ =0.01 (c)m=25, n=25, d=180, σ =0.05. F an et al. Pag e 13 of 13 10 −6 10 −5 10 −4 10 −3 10 −2 10 −1 10 0 10 0 10 1 10 2 10 3 Lambda Paramter estimation error (L2,1) m=25,n=25,d=180,sigma=0.05 Efficient−L2,1 MSMTFL−AT rMTFL MSMTFL (a) 10 −6 10 −5 10 −4 10 −3 10 −2 10 −1 10 0 10 −1 10 0 10 1 10 2 10 3 Lambda Paramter estimation error (L2,1) m=20,n=30,d=200,sigma=0.005 Efficient−L2,1 MSMTFL−AT rMTFL MSMTFL (b) 10 −6 10 −5 10 −4 10 −3 10 −2 10 −1 10 0 10 −1 10 0 10 1 10 2 10 3 Lambda Paramter estimation error (L2,1) m=15,n=40,d=250,sigma=0.01 Efficient−L2,1 MSMTFL−AT rMTFL MSMTFL (c) Figure 4 Average d pa rameter estimation error k ˆ W − ¯ W k 2 , 1 vs. Lambda ( λ ) plots for Efficient-L2 ,1, rM TFL, MSMTFL-A T and MSMTFL(the ta4) algo rithms on the synthet ic data set (averaged over 10 runs) .(a)m=25, n=25, d=180, σ =0.05 (b)m=20, n=30, d=200, σ =0.005 (c)m=15, n=40, d=250, σ =0.01. 0.15 0.2 0.25 0.26 0.28 0.3 0.32 0.34 0.36 0.38 0.4 0.42 0.44 0.46 aMSE Training Ratio MSMTFL−AT MSMTFL rMTFL Efficient−L21 (a) 0.15 0.2 0.25 0.2 0.21 0.22 0.23 0.24 0.25 0.26 nMSE Training Ratio MSMTFL−AT MSMTFL rMTFL Efficient−L21 (b) Figure 5 ( a) aMSE vs. training ratio plots on the Isolet data sets.(b ) nMSE v s. training ratio plots on the Isolet data sets.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment